吴恩达大模型教程笔记(十一)
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P96:5.L4-rerank.zh - 吴恩达大模型 - BV1gLeueWE5N

欢迎来到第四课,我非常兴奋要向您展示一种我特别喜欢的方法,叫做重新排名。

现在您已经学习了关键词搜索和密集检索,重新排名是一种改进两者方法的方式,而且,它是语义搜索的第二个组成部分。

除了密集检索之外,重新排名是大型语言模型排序搜索结果的一种方式,从最佳的两个词开始,基于它们与查询的相关性。

现在,让我们在实验室中看到重新排名的实际操作,那么让我们从Coherent和Viviate中获取API密钥,然后,我们将导入Cohere,并导入V8,下一步,我们将创建我们的客户端。
这将存储所有维基百科条目,现在,让我们使用密集检索进行搜索,这是我们在上一节课中学到的,我们将导入密集检索函数,现在,让我们搜索以下查询,加拿大的首都是什么,我们将调用答案为密集检索结果。
并且要得到这些结果,我们将使用密集检索函数,使用查询和客户端作为输入,现在如果你记得我们之前有一个可以帮助我们打印结果的函数,很巧它被叫做print result,所以当我们打印结果时,我们得到以下。
所以让我们来看看这些结果,第一个是正确的,它是渥太华,然后我们有一些嘈杂的,多伦多不是加拿大的首都,然后我们还有魁北克市,这是错误的答案,那么为什么这会发生呢,让我来在这里给你展示一个小的示意图。
答案不同,但它是为了理解,所以查询说加拿大的首都是什么,让我们假设可能的响应是这些五个,加拿大的首都是渥太华,哪个是正确的,多伦多在加拿大,虽然正确,但与问题无关,法国的首都是巴黎,这也是正确的。
但不是问题的答案,然后一句错误的句子,加拿大的首都是悉尼,这不是正确的,然后一句话说安大略省的首都是多伦多,这是真的,但也没有回答问题,当我们在这里做好密集检索时,会发生什么,假设这些句子在这里。
加拿大的首都是渥太华,多伦多在加拿大,法国的首都是巴黎,加拿大的首都是悉尼和安大略省的首都是多伦多,所以在嵌入中,让我们想象它们位于这里,现在,记住密集检索的工作方式是,它将查询放入嵌入中。
然后返回最接近的响应,在这种情况下是安大略省的首都是多伦多,密集检索看相似性,所以它返回与问题最相似的响应,这可能不是正确答案,这可能甚至不是真实的陈述,这只是一个恰巧接近问题的句子,因此。
密集检索有潜力返回并非必然是答案的东西,我们如何修复这个问题,这就是排名的作用,现在,让我为您展示一个小型的重新排名的例子,假设查询是加拿大的首都是什么,我们有十个可能的答案,如您所见,一些与问题相关。
一些则不相关,当我们使用密集检索,它给我们返回前五,假设是五个最相似的查询响应,并假设它们是这些,但我们不知道哪个是响应,我们只有有五个句子非常接近查询,这就是重新排名的作用。
重新排名将为每个查询响应对分配一个相关性得分,它告诉您答案的相关性与查询的多少,它也可以是文档,所以文档与查询的相关性是多少,如您所见,最高相关性在这里是0。9,对应于加拿大的首都是渥太华。
这是正确答案,这就是重新排名的作用,您可能想知道排名是如何训练的,嗯,重新排名的训练方法是给它很多良好的对,这就是一个对,其中查询和响应非常相关,或者当查询和文档非常相关时。
并且训练它给出那些高相关性的分数,然后也给它一个大量的错误查询响应,所以查询响应,其中响应不匹配查询的,可能很接近,但可能不匹配,或者也是一个文档,一个可能不匹配查询的文档。
如果你训练一个模型来给好查询响应对的高分数,和坏查询响应对的低分数,那么你就有重新排名的模型,它分配一个相关性,当您有一个查询和一个响应时,相关性很高,因为它们非常相关。

现在,让我们看更多的重新排名示例,让我们用它来改进关键词搜索,所以我们将导入我们在第一课中使用的关键词搜索函数,再次让我们问它加拿大的首都是什么,所以现在让我们使用关键词搜索来找到这个查询的答案。
我们将开始由输出三个答案,它们并不好,早期现代时期和加拿大国旗。

为什么它不工作那么好,因为关键词搜索正在找到大量与查询共有很多词的文档,但关键词搜索无法真正告诉您是否回答了问题,所有这些文章都与查询有很多词共有,但它们不是答案,所以让我们让它大一点。
让我们说实际上问它要五百个结果,我不会打印文本,只打印标题,所以这里我们有五百个顶级结果,那太多了,我们如何找到,如果其中一个有答案,嗯,这就是重新排名的作用,这个函数在这里重新排名列表,并输出前十个。
现在让我们叫答案,文本,让我们应用它重新排名列表,其中我们输入查询,和结果,最后让我们打印前十个,重新排名列表结果,注意,这实际上捕捉到了答案,它捕捉到了渥太华作为加拿大的首都,相关性得分非常高。
因为它非常接近一,它是0。988,注意,第二好的文章也非常好,因为它讨论了加拿大历史上有过的不同首都,这个的有一个相关性得分为0。97,正如你可以看到,第三个也相当好并重新排名。
实际上从关键词搜索表面挑选了前十个答案,那是相关性最高的,现在让我们做最后一个例子,使用密集检索,所以再次我将使用此密集检索函数,让我们给它一个稍微困难的问题,让我们给它的问题历史上最高的人是谁。
这将是关键词搜索的困难问题,因为它可能会表面包含历史或人的词汇的文章,它可能不会实际上抓住问题的含义,但我们希望紧张检索能做得更好,所以我们将调用函数来获取一些结果,现在让我们打印出这些结果,注意。
这实际上得到了正确的答案,罗伯特·瓦德洛是斑点,这也选择了其他文档,但我们仍然可以使用rerank来帮助我们出什么事情,当我们重写这些结果时,所以让我们叫结果文本,现在让我们叫排名为函数。
再次是检查文本与给我们提供的查询的相关性,以我们给它的查询为参考,当我们打印答案时,那么我们确实得到那个相关性最高的,0。97属于罗伯特·瓦德洛,对于其他文章,它们给它了一些相关性,但不是很高。
rerank实际上帮助我们识别问题的正确答案,在密集检索表面出现的文章之中,现在我建议你暂停这里并实际上尝试你自己的例子,所以制作你自己的查询,找到搜索结果,然后使用rerank来找到正确的答案。
现在我们有了所有这些搜索系统,你可能在 wonder 如何评估它们,有许多方法可以评估它们,其中一些是平均准确率或map,平均反向排名或mrr和归一化,折扣累积收益或ndcg。
那么如何制作一个测试集来评估这些模型,嗯,一个好的测试集应该是包含查询和正确响应的,然后您可以比较这些正确响应与模型给您的响应,以您将找到分类模型的准确性或精确度或召回率相同的方式。
如果您想要了解更多关于评估搜索系统的信息,我们将在资源中放置一些关于文章的链接,以便您更仔细地查看,现在,你已经学会了如何使用搜索和重新排序,以检索包含特定问题的文档,在下一节课。
你将学习一些真的很酷的东西,你将学习如何将搜索系统和生成模型结合在一起,以在句子模式中输出查询的答案。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P97:6.L5-generating answer.zh - 吴恩达大模型 - BV1gLeueWE5N

本课内容,将生成步骤加入搜索管道的末尾。

这样可得到答案而非搜索结果。

例如,这是一种构建用户可与文档或书籍聊天的应用的好方法,如本课所示,一篇文章,大型语言模型擅长许多事情,然而,需要它们提供帮助的用例,举个例,假设你有一个问题,当你开始学习AI时,边项目重要吗?
你可以问大型语言模型,它们中的一些可能会给出有趣的答案,但真正有趣的是,如果你问专家或专家的写作,例如,你可以问安德鲁·恩格或顾问。

安德鲁关于这个问题的写作,像这样,幸运的是,我们可以访问安德鲁的一些写作,所以你可以深入学习,AI有一个名为《批量》的新闻通讯,你可以找到名为《如何在AI中建立职业生涯》的一系列文章,它包含多篇文章。
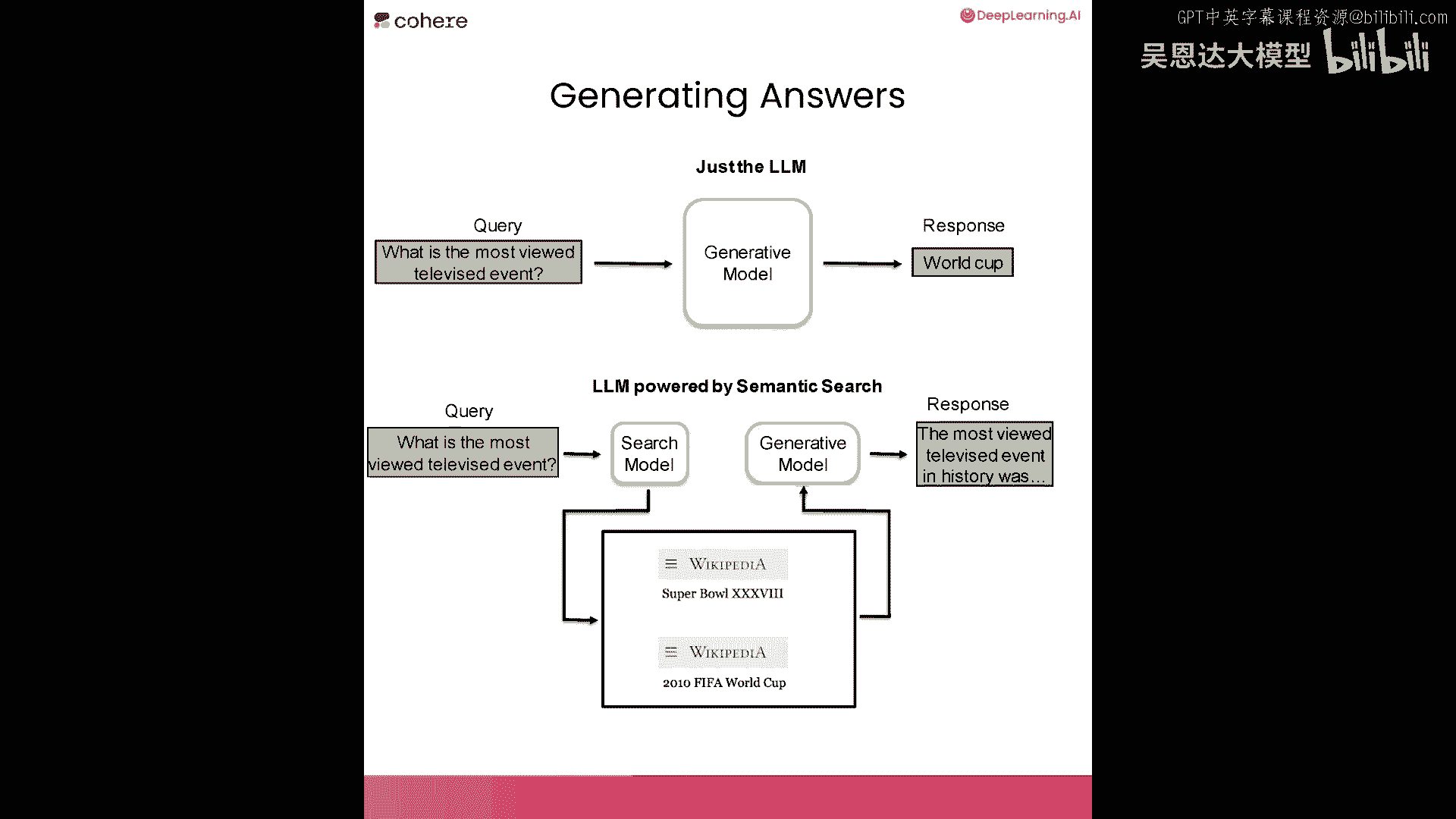
我们将使用本课程所学来搜索,然后使用生成性大型语言模型从这篇文章中生成答案,让我们可视化并确切描述我们的意思。

你可以问大型语言模型一个问题,它们能回答许多问题,但有时我们想让他们从特定文档或档案中回答,这就是你可以在生成步骤之前添加搜索组件以改进这些生成的原因,当你依赖大型语言模型的直接答案时。
你依赖于它存储在内部的世界信息,但你可以提供上下文,使用先前的搜索步骤,例如,当你在提示中提供上下文以改善案例的生成时,当你希望将模型锚定到特定领域、文章或文档时,或我们的文本档案,这也提高了事实生成。
因此,在许多情况下,当你想从模型中检索事实时,并使用上下文增强它,像这样,这提高了模型生成事实性的概率。

这两个步骤的区别在于,不是仅仅向生成模型提问,并查看它打印出的结果,我们可以首先将问题呈现给搜索系统,就像我们在本课程早期构建的那样,然后检索其中的一些结果,将它们与问题一起放在提示中提供给生成模型。
除此之外,然后得到基于上下文的响应,我们将在下一个代码示例中查看如何做到这一点,所以这是我们的问题。
让我们为这个用例构建文本档案。

我们只需打开这些文章并复制文本,我们可以复制并粘贴到该变量中,我们可以称之为text,只需将它们全部放入其中,我们可以复制三个,所以这是第二篇文章,这里有一个包含三篇文章文本的变量,你可以做更多。
并且它是,我认为可能在七或八部分,但我们可以用三个例子来做,你以前见过的熟悉代码,运行这里设置环境,还有一些熟悉的代码,因此我们可以导入cohere,因为接下来我们将嵌入此文本,将首先将其拆分为块。
然后嵌入它,然后构建我们的语义搜索索引,所以这是我们拆分的部分,让我们看看text现在看起来像什么,让我们看看前三个示例,所以这是前三个块,人工智能的快速崛起导致人工智能职位的快速崛起。
职业成长的三个初步步骤,所以这是三个段落,安德烈文章中的三个段落,我们可以继续设置cohersdk并嵌入文本,所以我们现在正在将其发送到嵌入并获取嵌入,让我们构建我们的文本档案,我们进行一些导入。
我们以前都见过所有这些,这是annoy,这是向量搜索库,Numpy pandas将不使用正则表达式,但处理文本时总是最好备有它们,所以相同的代码也在这里运行,这是,我们只是将其转换为numpy数组。
所以这是我们得到的向量,所以这是嵌入,我们创建一个新的索引,一个向量索引,我们将向量插入其中,然后构建并保存到文件中,我们有向量搜索,现在定义函数,命名为搜索,安德鲁的文章,给它查询。
在此数据集上运行搜索,为此,步骤与过去相同,嵌入查询,对档案进行向量搜索,比较查询与,文本中每段落的嵌入,然后返回结果,现在可问搜索系统问题,类似这样的副业,在构建AI职业时是好主意。
我想知道安德鲁会怎么说,这里返回第一个结果,这是长段落,与问题最接近,如果你看这里,发展副业,即使你有全职工作,有趣的项目可能变大,激发创造力,这是大文本中答案。

这是为什么,可用大型语言模型回答。

给它这个,提取相关信息,接下来做,不是搜索,我们要定义新函数,问安德鲁的文章,并给它问题,生成次数,这里有几件事,在做事前,我们会搜索,获取相关上下文,嗯,从文章中获取最佳结果,这是设计选择。

你想在提示中注入1个结果还是2或3个,我们使用1个,因为这是最简单的,提示可以像这样,来自安德鲁·王关于如何构建AI职业文章的摘录,这是提示工程技巧,提供越多上下文给模型,它越能更好地完成任务。
在此注入接收到的上下文,这是文章中的段落,然后提出问题,给出指令或命令给模型说,从提供的文本中提取答案,如果不在那里,告诉我们不可用,然后我们说需要发送给模型的预测,现在我们有提示,我们说co。
generate_prompt等于,提示最大标记,假设七十,其中一些倾向于较长模型,我们想使用称为command nightly的模型,这是Cohere上更新最快的生成模型。
所以如果你使用command nightly,你使用的是平台上可用的最新模型,这往往是比较实验性的模型,但它们是最新的,通常也是最好的,嗯,我们可以在这里停止,我们还没有使用它们生成。
但我们可以稍后使用,然后我们会返回预测生成,这就是我们的代码现在,确切这个问题,让我们在这里提出,而不是这是一个搜索练习,我们希望这是一个对话练习,由搜索提供信息,并向语言模型提出,嗯,如果我们执行它。
我们得到这个答案,是的,副项目是个好主意,当试图在AI领域建立职业时,它们可以帮助你发展技能和知识,也可以是一个很好的方式与其他人士建立联系,但你应该小心不要与雇主产生冲突,并且你应该确保你没有评估。
然后我们在这里用完了标记,所以我们可以在这里增加标记数,如果你想得到更长的答案,所以这是一个如何工作的快速演示,你可以试试,问它几个问题,其中一些可能需要一点提示工程,但这是一个这些应用的总体概述。
有很多人正在用这些东西做有趣的事情,例如,向Lex Friedman播客提问,这确实实现了这个流程,因此,对整个播客的转录进行语义搜索,有人也对Andrew Huberman的播客做了同样的事情。
你看到的是,um,YouTube的转录,书籍的视频,这是人们使用大型语言模型构建的常见事物,它通常由这个驱动,两步搜索后生成,可加入重排以改进搜索组件,请暂停尝试,运行代码至此,更改问题。
或获取感兴趣的数据集,不必总是复制代码,仅快速示例,使用llama index和lang chain从pdf导入文本,若要工业规模工作。

记住num generations参数,开发时的小技巧,测试模型行为时,每次调用API多次,可传递给代码生成的参数,num_generations=num_generations,提问时。
num_generations=3,无需打印,嗯,要打印多个,嗯,这里发生的是,这个问题将给语言模型,语言模型将被要求同时给出三个不同的生成,不只是一个,所以它像批处理一样运行它们。
然后我们可以说对于jin结果,打印gen十代,基本上打印,这仅为我们查看,调试模型行为时,希望快速看到,好的,模型回答问题或响应提示,嗯,多次,嗯,正确与否,无需继续逐一运行,可看3至5次。
我认为你能通过这,这是模型的一代,这是一个生成,它们都是对同一提示的响应,这是你进行提示工程的一种方式,并获得模型对提示行为的句子响应。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P98:7.Conclusion.zh - 吴恩达大模型 - BV1gLeueWE5N
"这是一门关于大规模语义搜索语言模型的课程结束",我们非常感谢您的关注,"我们希望你们喜欢学习这个主题",我们邀请您去cohere的llm大学查看更多的广泛课程。"在这个课程中。
你可以学习到关于lms的许多更多主题。","此外,你也可以加入协作组","一个由我自己和其他人组成的Discord社区,我们将非常乐意回答任何问题。",你可能有关于LMS的信息。
我们也要感谢许多没有他们,这个课程就无法实现的人,像我或者阿米尔·阿德里安,莫里斯萨,埃利奥特,崔,伊万,尚,尼尔斯,韵人,帕特里克·刘易斯,塞巴斯蒂安,霍夫斯塔特,Sylvie。
她和伟大的人们以及深度学习AI。
标签:检索,吴恩达,模型,教程,笔记,查询,搜索,答案,我们 From: https://www.cnblogs.com/apachecn/p/18443050