这里的边分治和树上的点分治边分治不一样,是维护强连通分量用的,每条边有一个出现时间,通过将每条边按连通关系分流重新排列,从而维护每个时间点整张图的连通性。
具体的,这个算法是维护这样的一类问题:
n 个点,m 条边按时间顺序依次加入,每加入一条边,你需要回答一些问题,比如在这个时间点,图中有多少强连通分量,或者某个点所在强连通分量的大小。
暴力的做法是每加入一条边就跑一遍tarjan算法,当边比较稠密时,缩点合并比较频繁,每次缩点就会让总点数减小,只用缩点后的图继续加边,复杂度似乎说的过去。
但强连通分量比较多时,跑一遍tarjan甚至缩不了任何点,比如一张DAG,就可以轻松卡到 n^2。这样暴力复杂度高的原因在于,很多无法成为强连通分量里的边遍历了好几次,每次都没有被缩掉,极大地浪费了时间。
按连通性进行边分治:
我们希望多次进行tarjan算法时,那些连不出强连通分量的边可以少遍历几次,而是尽量让它们在形成强连通分量的时候被遍历,因为这样可以把这些点和边缩掉,以后也不用遍历。
一个很妙的分治方式:我们将当前计算的时间线 \([l,r]\) 分一半,只保留前一半时间的边,跑一遍tarjan算法,将强连通分量找到,把那些已经在强连通分量中的边放进前一半时间 \([l,mid]\) ,把没有进入强连通分量的边放进后一半时间 \([mid+1,r]\) 。
这样做的意义是:在 mid 时刻某些边还没有进入强连通分量,说明在之前的时刻也一定没有进入,这条边就是一条废边,在前 mid 的时间里对我们要维护的东西(连通块)没有任何作用,我们把它丢进后半的时间,也就是在计算前面的时间段内,tarjan算法根本不会去跑这条边,这就节省了暴力做法多次遍历同一条边的复杂度。而反过来,在mid时刻形成的强连通分量,必定是在 \([l,mid]\) 内形成的,但我们不知道具体形成时间。所以我们再分治下去,计算 \([l,mid]\) 这个时间段内的连通情况,以及后半段 \([mid+1,r]\) 的连通情况,在后半段,新加入的边和前半段丢进来的废边有可能会形成新的强连通分量。
我们将每条边不断地向下分,形成类似线段树的分治结构,这个和线段树分治+可撤销并查集的科技非常相似,都是按时间分治,有异曲同工之处。
我们放一张图,图中的边权是这条边加入的时间:
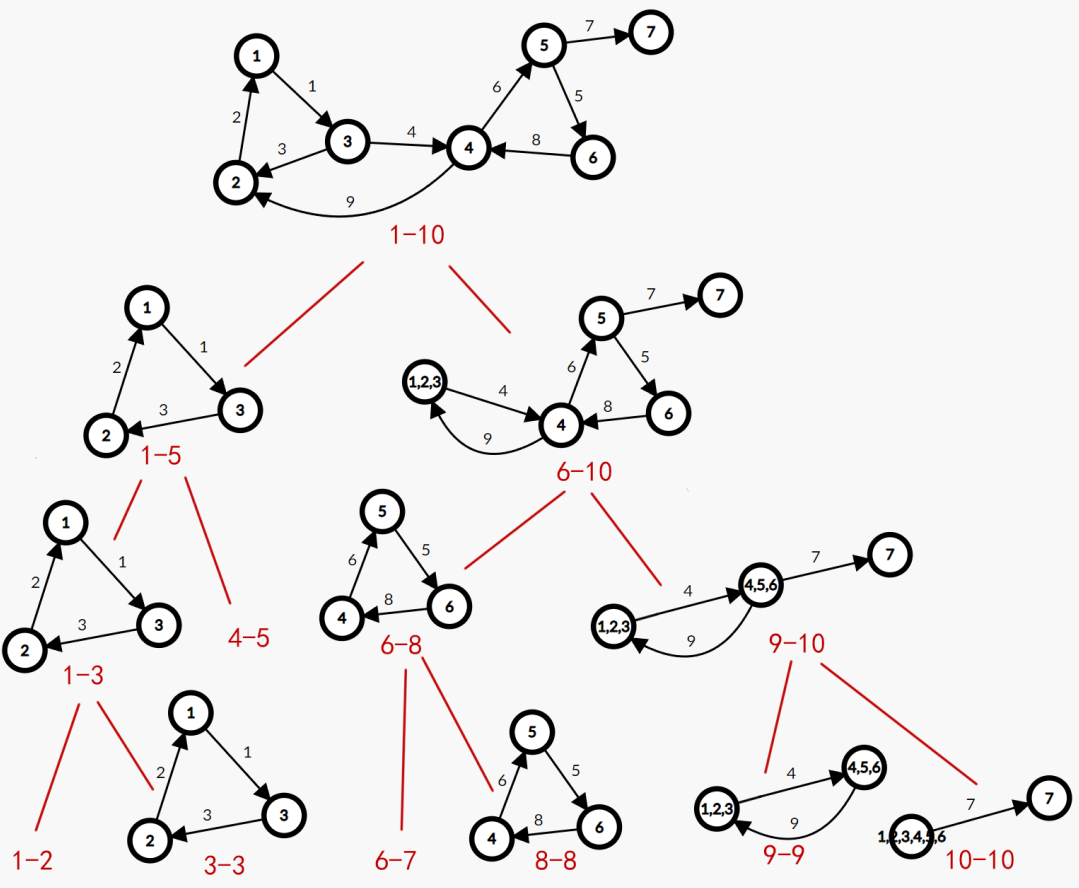
当我们的时间分治到线段树的叶子时,也就是代表这个时刻,由于我们一直将同一个强连通分量的边放在同一侧,在叶子处的边一定是形成了新的强连通分量,我们可以放心地将叶子处的这些点进行合并处理。
注意到时间段 6-10 处的 1,2,3 号点已经缩成了一个点,这是由于我们优先走线段树的左子树,在 3 时刻,我们就已经用并查集将1,2,3三个点连接在一起,并用1号点当做这个强连通分量的代表点,之后的连接1,2,3的边,统一改为连接 1 号点。
在做题时看到题解里说要用并查集维护缩点,于是去学习了一下,回来发现这个维护和那个维护不是同一回事,有一个并查集代替tarjan的缩点算法,实现起来也比较简单,感兴趣可以看下:一个代替tarjan的缩点算法:并查集维护缩点。可是这里所说的并查集仅仅是维护一下每个强连通分量有哪些点,并没有替换掉tarjan算法。
这张图中还有一个要注意的点:虽然我们只有9条边,但是分治的时间段是1-10,这是因为时间点10是用于 “垃圾存放” 的,因为我们每个时间段都把边分成了两种,把废边扔到右侧,保证在遍历到叶子时一定是找到了一个强连通分量,但是仍然有一些边最终也没有进入强连通分量(如此图中的7号边),我们每次都将它分流到右侧,因此被放在了垃圾回收的地方,多出来的这个时刻 10 也不需要我们记录答案。
注意到每层都是 m 条边,一共log层,因此复杂度是 \(O(mlogm)\)。
下面是算法的核心代码:(此模板用于记录每个时刻强连通分量数量,代码下附带样例与上图相同)
int find(int x) { return fa[x]==x ? x : fa[x]=find(fa[x]); }
inline void merge(int x,int y) {
x = find(x); y = find(y);
if(x==y) return ;
fa[x] = y;
_ans--;
}
void tarjan(int u) {
dfn[u] = low[u] = ++tim;
st[++cnt] = u; in[u] = 1;
for(int v : e[u]) {
if(!dfn[v]) {
tarjan(v);
low[u] = min(low[u],low[v]);
}
else if(in[v]) low[u] = min(low[u],dfn[v]);
}
if(low[u]==dfn[u]) {
while(1) {
int v = st[cnt--]; in[v] = 0;
belong[v] = u;
if(v==u) break;
}
}
}
void solve(ll now,ll l,ll r) {
if(l==r) {
for(E vv : d[now]) merge(vv.x, vv.y);
vector<E>().swap(d[now]);
ans[l] = _ans;
return ;
}
ll mid = l+r >> 1;
for(E &vv : d[now]) {
e[vv.x = find(vv.x)].clear();
e[vv.y = find(vv.y)].clear();
dfn[vv.x] = dfn[vv.y] = 0;
}
for(E vv : d[now]) if(vv.ti<=mid) e[vv.x].push_back(vv.y);
for(E vv : d[now]) {
if(vv.ti<=mid) {
if(!dfn[vv.x]) tarjan(vv.x);
if(!dfn[vv.y]) tarjan(vv.y);
if(belong[vv.x]==belong[vv.y]) d[ls].push_back(vv);
else d[rs].push_back(vv);
}
else {
d[rs].push_back(vv);
}
}
vector<E>().swap(d[now]);
solve(ls, l, mid);
solve(rs, mid+1, r);
}
void chushihua() {
_ans = 0;
tim = 0;
}
int main() {
int x,y;
T = read();
while(T--) {
chushihua();
n = read(); m = read();
_ans = n;
for(int i=1;i<=n;i++) fa[i] = i;
for(int i=1;i<=m;i++) {
x = read(); y = read();
d[1].push_back({x,y,i});
}
solve(1, 1, m+1);
for(int i=1;i<=m;i++) cout<<ans[i]<<"\n";
}
return 0;
}
/*
1
7 9
1 3
2 1
3 2
3 4
5 6
4 5
5 7
6 4
4 2
*/
例题1:CF1989F
题意:一个方阵,可以横着刷红漆,竖着刷蓝漆,你可以不花费代价一行一列刷,或花费 k^2 的代价同时刷 k 次,相交处颜色自己定。Q次询问,每次增加一个格子的颜色限制,问最小花费。
Solution:
我们把每一行,每一列的刷漆动作都看成一个点,一个格子颜色的限制暗示了一个顺序:这个颜色的动作必须晚于另一个颜色的动作。这个限制也就是拓扑序的一条边,连接这一行一列两个动作的点。
这些边限制了我们选点的顺序,而当这些边形成了环,我们就无法找出一个拓扑序,就需要进行同时刷 k 次的操作。根据经验得出 k 就是这些边强连通分量的大小,这个强连通分量的贡献也就是 size 的平方。
因此题意转化为了:每个时刻加入一条边,询问当前时刻所有 size>1 的强连通分量的 size 平方和。可以直接套用边分治缩点的模板。
#include <algorithm>
#include <iostream>
#include <cstring>
#include <cstdio>
#include <cmath>
#define FOR() ll le=e[u].size();for(ll i=0;i<le;i++)
#define QWQ cout<<"QwQ\n";
#define ll long long
#include <vector>
#include <queue>
#include <map>
#define ls now<<1
#define rs now<<1|1
using namespace std;
const ll N=501010;
const ll qwq=303030;
const ll inf=0x3f3f3f3f;
inline ll read() {
ll sum = 0, ff = 1; char c = getchar();
while(c<'0' || c>'9') { if(c=='-') ff = -1; c = getchar(); }
while(c>='0'&&c<='9') { sum = sum * 10 + c - '0'; c = getchar(); }
return sum * ff;
}
ll T;
ll n,m,Q,tot;
ll ans[N], _ans;
ll fa[N],siz[N];
struct E{
ll x,y,ti;
};
vector <E> d[N<<2];
vector <ll> e[N];
ll tim,dfn[N],low[N],belong[N];
ll in[N],st[N],cnt;
ll find(ll x) { return fa[x]==x ? x : fa[x]=find(fa[x]); }
inline void merge(ll x,ll y) {
x = find(x); y = find(y);
if(x==y) return ;
if(siz[x]>1) _ans -= siz[x] * siz[x];
if(siz[y]>1) _ans -= siz[y] * siz[y];
fa[x] = y;
siz[y] += siz[x];
_ans += siz[y] * siz[y];
}
void tarjan(ll u) {
dfn[u] = low[u] = ++tim;
st[++cnt] = u; in[u] = 1;
for(ll v : e[u]) {
if(!dfn[v]) {
tarjan(v);
low[u] = min(low[u],low[v]);
}
else if(in[v]) low[u] = min(low[u],dfn[v]);
}
if(low[u]==dfn[u]) {
while(1) {
ll v = st[cnt--]; in[v] = 0;
belong[v] = u;
if(v==u) break;
}
}
}
void solve(ll now,ll l,ll r) {
if(l==r) {
for(E v : d[now]) merge(v.x, v.y);
vector<E>().swap(d[now]);
ans[l] = _ans;
return ;
}
ll mid = l+r >> 1;
for(ll i=0;i<d[now].size();i++) {
d[now][i].x = find(d[now][i].x);
d[now][i].y = find(d[now][i].y);
}
for(E v : d[now]) e[v.x].clear(), e[v.y].clear(), dfn[v.x] = dfn[v.y] = 0;
for(E v : d[now]) if(v.ti<=mid) e[v.x].push_back(v.y);
for(E v : d[now]) {
if(v.ti<=mid) {
if(!dfn[v.x]) tarjan(v.x);
if(!dfn[v.y]) tarjan(v.y);
if(belong[v.x]==belong[v.y]) d[ls].push_back(v);
else d[rs].push_back(v);
}
else {
d[rs].push_back(v);
}
}
vector<E>().swap(d[now]);
solve(ls, l, mid);
solve(rs, mid+1, r);
}
int main() {
ll x,y; char cz[2];
n = read(); m = read(); Q = read();
tot = n+m;
for(ll i=1;i<=tot;i++) fa[i] = i, siz[i] = 1;
for(ll i=1;i<=Q;i++) {
x = read(); y = read();
scanf("%s",cz);
if(cz[0]=='R') d[1].push_back({y+n, x, i});
else d[1].push_back({x, y+n, i});
}
solve(1, 1, Q+1);
for(ll i=1;i<=Q;i++) cout<<ans[i]<<"\n";
return 0;
}
例题2:P5163
题意:给你一张 n 个点 m 条边的有向图,q 个操作:操作一,删除某条边;操作二,增加某个点权值;操作三,询问某个点所在强连通分量内前 k 大点权和。
Solution:
我们的边分治缩点模板是每个时刻加入一条边,这题是删除某条边,我们倒着来做,从最后一个操作开始往上,就变成了加边。由于最后一个操作时边还有剩余,我们也给剩余的边设置一个不一样加入时间,省去讨论的麻烦。
将每个修改点权的操作和询问挂在某条边加入的时间点,在分治到叶子结点时处理这些操作。记住我们正着挂,在遍历时要倒着遍历。
这题要维护的东西比上一个例题要复杂,但也是很模板的东西,而且和我们的边分治过程代码交叉很少,所以不难写。
可以用平衡树,启发式合并,空间稍微小点但是时间多个log,不如权值线段树合并,也可以维护前 k 大的权值。
#include <algorithm>
#include <iostream>
#include <cstring>
#include <cstdio>
#include <cmath>
#define FOR() ll le=e[u].size();for(ll i=0;i<le;i++)
#define QWQ cout<<"QwQ\n";
#define ll long long
#include <vector>
#include <queue>
#include <map>
#define ls L[now]
#define rs R[now]
using namespace std;
const ll N=501010;
const ll qwq=303030;
const ll inf=0x3f3f3f3f;
inline ll read() {
ll sum = 0, ff = 1; char c = getchar();
while(c<'0' || c>'9') { if(c=='-') ff = -1; c = getchar(); }
while(c>='0'&&c<='9') { sum = sum * 10 + c - '0'; c = getchar(); }
return sum * ff;
}
ll n,m,Q;
map <ll,ll> f;
struct E{
ll x,y,ti;
};
vector <E> d[N<<2];
vector <ll> e[N];
ll X[N],Y[N];
struct Qr{
ll cz,x,y;
};
vector <Qr> g[N];
ll ans[N],cntq;
ll a[N];
ll ma_val = 1e9;
ll siz[N*34],t[N*34],rt[N],tot,L[N*34],R[N*34];
inline void pushup(ll now) {
t[now] = t[ls] + t[rs];
siz[now] = siz[ls] + siz[rs];
}
void insert(ll &now,ll l,ll r,ll x,ll v) {
// if(l==1 && r==ma_val) cout<<""
if(!now) now = ++tot;
if(l==r) { siz[now] += v; t[now] += l*v; return ; }
ll mid = (l+r) >> 1;
if(x<=mid) insert(ls, l, mid, x, v);
else insert(rs, mid+1, r, x, v);
if(!siz[ls]) ls = 0;
if(!siz[rs]) rs = 0;
pushup(now);
}
ll query(ll now,ll l,ll r,ll k) {
if(siz[now]<=k) return t[now];
if(l==r) { return k*l; }
ll mid = (l+r) >> 1;
if(siz[rs]>=k) return query(rs, mid+1, r, k);
else return query(ls, l, mid, k-siz[rs]) + t[rs];
}
ll merge_tree(ll r1,ll r2,ll l,ll r) {
if(!r1 || !r2) return r1 + r2;
if(l==r) {
siz[r1] += siz[r2];
t[r1] += t[r2];
return r1;
}
ll mid = (l+r) >> 1;
L[r1] = merge_tree(L[r1], L[r2], l, mid);
R[r1] = merge_tree(R[r1], R[r2], mid+1, r);
pushup(r1);
return r1;
}
ll pa[N];
ll find(ll x) { return pa[x]==x ? x : pa[x]=find(pa[x]); }
inline void merge(ll x,ll y) {
x = find(x); y = find(y);
if(x==y) return ;
pa[x] = y;
rt[y] = merge_tree(rt[x], rt[y], 1, ma_val);
}
ll tim,dfn[N],low[N],belong[N];
ll in[N],st[N],cnt;
void tarjan(ll u) {
dfn[u] = low[u] = ++tim;
st[++cnt] = u; in[u] = 1;
for(ll v : e[u]) {
if(!dfn[v]) {
tarjan(v);
low[u] = min(low[u], low[v]);
}
else if(in[v]) low[u] = min(low[u], dfn[v]);
}
if(low[u]==dfn[u]) {
while(1) {
ll v = st[cnt--]; in[v] = 0;
belong[v] = u;
if(v==u) break;
}
}
}
void calc(ll ti) {
for(ll i=g[ti].size()-1; i>=0; i--) {
Qr vv = g[ti][i];
if(vv.cz==2) {
insert(rt[find(vv.x)], 1, ma_val, a[vv.x], -1);
a[vv.x] -= vv.y;
insert(rt[find(vv.x)], 1, ma_val, a[vv.x], 1);
}
else {
ans[++cntq] = query(rt[find(vv.x)], 1, ma_val, vv.y);
}
}
}
void solve(ll now,ll l,ll r) {
if(l==r) {
for(E vv : d[now]) merge(vv.x, vv.y);
vector<E>().swap(d[now]);
calc(l);
return ;
}
ll mid = (l+r) >> 1;
for(E &vv : d[now]) {
e[vv.x = find(vv.x)].clear();
e[vv.y = find(vv.y)].clear();
dfn[vv.x] = dfn[vv.y] = 0;
}
for(E vv : d[now]) if(vv.ti<=mid) e[vv.x].push_back(vv.y);
for(E vv : d[now]) {
if(vv.ti<=mid) {
if(!dfn[vv.x]) tarjan(vv.x);
if(!dfn[vv.y]) tarjan(vv.y);
if(belong[vv.x]==belong[vv.y]) d[now<<1].push_back(vv);
else d[now<<1|1].push_back(vv);
}
else {
d[now<<1|1].push_back(vv);
}
}
vector<E>().swap(d[now]);
solve(now<<1, l, mid);
solve(now<<1|1, mid+1, r);
}
int main() {
ll cz,x,y;
n = read(); m = read(); Q = read();
ll nowtim = m;
for(ll i=1;i<=n;i++) a[i] = read(), pa[i] = i;
for(ll i=1;i<=m;i++) X[i] = read(), Y[i] = read();
for(ll i=1;i<=Q;i++) {
cz = read();
if(cz==1) {
x = read(); y = read();
f[x*n+y] = 1;
d[1].push_back({x,y,nowtim});
nowtim--;
}
if(cz==2) {
x = read(); y = read();
a[x] += y;
g[nowtim].push_back({2,x,y});
}
if(cz==3) {
x = read(); y = read();
g[nowtim].push_back({3,x,y});
}
}
for(ll i=1;i<=m;i++) {
if(f[X[i]*n+Y[i]]) continue;
d[1].push_back({X[i],Y[i],nowtim});
nowtim--;
}
for(ll i=1;i<=n;i++) {
insert(rt[i], 1, ma_val, a[i], 1);
}
calc(0);
solve(1, 1, m+1);
for(ll i=cntq;i>=1;i--) cout<<ans[i]<<"\n";
return 0;
}