吴恩达大模型教程笔记(一)
【LangChain大模型应用开发】DeepLearning.AI - P1:基于LangChain的大语言模型应用开发1——介绍 - 吴恩达大模型 - BV1iZ421M79T

欢迎参加语言链课程。

通过提示LLM开发应用,现在开发AI应用更快,应用需多次提示LM并解析输出,因此需编写大量胶水代码,Harrison Chase创建的语言链简化此过程,很高兴Harrison能来。
与深度学习合作开发此课程,AI教授如何使用此工具,感谢邀请,我真的很高兴来到这里,长链最初是一个开源框架,当我与领域内的一群人交谈时,他们正在构建更复杂的应用程序,并看到了开发过程中的一些共同抽象。
我们一直对长链社区的采纳感到兴奋,所以期待与这里的每个人分享,并期待看到人们用它构建什么,实际上,作为长链动力的标志,但也有数百开源贡献者,这对快速开发至关重要,团队以惊人速度发布代码和功能。
所以希望短期课程后,你能快速用Line Chain开发酷应用,也许你甚至决定回馈开源Line Chain,Lang Chain是构建LM应用的开源框架,有两个不同包,一个是Python。
一个是JavaScript,专注于组合和模块化。

它们有许多可单独使用或相互结合的独立组件,这是关键价值之一。

另一个关键价值是一系列不同的用例,因此,这些模块化组件可以组合成更多端到端应用程序,并且使开始使用这些用例变得非常容易。

我们将涵盖lang chain的常见组件。

我们将讨论模型,我们将讨论提示,这是如何让模型做有用和有趣的事情。

我们将讨论索引,数据摄入方式有哪些。

这样您就可以与模型结合,然后讨论端到端用例的链条,连同代理商,这些是令人兴奋的端到端用例类型,将模型用作推理引擎。

我们也感谢阿尼什·戈拉,与哈里森·蔡斯一起创办的人是谁,深入思考这些材料,并协助制作这门短课。

在深度学习AI方面,杰夫,路德维希,埃迪舒和迪亚拉作为院长也贡献了这些材料。

那么让我们继续看下一个视频,在那里我们将学习空白模型。

【LangChain大模型应用开发】DeepLearning.AI - P10:2——文档加载 - 吴恩达大模型 - BV1iZ421M79T

为了创建一个应用程序,您可以在其中与您的数据聊天,您首先必须将数据加载到可以使用的格式中,这就是长链文档加载器发挥作用的地方,我们有80多种不同类型的文档加载器,在这节课中,我们将讨论一些最重要的问题。
让您对这个概念感到满意,一般来说,我们跳进去吧,文档加载器处理访问和转换数据的细节,从各种不同的格式和来源变成标准化的格式,我们可以在不同的地方从类似的网站加载数据,不同数据库,YouTube。
这些文档可以有不同的数据类型,比如PDF。

html json,然后呢,所以,文档加载器的全部目的是获取各种数据源,并将它们加载到标准文档对象中,它由内容和相关的元数据组成。

链接链中有许多不同类型的文档加载器,我们没有时间把它们都盖住。
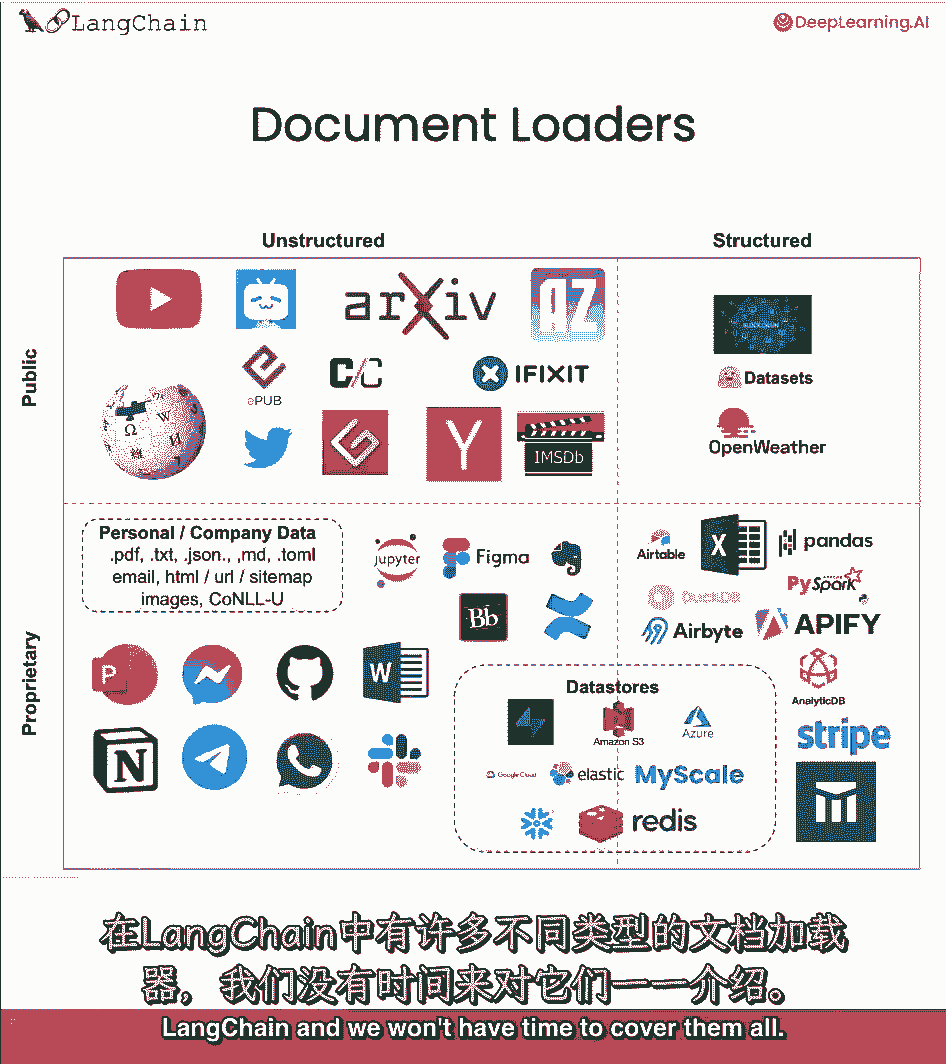
但这里有一个八十个的粗略分类,另外,我们有很多处理加载非结构化数据的方法,就像来自公共数据源的文本文件,比如YouTube。
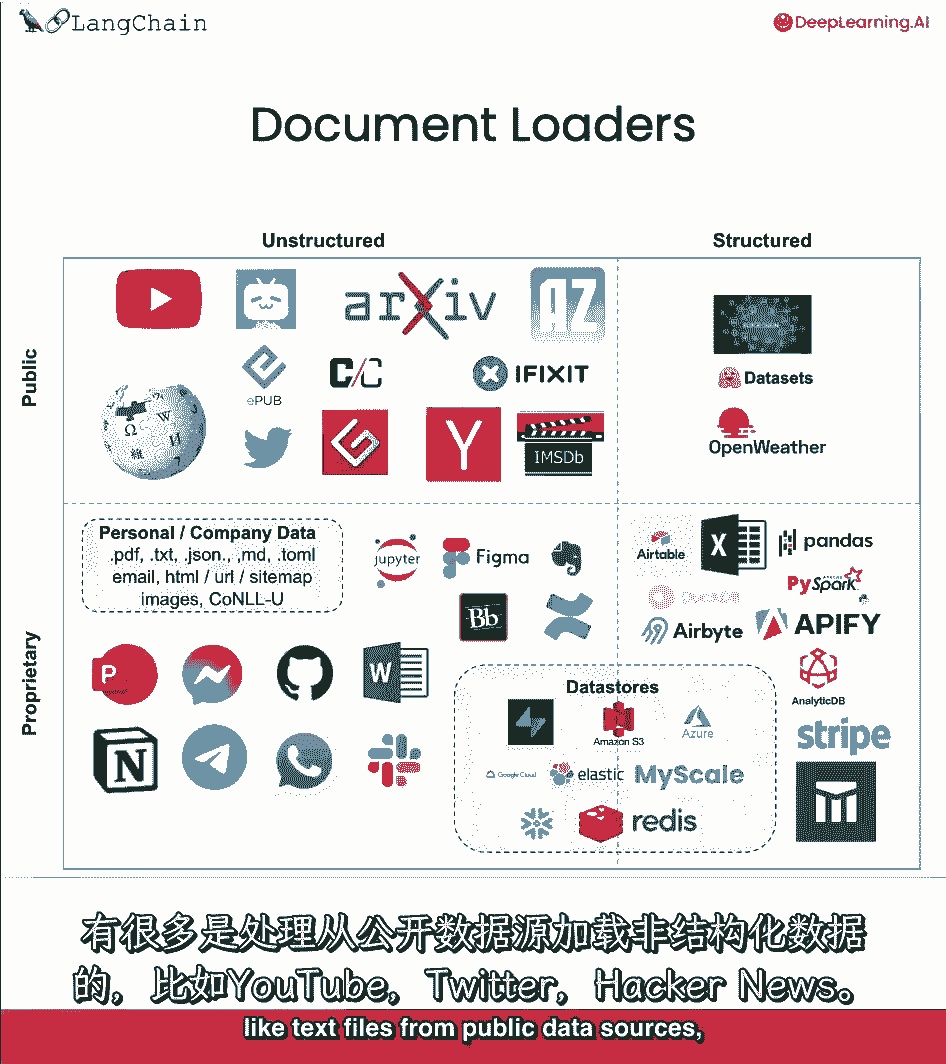
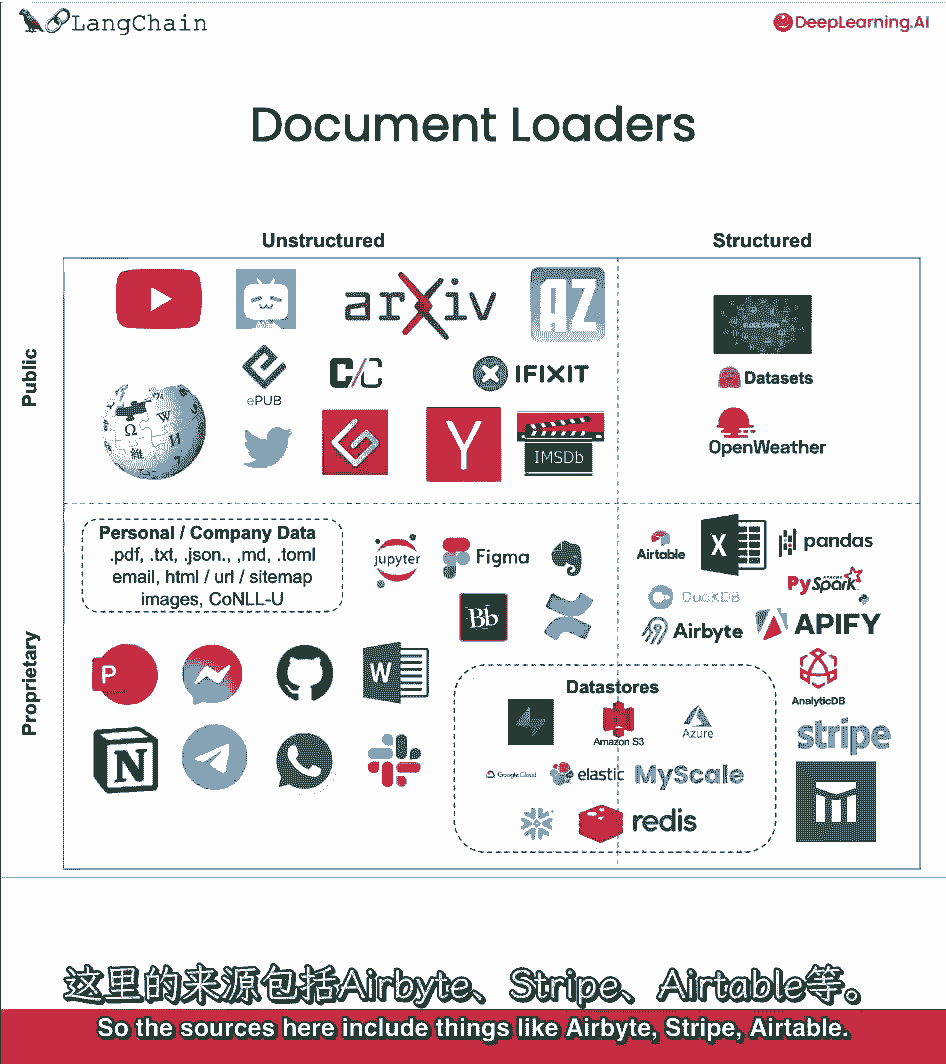
推特,黑客新闻,还有更多的处理加载非结构化数据,从专有数据源,您或您的公司可能有像Figma概念,文档加载器还可用于加载结构化数据,表格格式的数据,可能只是在其中一个单元格或行中有一些文本数据。
你还想做的问题,回答,或语义搜索,所以这里的来源包括像AirByte这样的东西,条纹,可空气。
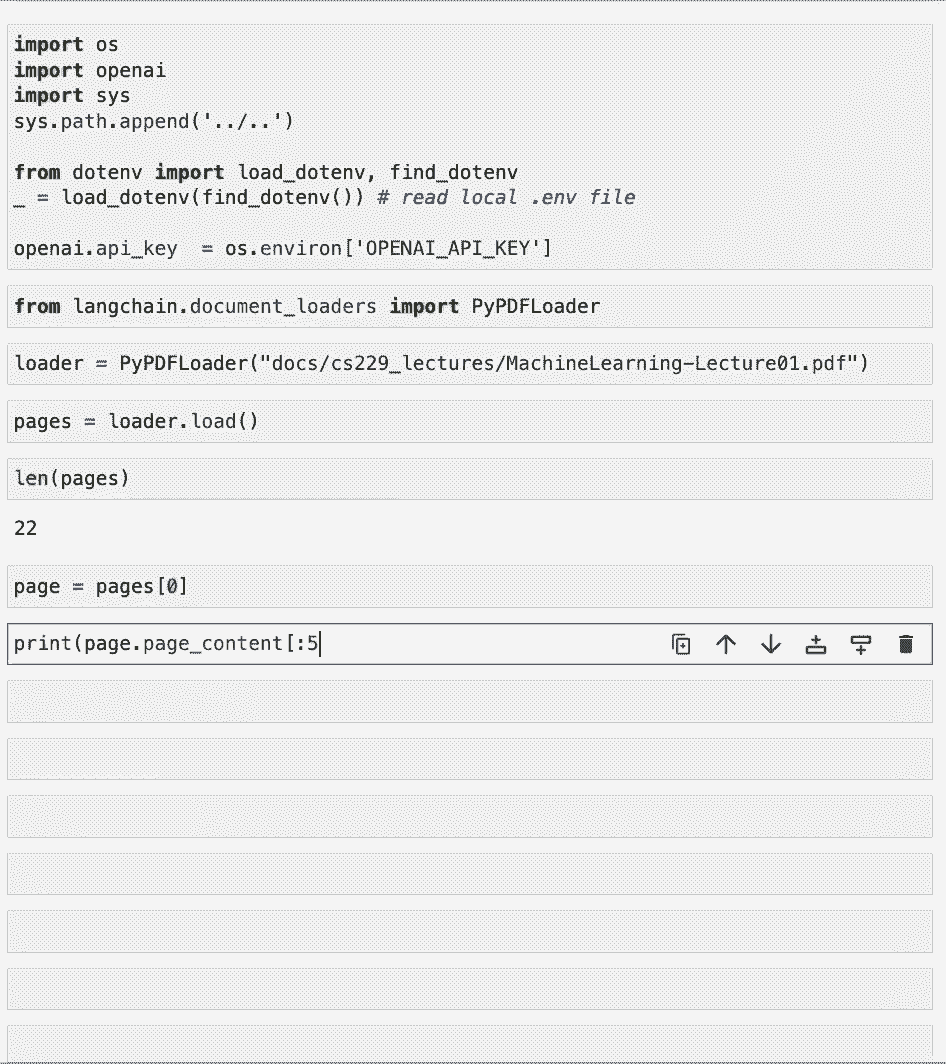
好了现在,让我们跳到有趣的东西,实际使用文档加载器,第一批,我们将加载一些我们需要的环境变量,比如openai api键,我们要处理的第一类文档是PDF,因此,让我们从长链导入相关的文档加载器。
我们要用圆周率PDF漂浮物,我们已将一堆PDF文件装入工作区的文档文件夹。

所以让我们选择一个,把它放在装载机里,现在让我们通过调用load方法来加载文档,让我们看看我们到底装了什么,所以这个,默认情况下,将加载文档列表,在这种情况下,这个PDF中有22个不同的页面。
每一个都是自己独特的文档,让我们来看看第一个,看看它是由什么组成的,文档的第一件事是一些页面内容,哪个是页面的内容,这可能有点长,所以让我们打印出最初的几百个字符。
另一个真正重要的信息是与每个文档相关联的元数据,这可以使用元数据元素访问。

你可以看到这里有两个不同的部分,一是源头信息,这是PDF,我们从另一个加载的文件的名称是页面字段,这与PDF的页面相对应,它是从我们将要看到的下一种文档加载程序加载的,是从YouTube上加载的。
YouTube上有很多有趣的内容,所以很多人使用这个文档加载器可以问问题,他们最喜欢的视频或讲座,或者类似的东西。
我们将在这里进口一些不同的东西,关键部分是YouTube音频加载器,从YouTube视频中加载音频文件,另一个关键部分是开放的AI耳语解析器,这将使用openai的耳语模型,一种语音到文本模型。
将YouTube音频转换为我们可以使用的文本格式。

我们现在可以指定一个URL。

指定保存音频文件的目录,然后创建通用加载程序作为这个YouTube音频加载程序的组合,结合openai耳语解析器,然后我们可以调用加载器点加载来加载与这个YouTube相对应的文档。

这可能需要几分钟。

所以我们要加快速度,现在它已经装完了。

我们可以看看我们加载的页面内容,这是YouTube视频的第一部分,现在是暂停的好时机,去选择你最喜欢的YouTube视频,看看这个转录是否适合你。

我们要看的下一组文件,如何从Internet加载URL,互联网上有很多非常棒的教育内容,那不是很酷吗?如果你能和它聊天。
我们将通过从链接链导入基于Web的加载器来实现这一点。

然后我们可以选择任何URL,我们最喜欢的URL,我们将从这个GitHub页面中选择一个标记文件,并为它创建一个加载器。

然后接下来我们可以调用加载器点加载,然后我们可以看看页面的内容。

在这里你会注意到有很多空白。

然后是一些初始文本,然后是更多的文本,这是一个很好的例子,说明为什么您实际上需要对信息进行一些后处理,使其成为可行的格式。

最后,我们将介绍如何从Concept加载数据,Notion是一个非常受欢迎的个人和公司数据存储,很多人创造了聊天机器人,与你笔记本上的概念数据库对话。
您将看到有关如何将数据从概念数据库导出为格式的说明,通过它我们可以把它加载到链接链中,一旦我们有了那种格式,我们可以使用概念目录加载器来加载数据,得到我们可以处理的文件。

如果我们看看这里的内容,我们可以看到它是降价格式的,这份概念文件来自混合的员工手册,我相信很多听众都认为,并有一些概念数据库,他们想与之聊天。

所以这是一个很好的机会去导出这些数据。

把它带进来,开始用这种格式工作,这里的文档加载到此结束,我们已经介绍了如何从各种来源加载数据,并将其放入标准化文档界面,然而,这些文件仍然相当大。

在下一节中,我们将学习如何把它们分成更小的块,这是相关的,也是重要的,因为当你在做这个检索增强生成时,您只需要检索最相关的内容片段,所以您不想选择我们在这里加载的整个文档,但只有这一段。
或者一些与你所说的最相关的句子,这也是一个更好的机会来思考数据的来源,我们目前没有装载机,但你可能还是想探索谁知道。

也许你甚至可以做一个公关链接。
【LangChain大模型应用开发】DeepLearning.AI - P11:3——文档分割 - 吴恩达大模型 - BV1iZ421M79T

我们刚刚讨论了如何将文档加载到标准格式,现在我们要讨论如何把它们分成更小的块,这听起来可能很容易,但这里有很多微妙之处,对未来产生了巨大的影响,让我们跳进去吧,将数据加载到文档格式后会发生文档拆分。
但在它进入矢量存储之前,这可能看起来很简单,你可以根据每个字符的长度或类似的东西来分割块。


但作为一个例子,为什么这既棘手又非常重要,让我们看一下这里的这个例子,我们有一个关于丰田凯美瑞的句子和一些规格。

如果我们做一个简单的分裂,我们可以把句子的一部分分成一大块,句子的另一部分在另一大块中,然后当我们试图回答一个问题时。

关于凯美瑞的规格是什么。

我们实际上在这两个块中都没有正确的信息,所以它分裂了,所以我们不能正确地回答这个问题,因此,在如何分割大块时,有很多细微差别和重要性,这样你就可以把语义上相关的块放在一起。

车道链中所有文本拆分器的基础都涉及到在块上拆分,在一些块大小和一些块重叠的情况下。

所以我们在下面有一个小图来显示它是什么样子的,所以块大小对应于块的大小,块的大小可以用几种不同的方法来测量,我们将在这节课中讨论其中的一些,所以我们允许传入一个length函数来测量块的大小。
这通常是字符或令牌,块重叠通常保持为两个块之间的一点重叠,就像一扇滑动的窗户,当我们从一个移动到另一个,这允许相同的上下文在一个块的末尾,在另一个的开始,并有助于创造一些一致性的概念。
文本拆分器和链接链都有一个创建文档和拆分文档的方法,这涉及到引擎盖下相同的逻辑,它只是暴露了一个稍微不同的界面。

一个接收文本列表,另一个接收文件列表,在长链中有很多不同类型的分配器,我们将在这节课中介绍其中的一些,但我会鼓励你在业余时间看看其余的,这些文本拆分器在一系列维度上有所不同。
它们可以根据如何分割大块而有所不同,里面有什么角色,它们可以根据,他们如何测量块的长度,是按人物写的吗,是用代币吗,甚至有些人使用其他较小的模型来确定句子的结尾可能是,用它来分割大块。

分割成块的另一个重要部分也是元数据。

在所有块中维护相同的元数据,但也会在相关时添加新的元数据,所以有一些文本拆分器真正关注于此。

块的拆分通常可以特定于,我们正在处理的文档类型。

当您在代码上分裂时,这一点非常明显,所以我们有一个语言文本拆分器,它有一堆不同的分隔符。

对于各种不同的语言。

就像蟒蛇,Ruby c,当拆分这些文件时,它考虑到了这些不同的语言和这些语言的相关分隔符。

当它先劈开的时候,我们将像以前一样通过加载打开的ai api密钥来设置环境。

接下来,我们将导入两种最常见的文本拆分器和长链。

递归字符文本拆分器和字符文本拆分器,我们将首先讨论一些玩具用例,只是为了了解这些到底是做什么的,所以我们要设置一个相对较小的26块大小。

更小的四块重叠,好让我们看看这些能做什么。

让我们将这两个不同的文本拆分器初始化为r拆分器和c拆分器,然后让我们来看看几个不同的用例。

让我们加载第一个学期,一直到z,让我们看看当我们使用各种拆分器时会发生什么。

当我们用递归字符文本拆分器拆分它时。

它最终仍然是一根弦,这是因为它有26个字符长,我们指定了26的块大小,所以现在甚至不需要在这里做任何分裂,让我们用稍微长一点的绳子来做,它比我们指定的块大小的26个字符长。
这里我们可以看到创建了两个不同的块,第一个以z结尾,那就是两个六个字,下一个我们可以看到的是以W开头的,X,Y,Z,这就是四块重叠,然后它继续与字符串的其余部分,让我们看一个稍微复杂一点的字符串。

我们在角色之间有一堆空格,我们现在可以看到它分成三块,因为有空间,所以它占用了更多的空间,所以如果我们看看重叠,我们可以在第一个中看到,有llm,l和m也出现在第二个中,好像只有两个角色。
但是由于l和n之间的空间,然后在L之前和M之后,这实际上算作组成块重叠的四个,现在让我们尝试使用字符文本拆分器。

当我们运行它时,我们可以看到,它实际上根本没有试图分裂它,那么这里发生了什么,问题是字符文本在单个字符上拆分。

默认情况下,该字符是一个新的行字符,但这里没有新的,如果我们将分隔符设置为空白。

我们可以看到会发生什么,然后呢。

这里和以前一样分裂,这是暂停视频并尝试一些新示例的好点,都是你编的不同的琴弦,然后交换分离器,看看会发生什么,实验块大小和块重叠也很有趣,并大致了解几个玩具例子中发生了什么。
所以当我们转向更多现实世界的例子时,你会对幕后发生的事情有很好的直觉。

现在呢,让我们用一些更真实的例子来尝试一下。

我们这里有很长一段,我们可以看到,就在这里,我们有这个双新线符号。

它是段落之间的典型分隔符,让我们看看这篇课文的长度。
我们可以看到它大约是500,现在让我们定义两个文本拆分器,我们将像以前一样使用字符文本拆分器,以空间为分隔符,然后我们将初始化递归字符文本拆分器,在这里我们传递一个分隔符列表。
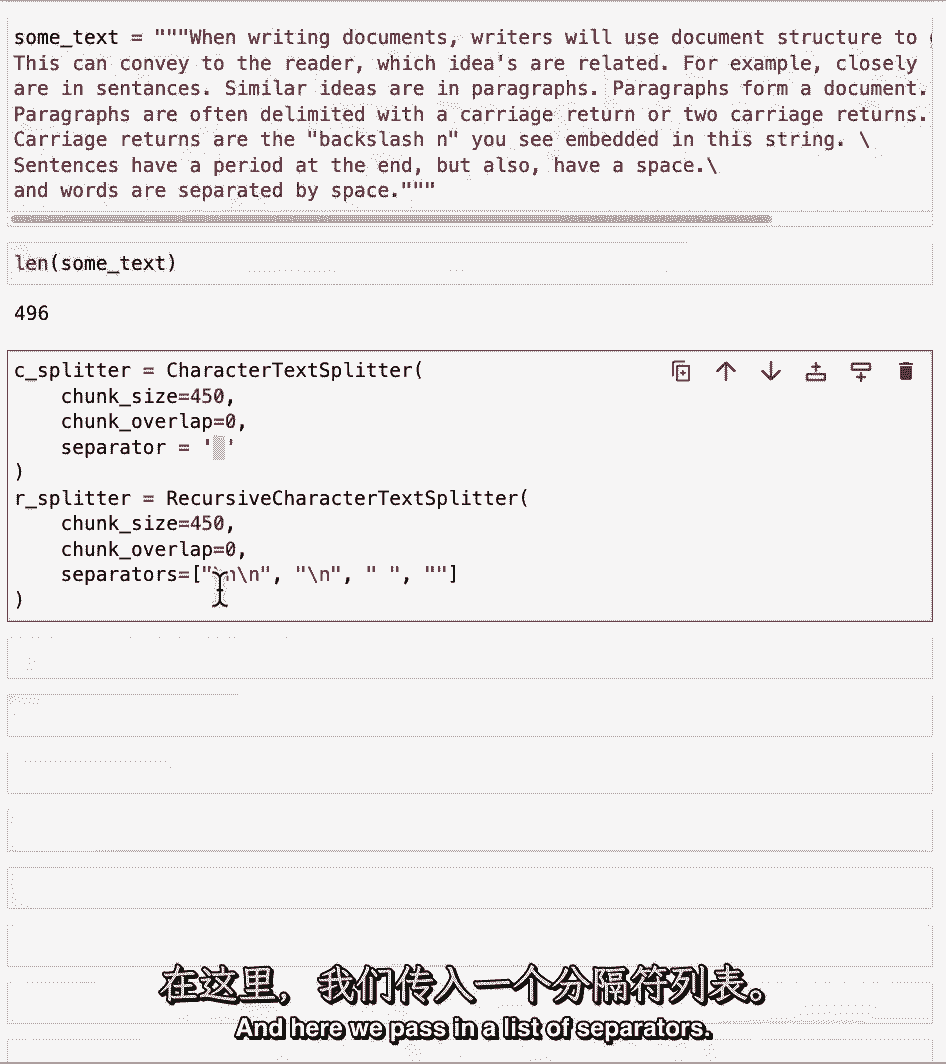
这些是默认的分隔符,但我们只是把它们放在这个笔记本里,以便更好地显示发生了什么。
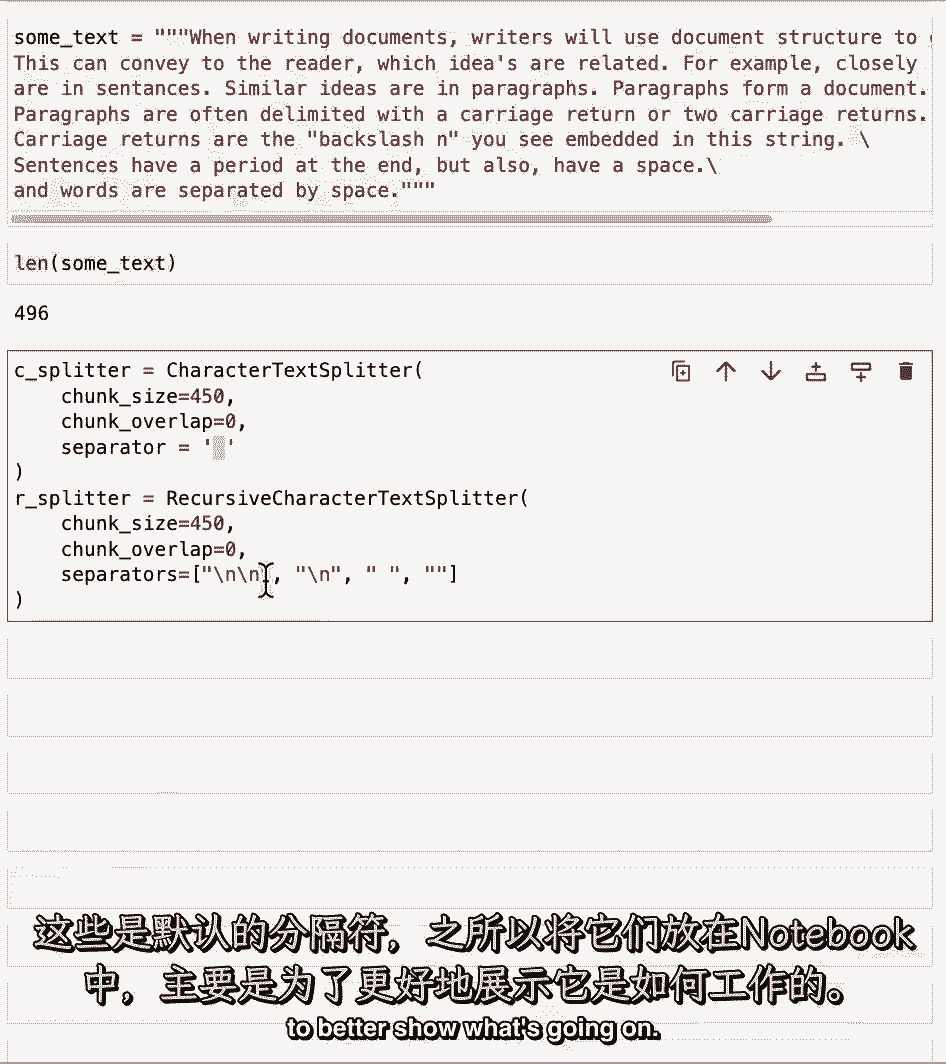
所以我们可以看到我们有一个双新行的列表,单新线空间,然后什么都没有,一个空字符串,这些意味着当你拆分一段文本时,它将首先尝试用两条新线来分割它,然后如果它还需要更多地分割单个块,它将继续单行新线。
如果它还需要做更多,它继续到空间。

最后它就会一个字符一个字符地,如果它真的需要这么做,看看它们在上面的文本中的表现。

我们可以看到字符文本拆分器在空格上拆分。

所以我们以句子中间奇怪的分离而告终。

递归文本拆分器首先尝试在双新行上拆分,所以这里它把它分成两段,即使第一个比指定的450个字符短,这可能是一个更好的分裂,因为现在两个段落各自是自己的段落在块中,而不是在句子中间分开。
现在我们把它分成更小的块,只是为了更好地了解发生了什么,我们还将添加句点分隔符。

这是为了在句子之间分开,如果我们运行这个文本拆分器,我们可以看到句子上的分裂,但经期实际上在错误的地方。

这是因为场景下发生的Reg X,为了解决这个问题,我们实际上可以通过查看后面的内容来指定一个稍微复杂一点的reg x,现在如果我们运行这个,我们可以看到它被分成句子,它是正确地分裂的,句号在正确的地方。
现在让我们在一个更真实的例子上这样做。

使用我们在第一个文档加载部分中使用的PDF文件之一,让我们把它装进去,然后让我们在这里定义我们的文本拆分器,我们在这里传递length函数,这是用孤,内置的蟒蛇,这是默认值。
但我们只是为了更清楚而具体说明。

幕后发生了什么,这是计算字符的长度,因为我们现在想使用文档,我们使用拆分文档的方法,我们正在传递一份文件清单。
如果我们将这些文件的长度与原始页面的长度进行比较。
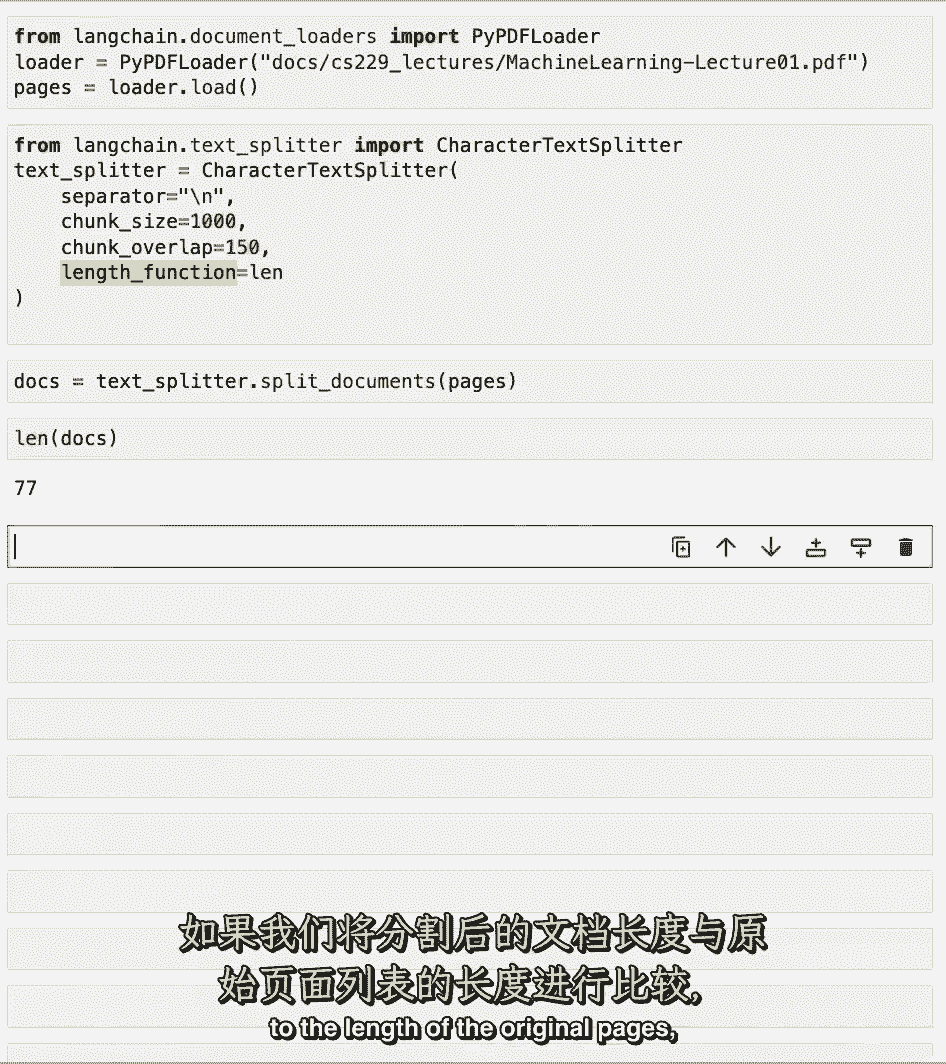
我们可以看到已经创建了更多的文档。
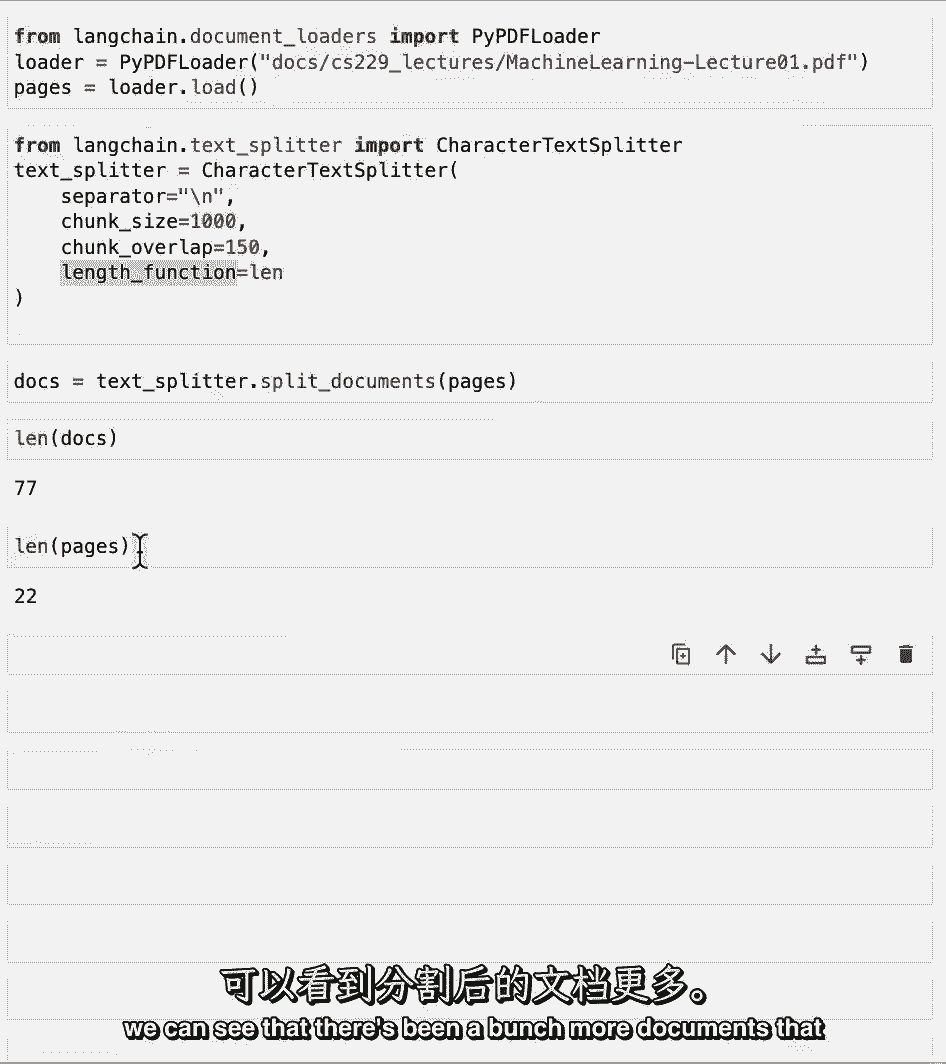
因为这种分裂,我们也可以用我们在第一节课中使用的db概念来做类似的事情。

并再次比较原始文档和新拆分文档的链接。

我们可以看到我们有更多的文件,现在我们已经做了所有的分裂,这是一个很好的点暂停视频和尝试一些新的例子到目前为止。

我们已经根据角色做了所有的拆分,但还有另一种方法,这是基于代币,为此,让我们导入令牌文本拆分器。

这之所以有用,是因为lms通常有上下文窗口,由令牌计数指定的,因此,了解代币是什么以及它们出现在哪里是很重要的,然后我们可以在他们身上分头行动,对LLM如何看待他们有一个更有代表性的想法。
为了真正了解代币和字符之间的区别,让我们初始化令牌文本拆分器,块大小为1,块重叠为零,因此,这将把任何文本拆分为相关令牌的列表,让我们创建一个有趣的编造文本。
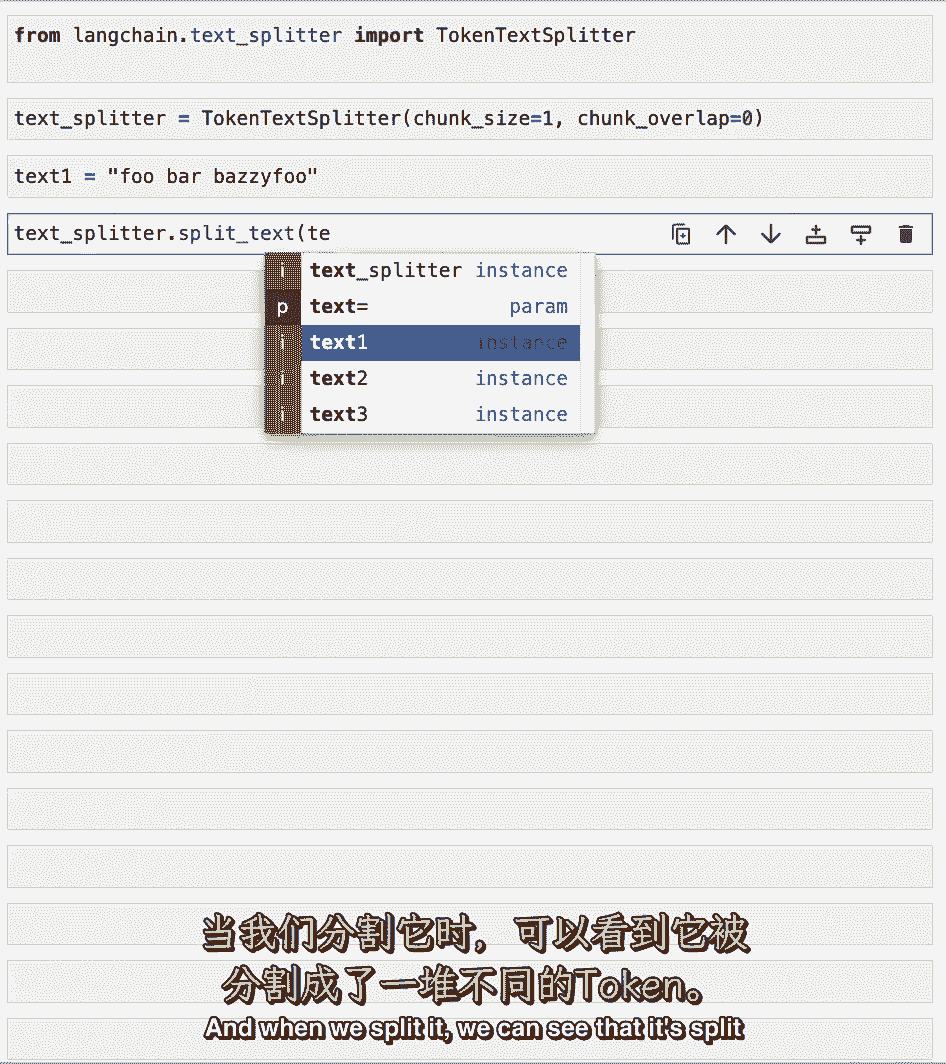
当我们分开的时候,我们可以看到它分裂成一堆不同的代币,它们的长度都有点不同,其中的字符数,所以第一个就是foo,然后你有一个空间,然后是酒吧,然后你在B中有一个空格,然后是一个Z,然后是z。
然后是foo,这显示了在字符上拆分和在令牌上拆分之间的一点区别,让我们将此应用于上面加载的文档,以类似的方式,以类似的方式,我们可以调用页面上的拆分文档。

如果我们看一下第一份文件,我们有了新的拆分文档,页面内容大致是标题,然后我们得到了源的元数据和它来自的页面,您可以在这里看到源的元数据,块中的页面与原始文档中的页面相同,所以如果我们看看。
只是为了确保第0页,元数据,我们可以看到它是一字排开的,这很好,它将元数据适当地传递到每个块,但也有一些情况,您实际上希望向块添加更多的元数据,当你把它们分开的时候,这可以包含文档中的位置等信息。
这一大块来自,它在哪里,相对于文档中的其他事物或概念,一般来说,这些信息可以在回答问题时使用,提供更多关于这个块到底要看什么的上下文,这方面的一个具体例子,让我们看看另一种类型的文本拆分器。
它实际上将信息添加到每个块的元数据中,您现在可以暂停并尝试您想出的几个示例。

此文本拆分器是标记头文本拆分器,它会做的是,它将根据标头或任何子标头拆分标记文件,然后我将把这些标题作为内容添加到元数据字段中,这将被传递给任何源于这些分裂的块。

让我们先做一个玩具示例,然后玩一下文档,我们有一个标题,然后是第一章的副标题,然后我们得到了一些句子,然后是一个更小的子标题的另一部分。
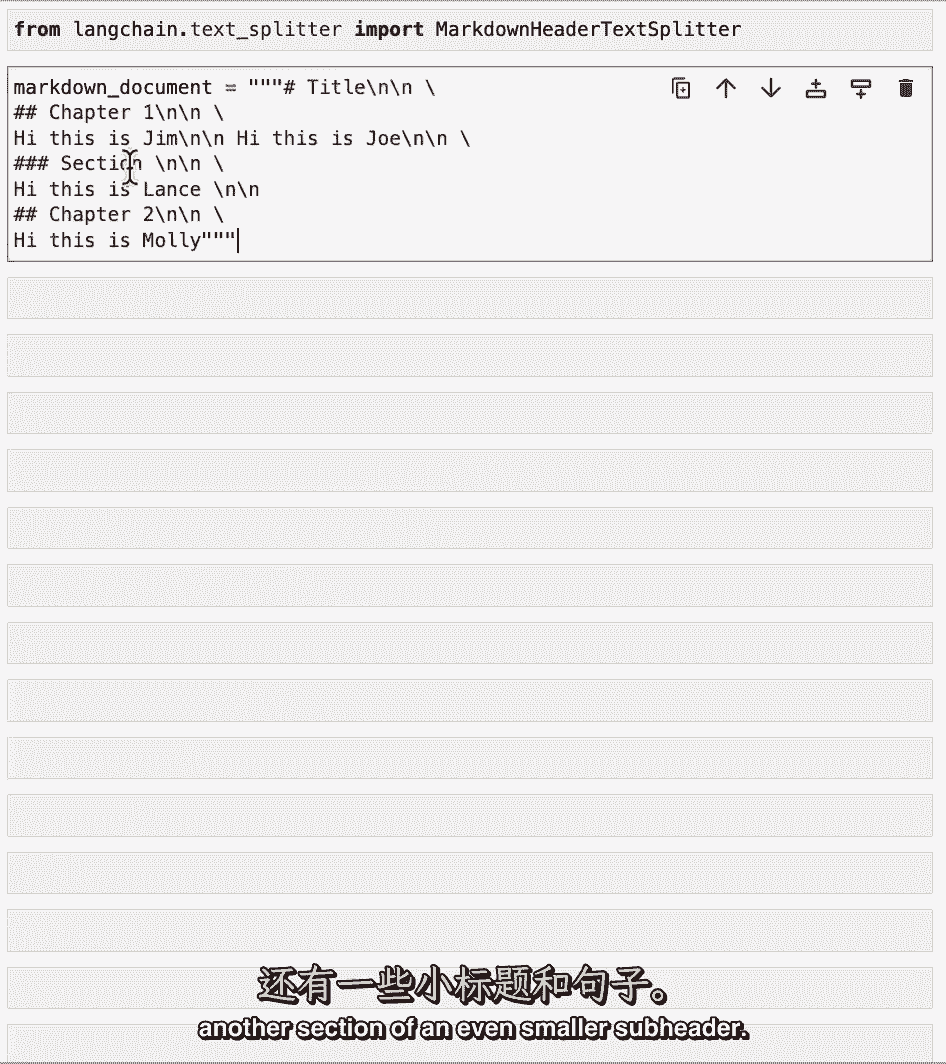
然后我们跳回到第二章,在那里的一些句子中,让我们定义一个要拆分的标题列表,那些标题的名字,首先我们有一个标签我们称它为标题一,然后我们有两个标签标题二,三个标签标题三。

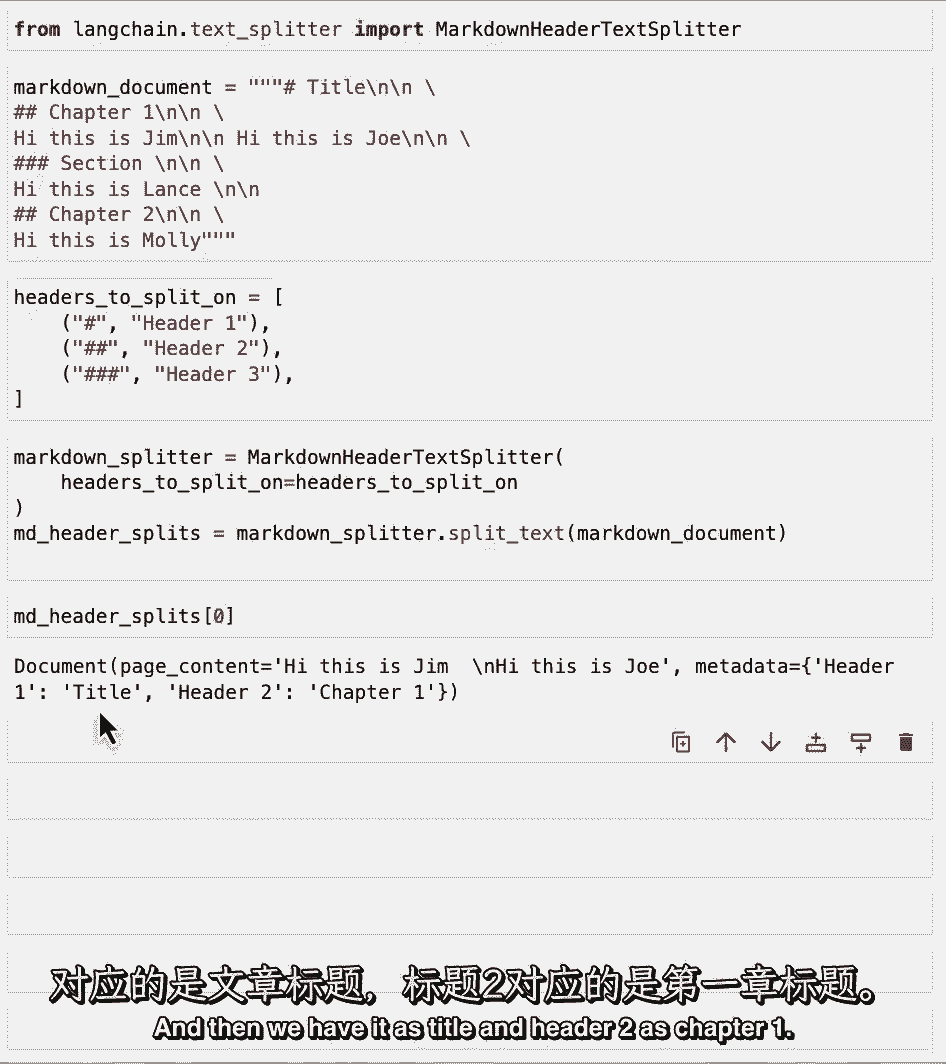
然后,我们可以用这些标头初始化markdown标头文本拆分器,然后拆分我们上面的玩具示例,如果我们看几个例子,我们可以看到第一个有内容嗨,我是吉姆嗨,我是乔,现在在元数据中,我们有标题一。
然后我们把它作为标题和标题二作为第一章。
这是从这里传来的。
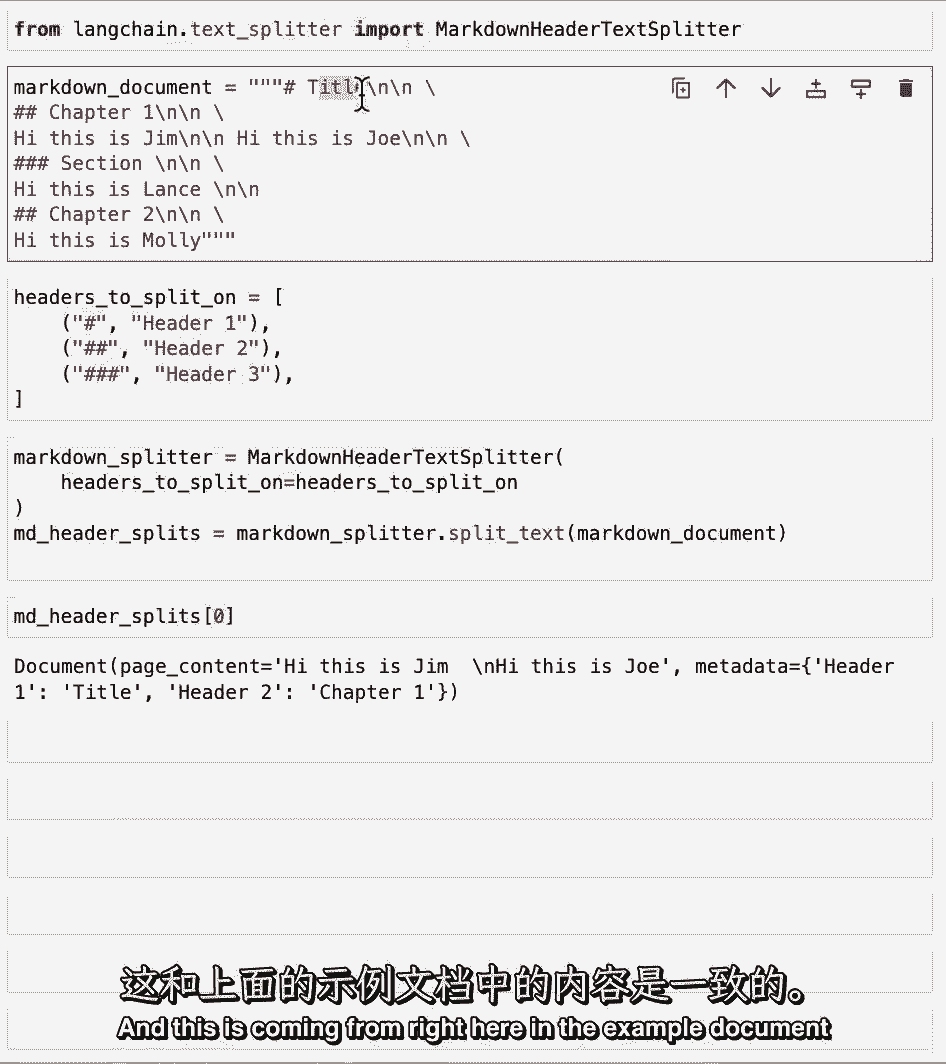
在上面的示例文档中,让我们来看看下一个,我们可以看到这里我们跳到了一个更小的部分,所以我们得到了嗨的内容,我是兰斯,现在我们不仅有头球,也是头球二,也是头球三,这又一次来自内容和名称。
在上面的降价文档中。

让我们在一个现实世界的例子中尝试一下,在我们使用concept目录加载器加载concept目录之前,它加载了文件来标记。

与标记标头拆分器相关,所以让我们加载这些文档,然后将标头为1的markdown拆分器定义为单个标签,标题二作为双重标签。

我们对文本进行拆分,如果我们看一下它们,我们就会得到拆分。
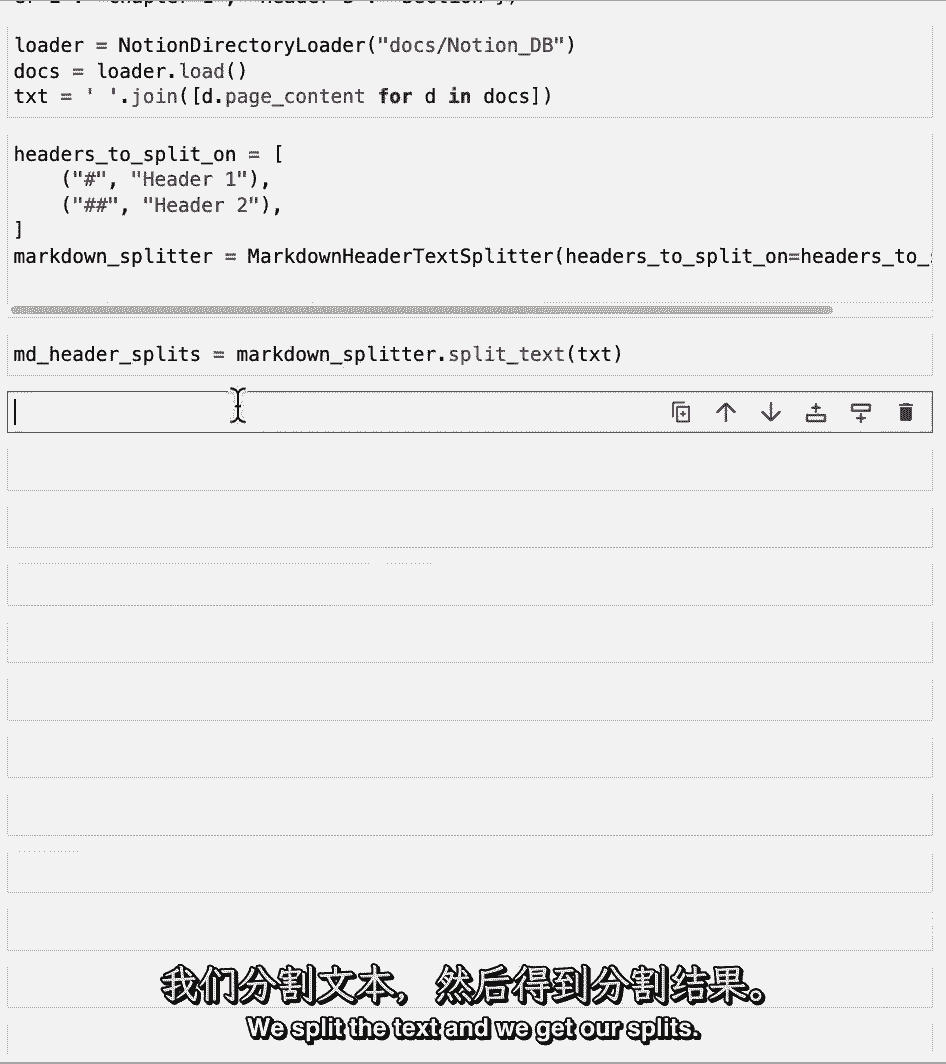
我们可以看到第一个有一些页面的内容,现在如果我们向下滚动到元数据,我们可以看到,我们已经加载了标题一作为blendel的员工手册,我们现在已经讨论了如何使用适当的元数据获得语义上相关的块。
下一步是将这些数据块移动到向量存储中。
【LangChain大模型应用开发】DeepLearning.AI - P12:4——向量和嵌入 - 吴恩达大模型 - BV1iZ421M79T

我们现在把文件分成了小的,语义有意义的块,是时候把这些块放入索引中了,在那里我们可以很容易地找回它们,当需要回答关于这个数据库的问题时,我们将利用嵌入和矢量存储,让我们看看这些是什么。
我们在上一节课中简要介绍过,但我们将重新审视它,原因有几个。
第一批,这些对于在数据上构建聊天机器人非常重要。
第二,我们要深入一点,我们将讨论边缘情况,这个通用方法实际上可能失败的地方。
别担心,我们以后会解决的,但现在让我们讨论矢量存储和嵌入。
这是在文本拆分之后出现的,当我们准备好以易于访问的格式存储文档时,什么是嵌入。
他们拿了一条短信,他们创建了文本的数字表示。

具有相似内容的文本将在此数字空间中具有相似的向量。

意思就是,然后我们可以比较这些向量,找到相似的文本片段。

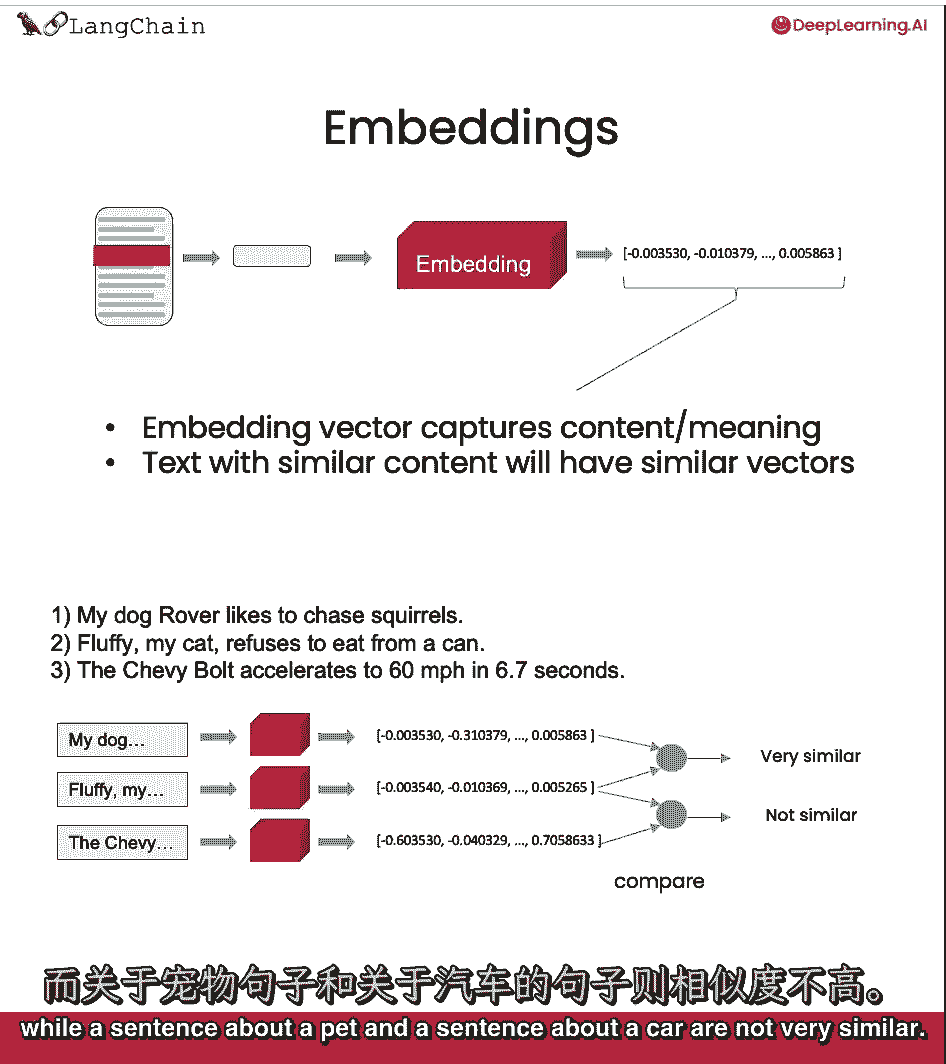
所以在下面的例子中,我们可以看到这两个关于宠物的句子非常相似。
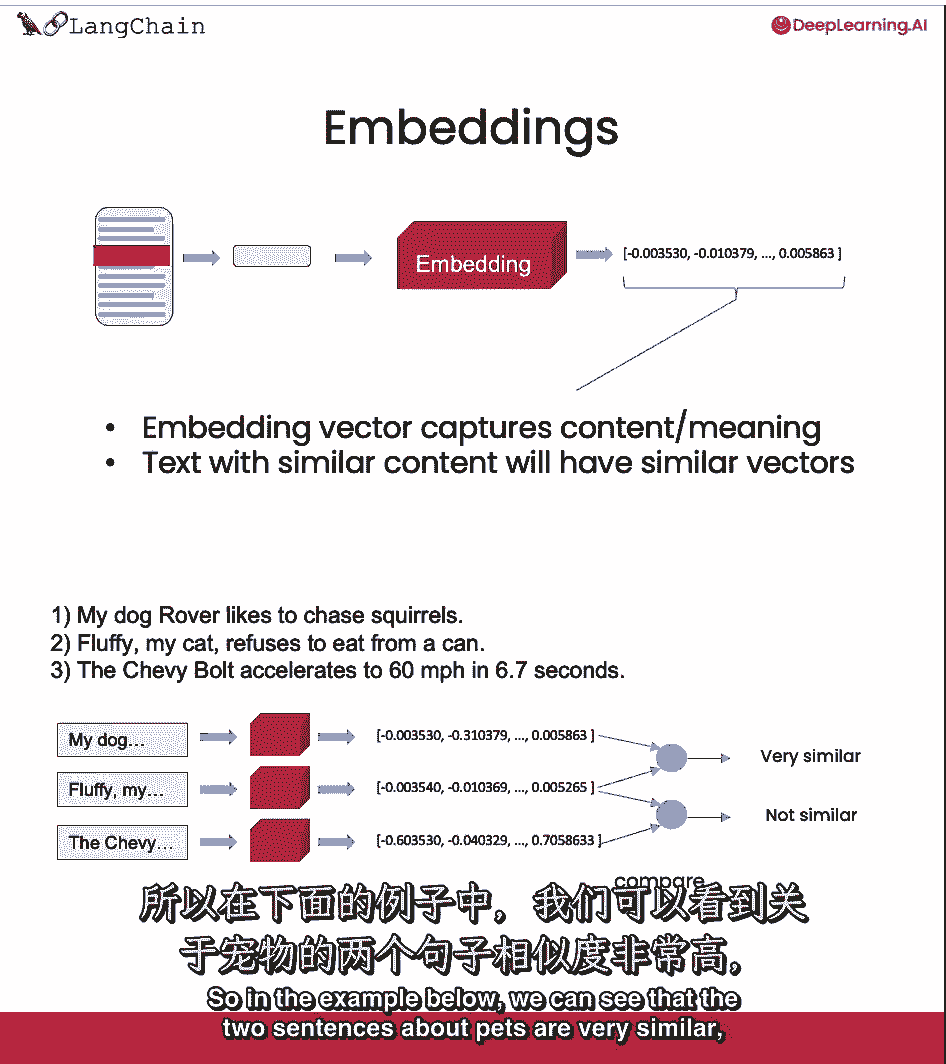
而关于宠物的句子和关于汽车的句子不是很相似。
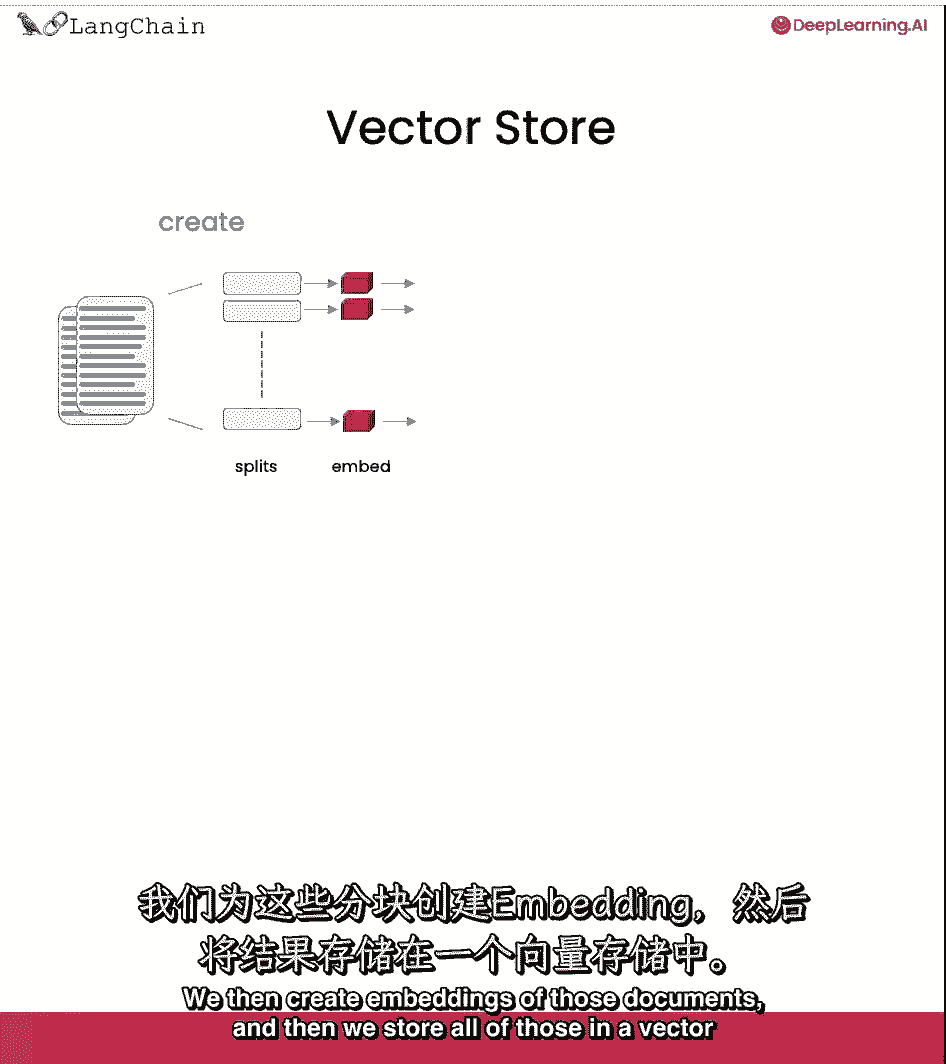
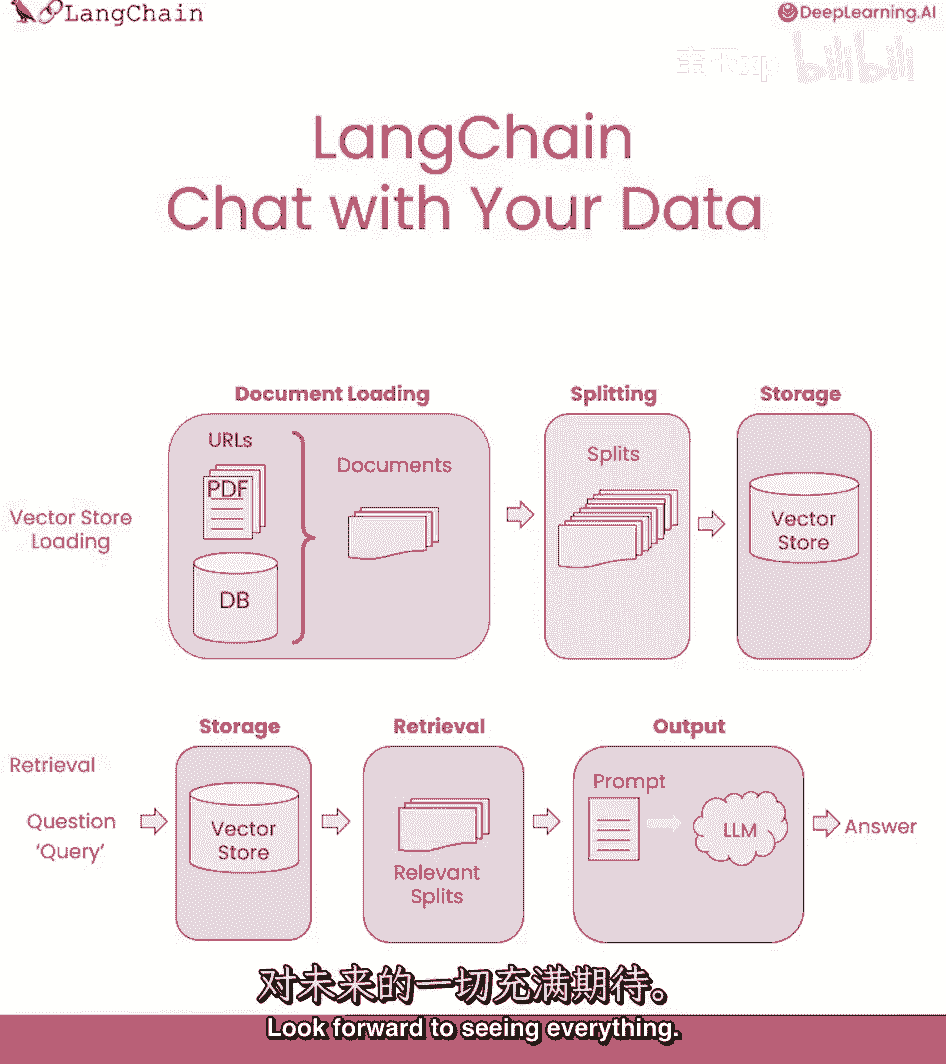
作为完整端到端工作流的提醒,我们从文件开始。

然后我们创建这些文档的较小拆分,然后我们创建这些文档的嵌入。
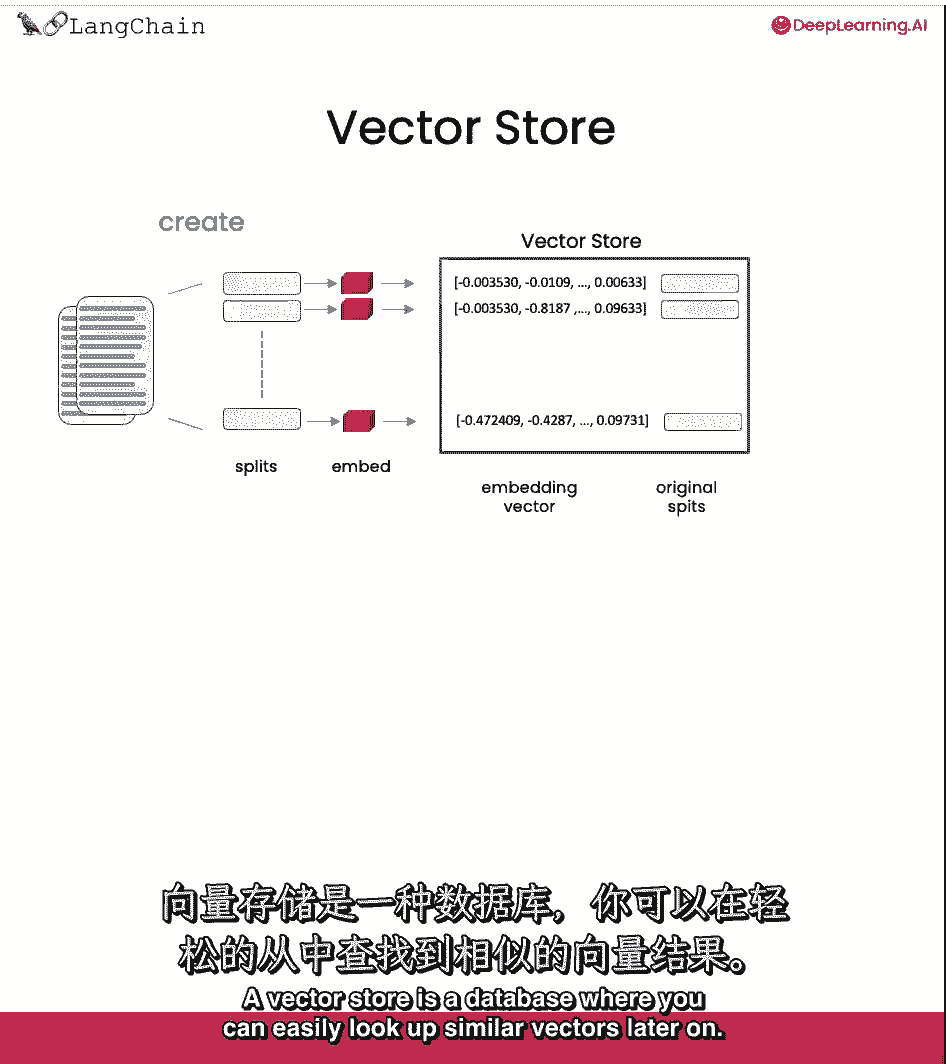
然后我们把所有这些都存储在向量存储中,向量存储是一个数据库,您以后可以在其中轻松地查找类似的向量。
当我们试图找到与手头问题相关的文档时,这将变得有用。
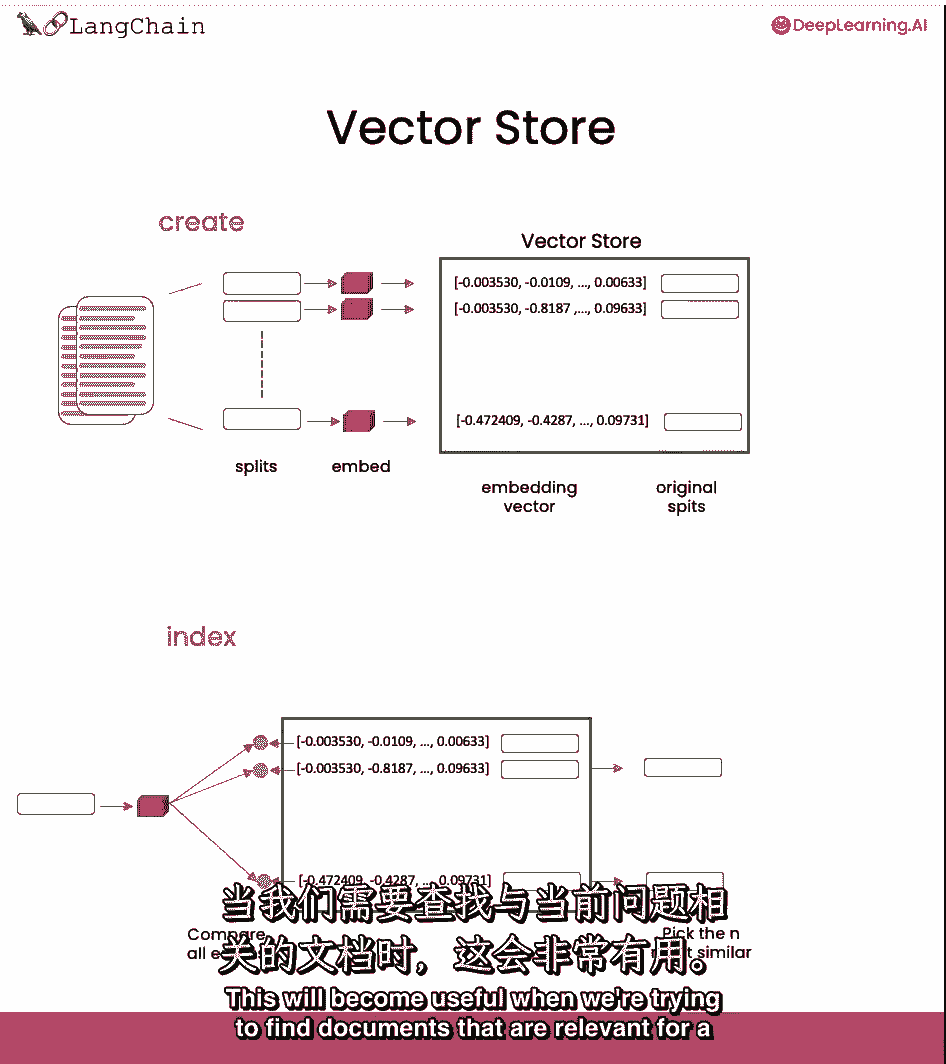
然后我们就可以回答手头的问题了,创建嵌入,然后与向量存储中的所有不同向量进行比较。
然后挑出最相似的末端,然后,我们把这些和大多数相似的块,把它们和问题一起传递给LLM,得到一个答案。
我们稍后会讨论所有这些,现在是深入研究嵌入和矢量存储本身的时候了。
开始,我们将再次设置适当的环境变量。

从现在开始我们要处理同一套文件,这些是CS二十九节课,我们要装载,这里有几个,请注意,我们实际上要复制,第一讲,这是为了模拟一些脏数据。
加载文档后,然后,我们可以使用递归字符文本拆分器来创建块。

我们可以看到我们现在已经创造了200多个不同的块,是时候进入下一个部分并为所有这些创建嵌入了。

在跳入真实世界的示例之前,我们将使用openai来创建这些嵌入。

让我们用几个玩具测试用例来尝试一下。

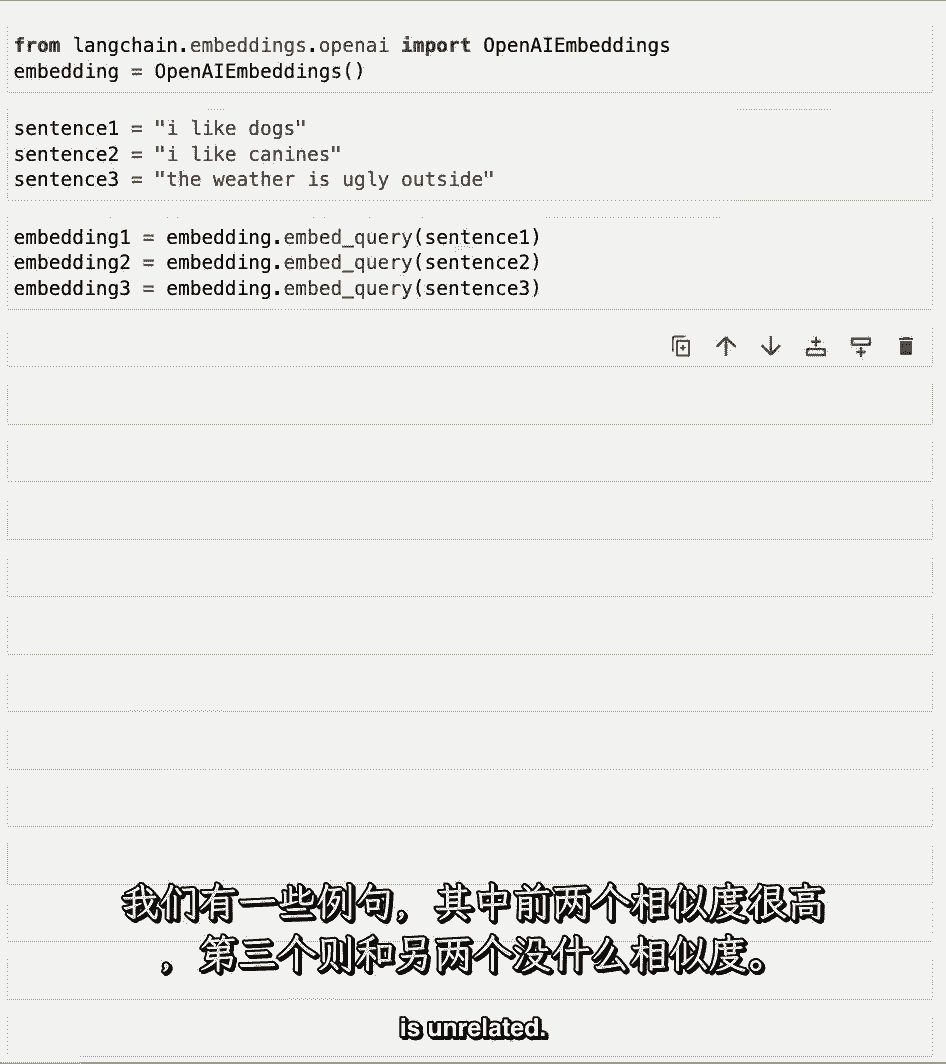
只是为了了解引擎盖下发生了什么,我们有几个例句,其中前两个非常相似。

第三个是没有关系的。
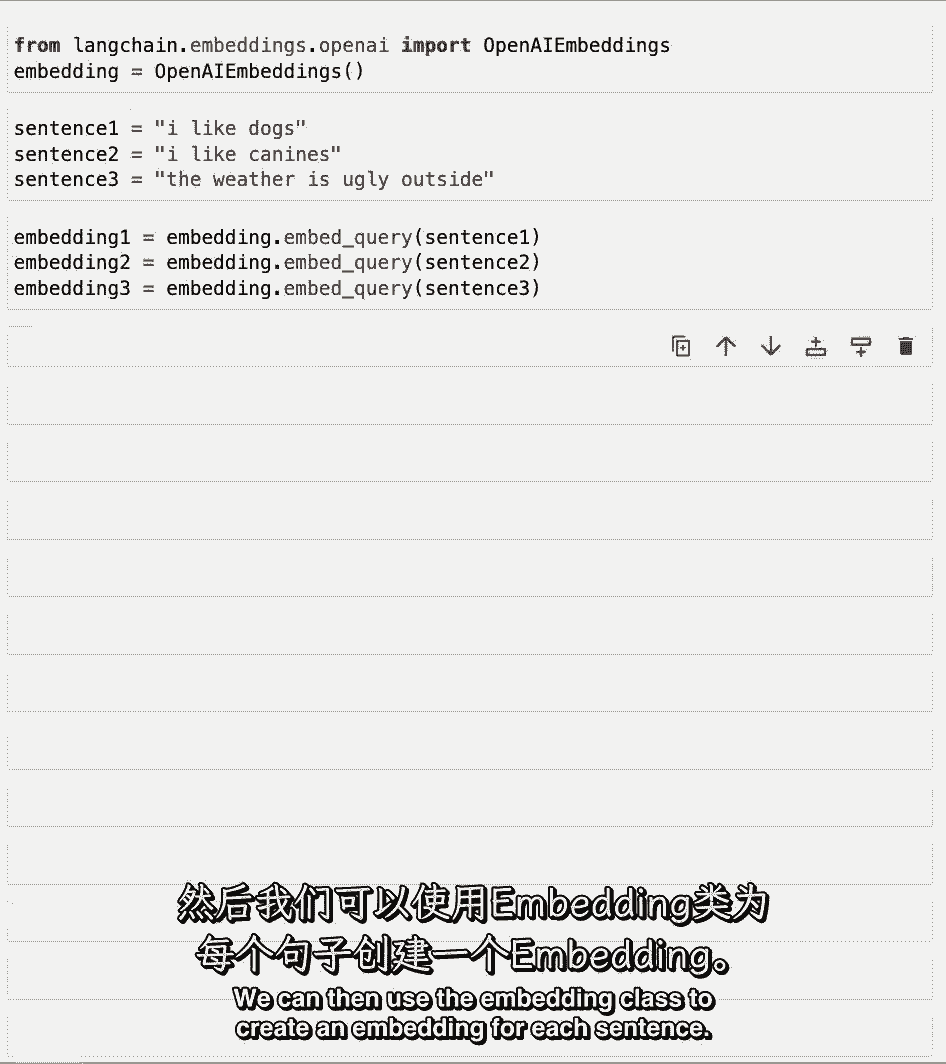
然后,我们可以使用嵌入类为每个句子创建嵌入。
然后我们可以使用Numpy来比较它们,看看哪些是最相似的。

我们期望前两句应该非常相似,然后第一个和第二个与第三个相比不应该几乎相似。

我们将使用点积来比较两个嵌入。
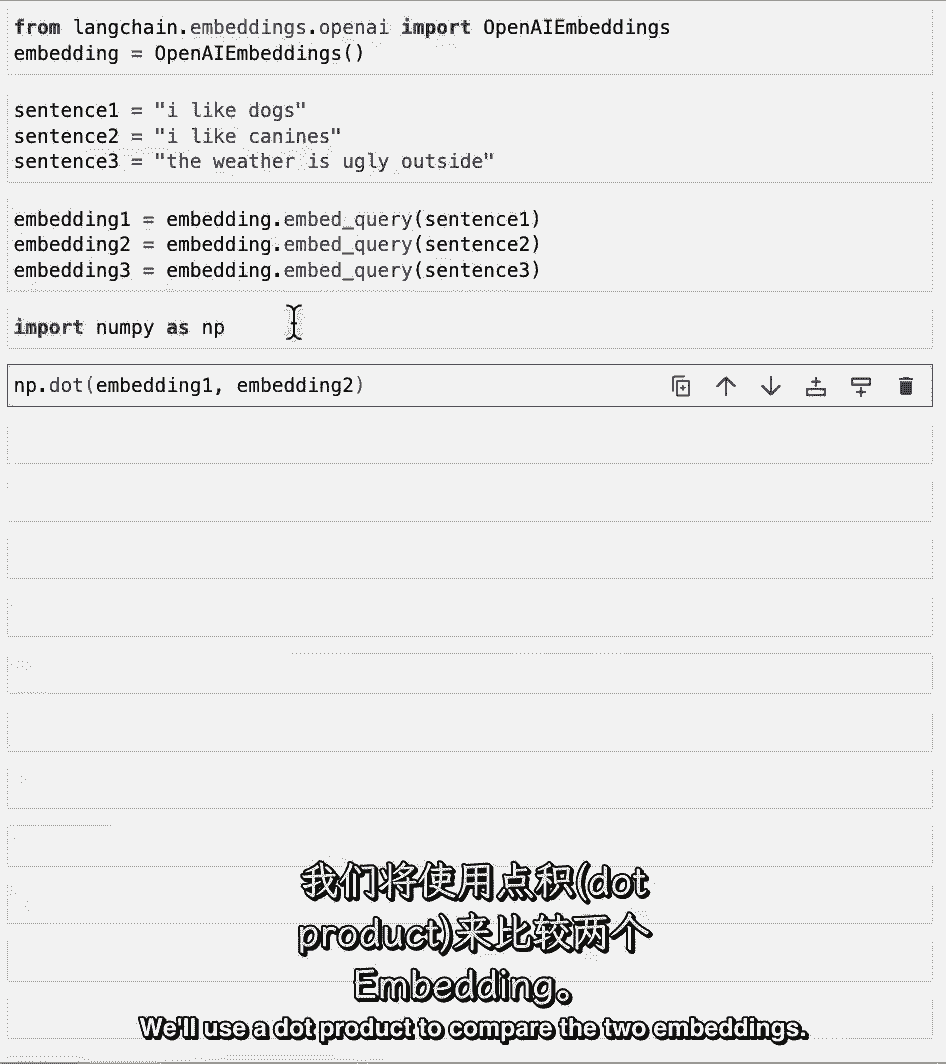
如果你不知道什么是点积,那很好,重要的是要知道越高越好。

这里,我们可以看到前两个嵌入有一个相当高的分数点9。6。

如果我们将第一个嵌入与第三个嵌入进行比较。

我们可以看到它在点七明显较低,如果我们把第二个和第三个比较。

我们可以看到它是正确的大约在点七六。

现在是停顿一下,尝试一下你自己的句子的好时机,看看点积是什么。

现在让我们回到现实世界的例子,现在是为PDF的所有块创建嵌入的时候了。

然后把它们储存在一个矢量中,存储我们将在本课中使用的向量存储是色度,所以让我们导入莱恩链,它与30多个不同的矢量商店集成在一起。

我们选择色度是因为它在内存中是轻量级的。

这使得它很容易站起来开始。

还有其他Vector商店提供托管解决方案,当您试图持久保存大量数据时,这可能很有用,或持久存在于云存储中。

我们要把这个矢量存储保存在某个地方,这样我们就可以在以后的课程中使用它。

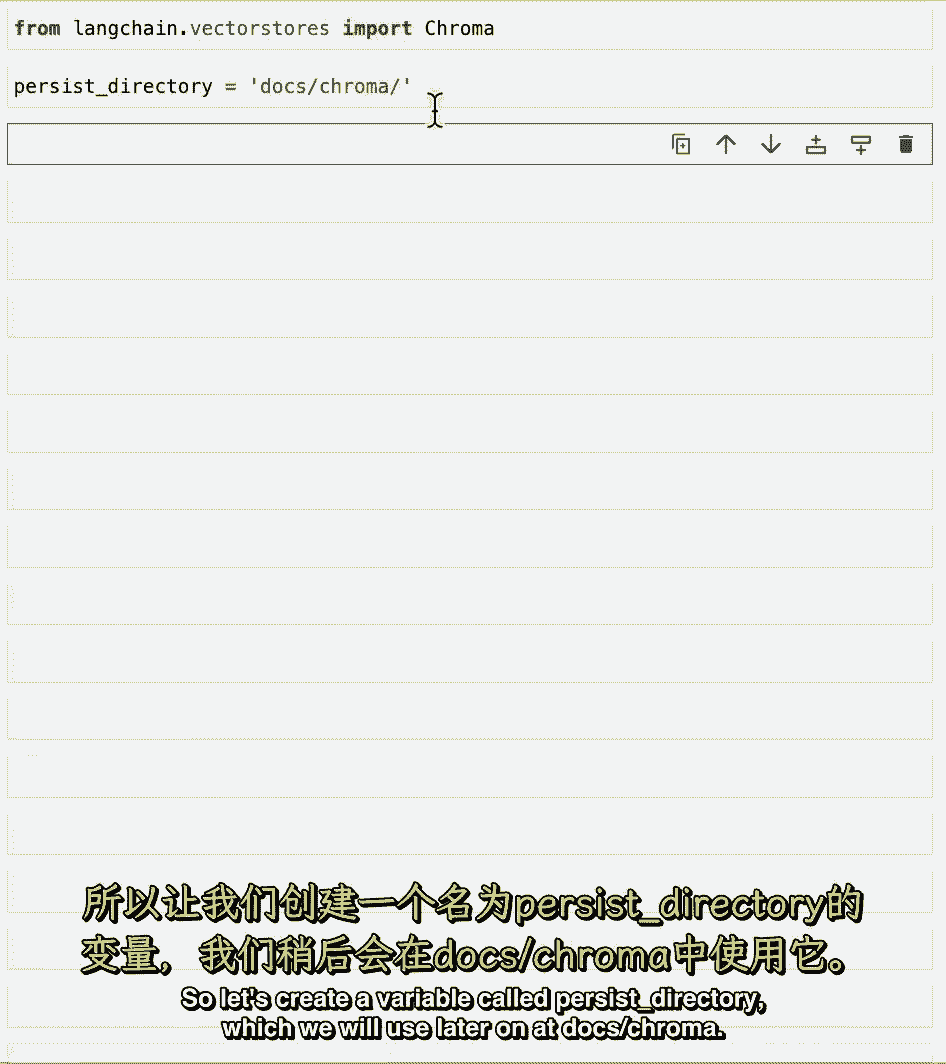
因此,让我们创建一个名为持久化目录的变量,我们将在稍后的《色度博士》中使用。
我们也要确保那里什么都没有。

如果那里已经有东西了,它可以把东西扔掉,我们不希望这种情况发生。

所以让我们rm破折号rf文档色度,只是为了确保那里什么都没有。

现在让我们创建向量存储,所以我们从以分裂方式传递的文档中调用色度,这些是我们之前创建的分裂传递和嵌入。
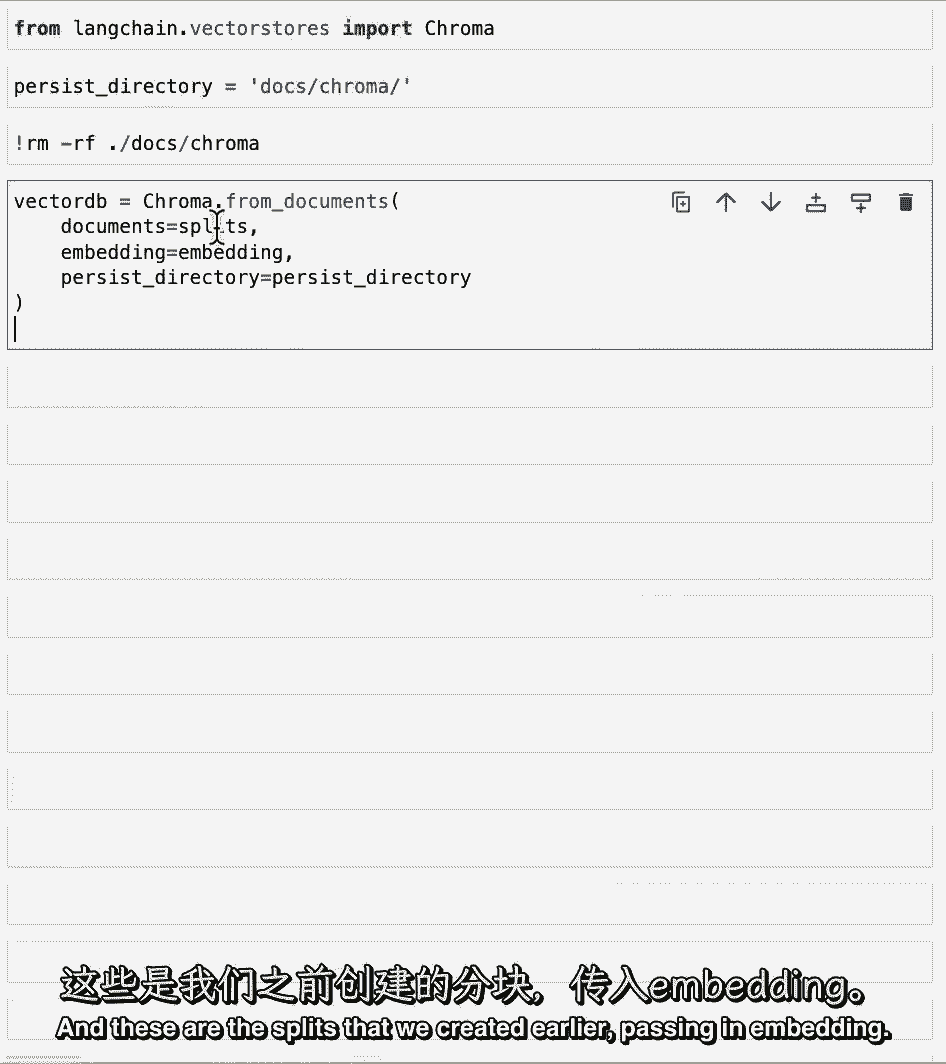
这是开放的AI嵌入模型,然后传入持久化目录,它是一个特定于色度的关键字参数,允许我们将目录保存到磁盘。
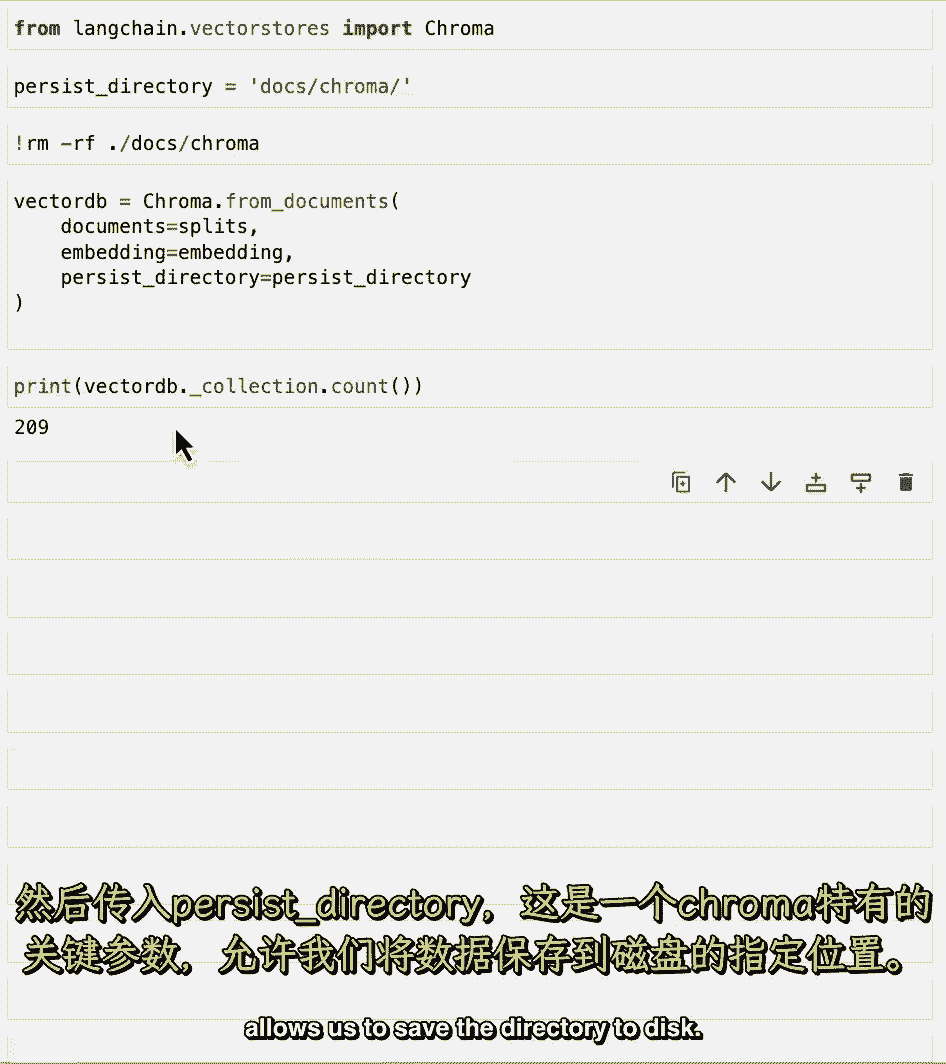
如果我们看看收集数,做完这个之后,我们可以看到它是二百零九,这和我们之前的分裂次数一样。

让我们现在开始使用它,让我们想一个问题,我们可以问这个数据,我们知道这是关于一个课堂讲座。

所以让我们问问是否有任何电子邮件可以寻求帮助,如果我们在课程或材料或类似的事情上需要任何帮助。

我们将使用相似搜索法,我们将通过这个问题,然后我们也通过k等于三,这指定了我们要返回的文档数。

所以如果我们运行它,我们看看文档的长度,所以我们可以看到它是我们指定的三个。

如果我们看看第一份文件的内容。

我们可以看到它实际上是关于一个电子邮件地址,CS二二九破折号QA CS,斯坦福,Edu,这是我们可以发送问题的电子邮件,所有的助教都读了,这样做之后,让我们确保保持向量数据库。
以便我们可以在以后的课程中使用它,通过运行向量db点持久化。

这涵盖了语义搜索的基础知识,并向我们展示了我们可以仅仅基于嵌入就得到相当好的结果。

但它并不完美,在这里,我们将讨论一些边缘案例,并展示它可能失败的地方。

让我们尝试一个新问题,他们怎么说matlab,让我们运行这个指定k等于五的程序,并得到一些结果。

如果我们看看前两个结果,我们可以看到它们实际上是相同的,这是因为当我们加载PDF时,如果你还记得我们故意指定,重复条目,这很糟糕,因为我们在两个不同的块中得到了相同的信息。
我们将把这两个块传递给语言模型,第二条信息没有真正的价值,如果有一个不同的,语言模型可以从中学习的不同块,我们下节课要讲的一件事,如何同时检索相关和不同的块,这是另一种类型的故障模式,也可能发生。

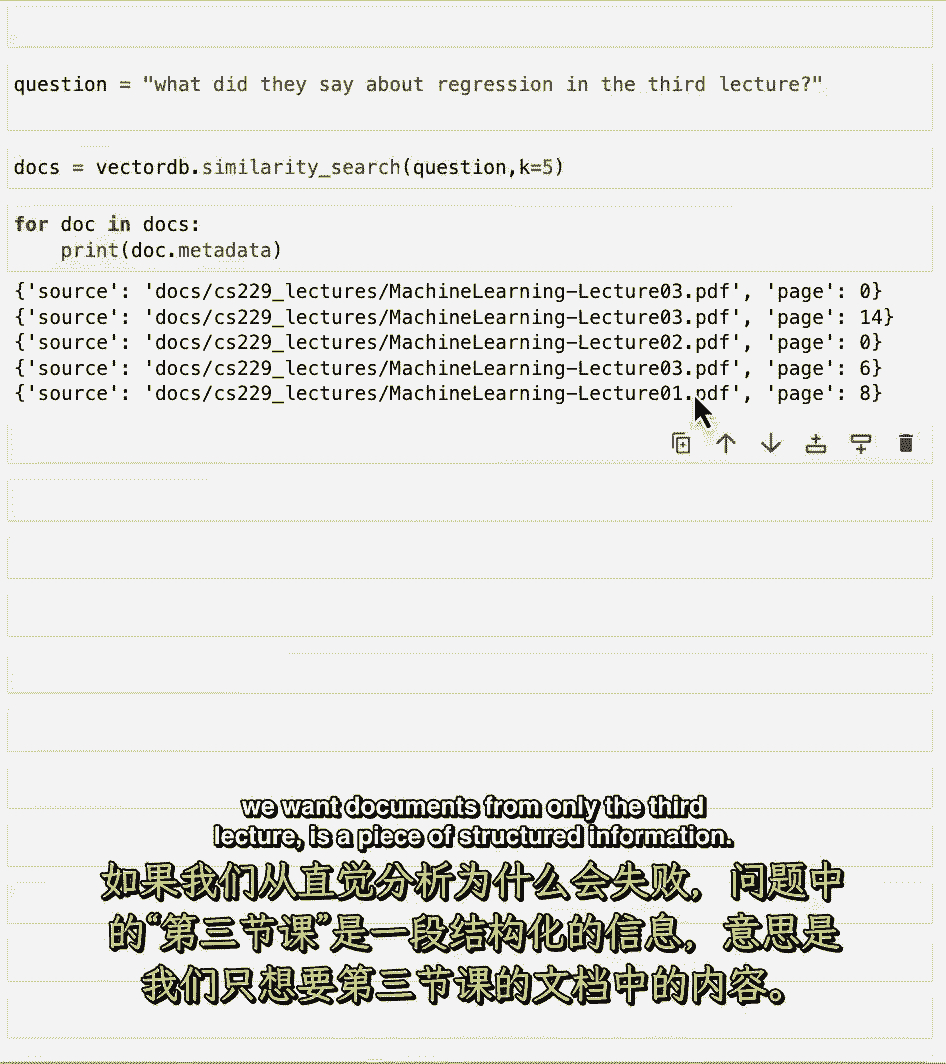
让我们来看看这个问题,他们在第三堂课上对回归说了什么。

当我们拿到文件的时候,直觉上,我们希望他们都是第三讲的一部分。

我们可以检查这一点,因为我们在元数据中有关于它们来自哪些讲座的信息。

因此,让我们循环所有文档并打印出元数据。

我们可以看到实际上有一个结果的组合。

第三讲的一些,有些是第二节课的,有些是第一节课的,关于为什么这是失败的直觉是,第三讲。

事实上,我们只需要第三堂课的文档,这是一个结构化的信息。
但我们只是在做一个基于嵌入的语义查找。
它为整个句子创建了一个嵌入。
它可能更专注于回归,因此,我们得到的结果可能与回归非常相关。

所以如果我们看看第五个,做第一堂课的那个,我们可以看到它确实,事实上,提及回归,所以它开始注意到这一点,但它没有意识到这样一个事实,它只应该查询第三堂课的文件,因为再一次,这是一个结构化的信息。
并没有真正完美地捕捉到,我们创建的语义嵌入,现在是暂停并尝试更多查询的好时机,你还能注意到出现了哪些边缘情况,你也可以玩改变K,检索的文档数,正如你可能已经注意到的,在本课中,我们先用了三个。
然后用了五个,你可以试着把它调整成你想要的任何东西,你可能会注意到,当你把它做大的时候,您将检索更多的文档,但结尾的文件可能不如开头的文件相关,现在我们已经介绍了语义搜索的基础知识,以及一些失效模式。
让我们继续下一节课。
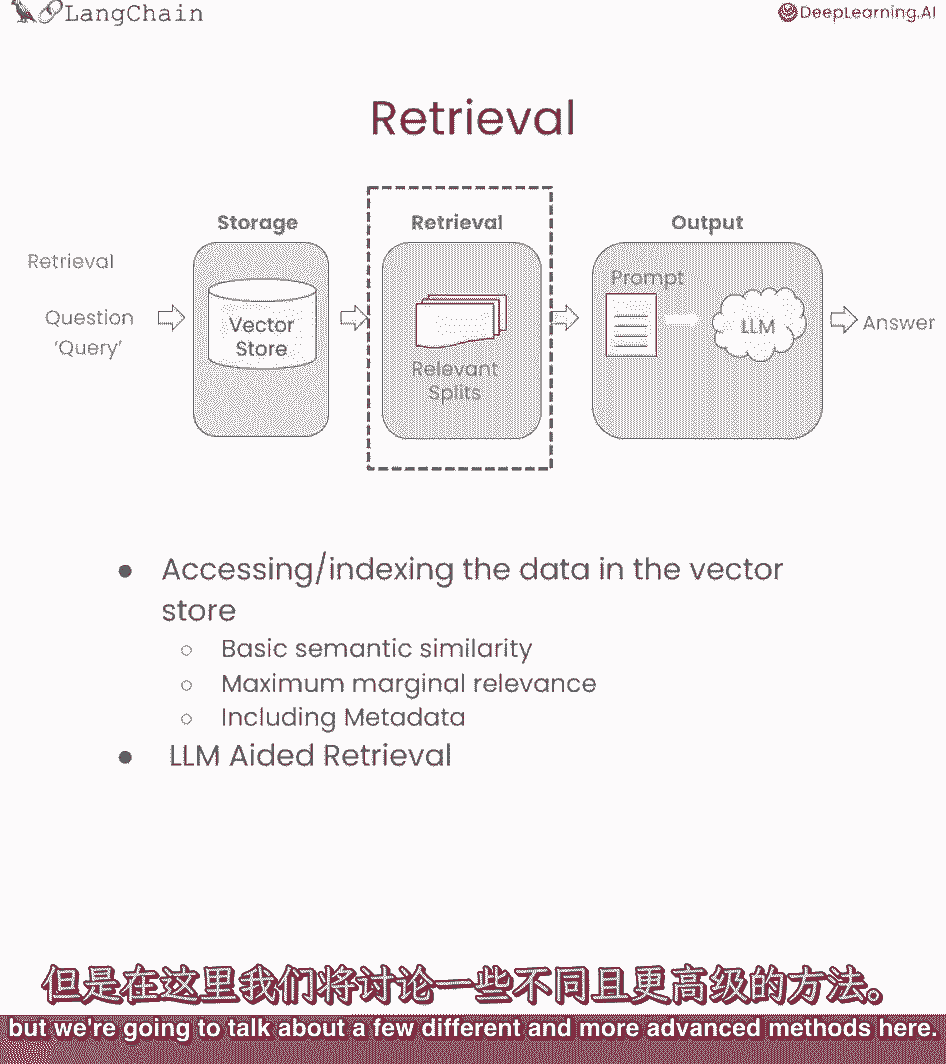
【LangChain大模型应用开发】DeepLearning.AI - P13:5——检索 - 吴恩达大模型 - BV1iZ421M79T

在上一课中,我们介绍了语义搜索的基础知识,并看到它在大量的用例中工作得很好,但我们也看到了一些边缘情况,看到了事情可能会出一点问题,在这节课中,我们将深潜回收,并介绍一些克服这些边缘情况的更先进的方法。
我真的很兴奋,因为我认为检索是一种新的东西,我们谈论的很多技术都出现了,在过去的几个月里,这是一个前沿的话题,所以你们将站在最前沿,我们找点乐子吧,在这节课中,我们将讨论检索,这在查询时很重要。
当您有一个查询进来时。
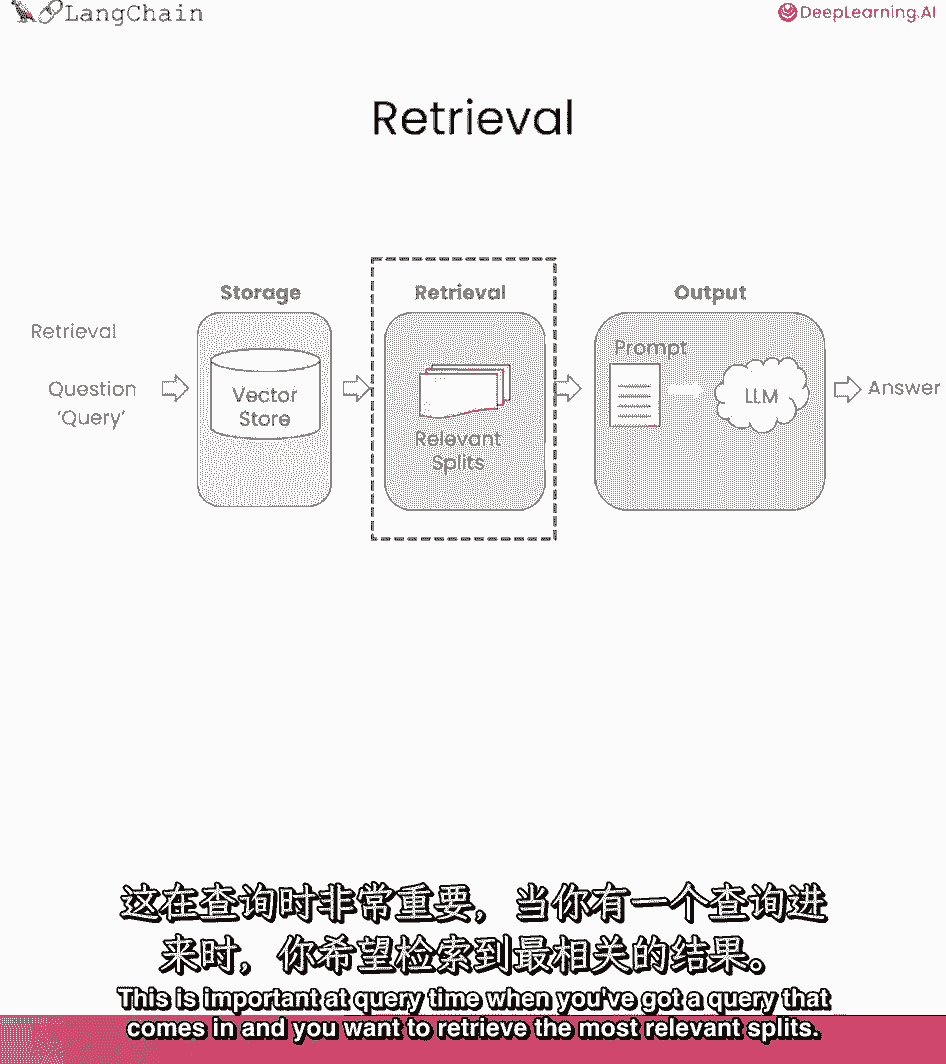
你想检索最相关的分裂。
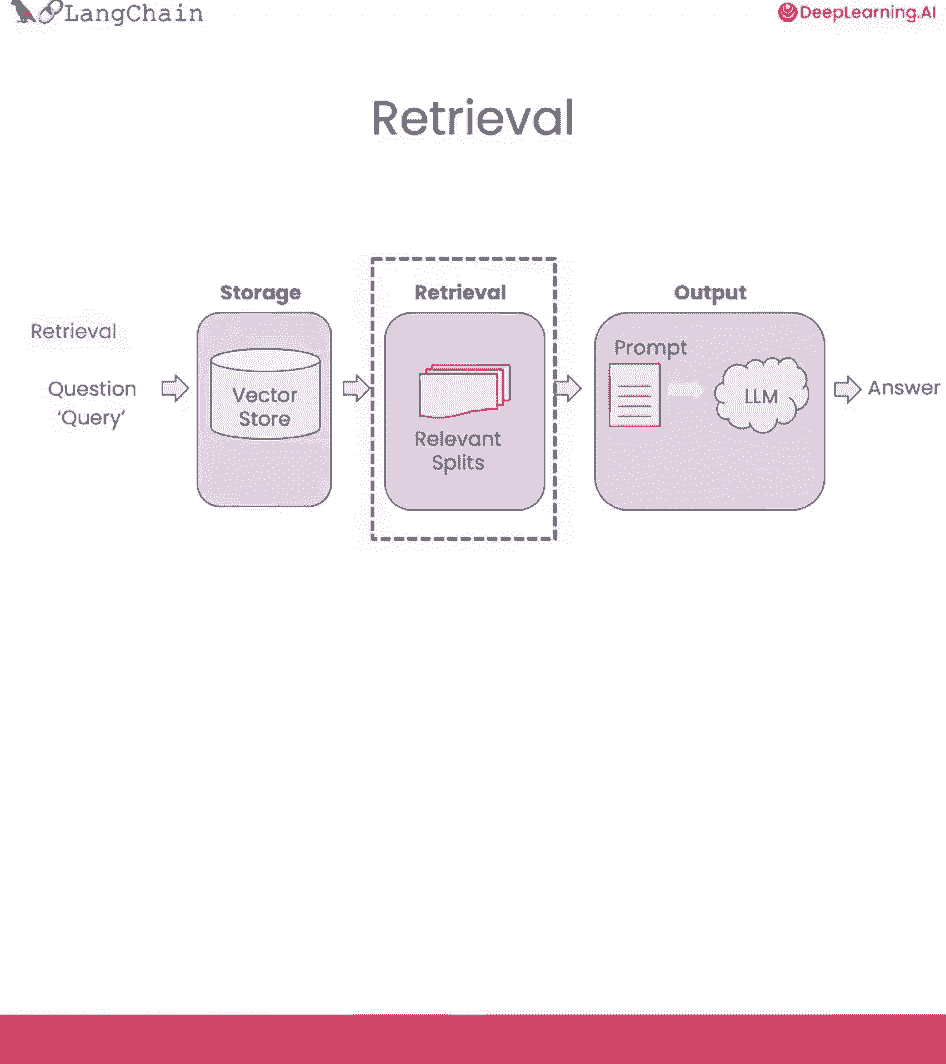
我们在上一课中谈到了语义相似性搜索,但我们将在这里讨论一些不同的、更先进的方法。
我们要讨论的第一个问题是最大边际相关性。

所以这背后的想法是。

如果您总是获取与查询最相似的文档,在嵌入空间中,你可能会错过不同的信息,就像我们在一个边缘案例中看到的那样。

在本例中。

我们有一个厨师问所有的白蘑菇,所以如果我们看看最相似的结果,这将是前两份文件,他们有很多类似于子实体查询的信息。

全身都是白的,但我们真的想确保我们也能得到其他信息。

比如它真的有毒,这就是mmr发挥作用的地方,因为它将为一组不同的文档选择。

mmr背后的想法是我们发送一个查询。

然后我们最初得到一组响应,取下划线k是我们可以控制的参数,为了确定我们得到了多少回应。

这完全基于语义相似性,从那里,然后,我们处理这组较小的文档,并优化。
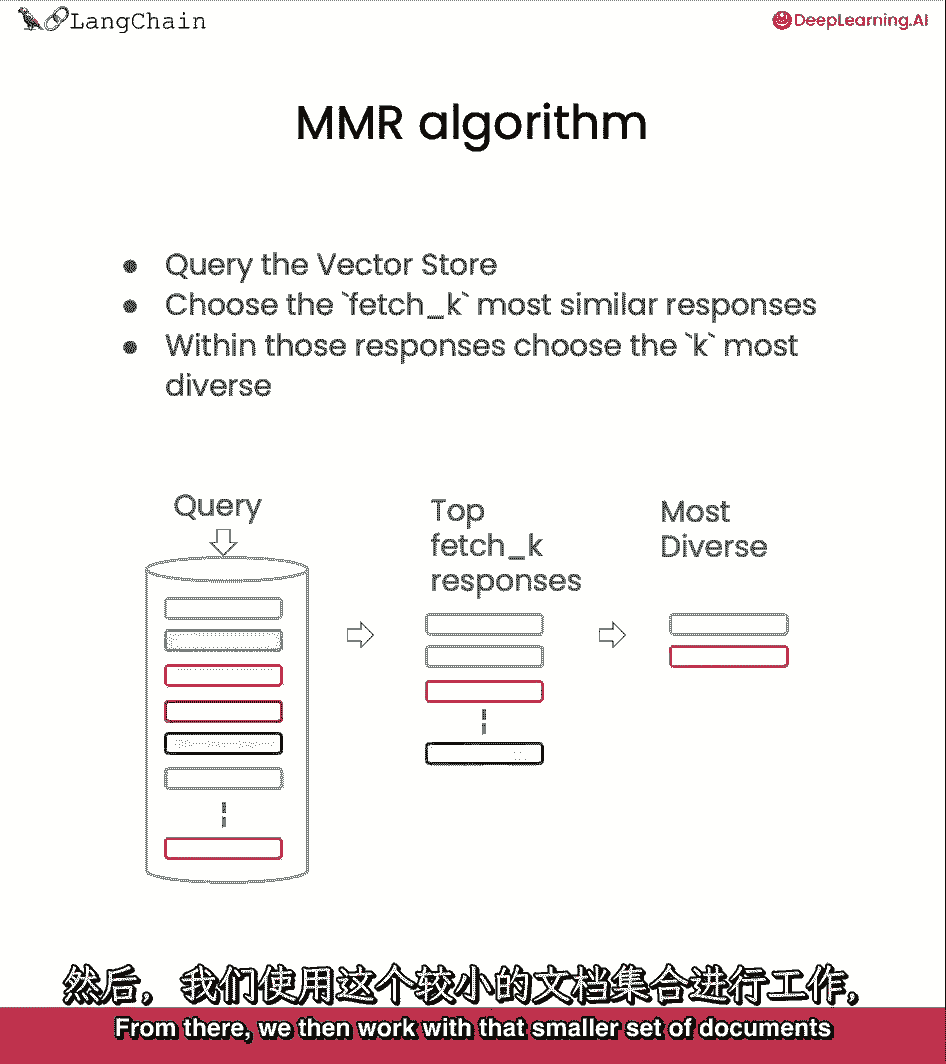
不仅是基于语义相似性的最相关的,但也有多样化的,从这组文档中,我们选择最后一个k返回给用户。

我们可以做的另一种类型的检索是我们所说的自我查询。
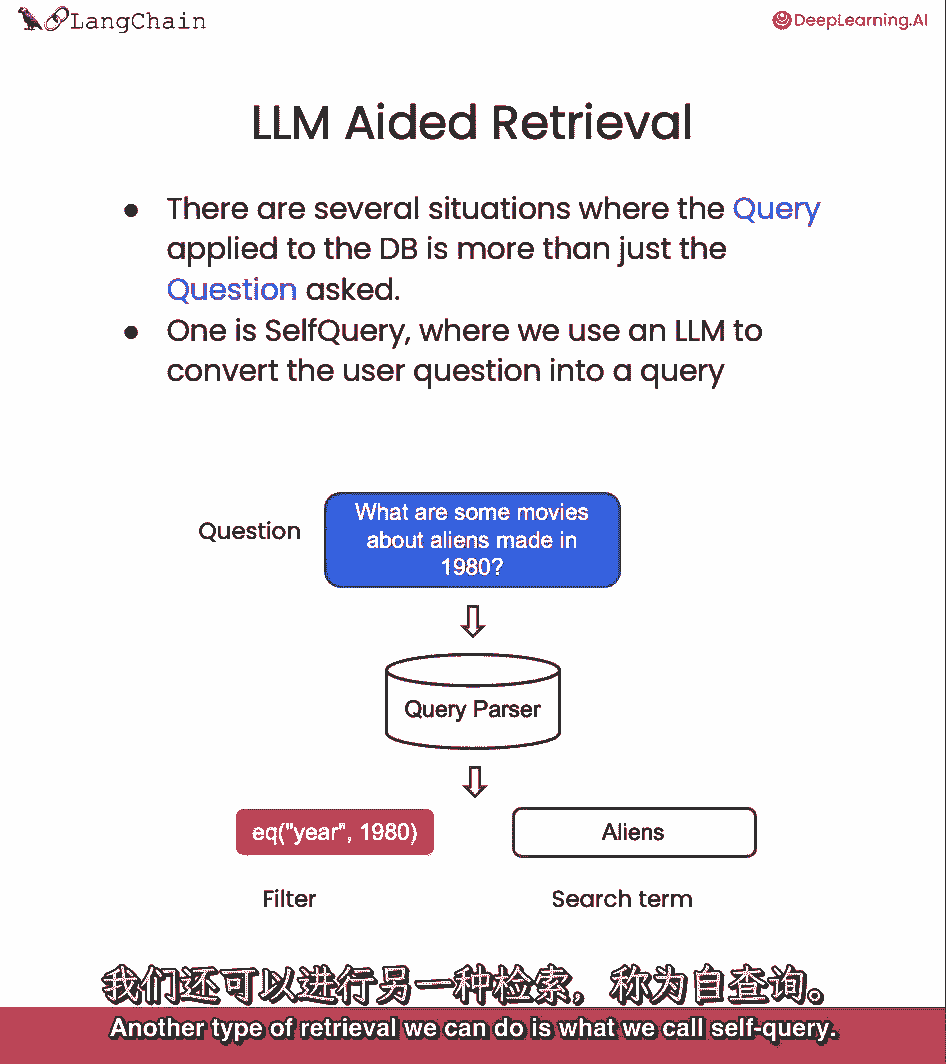
因此,当你遇到问题时,这很有用,这些问题不仅仅是关于,要从语义上查找的内容。
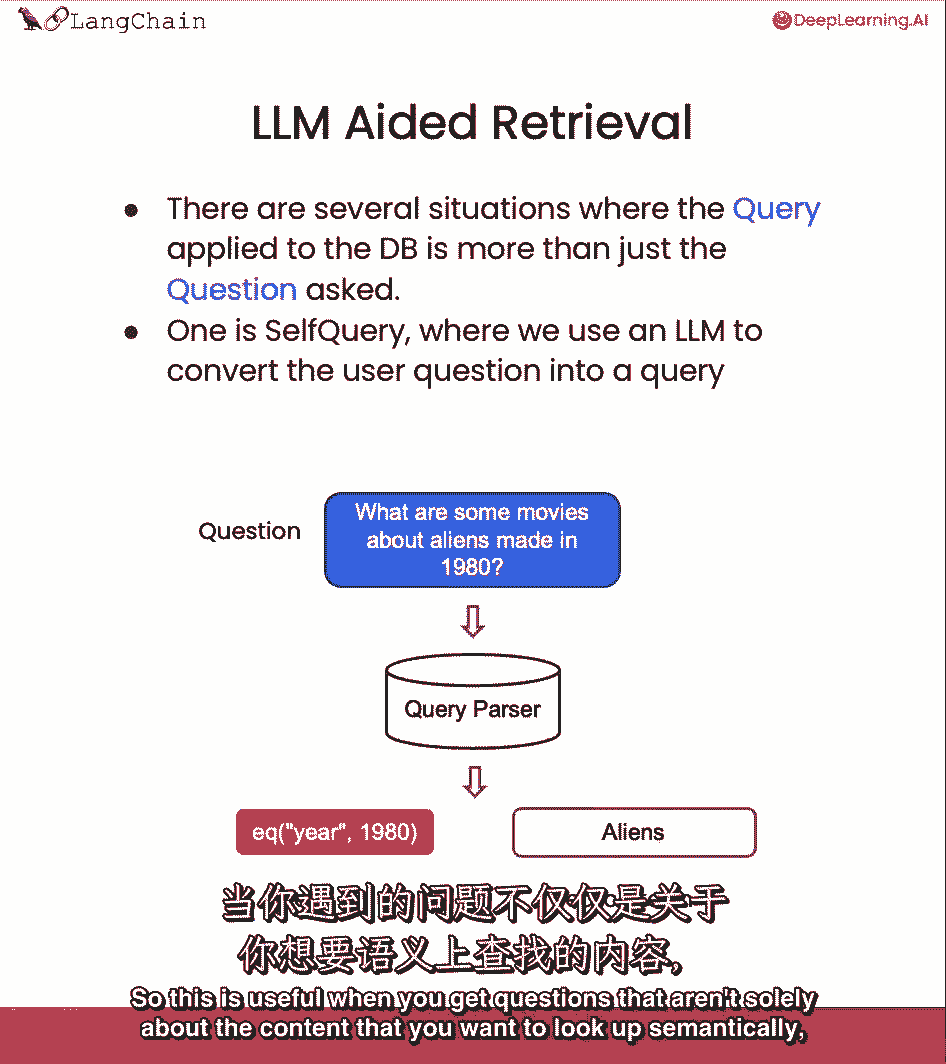
但也要提到一些要对其进行筛选的元数据,所以让我们来回答这个问题,1980年拍的关于外星人的电影有哪些?这真的有两个组成部分,它有一个语义部分,外星人咬了。
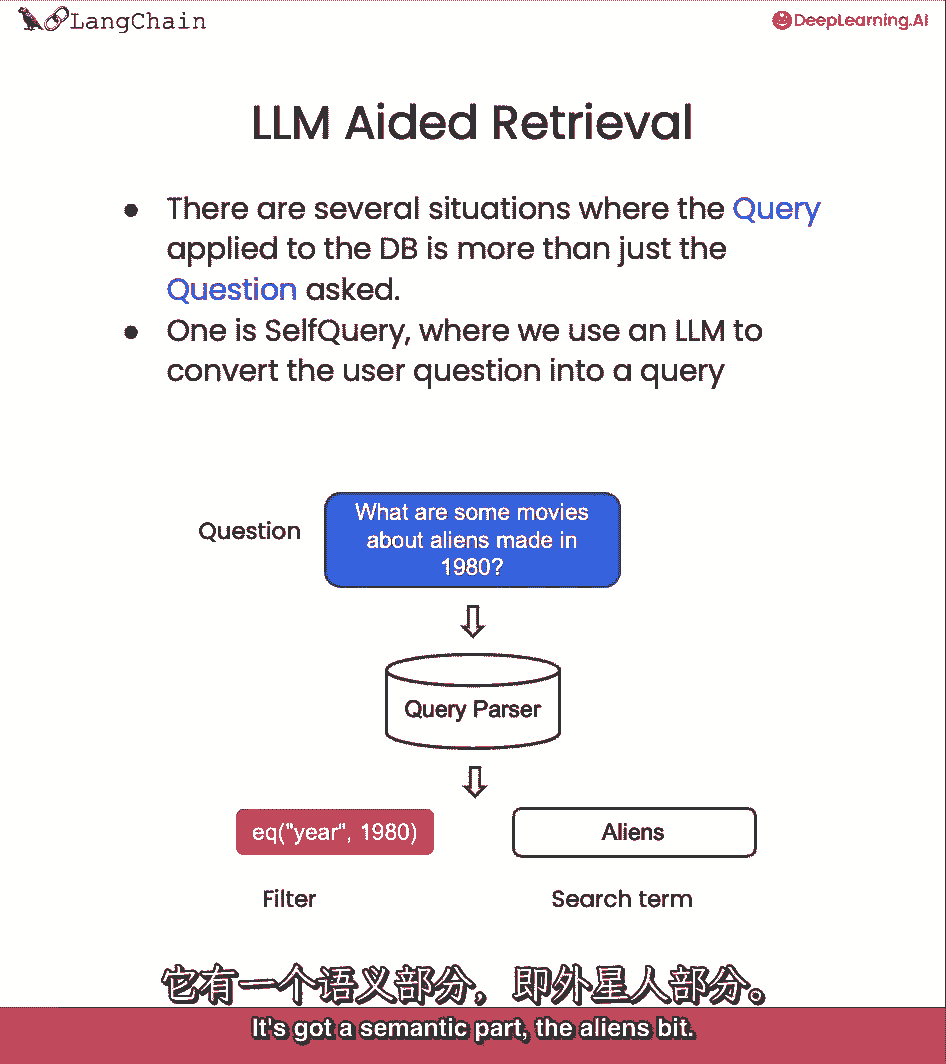
所以我们想在我们的电影数据库中查找外星人,但它也有一个真正引用每部电影元数据的部分,这就是年份应该是1980年的事实。
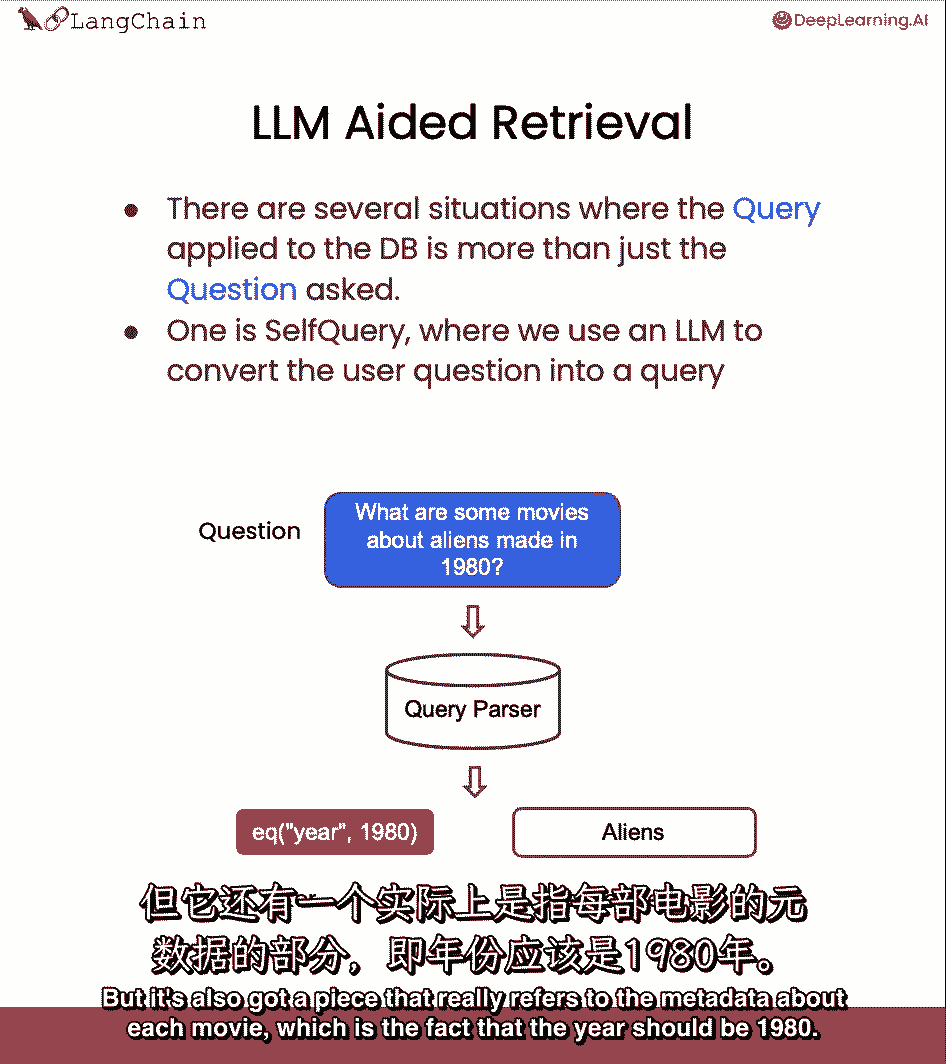
我们能做的就是,我们可以使用语言模型本身将最初的问题分成两个独立的东西,筛选器和搜索词。
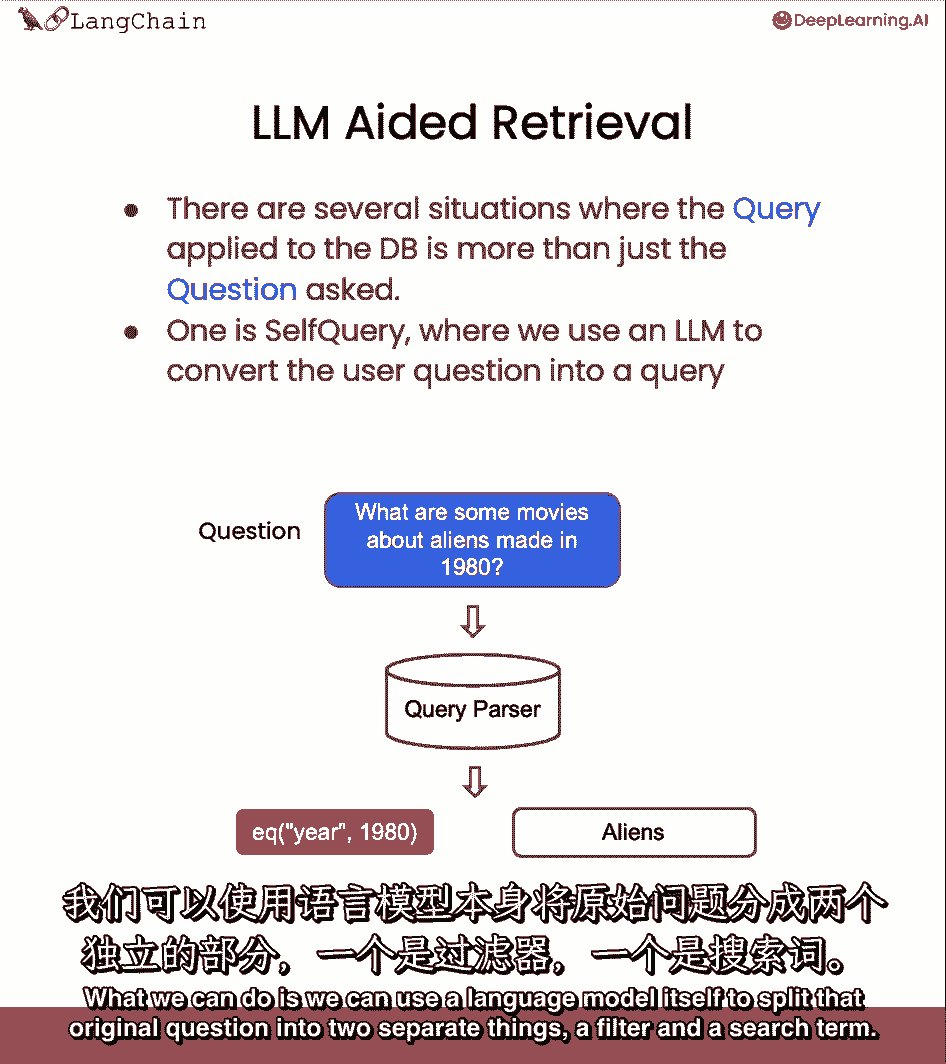
大多数向量存储支持元数据筛选器,因此,您可以轻松地基于元数据筛选记录。
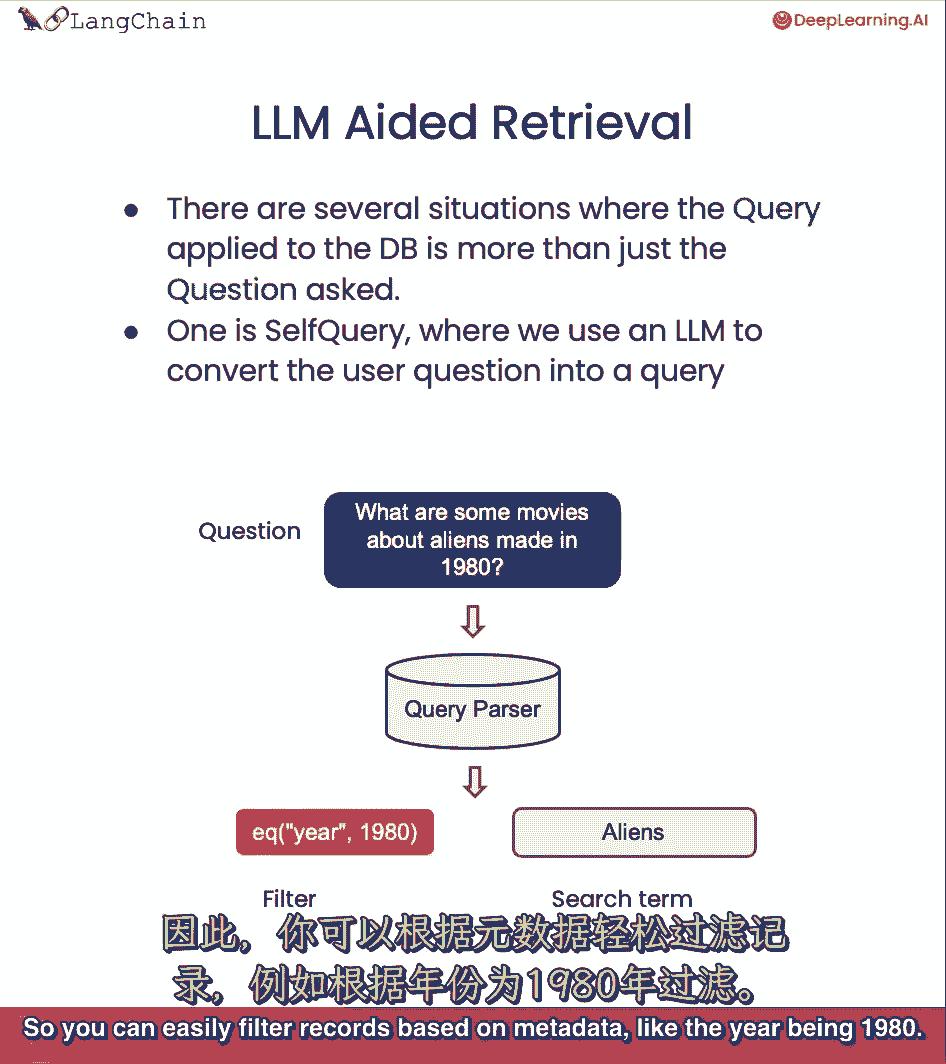
就像1980年。
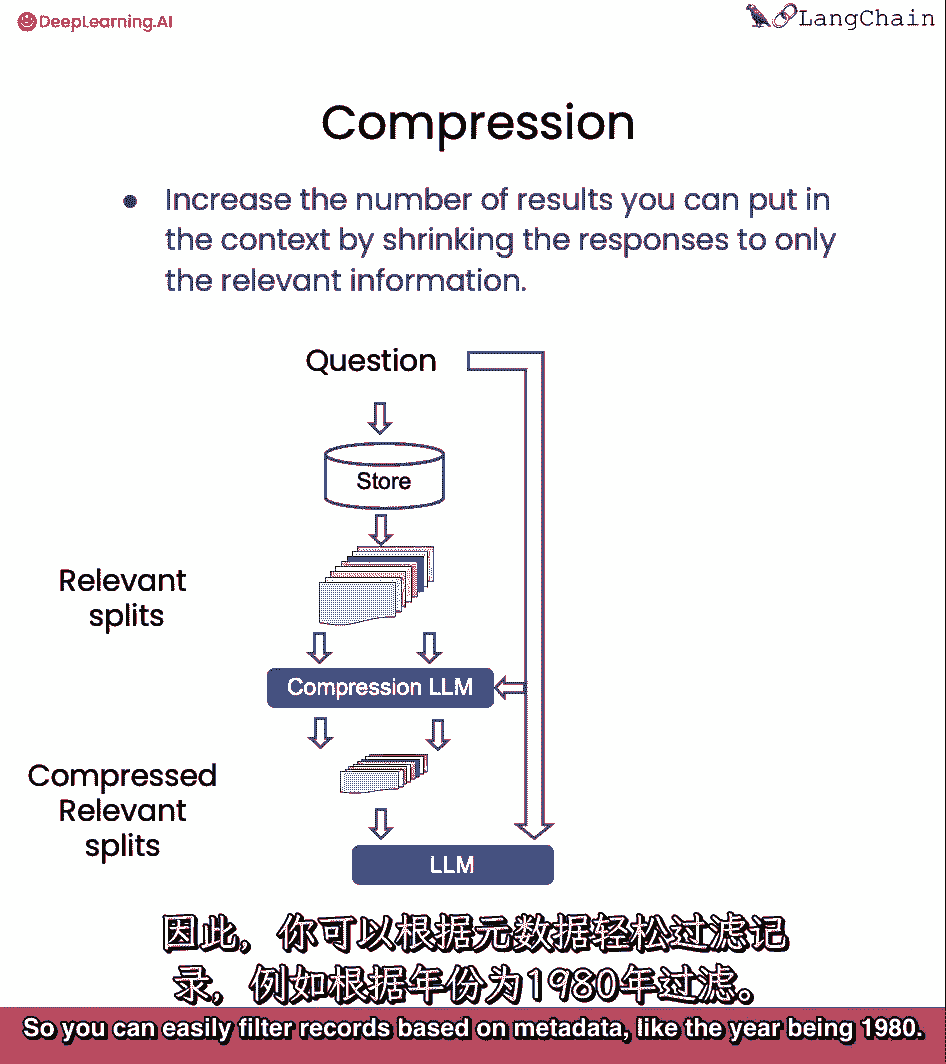
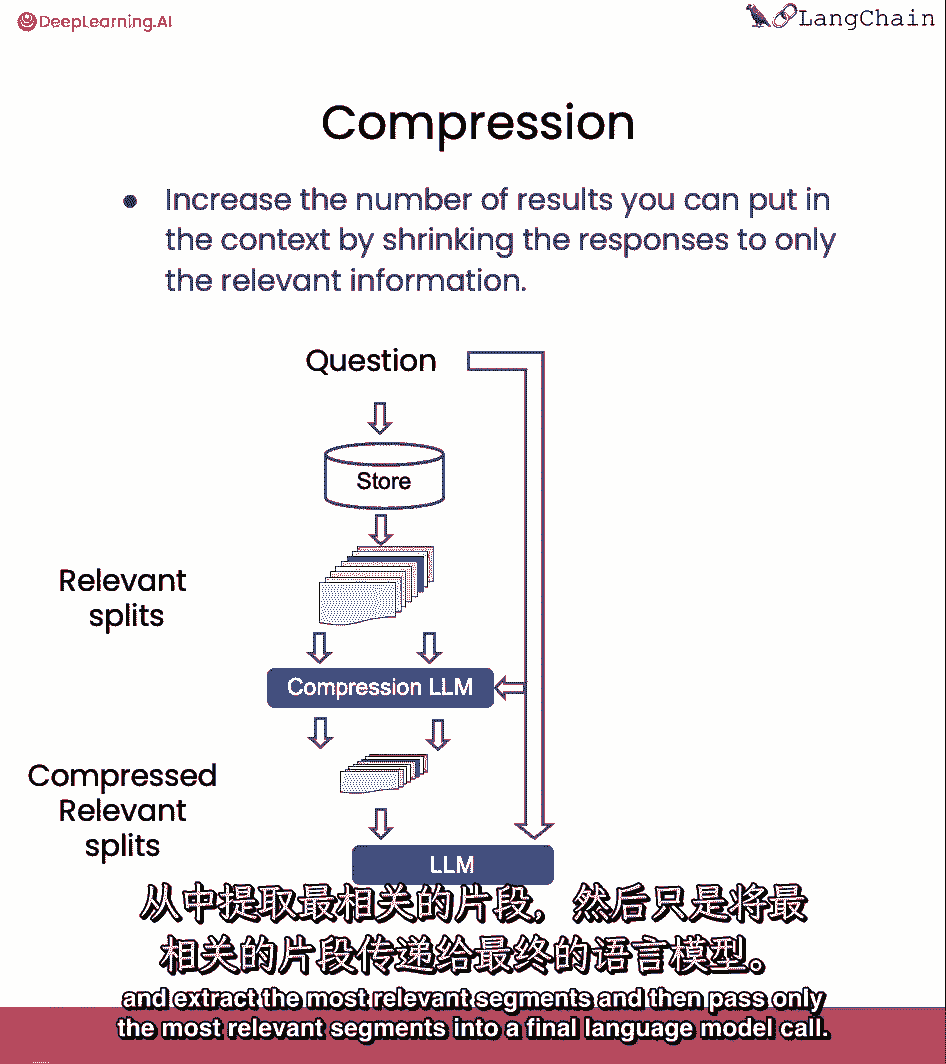
最后我们将讨论压缩,这对于只提取检索到的段落中最相关的部分是有用的,例如,在问问题时,你拿回储存在。
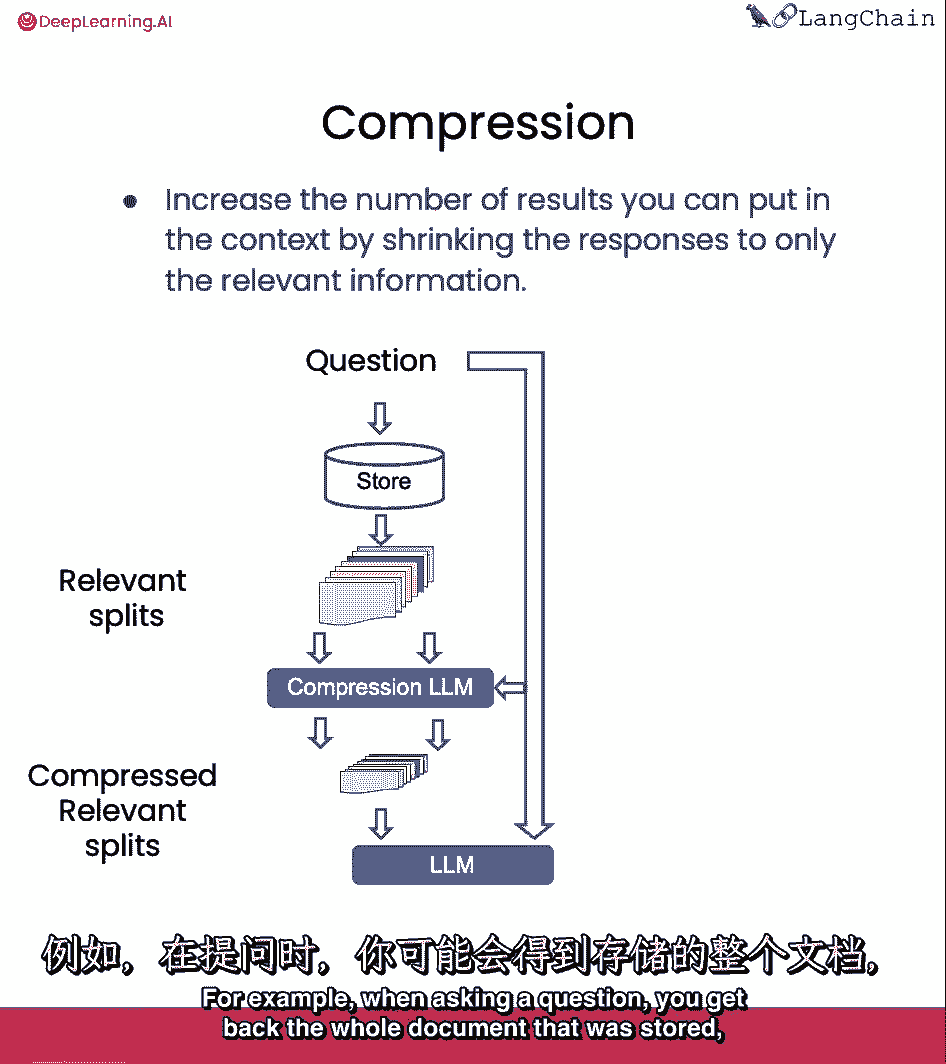
即使只有前一两句是压缩的相关部分。
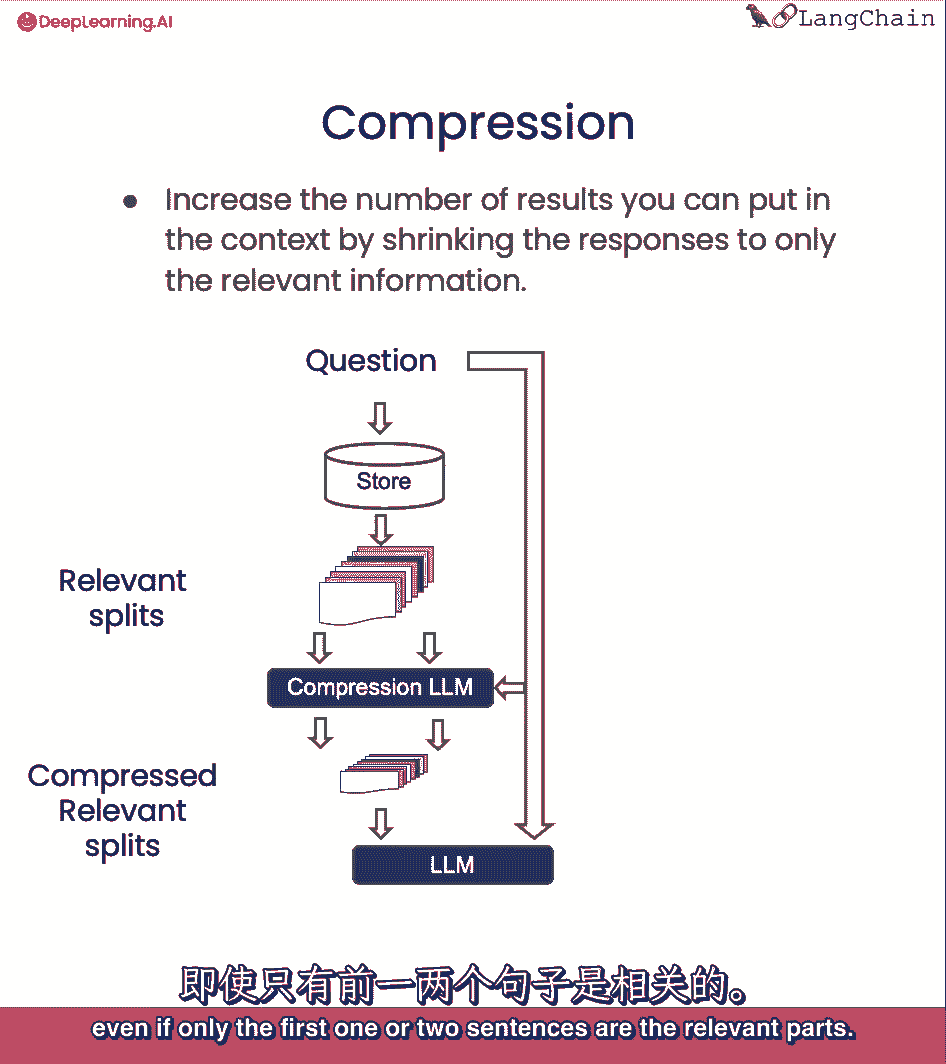
然后,您可以通过语言模型运行所有这些文档,并提取最相关的段。
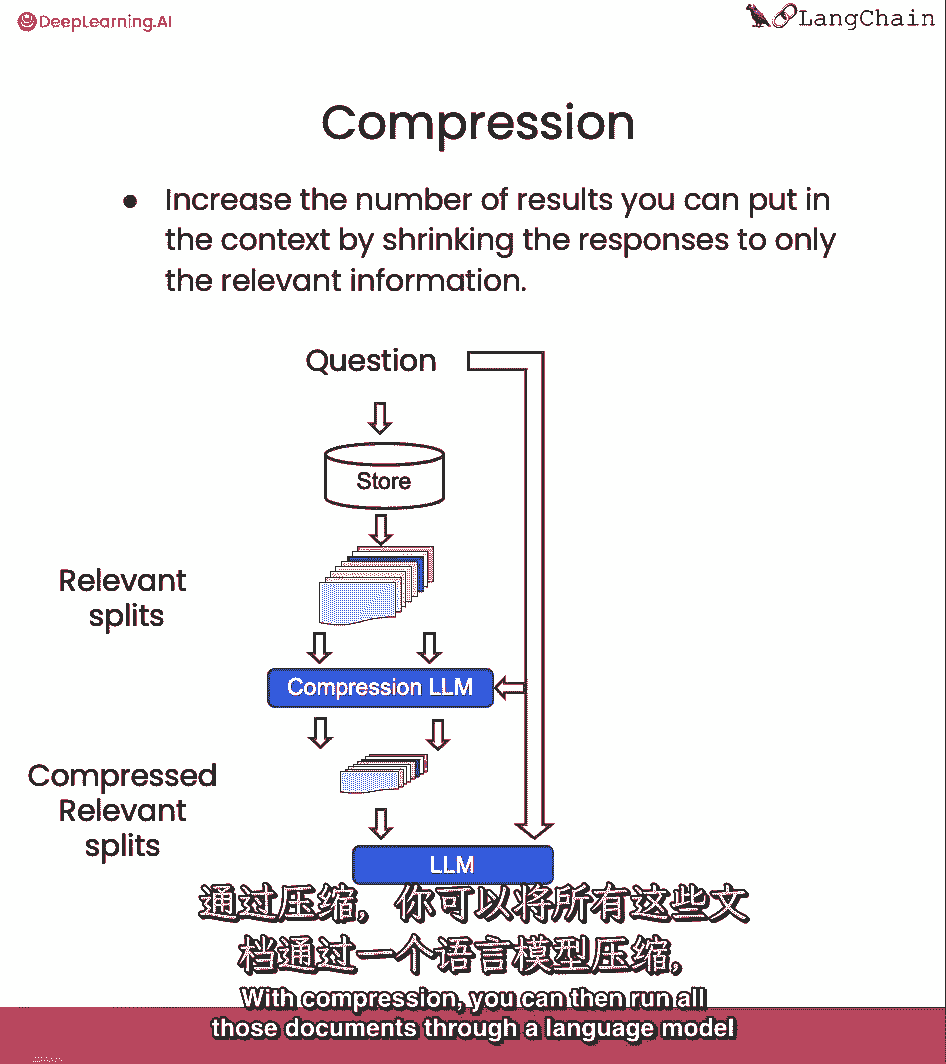
然后只将最相关的段传递到最终的语言模型调用中。
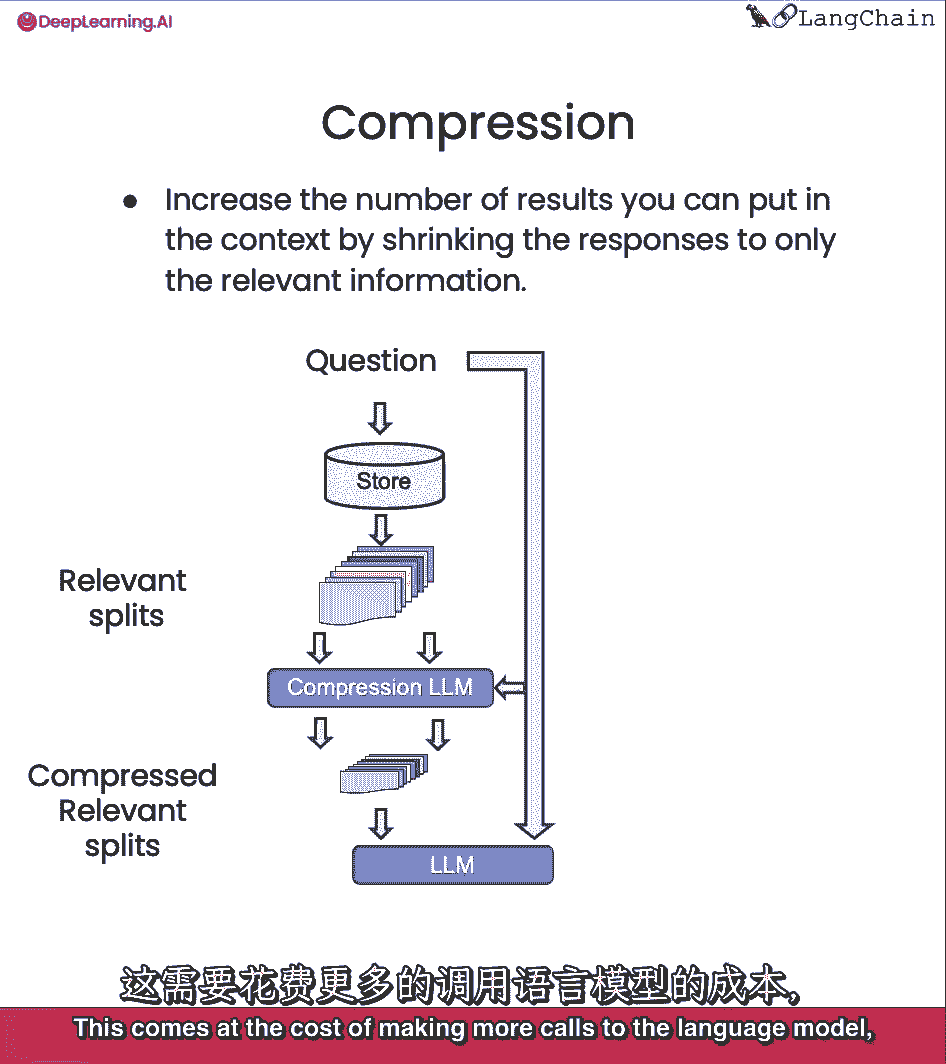
这是以对语言模型进行更多调用为代价的。
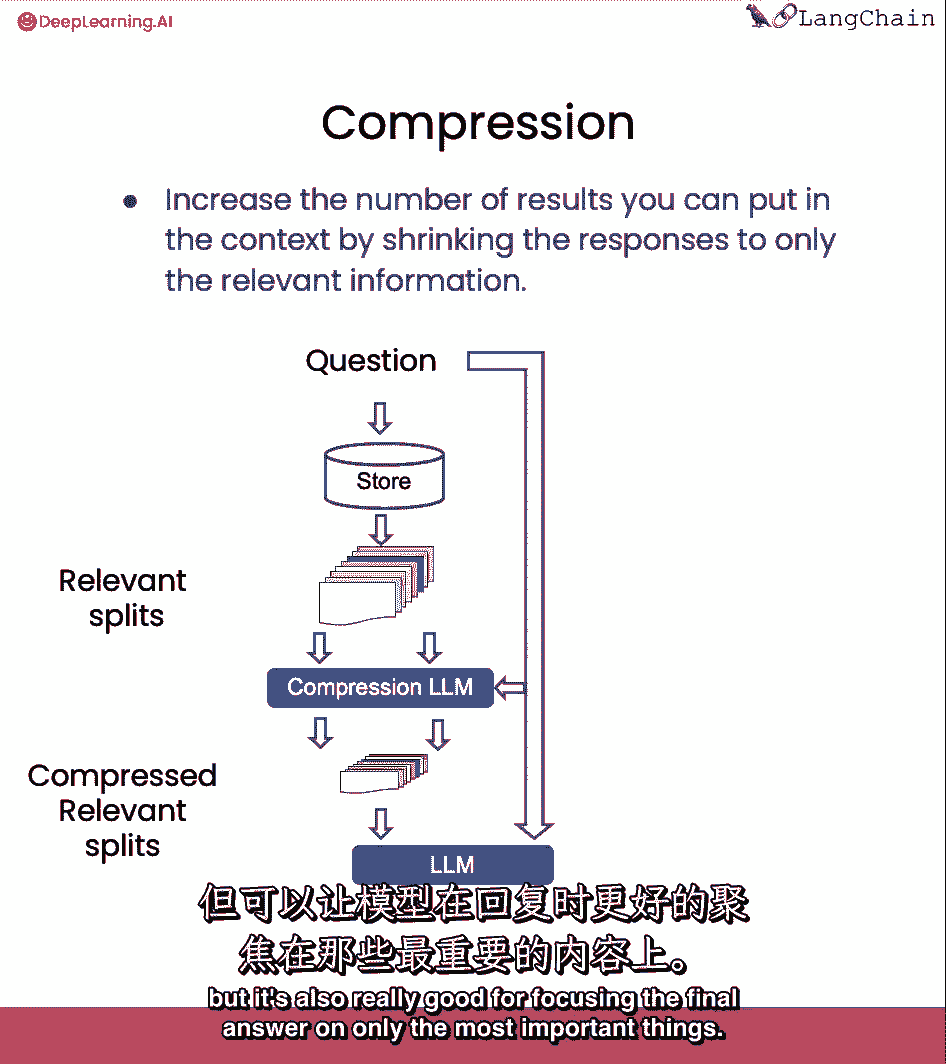
但它也非常有利于将最终答案集中在最重要的事情上。
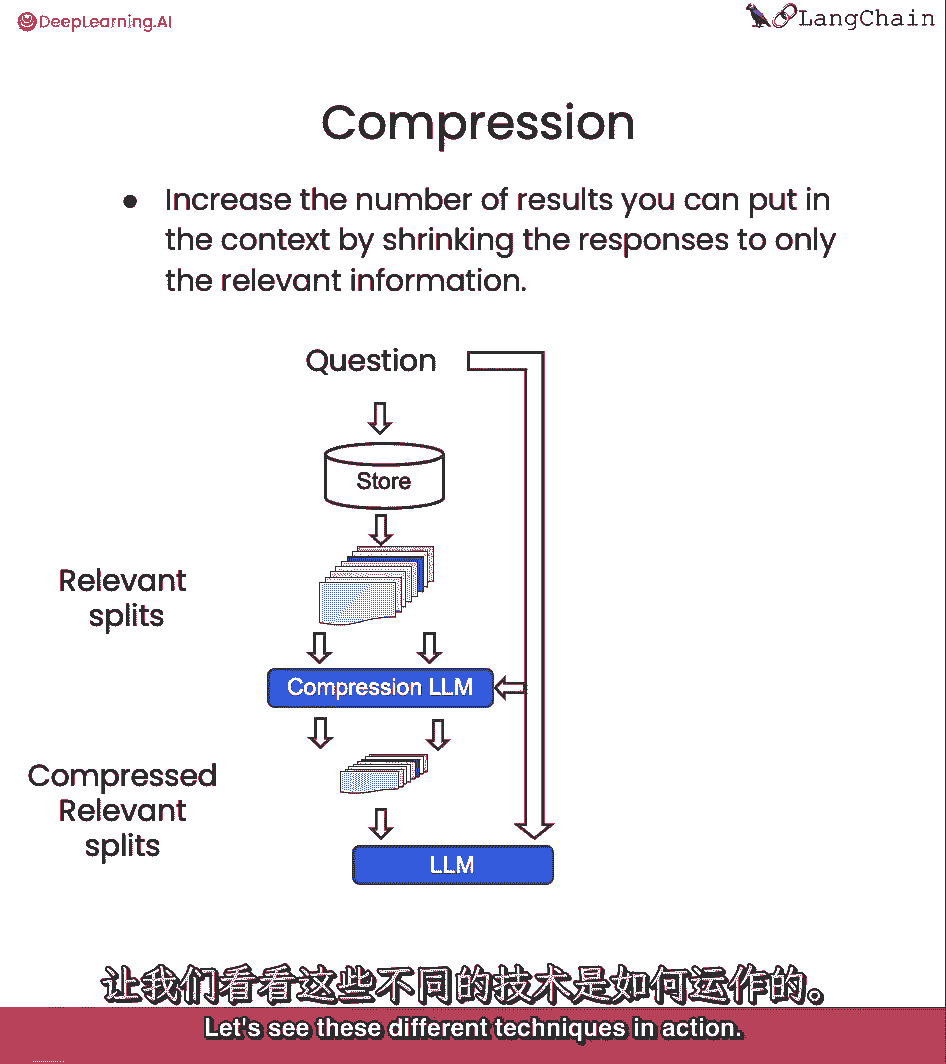
所以这有点折衷,让我们看看这些不同的技术在起作用。
我们将从加载环境变量开始,就像我们一直做的那样。

进口色度和开放AI是多少,就像我们以前用的那样。

我们可以从收藏中看到,数一数,它有我们之前加载的209份文件。

现在让我们来看看最大边际相关性的例子。

因此,我们将从示例中加载文本,我们有关于蘑菇的信息,对于本例,我们创建一个小数据库,我们可以把它当作玩具使用,例。

我们有问题了,现在我们可以进行相似性搜索,我们将k等于2设置为只返回两个最相关的文档。

我们可以看到没有提到它有毒的事实,现在让我们用mmr运行它,除非通过k等于2,我们还要还两份文件,但是让我们把fetch k设为3,我们把这三份文件,原来。

我们现在可以看到,有毒的信息在我们检索的文档中返回。

让我们回到上一课的一个例子。

当我们询问Matlab并得到文档时,这些文档中有重复的信息来刷新您的记忆。

我们可以看看前两份文件。

只是看看最初的几个字符,因为它们很长,否则,我们可以看到他们是一样的,当我们在这些结果上运行mmr时。

我们可以看到第一个和之前一样。

因为那是最相似的,但当我们进入第二个,我们可以看到它是不同的。

它得到了一些不同的反应。

现在让我们进入self查询示例,这是我们有问题的地方。

他们在第三堂课上对回归说了什么,它返回的结果不仅仅是第三次讲座。

也是第一个和第二个,如果我们用手把它修好。

我们要做的是指定一个元数据过滤器,所以我们传递这个信息,我们希望源等于第三个讲座。

PDF,然后如果我们看看会被检索到的文件,它们都来自那个讲座。

我们可以使用语言模型来为我们做到这一点,所以我们不必手动指定,做这件事。

我们将导入一个语言模型开放AI,我们将导入一个称为自查询检索器的检索器。

然后我们将导入属性信息,我们可以在元数据中指定不同的字段,以及它们对应于什么。
元数据中只有两个字段。

来源和页面,我们填写名字的描述。

每个属性的描述和类型,这些信息实际上将被传递给语言模型。

因此,使其尽可能具有描述性是很重要的。

然后,我们将指定有关此文档存储中实际内容的一些信息,我们将初始化语言模型,然后,我们将使用from lm方法初始化自查询检索器。

并将我们将要查询的底层向量数据库传递到语言模型中,有关描述和元数据的信息,然后我们还将传递详细等于真实的设置。

冗长等于真井,让我们看看引擎盖下面是怎么回事,当LLM推断应该与任何元数据筛选器一起传递的查询时。

当我们运行带有此问题的自查询检索器时。

我们可以看到感谢若等于真的,虽然我们正在打印引擎盖下发生的事情。

我们得到一个回归查询,这是语义位,然后我们得到一个过滤器,在那里我们有一个平等的比较器,在source属性和docs值之间。

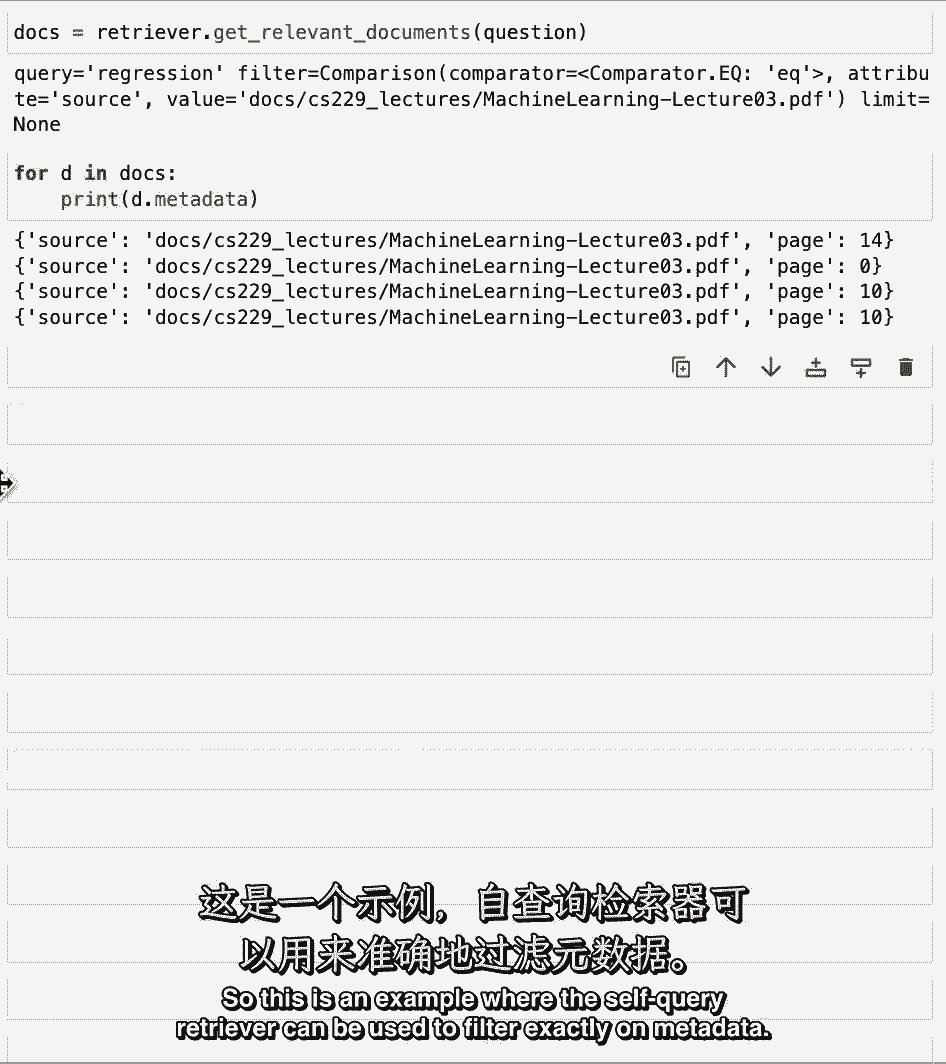
然后这个路径,也就是第三个机器学习讲座的路径,所以说,这基本上是告诉我们在回归的语义空间中进行查找,然后做一个筛选,我们只查看源值为此值的文档。

所以如果我们在文档上循环并打印出元数据,我们应该看到他们都来自第三课。

他们确实如此,这是一个例子,其中可以使用自查询检索器准确地筛选元数据。
我们可以谈论的最后一种检索技术是上下文压缩,所以让我们在这里加载一些相关的模块。

上下文压缩检索器,然后是一个LLM链条提取器。

接下来要做的是,这将只从每个文档中提取相关的位。

然后将这些作为最终的返回响应传递给,我们将定义一个很好的小函数来漂亮地打印文档。
因为它们往往又长又乱,这将使人们更容易看到发生了什么。

然后我们可以用LLM链提取器创建一个压缩机。
然后我们可以创建上下文压缩检索器,通过压缩机。
然后向量存储的基检索器,当我们现在通过这个问题,他们怎么说matlab。

我们看看压缩的文档,如果我们看了文件,我们可以看到两件事,一个,它们比正常的文件短得多,但第二,我们仍然有一些重复的事情发生,这是因为在引擎盖下,我们使用的是语义搜索算法。
这就是我们在本课前面使用mmr解决的问题,这是一个很好的例子,说明您可以结合各种技术来获得最好的结果,为了做到这一点,当我们从向量数据库创建检索器时,我们可以将搜索类型设置为Mr。
然后我们可以重新运行这个,确保我们回来,不包含任何重复信息的筛选结果集,到目前为止,我们提到的所有附加检索技术都建立在矢量数据库之上。

值得一提的是,还有其他类型的检索根本不使用矢量数据库。

取而代之的是其他,更传统的nlp技术。

这里,我们要重新建立一个检索管道,有两种不同类型的寻回器,和SVM寻回器和一个TF IDF寻回器。

如果你从传统的NLP或传统的机器学习中认识到这些术语,那就太好了。

如果你不,也很好,这只是其他一些技术的一个例子。

除了这些,还有很多,我鼓励你去看看,他们中的一些人。

我们可以很快地通过通常的装货和拆分管道。

然后这两个检索程序都公开一个from text方法,其中一个接受嵌入模块,即svm检索器,tf idf寻回器直接接收分裂。

现在我们可以用其他的寻回者,我们进去吧,他们怎么说matlab,到svm检索器,我们可以看看顶部的文档,我们回来了,我们可以看到它提到了很多关于Matlab的东西,所以它在那里取得了一些好的结果。
我们也可以在tf idf寻回器上尝试一下,我们可以看到结果看起来有点糟糕,现在是停下来尝试所有这些不同检索技术的好时机,我想你会注意到他们中的一些人在各种事情上都比其他人好。
所以我鼓励你们在各种各样的问题上尝试一下,自我查询检索器尤其是我最喜欢的,所以我建议用越来越复杂的元数据过滤器来尝试,甚至可能在有嵌套元数据结构的地方编造一些元数据,你可以试着让LLM推断。
我觉得这很有趣,我想这是一些更先进的东西,所以我真的很兴奋能和你们分享,既然我们已经谈到了回收,我们将讨论这个过程的下一步。
【LangChain大模型应用开发】DeepLearning.AI - P14:6——问答聊天机器人 - 吴恩达大模型 - BV1iZ421M79T

我们已经讨论了如何检索与给定问题相关的文档,下一步就是把那些文件,接受最初的问题,把它们都传递给一个语言模型,并要求它回答这个问题,我们将在这节课中复习这一点,完成这项任务的几种不同方法。
让我们开始上这节课吧。
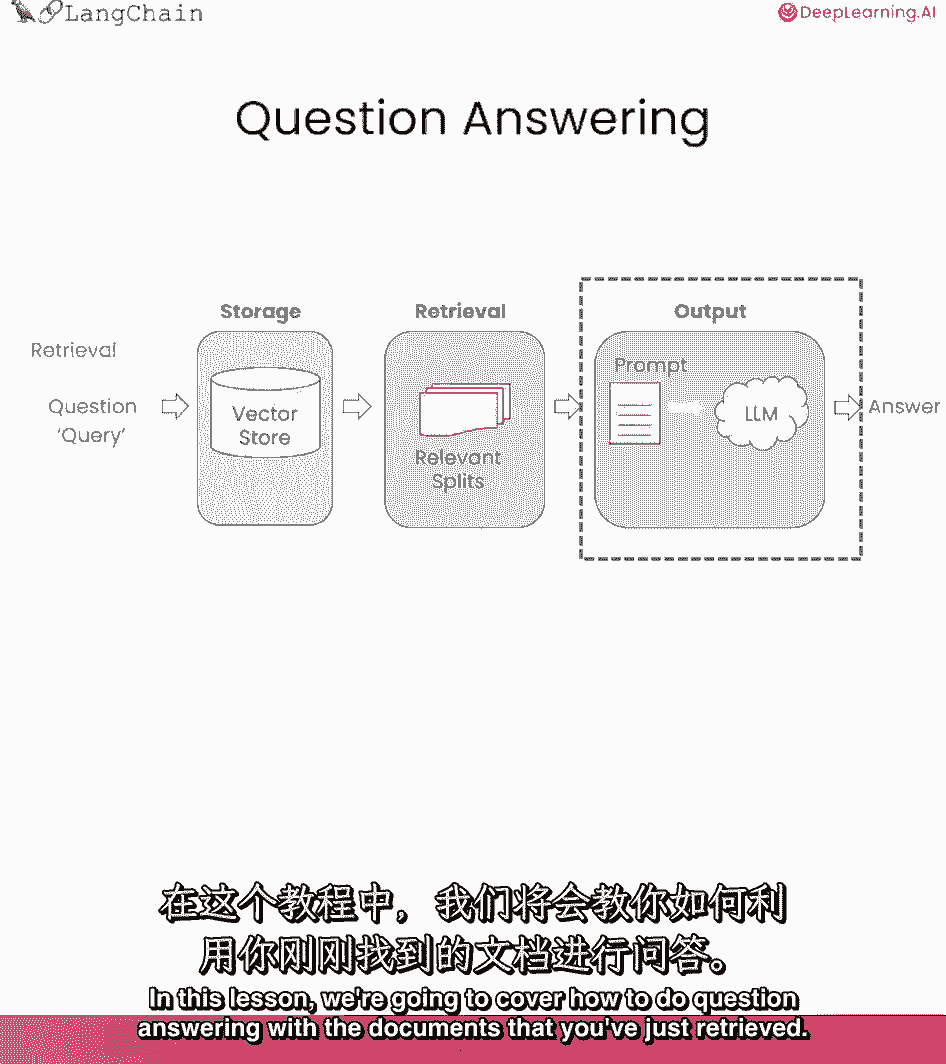
我们将讨论如何做问题,使用您刚刚检索到的文档进行应答,这是在我们完成整个储存和摄入之后,在我们检索到相关的分裂后,现在我们需要把它传递给一个语言模型来得到答案。
一般的流程是这样的,问题来了。
我们查阅相关文件,然后我们通过这些分裂,伴随着系统提示符。
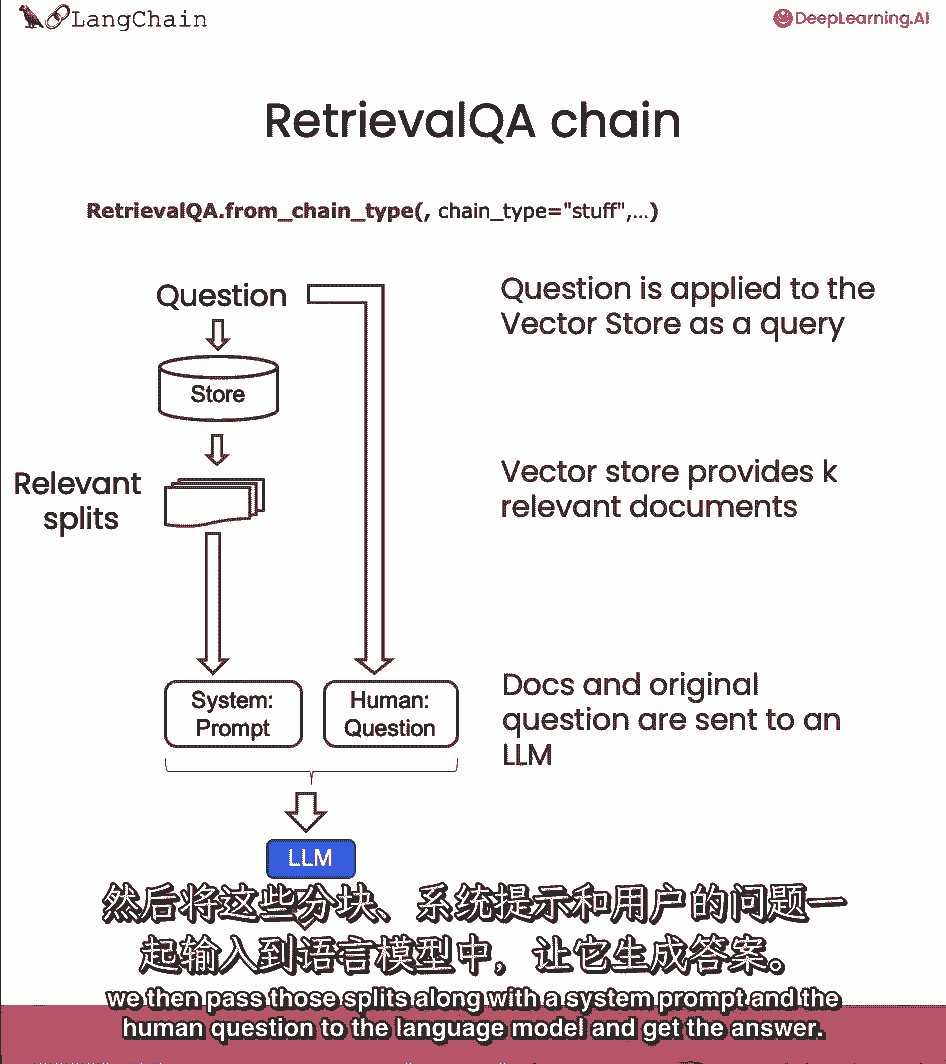
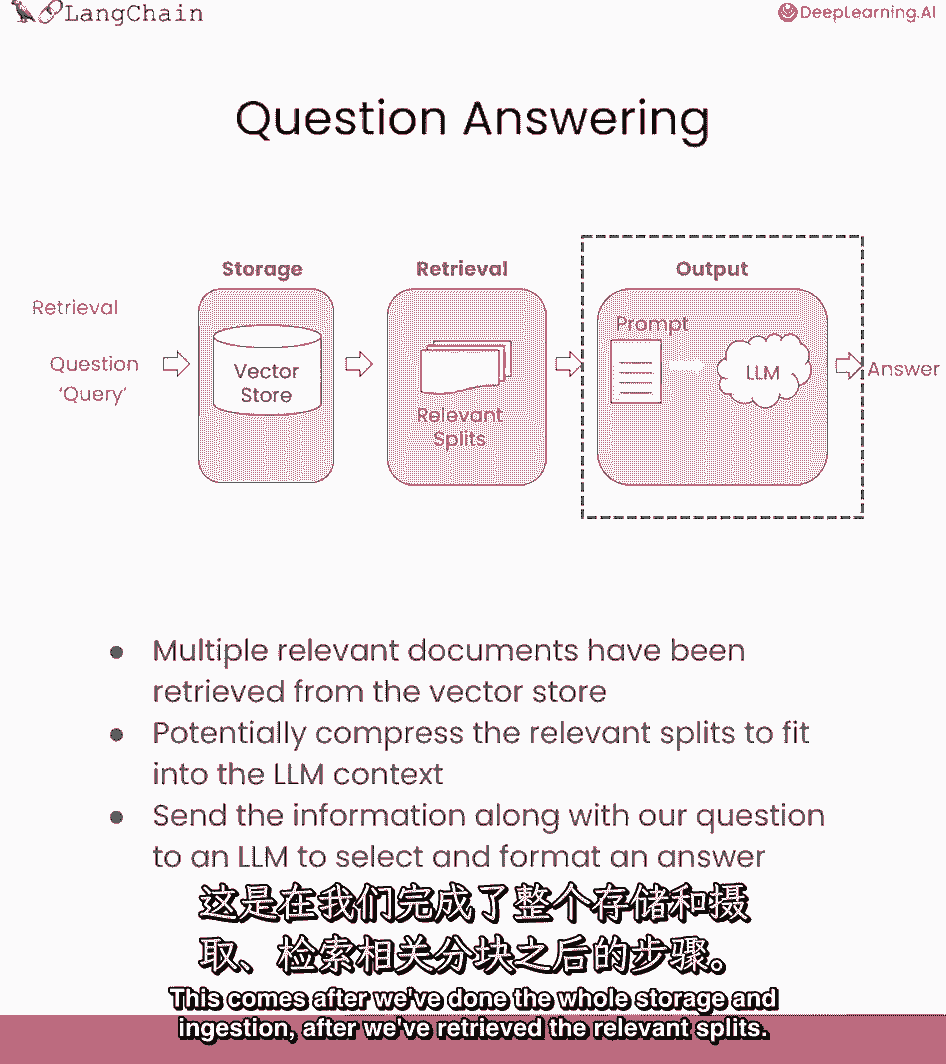
和人类的问题到语言模型并得到答案,默认情况下,我们只需将所有块传递到同一个上下文窗口中,语言模型的相同调用。
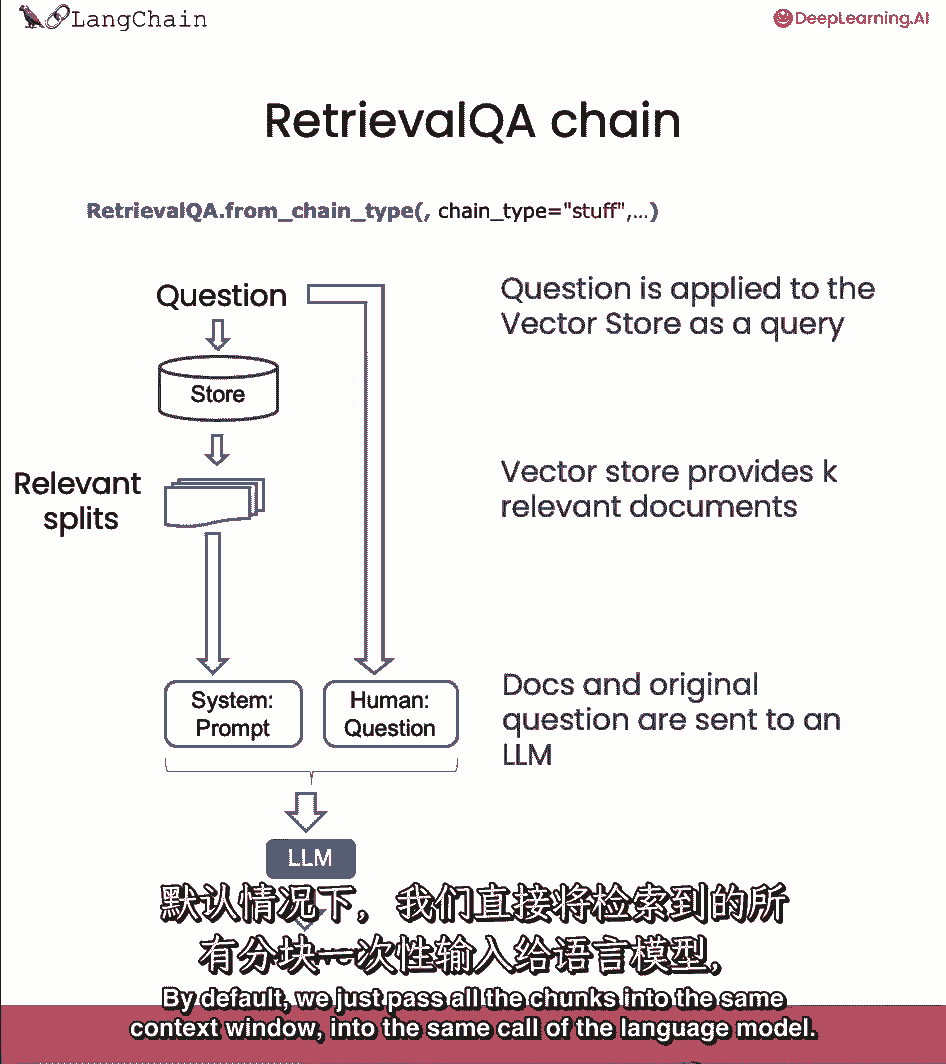
然而,我们可以使用一些不同的方法,对此有利弊。
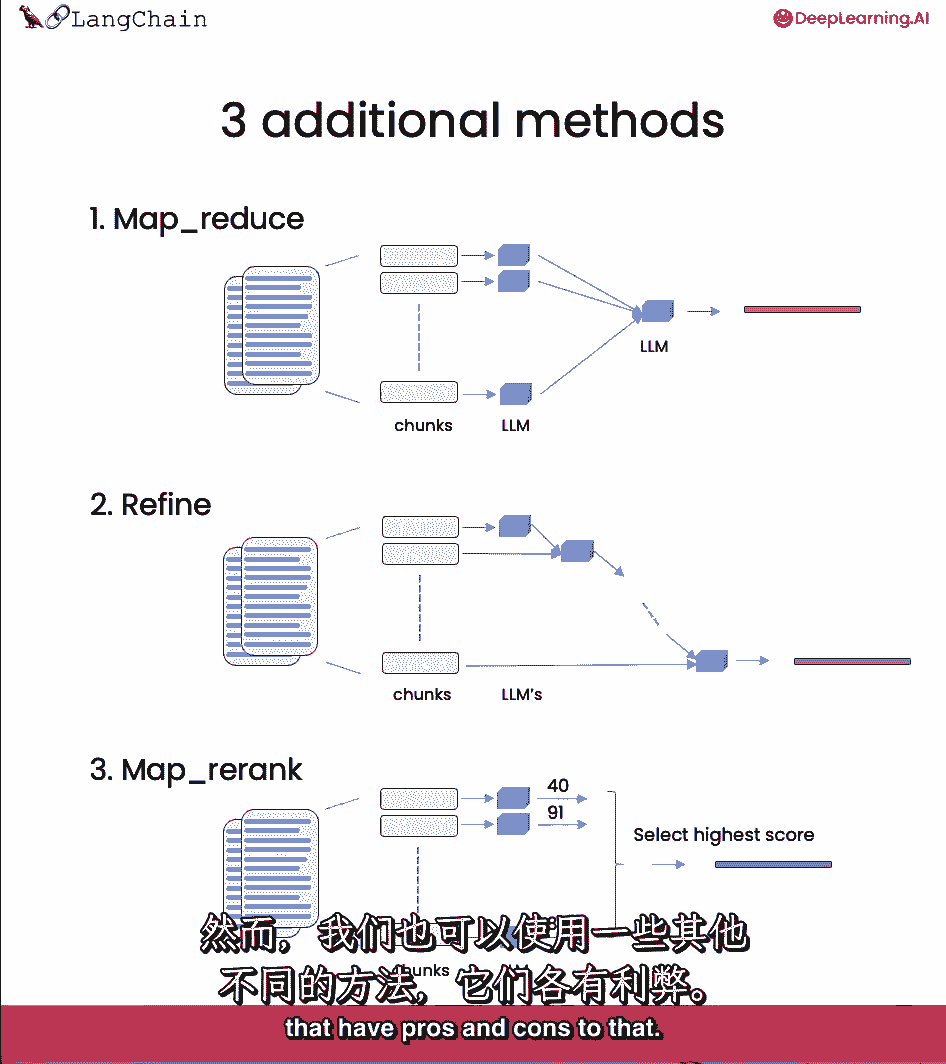
大多数优点来自于这样一个事实,即有时会有很多文件,您不能简单地将它们都传递到相同的上下文菜单中。
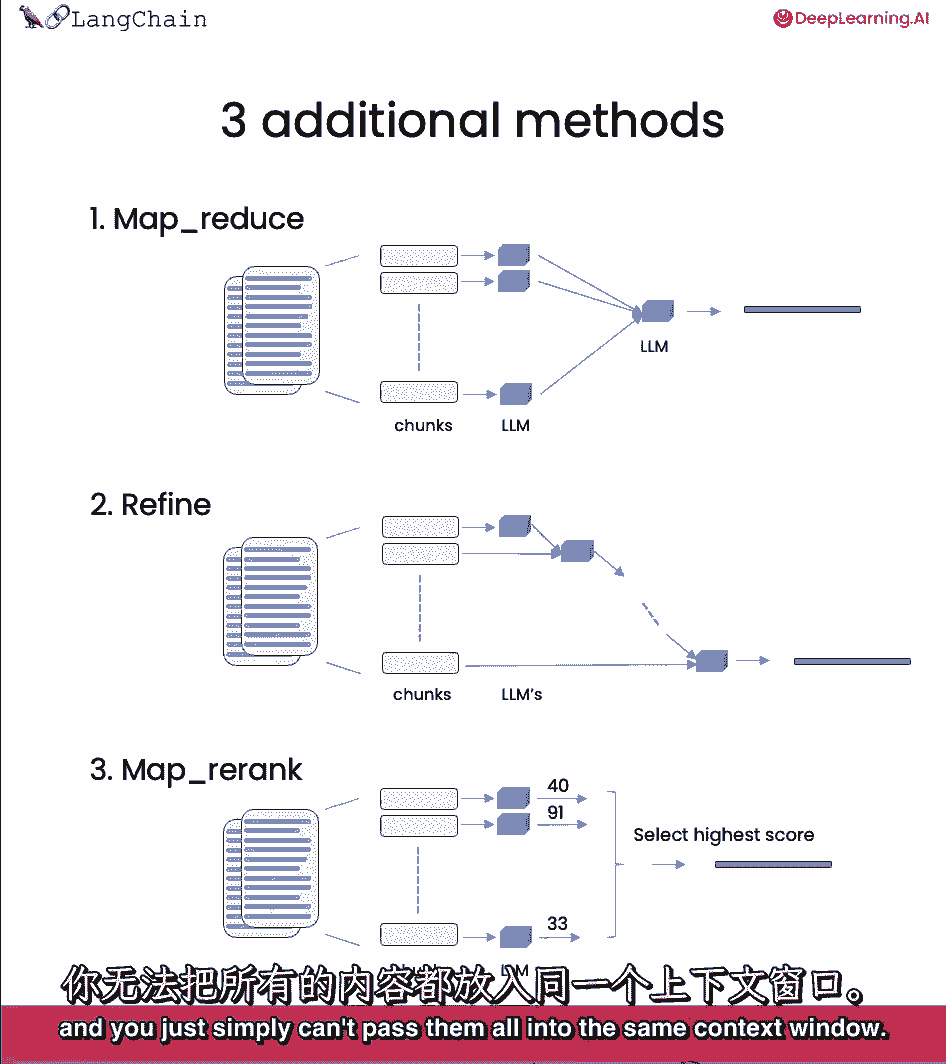
Mapreduce,精炼。
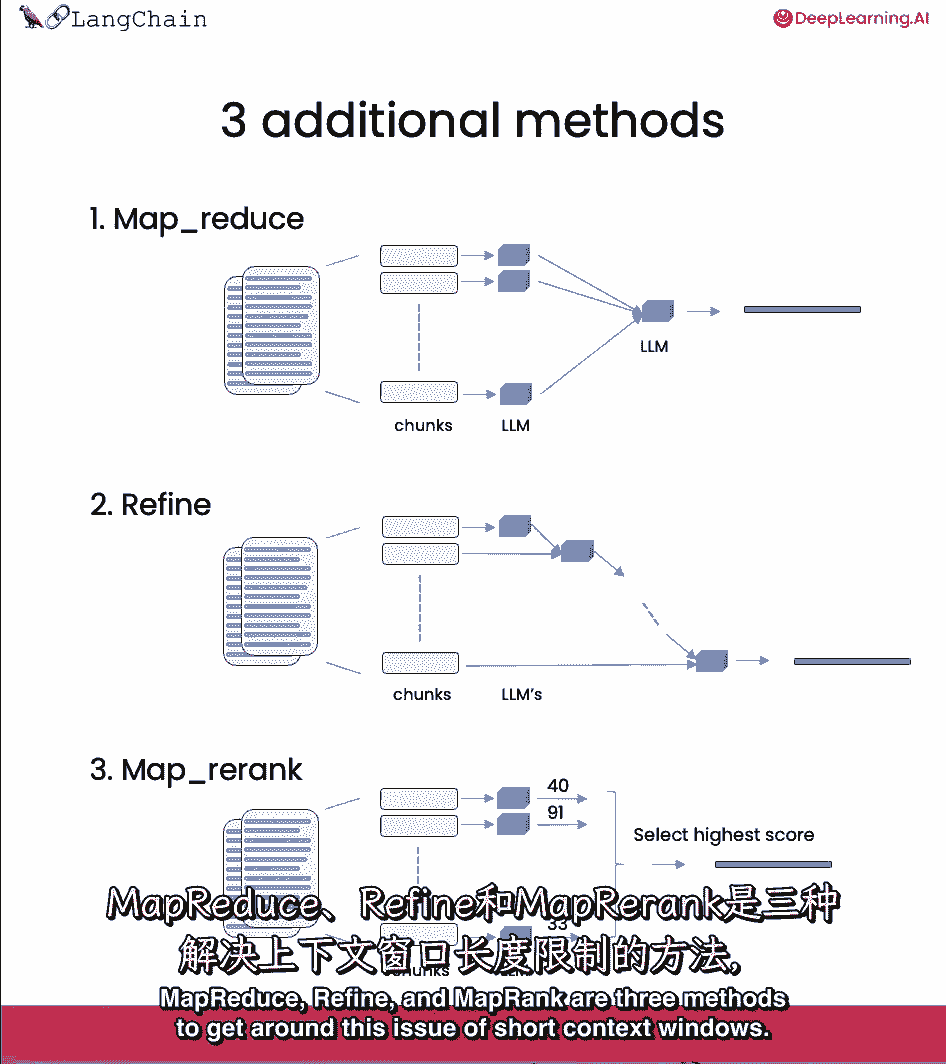
我们将在今天的课上讨论其中的一些,让我们开始编码。
第一批,我们会像往常一样输入环境变量。

然后,我们将加载以前持久化的向量数据库,我要检查它是否正确。
我们可以看到它有以前的209份文件。

我们做一个快速的相似性搜索,为了确保它对第一个问题起作用,即这门课的主要主题是什么。

现在我们初始化我们要用来回答问题的语言模型。

我们将使用聊天开放人工智能模型GPT三点五。

我们要把温度设为零,当我们想要真实的答案出来时,这真的很好。

因为它的可变性很低,通常只给我们最高的保真度,最可靠的答案。

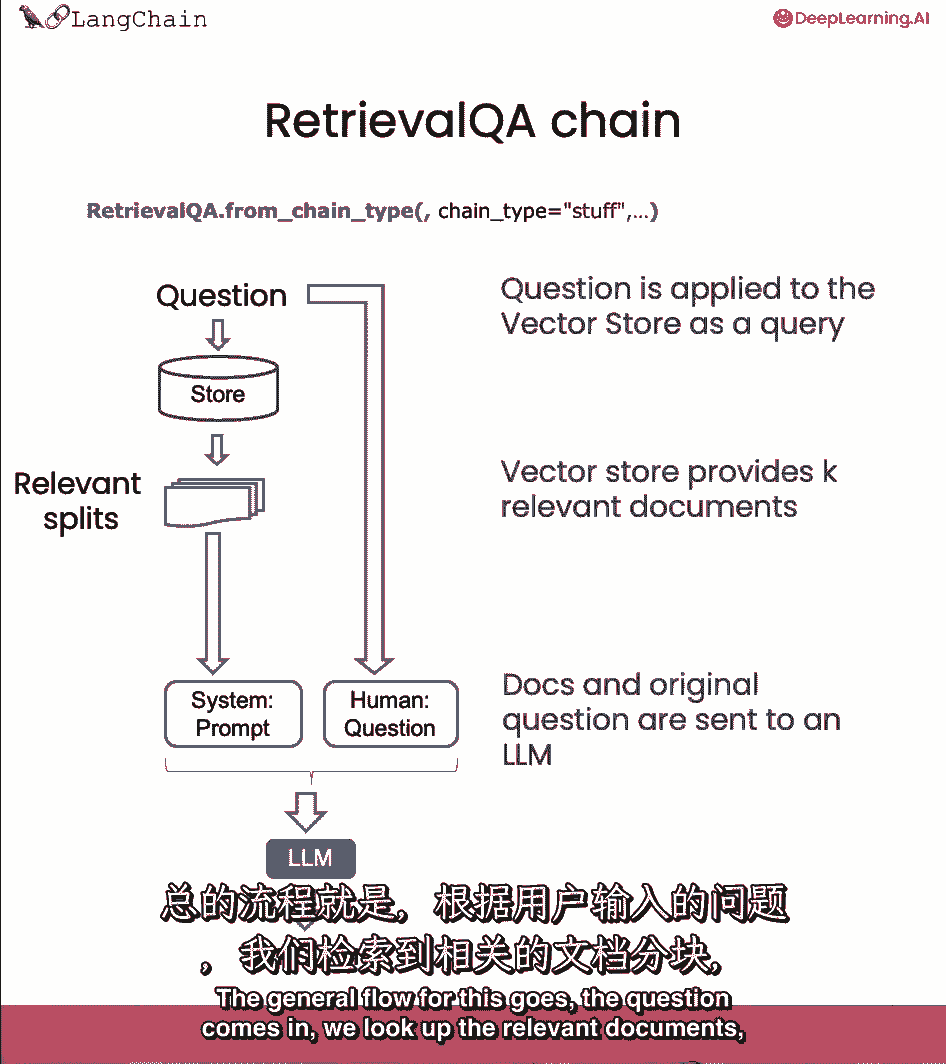
然后我们将导入检索QA链,这是在回答问题,由检索步骤支持。

我们可以通过传入一个语言模型来创建它。

然后向量数据库作为检索器。

然后,我们可以调用它,查询等于我们想要问的问题。

当我们看到结果时,我们得到了答案,这堂课的主要主题是机器学习,另外,这门课可以在讨论部分复习统计学和代数。

本季度晚些时候,讨论部分还将涵盖主要讲座中教授的材料的扩展。

让我们试着更好地理解一点,引擎盖下面是怎么回事,并暴露一些不同的旋钮,你可以把主要部分,这里很重要的是我们正在使用的提示符,这是接收文档和问题并将其传递给语言模型的提示符。

关于提示的复习。

你可以看到我和安德鲁一起上的第一堂课,这里我们定义一个提示模板。

它有一些关于如何使用以下上下文的说明,然后它有一个上下文变量的占位符,这就是文件要去的地方,以及问题变量的占位符。

我们现在可以创建一个新的检索,Qn,我们将使用与以前相同的语言模型,在与以前相同的矢量数据库中,但我们将通过几个新的论点,所以我们得到了返回源文件,所以我们要把这个等于零设为真。
这将使我们能够轻松地检查我们检索的文档。

然后我们还将传递一个提示。

相当于QA链,我们在上面定义的提示,让我们尝试一个新问题:概率,课堂主题。

我们得到一个结果,如果我们检查里面的东西,我们可以看到是的,概率被假定为该类的先决条件。

讲师假设熟悉基本的概率统计,我们将在讨论部分讨论一些先决条件,作为复习课程,谢谢你的询问,当它回应我们时,它也很好,为了更好地了解它从哪里获得这些数据。

我们可以看看一些被退回的源文件。

如果你看穿它们,您应该看到,回答的所有信息都在这些源文档中的一个中,现在是停下来考虑几个不同问题的好时机,或者您自己的不同提示模板,看看到目前为止结果是如何变化的。
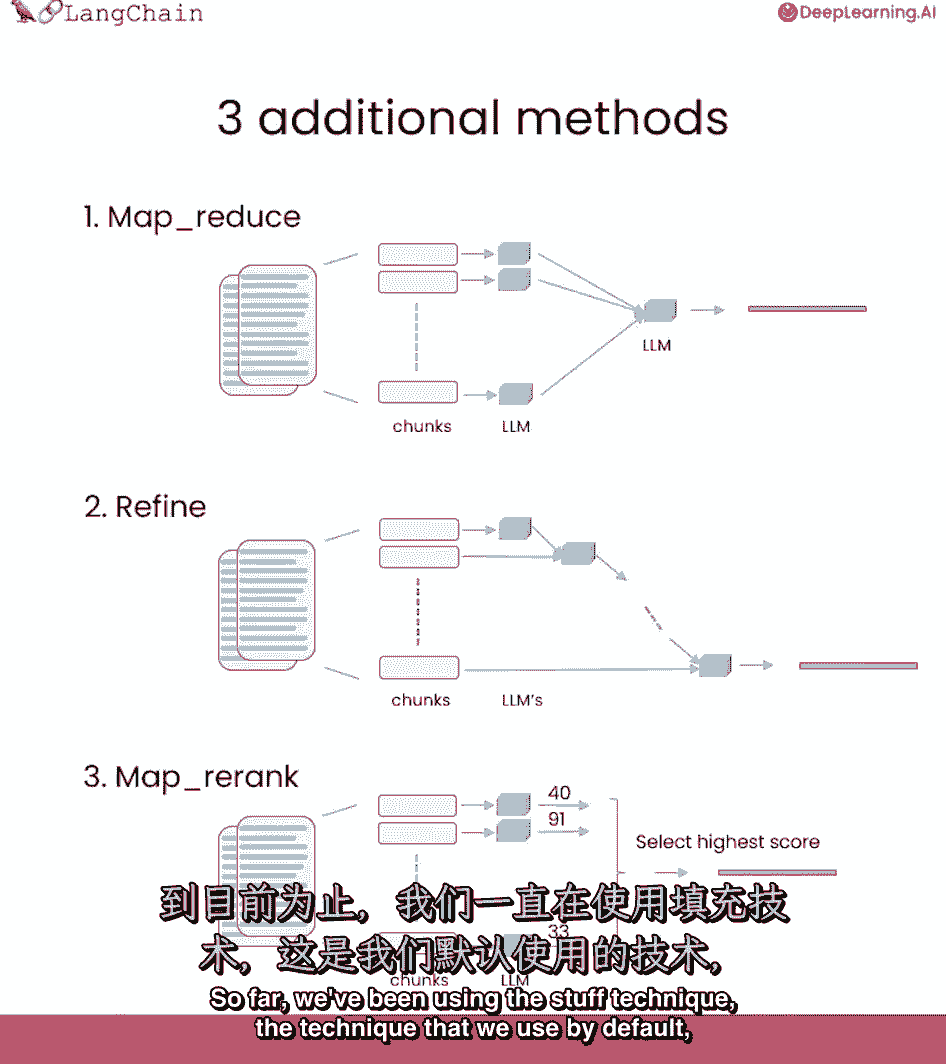
我们一直在用东西技术,我们默认使用的技术,它基本上只是把所有的文档塞进最后的提示符中,这真的很好,因为它只涉及到对语言模型的一次调用,然而,这确实有一个限制,如果文件太多。
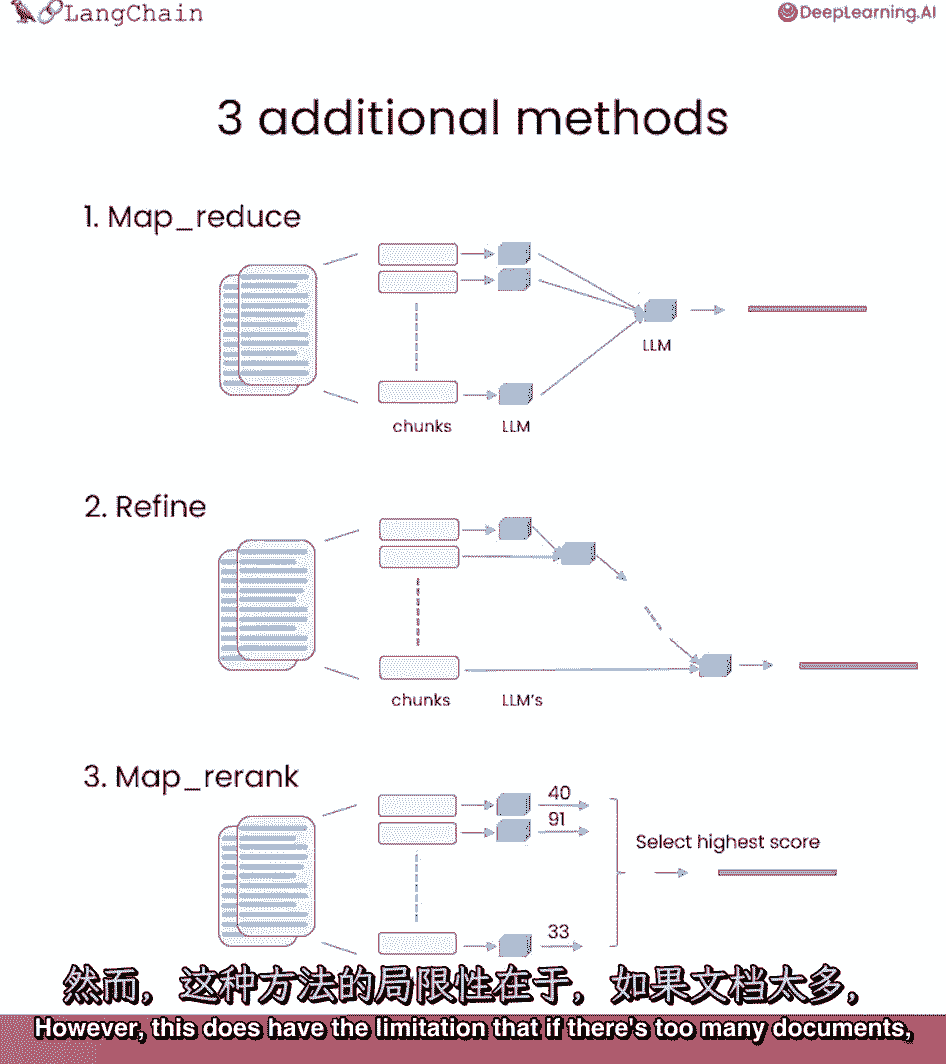
它们可能并不都适合上下文窗口,一种不同类型的技术,我们可以用来做问题,回答文档是这种技术中的mapreduce技术,每个单独的文档首先被单独发送到语言模型以获得原始答案。
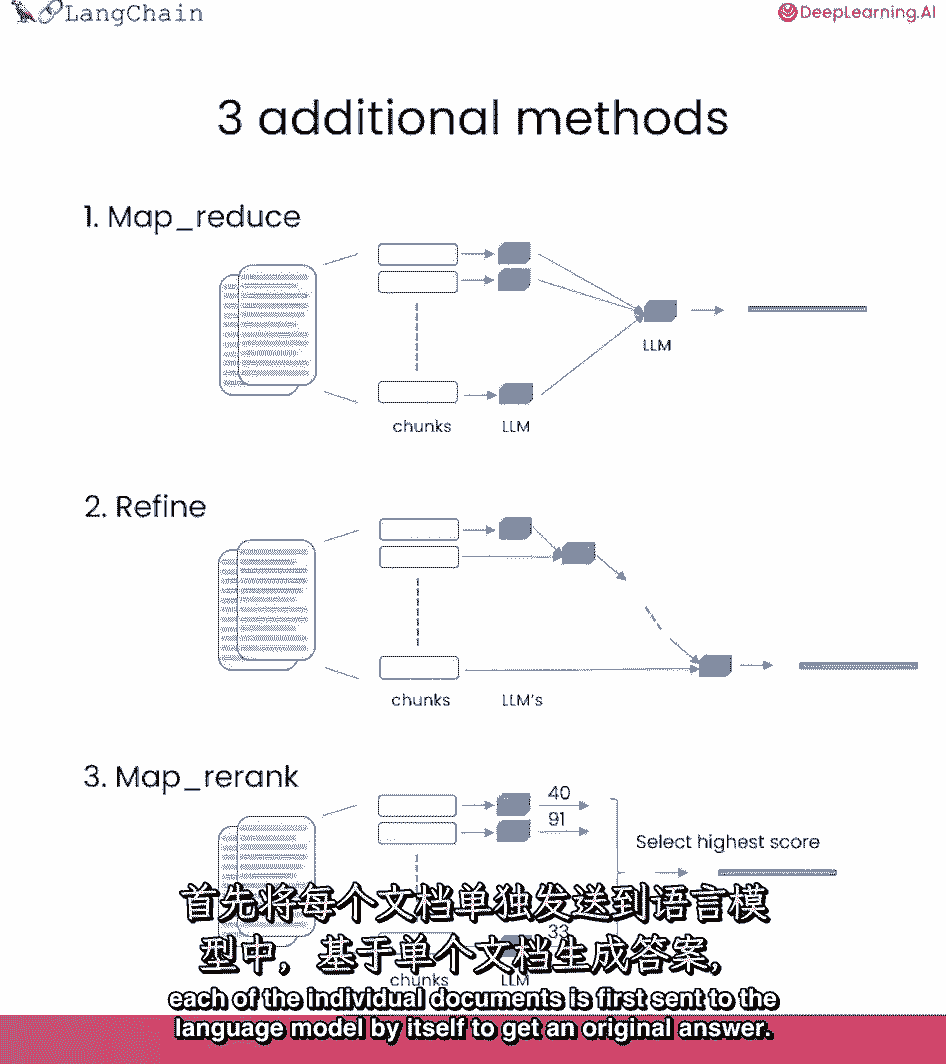
然后这些答案被组成一个最终的答案,最后调用一个语言模型。
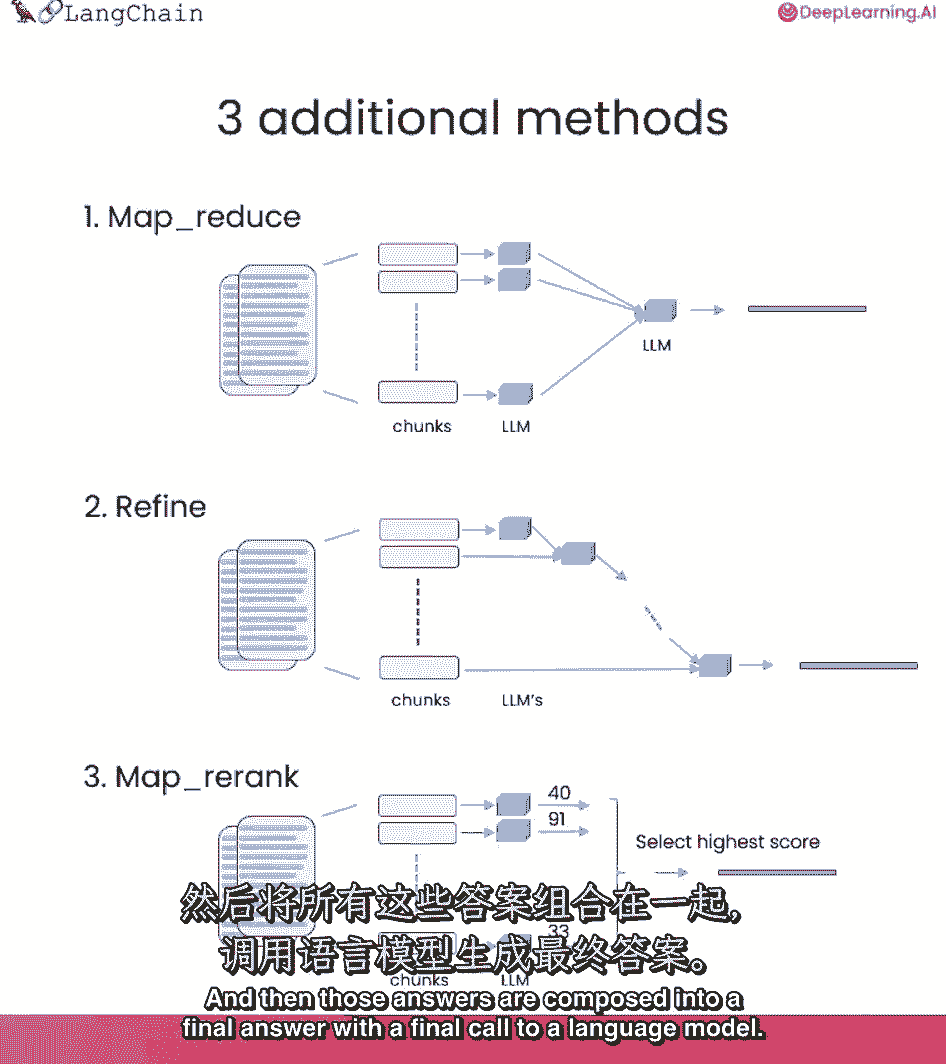
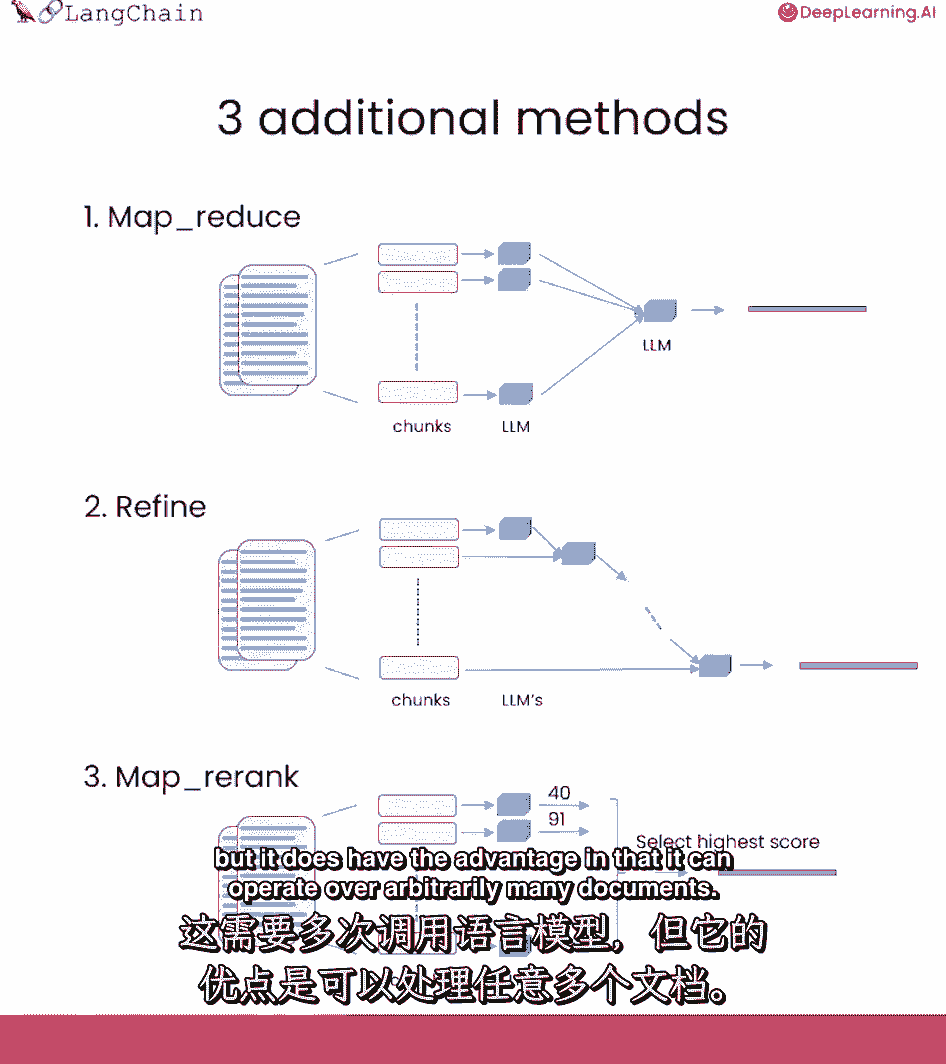
这涉及到更多的语言模型调用,但它确实有优点,因为它可以对任意多的文档进行操作。
当我们通过这个链运行前一个问题时,我们可以看到这种方法的另一个局限性,或者实际上我们可以看到两个一,慢多了,两个,结果其实更糟,这个问题没有明确的答案,根据文件的给定部分,可能会发生这种情况。
因为它是根据每个文档单独回答的。

因此,如果有信息分散在两个文档中,它并没有把所有的东西都放在同一个背景下。

这是利用车道链平台获得感提升的好机会,因为这些锁链里面发生了什么。

我们将在这里演示这一点,如果你想自己用的话。

教材里会有说明,关于如何获得API密钥,一旦我们设置了这些环境变量,我们可以重新运行地图,减少链条,然后我们可以切换到用户界面,看看发生了什么。

在引擎盖下,从这里我们可以找到我们刚才运行的运行。
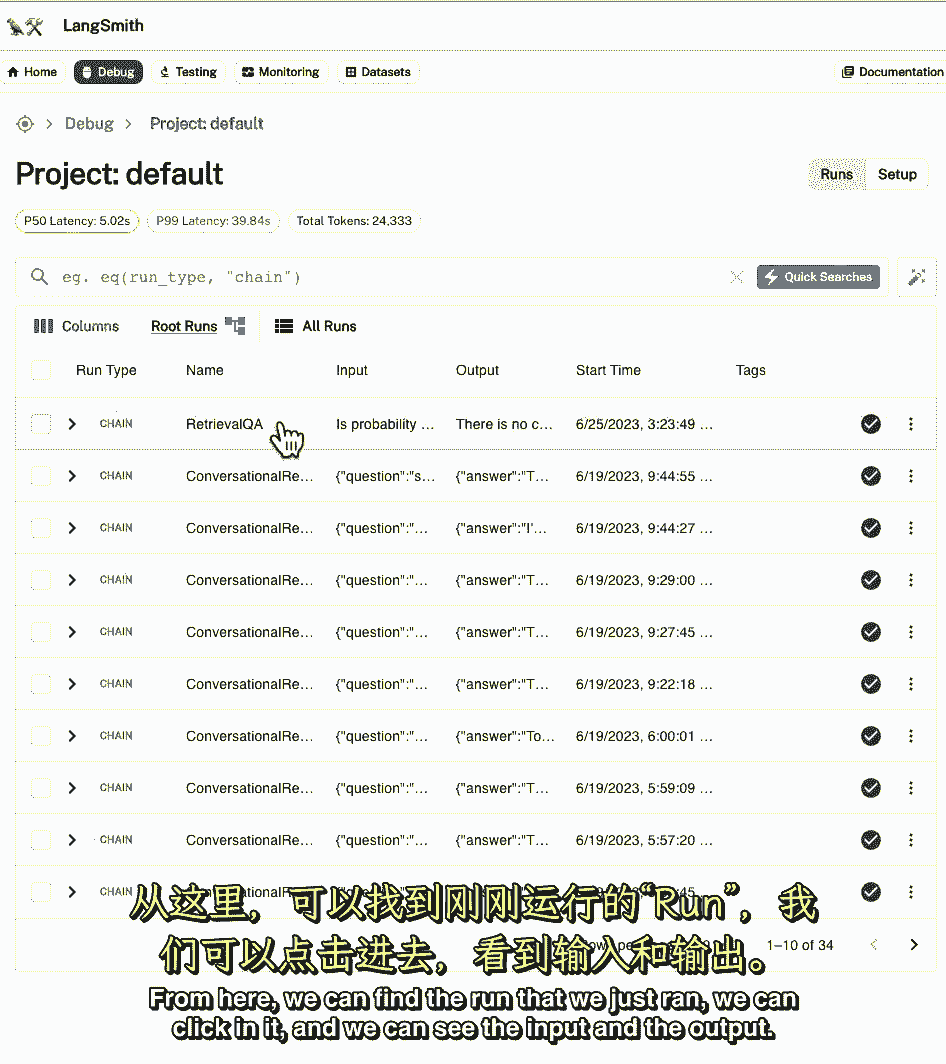
我们可以点击它,我们可以看到输入和输出,然后我们可以看到孩子跑去很好地分析发生了什么,在引擎盖下,第一批,我们有MapReduce文档链,这实际上涉及到对语言模型的四个单独调用。

如果我们点击其中一个电话,我们可以看到我们有每个文档的输入和输出。

如果我们回去,然后我们可以看到,在它运行这些文档之后,它在最后的链条中结合在一起,填充文档链,它将所有这些响应塞进最后的呼叫中,点击进入。
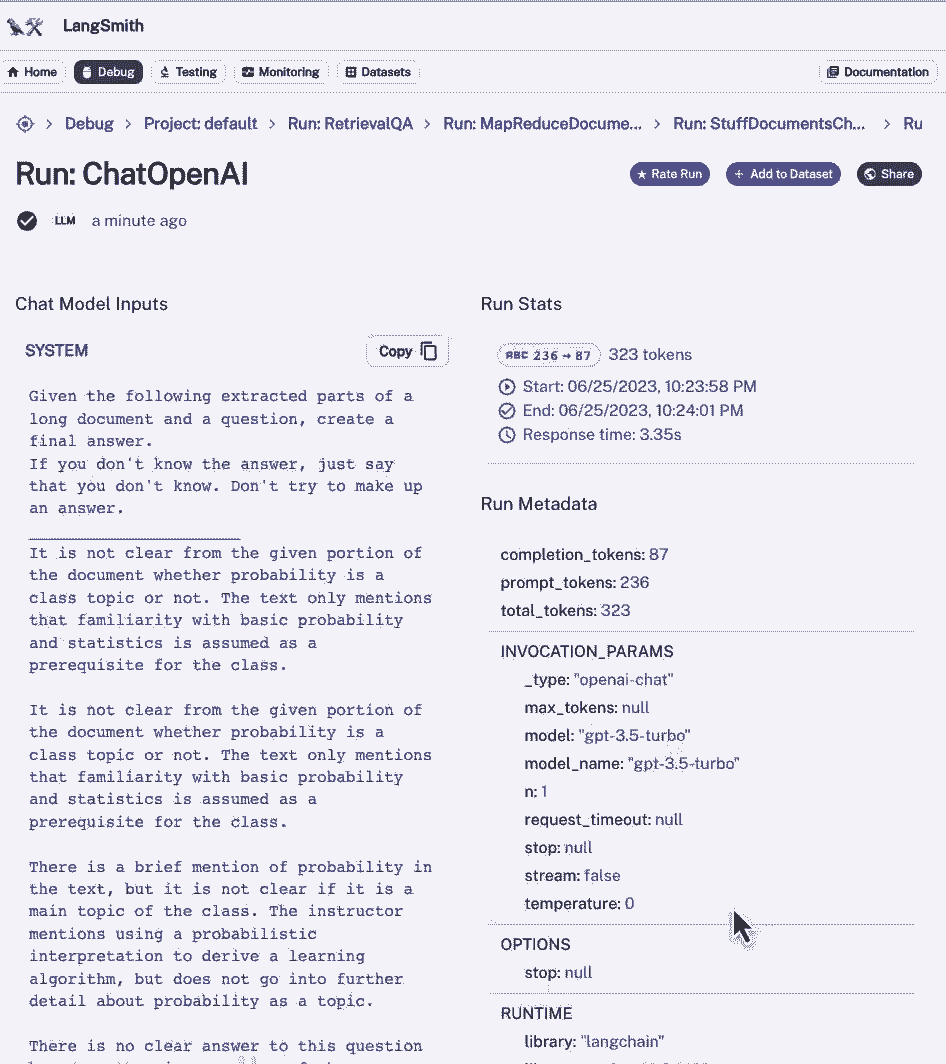
我们可以看到我们得到了系统消息,我们从以前的文件中得到了四个摘要,然后用你的问题,然后我们就有了答案,我们可以做类似的事情,将链类型设置为细化。

这是一种新型的链条,让我们看看引擎盖下面是什么样子,我们可以看到它正在调用精炼文档链,包括4次连续呼叫,让我们来看看这个链中的第一个调用,来看看这里发生了什么,在它被发送到语言模型之前。
我们已经得到了提示,我们可以看到一个由几个比特组成的系统消息,这篇文章的上下文信息如下,是系统消息的一部分,它是我们提前定义的提示模板的一部分,下一段,这里的所有文字,这是我们检索到的文件之一。
下面是用户的问题,答案就在这里,如果我们回去,我们可以在这里查看对语言模型的下一个调用,我们发送给语言模型的最后一个提示,是将以前的响应与新数据相结合的序列,然后要求改进回应。
所以我们可以在这里看到我们得到了最初的用户问题。

我们就得到了答案,这是和以前一样的,然后我们说我们只有机会改进现有的答案,如果需要,请在下面提供更多上下文,这是提示模板的一部分,部分说明,剩下的部分是我们检索列表中第二个文档的文档,然后我们可以看到。
在新的上下文中,我们有更多的指示,改进原始答案以更好地回答问题,然后在下面我们得到了最终的答案,但这只是第二个最终答案,所以它运行了四次,在得到最终答案之前,它会遍历所有的文档,最终的答案就在这里。
这门课假定熟悉基本的概率和统计学,但是我们会有复习部分来刷新先决条件,您会注意到这是一个比地图缩减链更好的结果,这是因为使用细化链确实允许您组合信息,尽管按顺序。
它实际上鼓励了比mapreduce链更多的信息传递,这是一个暂停的好机会,尝试一些问题,尝试一些不同的链条,尝试一些不同的提示模板,看看它在UI中是什么样子的,这里有很多东西可以玩。
聊天机器人的伟大之处之一,为什么它们变得如此受欢迎是因为你可以问后续的问题。

你可以要求澄清以前的答案,所以让我们在这里做,让我们创建一个QA链,我们就用默认的东西。

我们去问问吧,一个问题是概率,课堂主题。

然后让我们问它一个后续问题,它提到概率应该是一个先决条件,所以让我们问,为什么需要这些先决条件,然后我们得到答案。

这门课的先决条件假定是计算机科学的基础知识。

以及与之前答案完全无关的基本计算机技能和原理,我们在问概率,这是怎么回事,基本上,我们使用的链没有任何状态的概念,它不记得以前的问题或以前的答案是什么,为此我们需要引入记忆。

【LangChain大模型应用开发】DeepLearning.AI - P15:7——完整功能的聊天机器人 - 吴恩达大模型 - BV1iZ421M79T

我们离拥有一个功能正常的聊天机器人如此之近,我们从装载文件开始,然后我们把他们分开,然后我们创建了一个向量存储,我们谈到了不同类型的检索,我们已经证明了我们可以回答问题,但是我们不能处理后续的问题。
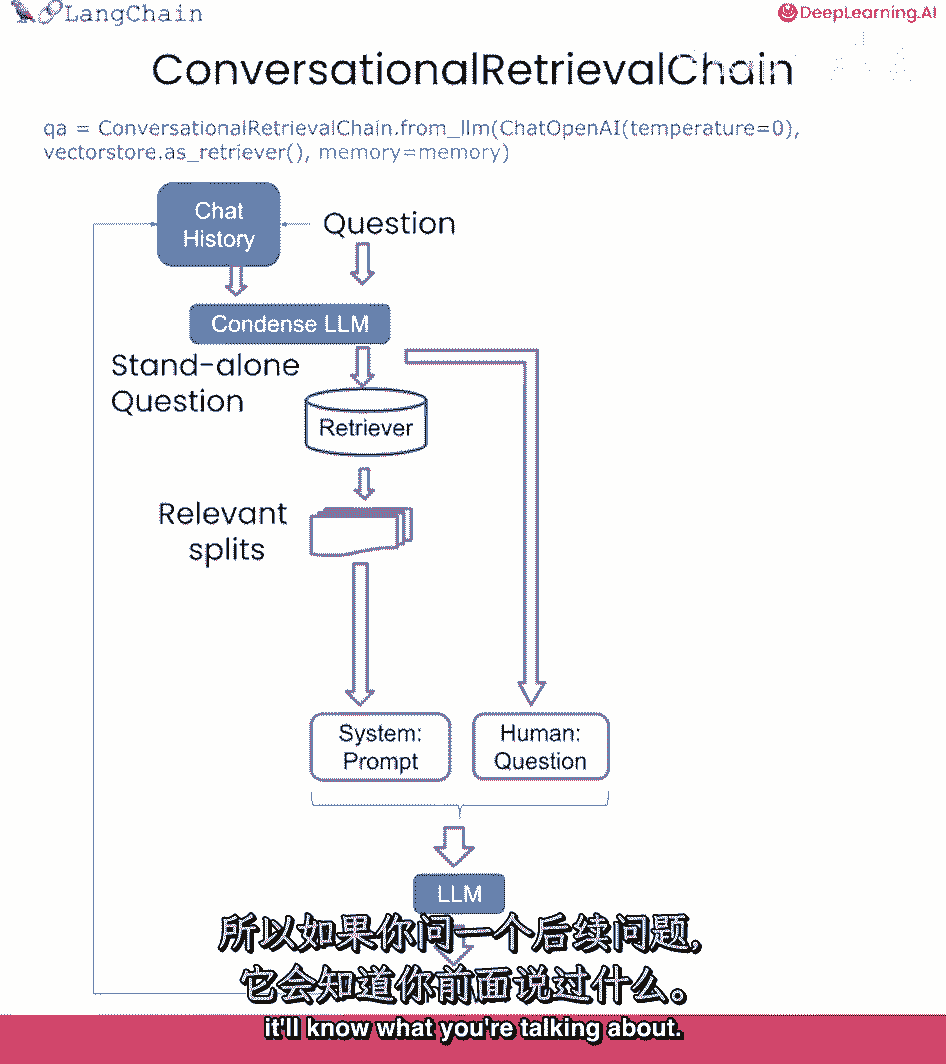
我们不能和它进行真正的对话,好消息是,我们会解决的,在这节课中,让我们弄清楚,我们现在要做一个问题来结束,回答聊天,它要做的是看起来和以前非常相似,但我们要加入聊天历史的概念。
这是您以前与连锁店交换的任何对话或信息,这将允许它做什么,它会允许它将聊天历史纳入上下文吗,当它试图回答问题时,所以如果你问一个后续问题,它会知道你在说什么。
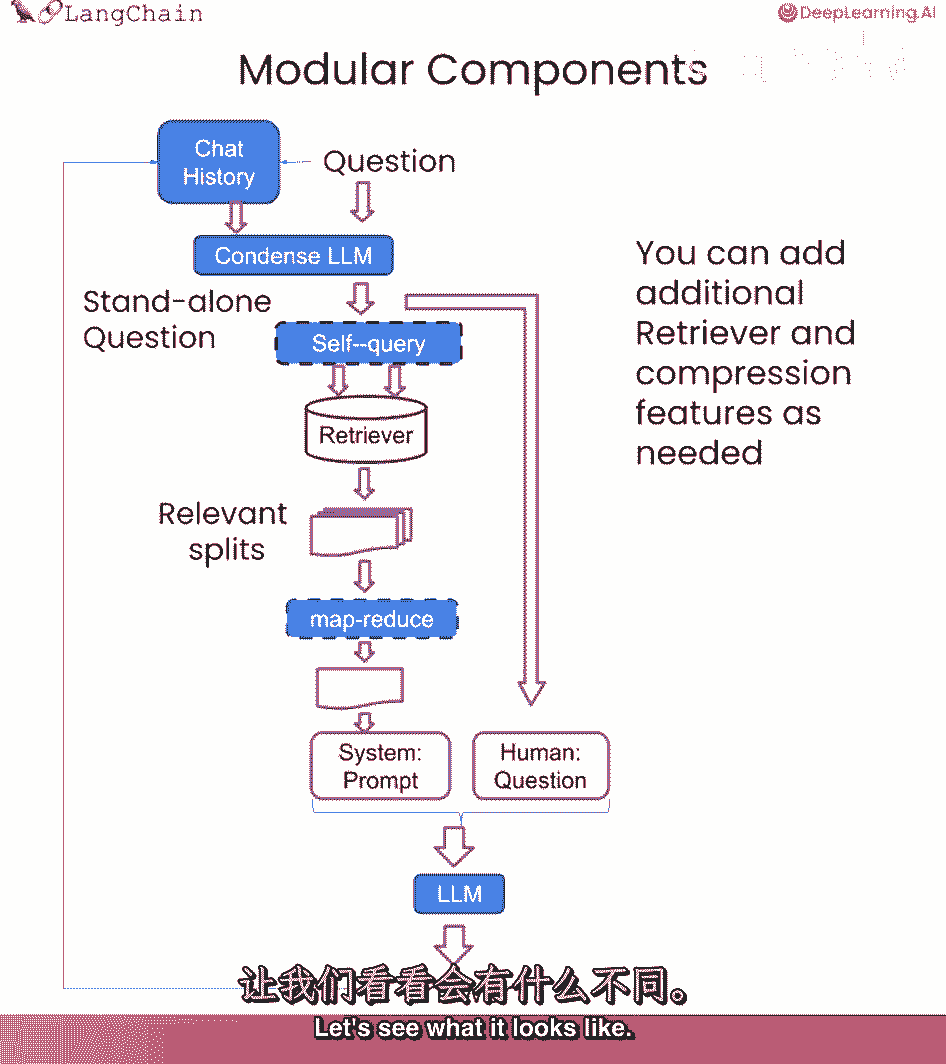
要注意的一件重要的事,到目前为止,我们谈到的所有很酷的检索类型,像自查询或压缩,或者类似的东西,你绝对可以在这里使用它们,我们谈到的所有组件都是非常模块化的,可以组合在一起,很好。
我们只是加入了聊天历史的概念。
让我们先看看它是什么样子,一如既往,我们要加载环境变量。

如果你设置了平台,打开它也可能很好,从一开始,会有很多很酷的东西想看,引擎盖下是怎么回事。

我们将加载我们的向量存储,其中包含所有的嵌入,所有的课堂材料。

我们可以在向量存储上进行基本相似性搜索。

我们可以初始化我们将用作聊天机器人的语言模型。

然后,这都是以前的。

这就是为什么我这么快就浏览了一遍,我们可以初始化一个提示模板,创建检索QA链,然后递进一个问题,得到一个结果。

但现在让我们做更多,让我们给它添加一些记忆,所以我们将使用会话缓冲内存,它的作用是,它只是简单地保留一个列表,历史上聊天消息的缓冲区,它会把这些和问题一起传递给聊天机器人,每次我们要指定内存键。
聊天历史记录,这只是将它与提示符中的一个输入变量对齐,然后我们将指定返回消息等于true,这将以消息列表的形式返回聊天历史记录,与单个字符串相反,这是最简单的内存类型,可以更深入地研究内存。
回到我和安德鲁教的第一堂课,我们详细报道了这件事。

然后呢,现在让我们创建一种新型的链,会话检索链,我们传入语言模型,我们通过寻回器,我们通过记忆,会话检索链在检索的基础上增加了一个新的位,Qa链,不仅仅是记忆,尤其是,它增加的是,它增加了一个步骤。
带着历史和新的问题,把它浓缩成一个独立的问题,传递到向量存储,查阅有关文件,我们将在UI中查看这一点,在我们运行它,看看它有什么影响。

但现在让我们试试,我们可以问一个问题,这是没有任何历史的。

看看我们得到的结果,然后我们可以问一个后续问题,这和以前一样,所以我们要问的是,课堂主题,我们得到一些答案,教师假设学生对概率和统计学有基本的了解,然后我们问,为什么需要这些先决条件,我们得到一个结果。
让我们看看。

我们得到一个答案,现在我们可以看到答案是指基本的概率和统计作为先决条件,在此基础上,不要把它与计算机科学混淆。

就像以前一样。
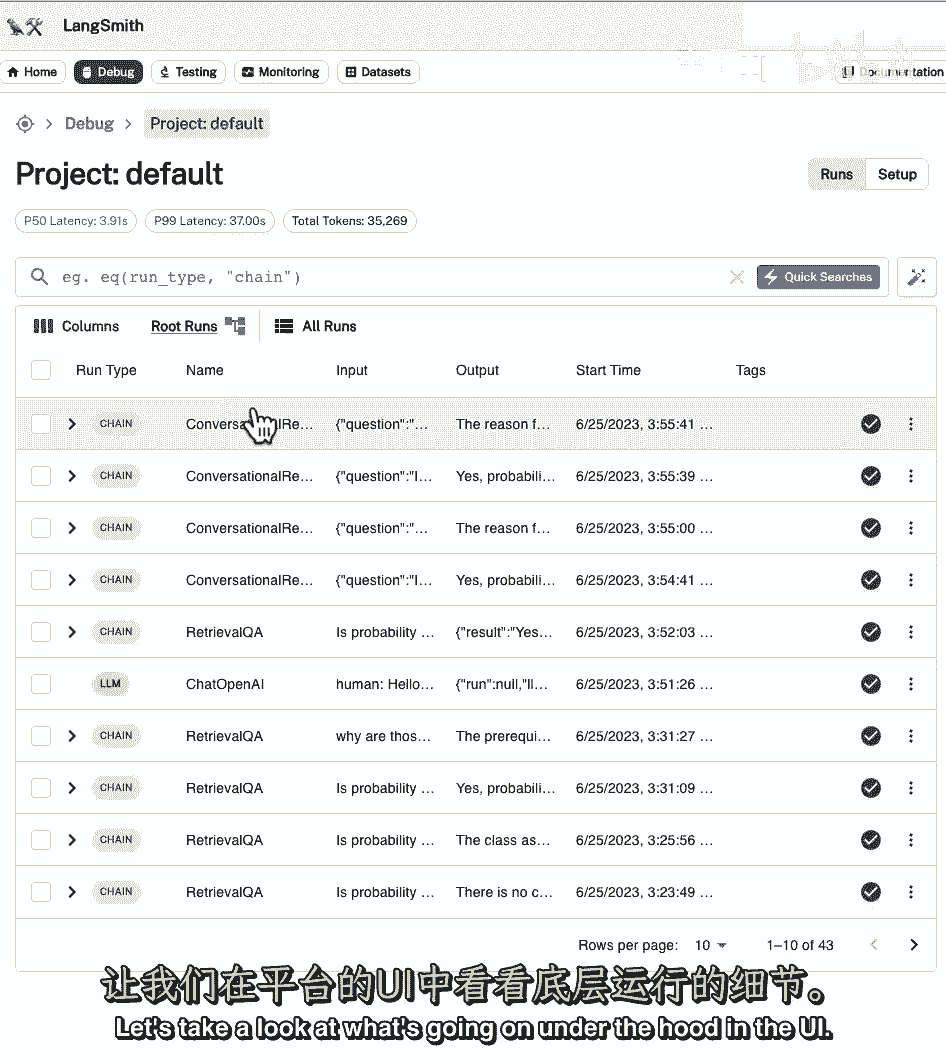
让我们来看看UI的引擎盖下发生了什么,所以在这里我们已经可以看到有更多的复杂性。

我们可以看到,现在链的输入不仅有问题。

也是聊天历史,聊天历史是从记忆中走来的,这将在链被调用并登录到日志系统之前应用。

如果我们看一下痕迹,我们可以看到有两件独立的事情在发生,首先是对一个项目的调用,然后有人打电话给填充文件链,让我们来看看第一个电话。

我们可以在这里看到一个带有一些说明的提示符,鉴于下面的对话,后续问题,将后续问题改写为独立问题。

这里我们有以前的历史,所以我们有一个问题,我们首先问的是课堂主题的概率,然后我们就有了帮助答案,然后在这里我们有一个独立的问题,要求基本概率和统计作为类的先决条件的原因是什么。
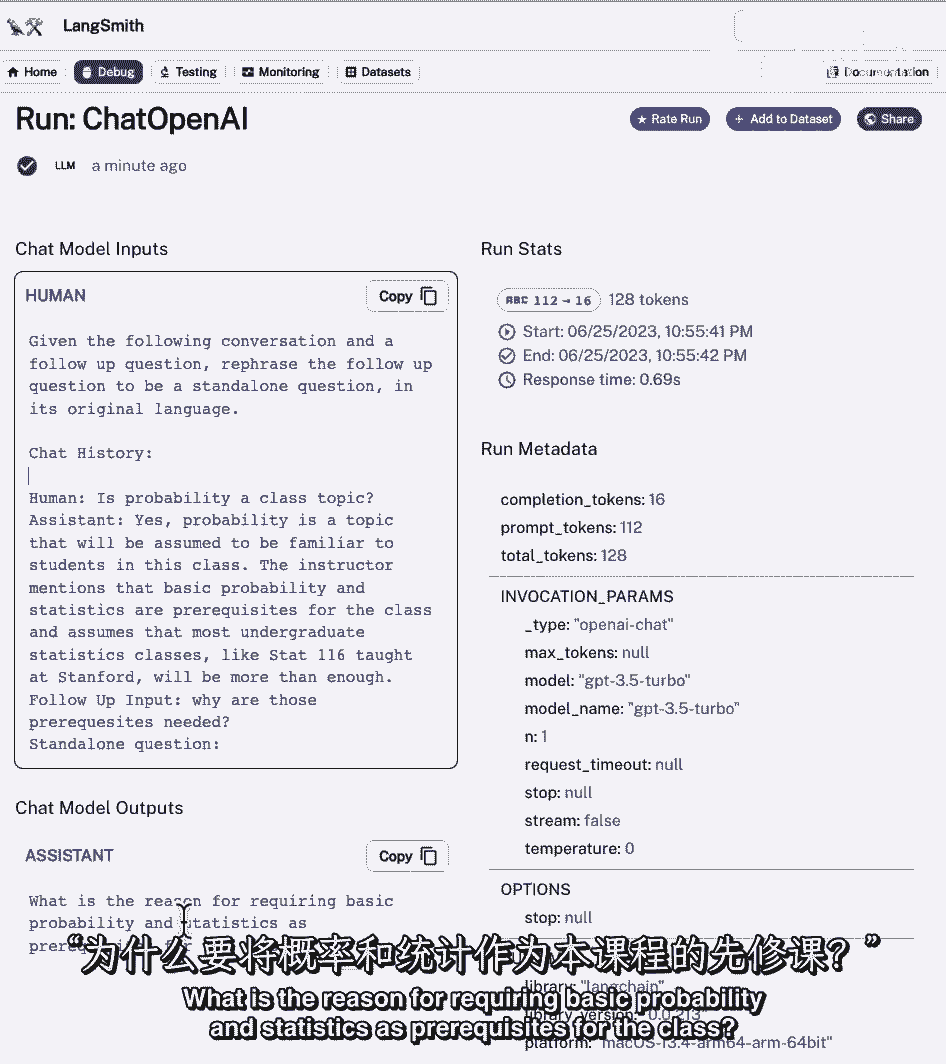
发生的情况是,独立的答案随后被传递给检索器,我们取回四或三份文件,或者不管有多少,我们指定,然后,我们将这些文档传递到填充文档链,并试图回答最初的问题。

所以如果我们调查一下,我们可以看到我们有了系统答案,使用以下上下文来回答用户的问题。
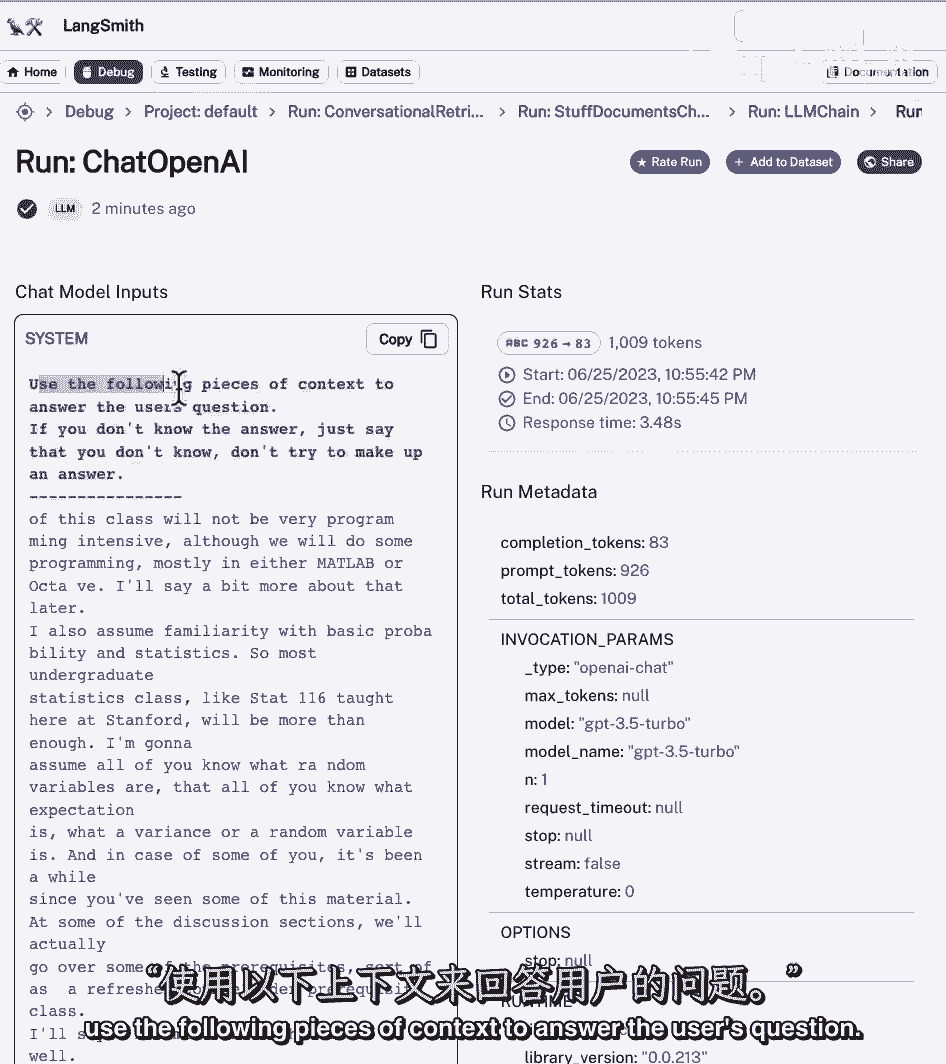
我们有一堆背景。

然后我们在下面有问题的摊位,然后我们得到一个答案,以下是与手头问题相关的答案。

它是关于概率和统计作为先决条件,现在是暂停并尝试这个链的不同选项的好时机,您可以传递不同的提示模板,不仅仅是为了回答问题,但也因为把它变成了一个独立的问题。

您可以尝试不同类型的内存,有很多不同的选择可以离开这里。

在这之后,我们要把它放在一个漂亮的UI中,会有很多代码来创建这个用户界面,但这是最重要的一点。

尤其是,这是一个完整的演练,基本上整个班,所以我们要加载一个数据库和检索链,我们要传递一份文件,我们要用PDF加载器加载它,他们会把它加载到文档中,我们要把那些文件分开,我们将创建一些嵌入。
并将其放在向量存储中,然后我们要把矢量存储变成寻回器。

我们将在这里使用相似性和一些K的搜索线。

我们将其设置为一个参数,我们可以传入,然后我们将创建会话检索链,这里要注意的一件重要的事情是,我们不是在记忆中传递,我们将从外部管理内存,为了方便下面的GUI,这意味着聊天历史将不得不在链外进行管理。

然后我们在这里有更多的代码--我们不会在上面花太多时间,但指出这里我们在聊天历史中传递到链中。

这也是因为我们没有附加的记忆。

然后我们在这里扩展聊天历史记录,有了结果,然后我们就可以把它放在一起了,运行这个来获得一个漂亮的用户界面,通过它我们可以与我们的聊天机器人交互,然后呢,我问你一个问题,助教是谁。

助教是保罗,布淀粉。

张凯蒂,你会注意到这里有几个标签,我们也可以点击查看其他东西。

所以如果我们点击数据库,我们可以看到我们对数据库提出的最后一个问题。

以及我们从那里得到的消息,这些是文件。

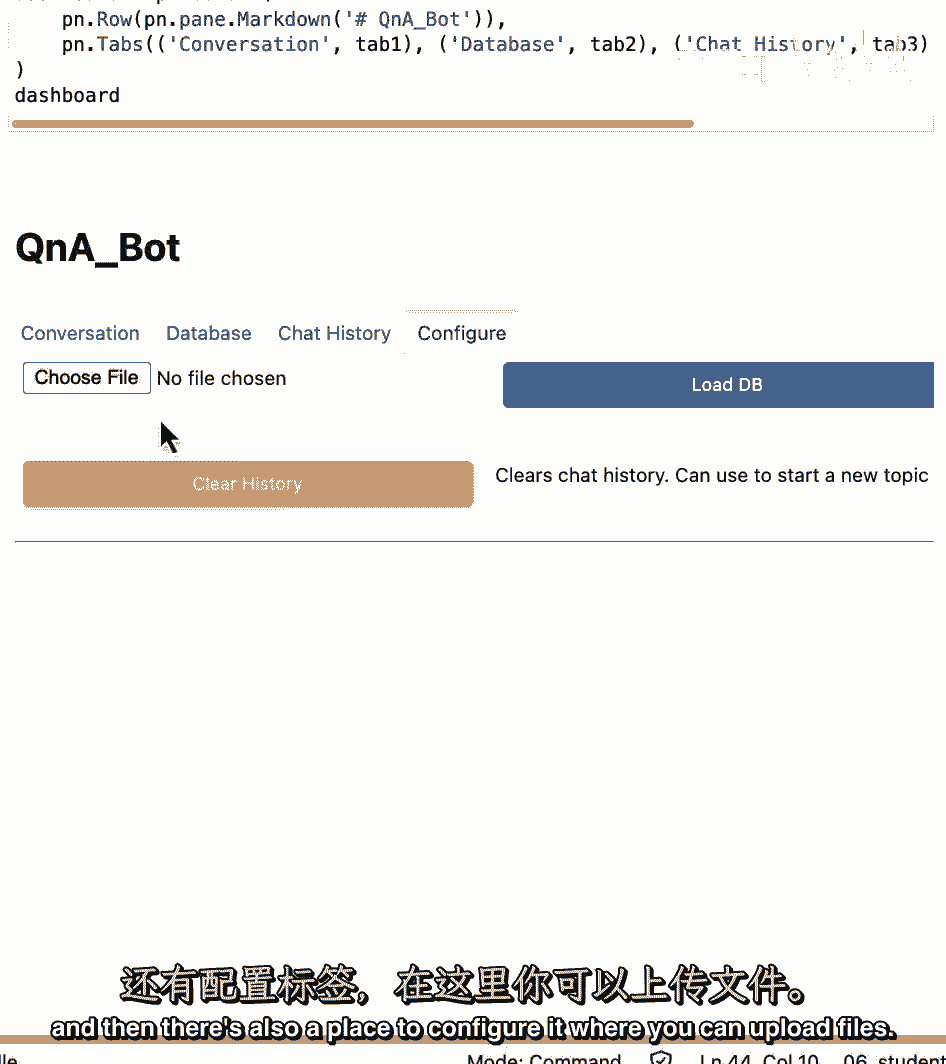
这些是在分裂发生后,这些是我们检索到的每个块,我们可以看到带有输入和输出的聊天历史记录。

然后还有一个地方来配置它,在那里你可以上传文件。
我们也可以要求跟进,所以让我们问问他们的专业是什么。
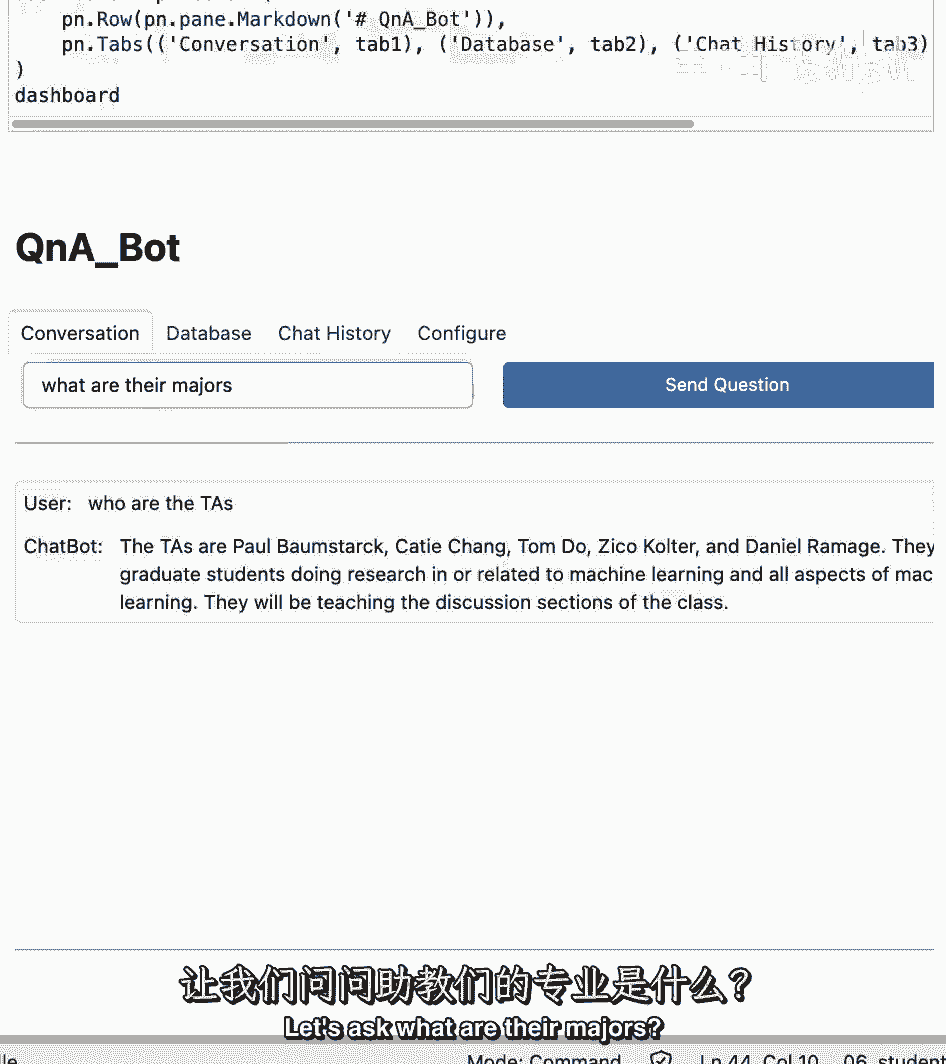
我们得到了关于前面提到的TA的答案,我们可以看到保罗正在学习机器学习和计算机视觉,凯蒂其实是个神经学家。

这节课基本上就结束了,所以现在是暂停的好时机,再问它一堆问题,在这里上传您自己的文档,享受这个端到端的问题回答机器人,配有令人惊叹的笔记本UI,这就结束了与您的数据进行车道链聊天的课程,在这门课上。
我们已经介绍了如何使用链接链从各种文档源加载数据,使用链接链,80多个不同的文档加载器,从那里我们把文件分成几块,并谈论许多这样做的细微差别,然后我们把这些大块,为它们创建嵌入,把它们放进矢量仓库。
展示了如何轻松地启用语义搜索,但我们也讨论了语义搜索的一些缺点,它可能在某些边缘失败的地方出现下一件事,我们涵盖的是检索,可能是我最喜欢的部分,在那里我们讨论了许多新的、先进的、非常有趣的检索算法。
为了克服这些边缘情况,我们在下一次会议上把它和llms结合起来,我们把那些检索到的文件,我们接受用户的问题,我们把它交给一个LLM,我们对最初的问题产生一个答案,但还缺一样东西,这是它的对话方面。
我们就在那里上完了课,通过在数据上创建一个功能齐全的端到端聊天机器人,我真的很喜欢教这门课,我希望你们喜欢,我要感谢开源领域的每一个人,他为这门课的成功做出了很多贡献。
就像你看到的所有提示和许多功能一样,当你们和朗链一起建造的时候,并发现新的做事方式、新的技巧和技巧,我希望你在推特上分享你所学到的东西,甚至在链接链中开设公关,这是一个变化非常快的领域。
这是一个激动人心的时刻。
【LangChain大模型应用开发】DeepLearning.AI - P16:8——完结 - 吴恩达大模型 - BV1iZ421M79T

这就结束了与您的数据进行长链聊天的课程,在这门课上,我们已经介绍了如何使用链接链从各种文档源加载数据,使用链接链,80多个不同的文档加载器,从那里我们把文件分成几块,并谈论许多这样做的细微差别。
然后我们把这些大块,为它们创建嵌入,把它们放进矢量仓库,展示了如何轻松地启用语义搜索,但我们也讨论了语义搜索的一些缺点,在某些边缘情况下它可能会失败,接下来我们讨论的是检索,可能是我最喜欢的部分。
在那里我们讨论了许多新的、先进的、非常有趣的检索算法,为了克服这些边缘情况,我们在下一次会议上把它和llms结合起来,我们把那些检索到的文件,我们接受用户的问题,我们把它传给一个LLM。
我们对最初的问题产生一个答案,但还缺一样东西,这是它的对话方面,这就是我们通过创建一个功能齐全的端到端来完成这个类的地方,通过您的数据聊天机器人,我真的很喜欢教这门课,我希望你们喜欢。
我要感谢开源领域的每一个人,他为这门课做出了很多贡献,就像你看到的所有提示和许多功能一样,就像你们和朗链一起建造一样,并发现新的做事方式、新的技巧和技巧,我希望你在推特上分享你将学到的东西。
甚至在链接链中开设公关,这是一个变化非常快的领域,这是一个激动人心的时刻。

我真的很期待看到你是如何申请的。
【LangChain大模型应用开发】DeepLearning.AI - P2:2——模型,提示和输出解析 - 吴恩达大模型 - BV1iZ421M79T

第一课,第一课。

将涵盖模型,将涵盖模型,提示和解析器,提示和解析器,所以模型指语言模型,所以模型指语言模型,支撑很多方面,支撑很多方面,提示指创建输入的风格,提示指创建输入的风格,然后解析器在另一端。
然后解析器在另一端,涉及将模型输出解析为更结构化的格式,涉及将模型输出解析为更结构化的格式,以便下游使用,以便下游使用,所以当你使用lm构建应用时,所以当你使用lm构建应用时,通常会有可重用模型。
通常会有可重用模型,我们反复提示模型,我们反复提示模型,解析输出,解析输出,因此启动提供了一组简单的抽象来执行此类操作,因此启动提供了一组简单的抽象来执行此类操作。
所以让我们深入了解一下模型、提示和解析器,所以让我们深入了解一下模型、提示和解析器,要开始,要开始。

这里是一些起始代码,这里是一些起始代码,我将导入os、openai并加载我的openai密钥,我将导入os、openai并加载我的openai密钥。
openai库已经安装在我的jupyter笔记本环境中,openai库已经安装在我的jupyter笔记本环境中。

如果你本地运行并且还没有安装open ai,如果你本地运行并且还没有安装open ai。

你可能需要运行pip,你可能需要运行pip,安装open ai,安装open ai。

但我不在这里做,但我不在这里做,然后这是一个辅助函数,然后这是一个辅助函数,这实际上与你在聊天,这实际上与你在聊天,Gpt提示工程开发人员,Gpt提示工程开发人员,课程中看到的辅助函数非常相似。
课程中看到的辅助函数非常相似。

我与open eyes一起提供的fulford,我与open eyes一起提供的fulford。

所以使用这个辅助函数你可以说完成1加1是什么,所以使用这个辅助函数你可以说完成1加1是什么,这将调用try gpc,这将调用try gpc,或技术上模型gpt三点五 turbo给你答案。
或技术上模型gpt三点五 turbo给你答案。

像这样现在为了激励,像这样现在为了激励。

模型提示和解析器的抽象,模型提示和解析器的抽象。

假设你收到一封非英语客户的电子邮件,假设你收到一封非英语客户的电子邮件,嗯,嗯,为确保可访问性,为确保可访问性。

我将使用的另一种语言是英语海盗语言,我将使用的另一种语言是英语海盗语言,当涉及到r时,当涉及到r时,我会很生气,我会很生气。

我的搅拌机盖子飞掉并把我的厨房墙溅满了奶昔,我的搅拌机盖子飞掉并把我的厨房墙溅满了奶昔,更糟糕的是,更糟糕的是。

保修不包括清理厨房的费用,保修不包括清理厨房的费用,我现在需要你的帮助,我现在需要你的帮助,伙计,伙计。

因此我们将要求这个lm将文本翻译成美式英语,因此我们将要求这个lm将文本翻译成美式英语,以冷静和尊重的语气,以冷静和尊重的语气,因此我将将样式设置为美式英语,语气常见且尊重。
因此我将将样式设置为美式英语,语气常见且尊重。

为了实际完成这个,为了实际完成这个,如果你之前看过一些提示,如果你之前看过一些提示。

我将使用f字符串指定提示,包含指令,我将使用f字符串指定提示,包含指令。

然后插入这两种样式,然后插入这两种样式,因此生成提示说,因此生成提示说。

翻译文本等,翻译文本等。

我建议你暂停视频并运行代码,我建议你暂停视频并运行代码,也尝试修改提示以查看是否可以得到不同的输出,也尝试修改提示以查看是否可以得到不同的输出。

你可以,你可以。

然后提示大型语言模型以获取响应,然后提示大型语言模型以获取响应。

让我们看看响应是什么,让我们看看响应是什么,所以它将英语海盗的消息翻译成这种非常礼貌的,所以它将英语海盗的消息翻译成这种非常礼貌的。

我真的很沮丧,我的搅拌机盖飞掉了,我真的很沮丧,我的搅拌机盖飞掉了。

把我的厨房墙搞得一团糟,把我的厨房墙搞得一团糟,如此顺滑的奶昔等,如此顺滑的奶昔等,我现在真的需要你的帮助,我现在真的需要你的帮助。

我的朋友那听起来很好,我的朋友那听起来很好,所以如果你有不同的客户用不同的语言写评论,所以如果你有不同的客户用不同的语言写评论。

不仅仅是英语海盗,不仅仅是英语海盗,而是法语,而是法语,德语,德语。

日语等等,日语等等,你可以想象需要生成一整序列的提示来生成这样的翻译,你可以想象需要生成一整序列的提示来生成这样的翻译。

让我们看看如何以更方便的方式做到这一点,让我们看看如何以更方便的方式做到这一点,使用lang chain,使用lang chain。

我将导入chat openai,我将导入chat openai,这是lang cha对chat gpt API端点的抽象,这是lang cha对chat gpt API端点的抽象。

因此如果我然后说had等于chat open ai并查看chat是什么,因此如果我然后说had等于chat open ai并查看chat是什么。

它创建了这个对象如下,它创建了这个对象如下,它使用chat gpt模型,它使用chat gpt模型,也称为gpt三点五 turbo,也称为gpt三点五 turbo。

当我构建应用程序时,当我构建应用程序时,我经常会将温度参数设置为等于零,我经常会将温度参数设置为等于零。

所以默认温度是零点七,所以默认温度是零点七,但让我实际上重新做一下,温度,但让我实际上重新做一下,温度,等于零点零,等于零点零,现在温度被设置为零以使其输出稍微少一些随机。
现在温度被设置为零以使其输出稍微少一些随机。


现在让我定义模板字符串如下,现在让我定义模板字符串如下。

将文本翻译成由样式指定的样式,将文本翻译成由样式指定的样式,然后这里是文本,然后这里是文本。

为了反复重用此模板,为了反复重用此模板,让我们导入lang chains,让我们导入lang chains,聊天提示模板,聊天提示模板。

然后让我使用上面编写的模板字符串创建提示模板,然后让我使用上面编写的模板字符串创建提示模板。


从提示模板,从提示模板,你可以实际提取原始提示,你可以实际提取原始提示,它意识到这个提示有两个输入变量,它意识到这个提示有两个输入变量,样式和文本,如这里用花括号所示,样式和文本,如这里用花括号所示。

这里是原始模板,我们实际上也指定了,这里是原始模板,我们实际上也指定了。

嗯,嗯,它意识到有两个输入变量,它意识到有两个输入变量。

样式和文本,样式和文本,现在,现在,确定风格,确定风格,这是客户消息要翻译成的风格,这是客户消息要翻译成的风格,我将称之为客户风格,我将称之为客户风格,这是我之前的客户电子邮件,现在。
这是我之前的客户电子邮件,现在。

如果我创建自定义消息,如果我创建自定义消息,这将生成提示,这将生成提示。

我们将传递这个,我们将传递这个,一分钟后的大语言模型以获取响应,一分钟后的大语言模型以获取响应,所以如果你想看类型,所以如果你想看类型,自定义消息实际上是一个列表,自定义消息实际上是一个列表,嗯,嗯。

如果你看列表的第一个元素,如果你看列表的第一个元素,这基本上是您期望它创建的最后提示,这基本上是您期望它创建的最后提示。

让我们将这个提示传递给LM,让我们将这个提示传递给LM。

因此我将调用聊天,因此我将调用聊天,我们之前说过,我们之前说过,嗯,嗯,作为对OpenAI GPT端点的引用,作为对OpenAI GPT端点的引用。

如果我们打印出客户响应内容,如果我们打印出客户响应内容,那么它会给你回,那么它会给你回,嗯,嗯,从英语海盗翻译成礼貌的美国英语,从英语海盗翻译成礼貌的美国英语,当然你可以想象其他用例。
客户电子邮件是其他语言的,当然你可以想象其他用例,客户电子邮件是其他语言的。

这两个可以用于将消息翻译成英语,这两个可以用于将消息翻译成英语。

说英语的人理解和回复,说英语的人理解和回复,我建议你暂停视频并运行代码,我建议你暂停视频并运行代码,并尝试修改提示以查看您是否可以获得不同的输出现在,并尝试修改提示以查看您是否可以获得不同的输出现在。

希望我们的客户服务代理用他们的原始语言回复了客户,希望我们的客户服务代理用他们的原始语言回复了客户。

所以让我们说,所以让我们说,说英语的,说英语的,客户服务代理出现,客户服务代理出现,说嘿,说嘿,客户保修不包括厨房清洁费用,客户保修不包括厨房清洁费用,因为是你误用搅拌机,用叉子戳盖子。
因为是你误用搅拌机,用叉子戳盖子,运气不好,运气不好,再见,不是很礼貌的信息,再见,不是很礼貌的信息,但假设这是客户服务代理想要的,但假设这是客户服务代理想要的。

我们将指定,我们将指定,服务消息将翻译成这种海盗风格,服务消息将翻译成这种海盗风格,我们希望它是用英语海盗语说的礼貌语调,我们希望它是用英语海盗语说的礼貌语调,因为我们之前创建了提示模板。
因为我们之前创建了提示模板。

酷的是,酷的是,我们现在可以重复使用那个提示模板,我们现在可以重复使用那个提示模板,并指定我们想要的服务风格海盗,并指定我们想要的服务风格海盗,文本是此服务回复,文本是此服务回复,如果我们这样做。
如果我们这样做。

这是提示,这是提示。

如果我们提示,如果我们提示,嗯,chagpt t,嗯,chagpt t。

这是它给我们的回应,这是它给我们的回应,我必须为你进来,保修不包括费用或清洁你的船舱等。

运气不好,法老,我的心,你可能想知道。

为什么使用提示模板而不是,你知道,只是一个f字符串,答案是,随着你构建复杂的应用程序,提示可以相当长和详细。

因此,提示模板是一个有用的抽象,帮助你重用好的提示。

当你能,嗯,这是一个相对较长的提示示例,为在线学习应用程序评分学生的提交。

像这样的问题可能相当长,你可以要求LM首先解决问题,然后以特定格式输出。

并将此包装在lang链中,使用提示使重用这样的提示更容易。

你稍后也会看到lang链为一些常见操作提供了提示,如摘要或问答,或连接到SQL数据库。

或连接到不同的API,因此,通过使用一些lang链内置的提示,你可以快速构建一个应用程序,而不需要um。

设计你自己的提示,lang cha的提示库的另一个方面是它也支持输出解析,我们稍后会讲到这一点,但当你使用一个LLM构建一个复杂的应用程序时,你经常指示LM以特定格式生成其输出,如使用特定关键字。
左侧的例子说明了如何使用一个LLM执行称为链式思维,推理,使用称为React的框架,但不用担心技术细节,但关键是思想是LM在想什么,因为给LM思考的空间,它往往能得出更准确的结论。
然后行动作为关键字来执行具体行动,然后观察显示它从该行动中学到了什么,等等,如果你有一个提示,指示LM使用这些特定关键字,思想,行动和观察,然后可以将这个提示与解析器耦合。
以提取出带有这些特定关键字标记的文本,因此,这共同提供了一个很好的抽象,来指定输入给LM,并让解析器正确解释,让我们回到一个输出解析器的例子。

在这个例子中,让我们看看如何让lm输出,并使用lang chain传递该输出。

运行我将使用的示例,将是从产品评论中提取信息。

并将该输出格式化为相邻格式。

这是您希望输出的技术示例,这是一个Python字典,其中产品是否为礼物,花费的天数,快递员是5人,价格相当实惠,这是一个期望输出的例子。

这是一个客户评价的例子。

以及尝试达到该JSON输出的模板,这是一个客户评价,睡眠模糊效果相当惊人,它有4个设置,蜡烛吹灭器,性别,微风,风城与龙卷风,两天后到达,及时为妻子周年礼物,我认为我妻子很喜欢,她至今无语。
我一直是唯一使用者等,以下为文本评论模板,从指定信息提取,这是动图吗,这种情况下是,因为这是个动图,还有送货日期,送达用了多久,看起来,这次两天就到了,价格多少,你知道,稍微贵点,鼓风机等。

因此,将评论模板作为输入的LM,客户评论,并提取这三个字段,然后格式化为输出,嗯,使用以下键。

好的,所以这是如何用lang chain包装的。

让我们导入聊天提示模板,我们之前已导入,技术上这行多余,但我会再导入,然后从评审模板创建提示模板。

这是提示模板。

类似我们之前使用提示模板,创建要传递给Open Eye的消息,嗯,端点,处理开放端点,调用该端点,然后打印响应,鼓励你暂停视频并运行代码。


就是它,它说,如果为真,这是二,价格值看起来也很准确。

嗯,但请注意,如果我们检查。

响应的类型,这实际上是一个字符串,所以看起来像JSON,看起来像键值对,但实际上不是一个字典,这只是一个长字符串。

所以我想做的是去响应内容并获取。

如果键的值,应该是真,但运行这个,应该会报错,因为,嗯。

这实际上是一个字符串,这不是Python字典,所以让我们看看如何使用Lang Chains解析器。

为了做到这一点。

我将导入,响应模式和结构化输出解析器从Lang Chain,并告诉它我想要暂停。

通过指定这些响应模式。

所以礼物模式名为礼物,描述是购买的礼物送给别人。

回答真或是,假,如果不是,那么未知。

等等,所以有一个好的模式,交付模式价格值模式,然后将它们全部放入列表如下。

现在我已经指定了这些模式的启动,实际上可以给你提示本身,输出为正,告诉你指令,若打印格式指令,她有精确指令,生成可解析输出,这是新评论模板。

评论模板含格式指令。


可从模板创建提示。

创建传递给OpenAI的消息。

若想,可查看实际提示,含提取熔断器指令,若送货天数,价格值,这是文本,然后这是格式指令,最后,若调用OpenAI端点,看看响应,现在这样。

若使用创建的输出解析器。

可传入输出字典。

区域打印看起来像这样。


非字符串,可提取与礼物键关联的值,或与送货天数关联的值。

或提取与价格值关联的值。

这是将LM输出。

解析为Python字典。

使输出便于下游处理,建议暂停视频并运行代码,模型、提示和解析结束,希望你能重用提示模板,轻松分享,与合作者,甚至使用Lang Chains内置模板,如你刚见。

常与输出解析器结合,使输入提示到特定格式输出,然后解析器解析该输出,存储数据于Python字典。

或其他数据结构,便于下游处理。

希望这在你的应用中很有用。

就这样,让我们看下一个视频,Lang Chain如何帮你建更好的聊天机器人,或让LM,更有效地聊天。

【LangChain大模型应用开发】DeepLearning.AI - P3:3——记忆 - 吴恩达大模型 - BV1iZ421M79T


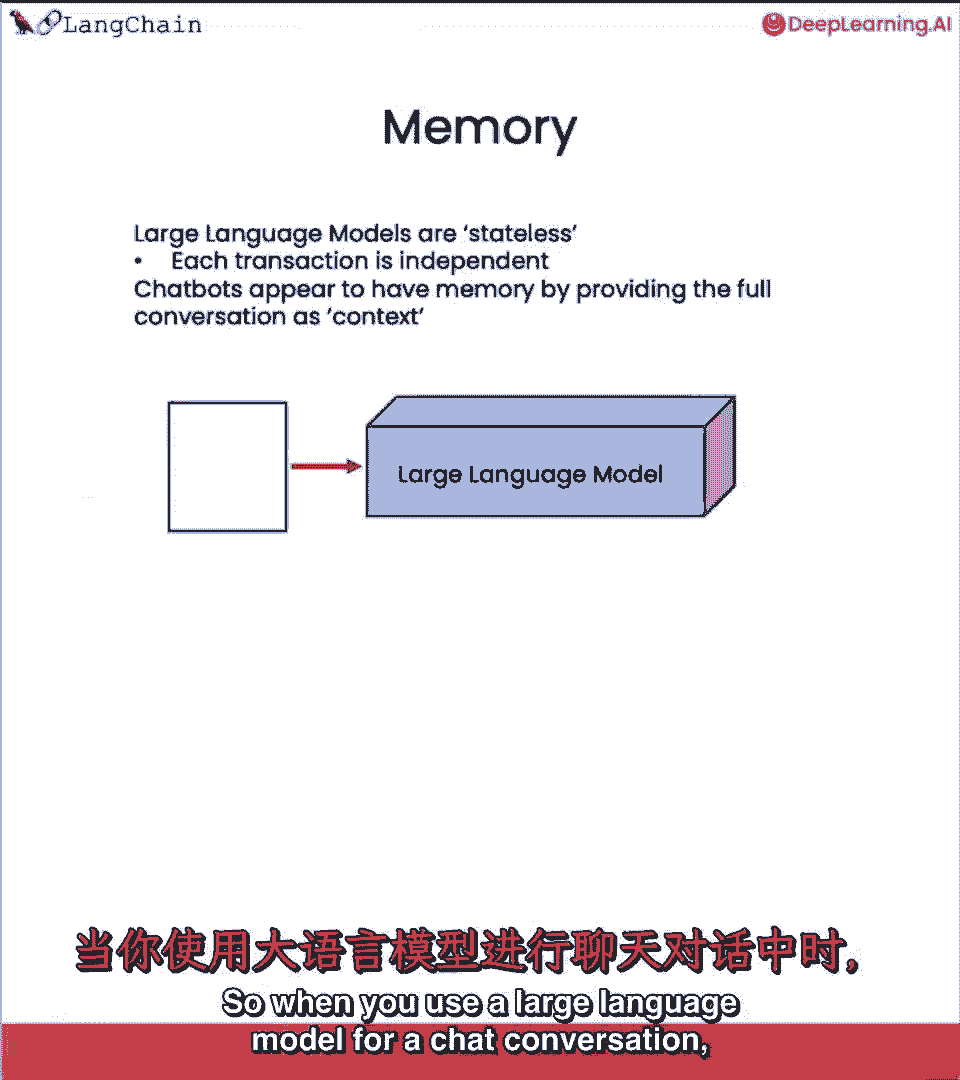
与这些模型互动时,与这些模型互动时,它们自然不记得你之前说过什么或之前的对话,它们自然不记得你之前说过什么或之前的对话,这是一个问题,这是一个问题,当你构建如聊天机器人等应用时,你想与他们交谈。
当你构建如聊天机器人等应用时,你想与他们交谈,因此,在这一节中我们将涵盖记忆,因此,在这一节中我们将涵盖记忆,基本上是如何记住对话的前一部分并将其输入语言模型。
基本上是如何记住对话的前一部分并将其输入语言模型,这样,当你与他们互动时,它们可以有这种对话流程,这样,当你与他们互动时,它们可以有这种对话流程,是的,是的,lang提供了多种高级选项来管理这些记忆。
lang提供了多种高级选项来管理这些记忆,让我们深入了解一下,让我们深入了解一下,首先导入API密钥,首先导入API密钥。

然后导入所需工具,然后导入所需工具。

以记忆为例,以记忆为例。

使用lag链管理聊天或聊天机器人对话,使用lag链管理聊天或聊天机器人对话。

为此,为此,我将设置lm为OpenAI的聊天界面,我将设置lm为OpenAI的聊天界面。

温度为0,温度为0,并将内存用作对话缓冲内存,并将内存用作对话缓冲内存。

稍后您将看到这意味着什么,稍后您将看到这意味着什么,嗯,嗯,稍后我将重建对话链,稍后我将重建对话链。

在这门短课中,在这门短课中,哈里森将更深入探讨链的本质和土地链,哈里森将更深入探讨链的本质和土地链,现在不必太担心语法的细节,现在不必太担心语法的细节,但这构建了一个LLM,但这构建了一个LLM。
如果我开始对话,如果我开始对话,对话点预测,对话点预测,给定输入嗨,给定输入嗨。

我叫安德鲁,我叫安德鲁,看看它说什么 你好,看看它说什么 你好,很高兴见到你等,很高兴见到你等,然后假设我问它,然后假设我问它,一加一等于几,一加一等于几,嗯,一加一等于二,嗯,一加一等于二。
然后再次问它,然后再次问它,你知道我的名字吗,你知道我的名字吗,你的名字是安德鲁,你的名字是安德鲁,如你之前所说,如你之前所说。

那里有一点讽刺,那里有一点讽刺,不确定,不确定,所以如果你想,所以如果你想,可将此变量设为真查看实际操作,可将此变量设为真查看实际操作。

运行predict high时,运行predict high时,我叫安德鲁,我叫安德鲁,这是lang chain生成的提示,这是lang chain生成的提示。

它说以下是人类与AI的对话,它说以下是人类与AI的对话。

健谈等,健谈等,这是lang chain生成的提示,这是lang chain生成的提示,让系统有希望和友好对话,让系统有希望和友好对话,并保存对话,并保存对话,这里是回应,这里是回应,当你执行这个时。
当你执行这个时。

嗯,嗯,因果的第二三部分,因果的第二三部分,它保持提示如下,它保持提示如下,注意当我念出我的名字时,注意当我念出我的名字时,这是第三个术语,这是第三个术语。

这是我的第三个输入,这是我的第三个输入,它已将当前对话存储如下,它已将当前对话存储如下。

你好,我叫安德鲁,你好,我叫安德鲁,1加1等,1加1等,因此,对话的历史越来越长,因此,对话的历史越来越长。

实际上在顶部,实际上在顶部,我用内存变量存储了记忆,我用内存变量存储了记忆。

所以如果我打印内存缓冲,所以如果我打印内存缓冲,它已存储到目前为止的对话,它已存储到目前为止的对话。

你也可以打印这个,你也可以打印这个。

内存加载内存变量,内存加载内存变量,嗯,嗯,这里的花括号实际上是一个空字典,这里的花括号实际上是一个空字典。

有一些更高级的功能你可以使用,有一些更高级的功能你可以使用。

但在这门短课程中我们不会讨论它们,但在这门短课程中我们不会讨论它们,所以不用担心,所以不用担心。

为什么这里有一个空的花括号,为什么这里有一个空的花括号,但这是lang chain记住的,但这是lang chain记住的。

到目前为止对话的记忆,到目前为止对话的记忆,它只是AI或人类所说的一切,它只是AI或人类所说的一切,我鼓励你暂停视频并运行代码,我鼓励你暂停视频并运行代码。

lang chain存储对话的方式是使用这个对话缓冲内存,lang chain存储对话的方式是使用这个对话缓冲内存。

如果我使用组合,如果我使用组合。

缓冲内存指定几个输入和输出,缓冲内存指定几个输入和输出,这就是你如何向记忆中添加新东西,这就是你如何向记忆中添加新东西。

如果你想明确地这样做,记忆,如果你想明确地这样做,记忆,保存上下文说你好,保存上下文说你好。

怎么了,怎么了,我知道这不是最令人兴奋的对话,我知道这不是最令人兴奋的对话。

但我想让它有一个简短的例子,但我想让它有一个简短的例子,有了这个,这就是记忆的状态,有了这个,这就是记忆的状态。

再次让我实际上显示,再次让我实际上显示,嗯,嗯,内存变量现在,内存变量现在,如果你想添加额外的,如果你想添加额外的。

嗯数据到内存,嗯数据到内存,你可以继续保存更多上下文,你可以继续保存更多上下文,因果继续不多,因果继续不多。

只是冷静地挂着,只是冷静地挂着,如果你打印出内存,如果你打印出内存。

你知道现在有更多的内容,你知道现在有更多的内容,所以当你使用大型语言模型进行聊天对话时,所以当你使用大型语言模型进行聊天对话时。
嗯大型语言模型本身实际上是无状态的,嗯大型语言模型本身实际上是无状态的。
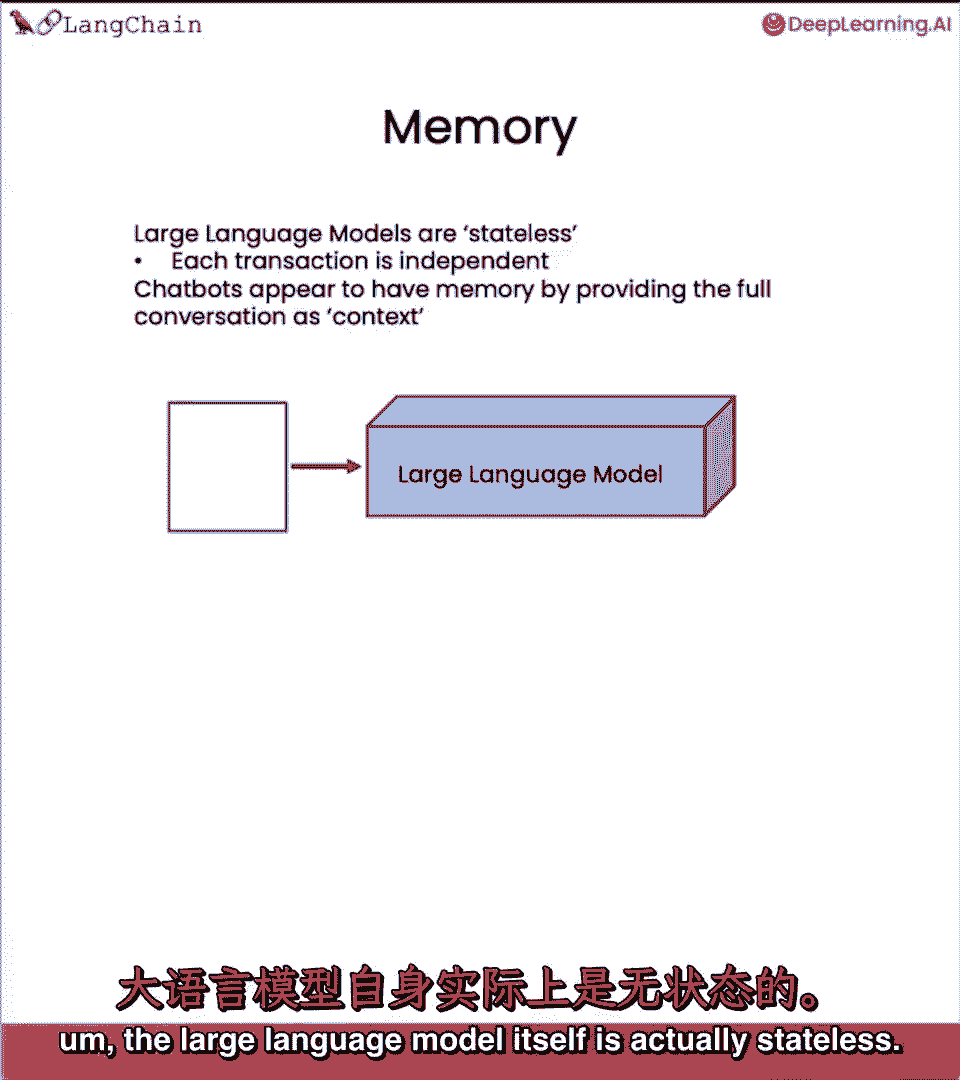
语言模型本身不记对话,语言模型本身不记对话,每笔交易,每笔交易,每次API调用独立,每次API调用独立。
聊天机器人,聊天机器人,仅因为通常有代码提供,仅因为通常有代码提供,迄今为止的完整对话作为上下文,迄今为止的完整对话作为上下文。
因此内存可以明确存储,因此内存可以明确存储。
嗨,嗨,我叫安德鲁,我叫安德鲁,很高兴见到你等,很高兴见到你等,这种内存存储用作输入或附加上下文,这种内存存储用作输入或附加上下文。
以便它们可以生成输出,以便它们可以生成输出,就像只有下一个对话回合,就像只有下一个对话回合。
知道之前说了什么,知道之前说了什么。
随着对话变长,随着对话变长,所需内存量变得非常长,所需内存量变得非常长,发送大量令牌到LM的成本也会增加,发送大量令牌到LM的成本也会增加。
通常按需要处理的令牌数收费,通常按需要处理的令牌数收费。
因此链提供了几种方便的内存类型,因此链提供了几种方便的内存类型。
以存储和累积对话,以存储和累积对话。

我们一直在看对话缓冲内存,我们一直在看对话缓冲内存,让我们看看另一种类型的内存,让我们看看另一种类型的内存。

我将导入对话缓冲窗口AR,我将导入对话缓冲窗口AR。

它只保留一段内存,它只保留一段内存,我设置内存为缓冲窗口内存,k等于一,我设置内存为缓冲窗口内存,k等于一。

变量k等于一,变量k等于一,指定我只想记住一次对话交换,指定我只想记住一次对话交换。

即一次我的回合,即一次我的回合,和一次聊天机器人的发言,和一次聊天机器人的发言。

所以现在如果我让它保存上下文嗨,所以现在如果我让它保存上下文嗨,怎么了,怎么了,不只是挂着,不只是挂着。

如果我查看内存加载变量,如果我查看内存加载变量。

它只记得最近的发言,它只记得最近的发言,注意'嗨'被丢弃,注意'嗨'被丢弃。

怎么了,怎么了,它只说人类说不多,它只说人类说不多,只是挂着,只是挂着,AI说酷,AI说酷。

因为k等于一,因为k等于一,这是一个很好的功能,这是一个很好的功能。

因为它让你跟踪最近的几次对话,因为它让你跟踪最近的几次对话。

实践中你可能不会用k等于一,实践中你可能不会用k等于一,你会用k设置为较大的数字,你会用k设置为较大的数字。

嗯,但这防止了内存无限制增长,嗯,但这防止了内存无限制增长。


随着对话变长,随着对话变长,如果我们重新运行刚才的对话,如果我们重新运行刚才的对话,我们说嗨,我们说嗨,我叫安德鲁,我叫安德鲁。

1加1等于几,1加1等于几,我叫什么名字。

因为k等于一,它只记得最后交流。

哪个是一加一,答案是1,加等于2,然后它忘记了,这个早期交流。

现在说抱歉,我没有访问这些信息。

我希望你会暂停视频,在左边的代码中改为true,并重新运行此对话,verbose等于true。

然后你会看到实际使用的提示。

当你调用lm时,希望你能看到记忆。

我叫什么名字,记忆已经丢失这个交流,我学到,我叫什么名字,这就是为什么现在说不知道,我叫什么名字。

使用对话令牌缓冲记忆,记忆将限制保存的令牌数。

因为许多lm定价基于令牌,这更直接地映射到lm调用的成本。

如果我设定最大令牌限制等于五十,实际上让我插入一些注释。

比如对话是人工智能是什么惊人的反向传播,美丽的教堂是什么迷人的,我用abc作为所有这些国家术语的第一个字母,我们可以跟踪何时说了什么。

如果我以高令牌限制运行,它几乎有整个对话,如果我增加令牌限制到一百,现在它有整个对话,人工智能的标志是什么,如果我减少它,那么你知道它切掉了对话的早期部分,以保留对应最近交流的令牌数。
但受限于不超过令牌限制,如果你想知道为什么我们需要指定,因为不同的lm使用不同的计数令牌方式,所以这告诉它使用聊天openai lm使用的计数令牌方式。

我鼓励你暂停视频并运行代码,并尝试修改提示以查看是否可以得到不同的输出,最后,这里有一种我想说明的最后一种记忆,即对话摘要缓冲记忆。

想法不是限制记忆到固定数量的令牌。

基于最近的陈述,而是基于最相关的陈述,或固定对话次数。

用语言模型写对话摘要。

让那成为记忆,示例如下。

我将创建某人日程长字符串,与产品团队会议,需PPT等,长字符串说。

你的日程如何,你知道,中午在意大利餐厅结束如何,与客户一起,带上笔记本电脑,展示最新电影演示,因此让我使用对话摘要。

缓冲,内存,嗯,最大标记限制为400。

在这种情况下,很高的标记限制,我将要。

我们以'你好'开始的一些对话术语,怎么了,没,就挂着,嗯,酷。

今天日程上有什么,回答是。

你知道那长长的日程,现在这段记忆包含了很多文本。

实际上让我们看看记忆变量,包含全部文本,400个标记足够存储,但若减少最大标记数,比如100个标记,记住存储全部对话历史,若减少标记数至100,实际上使用了OpenAI的lm端点,因为我们说过。
让lm生成对话摘要,所以摘要是人类和AI闲聊,通知人类早会,blah blah blah,嗯,与对AI感兴趣的客户午餐会议,因此,如果我们进行对话,使用此LM,让我创建对话链,与之前相同,嗯。
假设我们要问。

你知道输入,展示什么好呢?我说详细为真,所以这是提示,Dlm认为对话已讨论这些,因为那是对话总结,还有注意点,若熟悉openai聊天API,有特定系统消息,例如中,这不是使用官方OpenAI系统消息。
只是将其作为提示的一部分,但它仍然工作得很好,考虑到这个提示,你知道,输出基本上很有趣,发展正在展示我们最新的NLP能力,好的,那很酷,好吧,你知道,给酷演示提建议,让你思考,如果见客户,我会说,伙计。
若开源框架可用,助我建酷NLP应用,好东西,比如,有趣的是,看内存发生了什么,注意,这里整合了最新AI系统输出,我询问的演示不会好,已集成到系统消息中,嗯,你知道到目前为止的对话概要,缓冲内存。
它试图做的是保持消息的显式存储,直到我们指定的标记数为止,所以你知道这部分显式存储,或尝试限制在一百个标记,因为这是我们要求的,然后任何超出部分它将使用lm生成摘要,这就是上面所见的。
尽管我已用聊天示例,说明了这些不同记忆,这些记忆对其他应用也有用,在那里你可能不断收到文本片段,或不断接收新信息,例如,若系统反复在线搜索事实,但你想保持总记忆量,不要让列表任意增长,我建议你暂停。
视频并运行代码,你看到几种内存。

嗯,包括基于交换次数或标记数的缓冲内存,或可总结超过一定限制标记的内存。

实际上,该链还支持其他类型的内存,最强大的是向量数据内存。

如果你熟悉词嵌入和文本嵌入。

向量数据库实际上存储这样的嵌入(如不知道,别担心)。

别担心,哈里森稍后会解释,然后检索最相关文本块,使用这种向量数据库存储记忆。

Lankan也支持实体记忆,适用于你想记住特定人或特定实体的细节时。

比如谈论特定朋友,可以让Lang Chain记住关于那个朋友的事实,这应该以明确实体方式。

在用Lang Chain实现应用时,也可以使用多种类型记忆。

如使用视频中看到的对话记忆类型之一,另外,还有实体记忆以回忆个人。

这样你可以记住对话的概要,以及关于对话中重要人物的重要事实的明确存储方式。

当然,除了使用这些记忆类型,开发人员将整个对话存储在传统数据库中也不罕见,某种键值存储或SQL数据库。



