CIFAR10の训练
一,CIFAR10
-
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。
每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片
二, 代码实现
-
GPU训练与保存模型
from torch import optim import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from model import * train_data = torchvision.datasets.CIFAR10("data1", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data = torchvision.datasets.CIFAR10("data1", train=False, transform=torchvision.transforms.ToTensor(), download=True) train_data_size = len(train_data) test_data_size = len(test_data) # print(train_data_size) # print(test_data_size) train_dataloader = DataLoader(train_data, batch_size=64) test_dataloader = DataLoader(test_data, batch_size=64) class kun(nn.Module): def __init__(self): super(kun, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 64, 5, 1, 2), nn.MaxPool2d(2) ) # 计算最后一个MaxPool2d后的特征图大小 # 初始大小是 (32, 32),每个MaxPool2d都会减半,因此最终大小是 (4, 4) self.flat_features = 64 * 4 * 4 # 64个通道,每个通道4x4的特征图 self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(self.flat_features, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.features(x) x = self.classifier(x) return x kunkun = kun() kunkun = kunkun.cuda() loss_fn = nn.CrossEntropyLoss() loss_fn = loss_fn.cuda() learing_rate = 0.01 optimizer = torch.optim.SGD(kunkun.parameters(), lr=learing_rate) total_train_step = 0 total_test_step = 0 epoch = 30 writer = SummaryWriter("logs_train") for i in range(epoch): print("---------第{}轮训练开始----------".format(i + 1)) for data in train_dataloader: imgs, targets = data imgs = imgs.cuda() targets = targets.cuda() outputs = kunkun(imgs) loss = loss_fn(outputs, targets) optimizer.zero_grad() loss.backward() optimizer.step() total_train_step += 1 if total_train_step % 100 == 0: print("训练次数:{},loss:{}".format(total_train_step, loss.item())) writer.add_scalar("train_loss", loss.item(), total_train_step) total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data imgs = imgs.cuda() targets = targets.cuda() outputs = kunkun(imgs) loss = loss_fn(outputs, targets) total_test_loss = total_test_loss + loss accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracy print("整体测试集的loss:{}".format(total_test_loss)) print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size)) writer.add_scalar("test_loss", total_test_loss, total_test_step) total_test_step += 1 torch.save(kunkun, "kunkun_{}.pth".format(i)) print("模型已保存") writer.close() -
图片测试
import torch import torchvision from PIL import Image from torch import nn image_path = "耶耶.jpg" image = Image.open(image_path) image = image.convert('RGB') transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()]) image = transform(image) class kun(nn.Module): def __init__(self): super(kun, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 64, 5, 1, 2), nn.MaxPool2d(2) ) # 计算最后一个MaxPool2d后的特征图大小 # 初始大小是 (32, 32),每个MaxPool2d都会减半,因此最终大小是 (4, 4) self.flat_features = 64 * 4 * 4 # 64个通道,每个通道4x4的特征图 self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(self.flat_features, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.features(x) x = self.classifier(x) return x model = torch.load("kunkun_29.pth") # print(model) image = torch.reshape(image, (1, 3, 32, 32)) image = image.cuda() model.eval() with torch.no_grad(): output = model(image) print(output) print(output.argmax(1))
三,训练效果
-
训练三十次后效果如下:
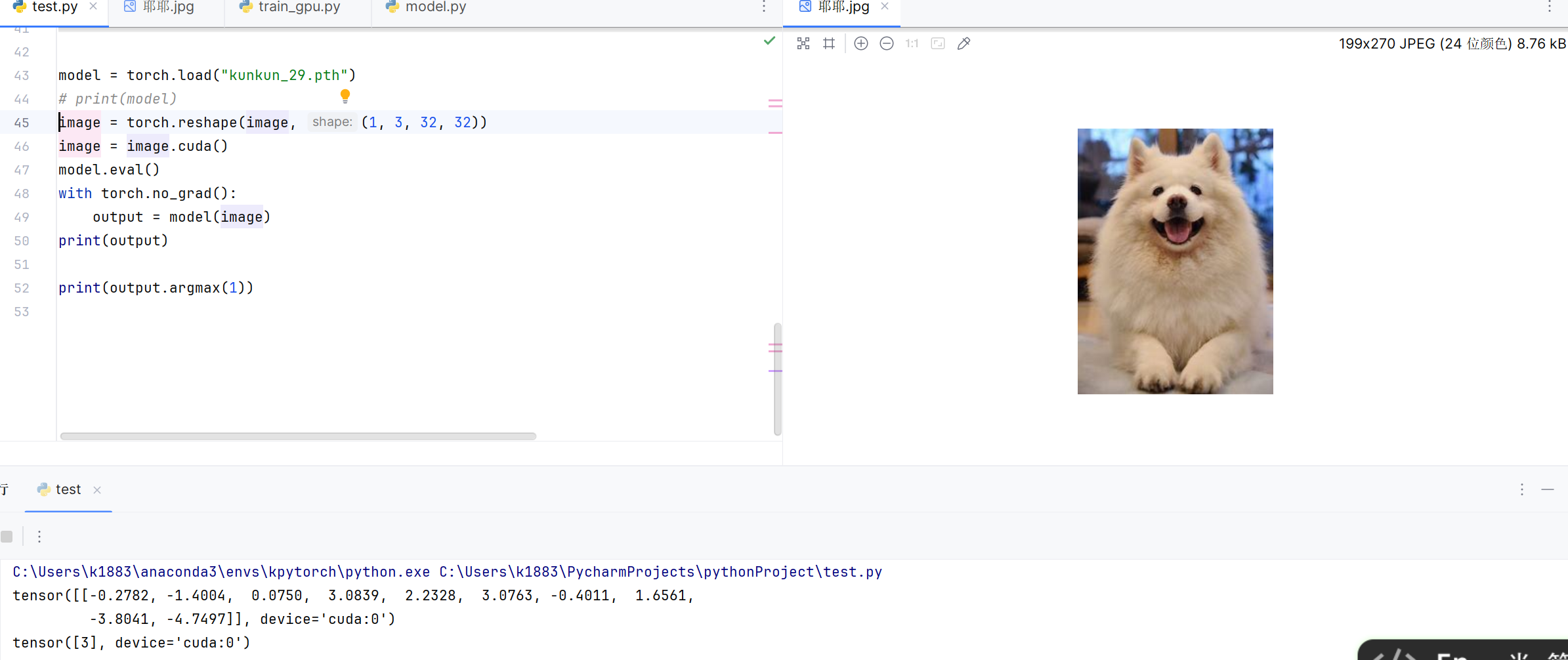
成功的将狗识别成了猫,继续训练,加大epoch的值
-
将epoch提高到50
识别成功
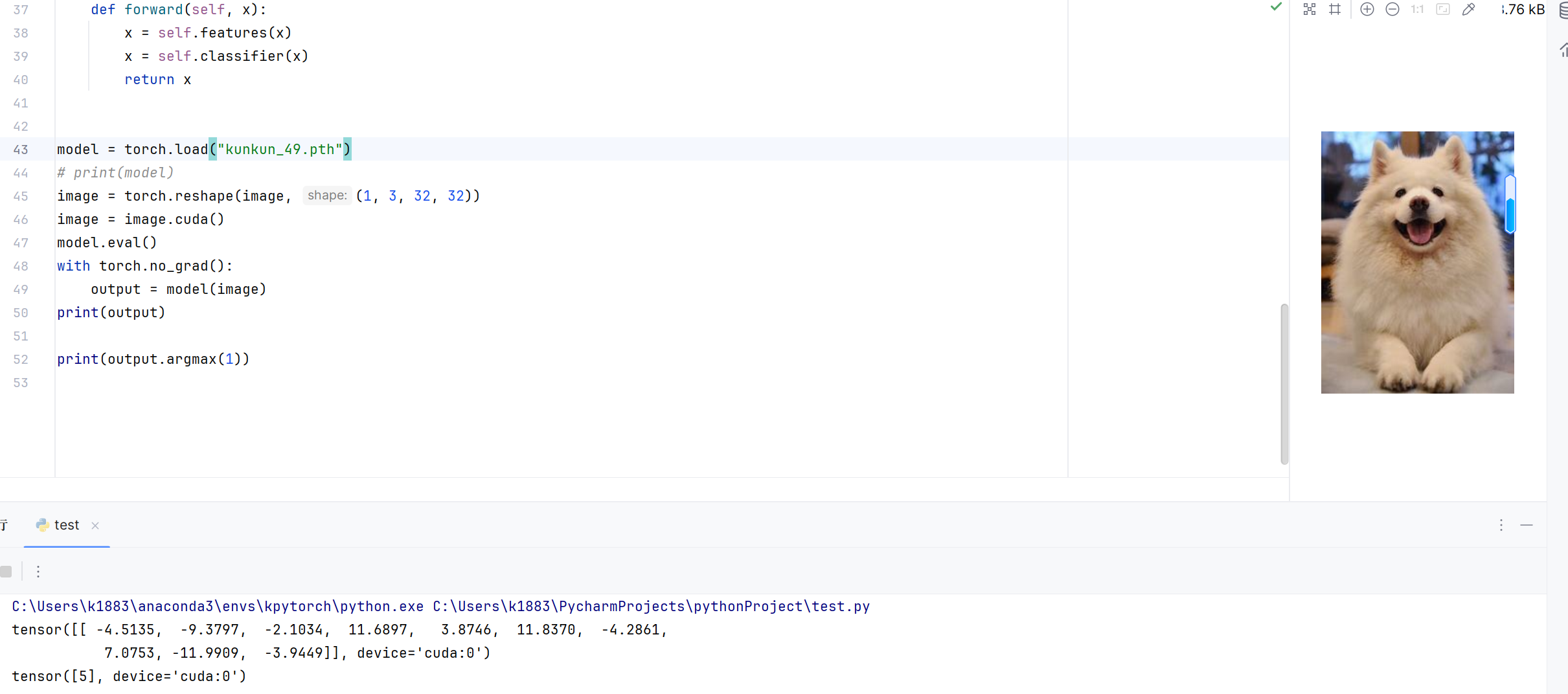
四,总结
经过数据集训练,已经初步可以识别出物体种类了,但是猫和狗的区分仍需加强
标签:loss,训练,nn,CIFAR10,32,self,test,total From: https://www.cnblogs.com/liuyankun111/p/18141374