关于检索增强生成(RAG)的文章已经有很多了,如果我们能创建出可训练的检索器,或者说整个RAG可以像微调大型语言模型(LLM)那样定制化的话,那肯定能够获得更好的结果。但是当前RAG的问题在于各个子模块之间并没有完全协调,就像一个缝合怪一样,虽然能够工作但各部分并不和谐,所以我们这里介绍RAG 2.0的概念来解决这个问题。
什么是RAG?
简单来说,RAG可以为我们的大型语言模型(LLM)提供额外的上下文,以生成更好、更具体的回应。LLM是在公开可用的数据上训练的,它们本身是非常智能的系统,但它们无法回答具体问题,因为它们缺乏回答这些问题的上下文。
所以RAG可以向LLM插入新知识或能力,尽管这种知识插入并不是永久的。而另一种常用向LLM添加新知识或能力的方法是通过对我们特定数据进行微调LLM。
通过微调添加新知识相当困难,昂贵,但是却是永久性。通过微调添加新能力甚至会影响它以前拥有的知识。在微调过程中,我们无法控制哪些权重将被改变,因此也无法得知哪些能力会增加或减少。
选择微调、RAG还是两者的结合,完全取决于手头的任务。没有一种适合所有情况的方法。
RAG的经典步骤如下:
- 将文档分成均匀的块。
- 每个块是一段原始文本。
- 使用编码器为每个块生成嵌入(例如,OpenAI嵌入,sentence_transformer等),并将其存储在数据库中。
- 找到最相似的编码块,获取这些块的原始文本,并将其作为上下文与提示一起提供给生成器。
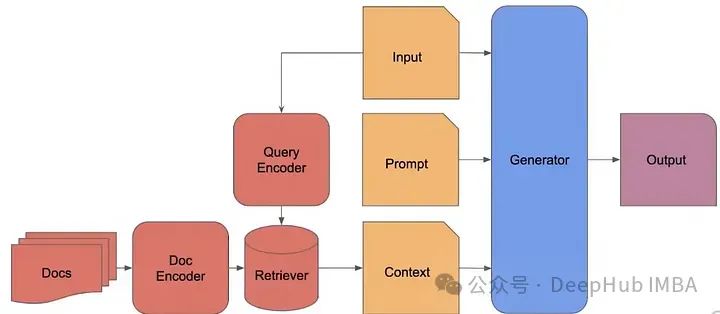
RAG 2.0
当今典型的RAG系统使用现成的冻结模型进行嵌入,使用向量数据库进行检索,以及使用黑盒语言模型进行生成,通过提示或编排框架将它们拼接在一起。各个组件技术上可行,但整体远非最佳。这些系统脆弱,缺乏对其部署领域的任何机器学习或专业化,需要广泛的提示,并且容易发生级联错误。结果是RAG系统很少通过生产标准。
而我们要说的RAG 2.0的概念,通过预训练、微调并对所有组件进行对齐,作为一个整体集成系统,通过语言模型和检索器的双重反向传播来最大化性能:
https://avoid.overfit.cn/post/18853fc6f10e4e23a992880c624ea1dd
标签:检索,RAG,微调,生成,LLM,2.0,端到 From: https://www.cnblogs.com/deephub/p/18145557