文章目录
防止遗忘和后续翻找的麻烦,记录下平时学到和用到的GPU知识,较为琐碎,不考虑连贯性和严谨性,如有欠妥的地方,欢迎指正。
一、概述
上章记录了单机多卡的拓扑结构,同时在计算网络小节中也提到了Spine-Leaf网络拓扑结构,这章会详细介绍这种拓扑结构的由来。
实际上,spine-leaf网络拓扑结构是一种Clos结构,我们称之为“脊叶网络”,由Charles Clos在1950年提出,初衷是为了解决网络电话爆炸式增长这一难题。
本章是基于数据中心来研究这种拓扑结构的,通过对数据中心学习,了解其发展演化历史,了解GPU主机在数据中心中的位置,我们才能清晰的理解如何进行多节点集群组网,才能清晰的理解物理拓扑,才能清晰的进行多卡通信,分布式训练等。
本章只介绍同一数据中心下的多机多卡拓扑结构。关于跨区域的数据中心,不做赘述,有感兴趣的可以自行搜索。
二、数据中心(DC)
2.1 数据中心简介
1)机房
计算机机房、通讯机房、互联网数据中心机房IDC(Internet Data Center)等电子设备机房,统称为“机房”。
机房的重要性不言而喻,我们根据其重要性将机房分为A、B、C三个等级。A级的可靠性要求最高,如果出现问题,将造成重大经济损失和混乱。其次是B级,如果出现问题,将造成较大经济损失和混乱。
一个具有高可靠性的机房,需要具备良好的冷却系统、电力系统、消防系统、安全操作规范,以及防水防尘、抗干扰抗辐射等机制。
废话不多说,先上一个数据中心机房图。

为了保证制冷效果,通常会将10~20个机柜背靠背并排放置在一起,形成一对机柜组,称为一个POD(Performance Optimized Datacenter)。

一个POD中的两排机柜都采用前后通风模式,冷空气从机柜前面板吸入并从后面板排出。
POD中的两排背靠背摆放的机会中间形成“热通道”,相邻的两个POD之间形成“冷通道”。通过机房空调(CRAC)形成一个循环,热空气沿“热通道”流回CRAC,冷空气从前面板吸入POD中。
2)基本单位 POD
注意,该POD与k8s中的pod不是一个概念。
每一对机柜组(POD),都是数据中心中规划的最小业务单位,由交换机、防火墙、LB、服务器等资源集成而成。
POD+接入层+汇聚层,会构成一个下层的二层广播域,我们称之为L2网络。汇聚层以上的网络称之为L3网络。汇聚层交换机是L2和L3层的共同边界。
关于网络拓扑的研究,在下面两节中会详细进行。
2.2 传统数据中心的网络模型
在传统的大型数据中心,采用了层次化的三层网络模型,将复杂的网络问题分解成不同层次的简单问题域。

在三层网络模型中,每一层都负责特定的功能,废话不多说,上拓扑结构图。
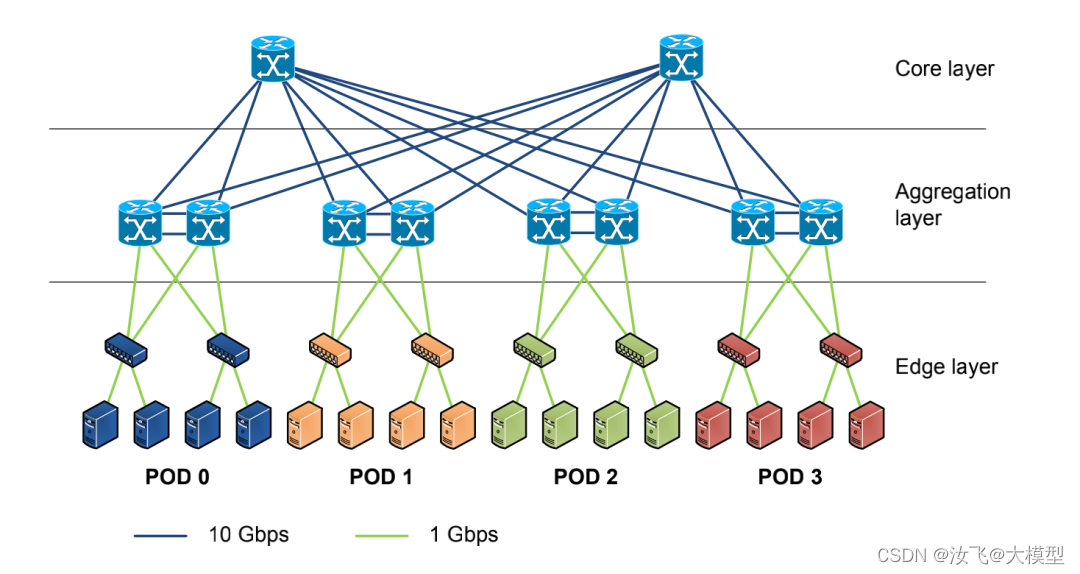
1)接入层
作用就是将工作站点(POD)接入到网络中,提供规划网段和带宽、设置网关等网络服务。
从拓扑图中,可知有4个POD,每个POD由4台机器组成,每2台机器组成一个机柜,共2组机柜。
2)汇聚层
作用就是承上启下,连接接入层与核心层,组成三层网络模型。
汇聚层交换机与接入层和核心层都是以full-mesh的形式互联互通。
汇聚层交换机支持“东西向流量”,每组的2个交换机互联互通,与下方网络组成二层广播域,即L2网络。
汇聚层除了提供内容转发,还提供防火墙、SSL卸载、入侵检测、网络分析等服务。
3)核心层
核心层路由交换机作为网络高速交换主干,是整个网络的支撑脊梁(spine)和数据传输通道,为网络中进出数据中心的报文提供高速路由转发,为多个汇聚层提供连接性。
核心层通常为整个网络提供一个弹性的L3网络路由。
4)二层广播域
通常情况下,汇聚交换机是L2和l3网络的边界,汇聚交换机以下是L2网络,以上是L3网络。
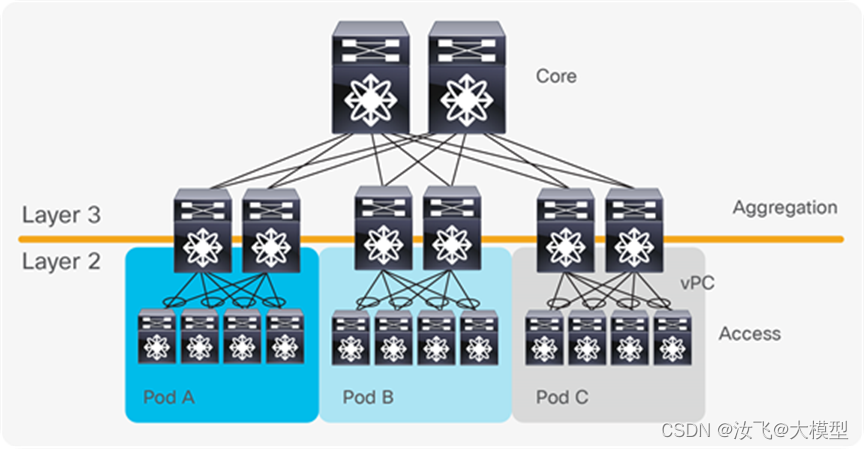
每组汇聚交换机都管理一个POD,每个POD都是一个独立的业务单元,总有独立的VLAN网络。服务器在POD内迁移时,不需要修改IP和网关等配置,因为他们都在同一个二层广播域内。
5)数据中心的流量形式
主要分三种:
- 南北向流量:数据中心与外部网络(互联网)的流量。在传统DC中,这种流量占80%,应用通常采用专线部署方式,即将服务部署在多个固定的物理机中,与其他系统物理隔离。
- 东西向流量:DC内服务器之间以及POD之间的流量。
- 跨IDC流量:不同IDC间的流量,如不同数据中心的容灾等
随着分布式技术、云原生技术的广泛应用,如大模型训练可以分布在一个数据中心的上千台服务器中并行计算,导致东西向流量快速增加。
传统的三层网络是为南北向流量占主导地位的数据中心设计的,已经不满足现在的大规模东西向流量需要。
6)传统IDC三层网络模型的优缺点
优点就是实现简单、配置简单、广播控制力强等,被广泛应用于传统DCN。
缺点就是无法满足日益发展的网络需求,现在的数据中心朝着云数据中心转型,虚拟化、云原生技术被广泛使用,由此衍生出了两大缺点:
- 无法支撑虚拟机跨POD迁移。
- POD间的东西向流量无法在二层广播域中无阻塞转发,需要通过核心层转发。
- 不满足大规模东西向流量需求,需要经过不必要汇聚层和核心层转发,大规模的东西向流量会导致连接同一交换机端口的设备争夺带宽,导致时延增加。
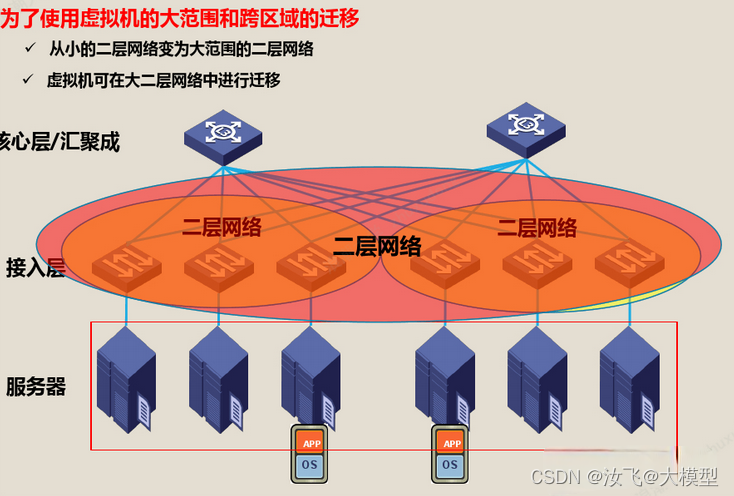
7)虚拟机跨POD迁移
虚拟机是物理服务器通过虚拟化技术构建出来的逻辑服务器,称为VM,拥有独立的系统和应用,也有自己的MAC和IP地址。
在生产环境中,我们需要根据容灾可靠性、可服务性等要求,进行虚拟机的动态迁移,迁移过程要求服务不中断,将VM从一台物理服务器迁移到另一台物理服务器。
虚拟机动态迁移过程中,为了保证服务的连续性,不能更改IP,TCP会话保持不能断,这就需要迁移的起始位置和目标位置都必须在同一个二层网络中,这个二层网络就称之为“大二层网络”。
2.3 脊叶网络模型(Spine-Leaf)
Spine-Leaf是Clos结构,一种新的数据中心网络模型,我们称之为“叶脊网络”。顾名思义,该架构拥有一个脊层spine和一个叶层leaf,包括脊交换机和叶交换机。
相比于传统网络的三层架构,叶脊网络进行了扁平化,变成了两层架构,每个叶交换机都连接到所有脊交换机,脊交换机间不互联,叶交换机间也不互联,他们之间形成full-mesh拓扑。如下图所示:
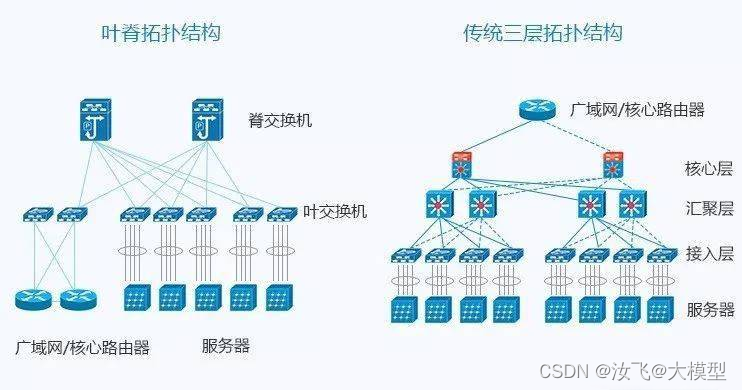
leaf层:由接入交换机组成,用于连接服务器等设备。
spine层:是网络的骨干,负责将所有的 leaf 连接起来。
fabric中的每个leaf都会连接到每个spine,如果一个spine挂了,数据中心的吞吐性能只会有轻微的下降。
叶交换机:相当于传统三层架构中的接入交换机,作为 TOR(Top Of Rack)直接连接物理服务器。叶交换机之上是L3网络,之下都是个独立的 L2 广播域。如果说两个叶交换机下的服务器需要通信,需要经由脊交换机进行转发。
脊交换机:相当于核心交换机。叶和脊交换机之间通过ECMP(Equal Cost Multi Path)动态选择多条路径。

图:叶交换机,思科Nexus 9396PX
在该模型中,任意两个服务器之间都是3跳可达的:serve<–>leaf<–>spine<–>leaf<–>serve,确保了延迟的可预测。
优缺点
优点:
- 成本低:
南北向流量,可以从叶节点出去,也可从脊节点出去。东西向流量,分布在多条路径上。这样一来,叶脊网络可以使用固定配置的交换机,不需要昂贵的模块化交换机,进而降低成本。- 扁平化:
扁平化设计缩短服务器之间的通信路径,从而降低延迟,可以显著提高应用程序和服务性能。- 低延迟和拥塞避免:
无论源和目的地如何,叶脊网络中的数据流在网络上的跳数都相同,任意两个服务器之间都是Leaf—>Spine—>Leaf三跳可达的。这建立了一条更直接的流量路径,从而提高了性能并减少了瓶颈。- 可拓展性:
当带宽不足时,增加脊交换机数量,可水平扩展带宽。当服务器数量增加时,如果端口密度不足,我们可以添加叶交换机。
例如:如果某个链路被打满了,扩容过程也很直接:添加一个spine交换机就可以扩展每个 leaf的上行链路,增大了leaf和spine之间的带宽,缓解了链路被打爆的问题。如果接入层的端口数量成为了瓶颈,那就直接添加一个新的leaf,然后将其连接到每个spine并做相应的配置即可。这种易于扩展的特性优化了IT部门扩展网络的过程。leaf层的接入端口和上行链路都没有瓶颈时,这个架构就实现了无阻塞。- 安全性和可用性高:传统的三层网络架构采用STP协议,当一台设备故障时就会重新收敛,影响网络性能甚至发生故障。叶脊架构中,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。
通过ECMP进行负载均衡,非常适合使用SDN 等集中式网络管理平台的环境。SDN允许在发生阻塞或链路故障时简化流量的配置,管理和重新分配路由,使得智能负载均衡的全网状拓扑成为一个相对简单的配置和管理方式。
缺点:
- 交换机的增多使得网络规模变大。叶脊网络架构的数据中心需要按客户端的数量,相应比例地增加交换机和网络设备。随着主机的增加,需要大量的叶交换机上行连接到脊交换机。脊交换机和叶交换机直接的互联需要匹配,一般情况下,叶脊交换机之间的合理带宽比例不能超过3:1。
例如,有48个10Gbps速率的客户端在叶交换机上,总端口容量为 480Gb/s。如果将每个叶交换机的 4 个 40G 上行链路端口连接到 40G 脊交换机,它将具有 160Gb/s 的上行链路容量。该比例为 480:160,即 3:1。数据中心上行链路通常为 40G 或 100G,并且可以随着时间的推移从 40G (Nx 40G) 的起点迁移到 100G (Nx 100G)。重要的是要注意上行链路应始终比下行链路运行得更快,以免端口链路阻塞。
叶脊网络也有明确的布线的要求。因为每个叶节点都必须连接到每个脊交换机,我们需要铺设更多的铜缆或光纤电缆。互连的距离会推高成本。根据相互连接的交换机之间的距离,叶脊架构所需要的高端光模块数量高于传统三层架构数十倍,这会增加整体部署成本。不过也因此带动了光模块市场的增长,尤其是100G、400G这样的高速率光模块。

2.4 Facebook的Fabric网络架构
Facebook从2014年开始对自己原有的数据中心网络架构进行改造,以适应对未来网络流量2-4倍的扩张。
Facebook的下一代数据中心网络——data center fabric网络架构(F4网络),是在原始叶脊网络基础上进行模块化组网,以承载数据中心内部的大规模东西向流量的转发,具有足够的扩展性。

F4架构:
在这种架构中,我们的Spine-Leaf 网络是其中的一个POD, 我们的SPINE是图中的Fabric Switches,我们的leaf是图中的Rack Switches,最上面的Spine Switches把各个POD连通起来。当一个POD的容量已满时,可以增加POD,并用spine将这些POD连通起来,实现了网络的继续扩展。除了前面描述的POD和spine,上图中还有黄色的Edge Plane,这是为数据中心提供南北向流量的模块。它们与spine交换机的连接方式,与前文中简单的的Spine-Leaf 架构一样。并且它们也是可以水平扩展的。
Spine-Leaf 网络架构只是一种网络部署的拓扑方式,具体的实现方法与配置多种多样,有的厂商根据这种拓扑结构定义了特定的网络协议,如思科的Fabric Path等。
目前Fabric网络已经演进到F16架构,将Spine平面增加为16个。单芯片处理能力提升为12.8TBps, 使得Spine交换机由原来的BackPack更新为MiniPark架构,不仅体积更小,所要通过的路径仅需跨越5个芯片。

三、基于数据中心的多机多卡拓扑
3.1 Spine-Leaf 架构网络规模测算方法
脊交换机下行端口数量,决定了叶交换机的数量。而叶交换机上行端口数量,决定了脊交换机的数量。它们共同决定了叶脊网络的规模。接下来我们可以根据交换机的端口数量和带宽,对Spine-Leaf 架构的网络适用的规模进行简单的估计,如下图所示的拓扑:
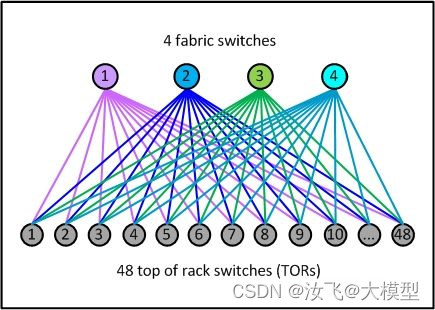
估算基于以下假设:
- spine数量:16台
- 每个spine的下联端口:48个 × 100G
- spine上联端口:16个 × 100G
- leaf数量:48台
- 每个leaf的下联端口:64个 × 25G
- leaf的上联端口: 16个 × 25G
spine的下联端口数量和LEAF的上联端口数量相同,以充分利用端口,在考虑链路Spine-Leaf 之间的带宽全部跑满的情况下,每个leaf下联的服务器数量最多为:16*100/25=64。
刚好等于leaf的下联端口数量,总共可支持的服务器数量为:64 * 48 = 3072。
在上述假设下,一组Spine-Leaf 网络可以支持3072台服务器,需要注意的是,叶脊交换机北向总带宽一般不会和南向总带宽一致,通常大于1:3即可,该例中为400:640。
这相当于一个中大型规模的数据中心,如果仍有扩展的需求该怎么办?根据上述的计算,leaf和spine的下联端口都已经耗尽,在这个网络中已无法增加spine,leaf或服务器。谷歌在此基础上进行了拓展,开发出了五级CLOS架构,即F4。
3.2 NVIDIA多机多卡组网
1)GPU上接Spine-Leaf网络

性能优化参见:NVIDIA Blog Leaf-Spine DC
2)Node间通信方式

详情参见:NVIDIA Blog: Network IO
3)基于spine-leaf的跨轨通信
在传统的多机间GPU通信时,常常将多个节点的GPU网卡连接到对应的Leaf上,通信路径经过spine switch,这种通信方式我们称之为“跨轨通信”。
GPU多机多卡组网拓扑

每个 DGX 系统的 NIC-0 连接到同一叶交换机 (L0),NIC-1 连接到同一叶交换机 (L1),依此类推。这种设计通常称为 Rail-optimized。
4)PXN单轨通信
PXN 利用节点内 GPU 之间的 NVIDIA NVSwitch 连接,首先在与目标相同的轨道上的 GPU 上移动数据,然后在不越轨的情况下将其发送到目标。这实现了消息聚合和网络流量优化。

参见:NVIDIA Blog: Collective Communication
5)英伟达数据中心设计与优化
下节详细介绍nccl和hccl通信。
标签:数据中心,spine,多卡,网络,Spine,交换机,多机,GPU,POD From: https://blog.csdn.net/qq_40214669/article/details/143307857