Spring Tips: Spring Statemachine
大纲
- 引言
- 介绍Spring State Machine及其重要性
- 解释状态机的基本概念和用途
- Spring State Machine概述
- 状态机的定义和功能
- 状态机的应用场景
- Spring State Machine的DSL和特性
- 创建和配置Spring State Machine
- 使用start.spring.io创建新应用
- 添加必要的依赖(JDBC, JPA, Lombok)
- 配置状态机类和状态转换
- 实现状态机逻辑
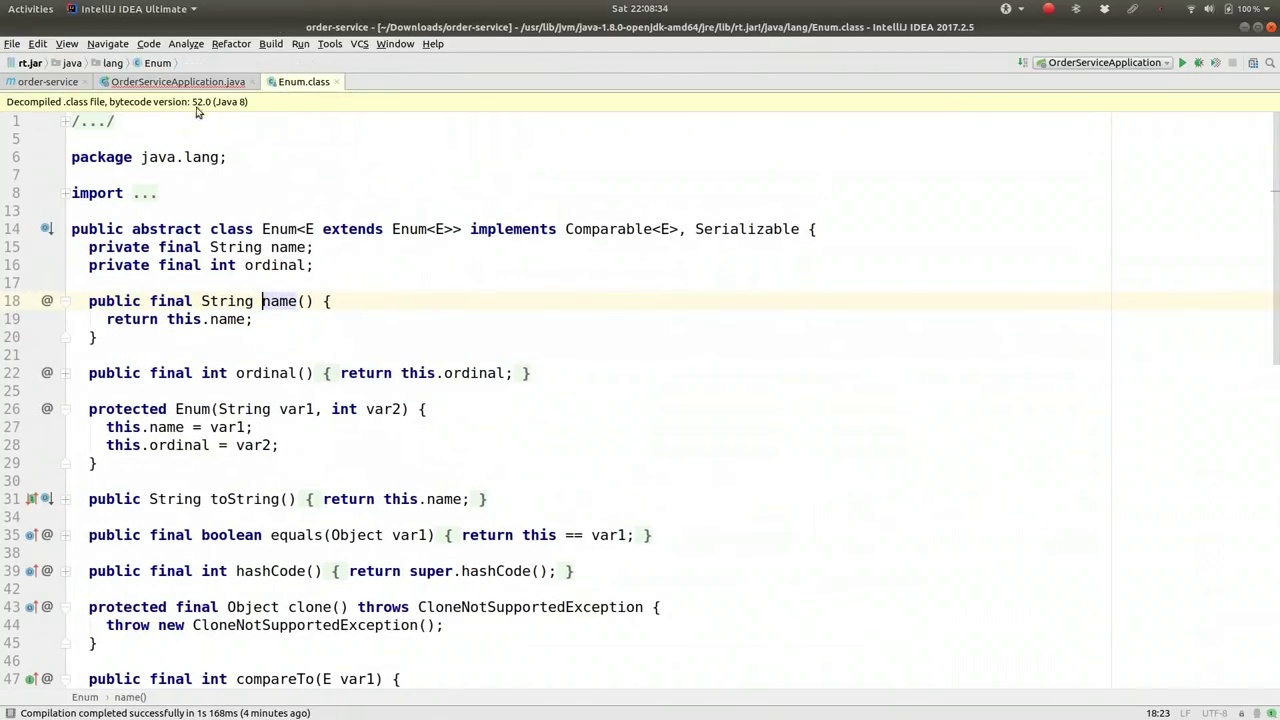
- 定义状态和事件
- 配置状态转换和事件触发
- 实现状态机监听器和日志记录
- 集成业务逻辑
- 创建OrderService类
- 实现订单状态管理和持久化
- 使用状态机处理订单状态转换
- 测试和验证
- 运行状态机并观察状态转换
- 验证订单状态的持久化和同步
- 总结和未来展望
- Spring State Machine的优势和应用
- 未来可能的集成和扩展
内容总结
一句话总结
本文详细介绍了Spring State Machine的配置、实现和应用,展示了如何通过状态机管理复杂的状态转换和业务逻辑。
观点与结论
- Spring State Machine提供了一种清晰的方式来管理复杂的状态转换,有助于分离业务逻辑和状态管理。
- 状态机可以作为业务和技术之间的逻辑接口,帮助将业务规则转换为代码。
- Spring State Machine的DSL和工厂机制使得状态机的创建和配置变得简单和灵活。
- 状态机可以与Spring的其他模块(如Spring Integration, Spring Batch)结合使用,增强其功能。
自问自答
-
什么是Spring State Machine?
- Spring State Machine是一个项目,允许我们定义状态机,这些状态机具有已知、可理解的状态转换。
-
为什么使用Spring State Machine?
- 使用Spring State Machine可以将业务逻辑的流程从一种状态分离到另一种状态,使其更容易修改和维护。
-
如何配置Spring State Machine?
- 通过创建一个配置类,继承
StateMachineConfigurerAdapter,并使用@EnableStateMachine注解来配置状态机。
- 通过创建一个配置类,继承
-
状态机如何处理状态转换?
- 状态机通过定义状态和事件,以及配置状态转换来处理状态转换。事件触发状态转换,状态机根据配置执行相应的动作。
-
如何将状态机与业务逻辑集成?
- 通过创建服务类(如OrderService),并在其中使用状态机来管理实体(如订单)的状态转换和持久化。
关键词标签
- Spring State Machine
- 状态机
- 状态转换
- 业务逻辑
- 持久化
适合阅读人群
- Spring开发者
- 业务逻辑开发者
- 系统架构师
- 软件工程师
术语解释
- 状态机(State Machine):一种数学模型,用于描述系统在不同状态之间的转换和行为。
- DSL(Domain-Specific Language):特定领域语言,用于描述特定领域的模型和规则。
- JPA(Java Persistence API):Java持久化API,用于对象关系映射(ORM)。
- Lombok:一个Java库,通过注解简化Java代码的编写。
- Saga模式:一种分布式事务处理模式,用于协调多个微服务之间的长事务。
讲座回顾

00:00:00-00:00:07
请提供需要翻译的英文段落,我将为您提供准确、地道的中文翻译。

00:00:07-00:00:23
请提供需要翻译的英文段落,我将为您提供准确、地道的中文翻译。
00:00:23-00:06:05
Hello, Spring enthusiasts! In this installment of Spring Tips, we will explore Spring State Machine. Spring State Machine is a project that enables us to define state machines, which are systems with well-known, well-understood transitions between states. If you have ever programmed, you likely have created numerous state machines. Any if-then-else statement or case statement constitutes a state machine. These are systems with orderly, predictable, deterministic transitions between states, accompanied by actions associated with those transitions. State machines are fundamental to our work, often reduced to complex if-statements or else-statements. However, it is beneficial to separate the flow of business logic from one state to another into a distinct model, allowing for easier modification and maintenance. Instead of scattering business logic across multiple decision points, it can be centralized, with actions or handlers responding to state changes. This approach simplifies workflow changes and enhances the clarity of application progressions. Modeling business logic as a state machine is beneficial, even if not implemented at the code level, as seen in UML's support for state machines. State machines serve as a logical interface between business and technology, allowing for the translation of business heuristics into code. They are also queryable, enabling tracking of long-running processes and facilitating decision-making in complex systems. Spring State Machine provides a simple DSL for describing state machines, allowing for persistence, hierarchical progressions, and transitions, among other features.
你好,Spring 爱好者们!在本期 Spring Tips 中,我们将探索 Spring State Machine。Spring State Machine 是一个项目,使我们能够定义状态机,即具有已知、易于理解的状态转换的系统。如果你曾经编写过程序,你可能已经创建了许多状态机。任何 if-then-else 语句或 case 语句都构成一个状态机。这些系统具有有序、可预测、确定性的状态转换,并伴随着与这些转换相关的动作。状态机是我们工作的基础,通常简化为复杂的 if 语句或 else 语句。然而,将业务逻辑从一个状态到另一个状态的流程分离到一个独立的模型中是有益的,这样可以更容易地修改和维护。与其将业务逻辑分散在多个决策点上,不如将其集中起来,由动作或处理程序响应状态变化。这种方法简化了工作流程的更改,并增强了应用程序进展的清晰度。将业务逻辑建模为状态机是有益的,即使没有在代码级别实现,正如 UML 对状态机的支持所示。状态机作为业务和技术之间的逻辑接口,允许将业务启发式方法转化为代码。它们也是可查询的,能够跟踪长时间运行的进程,并在复杂系统中促进决策。Spring State Machine 提供了一个简单的 DSL 来描述状态机,支持持久化、层次化进展和转换等功能。
精炼总结 1. **Spring State Machine 简介**:Spring State Machine 是一个项目,用于定义具有已知、易于理解的状态转换的系统。-
状态机的普遍性:任何 if-then-else 或 case 语句都构成一个状态机,这些系统具有有序、可预测、确定性的状态转换。
-
状态机的好处:将业务逻辑从分散的决策点集中到一个独立的模型中,简化了修改和维护,增强了应用程序进展的清晰度。
-
状态机的应用:状态机作为业务和技术之间的逻辑接口,允许将业务启发式方法转化为代码,并支持长时间运行的进程跟踪和复杂系统中的决策。
-
Spring State Machine 的功能:提供简单的 DSL 来描述状态机,支持持久化、层次化进展和转换等功能。
参考回答:通过将业务逻辑集中到一个独立的模型中,而不是分散在多个决策点上,使得修改和维护更加容易,因为所有的状态转换逻辑都集中在一个地方。
- 问题:状态机在业务和技术之间扮演什么角色?
参考回答:状态机作为业务和技术之间的逻辑接口,允许将业务启发式方法转化为代码,使得业务逻辑的实现更加直观和易于理解。
批判性思考 - **状态机的复杂性**:虽然状态机提供了一种结构化的方式来管理复杂的业务逻辑,但在某些情况下,过度使用状态机可能会导致系统变得更加复杂,特别是在状态和转换非常多的情况下。-
学习成本:引入 Spring State Machine 可能需要开发人员学习新的 DSL 和概念,这可能会增加项目的时间和成本。
-
适用性:并非所有项目都适合使用状态机,对于简单的业务逻辑,使用传统的 if-then-else 或 case 语句可能更加直接和高效。
00:06:05-00:06:07
here today and at the
今天在这里,以及在
00:06:07-00:06:09
Normal pace here. So let's see.
这里一切如常。那么,我们来看看。
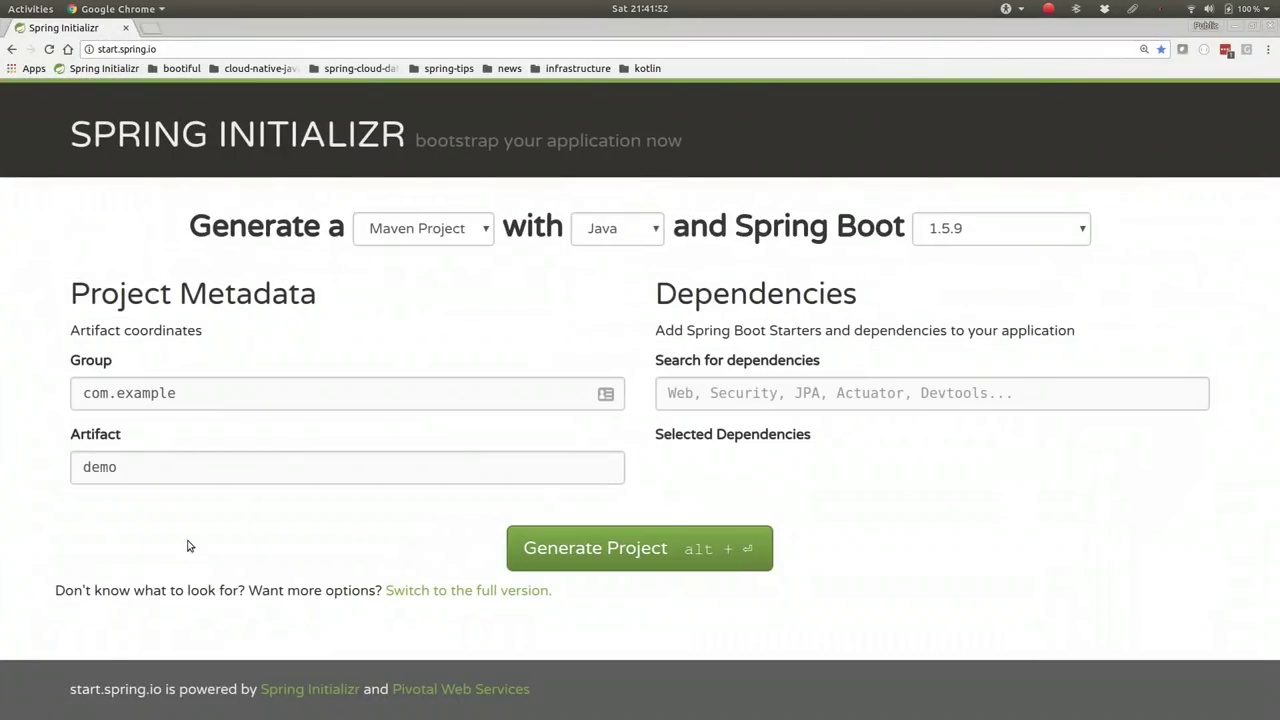
00:06:09-00:06:18
Okay, start.spring.io. We'll build a new application. We're going to call this order service. All right, and we don't need any
好的,我们从 start.spring.io 开始。我们将构建一个新的应用程序。我们打算将其命名为订单服务。好的,我们不需要任何
00:06:18-00:06:39
So let's proceed without including web support. We'll create an application and click Generate. I would like to include JDBC, JPA, and HTTPS.
那么,我们就不包含网络支持进行操作。我们将创建一个应用程序并点击“生成”。我希望包含JDBC、JPA和HTTPS。
00:06:39-00:06:55
So, let me delete the incorrectly downloaded version. We need JDBC, JPA, and I believe that should suffice. I think Lombok is included as well, okay.
好的,我来删除下载错误的版本。我们需要JDBC、JPA,我想这些应该就够了。Lombok应该也包含在内,好的。
00:06:55-00:07:04
Good, so now notice that right now there is no checkbox, and I think that will change pretty soon. If not, I will certainly add one, but in the meantime...
好的,现在请注意,目前这里没有复选框,但我想这一情况很快就会改变。如果不变,我肯定会添加一个,不过在此之前……
00:07:04-00:07:07
We'll just have to add it ourselves. It's just a single dependency. It's not a very complex task.
我们只能自己加上它了。这只是个单一的依赖项,任务并不复杂。
00:07:07-00:07:11
There is not an entire ecosystem of projects; it is just one library.
这里并没有一个完整的项目生态系统,仅仅是一个库而已。
00:07:11-00:07:16
One project, rather, a small project with a few interesting modules. You can use it if you want.
一个项目,确切地说,是一个包含几个有趣模块的小项目。如果你愿意,可以随意使用。
00:07:16-00:08:13
I happen to like it. I think it fits a very nice space. There's a really nice space for describing complex transitions and for reconciling those transitions. If you've ever used the saga pattern, the saga pattern requires you to have a saga execution coordinator, and you can model that with Spring State Machine, for example. The saga pattern is a great way of achieving consensus across multiple workloads, across multiple units of work in a distributed system, or at the very least in a long-running single-node transaction. That's a good example. You could use Spring State Machine to achieve that. You can model more complex business processes that need some sort of representation separate from the actual implementation. You could do that with Spring State Machine as well. Let's suppose we have a very simple order service. We're going to first add our dependency here.
我恰好喜欢它。我认为它非常适合一个非常不错的空间。这里有一个很好的空间,用于描述复杂的转换以及协调这些转换。如果你曾经使用过 saga 模式,saga 模式要求你有一个 saga 执行协调器,例如,你可以用 Spring State Machine 来建模。saga 模式是在分布式系统中,或者至少在长时间运行的单节点事务中,跨多个工作负载、多个工作单元达成共识的好方法。这是一个很好的例子。你可以用 Spring State Machine 来实现这一点。你可以建模更复杂的业务流程,这些流程需要某种与实际实现分离的表示。你也可以用 Spring State Machine 来实现这一点。假设我们有一个非常简单的订单服务。我们首先要在这里添加我们的依赖项。
精炼总结 1. 作者喜欢并认为saga模式适合用于复杂空间。-
saga模式用于分布式系统或长时间运行的单节点事务中,跨多个工作负载达成共识。
-
可以使用Spring State Machine来建模和实现saga模式。
-
Spring State Machine可以用于建模复杂的业务流程,并与实际实现分离。
-
示例中提到了一个简单的订单服务,需要添加依赖项。
- 参考回答:saga模式是一种在分布式系统或长时间运行的单节点事务中,用于跨多个工作负载、多个工作单元达成共识的方法。它主要用于解决在分布式环境中协调复杂事务的问题。
- Spring State Machine如何帮助实现saga模式?
- 参考回答:Spring State Machine是一个框架,可以用于建模和实现saga模式。它允许开发者以一种与实际实现分离的方式来表示复杂的业务流程,从而简化saga模式的实现和管理。
00:08:13-00:08:15
I find the font a bit too small.
我觉得这字体有点太小了。
00:08:15-00:08:21
Small there. Let me adjust the font size slightly. Alright, 22, good.
稍小了点。让我稍微调整一下字体大小。好了,22号,不错。
00:08:21-00:08:27
We will proceed to incorporate Spring State Machine into our project for personal use.
我们将着手在我们的个人项目中整合Spring State Machine。
00:08:27-00:08:31
Kept the dependency aside.
暂且不谈依赖问题。
00:08:31-00:08:44
And we'll add that here. All right, 1.2.3. 1.2.3 is Spring State Machine. That's the version we're going to use. And so we're going to create a new Spring State Machine.
我们在这里添加这个。好的,1.2.3。1.2.3 是 Spring State Machine 的版本,这是我们将要使用的版本。因此,我们将创建一个新的 Spring State Machine。
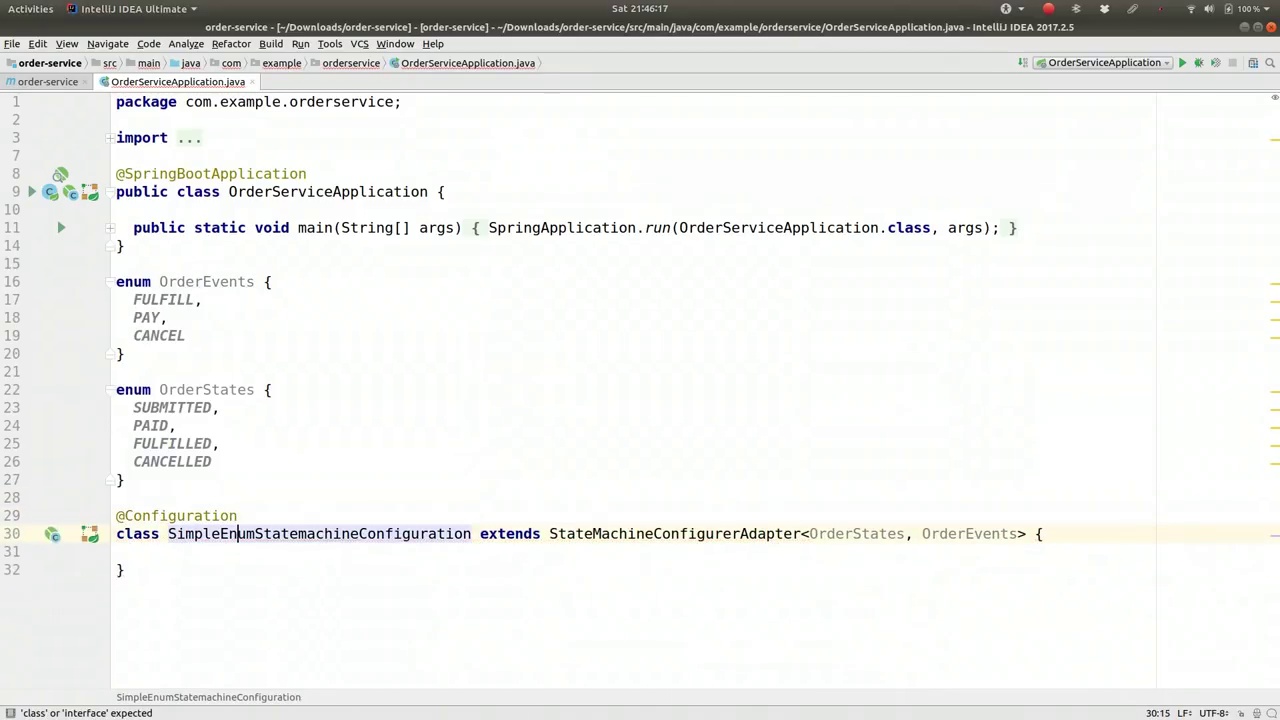
00:08:44-00:10:36
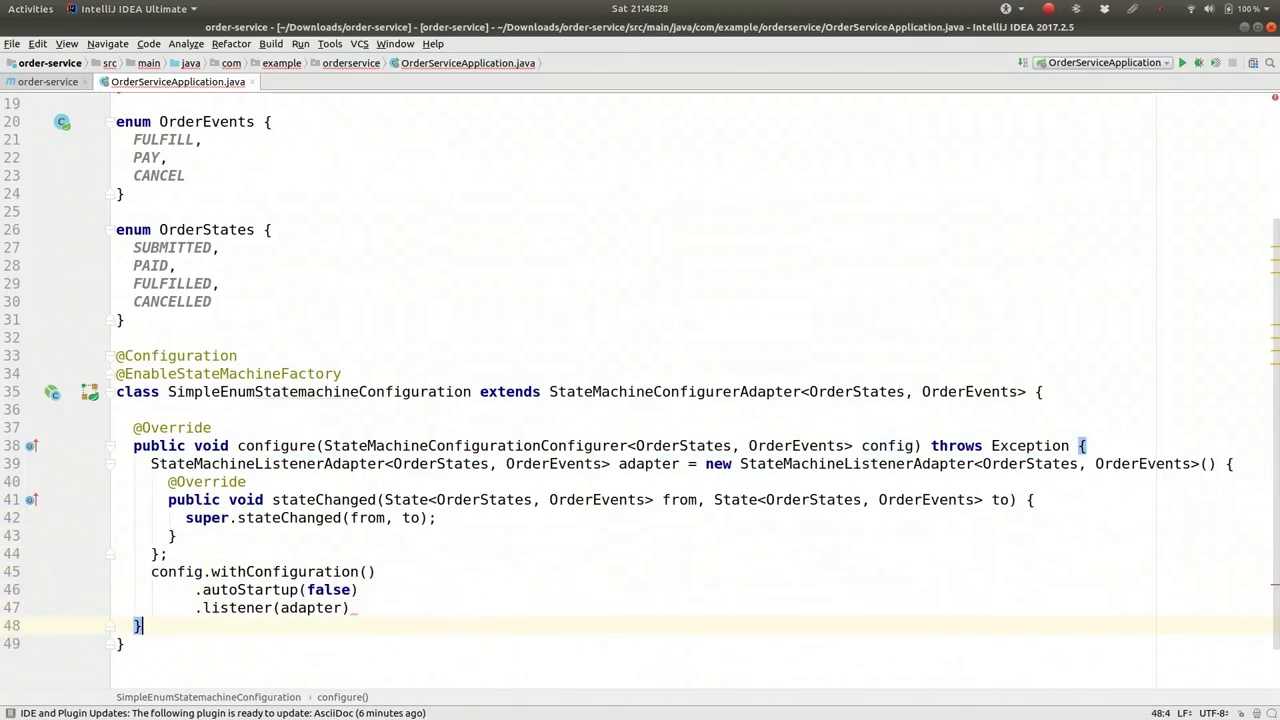
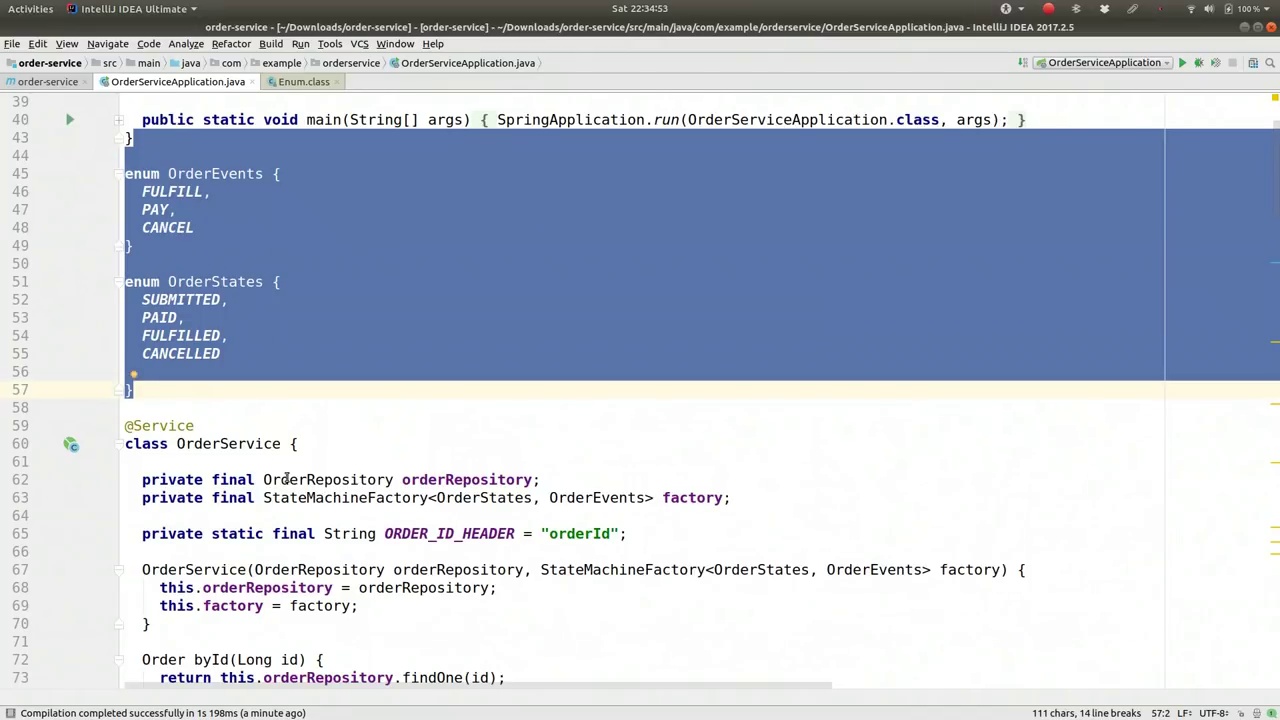
Now, before we proceed, let's configure the state machine itself. The first step is to create a configuration class. We will name it SimpleEnumStateMachineConfiguration and it will extend StateMachineConfigurerAdapter. This class will model a state machine with well-known states that respond to well-known events, a common practice you will often encounter. States can be described using strings or enums; the latter is preferred here for its type-safe approach. We define these states using an enum called OrderStates. When an order is placed on an e-commerce website, it transitions through states such as SUBMITTED, PAID, FULFILLED, and CANCELLED. The fulfillment process involves packaging and shipping the order, while cancellation can occur at any time, though more complex business logic could govern this. The state transitions are triggered by well-known events like PAY, FULFILL, and CANCEL. For instance, sending a PAY event moves the order to the PAID state. Similarly, FULFILL and CANCEL events lead to FULFILLED and CANCELLED states, respectively. We will construct a state machine using these OrderStates and OrderEvents, ensuring states are defined before events.
现在,在我们继续之前,让我们先配置状态机本身。第一步是创建一个配置类。我们将它命名为SimpleEnumStateMachineConfiguration,并让它继承StateMachineConfigurerAdapter。这个类将模拟一个具有已知状态和响应已知事件的状态机,这是你经常会遇到的一种常见做法。状态可以用字符串或枚举来描述;后者因其类型安全的方法而在这里更受青睐。我们使用一个名为OrderStates的枚举来定义这些状态。当一个订单在电子商务网站上被下单时,它会经历诸如已提交、已支付、已履行和已取消等状态。履行过程涉及包装和发货订单,而取消可以在任何时候发生,尽管更复杂的业务逻辑可能控制这一点。状态转换由诸如支付、履行和取消等已知事件触发。例如,发送一个支付事件会将订单移至已支付状态。同样,履行和取消事件分别导致已履行和已取消状态。我们将使用这些OrderStates和OrderEvents构建一个状态机,确保在定义事件之前先定义状态。
-
使用枚举
OrderStates定义状态,包括已提交、已支付、已履行和已取消。 -
状态转换由
支付、履行和取消等事件触发。 -
事件
支付、履行和取消分别导致状态变为已支付、已履行和已取消。
- 参考回答:使用枚举定义状态可以提供类型安全,减少错误,并且更易于维护和理解。
- 在电子商务网站中,订单的
已履行状态具体涉及哪些操作?
- 参考回答:
已履行状态涉及包装和发货订单的操作。
- 文章中提到取消可以在任何时候发生,但在实际业务中,取消订单可能受到特定条件或时间的限制。是否应该在状态机设计中加入更复杂的业务逻辑来控制取消操作的时机和条件?
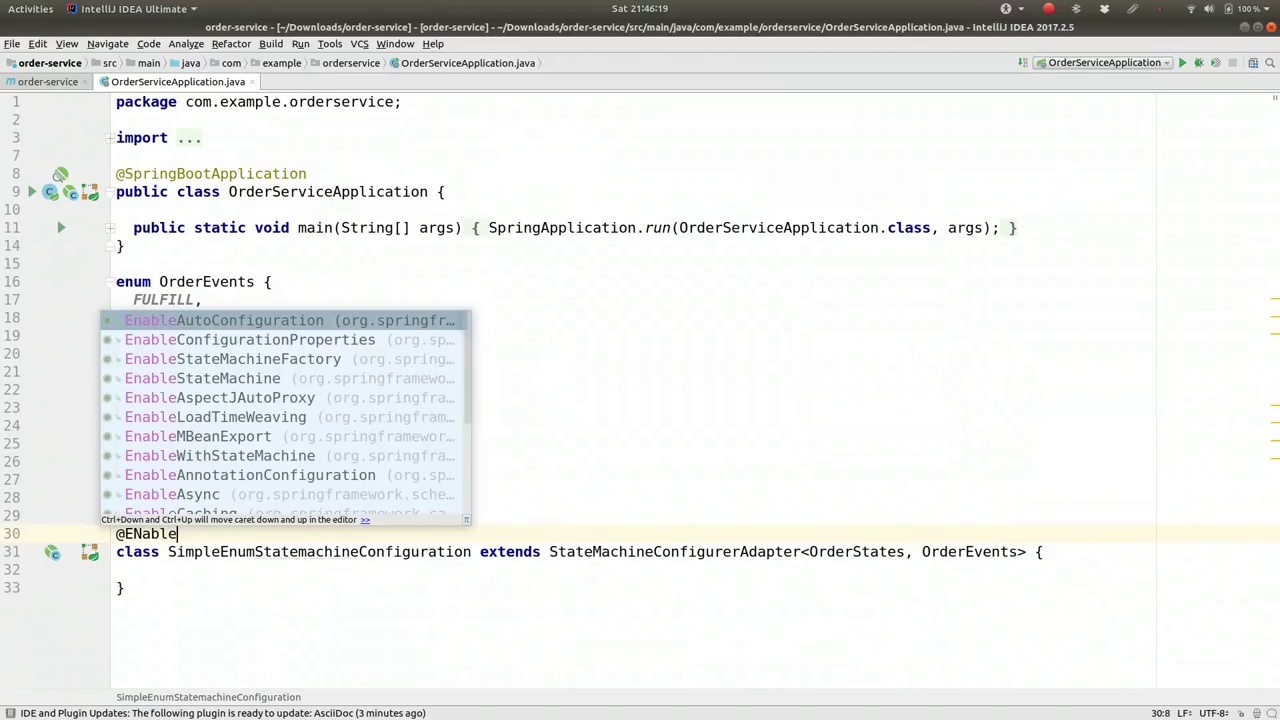
00:10:36-00:11:32
Configuration class, and we want to use the @EnableStateMachine factory. This refers to the ability of SpringStateMachine to either maintain one global state machine or to provide new instances of the state machine for any purpose. I want to provide different instances, so I'm going to use the factory mechanism here. It's worth understanding that you could use the SpringStateMachine project without Spring. I'm using it with Spring because I think it fits well there. However, it is fundamentally a simple library with a builder DSL that you can use. I think it's fine to use it as is with this. So, first, we have to do three things. First, we need to configure the engine itself.
配置类,我们希望使用 @EnableStateMachine 工厂。这指的是 SpringStateMachine 能够维护一个全局状态机或为任何目的提供新的状态机实例的能力。我想要提供不同的实例,因此我将在这里使用工厂机制。值得一提的是,你可以在不使用 Spring 的情况下使用 SpringStateMachine 项目。我选择将其与 Spring 结合使用,因为我认为它在那里很合适。然而,从根本上说,它是一个简单的库,带有构建器 DSL,你可以直接使用。我认为这样使用是没问题的。因此,首先,我们需要做三件事。首先,我们需要配置引擎本身。
-
SpringStateMachine可以维护全局状态机或提供新的状态机实例。 -
作者选择使用工厂机制来提供不同的状态机实例。
-
SpringStateMachine可以在不使用 Spring 的情况下使用,但作者选择将其与 Spring 结合使用。 -
SpringStateMachine是一个带有构建器 DSL 的简单库,可以直接使用。 -
配置
SpringStateMachine需要完成三件事:配置引擎本身。
- 参考回答:
SpringStateMachine可以在任何需要状态机管理的场景下使用,即使不依赖 Spring 框架。
- 为什么作者选择将
SpringStateMachine与 Spring 结合使用?
- 参考回答:作者认为
SpringStateMachine与 Spring 结合使用更合适,可能是因为 Spring 提供了更好的集成和依赖注入机制。
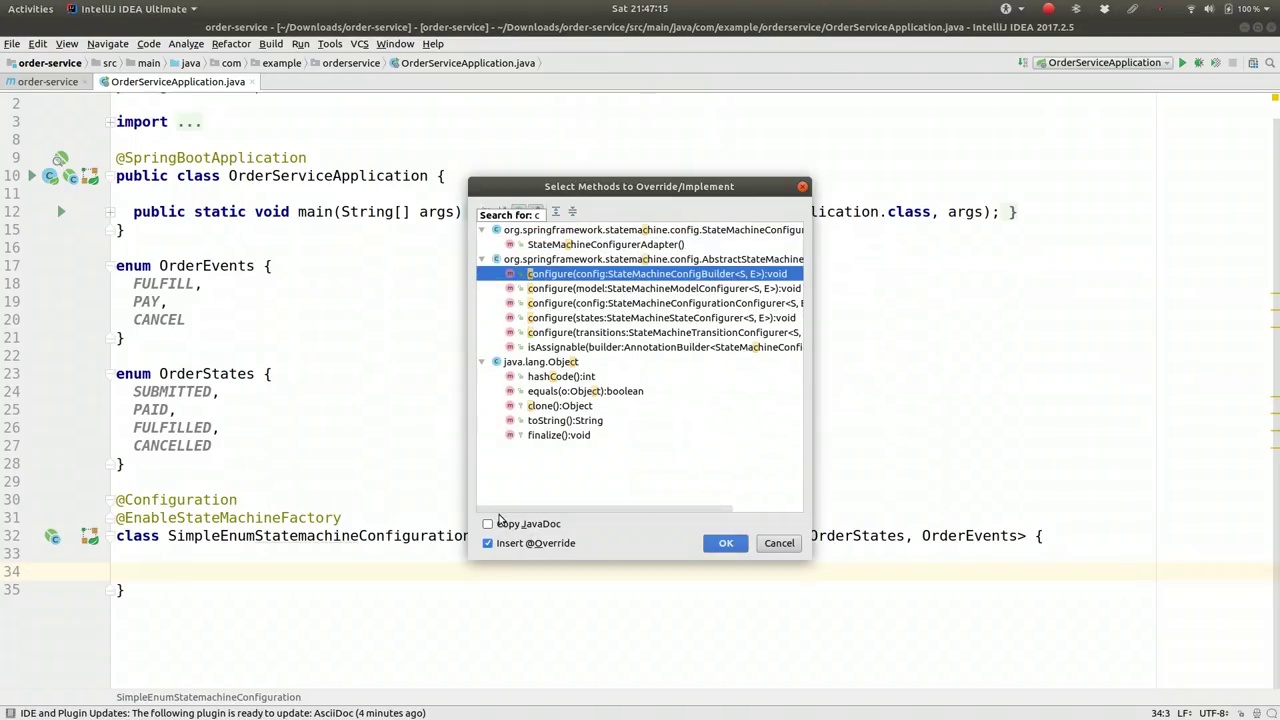
00:11:32-00:12:34
So we'll override the state machine configuration. Configure is the engine itself. Here, we're going to say config. I want to change the configuration. We want to start it up automatically, set that to false, and then we want to specify a listener. Actually, we don't need this right now, but we could provide a state machine listener. So here, we'd have something that we can use. So it's a state machine listener. Let's see, it's order states, order events, and we override any one of these interface methods. So I've got the adapter here, but if I were to override the interface proper, I'd get a number of different callback methods. One that's interesting from I think is the state changed method. So state changed or entered or exited.
因此,我们将覆盖状态机配置。Configure 是引擎本身。在这里,我们要说 config,我想更改配置。我们希望它自动启动,将此设置为 false,然后我们要指定一个监听器。实际上,我们现在不需要这个,但我们可以提供一个状态机监听器。所以这里,我们会有一些可以使用的功能。这是一个状态机监听器。让我们看看,它是订单状态、订单事件,并且我们覆盖这些接口方法中的任何一个。所以我在这里有适配器,但如果我要正确地覆盖接口,我会得到许多不同的回调方法。其中一个有趣的方法是状态变更方法。所以状态变更或进入或退出。
精炼总结 1. 讨论了状态机配置的修改。-
提到了自动启动设置为false。
-
介绍了状态机监听器的使用和功能。
-
强调了覆盖接口方法的重要性,特别是状态变更方法。
参考回答:状态机监听器的主要功能是监听和处理状态机中的状态变更、进入和退出等事件。
- 问题:为什么将自动启动设置为false?
参考回答:将自动启动设置为false可能是为了在某些特定条件下手动控制状态机的启动,以确保系统的灵活性和可控性。
批判性思考 - 虽然文中提到了状态机监听器的重要性和功能,但没有详细说明在实际应用中如何选择和配置监听器,以及不同监听器之间的差异和优劣。-
关于将自动启动设置为false,文中没有提供具体的应用场景或理由,这可能导致读者难以理解这一设置的实际意义和必要性。
-
文中提到的“覆盖接口方法”是一个技术细节,但缺乏对这一操作可能带来的风险和注意事项的讨论,例如可能导致系统不稳定或难以维护。
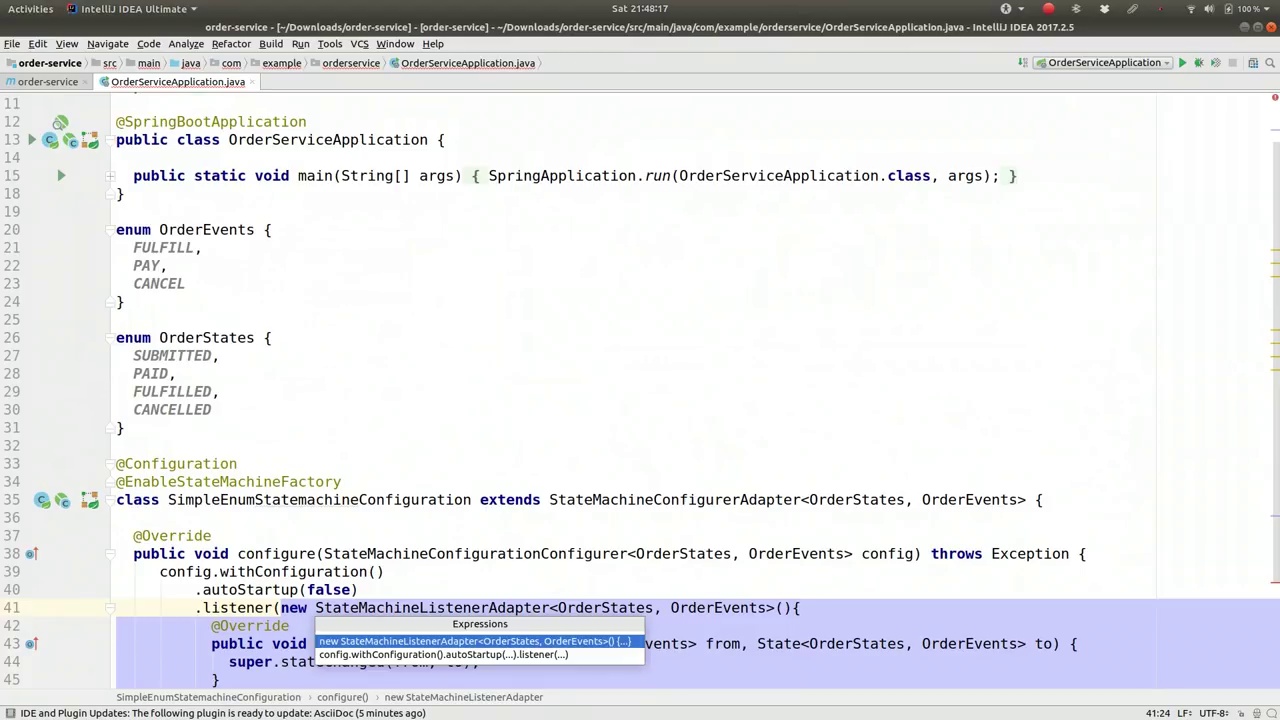
00:12:34-00:12:39
To see when the state changes when the consumer
查看消费者状态何时发生变化
00:12:39-00:12:57
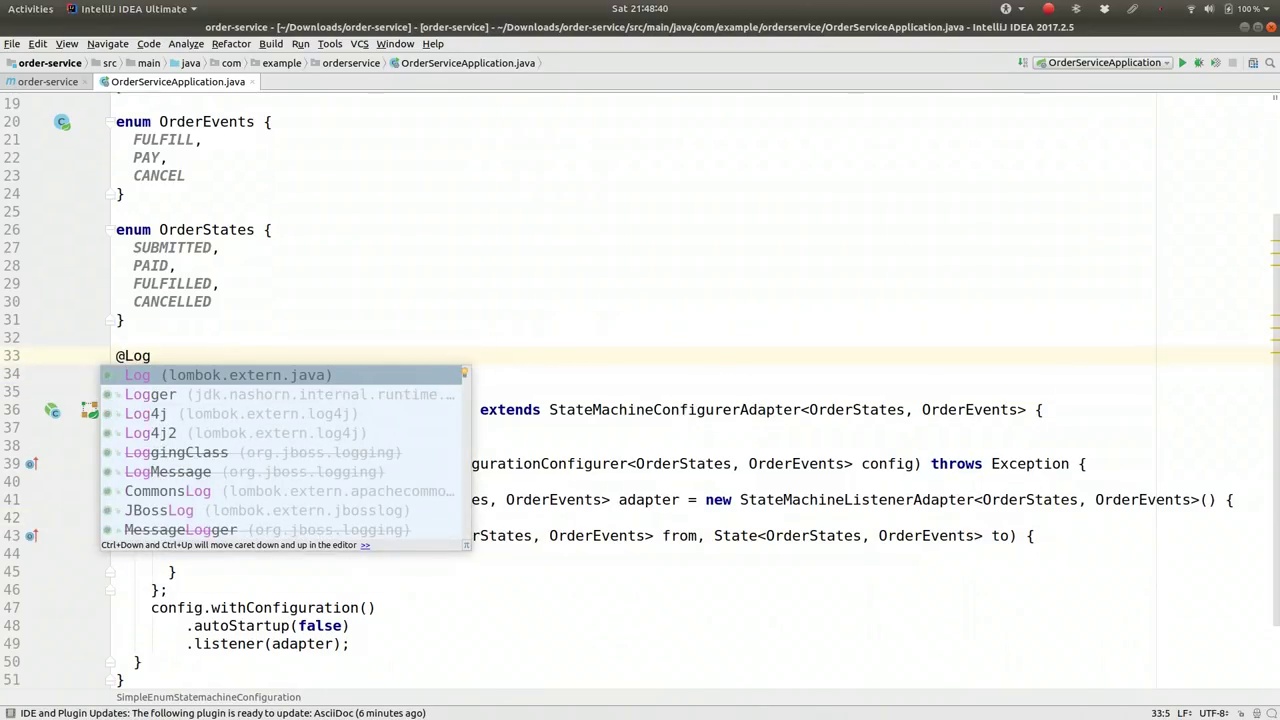
State machine has transitioned from one state to another. Let's extract that into a separate class. We can store that; it's fine. There we go, that's my simple adapter. These are no-op methods based on the interface.
状态机已从一个状态转换到另一个状态。让我们将这一过程提取到一个单独的类中。我们可以存储它;没问题。好了,这就是我的简单适配器。这些是基于接口的空操作方法。
00:12:57-00:13:39
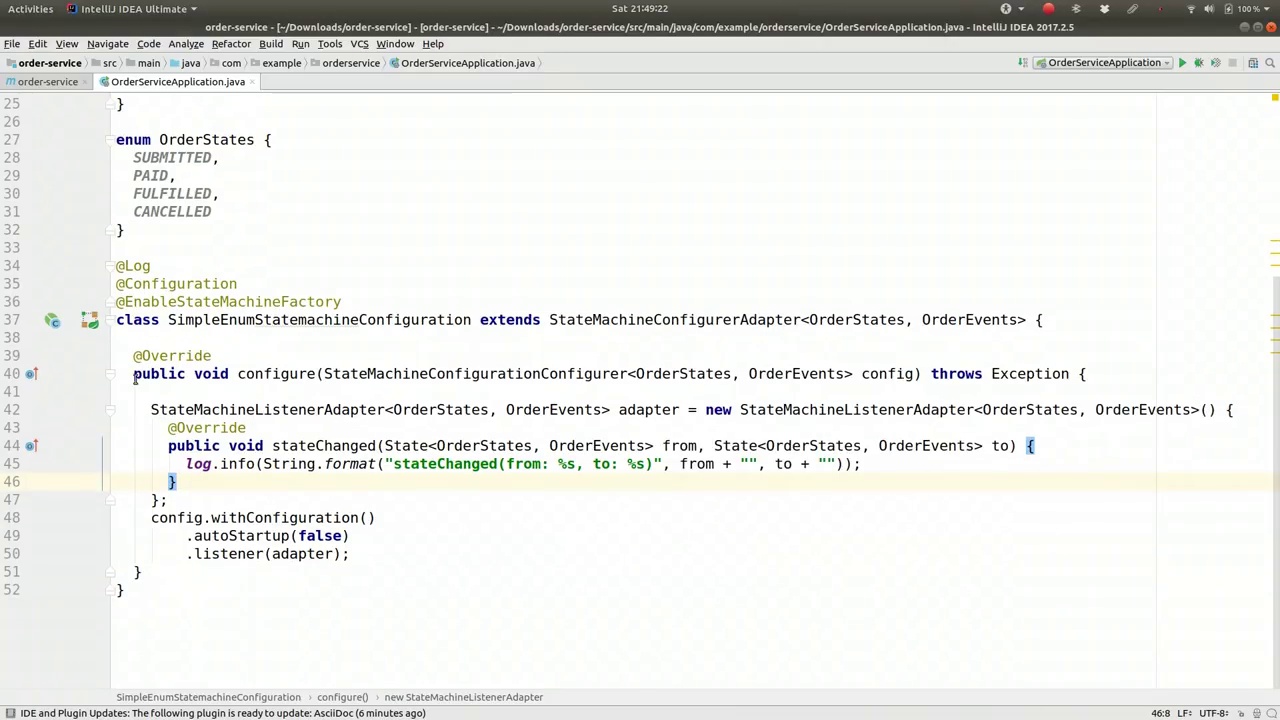
In the code, you can perform any actions you desire. I will simply log the event using Lombok, which is included in the classpath. I'll utilize the @Log annotation to create a logger and log the state change. The log entry will read "State changed from [from state] to [to state]." We'll discuss the specifics in a moment. For now, the log message will be formatted as "from.toString() + to.toString()". This simple listener implementation demonstrates the basic logging functionality.
在代码中,你可以执行任何你希望的操作。我只需使用Lombok记录事件,它已包含在类路径中。我会利用@Log注解创建一个记录器并记录状态变化。日志条目将显示为“状态从[原状态]变为[新状态]”。稍后我们将详细讨论具体细节。目前,日志消息将格式化为“from.toString() + to.toString()”。这个简单的监听器实现展示了基本的日志记录功能。
-
记录状态变化,日志条目格式为“状态从[原状态]变为[新状态]”。
-
日志消息格式为“from.toString() + to.toString()”。
-
展示了基本的日志记录功能。
参考回答:Lombok的@Log注解通过自动生成记录器实例,简化了手动创建和配置记录器的过程,使得开发者可以更专注于业务逻辑的实现。
- 问题:日志条目的具体格式是什么?
参考回答:日志条目的具体格式是“状态从[原状态]变为[新状态]”,其中原状态和新状态是通过调用对象的toString()方法得到的字符串表示。
- 日志条目的格式固定为“状态从[原状态]变为[新状态]”,这种固定格式可能在某些复杂的应用场景中不够灵活。开发者可能需要根据具体需求调整日志格式,以提供更详细或更符合特定业务逻辑的日志信息。
00:13:39-00:13:53
Actually, you probably don't need to do this first, but it's always nice to have it. Since we're using the factory, we don't want to start up a global state machine when we start the application, so we'll disable that immediately as the first thing.
实际上,您可能并不需要首先进行这一步,但有它总是好的。因为我们使用的是工厂模式,所以在启动应用程序时,我们不希望启动一个全局状态机,因此我们首先要做的就是立即禁用它。
00:13:53-00:15:49
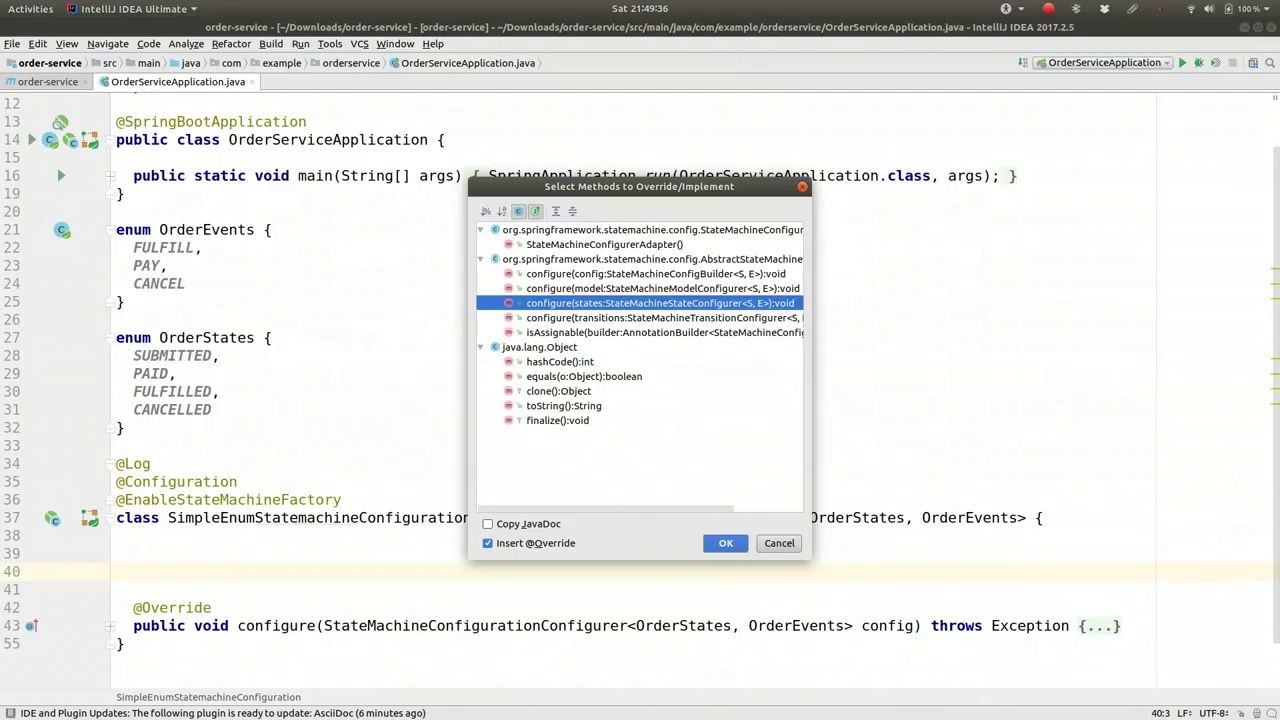
Now, the next thing we want to override is the state machine states themselves. So we need to actually tell the state machine about the different states. So we use the state machine state configurer. And we'll say states.withStates.initial. So what we're going to do is we're going to provide a directed graph. We're trying to describe which states are the genesis of a state machine, which ones are the termination, and which ones are progressions, which ones are actual states that can be kept or maintained or whatever. And we can do complex things here. We can do a splitting and joining. And we can describe custom things here. But for our purposes, we just want to describe which one is the initial one. So the initial is going to be a submitted, right? So order machines, order states, rather, submitted. That's the first state that our state machine will be in when it starts up. We're going to have another state called orderStatesPaid. And then there are two terminal ones. And one is called orderStatesFulfilled. And another one is called orderStates.canceled. So there's two different states that can finish the workflow. So we can either end correctly on a fulfilled, or we can cancel it. These are both terminal conditions. The state machine is done if we enter either of those states. Now finally, we need to actually describe the transitions from one state to another. So here, we'll use the state machine transition configure. So let's see. That is this one here.
接下来,我们要重写的是状态机本身的状态。因此,我们需要向状态机告知不同的状态。我们使用状态机状态配置器,并声明states.withStates.initial。我们要做的是提供一个有向图,描述哪些状态是状态机的起始点,哪些是终止点,哪些是过渡状态,哪些是实际可保持或维护的状态。在这里,我们可以进行复杂的操作,比如拆分和合并,还可以定义自定义内容。但就我们的目的而言,我们只需描述哪个是初始状态。初始状态将是“已提交”,对吧?因此,订单状态机的第一个状态是“已提交”。我们将有另一个状态叫做“已支付”。然后有两个终止状态,一个是“已完成”,另一个是“已取消”。这两种状态都可以结束工作流程。我们可以正确地在“已完成”状态下结束,或者取消它。这两种都是终止条件。一旦进入其中任何一个状态,状态机就完成了。最后,我们需要描述从一个状态到另一个状态的转换。这里,我们将使用状态机转换配置器。让我们看看,就是这个。
-
提供有向图描述状态机的起始点、终止点、过渡状态和实际状态。
-
初始状态为“已提交”,后续状态包括“已支付”、“已完成”和“已取消”。
-
“已完成”和“已取消”为终止状态,结束工作流程。
-
使用状态机转换配置器描述状态间的转换。
参考回答:初始状态是“已提交”。
- 问题:状态机中有哪些终止状态?
参考回答:终止状态包括“已完成”和“已取消”。
批判性思考 - 原文中提到可以进行复杂的操作如拆分和合并,但实际描述中并未详细说明这些操作的具体实现方式和应用场景,这可能导致读者对状态机的灵活性和复杂性理解不足。-
状态机的描述侧重于状态的定义和转换,但对于状态间的逻辑关系和业务规则的描述较为简略,这可能影响读者对状态机在实际业务流程中应用的理解和设计。
-
原文中提到“已完成”和“已取消”都是终止状态,但未详细说明这两种状态在业务逻辑上的区别和处理方式,这可能导致在实际应用中对这两种状态的处理不够明确和一致。
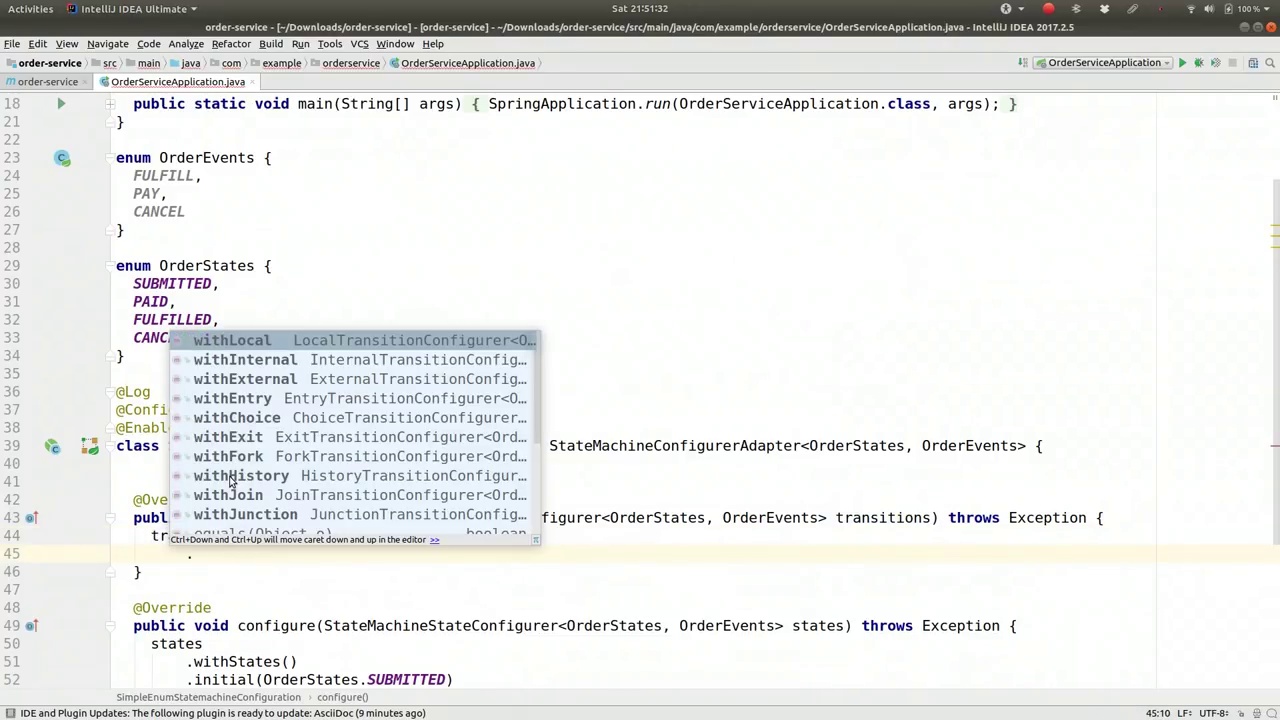
00:15:49-00:19:04
And here, we're going to say transitions dot, and here you can see there's a lot of different types of transitions, a lot of different ways for transitions to be triggered or activated, and a lot of different kinds of transitions themselves and things that you can actually do with them. So if you, for example, had a state machine that just went from start to A to Z, if you had from A and then B and then C and then D directly with absolutely no intervention at all, that'd be called a local transition, right? You could say with local source, and the source would be, let's say, for example, order states dot submitted dot, and then the target would be order states, what did we say, fulfilled? Yeah, fulfilled. So that would be, if we were to create a state machine like that, it would start up, it would go from submitted directly to fulfilled, and it would just be automatic. As soon as a program started, it would continue doing that, which isn't that useful. Usually you want to, unless you want to automatically advance the token represented, or the token representing each state, if you want to automatically advance it to the next state when the application starts up, or based on it having entered some other state, then this is probably useful. But in our case, we want our state machine to change only in response to some sort of event. So commonly, I find that I use with external. So with external gives you three options here in the DSL. So you specify the source. So one source is submitted, and the target is going to be paid, and then the event that can trigger that transition is the pay event, so that's one state transition that we care about. Another one is and. Here we're going to say source with external first, dot, let's see, keep this a little cleaner. Let's try it like that. There we go. So source paid, target is fulfilled, and event is fulfilled. All right. There we go. So that's another progression. So it'll go from submitted to paid with a pay event, and then from there it'll go from paid to fulfilled with a fulfill event. What else do we want? With external, oh sorry, and with external, source, order state submitted to cancel. So we want to be able to support canceling it at any point, right? So cancelled based on the cancel event, cancel, all right, and we're going to duplicate that again here for the paid, you know, if it's in the paid state, we're going to be able to cancel it as well. So here paid to cancelled based on the
在这里,我们要说的是“transitions”点,你可以看到有很多不同类型的转换,很多不同的触发或激活转换的方式,以及很多不同种类的转换本身和你可以用它们做的事情。比如说,如果你有一个状态机,它只是从开始到A再到Z,如果你从A到B再到C再到D,完全没有干预,那就会被称作本地转换,对吧?你可以说“本地源”,源可以是,比如说,订单状态点“已提交”,然后目标就是订单状态,我们说的是“已完成”吗?是的,已完成。所以如果我们创建这样一个状态机,它会启动,直接从“已提交”转到“已完成”,完全是自动的。一旦程序开始,它就会持续这样做,这并不是很有用。通常你希望,除非你想自动推进代表每个状态的令牌,如果你想在应用启动时或基于进入其他状态时自动推进到下一个状态,这可能是有用的。但在我们的例子中,我们希望状态机只在响应某种事件时改变。所以通常我发现我使用“外部”。所以在DSL中,“外部”给你三个选项。你指定源。所以一个源是“已提交”,目标是“已支付”,然后可以触发该转换的事件是“支付”事件,这是我们关心的一个状态转换。另一个是。这里我们要说“外部源”点,让我们保持简洁一点。就这样吧。所以源是“已支付”,目标是“已完成”,事件是“完成”。好了。这是另一个进展。它会从“已提交”到“已支付”通过“支付”事件,然后从那里它会通过“完成”事件从“已支付”到“已完成”。我们还想要什么?外部,哦对不起,外部,源,订单状态从“已提交”到“取消”。所以我们希望能够随时支持取消,对吧?所以基于“取消”事件取消,好的,我们在这里还要为“已支付”再重复一次,你知道,如果它在“已支付”状态,我们也能够取消它。所以这里从“已支付”到“取消”基于“取消”事件。
精炼总结 1. 状态机中的转换类型包括本地转换和外部转换。-
本地转换是自动进行的,如从“已提交”直接到“已完成”。
-
外部转换需要特定事件触发,如“支付”事件触发从“已提交”到“已支付”。
-
状态机支持在特定状态下响应“取消”事件,如从“已支付”到“取消”。
参考回答:本地转换是自动进行的,不需要外部事件触发;而外部转换需要特定事件触发才能进行状态转换。
- 问题:在状态机中,如何处理“取消”事件?
参考回答:在状态机中,可以通过设置外部转换,使得在特定状态下(如“已支付”)响应“取消”事件,从而进行状态转换到“取消”。
批判性思考 - 原文中提到的状态机设计主要依赖于外部事件触发状态转换,这种设计虽然灵活,但也可能导致系统对外部事件的依赖过强,一旦外部事件处理不当,可能会影响整个状态机的稳定性和可靠性。- 另外,状态机的设计中没有提到如何处理异常情况或错误处理机制,这在实际应用中是非常重要的,因为任何系统都可能遇到意外情况,需要有相应的应对策略。
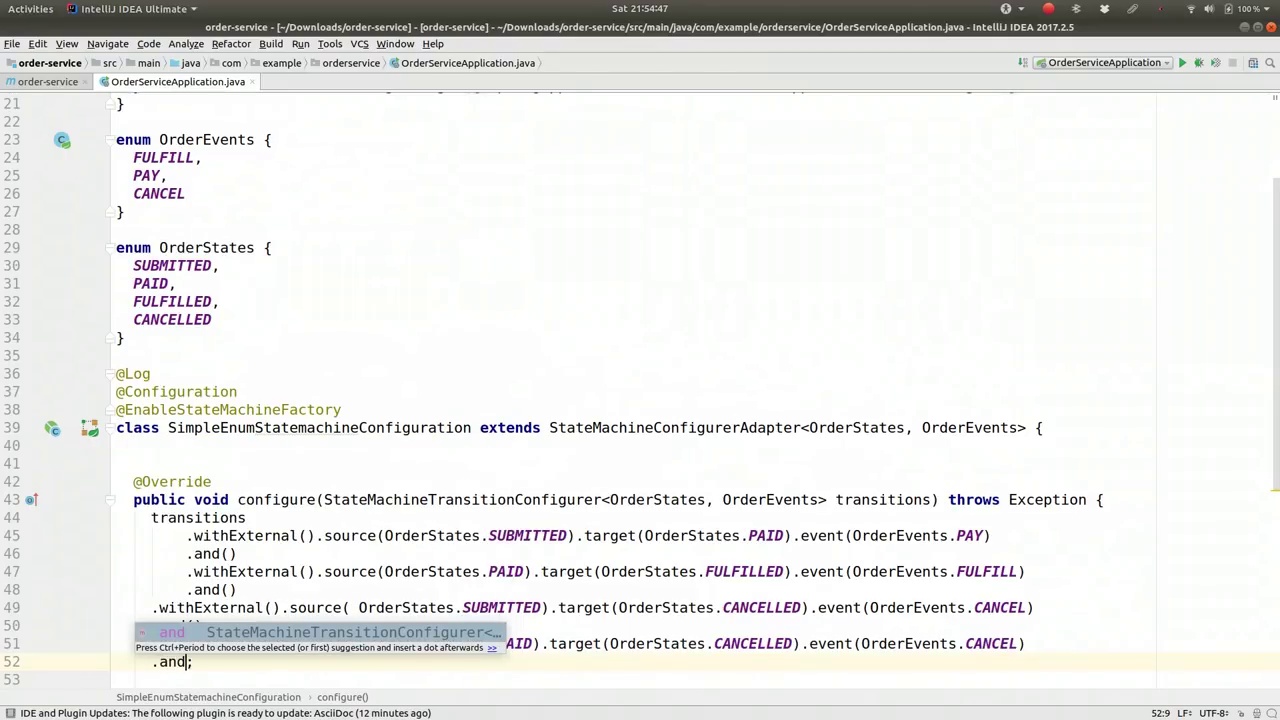
00:19:04-00:19:44
Cancel event and then finally, we want to cancel it if it's in the fulfilled state. So, with external dot source fulfilled dot target will be cancelled and then the event will be cancelled. All right, there we are. So, there are numerous different states here. It's going from submitted to paid, paid to fulfilled, and fulfilled is our final state, right? So that's a successfully finished workflow or the state machine. We also have submitted to cancelled, paid to cancelled, and fulfilled to cancelled. Then, one could argue that this is
取消事件,然后最终,如果事件处于已完成状态,我们也希望取消它。因此,通过external.source.fulfilled.target将被取消,随后事件也会被取消。好了,就是这样。这里有许多不同的状态。它从已提交变为已支付,已支付变为已完成,而完成是我们最终的状态,对吧?这就是一个成功完成的工作流程或状态机。我们还有从已提交到已取消,已支付到已取消,以及已完成到已取消的状态转换。然后,有人可能会说这
精炼总结 1. 事件状态包括已提交、已支付、已完成和已取消。- 状态转换路径包括:
-
已提交到已支付
-
已支付到已完成
-
已完成到已取消
-
已提交到已取消
-
已支付到已取消
- 最终状态为已完成或已取消。
参考回答:事件在已提交、已支付和已完成状态下可以被取消。
- 问题:已完成状态的事件为何也需要取消?
参考回答:即使事件处于已完成状态,也可能因为某些原因需要取消,例如外部因素或错误操作。
批判性思考 - 原文描述了一个典型的状态机模型,用于管理事件的不同状态和转换。然而,这种模型可能过于简化,没有考虑到实际操作中可能出现的复杂情况,如状态转换的触发条件、错误处理机制等。- 此外,原文没有详细说明取消事件的具体原因和后果,这可能导致在实际应用中缺乏灵活性和适应性。例如,如果取消操作频繁发生,可能需要更细致的状态管理和错误恢复策略。
00:19:44-00:19:52
Very useful, so maybe we'll actually get rid of that one. It doesn't seem to be particularly useful since they're both terminal states, but okay.
非常有用,所以也许我们真的会去掉那一个。既然它们都是终止状态,似乎并没有特别大的用处,不过好吧。
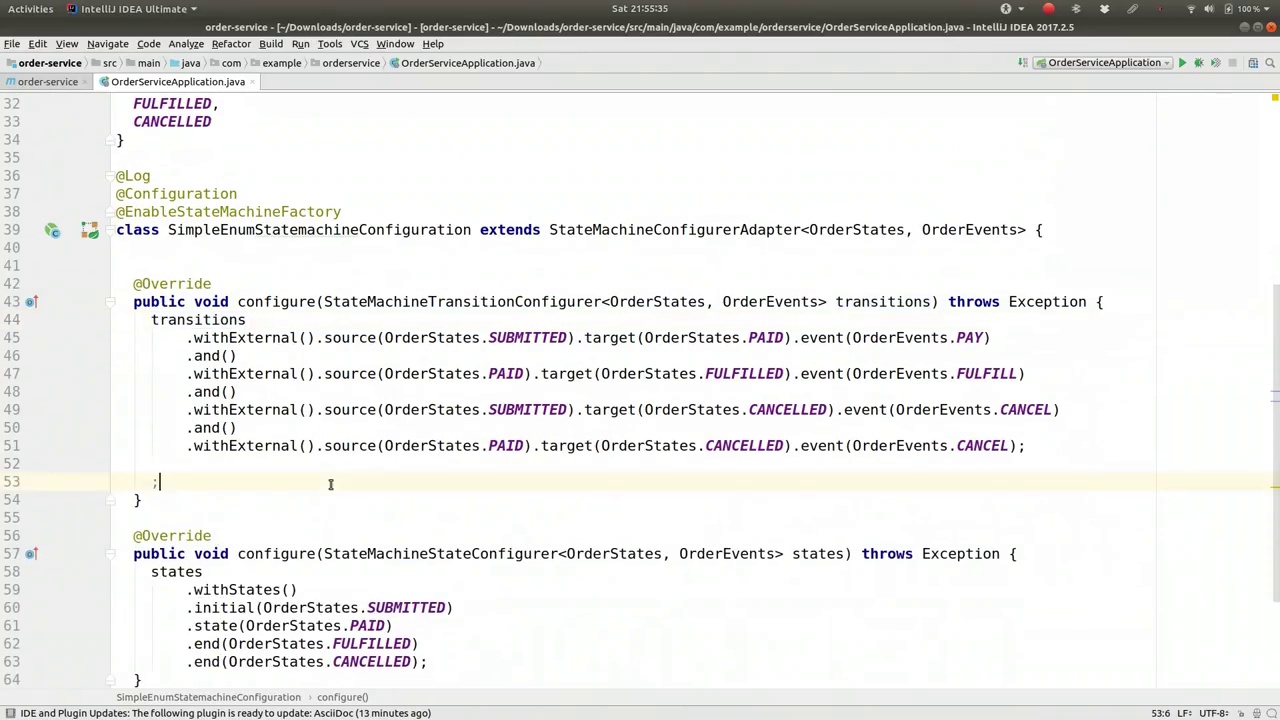
00:19:52-00:20:22
So there we go, there are our states. And that's it, right? We've configured a state machine. It's a lot of configuration, but you get a working result. So let's actually try it out. Let's actually use the state machine and just advance it. Let's just use it to move data, to move the token represented by the state machine from one state to another. So we're going to actually create a command line.
好了,这就是我们的状态。就这样,对吧?我们已经配置了一个状态机。虽然配置过程繁琐,但最终得到了一个可运行的结果。现在,让我们实际尝试一下。我们来使用这个状态机,并让它前进。我们将利用它来移动数据,将由状态机表示的令牌从一个状态转移到另一个状态。因此,我们将实际创建一个命令行。
精炼总结 1. 配置了一个状态机,过程繁琐但最终成功。-
状态机可运行,用于移动数据和转移令牌。
-
计划创建一个命令行来使用这个状态机。
- 参考回答:原文提到配置过程繁琐,具体挑战可能包括复杂的设置步骤、需要调整的参数多、可能出现的错误调试等。
- 状态机如何具体用于移动数据和转移令牌?
- 参考回答:状态机通过定义不同的状态和状态间的转移条件,可以控制数据在不同状态间的流动,从而实现数据的移动和令牌的转移。
00:20:22-00:20:52
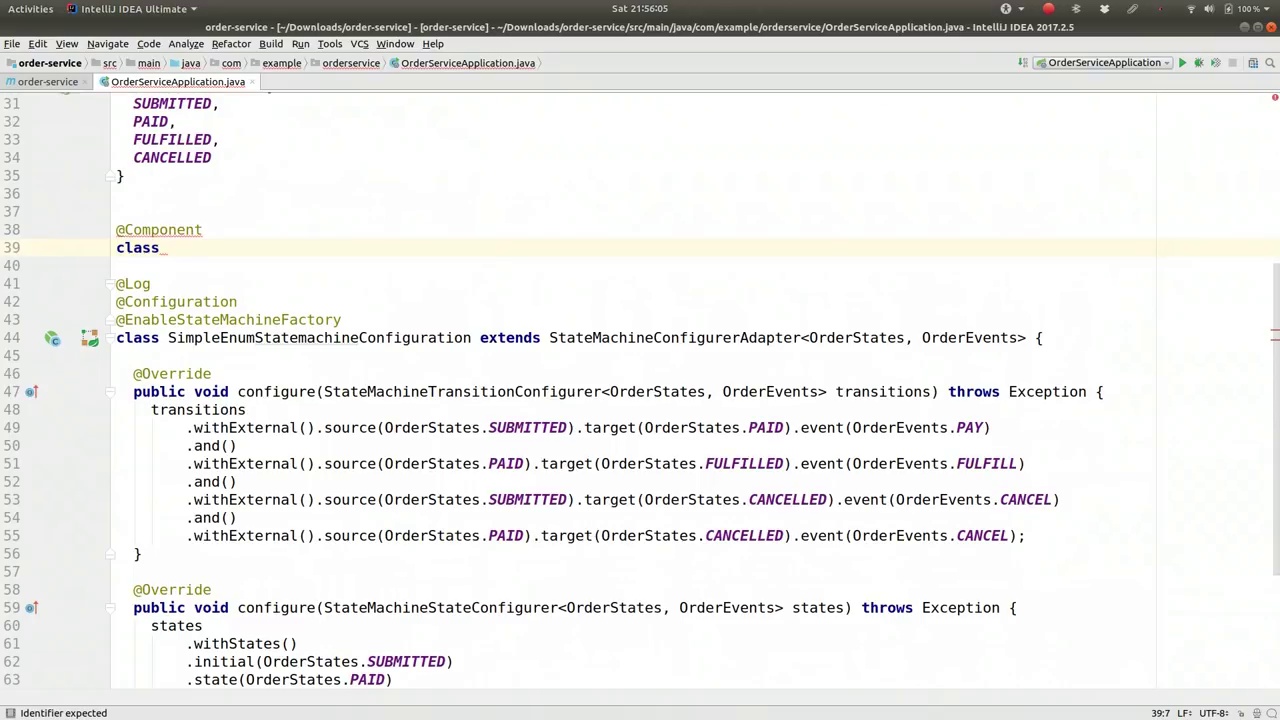
The runner class takes advantage of a state machine factory. The class, named Runner, implements ApplicationRunner and injects a private final state machine factory for OrderStates and OrderEvents, referred to as factory.
运行器类利用了状态机工厂。该类名为Runner,实现了ApplicationRunner接口,并注入了一个私有的最终状态机工厂,用于OrderStates和OrderEvents,称为factory。
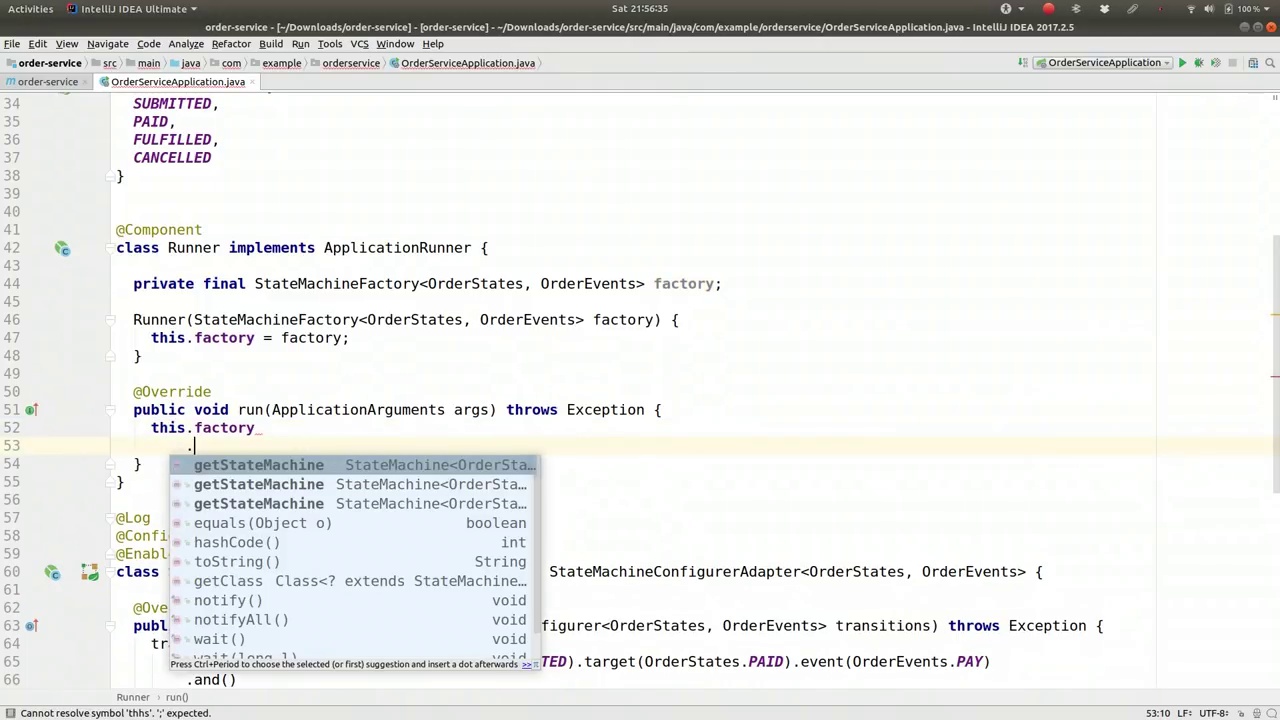
00:20:52-00:22:08
Factory dot get state machine this stuff factory dot get state machine so that's it actually with that's the result there we have a state mission we have a valid new instance of the state machine we can also provide a unique ID for unlike to have multiple instances so maybe you have a state machine for a particular order number right order 75 whatever right whatever you want whatever you want to be able to correlate or to build a you know correlate the state machine to whatever external state you've got so let's see what happens let's actually interact with this so machine dot start right so let's hit start and then we'll say machine dot get state and that'll give us the current state and we're gonna get the ID and then the name right so let's print it out it's actually a log that out so when I say at log and we'll go down here log dot info current state is that right run the code
工厂获取状态机,这就是我们得到的结果。我们有一个状态机任务,并且获得了一个有效的新状态机实例。我们还可以为每个实例提供一个唯一的ID,以便管理多个实例。例如,你可能有一个特定订单号(如订单75)的状态机,这样你就可以将状态机与任何外部状态关联起来。让我们看看实际操作中会发生什么。首先,我们启动状态机,调用machine.start,然后获取当前状态,即machine.getState。这将返回当前状态的ID和名称。让我们打印出来,实际上是记录下来。所以当我调用log时,我们会在这里记录下来,log.info显示当前状态是正确的,运行代码。
-
为每个状态机实例提供唯一的ID,便于管理多个实例。
-
状态机可以与外部状态(如订单号)关联。
-
启动状态机并获取当前状态,记录状态信息。
- 参考回答:通过为每个状态机实例提供一个唯一的ID,并将这个ID与外部状态(如订单号)进行关联,从而实现状态机与外部状态的关联。
- 在实际操作中,如何启动状态机并获取当前状态?
- 参考回答:通过调用
machine.start方法启动状态机,然后调用machine.getState方法获取当前状态,该方法返回当前状态的ID和名称。
- 状态机与外部状态的关联虽然增强了状态机的应用灵活性,但也增加了系统的复杂性。在设计时需要考虑如何有效地管理和同步这些外部状态,以避免状态不一致或错误的情况发生。
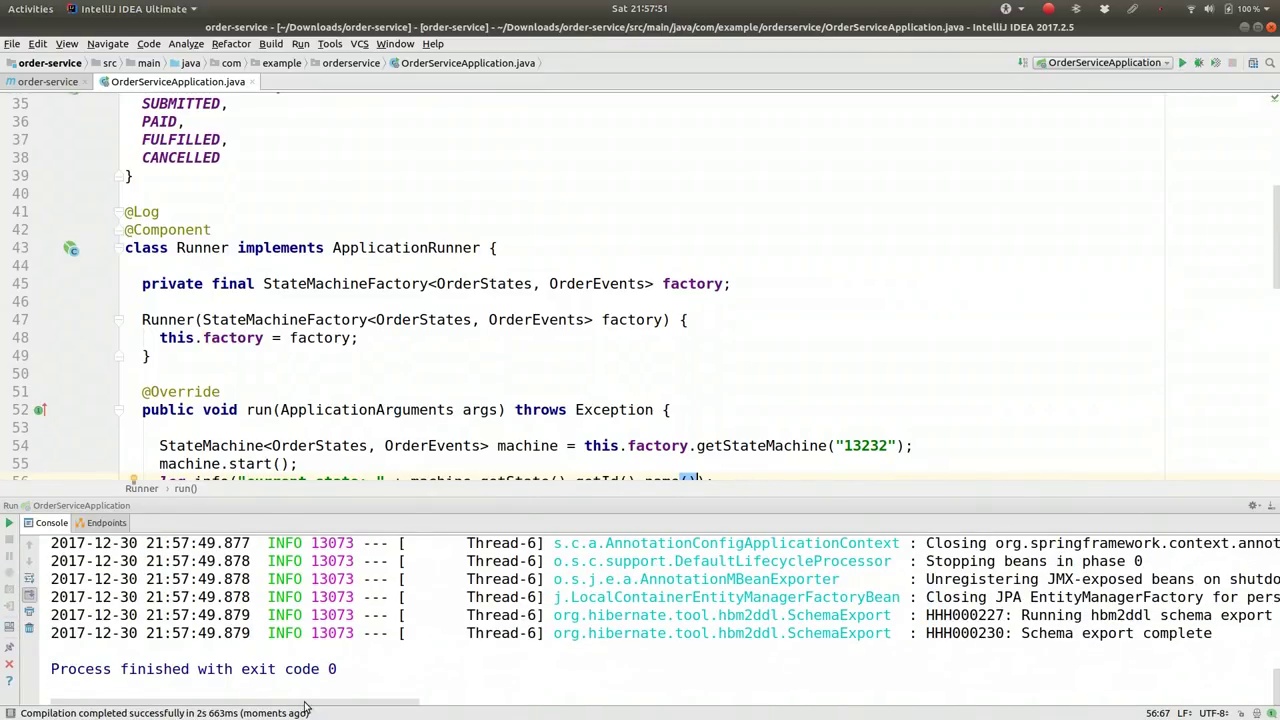
00:22:08-00:22:41
All right, what did we get? So the state change, we saw the listener there. State changed from null, so it's the first one, to object state submitted. So when it first started up, it automatically goes to the initial state, which is submitted. We can see that the machine has actually started. And so these are the different states. The current state is submitted. Here's the UUID for it. And there's the random ID that we gave it.
好的,我们来看看得到了什么。状态变化,我们看到监听器在那儿。状态从 null 变为对象状态 submitted,这是第一个状态。因此,当它首次启动时,会自动进入初始状态,即 submitted 状态。我们可以看到机器实际上已经启动了。这些是不同的状态,当前状态是 submitted。这是它的 UUID,还有我们给它的随机 ID。
精炼总结 1. 状态变化:从 null 变为 submitted 对象状态。-
初始状态:系统启动后自动进入 submitted 状态。
-
当前状态:submitted 状态。
-
标识信息:状态的 UUID 和随机 ID。
- 参考回答:原文未明确说明具体触发条件,但可以推测是在系统启动时自动触发的。
- 问题:UUID 和随机 ID 在系统中分别起什么作用?
- 参考回答:UUID 通常用于唯一标识状态对象,而随机 ID 可能用于其他特定用途,如临时标识或辅助功能。
- 对于 UUID 和随机 ID 的描述,原文仅简单提及,未详细解释它们在系统中的具体作用和重要性,这可能影响读者对系统设计的全面理解。
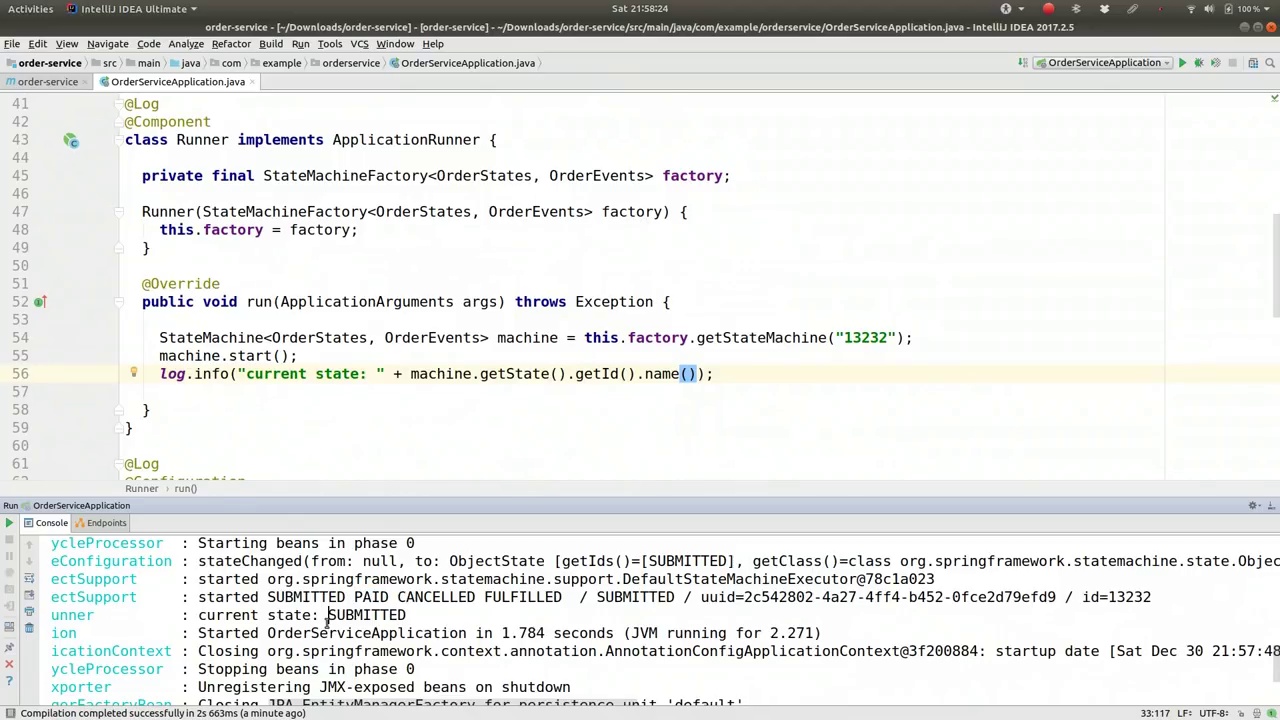
00:22:41-00:23:17
We printed out the current state, which was "submitted," and the program finished at that point. Now, let's continue. Suppose we want to trigger the transition from "fulfilled" to "paid." We can send an event in several ways. For instance, we can use "order events" and pass in one of the events, such as "order events dot fulfill." This will provide more details. Now, let's input that again and run the application. If we look at this...
我们打印出了当前状态,即“已提交”,程序在此处结束。现在,让我们继续。假设我们希望触发从“已履行”到“已支付”的状态转换。我们可以通过几种方式发送事件。例如,我们可以使用“订单事件”并传入其中一个事件,比如“订单事件点履行”。这将提供更多细节。现在,让我们再次输入并运行应用程序。如果我们查看这个...
精炼总结 1. 程序在“已提交”状态结束。-
讨论了从“已履行”到“已支付”的状态转换。
-
提到了通过“订单事件”发送事件,如“订单事件点履行”。
-
建议再次输入并运行应用程序以查看状态转换。
参考回答:可以通过发送“订单事件”并传入“订单事件点履行”来触发状态转换。
- 问题:为什么需要再次输入并运行应用程序?
参考回答:为了查看和验证状态转换是否成功,需要再次运行应用程序。
批判性思考 - 原文中提到的状态转换机制可能过于简化,实际应用中可能需要考虑更多的业务逻辑和异常处理。例如,如果“已履行”状态下的订单存在问题,是否应该直接转换到“已支付”状态?-
原文没有详细说明“订单事件点履行”的具体内容和作用,这可能导致读者对状态转换的具体实现不够清晰。在实际开发中,应该详细定义每个事件的具体参数和处理逻辑。
-
原文建议再次输入并运行应用程序以查看状态转换,但未提及如何监控和调试这一过程。在实际操作中,开发者可能需要使用日志记录、断点调试等工具来确保状态转换的正确性。
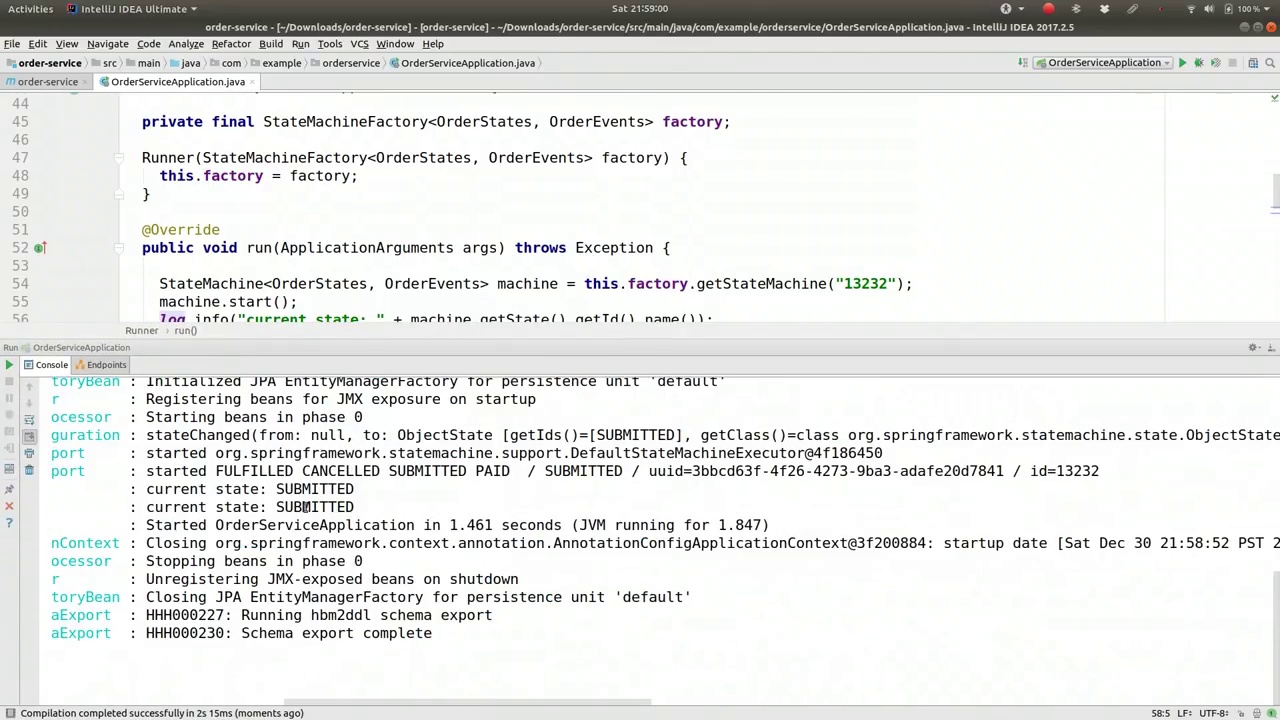
00:23:17-00:23:42
Current state is again submitted. Oh, what did I do wrong? We said it's submitted. We have to pay, don't we? See, I can't. That's actually a good demo. I can't go from submitted to fulfilled. I have to go through the predictable, well-known states here, right? It's not going to let me enter an invalid state. So I'm not going to be able to do something that's outside of
当前状态再次被提交。哦,我哪里做错了呢?我们明明说了已经提交了。我们得付款,不是吗?你看,我做不到。这其实是个很好的演示。我不能直接从提交状态跳到完成状态。我必须按照这些可预测、众所周知的步骤来,对吧?系统不会允许我进入一个无效的状态。所以我无法执行超出这些步骤的操作。
精炼总结 1. 当前状态再次被提交,表明之前的提交未被正确处理。-
用户疑惑为何需要再次提交,因为之前已确认提交。
-
用户需要付款,但目前无法进行,因为状态不允许。
-
用户强调必须遵循预设的步骤,系统不允许跳过步骤或进入无效状态。
-
用户无法执行超出预设步骤的操作。
参考回答:可能是因为系统错误、网络问题或之前的提交未被正确接收。
- 问题:用户提到的“可预测、众所周知的步骤”具体指的是哪些步骤?
参考回答:这些步骤可能包括提交申请、审核、付款、确认等,具体取决于系统的操作流程。
批判性思考 1. 系统设计的局限性:原文中用户提到必须遵循预设的步骤,这反映了系统设计的局限性。系统可能过于僵化,不允许用户在特定情况下灵活操作,这可能导致用户体验不佳。-
用户操作的困惑:用户对为何需要再次提交感到困惑,这表明系统在状态管理和用户反馈方面可能存在不足。系统应该提供更清晰的状态指示和错误提示,帮助用户理解当前操作的必要性和原因。
-
系统与用户需求的匹配:用户无法执行超出预设步骤的操作,这可能限制了用户在特定情况下的需求。系统设计时应考虑更多用户场景,允许在特定条件下进行状态跳转或操作调整,以提高系统的灵活性和用户满意度。
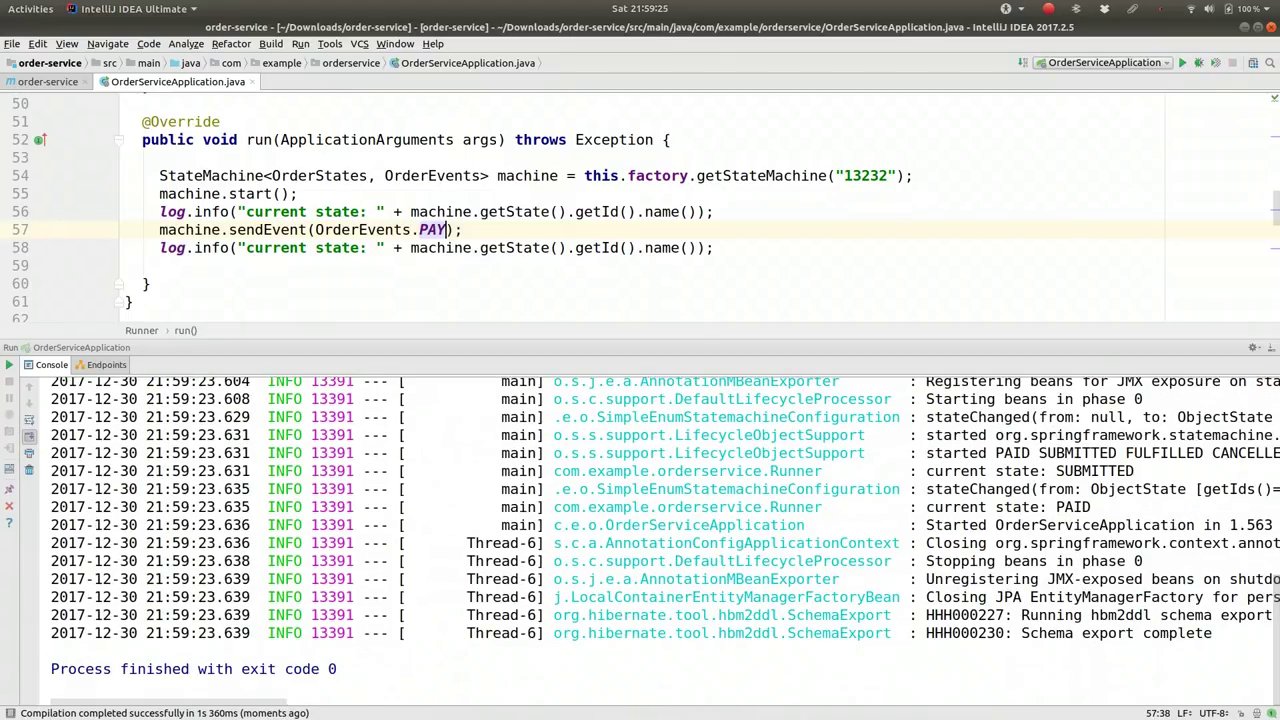
00:23:42-00:25:19
The design of the state machine is exactly what we want. We desire a predictable, deterministic progression. We need to ensure that it's impossible to advance too far in the processing without satisfying all the preconditions, meaning all previous states must be fulfilled. Currently, the state is "paid." This is the second time we've seen this; the first state was "submitted," followed by "paid." Now, let's send an event. Instead of using the enum object directly, we'll send a message using the Spring Framework Message Builder. This is the same Message Builder used for Spring Integration and WebSocket support in Spring MVC. It's also used for the JMS messaging template and the MQ messaging template. We'll use the payload to send an event, specifically "order events, fulfill." This is crucial because you can craft a message with headers, such as setting header A to B. These headers can be beneficial in your component logic. Let's proceed and run the application to observe the results.
状态机的设计正是我们所期望的。我们希望它能够按照可预测、确定性的顺序推进。我们需要确保在未满足所有前置条件的情况下,无法进行过多的处理步骤,这意味着所有先前的状态都必须得到满足。目前的状态是“已支付”。这是我们第二次看到这个状态;第一个状态是“已提交”,随后是“已支付”。现在,让我们发送一个事件。我们不会直接使用枚举对象,而是通过Spring框架的消息构建器发送一条消息。这个消息构建器与Spring集成和Spring MVC中的WebSocket支持所使用的消息构建器相同。它还用于JMS消息模板和MQ消息模板。我们将使用有效载荷来发送一个事件,具体是“订单事件,履行”。这一点至关重要,因为你可以在消息中设置头信息,例如将头信息A设置为B。这些头信息在你的组件逻辑中可能非常有用。接下来,让我们继续运行应用程序,观察结果。
精炼总结 1. 状态机设计要求:可预测、确定性顺序推进,确保所有前置状态满足。-
当前状态:“已支付”,前一状态为“已提交”。
-
事件发送方式:通过Spring框架的消息构建器发送,支持WebSocket、JMS和MQ消息模板。
-
发送事件:“订单事件,履行”,可设置消息头信息。
-
后续操作:运行应用程序,观察结果。
参考回答:因为这样可以确保系统的稳定性和一致性,避免在未满足所有前置条件的情况下进行过多的处理步骤,从而减少错误和异常情况的发生。
- 问题:使用Spring框架的消息构建器发送事件有哪些优势?
参考回答:Spring框架的消息构建器提供了与多种消息传递技术的集成,如WebSocket、JMS和MQ,这使得事件发送更加灵活和高效,同时支持设置消息头信息,便于在组件逻辑中使用。
批判性思考 - 虽然状态机的确定性和可预测性有助于系统的稳定,但在某些情况下,过于严格的状态限制可能会限制系统的灵活性和响应速度。例如,在需要快速响应市场变化或用户需求的场景中,过于僵化的状态机可能会导致系统反应迟缓。- 使用Spring框架的消息构建器虽然提供了多种集成和灵活性,但也可能增加了系统的复杂性和依赖性。在小型或简单项目中,这种复杂性可能是不必要的,甚至可能增加维护成本。因此,在选择技术方案时,需要根据项目的实际需求和规模进行权衡。
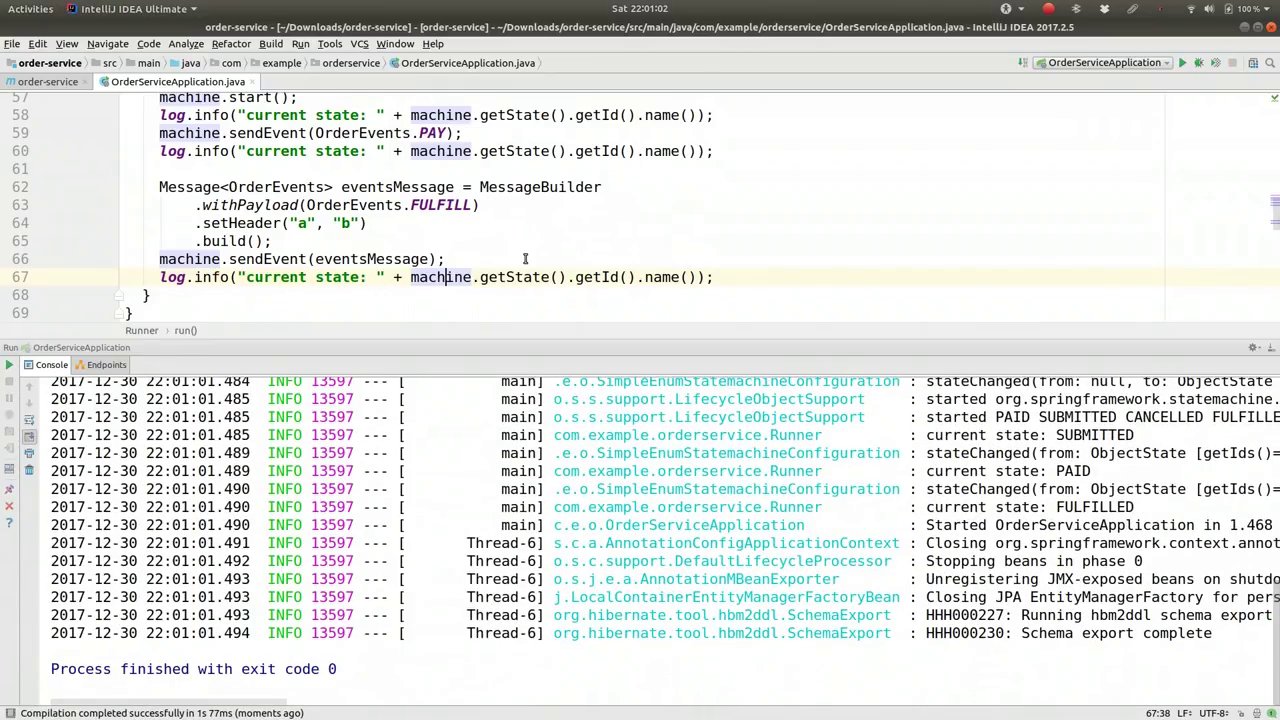
00:25:19-00:25:27
Awesome, okay, so we can see the current state is now FULFILLED, all right.
太好了,现在我们可以看到当前状态已经变为“已完成”了。
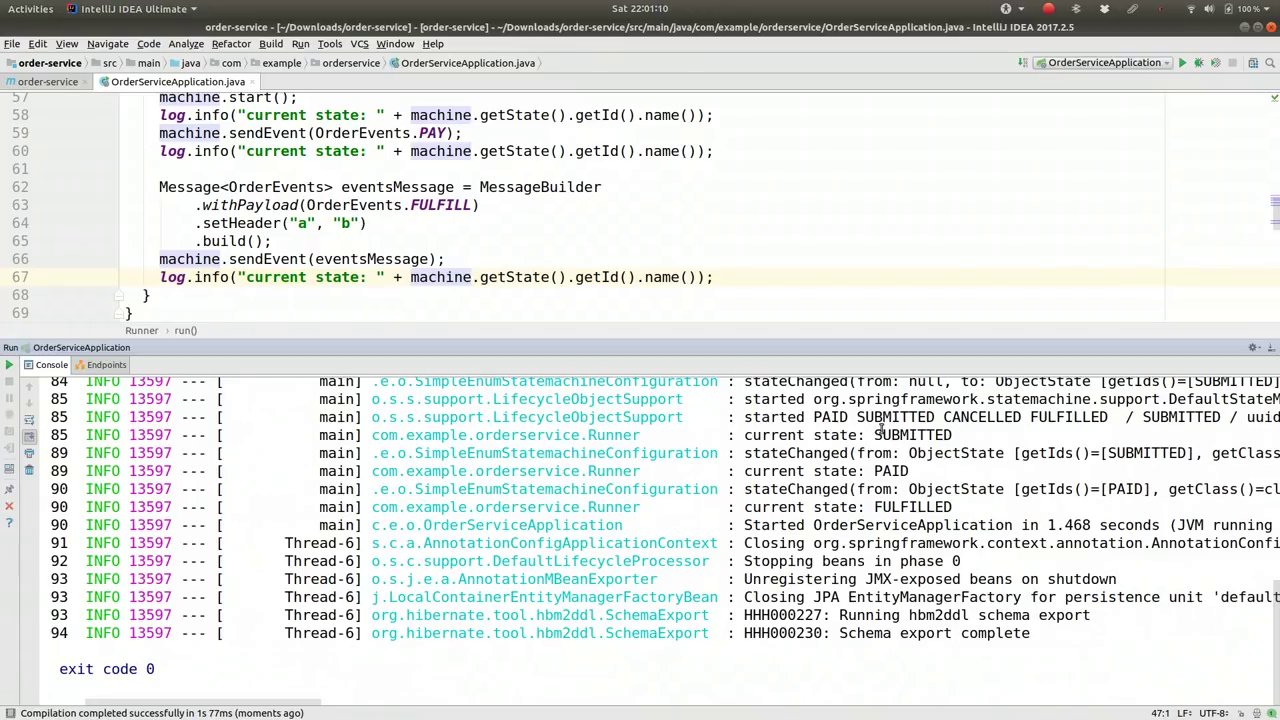
00:25:27-00:25:42
So, we've received the fulfilled support after going through the states of submitted, paid, and fulfilled. This is functioning as anticipated. We can engage with the state machine at any point, and it provides a predictable outcome. That concludes our discussion.
因此,在经历了提交、支付和完成这几个状态后,我们收到了已完成的支援。这一切都在按预期运作。我们可以在任何时候与状态机互动,它都能提供可预测的结果。至此,我们的讨论就结束了。
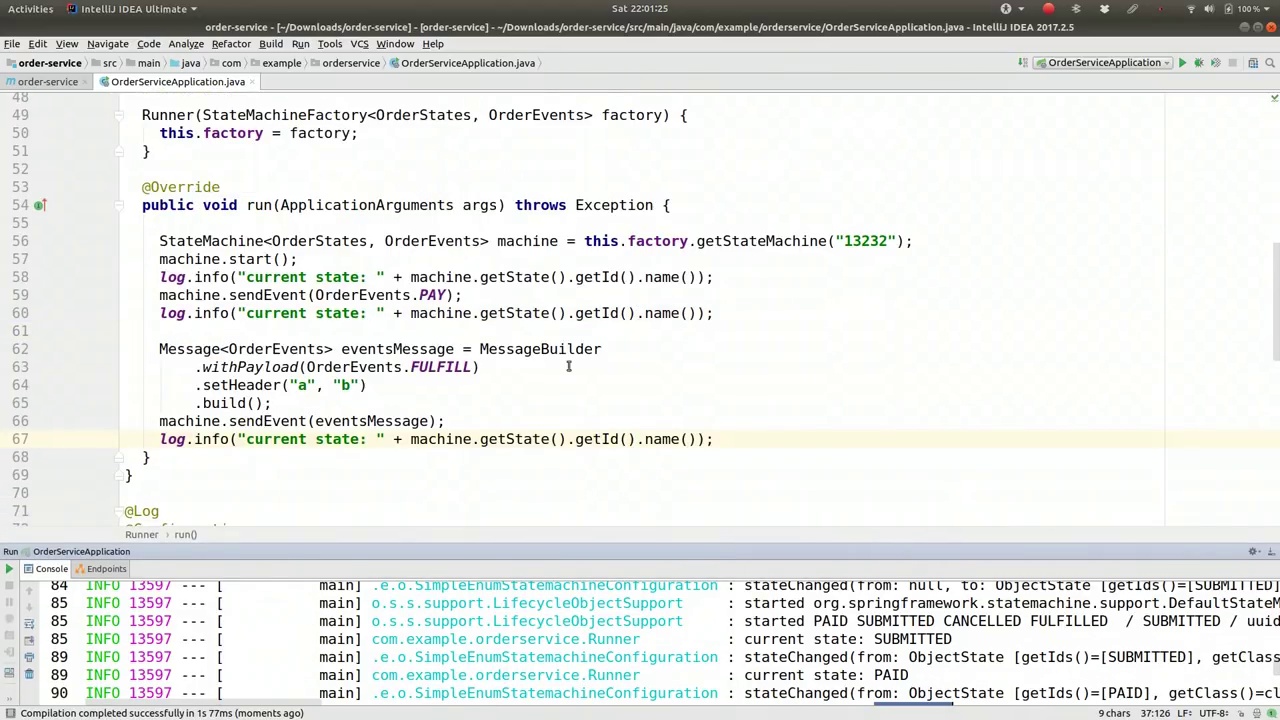
00:25:42-00:27:50
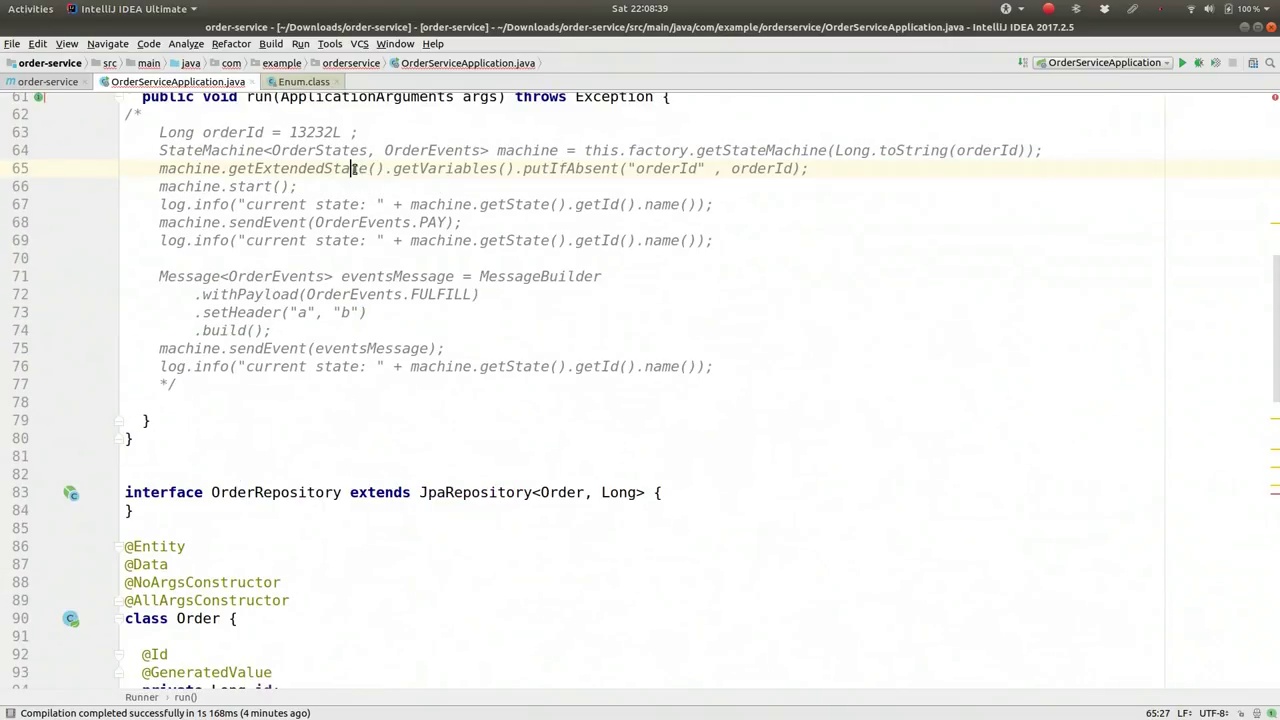
All very well and good, of course, but it is, at the end of the day, just moving state around in memory. We're not doing anything based on it, right? We're not actually acting on it. So you have a couple of places where you could do that. First of all, you could actually provide state entry handlers, right? You could say based on whenever somebody enters the submitted state, you have a handler. So a new action looks like that, right? So your job is to do something that reflects that we're in the state. Maybe you want to write a record to the database. Maybe you want to send a notification or send a message on a queue or whatever you want, right? So entering submitted state, right? And you could have new data, right? You can actually have data that is encoded in this order. So you might have data that comes from the message that we talked about earlier. You could actually pull it out here. So if you wanted to. So the context, get event, right? This is the event. Get extended state. You can get variables, right? So I can get order ID if I want to. Get order default. So let's say it's negative one long order ID. So I'm now class.cast. There we are. So this is me extracting out either a negative one or an order ID from the extended state in the state machine. So let's actually see if we can send that into the state machine before we start it up, right? So here we go. Entering state machine. Order ID is. And we'll write out the order ID. So now we have to actually send this order ID. That's a precondition for this to work, right?
当然,这一切都很好,但归根结底,这只是将状态在内存中移动而已。我们并没有基于它做任何事情,对吧?我们并没有实际操作它。因此,你有几个地方可以这样做。首先,你可以实际提供状态入口处理程序,对吧?你可以根据某人进入提交状态时设置一个处理程序。因此,一个新的动作看起来像这样,对吧?你的任务是做一些反映我们处于该状态的事情。也许你想将记录写入数据库。也许你想发送通知或在队列上发送消息,或者任何你想做的事情,对吧?进入提交状态,对吧?而且你可能有新数据,对吧?你实际上可以有编码在这个订单中的数据。因此,你可能有来自我们之前讨论的消息的数据。你实际上可以在这里提取它。所以如果你想这样做。所以上下文,获取事件,对吧?这是事件。获取扩展状态。你可以获取变量,对吧?所以如果我想,我可以获取订单ID。获取订单默认值。假设它是负一长订单ID。所以我现在是类.cast。我们到了。这就是我从状态机中的扩展状态提取负一或订单ID的过程。所以让我们实际看看我们是否可以在启动之前将它发送到状态机,对吧?所以开始了。进入状态机。订单ID是。我们将写出订单ID。所以现在我们必须实际发送这个订单ID。这是使其工作的先决条件,对吧?
精炼总结 1. **状态处理的概念**:讨论了在内存中移动状态的基本概念,并指出这并未涉及实际操作。-
状态入口处理程序:提出可以设置状态入口处理程序,当进入特定状态(如提交状态)时触发。
-
动作的具体实施:描述了在进入提交状态时可能执行的具体动作,如写入数据库、发送通知或消息等。
-
数据处理与提取:强调了在状态处理中可能涉及的数据处理,如从消息中提取数据,并具体提到了订单ID的提取和使用。
-
状态机的操作:讨论了如何将提取的数据(如订单ID)发送到状态机,并强调这是实现功能的关键步骤。
参考回答:主要目的是在进入特定状态时触发预设的动作,如写入数据库、发送通知等,以实现状态相关的具体操作。
- 问题:在提取订单ID的过程中,为什么强调需要将其发送到状态机?
参考回答:因为将订单ID发送到状态机是实现后续操作(如记录订单状态)的先决条件,确保状态机能够正确处理和响应订单相关的信息。
批判性思考 - **状态处理的实际应用**:虽然文中提到了状态处理和数据提取的具体步骤,但未详细讨论这些操作在实际应用中的效率和安全性。例如,频繁的数据库写入可能会影响系统性能,而数据提取和处理过程中可能存在的安全漏洞也未被提及。- 状态机的复杂性:文中简化了状态机的操作流程,但实际应用中状态机可能涉及更复杂的逻辑和状态转换,需要更详细的错误处理和状态管理机制。此外,对于状态机的维护和更新,文中也未进行深入讨论。
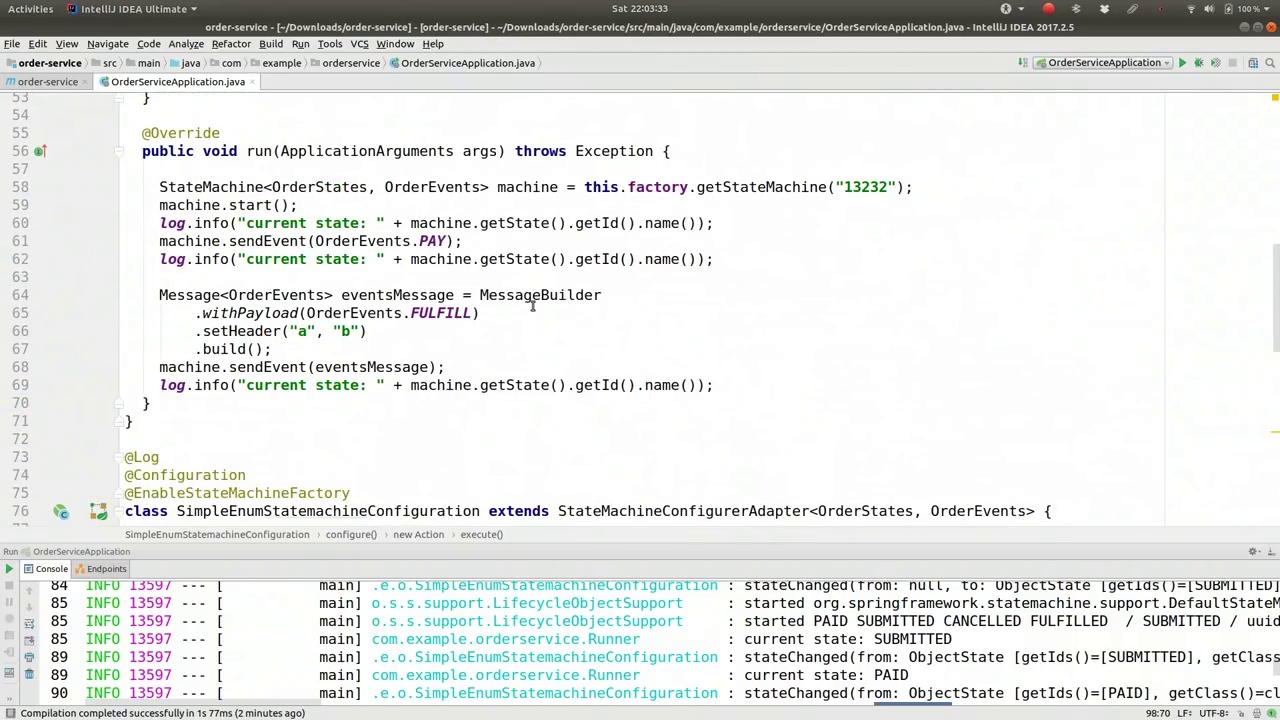
00:27:50-00:28:29
If we don't have the order ID, it's going to fail spectacularly. So let's go back to our state machine before we start it. We need to get the extended state, retrieve the variables, and set the order ID if it's absent. We'll extract that into a separate variable. So, we'll declare a long variable, orderID, and assign it the value from this context. Then, we'll convert it to a string and place it in the order ID field. We're doing this before we initiate the state machine process. Now, let's run this again.
如果我们没有订单ID,整个过程将会以失败告终。因此,在启动状态机之前,让我们先回顾一下。我们需要获取扩展状态,检索变量,并在订单ID缺失时设置它。我们将把这个步骤提取到一个单独的变量中。所以,我们将声明一个长整型变量orderID,并从上下文中赋予它值。然后,我们将它转换为字符串并放入订单ID字段中。我们这样做是为了在启动状态机流程之前完成这些步骤。现在,让我们再次运行这个流程。
-
在启动状态机之前,需要获取扩展状态和检索变量。
-
如果订单ID缺失,需要设置它。
-
声明一个长整型变量
orderID,并从上下文中赋予其值。 -
将
orderID转换为字符串并放入订单ID字段中。
- 参考回答:因为订单ID是识别和管理订单的核心标识,没有它,整个流程无法正确执行和追踪。
- 在设置订单ID时,为什么要将长整型变量转换为字符串?
- 参考回答:因为订单ID字段可能需要以字符串形式存储和处理,转换为字符串可以确保数据格式的一致性和兼容性。
- 另外,原文假设订单ID总是可以从上下文中获取,这在实际应用中可能并不总是成立。批判性思考应包括对订单ID获取来源的多样性和可靠性的讨论,以及在无法从上下文获取订单ID时的替代方案。
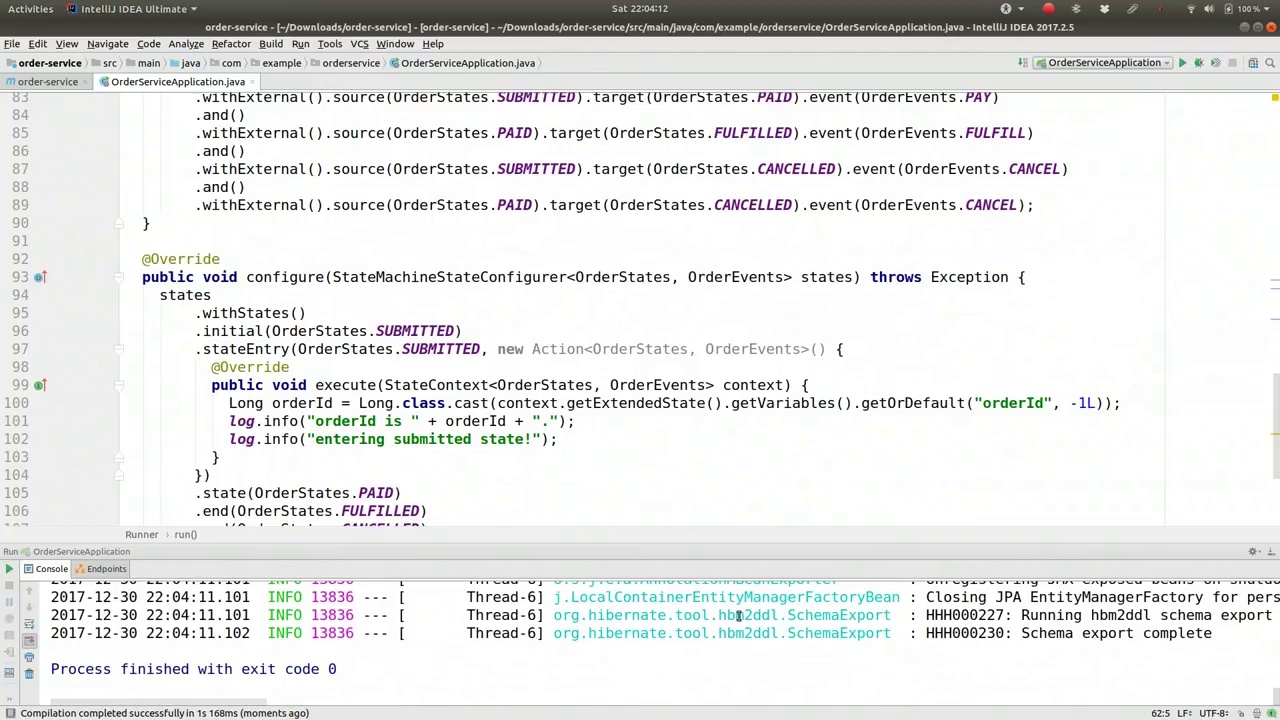
00:28:29-00:28:38
See what we get. Alright, so if we go here.
看看我们能得到什么。好的,如果我们来这里。
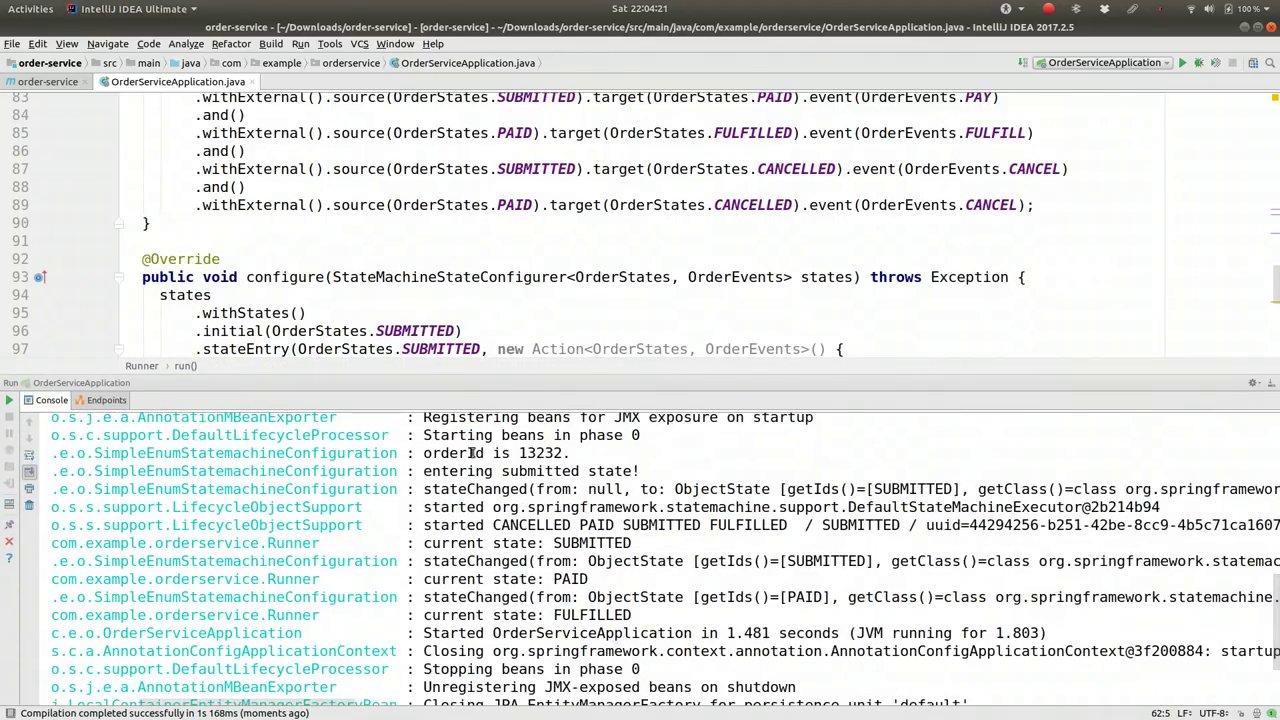
00:28:38-00:29:31
Order ID is 13232, as expected, entering the submitted state. Here, we have the capability to propagate state from one node to another within the graph of the state machine. This is quite convenient. You can implement various handling logic here, which can be directly embedded or you can call another function. You could utilize Spring Integration or Spring Batch, or any other desired functionality. However, you can maintain a well-defined progression of state. Spring State Machine is particularly useful for these scenarios, especially in long-lived distributed transactions or distributed worker situations where there are many components that need to coordinate their state. This is how you would provide your own...
订单ID为13232,正如预期,进入了已提交状态。在这里,我们具备将状态从一个节点传播到状态机图中另一个节点的能力,这非常方便。你可以在此实现各种处理逻辑,这些逻辑可以直接嵌入,也可以调用另一个函数。你可以利用Spring Integration或Spring Batch,或者任何其他所需的功能。然而,你可以保持状态的明确进展。Spring State Machine在这些场景中特别有用,尤其是在长生命周期的分布式事务或分布式工作场景中,有许多组件需要协调它们的状态。这就是你如何提供自己的...
精炼总结 - 订单ID 13232已进入已提交状态。-
系统具备将状态在状态机图中传播的能力。
-
处理逻辑可以嵌入或调用其他函数实现。
-
可使用Spring Integration或Spring Batch等工具。
-
Spring State Machine在长生命周期分布式事务中特别有用。
参考回答:Spring State Machine在长生命周期的分布式事务或分布式工作场景中特别有用,尤其是在有许多组件需要协调它们的状态时。
- 问题:处理逻辑可以如何实现?
参考回答:处理逻辑可以直接嵌入到系统中,也可以通过调用其他函数来实现。
批判性思考 - 虽然Spring State Machine在处理复杂状态转换时提供了便利,但其学习和配置的复杂性可能对小型项目或初学者构成挑战。是否存在更简单、更轻量级的解决方案来处理状态管理?- 文中提到可以使用多种工具和框架来实现处理逻辑,这虽然提供了灵活性,但也可能导致系统集成和维护的复杂性增加。如何平衡灵活性和系统复杂性,确保系统的可维护性和扩展性?
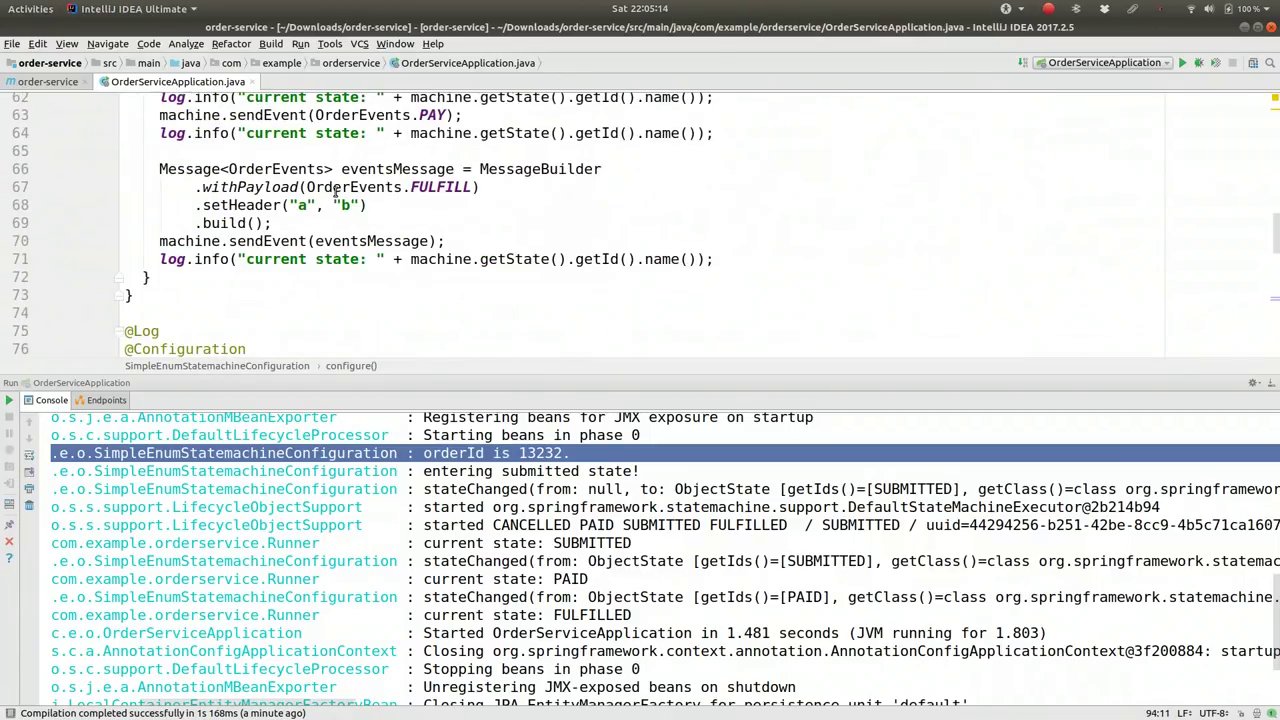
00:29:31-00:29:45
Custom behavior, which is convenient. We've also examined, by the way, how to launch an instance of the state machine and how to activate it.
自定义行为,既方便又实用。顺便说一下,我们还探讨了如何启动状态机实例以及如何激活它。
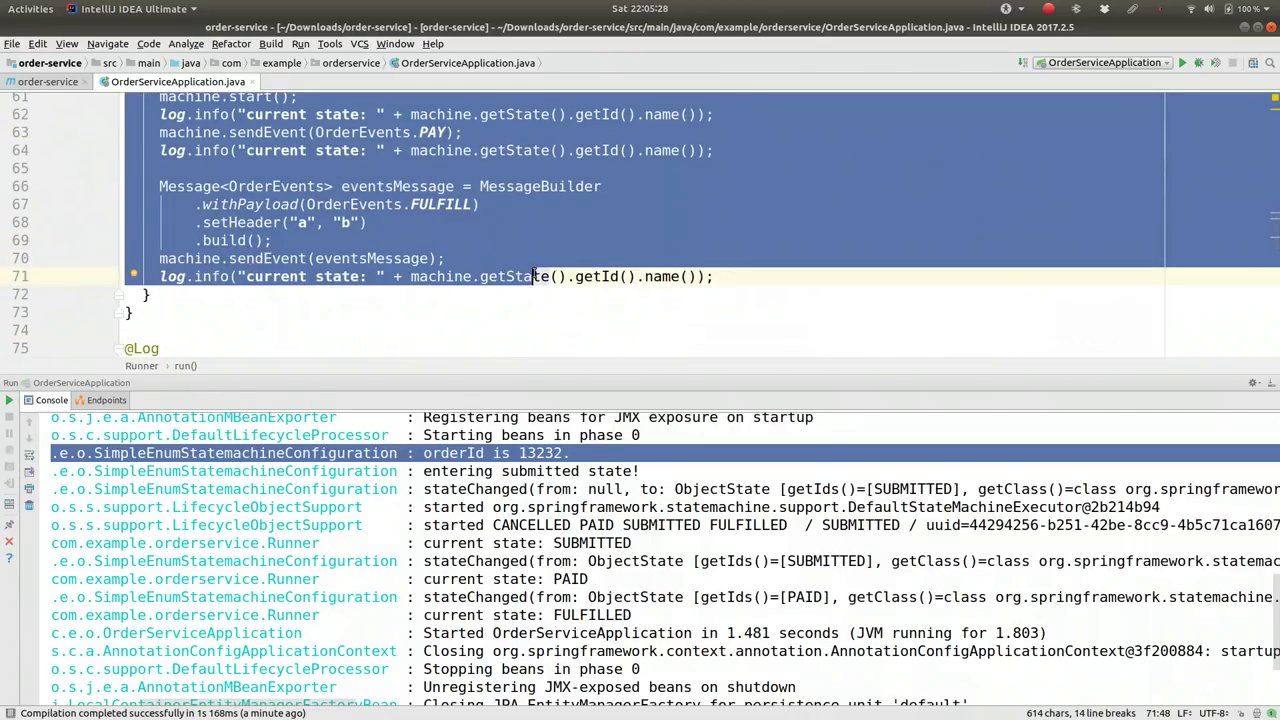
00:29:45-00:29:57
Let's go ahead and comment this out now, and let's actually wrap a service around this machine. A service that manages our entity for us and does things; it's got some semblance of business logic. So, we're going to create an OrderService.
我们现在先注释掉这部分代码,然后围绕这台机器实际构建一个服务。这个服务将为我们管理实体并执行一些操作;它具备一定的业务逻辑。因此,我们将创建一个OrderService。
00:29:57-00:32:30
class OrderService {
@Entity
class Order {
private long id;
private LocalDateTime dateTime;
@Id
@GeneratedValue
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public LocalDateTime getDateTime() {
return dateTime;
}
public void setDateTime(LocalDateTime dateTime) {
this.dateTime = dateTime;
}
}
@Repository
interface OrderRepository extends JpaRepository<Order, Long> {}
@Service
class OrderService {
private final OrderRepository orderRepository;
@Autowired
public OrderService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public Order createOrder(LocalDateTime dateTime) {
Order order = new Order();
order.setDateTime(dateTime);
return orderRepository.save(order);
}
}
}
class OrderService {
@Entity
class Order {
private long id;
private LocalDateTime dateTime;
@Id
@GeneratedValue
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public LocalDateTime getDateTime() {
return dateTime;
}
public void setDateTime(LocalDateTime dateTime) {
this.dateTime = dateTime;
}
}
@Repository
interface OrderRepository extends JpaRepository<Order, Long> {}
@Service
class OrderService {
private final OrderRepository orderRepository;
@Autowired
public OrderService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public Order createOrder(LocalDateTime dateTime) {
Order order = new Order();
order.setDateTime(dateTime);
return orderRepository.save(order);
}
}
}
-
OrderRepository接口:继承JpaRepository,用于订单的CRUD操作。
-
OrderService类:依赖OrderRepository,提供创建订单的方法。
- 参考回答:
@Id注解用于标记实体类的主键字段,@GeneratedValue注解用于指定主键的生成策略,通常是自动递增。
- 问题:OrderService类是如何依赖OrderRepository的?
- 参考回答:OrderService类通过构造函数注入OrderRepository实例,并在
createOrder方法中使用该实例来保存订单。
-
异常处理:当前代码在创建订单时没有处理可能的异常情况,如数据库连接失败或保存失败。建议增加异常处理机制,以提高系统的健壮性。
-
日期时间处理:代码中直接使用
LocalDateTime作为订单的日期时间,未考虑时区问题。在实际应用中,可能需要根据用户所在的时区来调整日期时间,以确保数据的准确性。
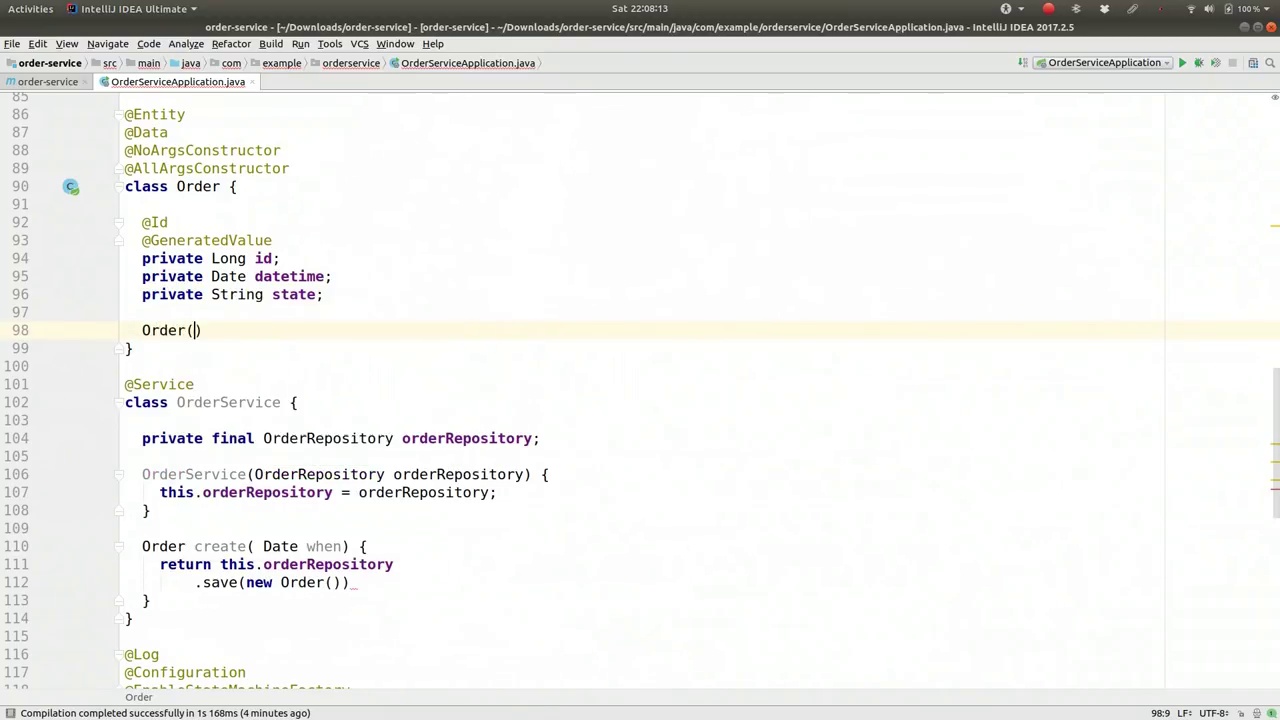
00:32:30-00:32:51
constructor and we're going to create a constructor that can take our enum values. So I'm going to say Date d and then the OrderStates os. So this.datetime = d, this.state = os.name(). So this is the
我们要创建一个构造函数,它可以接受我们的枚举值。所以我会写上 Date d 和 OrderStates os。然后是 this.datetime = d,this.state = os.name()。这就是我们的构造函数。
-
构造函数参数包括
Date d和OrderStates os。 -
在构造函数中,将
d赋值给this.datetime,将os.name()赋值给this.state。
- 参考回答:
Date d代表日期时间,OrderStates os代表订单状态的枚举值。
os.name()方法的作用是什么?
- 参考回答:
os.name()方法返回枚举值的名称。
- 构造函数中直接赋值给实例变量,没有进行任何参数校验,这可能导致在后续使用中出现非法状态。可以考虑在构造函数中加入参数校验,确保传入的参数是合法的。
00:32:51-00:32:56
String representation of the enum. This is a Java idiom. All enums have the ability to produce a name that
枚举的字符串表示。这是Java中的一个惯用法。所有枚举都有生成名称的能力。
00:32:56-00:33:47
corresponds to the symbol that you see in the unit itself, and in our case, it will be fulfilled. So, maybe I'll make that public. The ID will be automatically incremented and generated for us by JPA. Let's use this new constructor, and the order state will be, of course, submitted. I'm cheating a little bit there; I should perhaps check the state machine, but let's assume we already know that all orders, when they start, are in the submitted state. Very good. We might even have some getters and setters for that, so public OrderState getOrderState.
译文终稿
对应于您在设备本身看到的符号,在我们的情况下,这一条件将会得到满足。所以,也许我会公开这一点。ID将由JPA自动递增并为我们生成。让我们使用这个新的构造函数,当然,订单状态将是“已提交”。我在那里稍微作弊了一下;我本应该检查状态机,但让我们假设我们已经知道所有订单在开始时都处于“已提交”状态。非常好。我们甚至可能为此设置一些getter和setter,例如public OrderState getOrderState。
-
ID将由JPA自动递增生成。
-
使用新的构造函数,订单状态初始为“已提交”。
-
假设所有订单初始状态为“已提交”,未实际检查状态机。
-
可能设置getter和setter方法,如
public OrderState getOrderState。
参考回答:作者可能基于系统设计的默认设置或历史数据分析,认为初始状态下所有订单应为“已提交”状态,以简化处理流程。
- 问题:设置getter和setter方法的目的是什么?
参考回答:getter和setter方法用于封装对象的属性,提供对这些属性的安全访问和修改,是面向对象编程中的常见实践,有助于维护代码的可读性和可维护性。
批判性思考 - 原文中作者未检查状态机而直接假设订单状态,这种做法可能带来风险,特别是在系统复杂或需求多变的情况下。应通过实际检查或测试来验证假设的正确性,以确保系统的稳定性和准确性。- 设置getter和setter方法虽然常见,但也可能导致过度封装,增加代码复杂性。在某些情况下,直接访问属性可能更简洁高效。因此,是否使用getter和setter应根据具体情况权衡利弊。
00:33:47-00:34:49
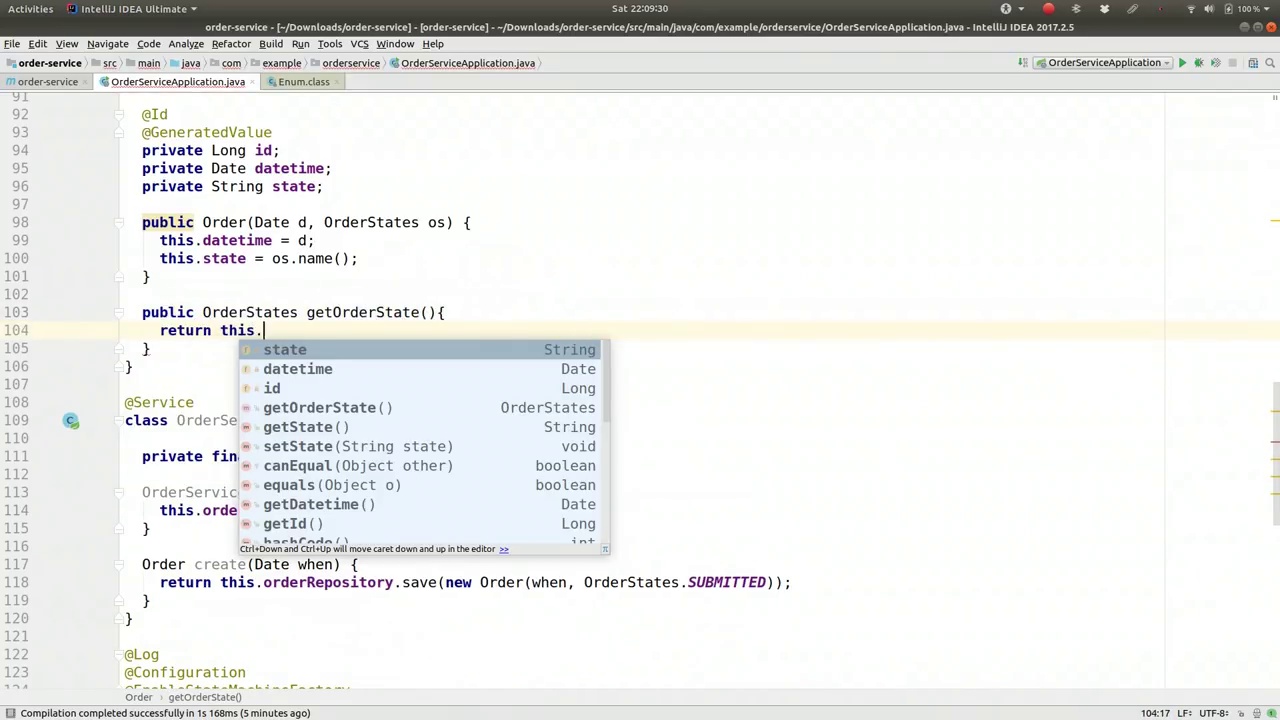
State, return this.state, I'm going to say OrderStates.valueOf, right. I'm going to get that string and use it to arrive at the enum, and we're going to have a writer as well, setOrderState, taking in the order state and writing it out. So this.state = s.name, same as before. And we could even just use that setter here, setOrderState, oh yes, very good. Okay, so now we need to manage that state, we need to actually manage the state machine. So let's imagine in our runner, we're actually going to call that OrderService here. So let's go to our runner, where is that runner? It's up here, I'm going to move our OrderService a little bit closer to our work, up here, close to the runner so we can actually balance back and forth with a bit of ease. Alright, so there we are, the OrderService is just above the runner.
状态,返回这个.state,我要说的是OrderStates.valueOf,对吧。我会获取那个字符串并用它来确定枚举值,我们还需要一个写入器,setOrderState,接收订单状态并将其写出来。所以这个.state = s.name,和之前一样。我们甚至可以直接在这里使用那个设置器,setOrderState,哦是的,非常好。好了,现在我们需要管理那个状态,我们实际上需要管理状态机。所以让我们想象一下在我们的运行器中,我们实际上会调用那个OrderService。那么让我们去我们的运行器,那个运行器在哪里?它就在这里,我要把我们的OrderService稍微移近我们的工作区,移到这里,靠近运行器,这样我们就可以轻松地来回切换了。好了,我们就在这里,OrderService就在运行器的上方。
精炼总结 1. 讨论了通过字符串获取枚举值的方法,使用`OrderStates.valueOf`。-
提到了需要一个写入器
setOrderState来接收并写入订单状态。 -
描述了在代码中直接使用设置器
setOrderState的便利性。 -
强调了管理状态机的重要性,并设想在运行器中调用
OrderService。 -
具体说明了将
OrderService移至运行器附近,以便于代码管理和切换。
参考回答:因为OrderStates.valueOf可以根据字符串直接获取对应的枚举值,这样可以简化代码并确保类型安全。
- 问题:在代码中直接使用设置器
setOrderState有什么好处?
参考回答:直接使用设置器可以减少代码重复,提高代码的可读性和维护性,同时确保状态设置的一致性。
批判性思考 - 虽然使用`OrderStates.valueOf`和设置器`setOrderState`可以提高代码的效率和可读性,但也可能导致代码耦合度增加。如果`OrderStates`枚举或`setOrderState`方法发生变化,可能会影响到整个状态管理系统的稳定性。因此,设计时应考虑如何降低这种耦合度,例如通过接口或抽象类来隔离具体实现。- 将
OrderService移至运行器附近虽然便于管理,但也可能因为过于集中而导致代码结构复杂。在实际开发中,应考虑如何平衡代码的集中管理和模块化设计,以确保代码的可扩展性和可维护性。
00:34:49-00:36:53
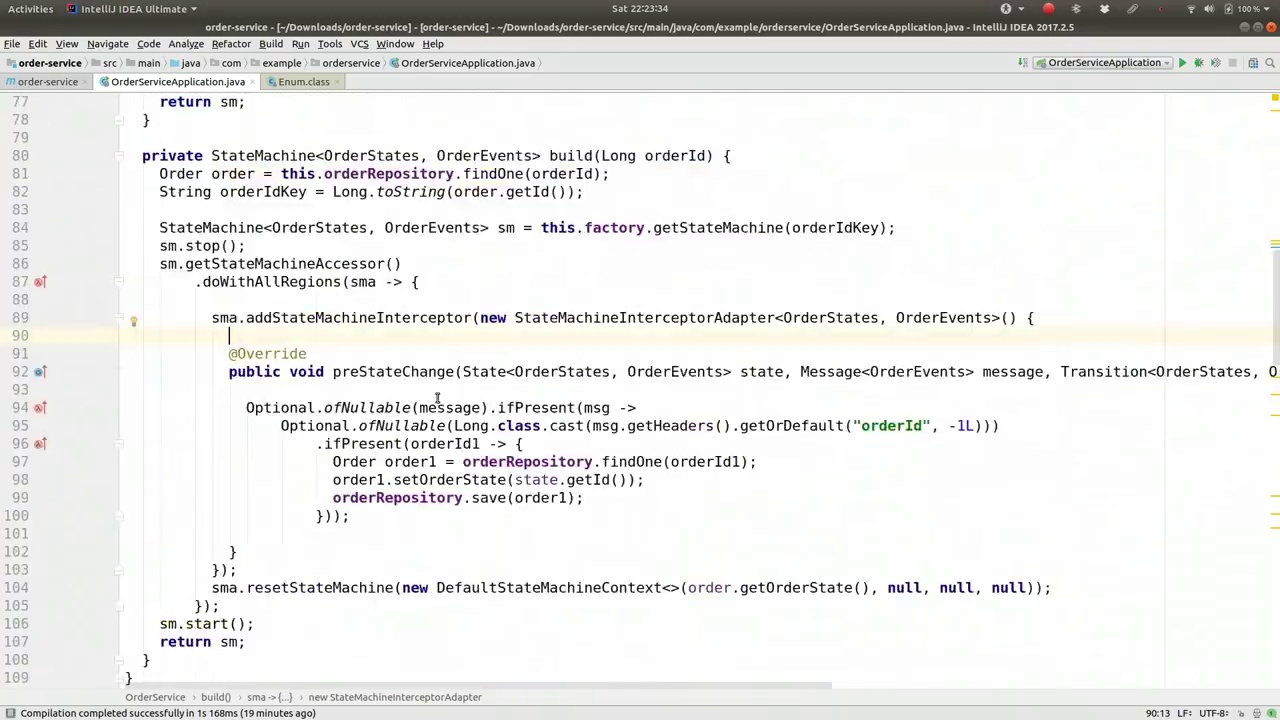
We're going to simplify the code by removing unnecessary details and organizing it for better visibility. We'll place the runner at the top for easy reference. This runner will serve as a basic test, though we might consider writing a separate test. For now, we'll keep it within the same code page.
Regarding the order process, we'll utilize the order service. We'll inject the order service and remove the factory, which is already included in the order service. We'll call this.orderService.createNewOrderService.
Next, let's consider modifying the order. There might be various business logic events, such as a button click to transition to the paid state, or form completion to update the state machine to reflect payment. Additionally, after a day, when a label is printed and the order is fulfilled, we need to ensure the order state is updated accordingly when the button is clicked on a mobile device in the warehouse.
To handle these transitions, we'll implement a method named change that moves the order from one state to another. This method can be adapted for various functionalities, serving as a backend service for different clients.
我们将通过移除不必要的细节并重新组织代码以提高可见性来简化代码。我们将把运行器置于顶部以便于参考。这个运行器将作为一个基本测试,尽管我们可能会考虑编写一个单独的测试。目前,我们将它保留在同一代码页内。
关于订单处理,我们将利用订单服务。我们将注入订单服务并移除工厂,因为工厂已经包含在订单服务中。我们将调用this.orderService.createNewOrderService。
接下来,让我们考虑修改订单。可能会有各种业务逻辑事件,例如按钮点击以过渡到已支付状态,或表单完成以更新状态机以反映支付情况。此外,一天后,当标签打印并且订单履行时,我们需要确保在仓库中移动设备上点击按钮时相应地更新订单状态。
为了处理这些状态转换,我们将实现一个名为change的方法,该方法将订单从一个状态移动到另一个状态。这个方法可以适应各种功能,作为不同客户端的后端服务。
-
订单处理:利用订单服务,注入订单服务并移除工厂,调用
this.orderService.createNewOrderService。 -
订单修改:考虑业务逻辑事件,如按钮点击或表单完成,实现
change方法处理状态转换。 -
状态转换:确保仓库中设备点击按钮时订单状态更新。
参考回答:将运行器置于代码顶部可以使开发者在查看代码时首先看到运行器,从而快速了解代码的基本测试和运行情况,提高代码的可读性和维护性。
- 问题:移除工厂并利用订单服务的好处是什么?
参考回答:移除工厂并利用订单服务可以简化代码结构,减少重复代码,提高代码的可维护性和扩展性。订单服务已经包含了工厂的功能,因此可以直接使用订单服务来创建新的订单服务实例。
批判性思考 - 虽然将运行器置于代码顶部可以提高可见性,但这也可能导致代码顶部的信息过于密集,影响整体代码的可读性。是否可以考虑将运行器放置在一个单独的模块或文件中,以便在需要时进行参考,同时保持主代码的清晰和简洁?-
移除工厂并利用订单服务虽然简化了代码结构,但这也可能导致订单服务的职责过于庞大,违反了单一职责原则。是否可以考虑将订单服务的某些功能拆分到其他服务中,以保持每个服务的职责清晰和单一?
-
实现
change方法处理状态转换虽然可以适应各种功能,但这也可能导致该方法变得过于复杂和难以维护。是否可以考虑将状态转换逻辑分解为多个小方法,每个方法处理一个特定的状态转换,以提高代码的可读性和可维护性?
00:36:53-00:39:26
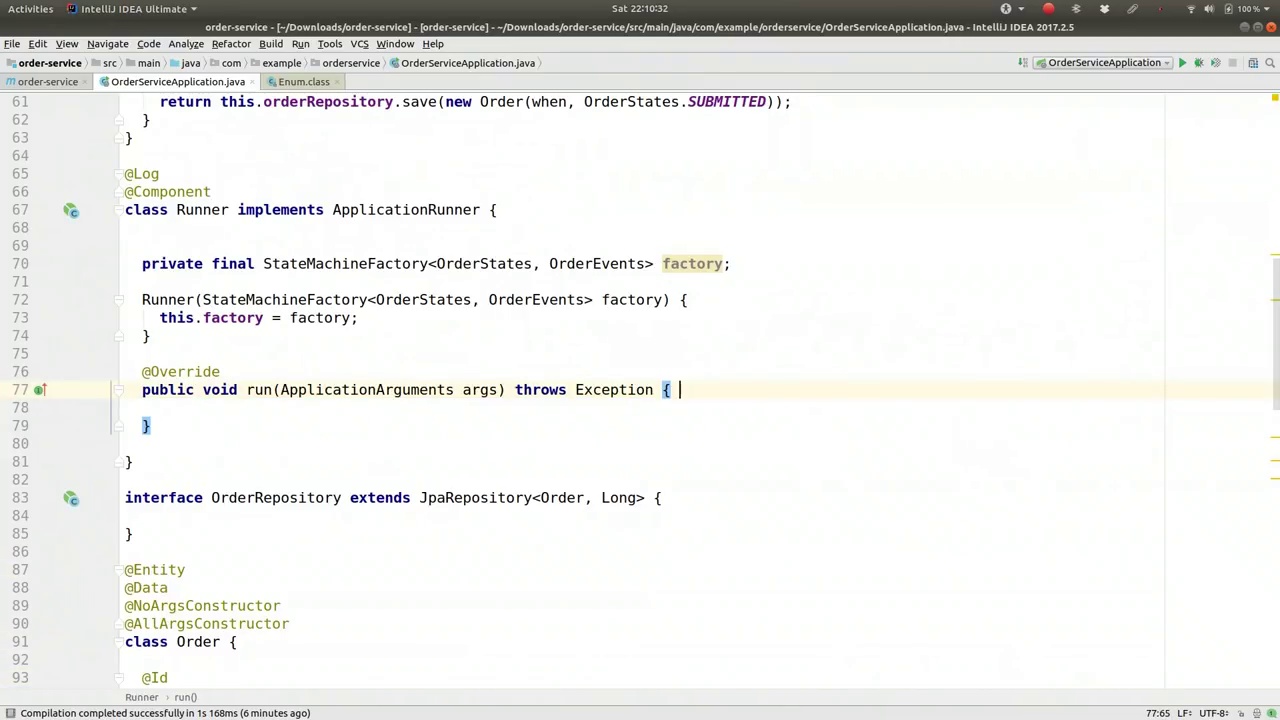
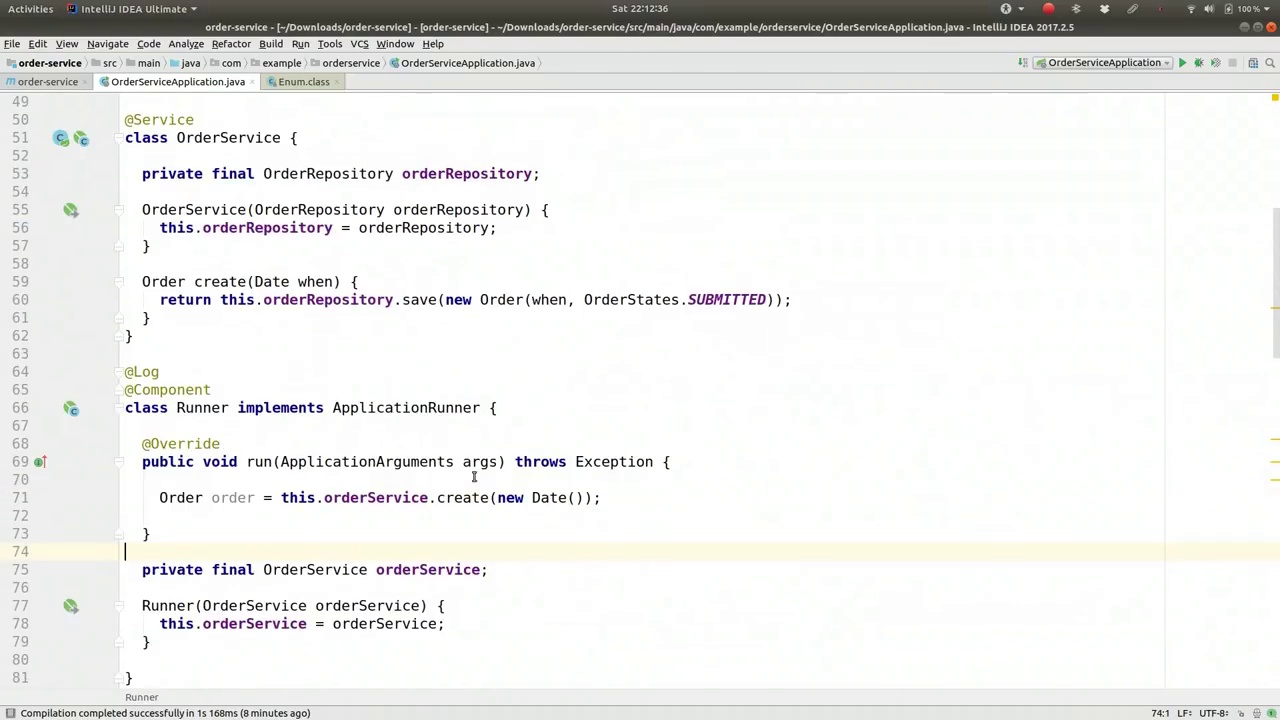
In our order service, the change method will return the state machine itself. To achieve this, we need a method that builds the state machine for a given order. Let's focus on the business logic, which is crucial here. We will use the order ID and an order events parameter. To make this work, we need a way to arrive at the state machine (SM). We will use this.build, passing in the order ID, and create a private implementation method.
First, we need to look up the record by ID. Initially, let's ensure the code compiles. We need to create a new instance and rehydrate the state machine. We won't persist the state machine itself, but we need to create a new state machine based on the order and set it to a specific state. If the order indicates it has been fulfilled, the state machine object from the build method should reflect this.
First, look up the existing order using this.orderRepository.findOneByOrderId. Convert the order ID to a key: orderIdKey = Long.toString(order.getId()). Then, create a new state machine: orderStates, orderEvents, SM = this.factory. We need the state machine factory, so we will inject it: private final stateMachineFactory for orderStates, orderEvents.
在我们的订单服务中,change方法将返回状态机本身。为了实现这一点,我们需要一个方法来为给定的订单构建状态机。让我们专注于这里的业务逻辑,这是至关重要的。我们将使用订单ID和一个订单事件参数。为了使这个工作,我们需要一种方法来达到状态机(SM)。我们将使用this.build,传入订单ID,并创建一个私有实现方法。
首先,我们需要通过ID查找记录。最初,让我们确保代码能够编译。我们需要创建一个新的实例并重新激活状态机。我们不会持久化状态机本身,但我们需要根据订单创建一个新的状态机并将其设置为特定状态。如果订单指示它已被履行,那么从build方法返回的状态机对象应该反映这一点。
首先,使用this.orderRepository.findOneByOrderId查找现有订单。将订单ID转换为一个键:orderIdKey = Long.toString(order.getId())。然后,创建一个新的状态机:orderStates, orderEvents, SM = this.factory。我们需要状态机工厂,因此我们将注入它:private final stateMachineFactory for orderStates, orderEvents。
精炼总结 1. **change方法功能**:在订单服务中,change方法返回状态机本身。-
状态机构建:需要一个方法根据订单ID和订单事件参数构建状态机。
-
实现细节:
-
使用
this.build方法传入订单ID。 -
通过订单ID查找记录,使用
this.orderRepository.findOneByOrderId。 -
将订单ID转换为键:
orderIdKey = Long.toString(order.getId())。 -
创建新的状态机实例:
orderStates, orderEvents, SM = this.factory。 -
注入状态机工厂:
private final stateMachineFactory for orderStates, orderEvents。
- 状态机状态设置:根据订单状态设置状态机状态,如订单已履行则反映在状态机中。
- 参考回答:通过在构建状态机时,根据订单的实际状态(如是否已履行)来设置状态机的状态,确保状态机准确反映订单状态。
- 问题:为什么需要将订单ID转换为键?
- 参考回答:将订单ID转换为键可能是为了在查找和处理订单记录时,使用更方便或标准化的数据格式,如字符串格式,以便于在系统中进行键值对的存储和检索。
- 依赖注入的复杂性:通过依赖注入状态机工厂增加了系统的复杂性。可以考虑是否有更简洁的方法来实现状态机的构建和管理,减少代码的耦合度。
00:39:26-00:41:02
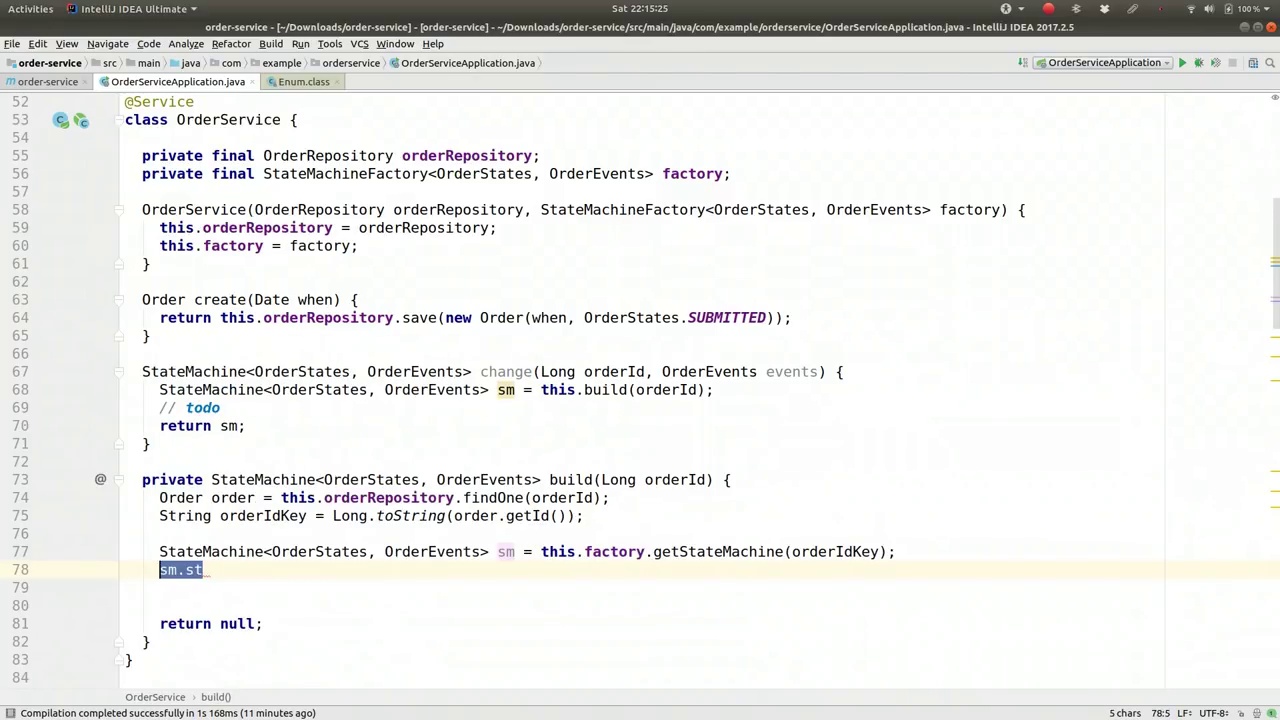
Factory, all right, good stuff, look at that. So this.factory.getStateMachine, passing in the ID and the ID is the order ID key there. Good. So that's our state machine. But again, this state machine hasn't been started. Remember how we used it before? We have to call start, we have to do all this stuff. But when we call start, it's going to start at submitted. This order might be an order that's all but fulfilled, for example. So we have to do a few things here. We need to actually tell the state machine to reset itself to our particular state. So let's do that here. We're going to say stateMachine.stop, first of all, we don't want it running, first of all, if it is already started. Then we're actually going to say sm.getStateMachineAccessor. This gives us the ability to do some things, to visit the nodes in the directed graph that is the state machine. So we can get the state machine accessor and then we can visit all the regions. So again, when you think about a state machine, you need to understand that state machines can themselves recurse on other state machines. You can have nodes that then lead to other state machines in a hierarchical fashion. So these are called regions. Each one of these state machines, nested or not, is called a region. I want to visit each region. So I'm going to visit each region here. So I'm going to say do with all regions. And I'm going to provide a state machine function. So new state machine function.
工厂,好的,好东西,看看那个。所以这个factory.getStateMachine,传入ID,这个ID就是订单ID键。很好。这就是我们的状态机。但再次强调,这个状态机还没有启动。记得我们之前是怎么用的吗?我们必须调用start,必须做所有这些事情。但当我们调用start时,它会从submitted状态开始。这个订单可能是一个几乎完成的订单,例如。所以我们需要做一些事情。我们需要告诉状态机将自己重置到我们特定的状态。所以让我们在这里做这件事。我们首先要做的是stateMachine.stop,首先,如果它已经启动了,我们不希望它运行。然后我们实际上要说sm.getStateMachineAccessor。这给了我们做一些事情的能力,访问有向图中的节点,这个有向图就是状态机。所以我们可以获取状态机访问器,然后我们可以访问所有区域。所以再次,当你考虑一个状态机时,你需要明白状态机本身可以在其他状态机上递归。你可以有节点,然后以层次结构的方式引导到其他状态机。所以这些被称为区域。每一个状态机,无论是嵌套的还是非嵌套的,都被称为一个区域。我想访问每个区域。所以我要在这里访问每个区域。所以我要说do with all regions。我要提供一个状态机函数。所以新的状态机函数。
精炼总结 1. **状态机操作**:讨论了如何通过`factory.getStateMachine`方法获取状态机实例,并传入订单ID作为键。-
状态机启动:强调状态机在调用
start方法时会从submitted状态开始,但可能需要重置到特定状态。 -
状态机重置:描述了如何通过
stateMachine.stop方法停止状态机,并使用sm.getStateMachineAccessor访问状态机中的节点和区域。 -
区域访问:解释了状态机可以嵌套,每个状态机(无论是嵌套还是非嵌套)都被称为一个区域,并讨论了如何访问所有区域。
- 参考回答:因为在某些情况下,状态机可能已经在运行,如果不先停止它,可能会导致状态混乱或冲突。
- 问题:状态机的区域访问有什么实际应用场景?
- 参考回答:在复杂的系统中,状态机的区域访问可以帮助管理不同层次的状态变化,确保每个部分的状态都能被正确处理和更新。
- 状态重置的必要性:原文强调了状态机需要重置到特定状态,这在某些情况下可能是必要的,但也可能引入额外的逻辑和潜在的错误点。是否可以通过其他方式(如状态检查和条件判断)来避免频繁的状态重置,从而简化状态管理?
00:41:02-00:42:29
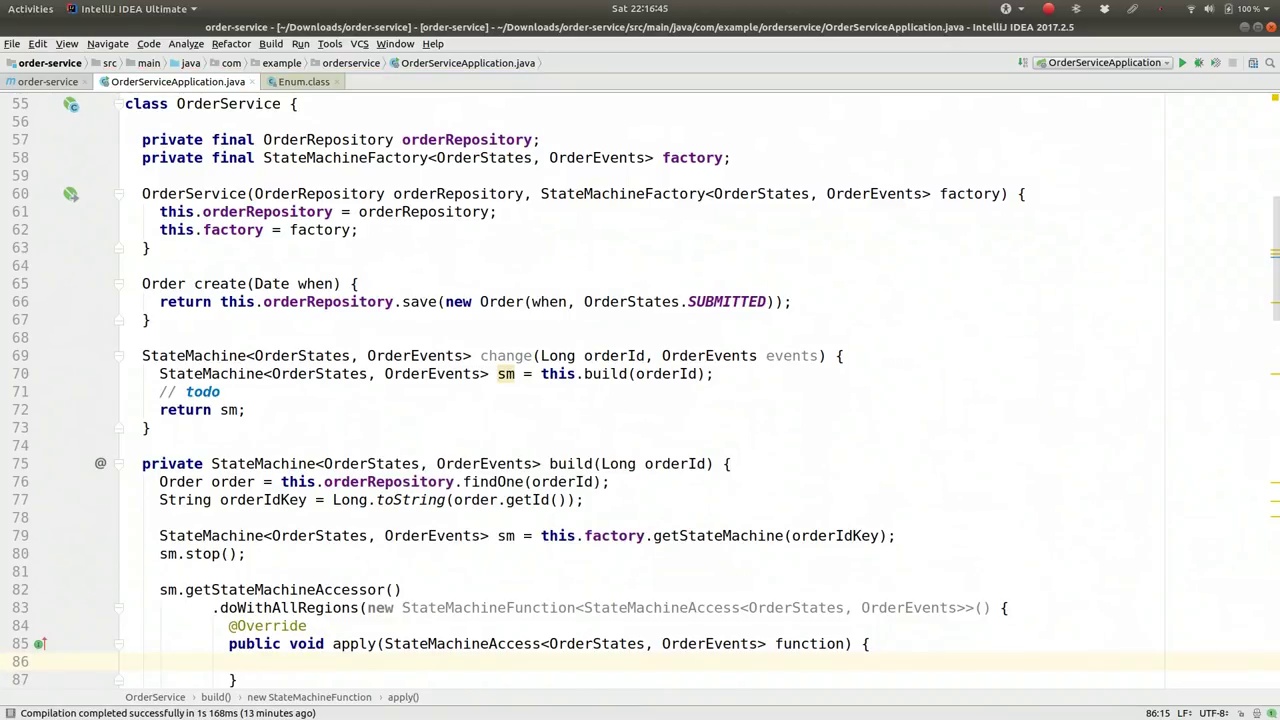
The state machine function has a simple apply method where I'm given a StateMachineAccess (SMA). The first step is to ensure a new default state machine context by calling SMA.resetStateMachine(). This context takes the current state of the object as its first parameter, which I obtain by calling order.getOrderState(). This action ensures the state machine is forcibly moved to the correct state, allowing for a predictable progression. All other parameters can be null for now. This method can also be implemented as a lambda, which is beneficial. We might reuse this functionality later, so it's advisable to keep it as is, though it can utilize the diamond syntax from Java 7.
状态机函数包含一个简单的apply方法,其中我获得了一个StateMachineAccess(SMA)。第一步是通过调用SMA.resetStateMachine()来确保一个新的默认状态机上下文。这个上下文以对象的当前状态作为其第一个参数,我通过调用order.getOrderState()来获取该状态。这一操作确保状态机被强制移动到正确的状态,从而允许可预测的进展。目前,所有其他参数都可以为空。这个方法也可以实现为lambda表达式,这是有益的。我们可能会在将来重用这一功能,因此建议保持原样,尽管它可以利用Java 7的菱形语法。
精炼总结 1. 状态机函数包含一个apply方法,使用StateMachineAccess(SMA)。-
通过调用SMA.resetStateMachine()确保新的默认状态机上下文。
-
上下文的第一个参数是对象的当前状态,通过order.getOrderState()获取。
-
确保状态机移动到正确状态,允许可预测的进展。
-
其他参数可以为空。
-
方法可实现为lambda表达式,建议保持原样,可能利用Java 7的菱形语法。
- 参考回答:调用SMA.resetStateMachine()是为了确保状态机从一个已知的状态开始,避免因之前操作的残留状态导致的不确定性,从而保证状态机的可预测性和正确性。
- 将方法实现为lambda表达式有什么好处?
- 参考回答:将方法实现为lambda表达式可以提高代码的简洁性和可读性,同时便于在需要时进行功能的重用和扩展。
- 文中提到“所有其他参数都可以为空”,这可能暗示了方法设计上的灵活性,但也可能增加了潜在的错误风险。是否应该明确这些参数的默认值或进行更严格的参数检查?
00:42:29-00:43:07
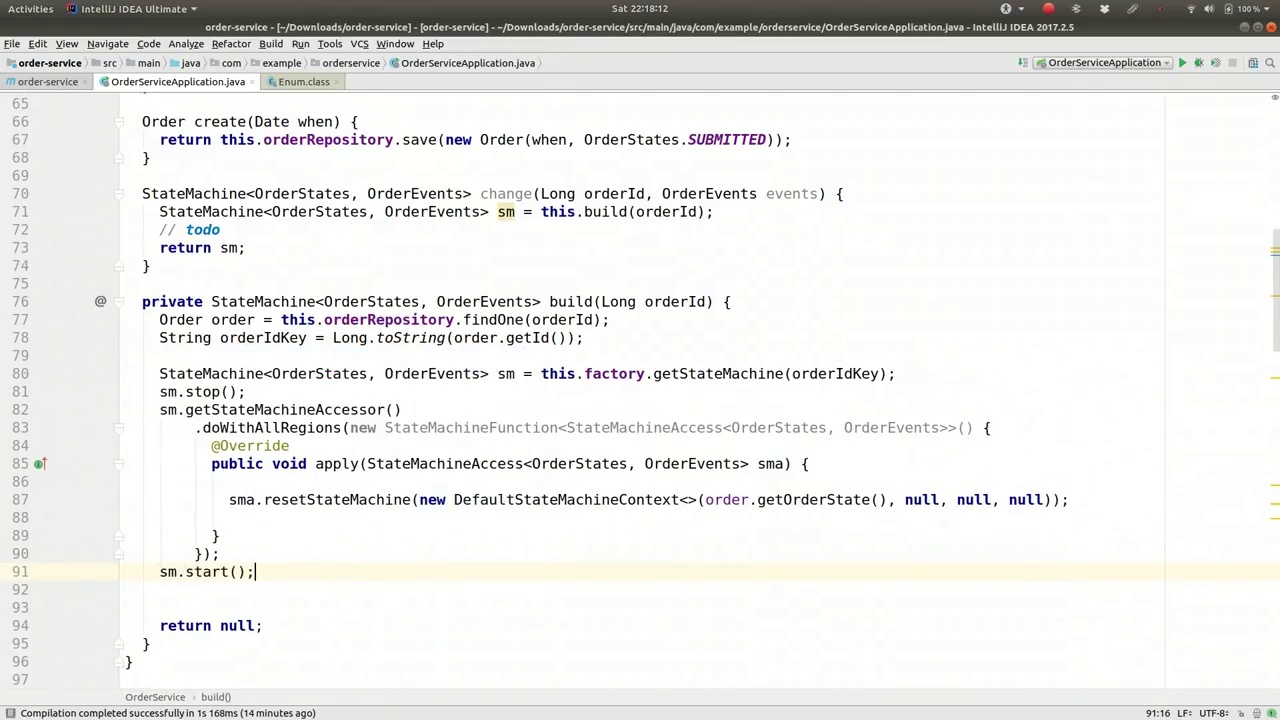
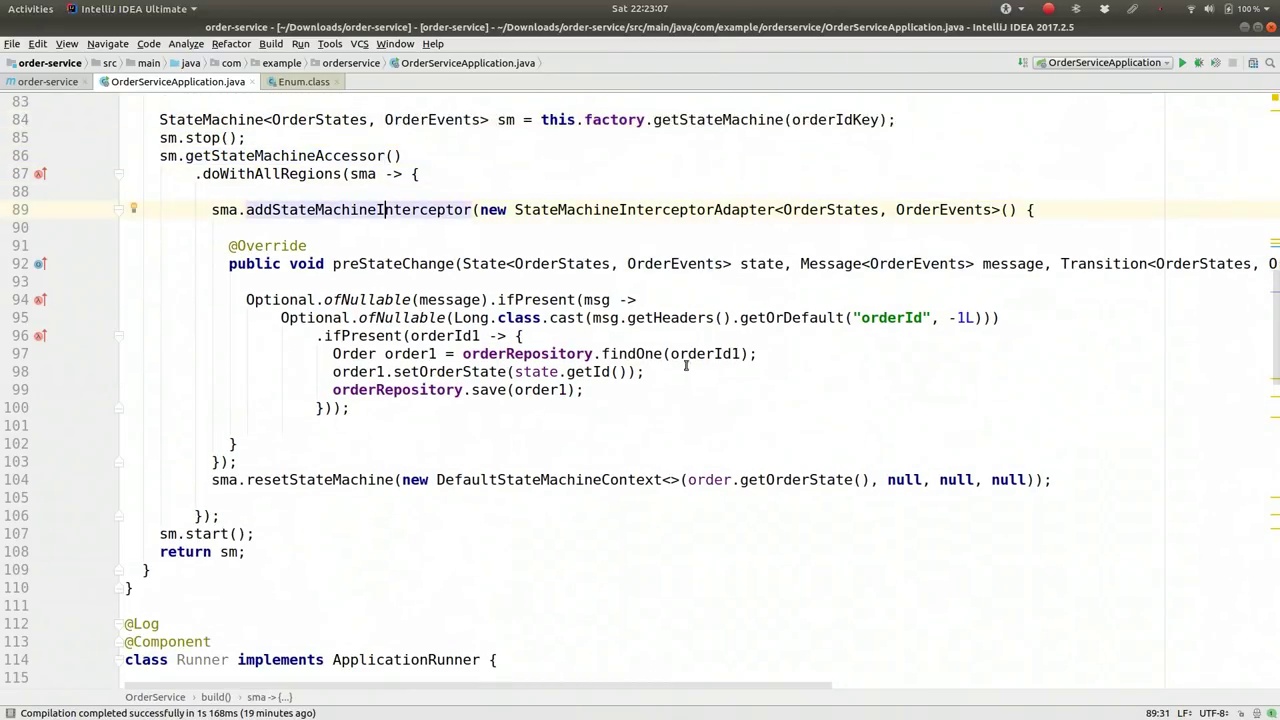
So let's actually start up the state machine for now, start it up, and return it. Now, the question that comes up is, how are we going to persist this record? How is this repository ever going to find that record in the first place? Something needs to take care to persist the state changes with the entity itself. So when the entity, when the state machine changes, I want to update that state field on the JP entity. So here we need to add a state machine interceptor here. So we'll say,
那么,现在我们实际上启动状态机,启动它,并返回它。现在出现的问题是,我们如何持久化这个记录?这个存储库最初是如何找到那个记录的?需要有人负责将状态变化与实体本身一起持久化。因此,当实体,即状态机发生变化时,我想更新JP实体上的状态字段。所以这里我们需要在这里添加一个状态机拦截器。我们会说,
精炼总结 1. 启动状态机并返回。-
需要持久化状态机记录。
-
存储库需找到并持久化状态变化。
-
状态机变化时更新JP实体的状态字段。
-
需添加状态机拦截器。
参考回答:通过存储库找到记录并持久化状态变化,确保状态机变化时更新JP实体的状态字段。
- 问题:为什么需要添加状态机拦截器?
参考回答:为了在状态机发生变化时,能够及时拦截并处理相关操作,确保状态变化与实体的持久化同步进行。
批判性思考 - 原文强调了状态机记录的持久化重要性,但未详细说明持久化过程中可能遇到的技术挑战和解决方案。例如,如何处理并发操作导致的状态冲突,以及如何确保持久化过程的效率和可靠性。-
添加状态机拦截器的建议是合理的,但未讨论拦截器的具体实现细节和可能的副作用。例如,拦截器的设计是否会影响系统的性能,以及如何处理拦截器本身的错误和异常情况。
-
原文提到需要有人负责持久化状态变化,这暗示了可能存在责任分配的问题。在实际应用中,如何明确责任并确保每个环节的顺畅协作是一个值得深入探讨的问题。
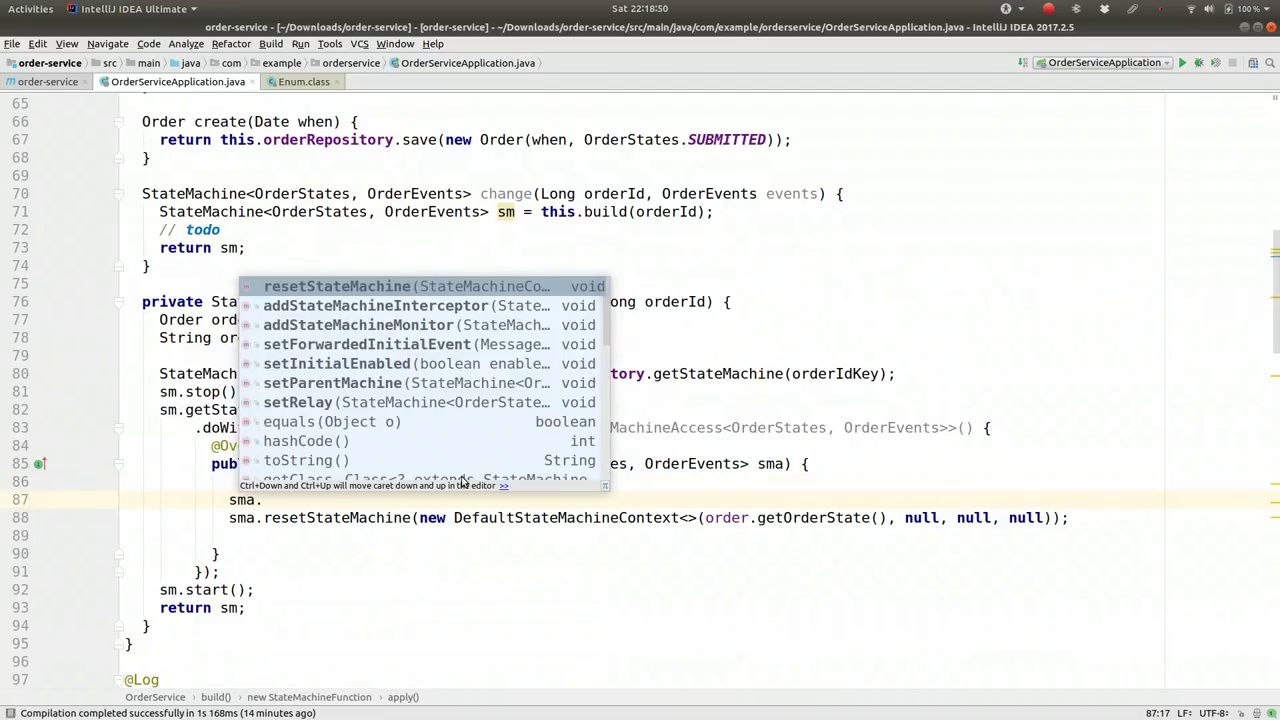
00:43:07-00:43:36
sma.addStateMachineInterceptor(new StateMachineInterceptor()); This uses the adapter because there are multiple callback methods for orderStates and orderEvents.
译文终稿
sma.addStateMachineInterceptor(new StateMachineInterceptor()); 这里使用了适配器,因为对于orderStates和orderEvents有多个回调方法。
- 适配器应用于orderStates和orderEvents。
- 参考回答:使用适配器模式可以简化代码结构,统一管理多个回调方法,提高代码的可维护性和扩展性。
- 适配器模式在处理多个回调方法时有哪些优势?
- 参考回答:适配器模式可以将多个回调方法封装在一个适配器类中,使得代码更加模块化和清晰,同时便于后续的修改和扩展。
- 另外,适配器模式可能会引入额外的性能开销,因为每次回调都需要通过适配器进行处理。在性能敏感的应用场景中,需要仔细评估适配器模式的使用是否会对系统性能产生负面影响。
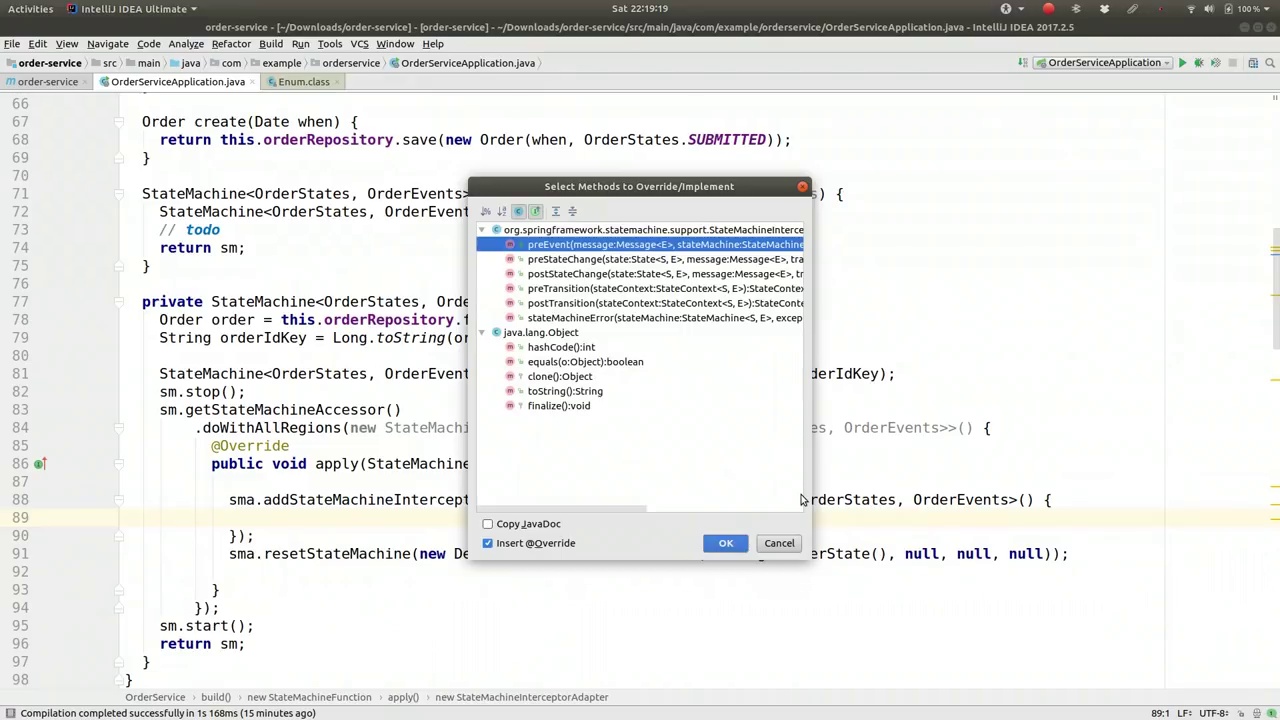
00:43:36-00:46:06
So we need to write the state into the database before every single state change, or we could do it after; it really doesn't matter. For our purposes, I'm going to write it down in the database. There's no reason this method couldn't take place in the same context if you're persisting the state change in our JPA entity. There's no reason the state change couldn't happen in the same context and thread as your business logic changes. However, in this case, you could also persist this completely separately from your entity. Okay, so for pre-state change, we're going to expect a parameter, a header, to come in on the event that triggered the state change. This is why we showed you the message builder variant earlier for sending an event into the state machine. You can send either the enum value or a Spring Framework messaging message with a header. That header option is what we're going to use because it has the ability to convey parameters, headers, values that we can pass into the state machine, which we can use to persist our data. So, if the message we are given here is not null, if it's present, we want to do something with it. We want to get out the ID, so the order ID is the value we're going to get from message.getHeaders.getOrDefault. It's going to be called order ID, defaulting to negative one. We looked at this exact same thing earlier and we're going to say optional.ofNullable. If that's present, order ID, then we want to process it. We have the ID, and if it's present, we're going to get the order, order equals orderRepository.findOne, and we'll put the order ID in to get it out of the database.
因此,我们需要在每次状态变化之前将状态写入数据库,或者之后再写入;这真的无关紧要。为了我们的目的,我打算将其记录在数据库中。如果你在我们的JPA实体中持久化状态变化,没有理由这种方法不能在相同的上下文中进行。没有理由状态变化不能在与你的业务逻辑变化相同的上下文和线程中发生。然而,在这种情况下,你也可以完全独立于你的实体来持久化这个状态。好的,对于状态变化之前,我们期望在触发状态变化的事件中传入一个参数,一个头部信息。这就是为什么我们之前向你展示了消息构建器的变体,用于将事件发送到状态机。你可以发送枚举值或带有头部的Spring框架消息。我们将使用头部选项,因为它有能力传递参数、头部值,我们可以将其传递到状态机中,用于持久化我们的数据。因此,如果我们在这里收到的消息不是空的,如果它存在,我们希望对其进行处理。我们想要获取ID,所以订单ID是我们将从message.getHeaders.getOrDefault中获取的值。它将被命名为order ID,默认值为负一。我们之前看过完全相同的内容,我们将说optional.ofNullable。如果存在order ID,那么我们希望处理它。我们有ID,如果它存在,我们将获取订单,order等于orderRepository.findOne,并将order ID放入以从数据库中获取它。
精炼总结 1. 状态变化记录:建议在状态变化前后将状态写入数据库,方法适用于JPA实体持久化。-
状态变化上下文:状态变化可在与业务逻辑相同的上下文和线程中进行,也可独立于实体持久化。
-
消息处理:在状态变化前,通过消息构建器发送带有头部信息的事件到状态机,用于传递参数。
-
消息处理细节:从消息头部获取订单ID,使用默认值-1,通过订单ID从数据库获取订单。
参考回答:在状态变化前后记录状态可以确保状态的完整性和一致性,避免因异常情况导致的状态丢失或不一致。
- 问题:使用消息构建器发送事件到状态机的优势是什么?
参考回答:使用消息构建器可以灵活地传递参数和头部信息,便于在状态机中处理和持久化数据,提高系统的可扩展性和灵活性。
批判性思考 - 原文强调了状态变化记录的灵活性,但未充分讨论这种灵活性可能带来的复杂性和维护成本。在实际应用中,频繁的状态变化记录可能会增加数据库的负担,影响系统性能。- 原文提到使用消息构建器发送事件到状态机,但未讨论消息传递失败或消息处理的错误处理机制。在分布式系统中,消息传递的可靠性是一个重要问题,需要有相应的容错和恢复机制。
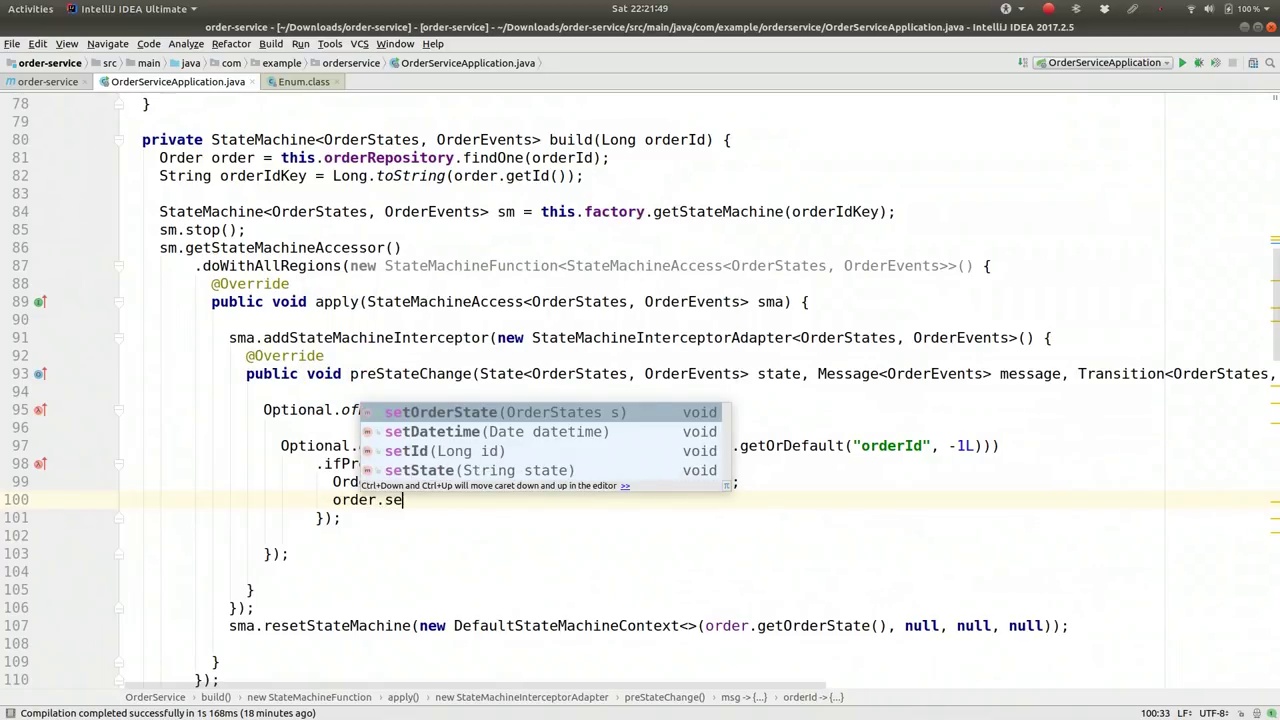
00:46:06-00:46:42
We're going to update the state, so I'm going to say order.setState, and the state will be whatever state we're progressing to, and that state, of course, is passed into this callback here. So state.getId.name, write that out, or we can actually just say setOrderState, I suppose that would have been easier. So setOrderState, there we go, .getId. All right, there's that. And we want to say OrderRepository.save, so order. Very good.
我们要更新状态,所以我会说 order.setState,状态将是我们要进入的任何状态,当然,这个状态会传递到这里的回调函数中。所以我们可以写 state.getId.name,或者我们可以直接说 setOrderState,我想这样会更简单。所以是 setOrderState,就这样,.getId。好了,就这样。然后我们想要说 OrderRepository.save,所以是 order。非常好。
精炼总结 1. 更新订单状态的方法:使用 `order.setState` 或 `setOrderState`。-
状态信息传递:状态会传递到回调函数中,可以通过
state.getId.name获取状态名称。 -
保存订单:使用
OrderRepository.save方法保存订单。
参考回答:作者认为 setOrderState 更简单易懂,可能是因为它更直观地表达了设置状态的操作。
- 问题:在更新订单状态时,如何确保状态信息正确传递到回调函数中?
参考回答:通过调用 state.getId.name 可以获取状态名称,确保状态信息被正确传递和使用。
- 对于状态信息的传递,原文仅提到可以通过
state.getId.name获取状态名称,但未讨论状态信息传递的完整性和安全性。在实际开发中,需要考虑状态信息在传递过程中可能出现的错误或被篡改的情况,并采取相应的措施来确保信息的准确性和安全性。
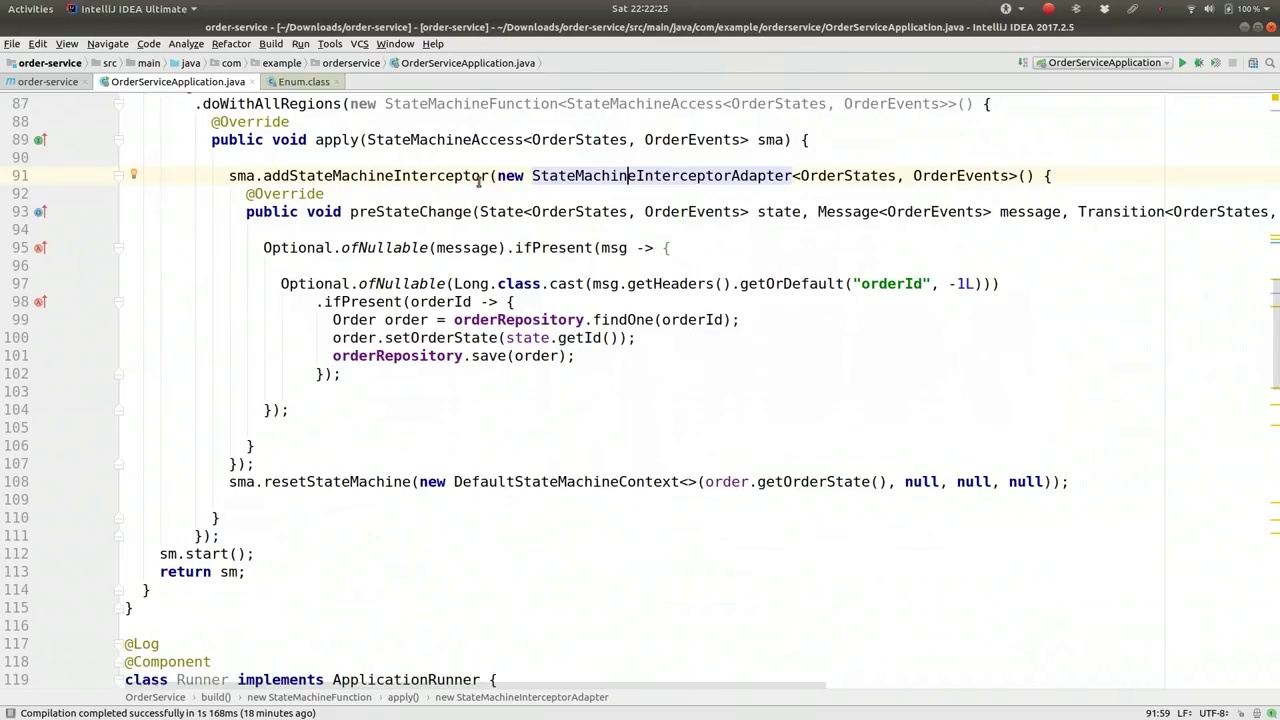
00:46:42-00:47:24
Okay, so that's what's happening here. We've got a callback when the state machine enters a particular stage. We want to, right before it enters, write down the state that it's going to arrive at. We want to do that by tying it to the order itself and we need to do that by linking our change to a parameter that tells us which order is affected. Let's revisit our code here and clean that up a little bit.
好的,这就是这里发生的情况。当状态机进入特定阶段时,我们会收到一个回调。我们希望在它进入之前,记录下它即将到达的状态。我们希望通过将其与订单本身关联来实现这一点,并且需要通过链接到一个参数来完成,该参数告诉我们哪个订单受到了影响。让我们重新审视一下这里的代码,并稍作整理。
精炼总结 1. 状态机在进入特定阶段时会触发回调。-
需要在状态机进入该阶段之前记录即将到达的状态。
-
记录的状态需要与特定订单关联。
-
通过链接参数来确定哪个订单受到影响。
-
需要重新审视和整理代码。
参考回答:可以通过在状态机进入该阶段之前设置一个预处理步骤,在这个步骤中记录即将到达的状态。
- 问题:如何将记录的状态与特定订单关联?
参考回答:可以通过在记录状态时,同时记录该状态对应的订单ID或订单信息,从而实现状态与订单的关联。
批判性思考 - 原文中提到需要通过链接参数来确定哪个订单受到影响,但没有具体说明这个参数是什么以及如何获取。这可能导致在实际操作中难以准确确定受影响的订单。-
原文提到需要重新审视和整理代码,但没有给出具体的整理方法或标准。这可能导致整理后的代码仍然存在逻辑不清晰或效率低下的问题。
-
原文没有讨论在多线程或并发环境下如何确保状态记录的准确性和一致性,这在实际应用中是一个需要考虑的重要问题。
00:47:24-00:47:51
So that's a bit cleaner, I like that, and I'm all about clean code. Now we have our state machine, including a state machine accessor. All of this is configured on every new state machine. The state machine is a lightweight object, but we will perform some complex operations with it. We will interact with a database to persist state very easily. It doesn't require much effort to integrate the state machine's state with our business logic.
这样一来代码更简洁了,我喜欢这种风格,我一向推崇编写干净的代码。现在我们有了状态机,包括一个状态机访问器。所有这些配置都应用于每个新的状态机实例。状态机是一个轻量级对象,但我们将在其上执行一些复杂的操作。我们将与数据库交互,以便非常轻松地持久化状态。将状态机的状态与我们的业务逻辑集成起来并不需要太多工作。
精炼总结 1. 作者喜欢编写简洁的代码风格。-
引入了状态机,包括状态机访问器。
-
状态机是轻量级对象,但将执行复杂操作。
-
状态机将与数据库交互,以便轻松持久化状态。
-
状态机状态与业务逻辑的集成相对简单。
参考回答:状态机的主要功能是管理和转换状态,以及与数据库交互以持久化这些状态。
- 问题:为什么作者认为状态机是轻量级的?
参考回答:尽管状态机将执行复杂操作,但作者提到它是轻量级对象,这可能意味着它在资源消耗和性能方面是高效的。
批判性思考 1. 虽然作者提到状态机是轻量级的,但并未详细说明其性能和资源消耗的具体情况。在实际应用中,轻量级可能并不总是意味着高效,特别是在处理复杂操作时。需要进一步的性能测试和优化来验证这一点。- 作者提到状态机与业务逻辑的集成相对简单,但这可能取决于具体的业务逻辑复杂度。对于简单的业务逻辑,集成可能确实简单,但对于复杂的业务逻辑,可能需要更多的设计和调整。因此,需要根据具体的业务需求来评估集成的难易程度。
00:47:51-00:48:38
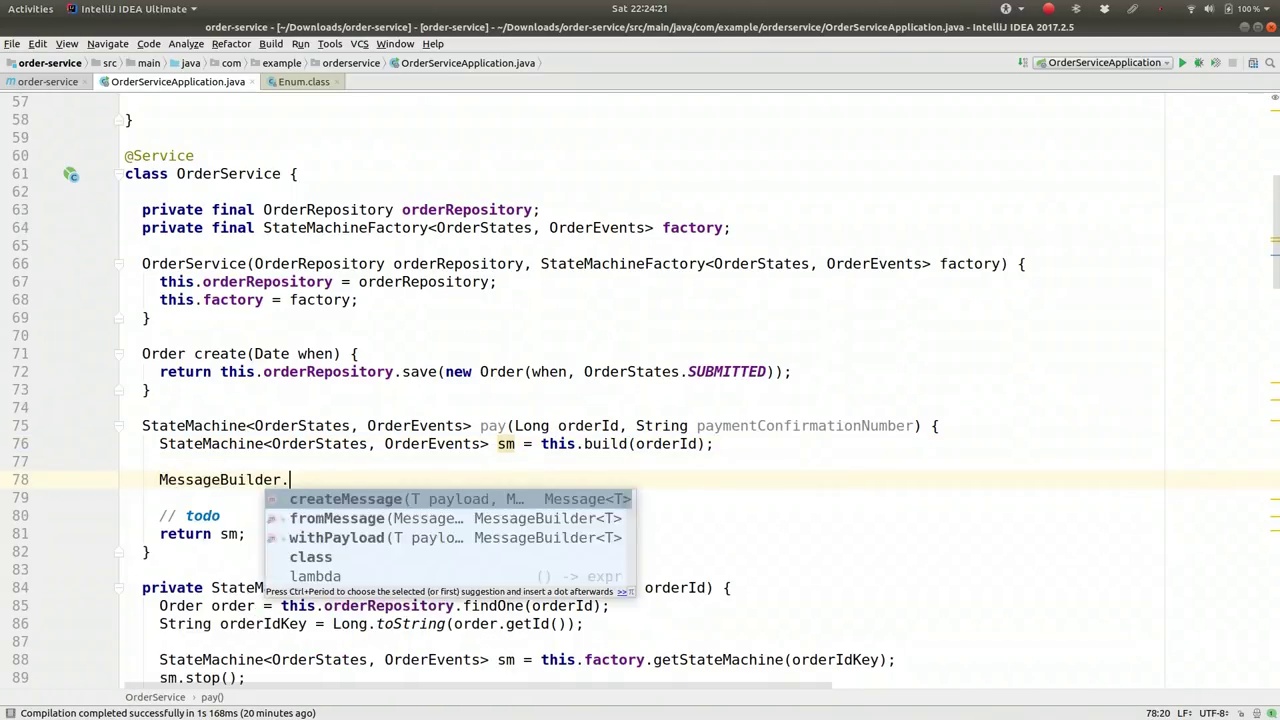
So we're going to get the best of both worlds. We get our business logic, which is clean. We get a definitive state machine and a model of how these things are supposed to progress, and so on. So, okay, good. Now let's see what happens. If we run this, what happens, right? So we want to be able to, this will actually create a state machine that'll build a state machine here. We want to be able to change the flow, the state of the state machine. So maybe we could do this. We could actually say pay, and then here we could say, we could have some property of how much is paid, string, I don't know, payment confirmation number, right? And then we could actually
所以我们将会两全其美。我们得到了清晰的业务逻辑,我们得到了一个明确的状态机以及这些事物应该如何进展的模型等等。好了,很好。现在让我们看看会发生什么。如果我们运行这个,会发生什么呢?我们希望能够,这实际上会创建一个状态机,在这里构建一个状态机。我们希望能够改变流程,改变状态机的状态。所以也许我们可以这样做。我们可以实际地说支付,然后在这里我们可以说,我们可以有一些属性,比如支付了多少,字符串,我不知道,支付确认号码,对吧?然后我们实际上可以
精炼总结 1. 描述了业务逻辑的清晰性和状态机的明确性。-
讨论了运行状态机可能的结果,包括创建和改变状态机状态。
-
提到了可能的支付流程,包括支付金额和支付确认号码等属性。
参考回答:状态机在业务逻辑中的主要作用是帮助管理和控制流程的进展,确保每个状态的转换都是明确和可控的。
- 问题:如何通过状态机实现支付流程的改变?
参考回答:通过在状态机中定义不同的状态和转换条件,可以实现支付流程的改变。例如,定义支付状态并设置相应的属性(如支付金额和支付确认号码),以便在状态转换时进行处理。
批判性思考 1. 虽然状态机提供了清晰的业务逻辑和流程控制,但在实际应用中可能面临复杂性和灵活性的挑战。例如,随着业务需求的变化,状态机的维护和更新可能会变得复杂。- 文中提到的支付流程和属性(如支付金额和支付确认号码)虽然提供了具体的例子,但在实际应用中可能需要更多的细节和验证机制,以确保支付流程的安全性和准确性。
00:48:38-00:48:53
Send a message, we could say MessageBuilder.withPayload and the payload, of course, in this case, is the pay event, so OrderEvents.
发送消息时,我们可以使用 MessageBuilder.withPayload 方法,而在这个例子中,负载(payload)就是支付事件,即 OrderEvents。
00:48:53-00:49:03
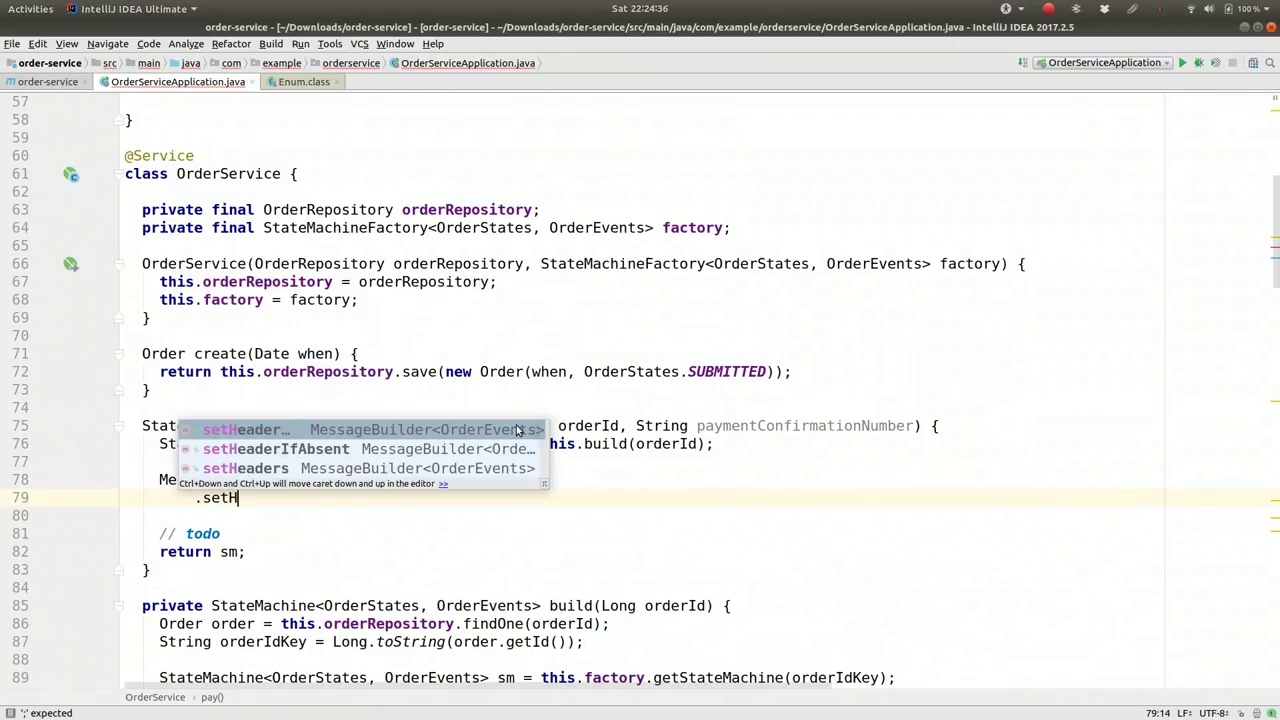
Pay and the header that we need, of course, is the order ID. So there's the order ID, and we're going to build that map.
当然,我们需要支付信息和标题中的订单ID。所以这里有订单ID,我们将构建这个映射。
00:49:03-00:49:48
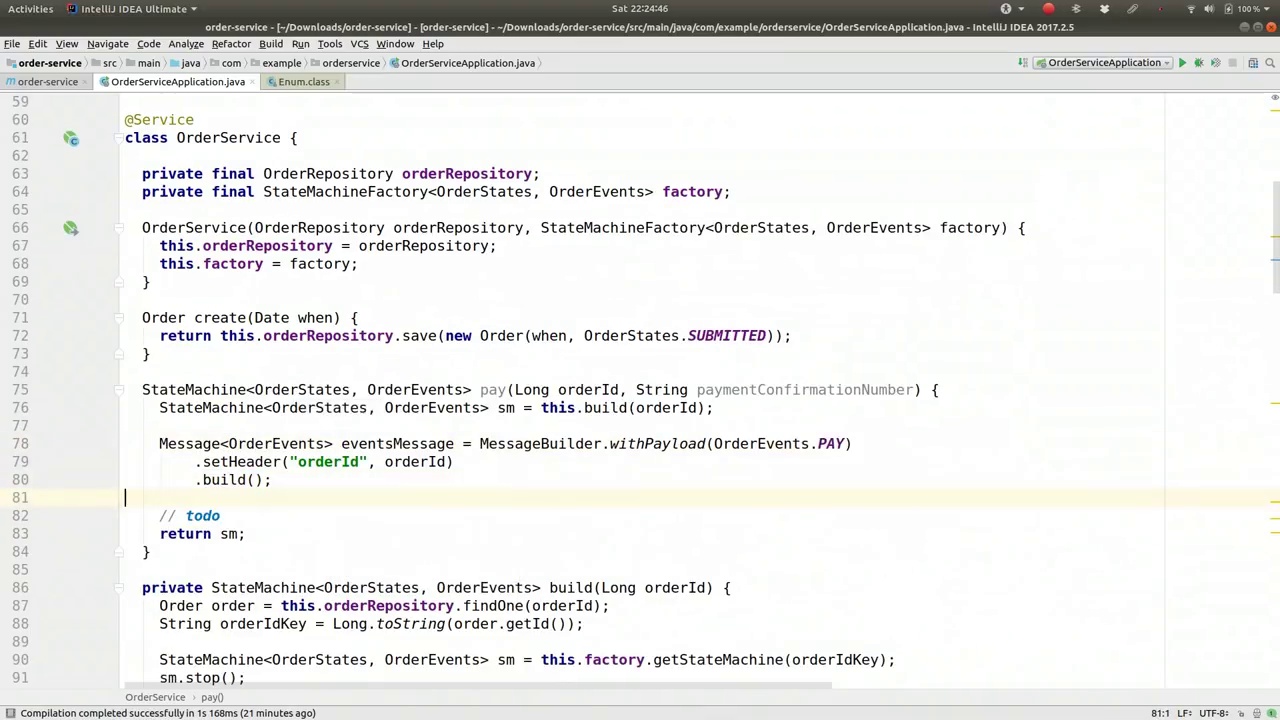
In the message, we could include elements such as the payment confirmation number. Setting the header for the payment confirmation number, or even the price, although we won't be using this in our example, it's useful to know that we can pass this information into the state machine. The state machine can then perform any actions as previously demonstrated. We will proceed by calling sm.sendEvent(eventsMessage), specifically the payment message. This is the initial step, and we know it will be referred to by the order ID, which should ideally be retained.
在消息中,我们可以包含诸如支付确认号等元素。设置支付确认号的标题,甚至是价格,尽管在我们的示例中不会用到这些,但了解我们可以将这些信息传递给状态机是很有用的。状态机随后可以执行任何先前展示过的操作。我们将通过调用sm.sendEvent(eventsMessage)来继续,特别是支付消息。这是初始步骤,我们知道它将通过订单ID来引用,理想情况下应该保留该ID。
-
可以设置支付确认号的标题和价格。
-
状态机可以处理这些信息并执行操作。
-
通过调用
sm.sendEvent(eventsMessage)发送支付消息。 -
支付消息通过订单ID引用,应保留该ID。
参考回答:支付确认号在消息中的作用是确保支付信息的准确性和唯一性,便于后续的状态机处理和操作。
- 问题:为什么需要保留订单ID?
参考回答:保留订单ID是为了确保支付消息的准确引用,便于追踪和管理支付流程,以及后续的订单状态更新和处理。
批判性思考 1. 虽然消息中包含支付确认号等元素可以提高信息的准确性,但也可能增加系统的复杂性和处理负担。需要权衡信息完整性和系统效率之间的关系。-
状态机处理支付消息的能力虽然强大,但也依赖于消息的准确性和完整性。如果消息中缺少关键信息,可能会导致状态机处理失败或错误。因此,需要确保消息的完整性和正确性。
-
保留订单ID的做法虽然有助于追踪和管理支付流程,但也可能带来数据安全和隐私保护的问题。需要采取适当的安全措施来保护订单ID和相关支付信息。
00:49:48-00:50:03
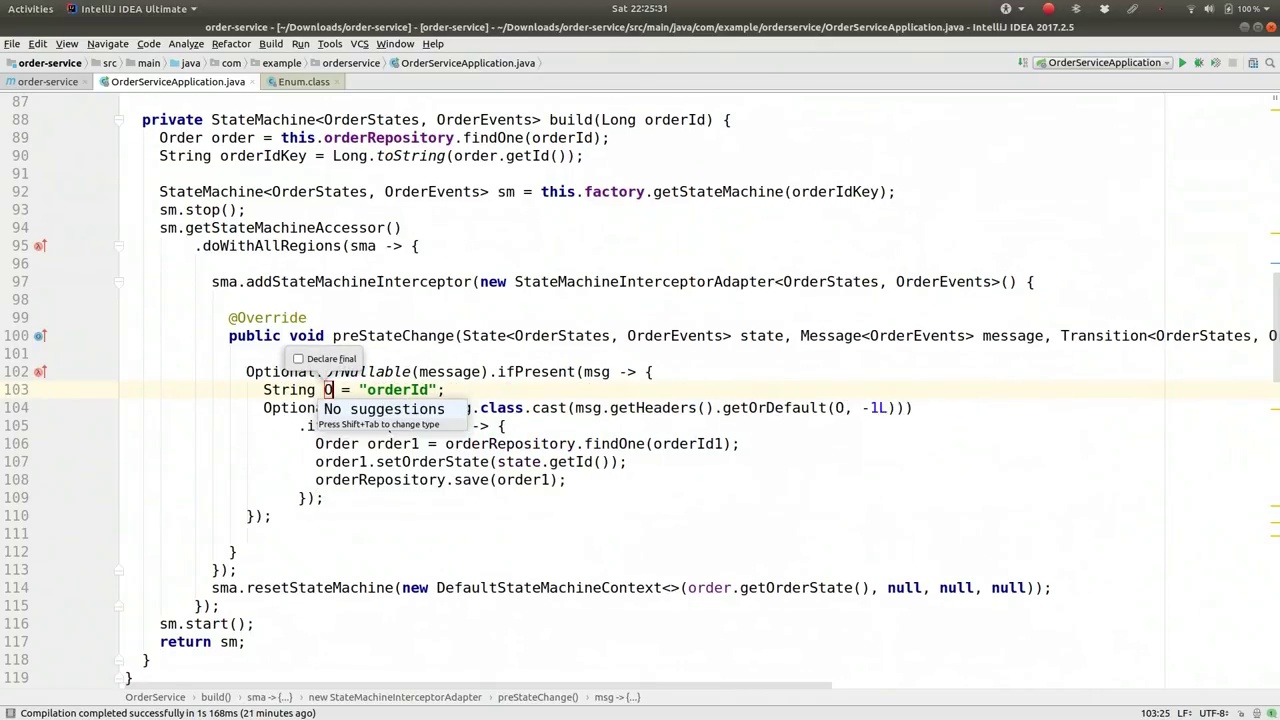
You've extracted into a single field, so you have the order ID header. You should have that as a constant somewhere and then use it in the class. So, private static final, there you go.
你已经将内容提取到一个字段中,因此你有了订单ID的标题。你应该在某个地方将其设为常量,然后在类中使用它。所以,使用private static final,就这样做。
00:50:03-00:51:16
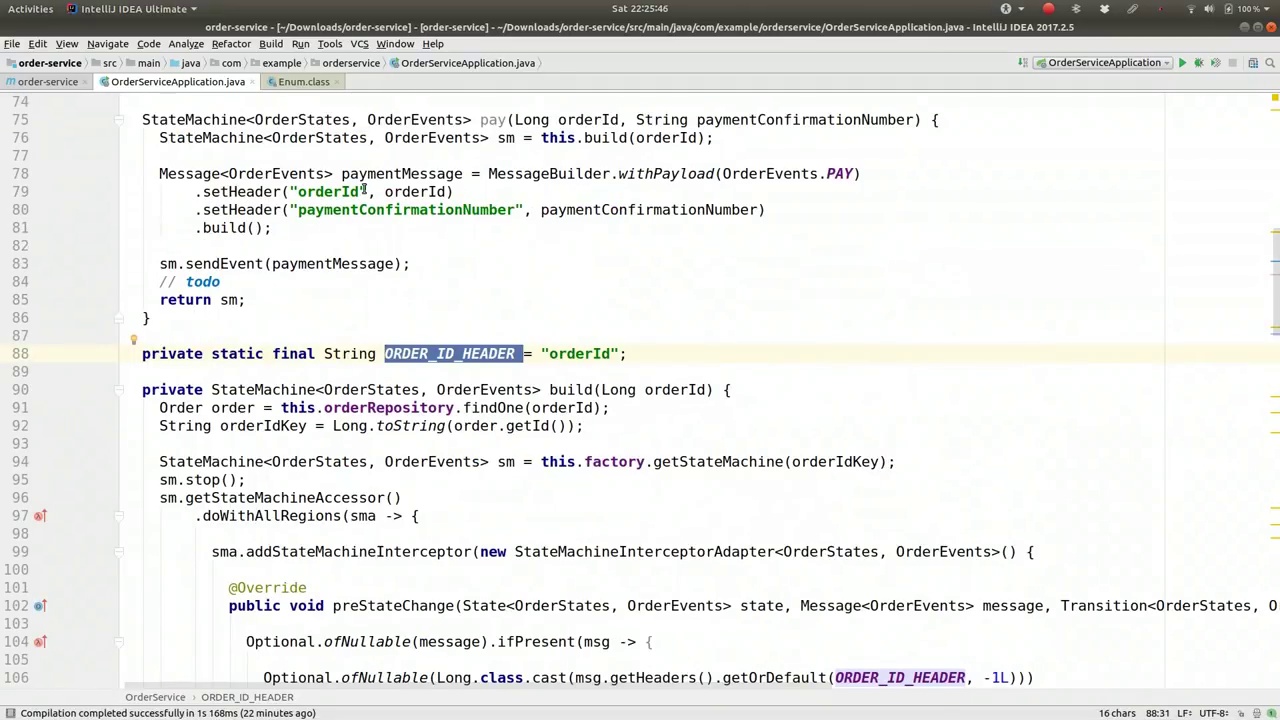
OrderIdHeader is a well-known type of header. Next, we need to implement a fulfillment method. This method, which I'll call Fulfill, should include the address for the parcel delivery. It can also include any additional information relevant to the object graph. The basic structure remains the same: we build the state machine and transition it to a specific state by sending an event.
OrderIdHeader 是一种常见的头部类型。接下来,我们需要实现一个履行方法。我将这个方法命名为 Fulfill,它应包含包裹递送的地址,还可以包含与对象图相关的任何附加信息。基本结构保持不变:我们构建状态机并通过发送事件将其过渡到特定状态。
精炼总结 1. **OrderIdHeader**:一种常见的头部类型。-
履行方法:命名为 Fulfill,包含包裹递送地址和可能的附加信息。
-
基本结构:构建状态机并通过发送事件实现状态过渡。
- 参考回答:这可能包括订单详情、客户信息、物流跟踪信息等,具体取决于业务需求和系统设计。
- 问题:状态机在实现Fulfill方法中的具体作用是什么?
- 参考回答:状态机用于管理订单处理的不同阶段,确保每个步骤按预定流程执行,通过发送事件触发状态转换,从而实现订单的正确履行。
- 附加信息的处理:在Fulfill方法中包含“与对象图相关的任何附加信息”可能导致方法过于臃肿。是否可以考虑将这些信息的管理和处理分离到其他模块或服务中,以保持方法的简洁性和专注性?
00:51:16-00:52:49
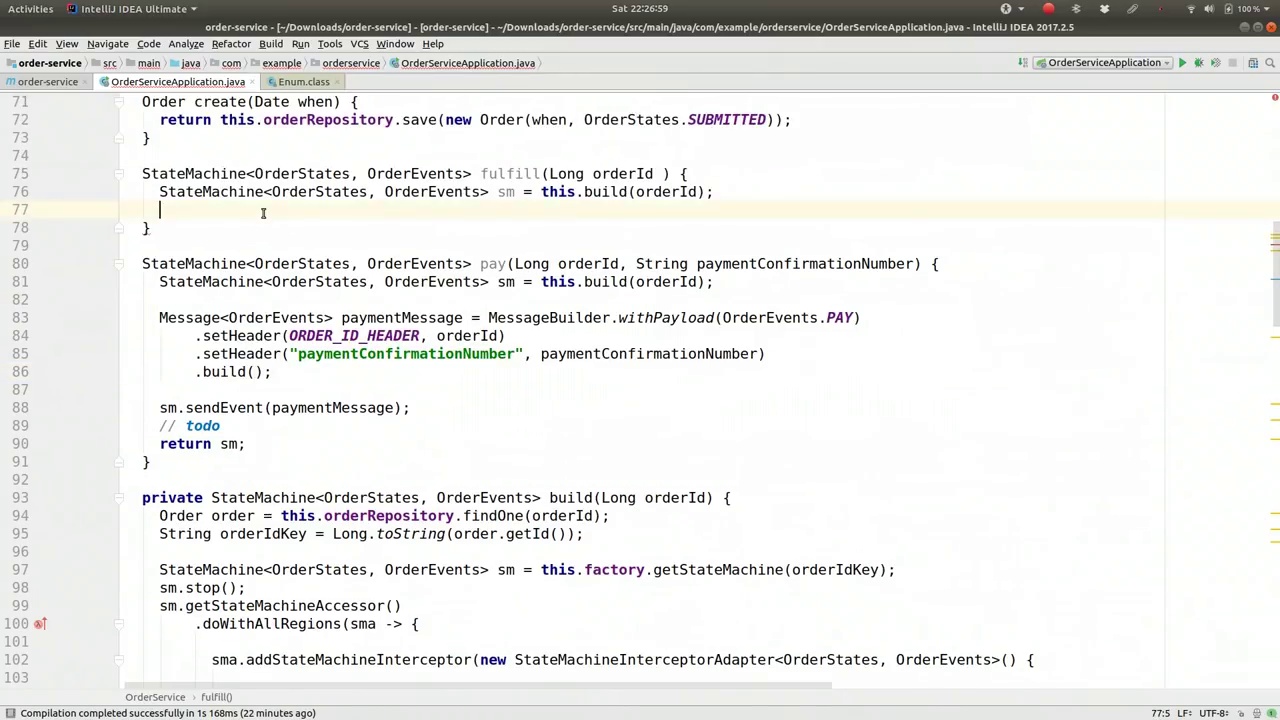
In this case, we don't have the payment confirmation. Therefore, we will use sm.sendEvent(paymentMessage). This will also involve fulfillmentMessage. Finally, we return sm. This completes our fulfillment method, including both payment and fulfillment processes. It is important to note that when initializing the state machine, it should reflect the current state of the order. Here, the state machine will trigger a state change, creating a new instance. This new instance will retrieve the corresponding record from the database, unpacking the event, message state, and order state. It ensures that by the time we reach this point, the state machine is already in the correct state. For example, if it is in the 'fulfilled' state, the state machine will reflect this before proceeding to the next line. In the next line, assuming it is in the 'paid' or 'submitted' state, it will be in the appropriate state upon exiting the this.build method. Subsequently, we transition it to the next state by sending a message.
在这种情况下,我们没有支付确认。因此,我们将使用 sm.sendEvent(paymentMessage)。这还会涉及 fulfillmentMessage。最后,我们返回 sm。这完成了我们的履行方法,包括支付和履行过程。需要注意的是,在初始化状态机时,它应该反映订单的当前状态。在这里,状态机会触发状态变化,创建一个新实例。这个新实例将从数据库中检索相应的记录,解包事件、消息状态和订单状态。它确保在我们到达这一点时,状态机已经处于正确的状态。例如,如果它处于“已履行”状态,状态机将在执行下一行之前反映这一点。在下一行,假设它处于“已支付”或“已提交”状态,它在退出 this.build 方法时将处于适当的状态。随后,我们通过发送消息将其过渡到下一个状态。
-
涉及
fulfillmentMessage完成履行过程。 -
返回状态机
sm完成履行方法。 -
初始化状态机时,应反映订单当前状态。
-
状态机触发状态变化,创建新实例,检索数据库记录,解包事件、消息状态和订单状态。
-
确保状态机在执行操作前处于正确状态,如“已履行”、“已支付”或“已提交”。
-
通过发送消息将状态机过渡到下一个状态。
参考回答:通过从数据库中检索相应的记录,解包事件、消息状态和订单状态,确保状态机在执行操作前处于正确的状态。
- 问题:状态机在什么情况下会触发状态变化并创建新实例?
参考回答:在初始化状态机时,状态机会触发状态变化,创建一个新实例,这个新实例将从数据库中检索相应的记录,解包事件、消息状态和订单状态。
批判性思考 - 原文强调了状态机在初始化时需要反映订单的当前状态,但未详细说明如何处理状态不一致或错误的情况。在实际应用中,可能会遇到数据库记录与实际订单状态不符的问题,需要有额外的错误处理和恢复机制来确保系统的稳定性和可靠性。- 文中提到通过发送消息将状态机过渡到下一个状态,但未讨论消息传递失败或延迟的情况。在分布式系统中,消息传递的可靠性是一个重要问题,需要考虑消息重试机制、超时处理和故障转移策略,以确保状态机能够正确过渡到下一个状态。
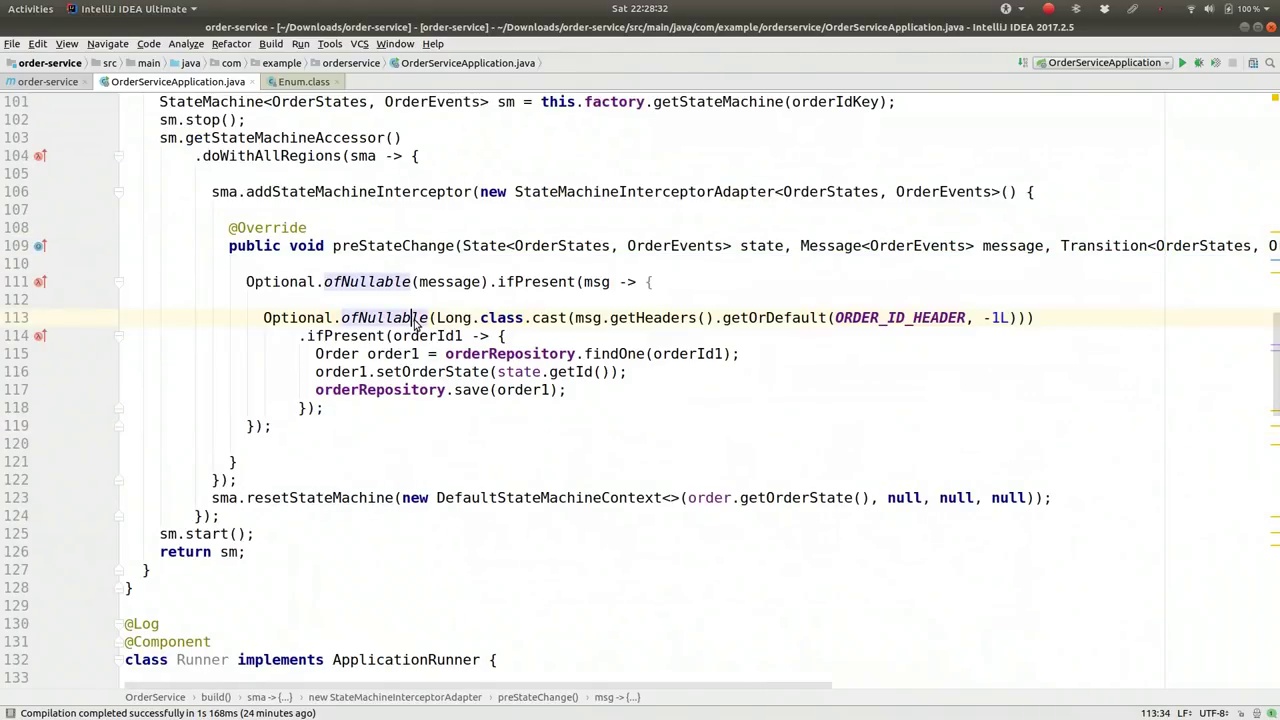
00:52:49-00:52:53
And that will trigger the pre-state change, which will update.
这将触发预状态变更,从而进行更新。
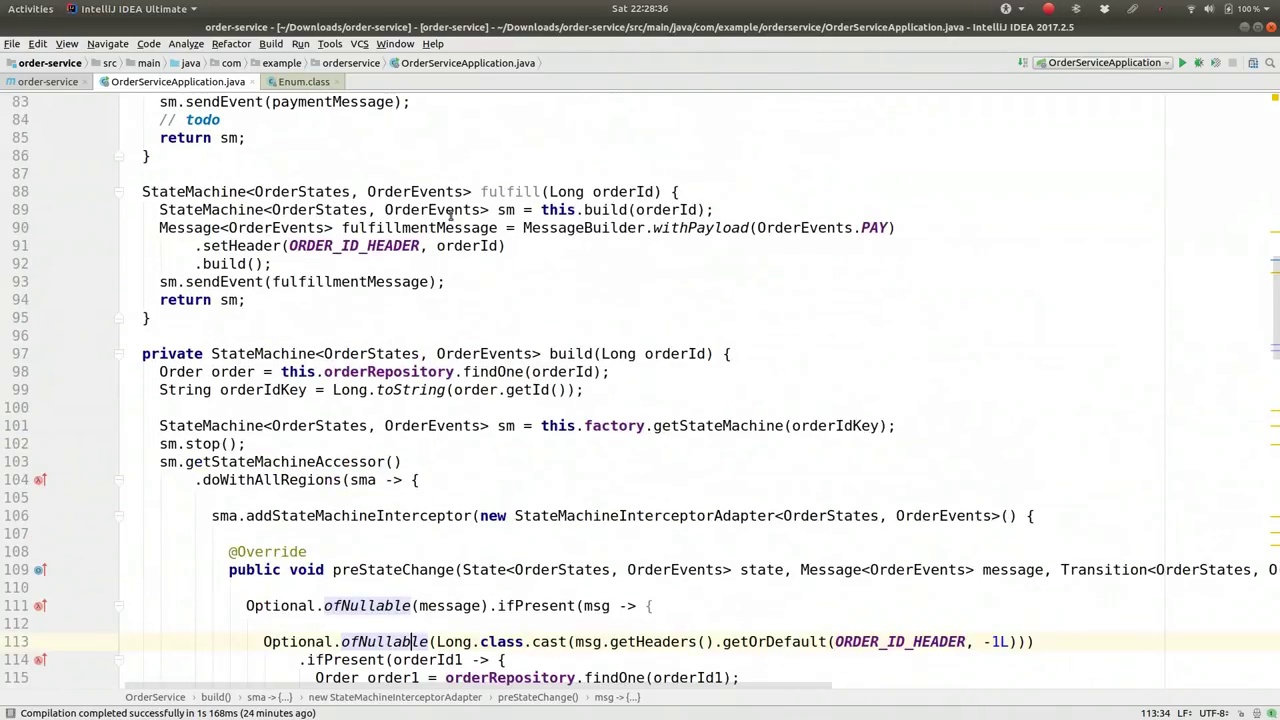
00:52:53-00:53:07
The persistent state is stored in the database. This process occurs very quickly. With this, we are reading the data from the order object, retrieving the state from the persistent order object, and setting the state machine to that state.
持久化状态存储在数据库中,这一过程非常迅速。通过这种方式,我们从订单对象中读取数据,从持久化的订单对象中获取状态,并将状态机设置为该状态。
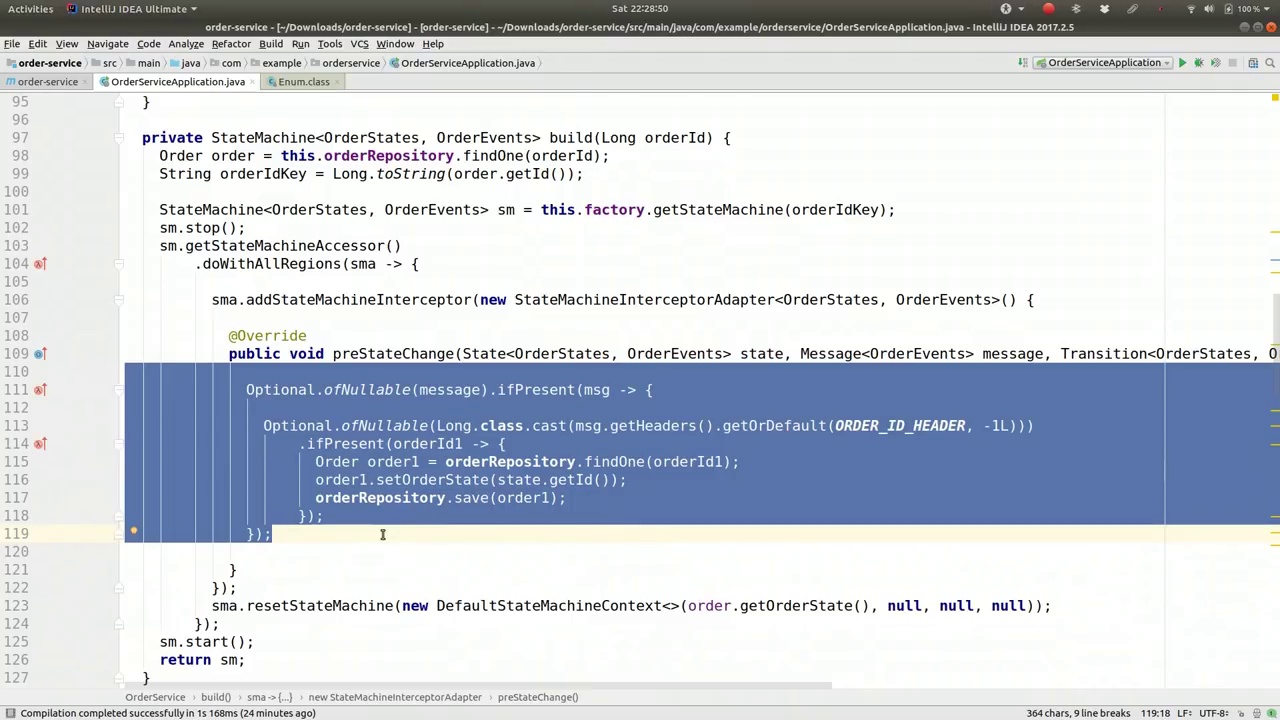
00:53:07-00:53:15
And with this, we're setting the changes or synchronizing the changes to the state machine to the order itself. So, bidirectional persistence.
这样一来,我们就将变更设置或同步到状态机中,使之与订单本身保持一致。这就是双向持久化。
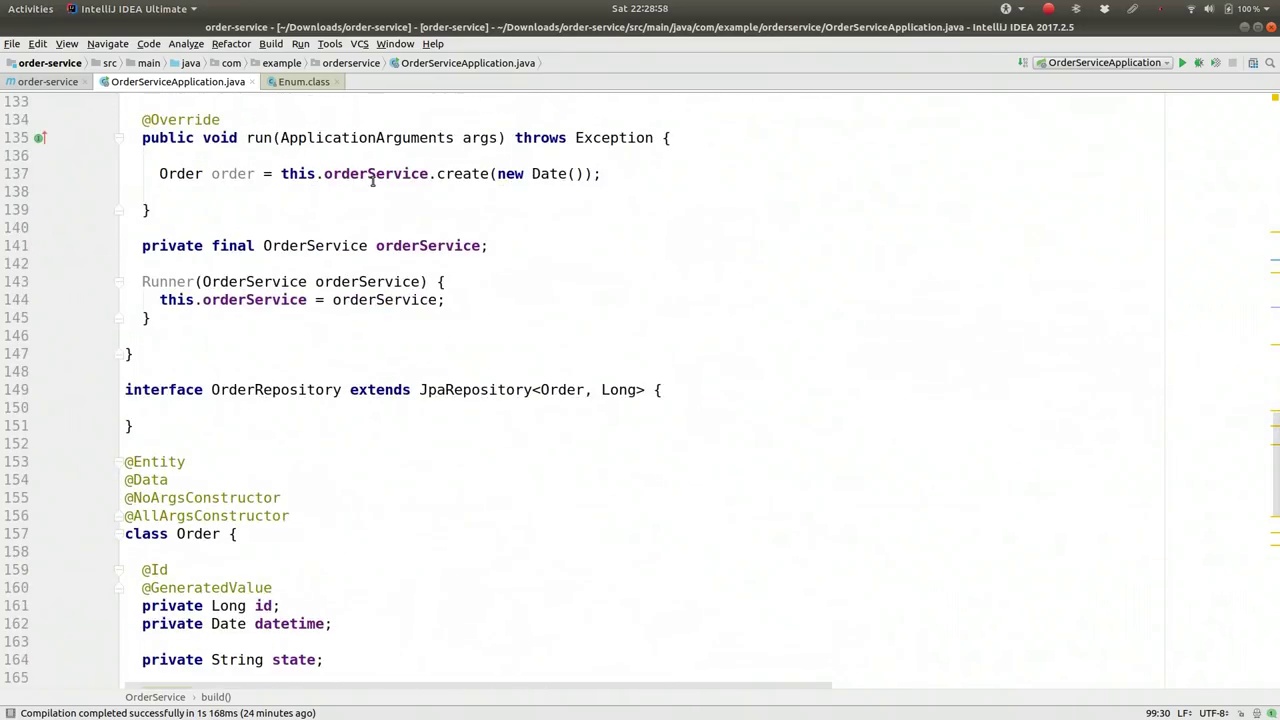
00:53:15-00:55:17
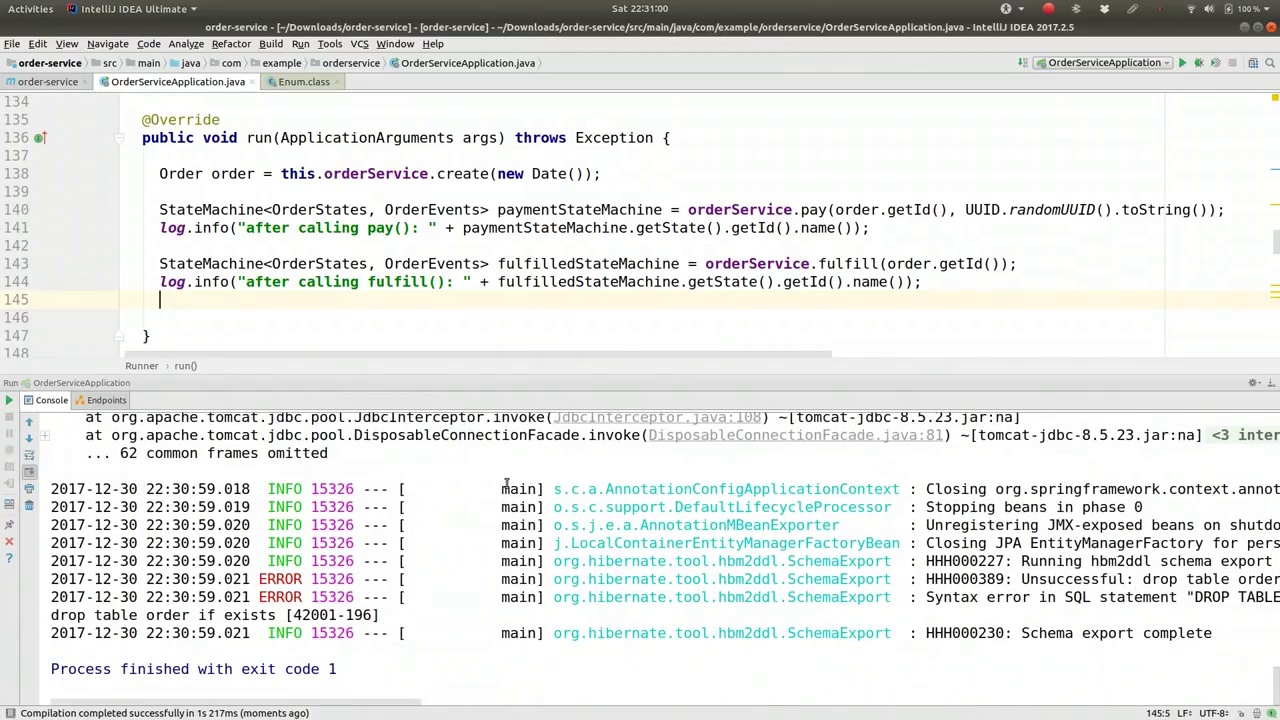
All right, so we've got our order service. Let's use this in our runner here. Where's our runner? Here we go. So order, and then in the order, we're going to send a few messages, I guess. So we'll use the order service. We're going to say, we've created a new one. Let's fulfill it now. So order.getId, all right. Oh, no, we want to pay for it first, right? So pay, and we'll have the, whatever. UUID.random.toString, okay? So there's our toString. Now, if we wanted to, we can actually look at the state machine for this. That's why we returned it. So payment state machine, and we'll say payment.stateMachine.getEvent, getState rather, .getId.name, log that out. After calling pay, okay. Goodie. So there's that. And we're going to have another one here called fulfilled. So I'm going to say fulfill. And we know that's not going to need that second parameter, so we'll use that after calling fulfill. And I suppose we should actually have this up here as well. After calling create, let's poke at the state right after it's been created. So, and in this case, we don't actually have it. So maybe we should have returned it there, right? We could have actually had the state machine being returned there. But for now, it's fine. Let's just leave it like that. Okay, so after calling fulfill, we can look at the current state as well. All right? Fulfilled. Fulfilled. State. Machine. All right. Go.
好的,我们有了订单服务。让我们在运行器中使用它。我们的运行器在哪里?找到了。所以,订单,然后在订单中,我们打算发送一些消息,我想。所以我们将使用订单服务。我们要说,我们已经创建了一个新的订单。现在让我们履行它。所以,order.getId,好的。哦,不,我们想先支付,对吧?所以支付,我们将使用,无论什么。UUID.random.toString,好的?这就是我们的toString方法。现在,如果我们愿意,我们实际上可以查看这个状态机。这就是我们返回它的原因。所以支付状态机,我们将说payment.stateMachine.getEvent,更确切地说,是getState,.getId.name,并将其记录下来。在调用pay之后,好的。很好。就这样。然后我们在这里还会有另一个叫做fulfilled的操作。所以我要说fulfill。我们知道这不需要第二个参数,所以我们在调用fulfill之后使用它。我想我们还应该在这里也这样做。在调用create之后,让我们在它刚被创建后查看状态。所以,在这种情况下,我们实际上没有它。所以也许我们应该在那里返回它,对吧?我们实际上可以在那里返回状态机。但现在,这样就可以了。我们就这样保留它。好的,所以在调用fulfill之后,我们也可以查看当前状态。对吧?Fulfilled。Fulfilled。State。Machine。好的。开始。
精炼总结 1. 使用订单服务创建并处理订单。-
订单处理包括创建、支付和履行步骤。
-
使用UUID生成支付信息。
-
通过状态机监控订单状态,包括支付和履行状态。
-
在订单创建后和履行后查看状态机状态。
参考回答:通过使用UUID.random.toString方法生成唯一的支付信息。
- 问题:在订单履行后,如何确认订单状态已经更新为“Fulfilled”?
参考回答:通过调用状态机的getState方法,并检查返回的状态是否为“Fulfilled”。
批判性思考 - 原文中提到使用UUID生成支付信息,虽然UUID可以确保唯一性,但在实际应用中,需要考虑UUID生成的性能开销和安全性问题。例如,频繁生成UUID可能会影响系统性能,且UUID的随机性是否足够强以防止被猜测也是一个需要考虑的问题。- 状态机的使用虽然可以有效监控订单状态,但也增加了系统的复杂性。在小型或简单系统中,状态机可能不是最优选择,需要权衡其带来的好处与增加的复杂性。此外,状态机的状态转换逻辑需要严格设计,以防止出现不一致或错误的状态转换。
00:55:17-00:55:20
请输入您需要翻译的英文段落,我将为您提供准确、地道的中文翻译。
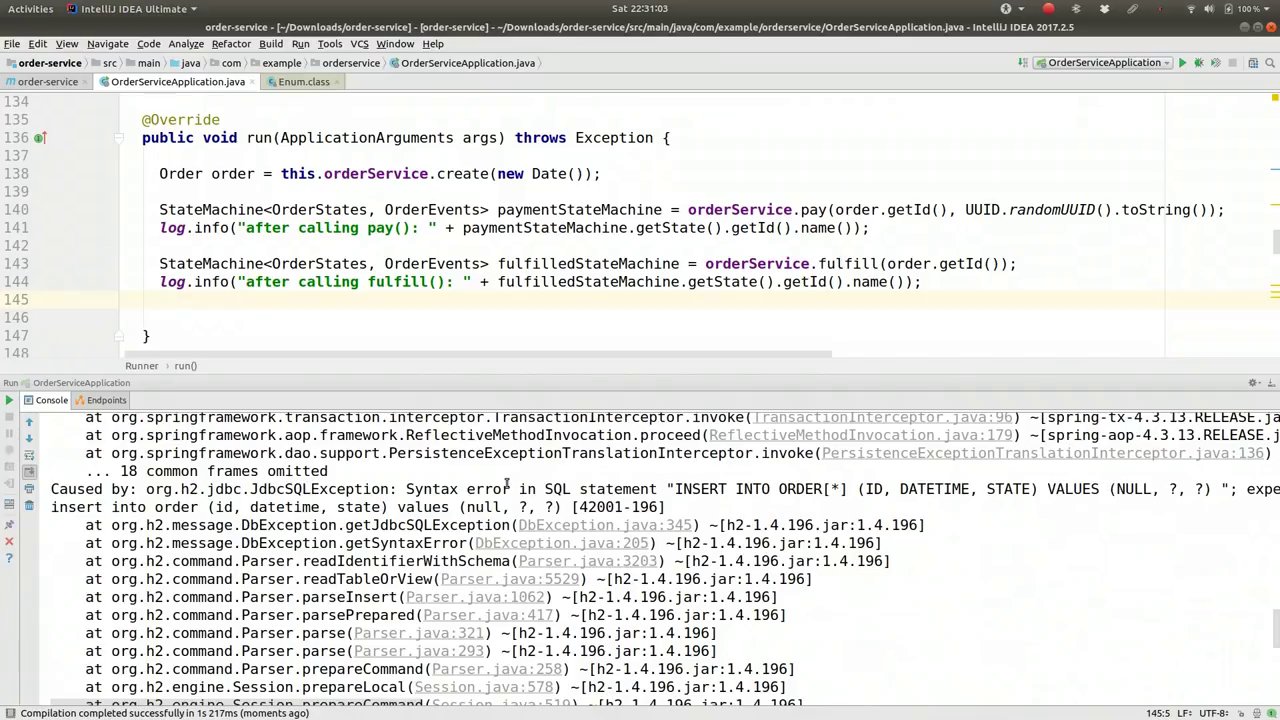
00:55:20-00:55:50
So what did we do wrong? Insert into order, a simple newbie error. Order is a reserved keyword in SQL, and I should have known that. So let's just change the JPA entity. Where is our JPA entity? It's down here. All right, name equals orders. Sure, good. Let's try again.
那么我们错在哪里呢?在SQL语句中使用了“order”,这是一个新手常犯的简单错误。在SQL中,“order”是保留关键字,我本应知道这一点。所以,我们只需修改JPA实体。我们的JPA实体在哪里?就在这里。好的,名称改为“orders”。没错,很好。我们再试一次。
精炼总结 1. 在SQL语句中错误地使用了保留关键字“order”。-
需要修改JPA实体以避免使用保留关键字。
-
修改后的JPA实体名称改为“orders”。
参考回答:因为在SQL中,保留关键字具有特定的含义和功能,用作标识符会导致语法错误或混淆。
- 问题:修改JPA实体名称时,除了避免使用保留关键字,还有哪些注意事项?
参考回答:修改JPA实体名称时,需要确保新的名称在数据库中唯一且符合命名规范,同时要更新所有相关的查询和代码以适应新的名称。
批判性思考 - 虽然避免使用保留关键字是SQL编程的基本原则,但在实际应用中,开发人员可能会因为疏忽或不熟悉而犯错。这提示我们需要在开发过程中加强代码审查和测试,以确保代码的正确性。- 另一方面,SQL标准和数据库管理系统可能会有不同的保留关键字列表,这增加了开发人员需要记忆和注意的内容。因此,提供一个全面的保留关键字列表和相应的开发工具支持,可以帮助减少这类错误的发生。
00:55:50-00:55:52
请输入您需要翻译的英文段落,我将为您提供准确、地道的中文翻译。
00:55:52-00:56:44
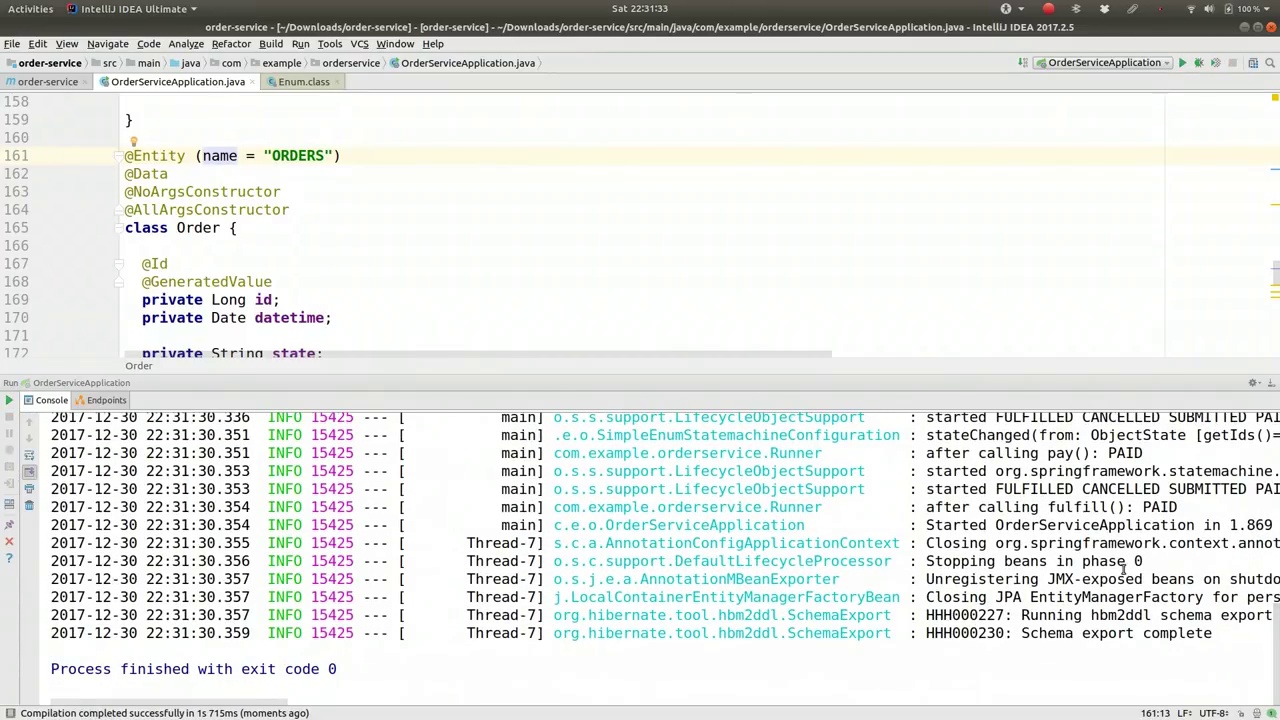
All right, let's review what we have. So, starting the state machine, it began with these four states. The state transitioned from submitted to paid, correct? This is somewhat confusing. Perhaps it's clearer to refer to the logs below. After invoking the pay method, the state is now paid. This is the current state. After invoking the fulfill method, did I send the incorrect event? Currently, the logs indicate that the fulfill event was sent. In the fulfill method, we must ensure to send the correct event. Otherwise, the system will remain in the previous state, specifically the paid state.
好的,我们来回顾一下现有的情况。首先,状态机从这四个状态开始。状态从“已提交”转变为“已支付”,对吗?这有点令人困惑。或许参考下面的日志会更清楚。调用支付方法后,状态现在是“已支付”。这是当前状态。调用履行方法后,我是否发送了错误的事件?目前日志显示已发送履行事件。在履行方法中,我们必须确保发送正确的事件,否则系统将保持在之前的状态,即“已支付”状态。
精炼总结 1. 状态机初始状态为“已提交”。-
支付方法调用后,状态变为“已支付”。
-
履行方法调用后,日志显示已发送履行事件。
-
履行方法中需确保发送正确事件,以避免系统停留在“已支付”状态。
参考回答:状态从“已提交”变为“已支付”。
- 问题:在履行方法中,为什么必须确保发送正确的事件?
参考回答:因为如果不发送正确的事件,系统将保持在之前的“已支付”状态,无法继续进行后续的状态转换。
批判性思考 - 原文中提到状态从“已提交”转变为“已支付”时,使用了“对吗?”这样的疑问句,这可能表明作者对状态转换的逻辑或实现存在疑虑。这提示我们需要进一步验证状态转换的逻辑是否正确,以及是否存在潜在的错误或遗漏。- 在履行方法中,强调了必须发送正确的事件以避免系统停留在“已支付”状态。这表明系统的状态管理依赖于事件的正确性。我们可以进一步探讨如果事件发送错误,系统是否有相应的错误处理机制,以及如何确保事件的正确性。
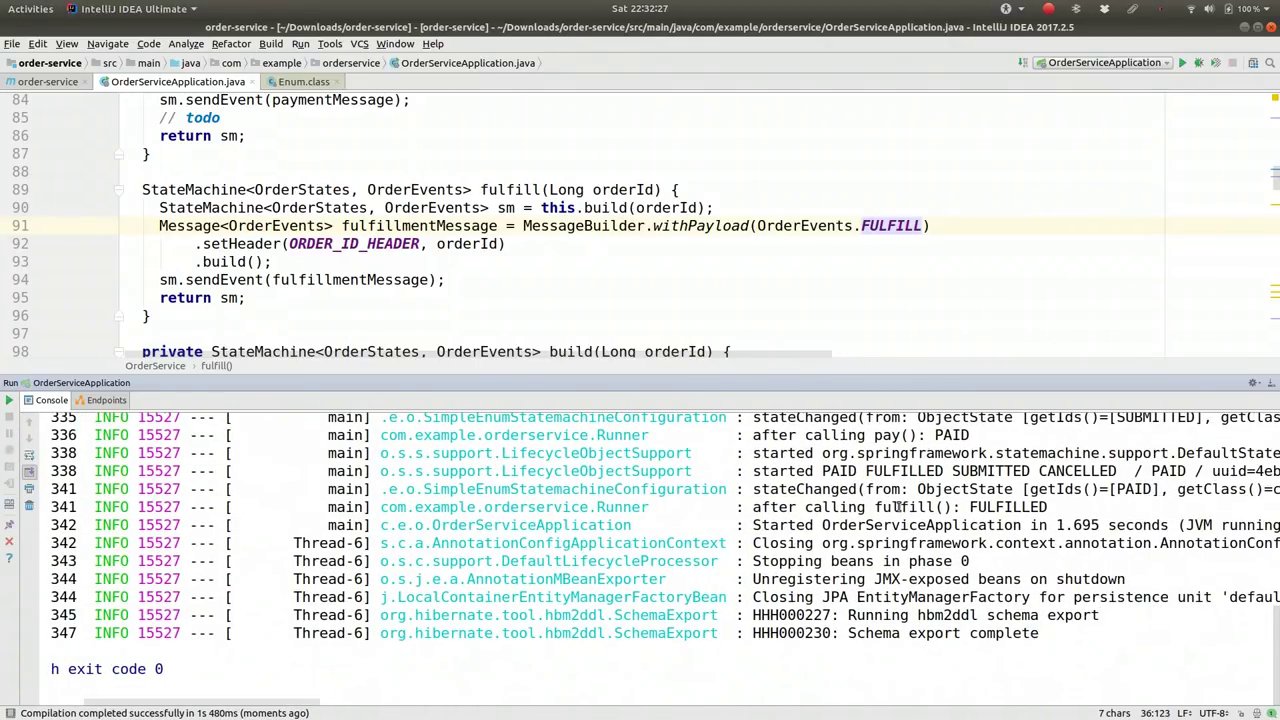
00:56:44-00:57:21
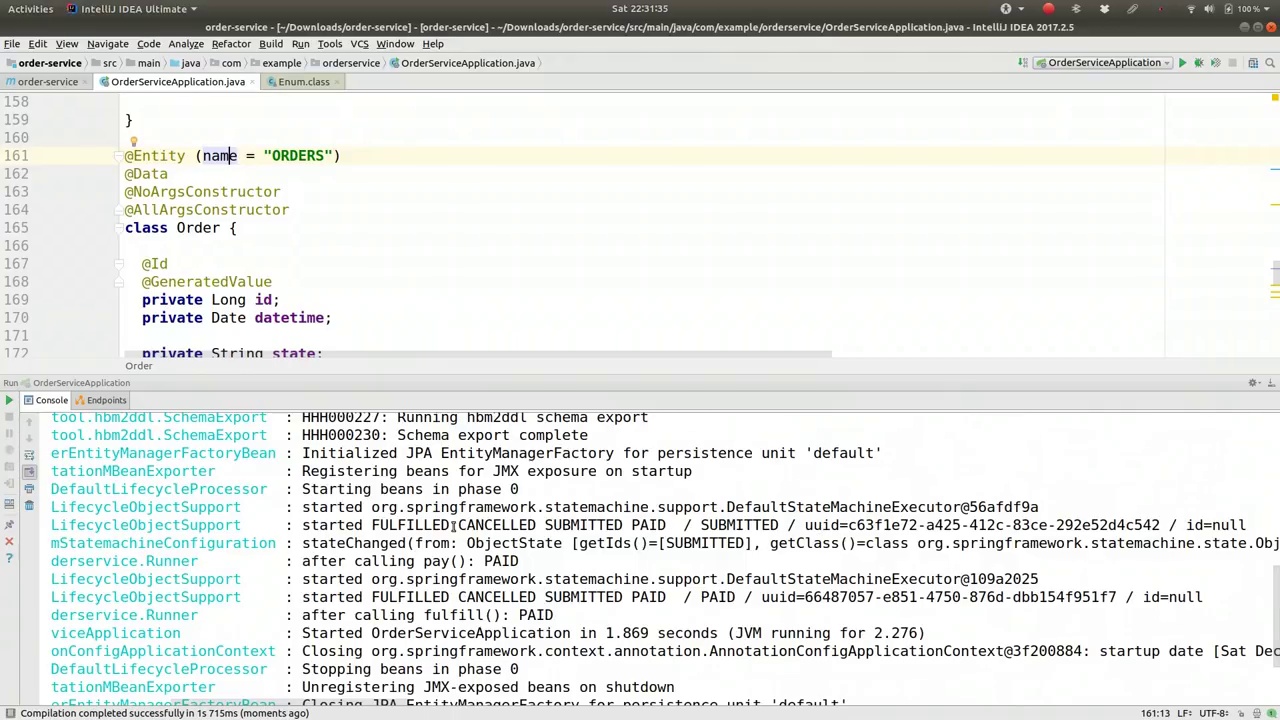
After calling fulfill, the result was that it was fulfilled. After calling pay, the state machine indicates that it's paid. We can confirm this by examining the object at each step and looking at the order itself. Let's do that. Where's my runner? We're going to look up the record as well. This time, we could have a method that just returns the order itself. Let's go to the order service here.
在调用fulfill之后,结果显示订单已履行。调用pay后,状态机指示订单已支付。我们可以通过检查每一步的对象和查看订单本身来确认这一点。让我们来这样做。我的执行者在哪?我们也要查找记录。这次,我们可以有一个方法直接返回订单本身。让我们转到这里的订单服务。
精炼总结 1. 调用fulfill后,订单状态显示为已履行。-
调用pay后,状态机显示订单已支付。
-
通过检查对象和订单本身来确认状态。
-
需要查找执行者和相关记录。
-
提供一个方法直接返回订单本身。
-
转向订单服务进行进一步操作。
参考回答:通过检查每一步的对象和查看订单本身来确认订单状态。
- 问题:在查找执行者和记录时,有哪些具体步骤或方法?
参考回答:需要查找执行者的位置,并查找相关的记录,可能包括日志或其他数据记录。
批判性思考 - 原文中提到的“通过检查每一步的对象和查看订单本身来确认这一点”可能存在一定的主观性,因为不同的检查方法可能会得出不同的结论。可以考虑引入自动化测试或标准化的检查流程来提高确认的准确性和一致性。- 提到“提供一个方法直接返回订单本身”,这虽然提高了操作的便捷性,但也可能增加了系统的复杂性和潜在的安全风险。需要评估这种方法对系统整体稳定性和安全性的影响,并考虑是否有更优化的解决方案。
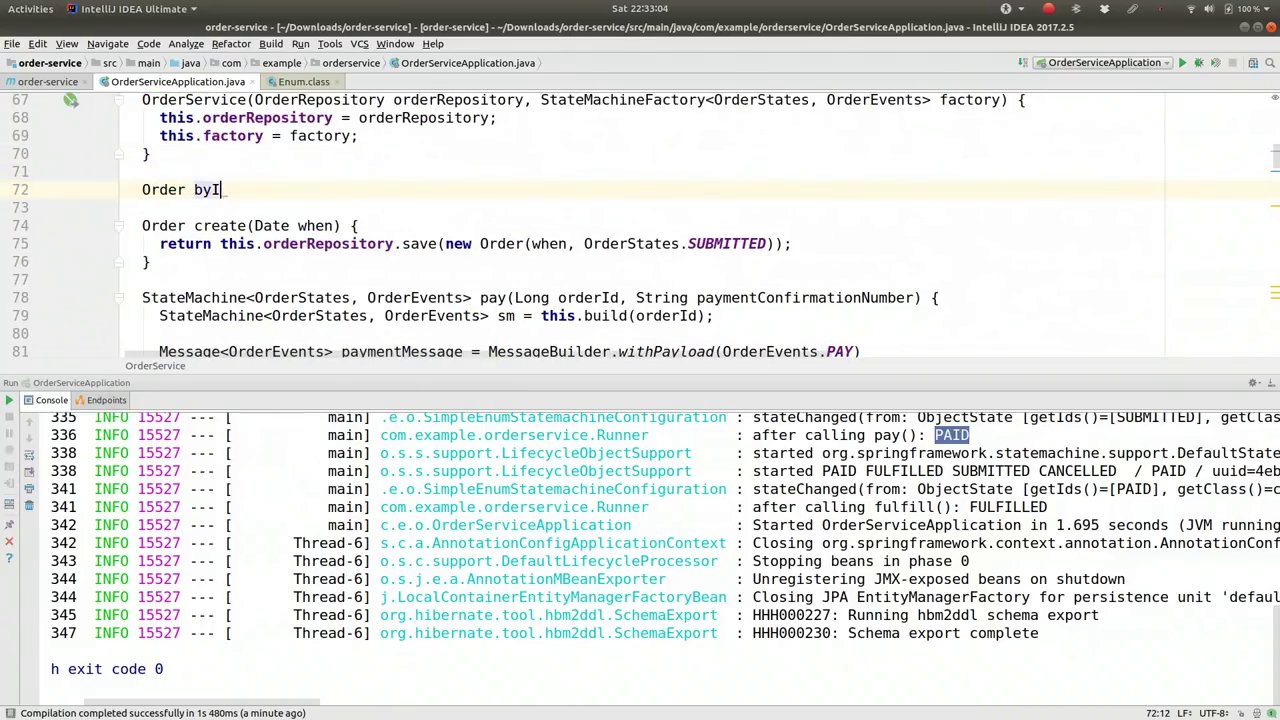
00:57:21-00:58:04
And looks at the order. Order by ID, long ID, all right? So this.findById, and we'll print that out, okay? So the last two methods return the state machine, but not the order. But we just want to poke at it, we just want to see what's happening, just to prove everything's working as we expect. Here, we'll actually say, logging.info, order will be equal to orderService.findById, passing in the order.getID. And this line, of course, we can duplicate down here as well. Run the code again.
然后查看订单。按ID排序,长ID,对吧?所以这里用.findById,我们会打印出来,好吗?最后两个方法返回状态机,而不是订单。但我们只是想检查一下,只是想看看发生了什么,只是为了证明一切都在按我们的预期工作。这里,我们实际上会说,logging.info,订单将等于orderService.findById,传入order.getID。当然,这一行,我们也可以复制到这里。再次运行代码。
-
最后两个方法返回状态机而非订单。
-
使用
logging.info记录订单信息,通过orderService.findById和order.getID实现。
- 参考回答:可能是因为这些方法的设计目的是为了获取订单的处理状态或流程状态,而不是订单的详细信息。
logging.info在这一段代码中的作用是什么?
- 参考回答:
logging.info用于记录订单的详细信息,帮助开发者或系统管理员监控和调试系统,确保订单处理按预期进行。
- 方法返回状态机而非订单可能是为了简化某些操作或提高系统效率,但这也可能导致信息不完整或难以追踪订单的详细状态。需要权衡返回状态机和订单的利弊,确保系统设计的合理性和用户需求的满足。
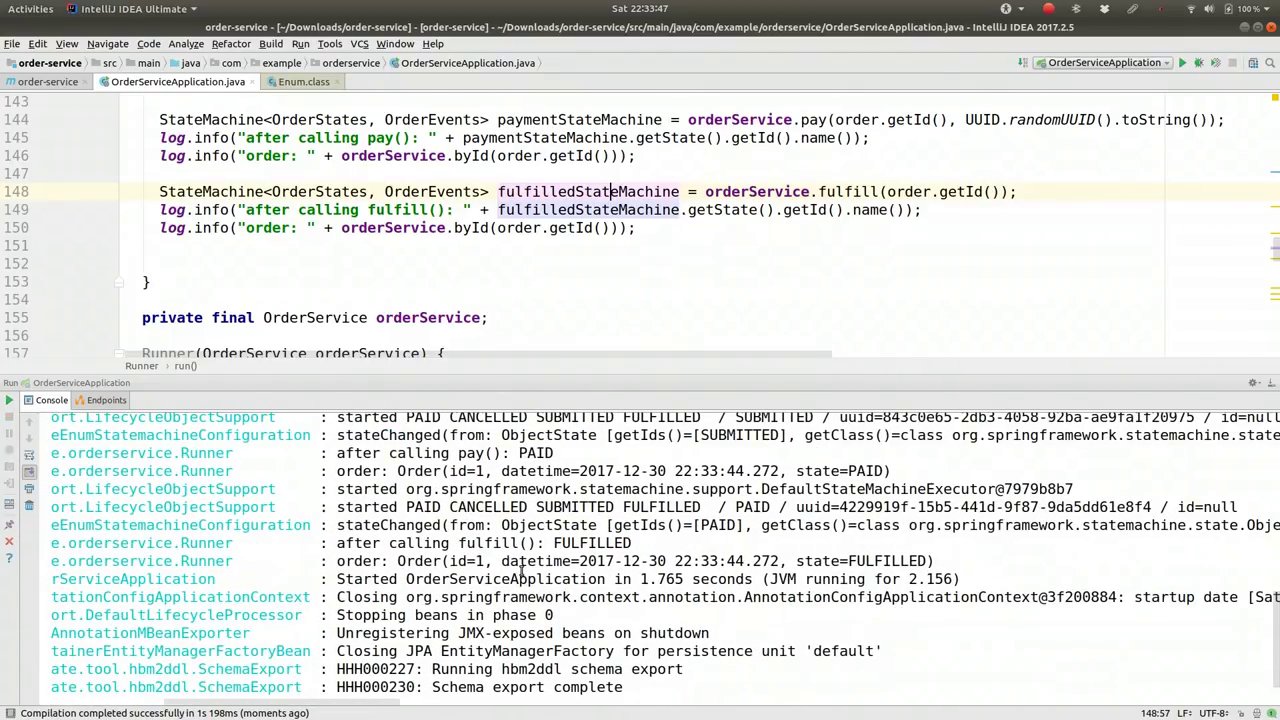
00:58:04-00:58:23
What did we get? So the order is equal to fulfilled, the state is equal to fulfilled, and the state is equal to paid. You can see it's synchronizing the changes back and forth. Alright, so we've just looked at a very brief introduction to Spring State Machine.
我们得到了什么?订单状态等于已完成,状态等于已完成,并且状态等于已支付。你可以看到它在来回同步这些变化。好了,我们刚刚看了一个非常简短的Spring状态机的介绍。
00:58:23-00:59:10
There are numerous possibilities in this area. A new product called Spring Cloud Skipper, which I plan to discuss in a future installment of Spring Tips, is designed for deploying and managing the lifecycle, including state transitions, of complex applications in cloud environments such as Cloud Foundry or Kubernetes. It requires a directed graph. For instance, when deploying an application, it may proceed smoothly or necessitate a rollback. Such scenarios are currently hard-coded, but we believe they would be well-suited for integration with Spring State Machine. This remains uncertain. Spring State Machine can be beneficial wherever you need to separately describe the graph. I have written a considerable amount of code in this context, but at the
这个领域有无数的可能性。我计划在未来的Spring Tips系列中讨论的一个新产品是Spring Cloud Skipper,它旨在云环境(如Cloud Foundry或Kubernetes)中部署和管理复杂应用程序的生命周期,包括状态转换。它需要一个有向图。例如,在部署应用程序时,它可能顺利进行,也可能需要回滚。这类场景目前是硬编码的,但我们认为它们非常适合与Spring State Machine集成。这一点尚未确定。无论何时你需要单独描述图表,Spring State Machine都能发挥作用。在这个背景下,我已经编写了相当多的代码,但在
精炼总结 1. **新产品介绍**:Spring Cloud Skipper,用于在云环境中部署和管理复杂应用的生命周期。-
功能特点:支持状态转换,需要有向图来管理部署过程中的顺利进行或回滚。
-
集成可能性:考虑与Spring State Machine集成,以更好地处理状态转换场景。
-
当前状态:相关功能尚未完全确定,但已开始编写代码。
参考回答:Spring Cloud Skipper主要解决在云环境中部署和管理复杂应用程序的生命周期问题,特别是状态转换的管理。
- 问题:为什么作者认为Spring State Machine适合与Spring Cloud Skipper集成?
参考回答:作者认为Spring State Machine适合集成,因为它能够有效地处理状态转换场景,特别是在需要单独描述图表的情况下。
批判性思考 1. **技术选择的合理性**:虽然Spring Cloud Skipper和Spring State Machine的集成听起来很有前景,但需要考虑这种集成是否真的能提高效率和降低复杂性,还是仅仅增加了系统的复杂度。-
实施的可行性:尽管已经开始了代码编写,但集成Spring State Machine的具体实施细节和潜在挑战尚未明确。需要进一步评估这种集成在实际应用中的可行性和效果。
-
用户需求与市场适应性:在推广新产品时,需要考虑目标用户群体的实际需求和市场适应性。是否所有用户都需要这种复杂的状态管理功能,或者是否有更简单、更直接的解决方案能够满足大部分用户的需求。
00:59:10-00:59:35
At the top level, what we care about is the fact that these are just well-known transitions and they're predictable. You can interrogate it, you can print it out, you can store it, you can do all these things with it. And you have a common way of discussing these state transitions. This aligns your code with what the business is trying to achieve. So with that, my friends, thanks so much for watching and we'll see you next time.
在最高层面上,我们关注的是这些状态转换是众所周知的且可预测的。你可以对其进行查询、打印、存储,可以对其进行各种操作。而且,我们有一种共同的方式来讨论这些状态转换。这使得你的代码与业务目标保持一致。那么,朋友们,非常感谢大家的观看,我们下次再见。
精炼总结 1. 状态转换是众所周知的且可预测的。-
状态转换可以进行查询、打印、存储和各种操作。
-
存在一种共同的方式来讨论这些状态转换,有助于代码与业务目标保持一致。
参考回答:因为这样可以确保系统的稳定性和可靠性,使得开发和维护人员能够准确理解和预测系统行为,从而更有效地进行开发和故障排除。
- 问题:共同的方式讨论状态转换如何帮助代码与业务目标保持一致?
参考回答:通过统一的讨论方式,团队成员可以更清晰地理解业务需求和系统状态之间的关系,确保代码实现与业务目标相符,减少误解和偏差。
批判性思考 - 虽然强调状态转换的可预测性和共同讨论方式有助于代码与业务目标的一致性,但这种一致性也可能导致过度标准化,限制了创新和灵活性。在实际应用中,可能需要权衡一致性与创新之间的关系,以适应不断变化的业务需求和技术发展。- 此外,过分依赖共同讨论方式可能会导致对特定领域知识的忽视,因为这种方式可能无法完全覆盖所有复杂和特殊的情况。因此,在实践中,还需要结合专业知识和经验,以确保系统的全面性和适应性。

00:59:35-00:59:45
请提供需要翻译的英文段落,我将为您提供准确、地道的中文翻译。
标签:状态,00,Statemachine,Spring,状态机,订单,state,Tips,ID From: https://www.cnblogs.com/wzqshb/p/18288858