1. 网络爬虫技能总览图
如图2-1所示,我们总结了网络爬虫的常用功能。
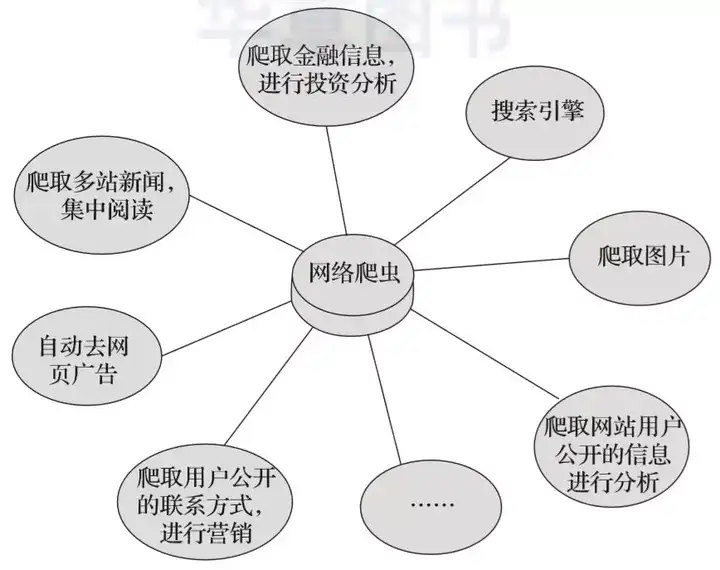
▲图2-1 网络爬虫技能示意图
在图2-1中可以看到,网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这些新闻网站进行浏览,比较麻烦。此时可以利用网络爬虫,将这多个新闻网站中的新闻信息爬取下来,集中进行阅读。
有时,我们在浏览网页上的信息的时候,会发现有很多广告。此时同样可以利用爬虫将对应网页上的信息爬取过来,这样就可以自动的过滤掉这些广告,方便对信息的阅读与使用。
有时,我们需要进行营销,那么如何找到目标客户以及目标客户的联系方式是一个关键问题。我们可以手动地在互联网中寻找,但是这样的效率会很低。此时,我们利用爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方式等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行分析,比如分析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时,可以利用爬虫轻松将这些数据采集到,以便进行进一步分析,而这一切爬取的操作,都是自动进行的,我们只需要编写好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现很多强大的功能。总之,爬虫的出现,可以在一定程度上代替手工访问网页,从而,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。

2. 搜索引擎核心
爬虫与搜索引擎的关系是密不可分的,既然提到了网络爬虫,就免不了提到搜索引擎,在此,我们将对搜索引擎的核心技术进行一个简单的讲解。
图2-2所示为搜索引擎的核心工作流程。首先,搜索引擎会利用爬虫模块去爬取互联网中的网页,然后将爬取到的网页存储在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并存储到索引数据库中。
当用户检索信息的时候,会通过用户交互接口输入对应的信息,用户交互接口相当于搜索引擎的输入框,输入完成之后,由检索器进行分词等操作,检索器会从索引数据库中获取数据进行相应的检索处理。
用户输入对应信息的同时,会将用户的行为存储到用户日志数据库中,比如用户的IP地址、用户所输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志分析器会根据大量的用户数据去调整原始数据库和索引数据库,改变排名结果或进行其他操作。
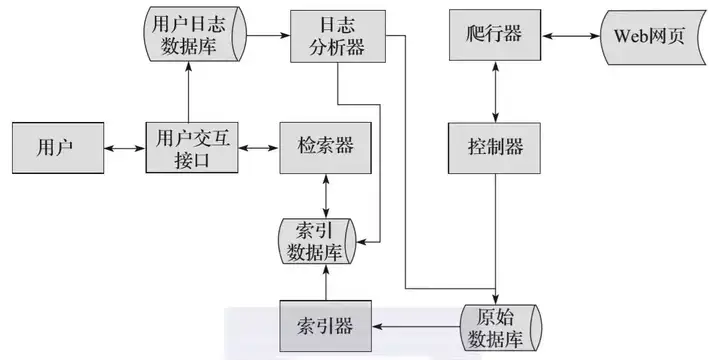
▲图2-2 搜索引擎的核心工作流程
以上就是搜索引擎核心工作流程的简要概述,可能大家对索引和检索的概念还不太能区分,在此我为大家详细讲一下。
简单来说,检索是一种行为,而索引是一种属性。比如一家超市,里面有大量的商品,为了能够快速地找到这些商品,我们会将这些商品进行分组,比如有日常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
如果,有一个用户想要找到某一个商品,那么需要在超市的大量商品中寻找,这个过程,我们称之为检索。如果有一个好的索引,则可以提高检索的效率;若没有索引,则检索的效率会很低。
比如,一个超市里面的商品如果没有进行分类,那么用户要在海量的商品中寻找某一种商品,则会比较费力。
3. 用户爬虫的那些事儿
用户爬虫是网络爬虫中的一种类型。所谓用户爬虫,指的是专门用来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的利用价值也相对较高。
利用用户爬虫可以做大量的事情,接下来我们一起来看一下利用用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据进行了爬取,然后进行对应的数据分析,便得到了知乎上大量的潜在数据,比如:
- 知乎上注册用户的男女比例:男生占例多于60%。
- 知乎上注册用户的地区:北京的人口占据比重最大,多于30%。
- 知乎上注册用户从事的行业:从事互联网行业的用户占据比重最大,同样多于30%。
除此之外,只要我们细心发掘,还可以挖掘出更多的潜在数据,而要分析这些数据,则必须要获取到这些用户数据,此时,我们可以使用网络爬虫技术轻松爬取到这些有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,比如:
- QQ空间用户发说说的时间规律:晚上22点左右,平均发说说的数量是一天中最多的时候。
- QQ空间用户的出生月份分布:1月份和10月份出生的用户较多。
- QQ空间用户的年龄阶段分布:出生于1990年到1995年的用户相对来说较多。
- QQ空间用户的性别分布:男生占比多于50%,女生占比多于30%,未填性别的占10%左右。
除了以上两个例子之外,用户爬虫还可以做很多事情,比如爬取淘宝的用户信息,可以分析淘宝用户喜欢什么商品,从而更有利于我们对商品的定位等。
由此可见,利用用户爬虫可以获得很多有趣的潜在信息,那么这些爬虫难吗?其实不难,相信你也能写出这样的爬虫。

03 小结
- 网络爬虫也叫作网络蜘蛛、网络蚂蚁、网络机器人等,可以自动地浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则去浏览,这些规则我们将其称为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
- 学习爬虫,可以:①私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理,进行更深层次地理解;②为大数据分析提供更多高质量的数据源;③更好地研究搜索引擎优化;④解决就业或跳槽的问题。
- 网络爬虫由控制节点、爬虫节点、资源库构成。
- 网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。在实际的网络爬虫中,通常是这几类爬虫的组合体。
- 聚焦网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。
- 爬虫的出现,可以在一定程度上代替手工访问网页,所以,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。
- 检索是一种行为,而索引是一种属性。如果有一个好的索引,则可以提高检索的效率,若没有索引,则检索的效率会很低。
- 用户爬虫是网络爬虫的其中一种类型。所谓用户爬虫,即专门用来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的利用价值也相对较高。
转自:什么是网络爬虫?有什么用?怎么爬?终于有人讲明白了 - 知乎 (zhihu.com)
标签:4.11,用户,网络,爬虫,爬取,索引,搜索引擎 From: https://www.cnblogs.com/binglinll/p/18255065