Efficient DETR结合密集检测和稀疏集合检测的优点,利用密集先验来初始化对象容器,弥补单层解码器结构与 6 层解码器结构的差距。在MS COCO上进行的实验表明,仅 3 个编码器层和 1 个解码器层即可实现与最先进的目标检测方法竞争的性能,在CrowdHuman密集数据集上的性能也远远优于其它检测器来源:晓飞的算法工程笔记 公众号
论文: Efficient DETR: Improving End-to-End Object Detector with Dense Prior

Introduction
最近,DETR提出构建一个基于编码器-解码器Transformer架构和二分匹配的端到端框架,该框架无需后处理即可直接预测一组边界框。然而,DETR需要比现代主流检测器多 10 到 20 倍的训练周期才能收敛,并且在检测小物体方面的性能较低。
Deformable DETR从两个方面解决上面的两个问题:(i) 用局部空间注意力取代全局范围注意力,从而加速训练的收敛。(ii) 用多尺度特征图代替单尺度特征图,显着提高了检测小物体的性能。
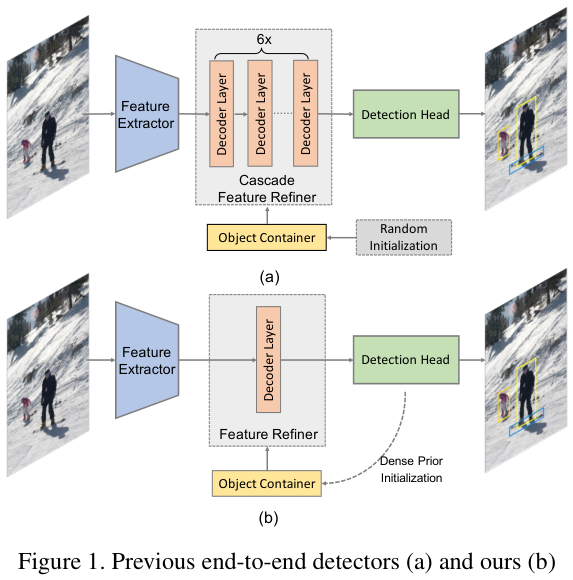
DETR的流程可以抽象为如图 1(a) 所示,对象容器定义为结构化信息的容器,对象查询和参考点都属于对象容器。一组随机初始化的对象容器被输入到含 6 个编码器层的特征细化器中,与从图像中提取的特征进行交互,细化的对象容器有助于DETR的最终预测。总之,图像和随机初始化的对象容器经过特征提取器和级联特征细化器以获得最终结果。在此流程中,DETR和Deformable DETR都具有 6 个编码器层和 6 个解码器层的架构,这种结构是DETR系列实现高精度物体检测的关键。
论文进行了大量的实验来研究DETR的组件以了解其机制,发现具有额外辅助损失的解码器层对性能的贡献最大。解码器层迭代地将对象容器与特征图进行交互,逐步将随机初始化对象容器进行细化,这是导致收敛缓慢的主要原因。
为此,论文提出了简单但高效Efficient DETR,架构如图 1(b) 所示,包含密集和稀疏两部分,共用相同的检测头。在密集部分,执行基于滑动窗口的类可知密集预测生成区域提案,选取 Top-K个高分提案并将其四维提案和 256 维编码器特征作为参考点和对象查询。由于这样的对象容器的初始化非常合理,只需 1 个解码器层即可实现更好的性能和快速收敛。
Exploring DETR
Revisit DETR
- Encoder and decoder
DETR系列采用编码器-解码器架构,编码器和解码器都级联 6 个相同的层。编码器层由多头自注意力和前馈网络(FFN)组成,而解码器层具有额外的多头交叉注意力层。编码器层起着与卷积类似的作用,通过多头自注意力从CNN主干中提取上下文特征。在解码器中,一组 256 维对象查询与整个图像的编码器特征交互,通过多头交叉注意力聚合信息,辅助二分匹配损失应用于每个解码器层。
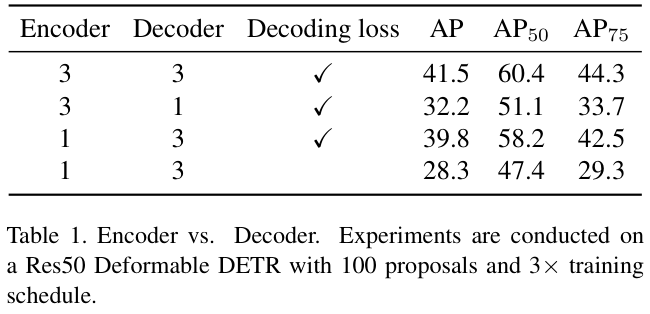
表 1 展示了不同层数的性能对比,实验说明DETR对解码器层数更敏感。将具有 3 个编码器和 3 个解码器的DETR作为论文的基线,删除两层解码层可能会减少约9.3 AP,而删除两层编码层仅导致AP下降1.7。这意味着,解码器比编码器对于DETR更重要。
- Why is the decoder more important than encoder?
编码器和解码器都采用级联架构,只不过解码器对于每层都有一个额外的辅助损失。在表 1 中,论文发现辅助解码损失是DETR对解码器层数更加敏感的主要原因。在没有辅助损失的情况下,编码器和解码器的行为趋于相同。辅助解码损失在更新查询特征时引入了强监督,使得解码器更加高效。解码器的级联结构通过逐层辅助损失来细化特征,迭代次数越多,辅助解码监督就越有效。
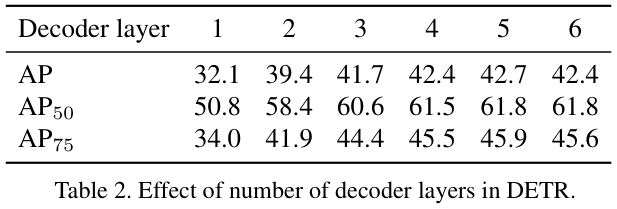
为了进一步探索解码器的级联结构,论文尝试不同数量的解码器层。表 2 显示,随着级联次数的减少,性能显着下降。 6 层解码器和 1 层解码器之间有10.3 AP的巨大下降。值得注意的是,编码器每次迭代后仅更新对象查询。因为最终预测是由检测头根据对象查询进行预测的,所以对象查询与性能密切相关。然而对象查询是在训练开始时随机初始化的,如果这种随机初始化不能提供良好的初始状态,可能就是DETR需要 6 次层级联结构才能实现有竞争力性能的原因。
Impact of initialization of object containers
对象查询属于对象容器的特征信息,定义为可学习的 256 维位置嵌入,难以分析其作用。但论文观察到DETR中的每个对象查询都会通过多种操作模式,学习到专门针对某些区域和框大小。为此,论文认为研究对象查询的空间投影可能有助于以直观的方式理解。
Deformable DETR带来了一个与对象查询相关的新组件,称为参考点。参考点是表示框中心预测的二维张量,属于对象容器的位置信息。此外,参考点是通过线性投影从 256 维对象查询中预测的,可以作为对象查询在二维空间中的投影,直观地呈现对象查询中的位置信息。

在传递到解码器层之前,参考点是通过随机初始化的对象查询的线性投影生成的,此过程称为参考点的初始化。图 2 展示了收敛模型学习到的参考点。初始阶段的参考点均匀分布在图像上,类似于基于锚点的检测器中锚点的生成。随着迭代阶段的增加,参考点逐渐聚集到前景的中心,在最后阶段覆盖几乎所有前景。直观上,参考点充当定位前景的锚点,并使注意力模块聚焦于前景周围的一小组关键采样点。
研究完参考点的更新后,论文开始探索其初始化,即参考点的生成方式。对于其余部分,论文将参考点的初始化和对象查询称为对象容器的初始化。
- Different initialization of reference point
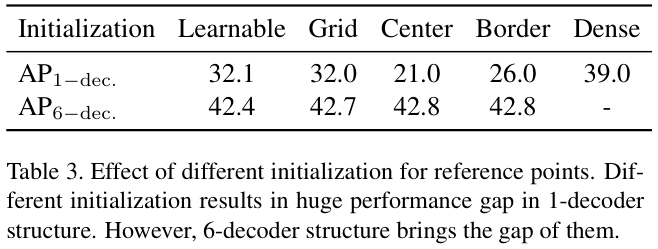
论文在级联(6-解码器)和非级联(1-解码器)结构中尝试几种不同的参考点初始化,如表 3 所示,不同的初始化在非级联结构中的行为差异很大,而级联结构则产生相似的性能。非级联结构中,将滑动窗口的中心作为参考点的网格初始化,其结果大约等于可学习初始化的性能,而另外两种初始化则会导致精度的巨大下降。

为了更好的分析,论文可视化了几个阶段不同初始化的参考点。随着迭代阶段的增加,参考点往往处于相同的分布并在最后阶段以相似的模式定位前景。总之,在非级联结构中,不同的参考点初始化会导致巨大的模型性能差异,而级联结构则可以通过多次迭代弥补了模型性能差异。从另一个角度来看,更好的参考点初始化可以提高非级联结构的性能。
- Can we bring the gap of 1-decoder structure and 6-decoder structure with better initialization?
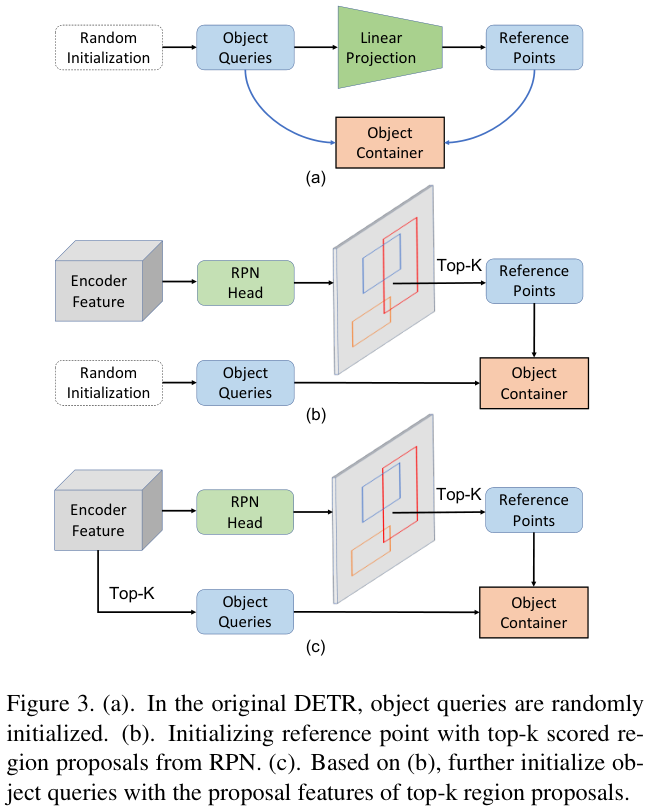
根据前面的发现,论文认为主流检测器中的锚点先验可能有助于论文解决这个问题。在现代两级检测器中,区域提案由RPN在滑动窗口中生成,为前景提供一组与类别无关的候选者。
RPN是一种有效的结构,可以通过密集先验生成前景的粗粒度边界框。如图 3(b) 所示,论文在编码器的密集特征上添加了一个RPN层,RPN头共享编码器的特征并预测锚点的对象分数和偏移量。选择得分最高的边界框作为区域建议,然后以非级联结构中的区域提案中心初始化参考点。从表 3 的结果可以看出,其性能大大优于其他方法,在非级联结构上带来了巨大的改进。
图 5 展示了该方法的可视化,初始阶段的参考点得到与其他方法在最后阶段的相似分布。区域提案以更合理的分布初始化参考点,提高了无级联结构的Deformable DETR的准确性。
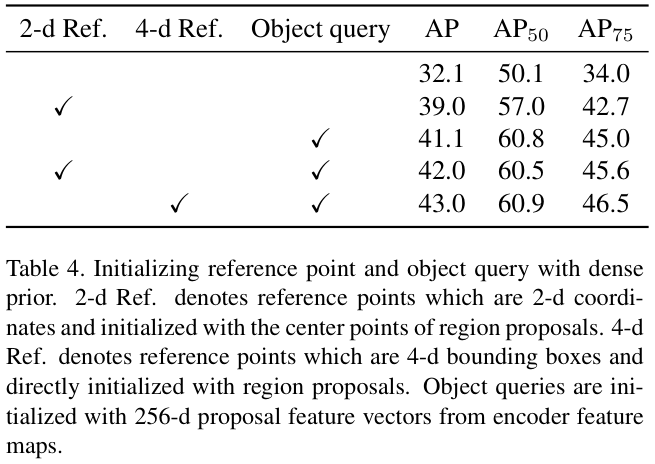
如表 4 所示,为参考点提供更好的初始状态和密集的先验结果可以显着改进1-解码器结构。但参考点只是对象查询的空间投影,对象查询还包含对象容器的额外抽象信息。因此,可以考虑动态根据先验结果来初始化对象查询。
对于提案初始化中的每个参考点,从特征图中选择其相应的特征作为其配套对象查询的初始化,即来自编码器的 256 维张量。论文的方法如图 3(c)所示。在表 4 中,该方法进一步将 1-解码器结构改进了3 AP。此外,仅使用密集先验初始化对象查询,也可以给基线带来显着的改进。
这些结果表明,对象容器的初始状态与非级联结构的性能高度相关,而RPN中的提案信息能够提供很好的初始化。基于上面的发现,论文提出了Efficient DETR,能够缩小 1-解码器结构和 6-解码器结构之间的性能差距。
Efficient DETR
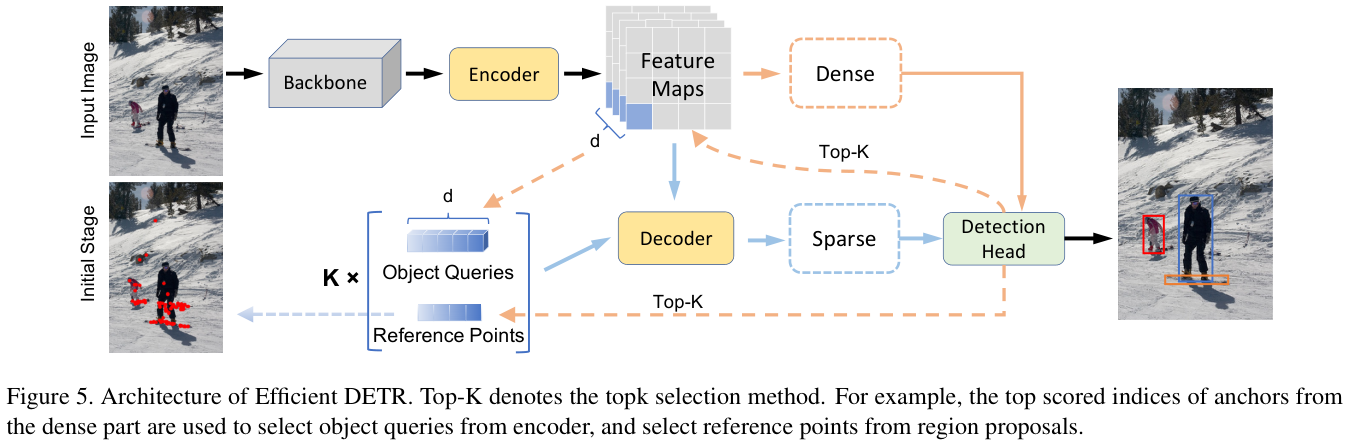
论文提出了一个简单但有效的Efficient DETR目标检测框架,包含 3 个编码器层和 1 个解码器层,解码器中没有级联结构。
Efficient DETR由密集和稀疏两部分组成:
- 密集部分对来自编码器的密集特征进行预测,挑选
top-k区域提案,将来自编码器的 4 维区域提案及其 256 维特征作为参考点和对象查询的初始化。 - 稀疏部分将密集先验初始化的参考点和对象查询输入到单层解码器,与编码器特征交互以进一步细化,从细化的对象容器中预测最终结果。
两个部分共用相同的检测头,所有编码器和解码器层都使用可变形注意模块。
- Backbone
遵循Deformable DETR的设计,从ResNet中提取的多尺度特征图构建主干特征,包含四种尺度特征,每个都为 256 通道。前三个特征图是通过步幅为 1 的 \(1\times 1\) 卷积从ResNet的C3、C4、C5特征图中提取的,最后一个特征图通过在C5上的步幅为 2 的 \(3\times 3\) 卷积生成。
- Dense part
密集部分由主干、编码器和检测头组成。遵循两阶段Deformable DETR的设计,在多尺度特征图的每个位置生成锚点,基础锚点的尺寸为 0.05(宽高相对于特征图的比例)。检测头预测每个锚点的C个类别分数和 4 个偏移量。分类分支是线性投影层,回归分支是隐藏层大小为 256 的 3 层MLP。
- Sparse part
密集部分的输出与编码器特征的大小一致,根据其对象得分来选择top-k提案作为参考点,由其 256 维编码器特征预测的最大类别得分作为其对象得分进行选择。注意,这里使用 4 维框作为参考点而不是 2 维中心,以便获取更多的空间信息。至于对象查询,取密集输出的特征图中对应的 256 维特征。
将密集部分的特征作为稀疏部分的初始状态,考虑到密集部分和稀疏部分的任务非常相似,这两个部分共享相同的检测头。
初始化后,对象查询被输入到解码器层以进行进一步细化。在传统的检测方法中,一级检测器面临特征未对准的问题,而两级检测器则通过ROIAlign或ROIPool解决这个问题。在论文的稀疏部分中,错位由解码器修复,其交叉注意模块使对象查询能够聚合与其相关的特征,通过增强的对象查询进行最终预测。
与DETR不同,提案数量是在训练过程中动态调整的。鉴于网络在训练开始时无法预测准确的类别分数,因此从一开始就设置了大量的提案(300),确保几乎所有前景都被稀疏的提案集覆盖。但仍然有可能少数提案会错过一些困难的例子,导致训练不稳定。随着网络的训练,论文线性减少提案数量到 100。这种策略使网络训练变得高效,仅用 100 个提案就达到了与使用 300 个提案训练的网络相当的精度。
- Loss
密集部分和稀疏部分共享相同的标签分配规则和损失函数。为了避免像NMS那样的后处理,采用一对一的标签分配规则并通过匈牙利算法将预测与GT进行匹配。匹配分数的定义与损失函数相同,均为 \(L = \lambda_{cls}\cdot \mathcal{L}_{cls}+\lambda_{L1}\cdot \mathcal{L}_{L1}+\lambda_{giou}\cdot \mathcal{L}_{giou}\),其中 \(\mathcal{L}\_{cls}\) 为focal loss。论文在密集部分使用一对一标签分配规则,用少量的提案(100)即可实现高精度,而一对多分配依赖于大量提案来达到相似的性能。
Experiments
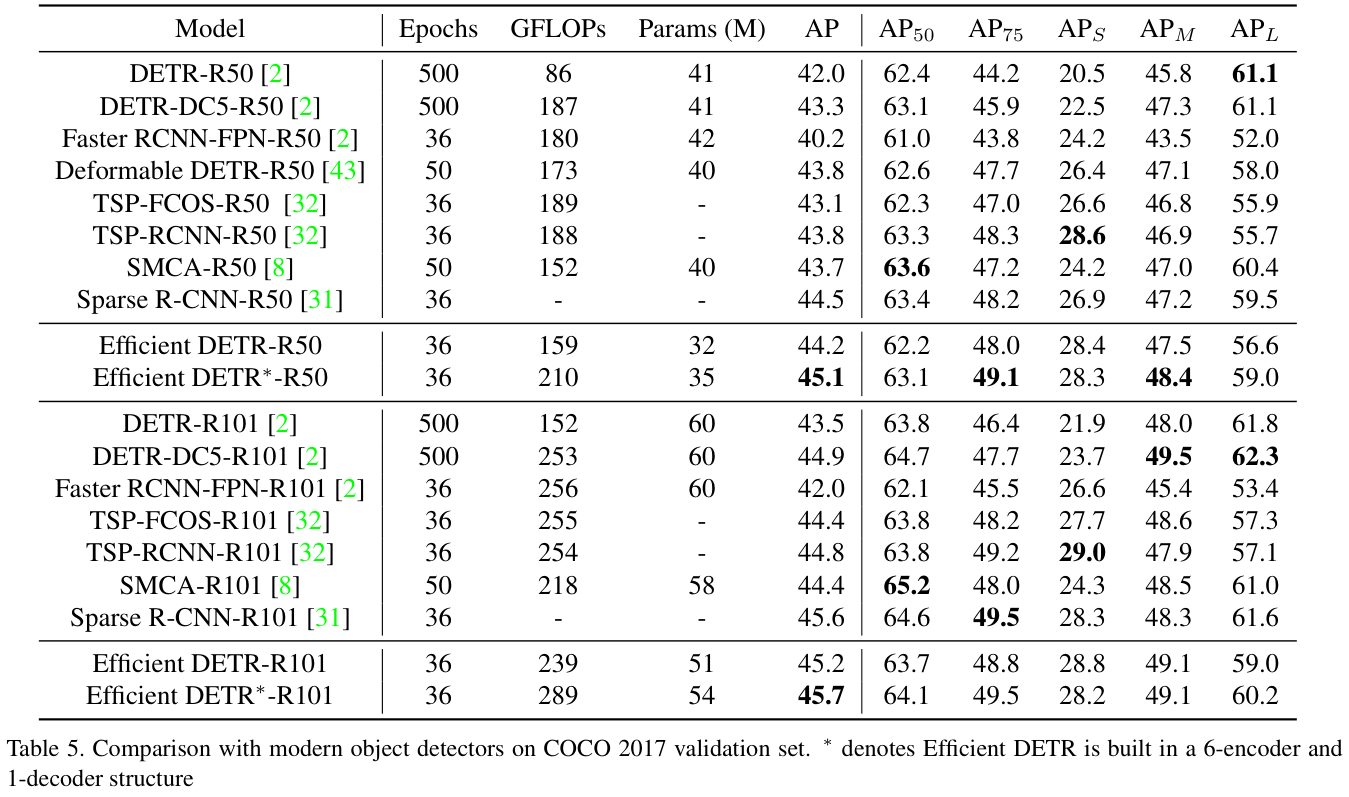
与其它模型在COCO 2017验证集上的结果如表 5 所示。
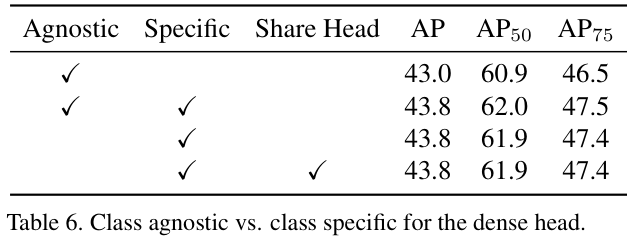
表 6 展示了不同检测头配置的对比实验。
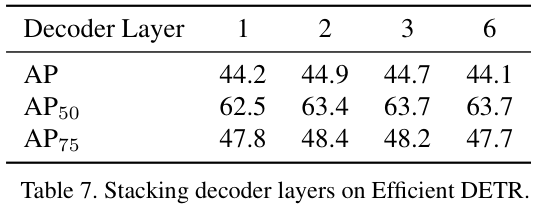
表 7 展示了编码层和解码层数量的对比实验。
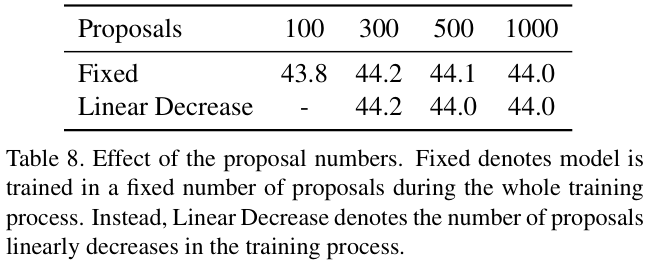
表 8 展示了不同提案数量的对比实验。
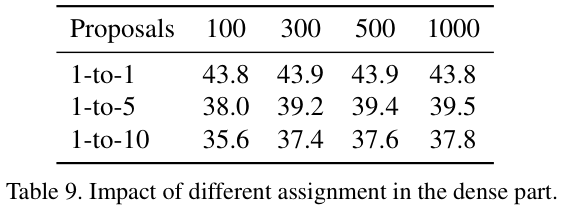
表 9 展示了不同标签分配规则的对比实验。
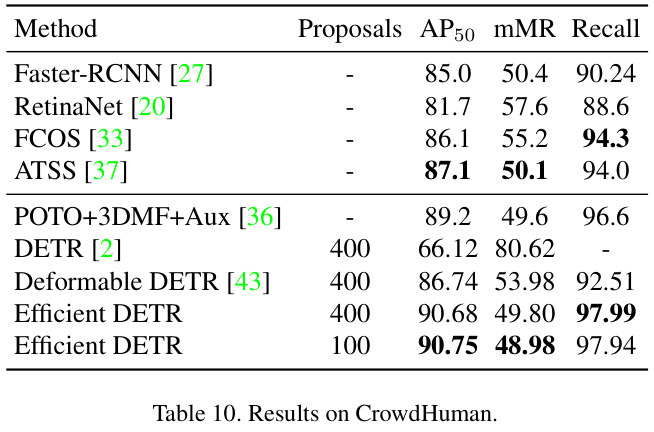
表 10 展示了拥挤场景中的性能对比。
如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
