stable diffusion是一种潜在扩散模型,可以从文本生成人工智能图像。为什么叫做潜在扩散模型呢?这是因为与在高维图像空间中操作不同,它首先将图像压缩到潜在空间中,然后再进行操作。
在这篇文章中,我们将深入了解它到底是如何工作的,还能够知道文生图的工作方式与图生图的的工作方式有何不同?CFG scale是什么?去噪强度是什么?
了解stable diffusion工作原理的好处: 可以更加正确的使用这个工具,从而实现更加可控的结果。
stable diffusion有什么用处?
简单来说,稳定扩散是一种文本到图像的模型。给它一个文本提示,它会返回一个与文本匹配的AI图像。
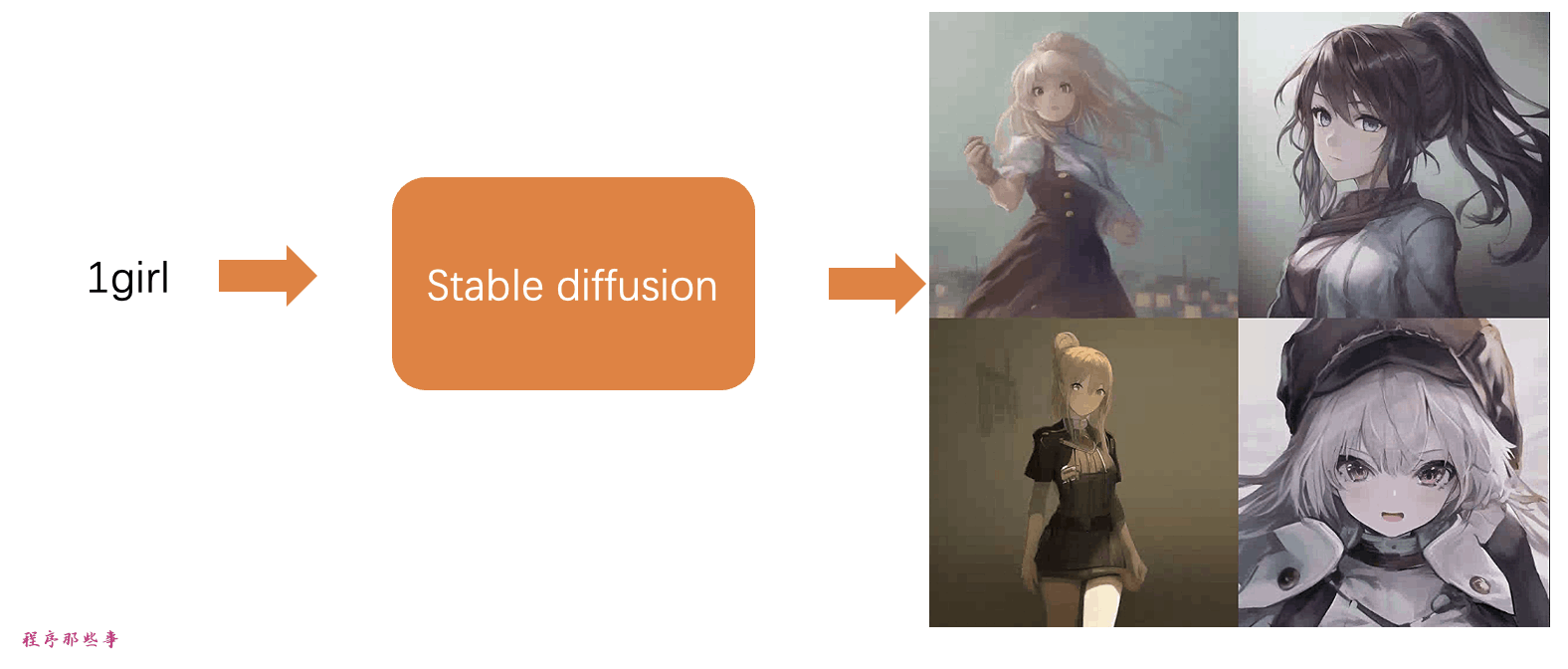
stable diffusion模型
稳定扩散属于一类称为扩散模型的深度学习模型。它们是生成模型,意味着它们被设计用来生成类似于训练数据的新数据。而在stable diffusion中下,这些数据就是图像。
那么为什么它被称为扩散模型?
因为它的实现原理看起来非常像物理学中的扩散。接下来让我们看看他的底层原理实现。这里我以最常见的1girl作为例子来说明。
正向扩散
在正向扩散过程中,会向训练图像添加噪音,逐渐将其转化为不具有特征的噪音图像。正向过程会将任何1girl的图像转变为噪音图像。最终,你将无法判断它们最初到底是什么。(这很重要)
就像一滴墨水落入了一杯水中。墨水滴在水中扩散开来。几分钟后,它会随机分布在整个水中。你再也无法判断它最初是落在中心还是靠近边缘。
下面是一个图像经历正向扩散的示例。1girl的图像变成了随机噪音。

逆向扩散
正向扩展很好理解,那么接下来就是神奇的部分,如果我们能够逆向扩散呢?就像倒放视频一样,倒退时间。
从一个嘈杂、毫无意义的图像开始,逆向扩散可以恢复出一张原始的1girl的图像。这就是主要的想法。
训练过程
逆扩散的概念肯定是有创意的。但是,现在的问题是,“怎样才能实现逆扩散呢?”
为了逆转扩散,最根本的是我们需要知道图像添加了多少噪音。
diffusion中使用了一个神经网络模型来预测添加的噪音。这就是稳定扩散中的噪音预测器。它是一个U-Net模型。训练过程如下。
-
选择一张训练图像,比如1girl的照片。
-
生成一个随机的噪音图像。
-
通过在训练的不同步数中添加一定的噪音图像来破坏训练图像。
-
通过调整噪音预测器的权重,来训练噪音预测器,从而告诉他,我们添加了多少噪音。

训练后,我们有了一个能够预估图像添加的噪音的噪音预测器。
逆扩散
现在我们有了噪声预测器。如何使用它呢?
首先,我们生成一个完全随机的图像,并要求噪声预测器告诉我们噪声。然后我们从原始图像中减去这个估计的噪声。重复这个过程几次。最终你会得到一张1girl的图像。
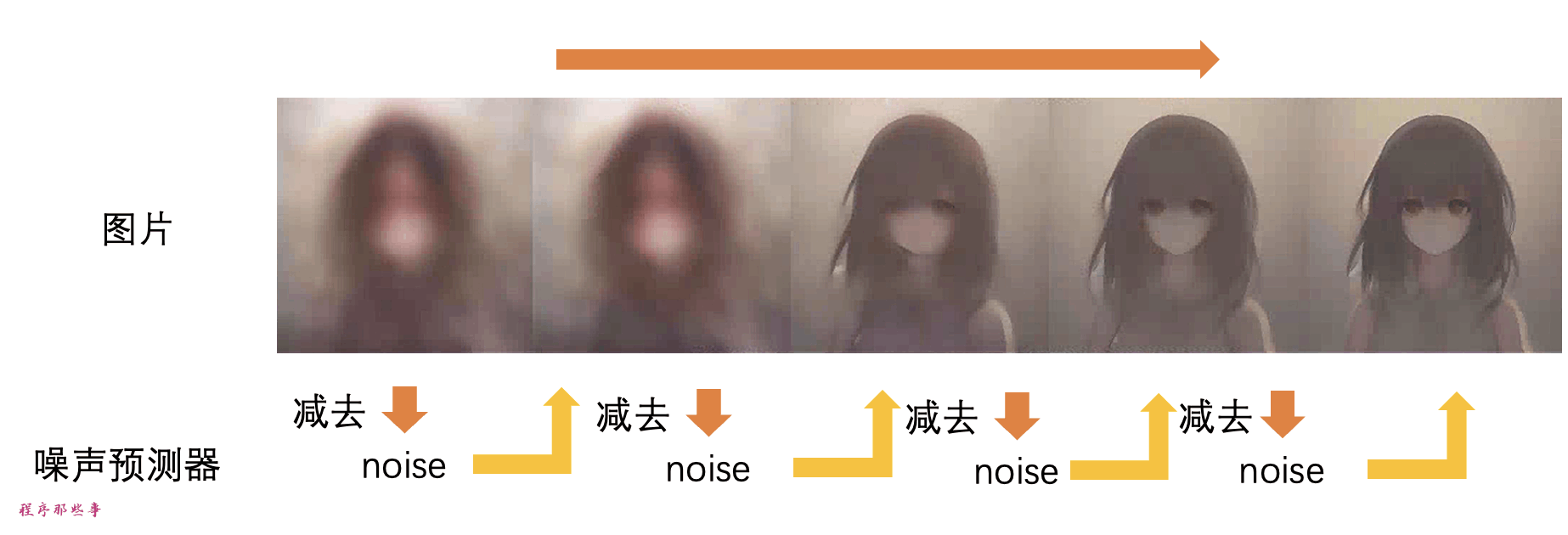
当然现在我们还无法控制生成的图像,现在这个过程完全是随机的。
稳定扩散模型Stable Diffusion model
上面讲了那么多原理,但是其实那并不是stable diffusion的工作原理!
原因是上述扩散过程是在图像空间进行的。因为图像空间非常的大,所以计算速度非常的慢。
举个例子:一个512×512像素的图像有三个颜色通道(红色、绿色和蓝色),就是一个786,432维的空间!(你需要为一个图像指定那么多数值。)这是一个非常大的数字,在现有的GPU硬件条件下,很难快速的生成需要的图片。
所以很多公司对这个像素空间的扩散模型做了优化,比如谷歌的Imagen和Open AI的DALL-E,它们使用了一些技巧来加快模型速度,但这样还是不够的。
潜在扩散模型Latent diffusion model
Stable diffuion中引入了一个叫做潜在扩散空间的概念,从而解决在像素空间的扩散模型计算速度慢的问题。下面是它的工作原理。
稳定扩散是一种潜在扩散模型。它不是在高维图像空间中运行,而是首先将图像压缩到潜在空间中。
以上面的512×512像素的图像为例,稳定扩散模型的潜在空间是4x64x64,这个潜在空间是原图像像素空间的1/48。
因为潜在空间只有之前的1/48,因此它能够在计算更少的数字的情况下获得结果。这就是为什么它更快的原因。
变分自动编码器VAE
从像素空间到潜在空间的变化,是通过一种称为变分自动编码器(variational autoencoder)的技术来实现的。是的,这就是我们经常看到的VAE。
变分自动编码器(VAE)是由两部分组成:(1)编码器和(2)解码器。编码器将图像压缩到潜在空间,解码器从潜在空间恢复图像。
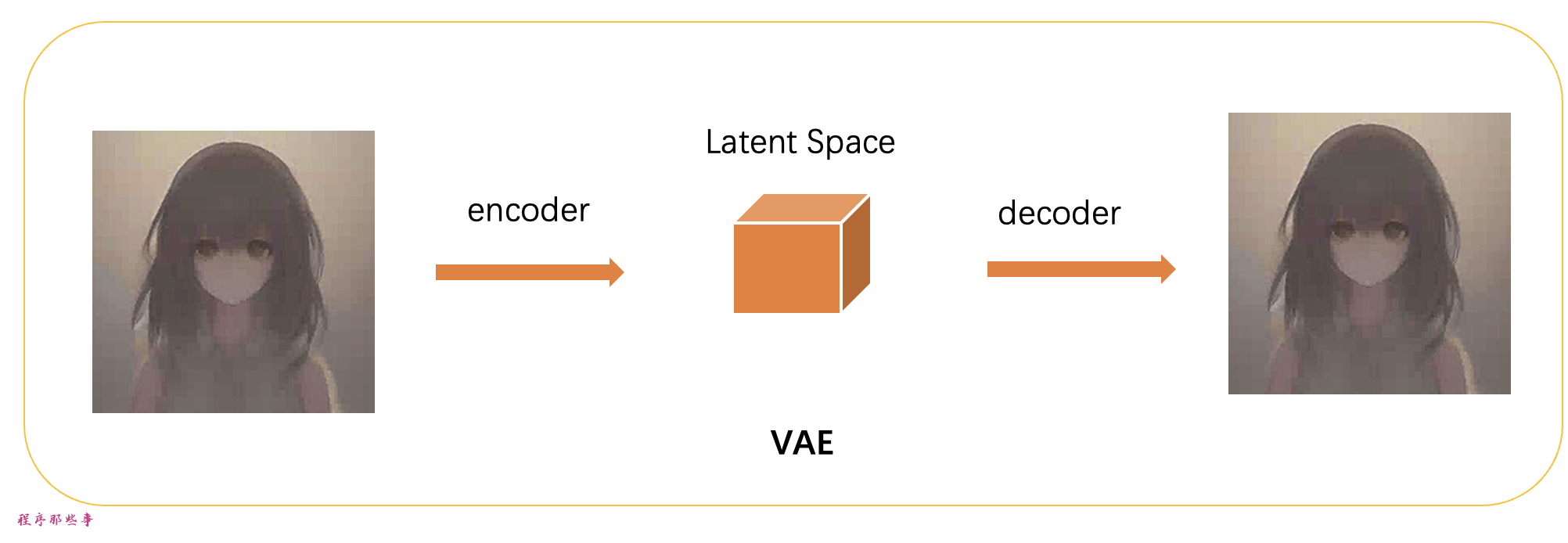
我们所说的所有前向和反向扩散实际上都是在潜在空间中进行的。因此,在训练过程中,它不是生成一个嘈杂的图像,而是在潜在空间中生成一个随机张量(潜在噪声)。它不是用噪音损坏图像,而是用潜在噪声损坏图像在潜在空间中的表示。这样做的原因是潜在空间较小,因此速度更快。
图像分辨率
图像分辨率反映在潜在图像张量的大小上。对于仅有512×512像素的图像,潜在图像的大小为4x64x64。对于768×512像素的肖像图像,潜在图像的大小为4x96x64。
这就是为什么生成更大的图像需要更长的时间和更多的VRAM。
这里想解释一下为什么我们在使用stable diffusion的时候,如果生成大于512×512像素的图像,有时候会出现双头的问题。
这是因为Stable Diffusion v1是在512×512像素图像上进行训练的。
图像放大
那么我们怎么才能生成分辨率更大的图片呢?最好的办法是保证图像至少有一边达到512像素,然后使用AI放大器或img2img的功能进行图像放大。
另外,可以使用SDXL模型。它具有更大的默认尺寸,为1024 x 1024像素。
为什么潜在空间可以工作?
你可能会想知道为什么变分自动编码器(VAE)可以将图像压缩成一个更小的潜在空间而不丢失信息。
原因是,自然图像并不是随机的,它们具有很高的规律性:一张脸遵循着眼睛、鼻子、脸颊和嘴巴之间特定的空间关系。一只狗有四条腿并且具有特定的形状。
换句话说,图像的高维度是人为的。自然图像可以很容易地压缩到更小的潜在空间而不丢失任何信息。这在机器学习中被称为流形假设。
潜在空间中的反向扩散
以下是stable diffusion中潜在空间反向扩散的工作原理。
-
生成一个随机潜在空间矩阵。
-
噪声预测器预测潜在矩阵的噪声。
-
然后从潜在矩阵中减去预测的噪声。
-
根据特定的采样步数,重复2,3这两步。
-
VAE的解码器将潜在矩阵转换为最终图像。
什么是VAE文件?
VAE文件是在Stable Diffusion v1中用于改进眼睛和脸部的生成效果。它们是我们刚刚谈到的自动编码器的解码器。通过进一步微调解码器,模型可以绘制出更精细的细节。
之前提到自然图像并不是随机的,它们具有很高的规律性,虽然是这样,但是将图像压缩到潜在空间确实会丢失信息,因为原始的VAE没有恢复细节。而这个VAE文件或者VAE解码器的作用就是负责绘制细节。
条件控制
到这里基本上运行流程已经差不多了,但是我们还缺了一部分:我们写的文本prompt是在哪里发挥作用的呢?
这些prompt实际上就是条件控制。条件控制的目的是引导噪声预测器,使得预测的噪声在从图像中减去后能够给我们想要的结果。
txt2img(文本到图像)
以下是对txt2img如何被处理并输入到噪声预测器的说明。
首先,分词器(Tokenizer)将提示中的每个单词转换为一个称为标记的数字。然后,每个标记被转换为一个名为嵌入embedding的768值向量。这些嵌入然后被文本变换器(text transformer)处理,并准备好被噪声预测器使用。
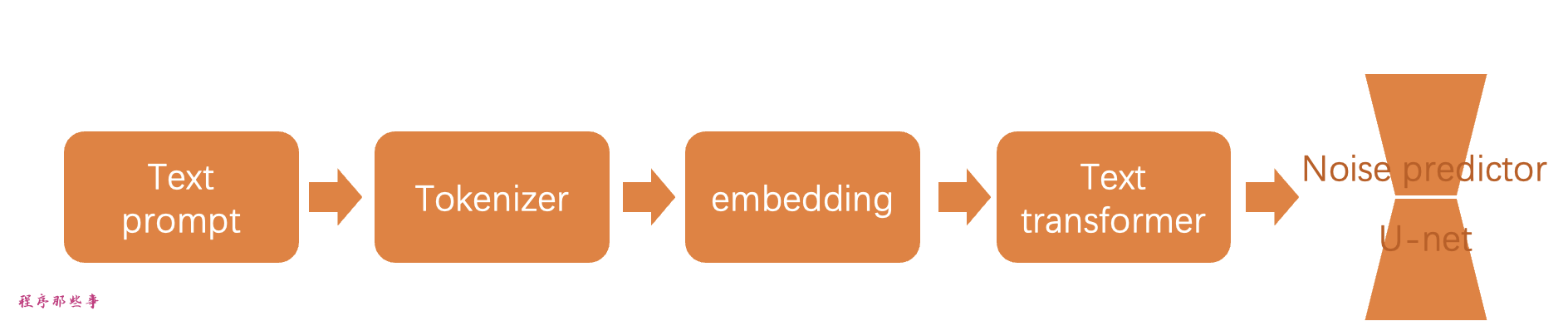
接下来,让我们详细介绍每一部分的含义。
分词器Tokenizer
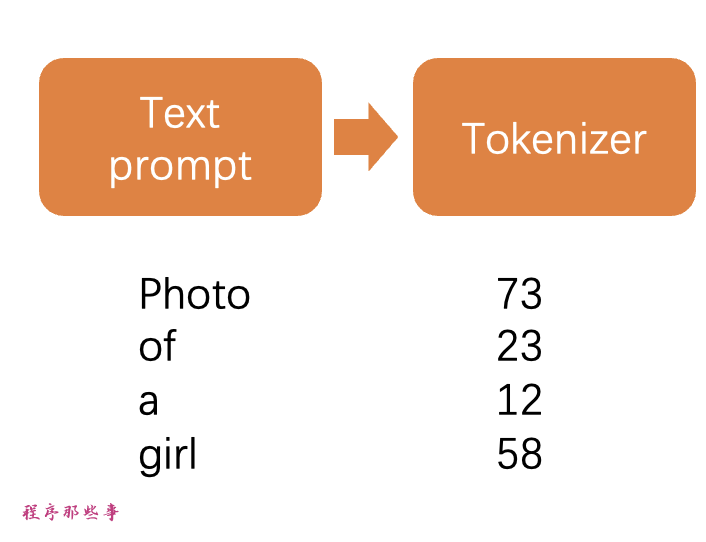
首先,文本提示被 CLIP 分词器进行分词。CLIP 是由 Open AI 开发的深度学习模型,用于生成任何图像的文本描述。Stable Diffusion v1 使用了 CLIP 的分词器。
分词是计算机理解单词的方法。我们人类可以读单词,但计算机只能读数字。这就是为什么文本提示中的单词首先被转换为数字的原因。分词器只能分词它在训练过程中见过的单词。例如,CLIP 模型中有“butter”和“fly”,但没有“butterfly”。分词器会将单词“butterfly”分解为两个标记“butter”和“fly”。所以一个单词并不总是意味着一个标记!
另一个细节是空格字符也是标记的一部分。在上面的情况中,短语“butter fly”产生了两个标记“butter”和“[space]fly”。这些标记与“butterfly”产生的不同,“butterfly”的标记是“butter”和“fly”(在“fly”之前没有空格)。
Stable Diffusion 模型在提示中仅限于使用75个标记。(这并不等同于75个单词)
嵌入embedding
Stable diffusion v1采用了Open AI的ViT-L/14 Clip模型。embedding嵌入是一个768值的向量。每个标记都有自己独特的嵌入向量。嵌入是由CLIP模型决定的,在训练过程中学习的。
为什么我们需要嵌入?因为一些词是密切相关的,我们希望能够充分利用这些信息。例如,man、gentleman和guy的嵌入几乎相同,因为它们可以互换使用。克劳德·莫奈、皮埃尔·奥古斯特·雷诺阿和爱德华·马奈都是印象派风格绘画的代表,但方式各有不同。所以这些名字在embedding中具有接近但不完全相同的值。
这就是我们讨论的用于通过关键词触发样式的嵌入。找到合适的嵌入可以触发任意对象和风格,这是一种称为文本反演(textual inversion)的微调技术。
embedding to noise predictor
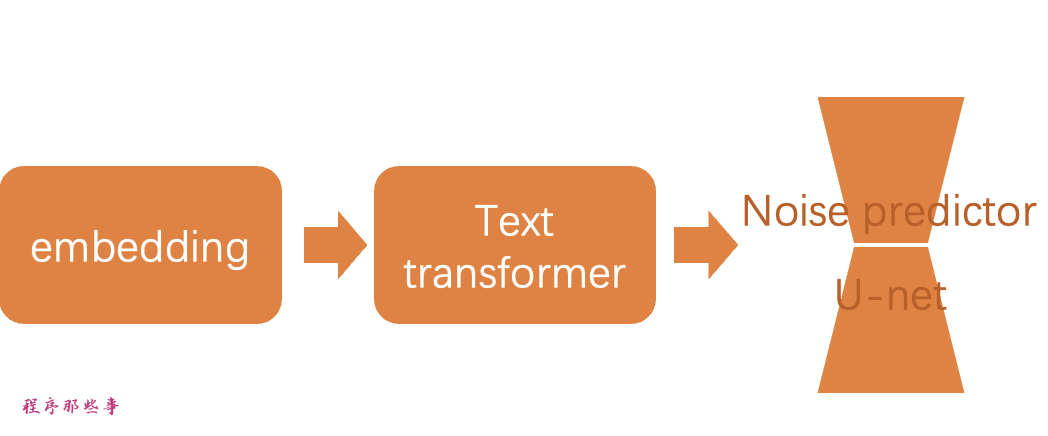
在发送到噪声预测器之前,嵌入需要通过文本转换器进行处理处理。
转换器就像一个通用适配器,用于条件处理。在这种情况下,它的输入是文本嵌入向量,但它也可以是其他东西,比如标签、图像和深度图。
注意力机制
在Stable Diffusion AI和类似的文本到图像生成模型中,U-Net是一个关键的组件,它负责将文本提示转换成图像。U-Net是一个深度学习模型,通常用于图像到图像的任务,如图像分割。在Stable Diffusion中,U-Net利用了一种称为“注意力机制”的技术来理解和处理文本提示。
- 自注意力 (Self-Attention):
- 自注意力允许模型在处理提示时识别单词之间的关系。比如一个蓝色眼睛的男人,“蓝”和“眼睛”通过自注意力机制被关联起来,这样模型就知道用户想要生成的是一个拥有蓝色眼睛的男人,而不是一个穿着蓝色衬衫的男人。
- 交叉注意力 (Cross-Attention):
- 交叉注意力是文本和图像之间的桥梁。在生成图像的过程中,U-Net使用交叉注意力机制来确保生成的图像与文本提示保持一致。这意味着模型会根据文本提示中的关键词生成相应的图像特征。
超网络是一种调整稳定扩散模型的技术,它利用交叉注意力网络来插入风格。
LoRA模型修改交叉注意力模块的权重来改变风格。
仅仅修改这个模块就能调整稳定扩散模型的结果,可见这个模块是多么重要。
还有其他控制条件吗?
稳定扩散模型可以被修改和设置的方式不止文本提示一种。
除了文本提示,深度图像也可以被用来设置图像模型。
比如ControlNet就可以使用检测到的轮廓、人体姿势等来设置噪声预测器,并实现对图像生成的出色控制。
Stable difussion逐步解析
现在你已经了解了稳定扩散的所有内部机制,让我们通过一些例子来看看它在幕后到底发生了什么。
文字转图像
在文字转图像中,你输入文字,模型会返回一个生成好的AI图片。
步骤1。稳定扩散在潜在空间中生成一个随机张量。你可以通过设置随机数生成器的种子来控制这个张量。
如果你把种子设置为固定的值,那么你将始终得到相同的随机张量。
最开始的图像只是一片噪音。
步骤2。噪声预测器 U-Net 将潜在的嘈杂图像和文本提示作为输入,并在潜在空间中预测噪音。
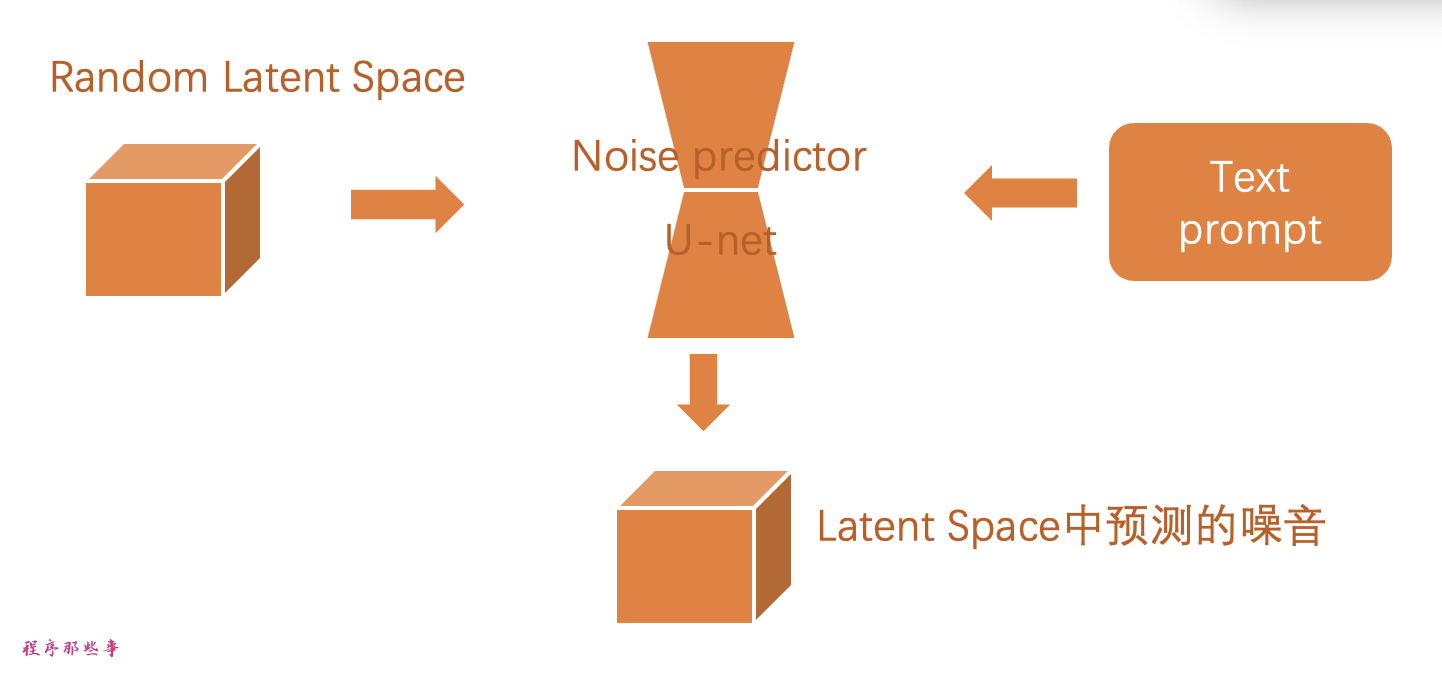
步骤3。从潜在图像中减去潜在噪声。这就成为了您的新潜在图像。
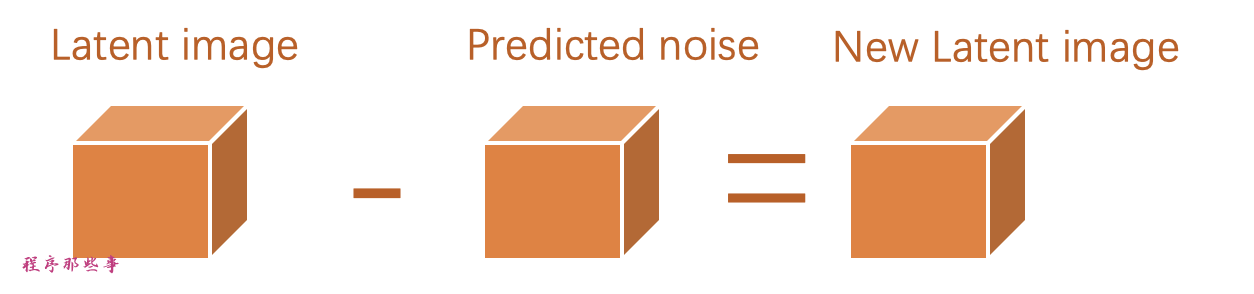
步骤2和步骤3会重复一定数量的采样步骤,这个步骤就是你设置的sample steps。
步骤4。最后,VAE 的解码器将潜在图像转换回像素空间。这就是在运行稳定扩散后得到的图像。
噪声调度(Noise schedule)
图片从嘈杂变得清晰。是因为每一步我们都从原始latent space中减去了预测到的噪声。
每步减少多少噪声,这个减去噪声的调度过程,就叫做noise schedule。
下面是一个噪声调度的例子。
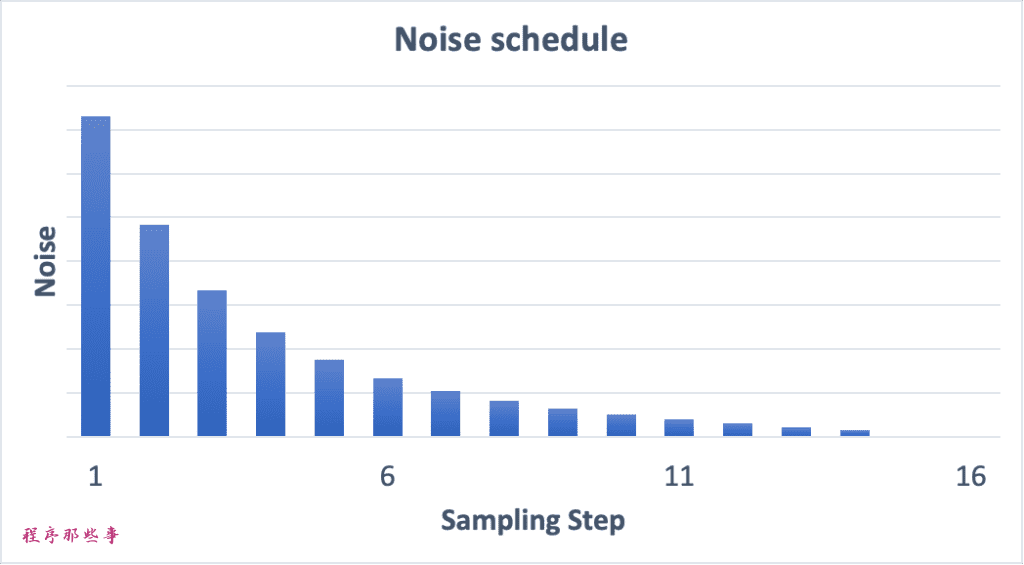
noise schedule是通过我们使用的采样器和采样步数来决定的,我们可以在每一步中减去相同量的噪声,也可以在开始阶段减去更多的噪声,就像上面的例子。
采样器在每一步中减去恰好足够的噪声,以便在下一步达到期望的噪声。
图像到图像
图像到图像的意思是使用稳定扩散将一幅图像转换成另一幅图像。
SDEdit是一种图像到图像的编辑方法,它允许用户通过结合输入图像和文本提示来控制图像生成过程。这种方法首次提出时,旨在提高对生成图像的控制能力,使得用户可以更精确地实现他们的创意愿景。SDEdit可以应用于任何扩散模型,包括Stable Diffusion。
图像到图像的输入是一幅图像和一个文本提示。生成的图像将同时受到输入图像和文本提示的影响。
比如我通过这左边的素描图加上提示词:
"photo of young woman,no suit,no shirt,no bar,on the street,
rim lighting,studio lighting,looking at the camera,dslr,ultra quality,sharp focus,tack sharp,dof,film grain,Fujifilm XT3,crystal clear,8K UHD,highly detailed glossy eyes,high detailed skin,skin pores,"
就可以把它转换成一张真实的图片:
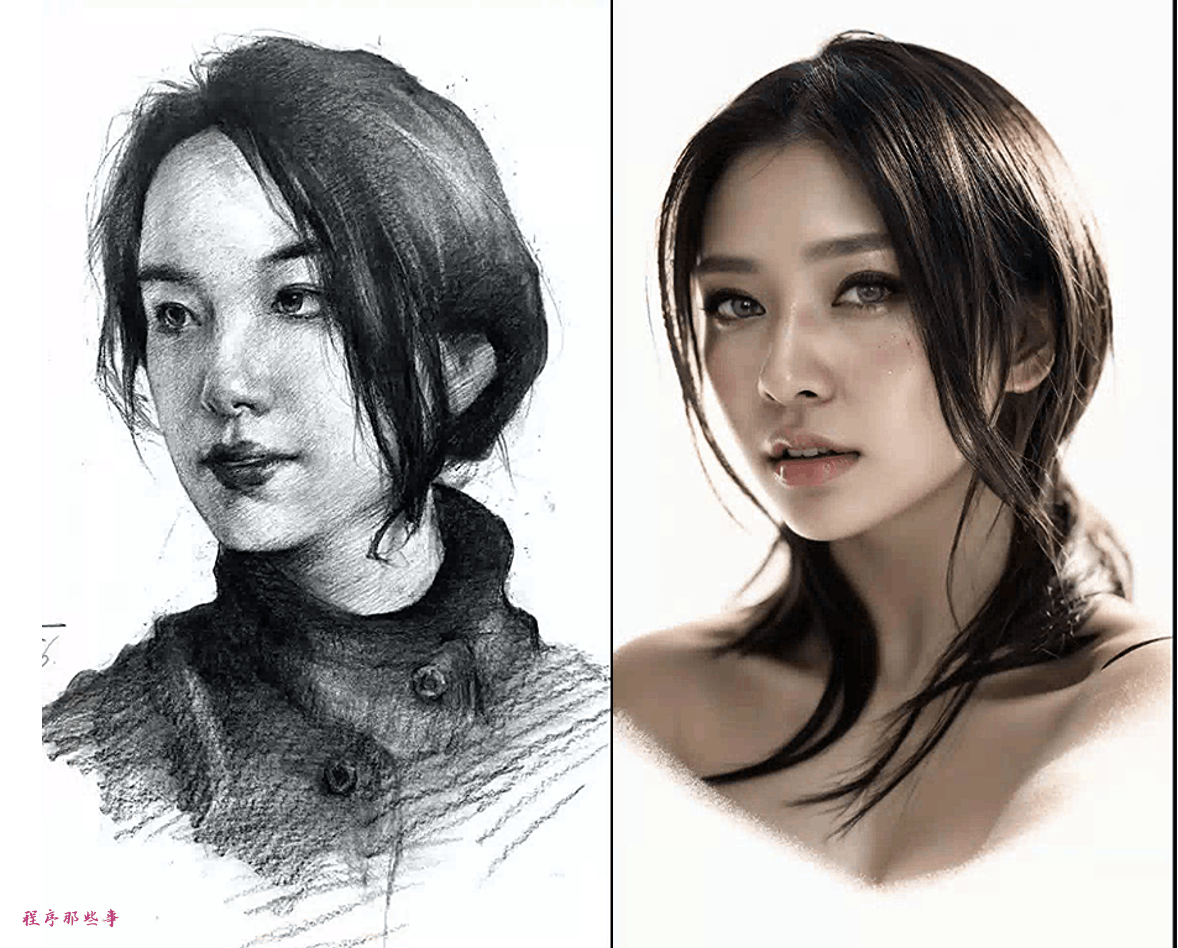
现在让我们来看看具体的步骤。
步骤1. 将输入图像编码为潜在空间。
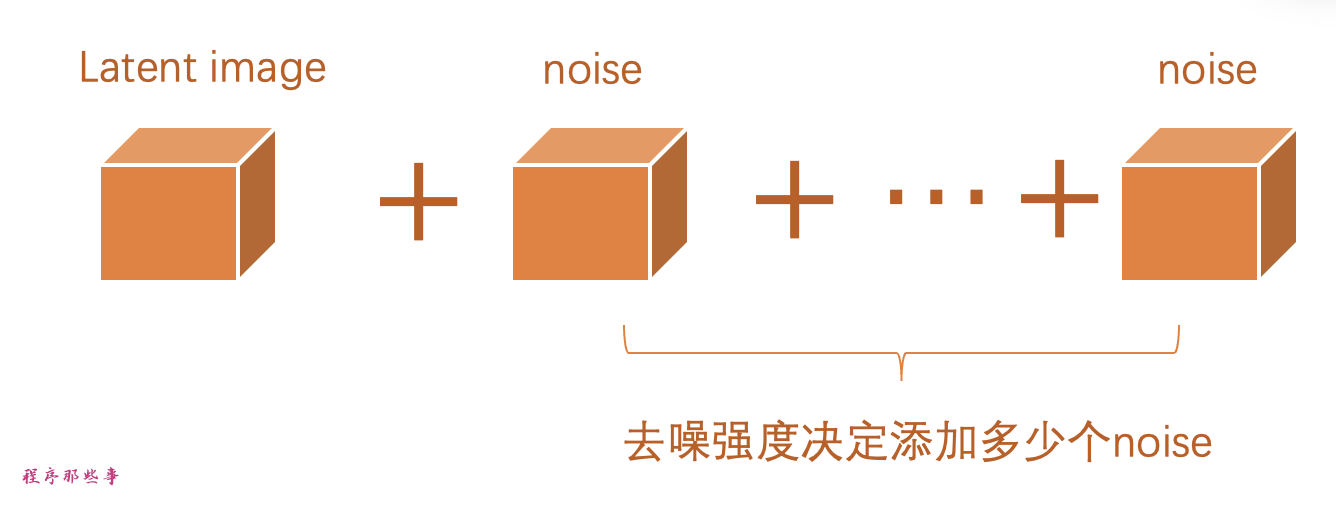
步骤2. 将噪声添加到潜在图像。去噪强度控制添加的噪声量。
如果为0,则不添加噪声。如果为1,则添加最大量的噪声,使潜在图像变成完全随机的张量。
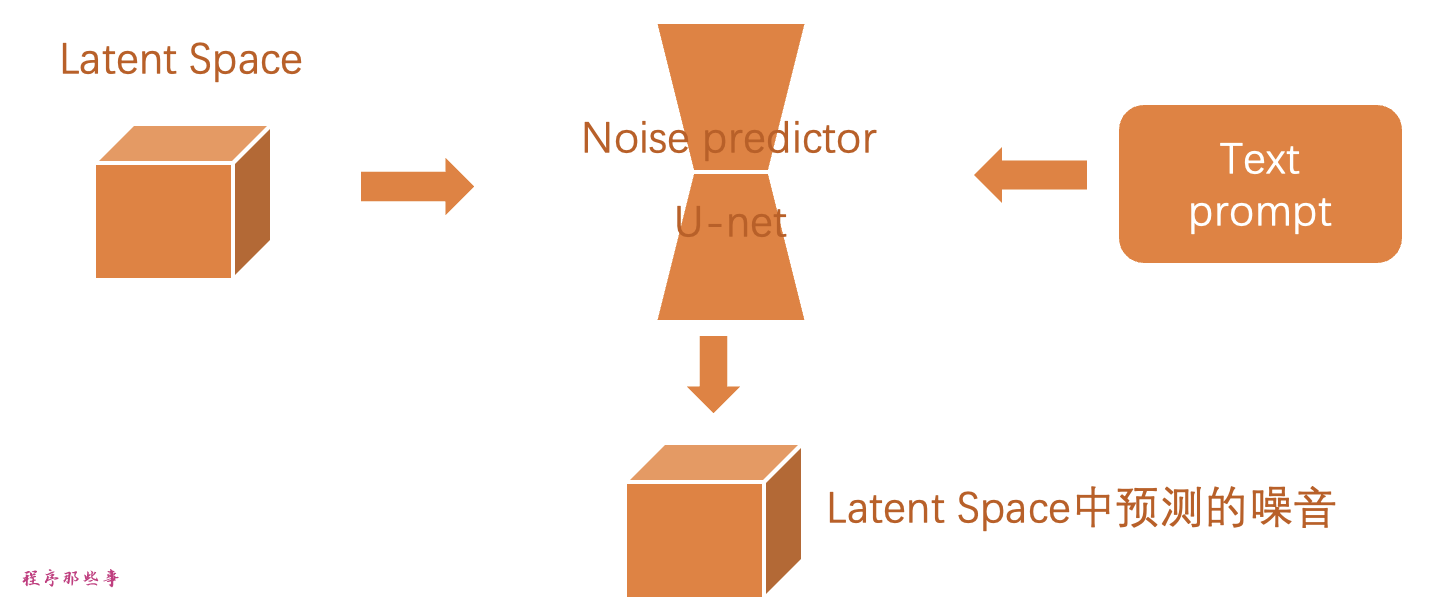
步骤3. 噪声预测器U-Net将潜在带噪声图像和文本提示作为输入,并预测潜在空间中的噪声。
步骤4. 从潜在图像中减去潜在噪声。这就成为了你的新潜在图像。
步骤3和步骤4会重复一定数量的采样步骤,这个步骤就是你设置的sample steps。
步骤5. 最后,VAE的解码器将潜在图像转换回像素空间。这就是你通过运行图像到图像得到的图像。
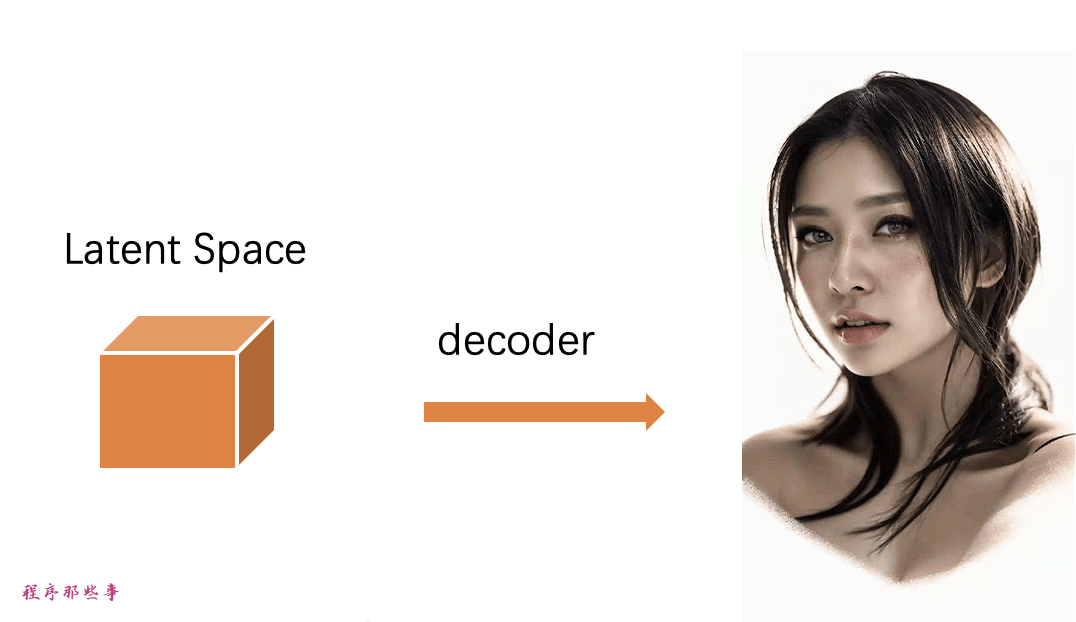
所以现在你知道图像到图像是什么了:它只是在初始潜在图像上加入一点噪声和输入图像。
将去噪强度设置为1等同于文本到图像,因为初始潜在图像完全是随机的。
图像修复
图像修复实际上只是图像到图像的特例。在需要修复的图像部分添加了噪音。噪音的数量同样由去噪强度控制。
什么是CFG值?
我们在使用stable diffusion的时候,有一个非常重要的参数叫做CFG。
在理解CFG之前,我们首先需要了解它的前身,分类器指导Classifier guidance
分类器指导Classifier guidance
分类器指导是在扩散模型中图像标签的一种整合方式。你可以使用标签来指导扩散过程。例如,标签“1girl”可以引导逆扩散过程生成女性的照片。
分类器指导比例(classifier guidance scale)是一个参数,用于控制扩散过程在多大程度上遵守这个分类标签。
假设我们有三组图像,分别带有“猫”、“狗”和“人类”的标签。如果扩散过程不受任何指导,模型可能会从每个类别中随机抽取样本。这可能导致生成的图像同时符合两个标签的特征,比如一个男孩正在抚摸一只狗的场景。
在classifier guidance scale指导的条件下,扩散模型产出的图像往往会倾向于典型或明确的样本。比如,当你要求模型生成一只猫的图片时,它将提供一张清晰无疑的猫的图像,而非其他任何生物。
分类器指导比例(classifier guidance scale)调节着模型遵循标签指导的严格程度,更高的值,意味着在生成图像时,模型更加严格地依据所给标签进行选择。在实际操作中,这个比例的值实际上是一个乘数,它决定了模型在生成过程中向具有特定标签的数据集偏移的程度。
无分类器引导Classifier-free guidance(CFG)
分类器引导虽然功能强大,但它需要额外的模型来提供指导,这给训练过程带来了一些挑战。
而无分类器引导是一种创新的方法,它允许实现“无需分类器的分类器引导”。通过使用图像的标题来训练一个有条件的扩散模型,将分类器的功能整合为噪声预测器U-Net的一个条件,从而实现了一种无需单独图像分类器的图像生成引导。
另外,文本提示为文本到图像的生成提供了一种引导机制,使得模型能够根据文本描述生成相应的图像。
无分类器引导规模(CFG scale)
现在,我们有一个使用条件控制的无分类器扩散过程。我们如何控制AI生成的图像应该多大程度上遵循引导?
无分类器引导规模(CFG scale)是一个控制文本提示如何引导扩散过程的值。当CFG规模设置为0时,AI图像生成是无条件的(即忽略提示)。较高的CFG规模会将扩散引导到提示方向。
稳定扩散 v1.5 与 v2 比较
模型差异
SD v2使用OpenClip进行文本嵌入。SD v1使用Open AI的CLIP ViT-L/14进行文本嵌入。这一变化的原因是:
-
OpenClip比原先的模型大了多达五倍。更大的文本编码器模型可以提高图像质量。
-
虽然Open AI的CLIP模型是开源的,但这些模型是使用专有数据进行训练的。转换到OpenClip模型能够让研究人员在研究和优化模型时更加透明。这对于长期发展是更有利的。
v2模型有两种版本。
-
512版本生成512×512像素的图像
-
768版本生成768×768像素的图像
训练数据差异
SD v1.4 是在名为 laion2B-en 的数据集上,以 256×256 的分辨率进行了 237,000 次训练迭代。
接着,在 laion-high-resolution 数据集上,以 512×512 的分辨率进行了 194,000 次训练迭代。
在“laion-aesthetics v2 5+”数据集上,同样以 512×512 的分辨率,进行了 225,000 次训练迭代,同时在文本条件中降低了 10% 的权重。
SD v2 则是在 LAION-5B 数据集的子集上,经过去除了显式NSFW内容的筛选,并应用了 LAION-NSFW 分类器,以 punsafe=0.1 的参数和 aesthetic score >=4.5 的条件下,进行了 550,000 次训练迭代。
此外,该模型还在相同数据集上以 256x256 的分辨率进行了 850,000 次训练迭代,但这次只包括图片分辨率大于或等于 512x512 的样本。
之后,模型使用了 v-objective 目标函数,在相同数据集上进行了额外的 150,000 次训练迭代。
最后,在 768x768 的图片上继续进行了 140,000 次训练迭代。
SD v2.1 是在 v2.0 的基础上进行了微调,先是以 punsafe=0.1 的参数额外训练了 55,000 步,然后又以 punsafe=0.98 的参数额外训练了 155,000 步。
值得注意的是,在最终的训练阶段,NSFW的过滤器被关闭了。
输出表现的差异
人们在使用SD v2 来控制风格和生成名人图像时,会更加的困难。因为虽然 Stability AI 并没有明确排除艺术家和名人的名字,但在 v2 版本中,这些名字的效果要弱得多。这很可能是因为训练数据的差异所致。Open AI 的专有数据可能包含更多的艺术作品和名人照片,而且这些数据很可能经过了高度筛选,以确保每件作品和每位人物都看起来都非常美观。
因为这种原因,SD V2 和v2.1并没有流行起来,用户们更倾向于使用经过精细调整的 v1.5 和 SDXL 模型。
SDXL model
作为一个规模更大的模型,在人工智能领域,人们普遍认为其性能会更为出色。SDXL 模型的参数总数达到了惊人的 66 亿,而相比之下,v1.5 模型的参数总数则为 9.8 亿。
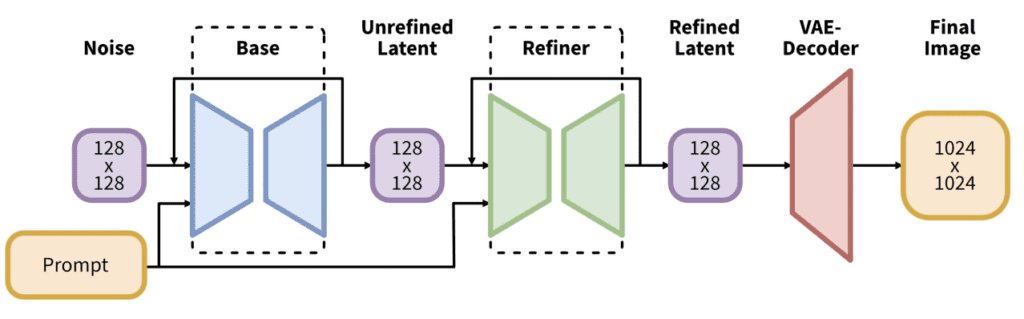
-
实际上,SDXL 模型由两个模型组成:基础模型和细化模型。基础模型负责构建整体构图,而细化模型则在此基础上添加更精细的细节。
基础模型可以独立运行,不依赖细化模型。
SDXL 基础模型的改进包括:
- 文本编码器结合了最大的 OpenClip 模型(ViT-G/14)和 OpenAI 的专有 CLIP ViT-L。这样的选择让 SDXL 更易于引导,同时保持了强大的性能,并且能够使用 OpenClip 进行训练。
- 新的图像尺寸调节旨在使用小于 256×256 的训练图像。这通过不丢弃 39% 的图像,显著增加了训练数据量。
- U-Net 的规模是 v1.5 模型的三倍。
- 默认的图像尺寸为 1024×1024,是 v1.5 模型 512×512 的四倍。