现有的方法通过利用视觉-语言模型(
VLMs)(如CLIP)强大的开放词汇识别能力来增强开放词汇目标检测,然而出现了两个主要挑战:(1)概念表示不足,CLIP文本空间中的类别名称缺乏文本和视觉知识。(2)对基础类别的过拟合倾向,在从VLMs到检测器的转移过程中,开放词汇知识偏向于基础类别。为了解决这些挑战,论文提出了语言模型指令(
LaMI)策略,该策略利用视觉概念之间的关系,并将其应用于一种简单而有效的类似DETR的检测器,称为LaMI-DETR。LaMI利用GPT构建视觉概念,并使用T5研究类别之间的视觉相似性。类别之间的这些关系改善了概念表示,避免了对基础类别的过拟合。全面的实验验证了该方法在相同严格设置下的优越性能,不依赖于外部训练资源。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: LaMI-DETR: Open-Vocabulary Detection with Language Model Instruction

Introduction
开放词汇目标检测(OVOD)旨在识别和定位来自广泛类别的物体,包括在推理过程中的基础类别和新类别,即使仅在有限的基础类别上进行训练。现有的开放词汇目标检测研究主要集中在检测器内部复杂模块的开发,这些模块旨在有效地将视觉-语言模型(VLMs)固有的零样本和少样本学习能力用于目标检测的上下文。
然而,大多数现有方法中存在两个挑战:(1)概念表示。大多数现有方法使用来自CLIP文本编码器的名称嵌入来表示概念。然而,这种概念表示方法在捕捉类别之间的文本和视觉语义相似性方面存在局限性,这种相似性有助于区分视觉上容易混淆的类别并探索潜在的新对象;(2)对基础类别的过拟合。尽管VLMs在新类别上表现良好,但开放词汇检测器的优化仅使用基础检测数据,导致检测器对基础类别的过拟合。因此,新对象容易被视为背景或基础类别。

首先,是概念表示的问题。CLIP文本空间中的类别名称在文本深度和视觉信息方面都存在不足。(1) 与语言模型相比,VLM的文本编码器缺乏文本语义知识。如图1a所示,仅依赖于来自CLIP的名称表示会集中于字母组成的相似性,忽视了语言背后的层次性和常识理解。这种方法对分类聚类不利,因为它未能考虑类别之间的概念关系。(2) 基于抽象类别名称或定义的现有概念表示未能考虑视觉特征。图1b展示了这个问题,尽管海狮和儒艮在视觉上相似,但它们被分配到了不同的聚类中。仅用类别名称表示概念忽视了语言所提供的丰富视觉语境,这可能有助于发现潜在的新对象。
其次,是对基础类别的过拟合问题。为充分利用VLM的开放词汇能力,采用一个冻结的CLIP图像编码器作为主干网络,并利用来自CLIP文本编码器的类别嵌入作为分类权重。论文认为,检测器训练应发挥两个主要功能:首先,区分前景和背景;其次,保持CLIP的开放词汇分类能力。然而,仅在基础类别注释上进行训练,而不结合额外策略,往往导致过拟合:新对象常常被错误分类为背景或基础类别。
探索类别之间关系是解决上述挑战的关键。通过培养对这些关系的细致理解,可以开发一种结合文本和视觉语义的概念表示方法。这种方法还可以识别视觉上相似的类别,引导模型更专注于学习通用的前景特征,从而防止对基础类别的过拟合。因此,论文提出了LaMI-DETR(Frozen CLIP-based DETR with Language Model Instruction),这是一种简单但有效的基于DETR的检测器,利用语言模型的见解提取类别间关系来解决上述挑战。
为了解决概念表示的问题,首先采用Instructor Embedding,一种T5语言模型,重新评估类别的相似性。与CLIP文本编码器相比,语言模型展现出更为细致的语义空间。如图1b所示,“fireweed”(火绒草)和“fireboat”(消防船)被分类到不同的簇中,更加贴近人类的识别方式。接下来,引入GPT-3.5为每个类别生成视觉描述。这包括对形状、颜色和大小等方面的详细描述,有效地将这些类别转换为视觉概念。图1c显示,在相似的视觉描述下,海狮和儒艮现在被归为同一簇。
为了减轻过拟合问题,根据T5的视觉描述嵌入将视觉概念聚类成组。这个聚类结果使得在每次迭代中能够识别和抽样与真实类别在视觉上不同的负类。这放宽了分类的优化,集中模型的注意力于推导更为通用的前景特征,而不是过拟合到基础类别。因此,这种方法通过减少对基础类别的过训练增强了模型的泛化能力,同时保留了CLIP图像骨干的分类能力。
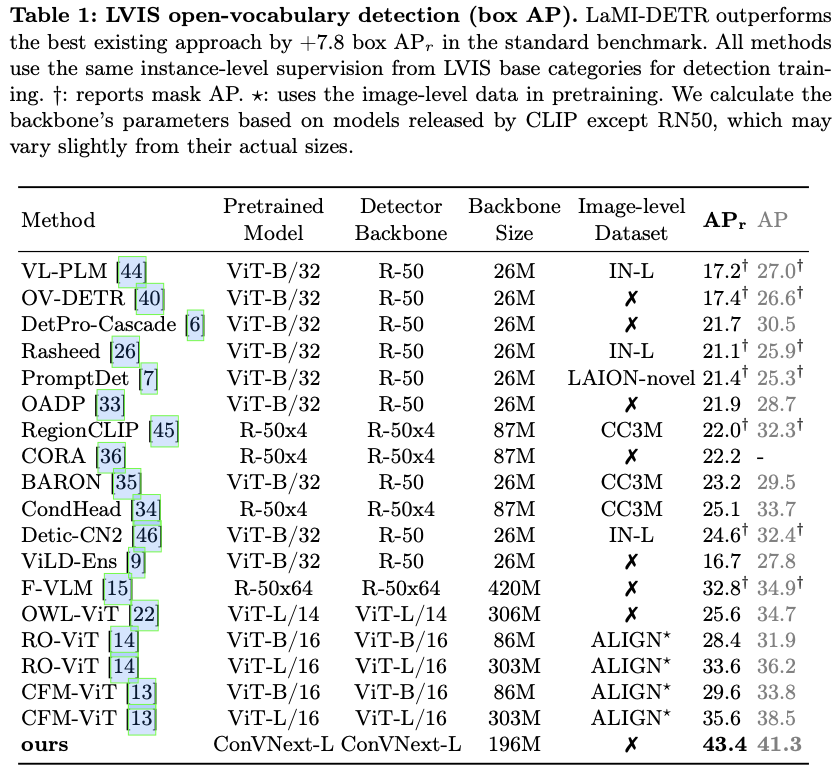
总之,论文提出了一种新颖的方法LaMI,以增强OVOD中的基础到新类别的泛化能力。LaMI利用大型语言模型提取类别之间的关系,并利用这些信息抽样简单的负类,以避免对基础类别的过拟合,同时优化概念表示,以实现视觉上相似类别之间的有效分类。论文提出了一个简单但有效的端到端LaMI-DETR框架,能够有效地将开放词汇知识从预训练的VLM转移到检测器上。通过在大词汇OVOD基准上进行严格测试,展示了LaMI-DETR框架的优越性,包括在OV-LVIS上提升 \(+7.8\) AP \(_\textrm{r}\) 和在VG-dedup上提升 \(+2.9\) AP \(_\textrm{r}\) (与OWL进行公平比较)。
Method
Preliminaries
给定一个输入的图像 \(\mathbf{I} \in \mathbb{R}^{H \times W \times 3}\) 到开放词汇对象检测器,通常会生成两个主要输出:(1)分类,其中为图像中第 \(j^{\text{th}}\) 预测对象分配一个类别标签 \(c_j \in \mathcal{C}_{\text{test}}\) , \(\mathcal{C}_{\text{test}}\) 表示在推理过程中针对的类别集合。(2)定位,包括确定边界框坐标 \(\mathbf{b}_j \in \mathbb{R}^4\) ,以识别第 \(j^{\text{th}}\) 预测对象的位置。遵循OVR-CNN建立的框架,定义了一个检测数据集 \(\mathcal{D}_{\text{det}}\) ,该数据集包含边界框坐标、类别标签及对应的图像,用于处理类别词汇 \(\mathcal{C}_{\text{det}}\) 。
遵循OVOD的惯例,将 \(\mathcal{C}_{\text{test}}\) 和 \(\mathcal{C}_{\text{det}}\) 的类别空间分别表示为 \(\mathcal{C}\) 和 \(\mathcal{C}_{\text{B}}\) 。通常情况下, \(\mathcal{C}_{\text{B}} \subset \mathcal{C}\) 。 \(\mathcal{C}_{\text{B}}\) 中的类别被称为基础类别,而仅出现在 \(\mathcal{C}_{\text{test}}\) 中的类别则被称为新类别。新类别的集合表示为 \(\mathcal{C}_{\text{N}} = \mathcal{C} \setminus \mathcal{C}_{\text{B}} \neq \varnothing\) 。对于每个类别 \(c \in \mathcal{C}\) ,利用CLIP编码其文本嵌入 \(t_c \in \mathbb{R}^d\) ,并定义 \(\mathcal{T}_{\texttt{cls}} = \{t_c\}_{c=1}^C\) ( \(C\) 是类别词汇的大小)。
Architecture of LaMI-DETR
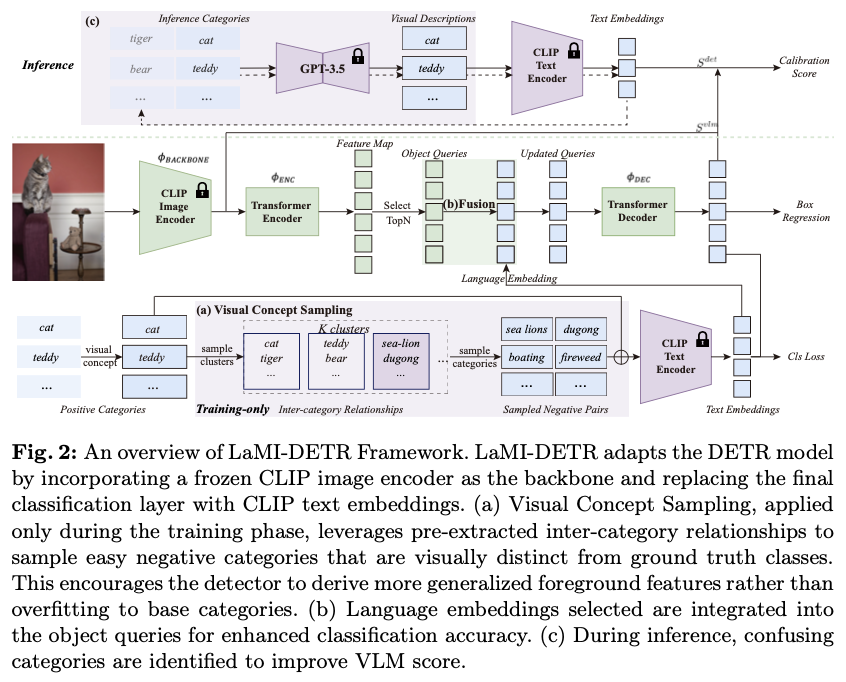
LaMI-DETR的整体框架如图2所示。给定一个图像输入,使用预训练的CLIP图像编码器中的ConvNext主干网络 \(\left(\Phi_{\texttt{backbone}}\right)\) 获取空间特征图,该主干在训练期间保持不变。然后,特征图依次经过一系列操作:一个Transformer编码器 \(\left(\Phi_{\texttt{enc}}\right)\) 来完善特征图;一个Transformer解码器 \(\left(\Phi_{\texttt{dec}}\right)\) ,生成一组查询特征 \(\left\{f_j\right\}_{j=1}^{N}\) 。查询特征随后由边界框模块 \(\left(\Phi_{\texttt{bbox}}\right)\) 处理,以推断对象的位置,记作 \(\left\{\mathbf{b}_j\right\}_{j=1}^{N}\) 。
遵循F-VLM的推理流程,并使用VLM分数 \(S^{vlm}\) 来校准检测分数 \(S^{det}\) 。
-
Comparison with other Open-Vocabulary DETR
CORA和EdaDet框架也在DETR中使用一个被冻结的CLIP图像编码器来提取图像特征。然而,LaMI-DETR在以下几个方面与这两种方法显著不同。
- 在使用的主干网络数量方面,
LaMI-DETR和CORA均采用单个主干。而EdaDet则使用两个主干:一个可学习的主干和一个被冻结的CLIP图像编码器。 CORA和EdaDet都采用了一种将分类和回归任务解耦的架构。虽然这种方法解决了无法召回新类别的问题,但它需要额外的后处理步骤,如NMS,从而破坏了DETR原有的端到端结构。CORA和EdaDet在训练过程中都需要RoI-Align操作。在CORA中,DETR仅预测物体性,necessitating在锚点预匹配过程中对CLIP特征图进行RoI-Align,以确定提议的具体类别。EdaDet基于每个提议的分类分数(通过池化操作获得)最小化交叉熵损失。因此,CORA和EdaDet在推理过程中需要多次池化操作。相比之下,LaMI-DETR简化了这一过程,仅在推理阶段需要一次池化操作。
Language Model Instruction
与仅依赖VLMs的视觉-语言对齐的先前方法不同,论文旨在通过增强概念表示和研究类间关系来改善开放词汇检测器。
-
Inter-category Relationships Extraction
根据图1中识别出的问题,采用视觉描述来建立视觉概念,从而完善概念表示。此外,利用具有丰富文本语义知识的T5来测量视觉概念之间的相似性关系,从而提取类间关系。

如图3所示,给定一个类别名称 \(c \in \mathcal{C}\) ,使用描述的方法提取其细粒度视觉特征描述符 \(d\) 。将 \(\mathcal{D}\) 定义为 \(\mathcal{C}\) 中类别的视觉描述空间。这些视觉描述 \(d \in \mathcal{D}\) 随后被送入T5模型,以获得视觉描述嵌入 \(e \in \mathcal{E}\) 。因此,构建了一个开放的视觉概念集合 \(\mathcal{D}\) 及其对应的嵌入 \(\mathcal{E}\) 。为了识别视觉上相似的概念,将视觉描述嵌入 \(\mathcal{E}\) 聚类为 \(K\) 个聚类中心。归类在同一聚类中心下的概念被认为具有相似的视觉特征。提取的类间关系随后在视觉概念采样中应用,如图2a所示。
-
Language Embedding Fusion
如图2b所示,在Transformer编码器之后,特征图 \(\{f_i\}_{i=1}^{M}\) 上的每个像素被解释为一个对象查询,每个查询直接预测一个边界框。为了选择得分最高的 \(N\) 个边界框作为区域提议,该过程可以概括如下:
在LaMI-DETR中,将每个查询 \(\{q_j\}_{j=1}^{N}\) 与其最近的文本嵌入进行融合,得到:
其中 \(\oplus\) 表示逐元素相加。
一方面,视觉描述被输入到T5模型以聚类视觉上相似的类别,如前所述。另一方面,视觉描述 \(d_j \in \mathcal{D}\) 被转发到CLIP模型的文本编码器以更新分类权重,记作 \(\mathcal{T}_{\text{cls}} = \{t'_c\}_{c=1}^{C}\) ,其中 \(t'_c\) 表示在CLIP文本编码器空间中 \(d\) 的文本嵌入。
因此,用于语言嵌入融合过程的文本嵌入会相应地更新:
\[\begin{align} \label{eqn:embedding_update} \{q_j\}_{j=1}^{N} = \{q_j \oplus t'_j\}_{j=1}^{N} \end{align} \]-
Confusing Category
由于相似的视觉概念通常共享共同的特征,因此可以为这些类别生成几乎相同的视觉描述符。这种相似性在推理过程中给区分相似的视觉概念带来了挑战。
为了在推理过程中区分容易混淆的类别,首先基于 \(\mathcal{T}_{\text{cls}}\) 在CLIP文本编码器语义空间中为每个类别 \(c \in \mathcal{C}\) 识别出最相似的类别 \(c^{\text{conf}} \in \mathcal{C}\) 。然后,修改用于生成类别 \(c\) 的视觉描述 \(d' \in \mathcal{D}'\) 的提示,将 \(c\) 与 \(c^{\text{conf}}\) 区分开来的特征。
设 \(t''\) 为 \(d'\) 在CLIP文本编码器空间中的文本嵌入。如图2c所示,推理流程如下:
-
Visual Concept Sampling
为了解决开放词汇检测数据集中不完整标注所带来的挑战,采用联邦损失,最初是为长尾数据集引入的。这种方法随机选择一组类别,以计算每个小批量的检测损失,有效地最小化了某些类别中缺失标注相关的问题。
给定类别出现频率 \(p = [p_1, p_2, \ldots, p_C]\) ,其中 \(p_c\) 表示第 \(c^{\text{th}}\) 视觉概念在训练数据中的出现频率, \(C\) 代表类别的总数。根据概率分布 \(p\) 随机抽取 \(C_{\text{fed}}\) 个样本。选择第 \(c^{\text{th}}\) 样本 \(x_c\) 的可能性与其对应的权重 \(p_c\) 成正比。该方法有助于将由语言模型提取的视觉相似性知识转移到检测器,从而减少过拟合问题:
\[\begin{align} \label{eqn:federated_loss} P(X = c) = p_c, \quad \text{for } c = 1, 2, \ldots, C \end{align} \]结合联邦损失,分类权重被重新表述为 \(\mathcal{T}_{\text{cls}} = \{t''_c\}_{c=1}^{C_{\text{fed}}}\) ,其中 \(\mathcal{C}_{\text{fed}}\) 表示每次迭代中参与损失计算的类别,而 \(C_{\text{fed}}\) 是 \(\mathcal{C}_{\text{fed}}\) 的数量。
利用一个具有强大开放词汇能力的冻结CLIP作为LaMI-DETR的主干。然而,由于检测数据集中类别的有限性,经过训练后对基本类别的过拟合是不可避免的。为了减少对基本类别的过度训练,根据视觉概念聚类的结果抽取简单的负类别。
在LaMI-DETR中,设包含真实类别的聚类在给定迭代中记作 \(\mathcal{K}_G\) 。将 \(\mathcal{K}_G\) 中的所有类别称为 \(\mathcal{C}_g\) 。具体而言,在当前迭代中排除 \(\mathcal{C}_g\) 的抽样。为此,将 \(\mathcal{C}_g\) 中类别的出现频率设置为零。这种方法使得由语言模型提取的视觉相似性知识能够转移到检测器,从而缓解过拟合问题:
其中 \(p_c^{cal}\) 表示在语言模型校准后类别 \(c\) 的出现频率,确保在这一迭代中不会抽样视觉上相似的类别。此过程如图2a所示。
-
Comparison with concept enrichment.
视觉概念描述与DetCLIP中采用的概念丰富不同。LaMI中使用的视觉描述更加强调对象自身固有的视觉属性。在DetCLIP中,类别标签被补充了定义,这些定义可能包括在图片中不存在的概念,以严格描述一个类别。
Implementation Details
训练是在 \(8\) 块40G A100 GPU上进行的,总批量大小为 \(32\) 。对于OV-LVIS设置,训练模型 \(12\) 个周期。在VG-dedup基准中,为了与OWL-ViT进行公平比较,在随机抽样的 \(1/3\) Object365 数据集上预训练LaMI-DETR \(12\) 个周期。随后,LaMI-DETR在VG dedup数据集上进行额外的 \(12\) 个周期的微调。
检测器使用来自OpenCLIP的ConVNext-Large作为其主干网络,在整个训练过程中保持不变。LaMI-DETR基于DINO,采用了 \(900\) 个查询,具体参数如detrex所述。严格遵循detrex中详细描述的原始训练配置,除了采用指数移动平均(EMA)策略以增强训练稳定性。为了平衡训练样本的分布,使用默认超参数应用重复因子抽样。在联邦损失方面,类别数量 \(C_{\text{fed}}\) 在OV-LVIS和VG dedup数据集中分别设置为 \(100\) 和 \(700\) 。
为了探索更广泛的视觉概念以实现更有效的聚类,从LVIS、Object365、VisualGenome、Open Images和ImageNet-21K中汇编了一个全面的类别集合。通过使用WordNet的上位词过滤掉冗余概念,最终形成了一个包含 \(26,410\) 个独特概念的视觉概念字典。在视觉概念分组阶段,该字典被聚类为 \(K\) 个中心,其中OV-LVIS的 \(K\) 值为 \(128\) ,VG dedup的 \(K\) 值为 \(256\) 。
Experiments

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
