~2011
1. A cross-lingual annotation projection approach for relation detection
摘要:尽管在过去十年中对关系提取进行了广泛的研究,基于监督学习的统计系统仍然受限,因为它们需要大量的训练数据才能达到高性能。在本文中,我们开发了一种跨语言注释投影方法,该方法利用平行语料库来启动一个关系检测器,而不需要为资源匮乏的语言进行大量的注释工作。为了使我们的方法更加可靠,我们引入了三种简单的投影噪声减少方法。我们的方法的优点通过一个新的韩语关系检测任务得到了证明。
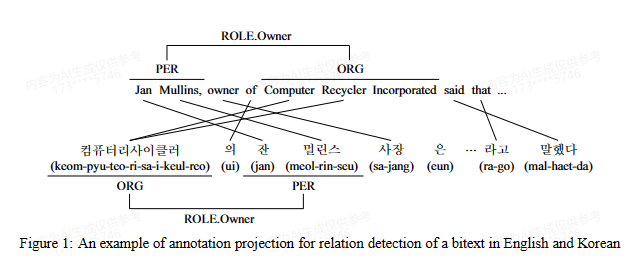
方法:爬虫得到平行语料库,对英语进行实体标注(斯坦福解析器),在ACE2003上训练和测试一个英语关系识别模型(基于树核的支持向量机),通过对齐将英语投影到韩语形成数据集(手动+投影),同样训练并测试韩语的一个基于树核的支持向量机模型
转移范例:标签
转移资源:平行语料库,词对齐(giza++),字典(作为补充)
评估语言:英语->韩语
评估数据集:ACE2003,self-generated
2. Bootstrapping Multilingual Relation Discovery Using English Wikipedia and Wikimedia-Induced Entity Extraction
摘要:关系提取在过去十年里一直是研究的重要课题。大多数关系提取器的开发都是通过结合在大量注释上训练复杂的计算系统以及语言专家广泛的规则编写来实现的。此外,许多关系提取器依赖于其他非平凡的自然语言处理(NLP)技术,这些技术本身也是通过大量的人力努力开发的,例如实体标注、解析等。由于创建和组装所需资源的成本高昂,关系提取器通常只为资源丰富的语言开发。在本文中,我们描述了一种几乎零成本的方法,使用免费的维基百科和其他网络文档以及一些英语知识,为明显不同的非英语语言构建关系提取器。我们将我们的方法应用于构建希腊语、西班牙语、俄语和中文中的母校、出生地、父亲、职业和配偶关系提取器。我们在文件级别对诱导出的关系进行了评估——这是我们在文献中看到的最精细的评估。
2012~2018
3. Multilingual open relation extraction using cross-lingual projection
摘要:开放域关系提取系统能够在不依赖任何底层模式的情况下识别句子中的关系和参数短语。然而,由于它们严重依赖于语言工具,如词性标注器和依存关系解析器,目前最先进的关系提取系统仅限于英语。我们提出了一种跨语言注释投影方法,用于语言无关的关系提取。我们在手动注释的测试集上评估了我们的方法,并在三种类型不同的语言上展示了结果。我们发布了从维基百科中提取的这十种语言的手动注释和提取出的关系。© 2015 计算语言学协会。
4. Multilingual relation extraction using compositional universal schema
摘要:通用模式通过联合嵌入来自输入知识库的所有关系类型以及在原始文本中观察到的文本模式,构建实体和关系的知识点(KB)。在以前的大多数通用模式应用中,每个文本模式都被表示为单一嵌入,这阻止了对未见模式的泛化。最近的工作采用神经网络捕捉模式的组合语义,为所有可能的输入文本提供泛化。作为回应,本文引入了对通用模式关系提取的覆盖范围和灵活性的重大改进:对训练中未见实体的预测以及对没有注释的领域的多语言迁移学习。我们通过在英语和西班牙语TAC KBP基准上进行广泛的实验来评估我们的模型,使用没有手工编写模式或额外注释的方法,超越了TAC 2013插槽填充的顶级系统。我们还考虑了一个多语言设置,其中英语训练数据实体与种子KB重叠,但西班牙语文本不重叠。尽管没有西班牙语数据的注释,我们训练了一个准确的预测器,并通过在语言之间绑定词嵌入获得了额外的改进。此外,我们发现多语言训练提高了英语关系提取的准确性。因此,我们的方法适用于在多种语言和领域中构建广泛覆盖的自动化知识库。©2016 计算语言学协会。
5. Neural Relation Extraction with Multi-lingual Attention
摘要:关系提取已被广泛用于从普通文本中发现未知的关系事实。大多数现有方法专注于利用单语言数据进行关系提取,忽略了来自各种语言文本的大量信息。为了解决这个问题,我们引入了一个多语言神经关系提取框架,该框架采用单语言注意力机制来利用单语言文本中的信息,并进一步提出跨语言注意力机制来考虑跨语言文本之间的信息一致性和互补性。在真实世界数据集上的实验结果表明,我们的模型可以利用多语言文本,并与基线相比在关系提取上持续取得显著的改进。本文的源代码可以从 https://github.com/thunlp/MNRE 获得。© 2017 计算语言学协会。