精确分割在当今众多领域都是一项关键需求比如说自动驾驶汽车的训练、医学图像识别系统,以及通过卫星图像进行监测。在许多其他领域,当感兴趣的对象微小但至关重要时,例如研究血管流动、手术规划、检测建筑结构中的裂缝或优化路线规划,需要更高的精度。此前已经做了大量工作来解决这种具有挑战性的分割问题。
此前已经做了大量工作来解决这种具有挑战性的分割问题。深度学习和神经网络的进步,例如[U-Net]及其变体,极大地提高了分割精度。“那还有什么问题呢?”所有这些方法在分割微小、细长和曲线结构方面表现不佳。根据研究,这可能是损失函数的一个问题
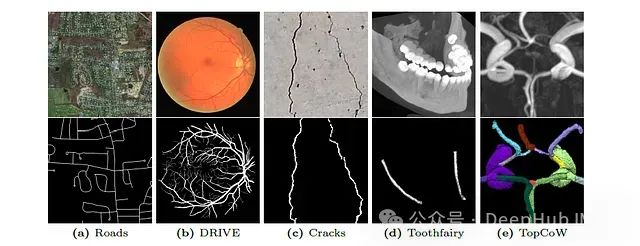
上面是来自不同数据库的包含示例,(a)卫星图像中的道路,(b)视网膜血管,(c)混凝土裂缝,(d)面部CT扫描的下牙槽管,(e)[圆]动脉
深度学习网络使用了最先进的损失算法,比如centerline-Dice或cl- dice,但是他们的计算成本非常大,在大容量和多类分割问题,即使在现代gpu,也表现得不好。
这篇论文则介绍了一个新的损失:Skeleton Recall Loss,我把它翻译成骨架召回损失.这个损失目前获得了最先进的整体性能,并且通过取代密集的计算他的计算开销减少超过90% !
为了说明这篇论文的损失函数,我们先介绍一下目前用于分割的损失函数
https://avoid.overfit.cn/post/ddf618e45066433f9aca7447773bc61f
标签:Loss,分割,Skeleton,Recall,损失,领域 From: https://www.cnblogs.com/deephub/p/18353168