论文基于改进训练配置以及一种新颖的蒸馏方式,提出了仅用ImageNet就能训练出来的Transformer网络DeiT。在蒸馏学习时,DeiT以卷积网络作为teacher,能够结合当前主流的数据增强和训练策略来进一步提高性能。从实验结果来看,效果很不错
来源:晓飞的算法工程笔记 公众号
论文: Training data-efficient image transformers & distillation through attention

Introduction
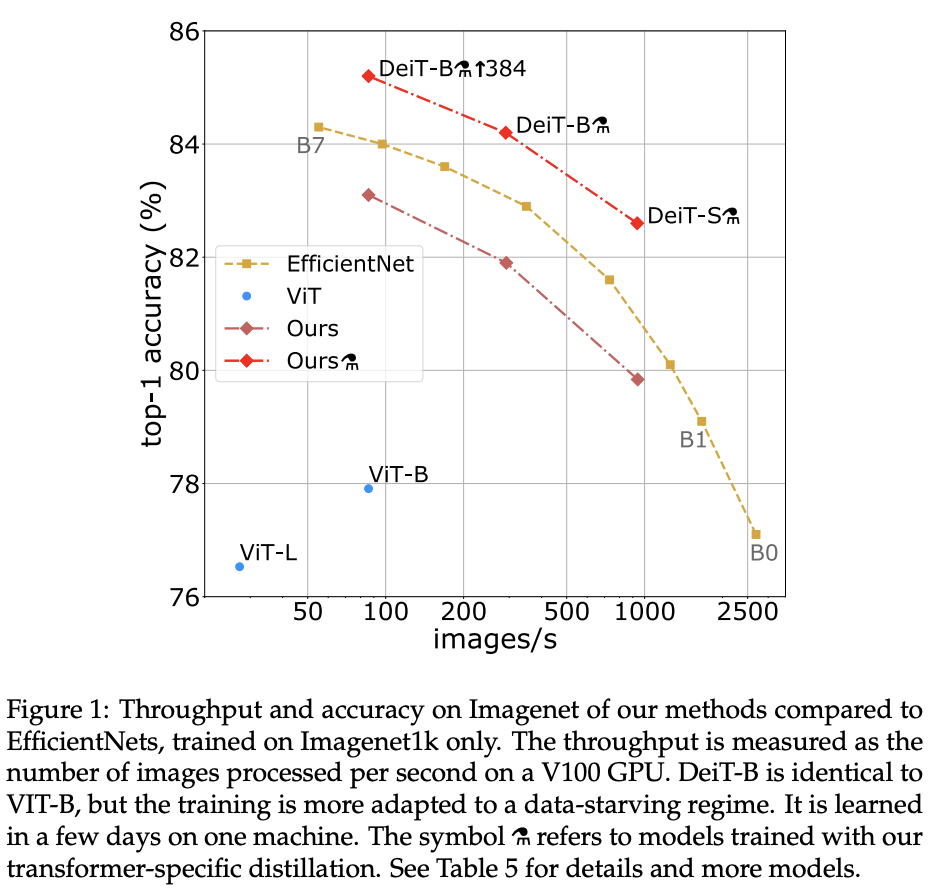
Vision Transformer一般要先在大型计算设施上预训练数以亿计的图片才能有较好的性能,这极大地提高其应用门槛。为此,论文基于ViT提出了可在ImageNet上训练的Vision Transformer模型DeiT,仅需要一台电脑(4卡)训练不到三天(53小时的预训练和可选的20小时微调)的时间。在没有外部数据预训练的情况下,在ImageNet上达到了83.1% 的最高精度。
此外,论文还提出了一种针对Transformer的蒸馏策略,通过一个蒸馏token确保student网络通过注意力从teacher网络那里进行学习。当使用卷积网络作为teacher网络时,ImageNet上可达到85.2%的准确性。
总体而言,论文主要有以下贡献:
- 通过实验表明,在没有外部数据的情况下,Vision Transformer也可以在ImageNet上达到SOTA的结果,而且仅需要4卡设备训练三天。
- 论文提出了一种基于蒸馏token的新蒸馏方法,这种用于Transformer的蒸馏方法大幅优于一般蒸馏方法。蒸馏token与class token的作用相同,都参与注意力计算中,只是蒸馏token的训练目的在于复现teacher网络的标签预测。
- 有趣的是,论文发现在使用新蒸馏方法时,用卷积网络作为teacher要比用另一个相同准确率的transformer的作为teacher的效果要好。
- 在Imagenet上预训练的模型可以转移到不同的下游任务(如细粒度分类),得到很不错的性能。
Distillation through attention
Soft distillation
一般的蒸馏方法都是Soft distillation,其核心目标是最小化teacher网络和student网络的softmax输出之间的Kullback-Leibler散度。
定义\(Z_t\)为teacher网络的logits输出(输入softmax的向量),\(Z_s\)为student网络的logits输出。用\(\tau\)表示蒸馏温度,\(\lambda\)表示平衡Kullback-Leibler散度损失(KL)和交叉熵损失(LCE)的权值,\(\psi\)表示softmax函数。定义soft distillation的目标函数为:
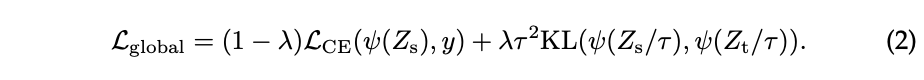
Hard-label distillation
论文提出了一种蒸馏的变体,将teacher网络的预测标签作为蒸馏的GT标签。假设\(y_t = argmax_c Z_t(c)\)是teacher网络的预测标签,与之相关的hard-label distillation目标为:
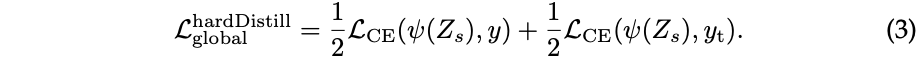
对于同一张图片,teacher网络预测的标签可能随着特定的数据增强而有所变化。从实验结果来看,将预测标签作为蒸馏目标的做法比传统的做法更好,不仅无额外参数,概念上还更简单:teacher网络预测的\(y_t\)与真实标签\(y\)是相同的作用。
此外,hard label也可以通过label smoothing转换为软标签,其中GT标签具有\(1 - \varepsilon\)的概率,其余类共享\(\varepsilon\)概率。在相关的实验中,参数固定为\(\varepsilon = 0.1\)。
Distillation token
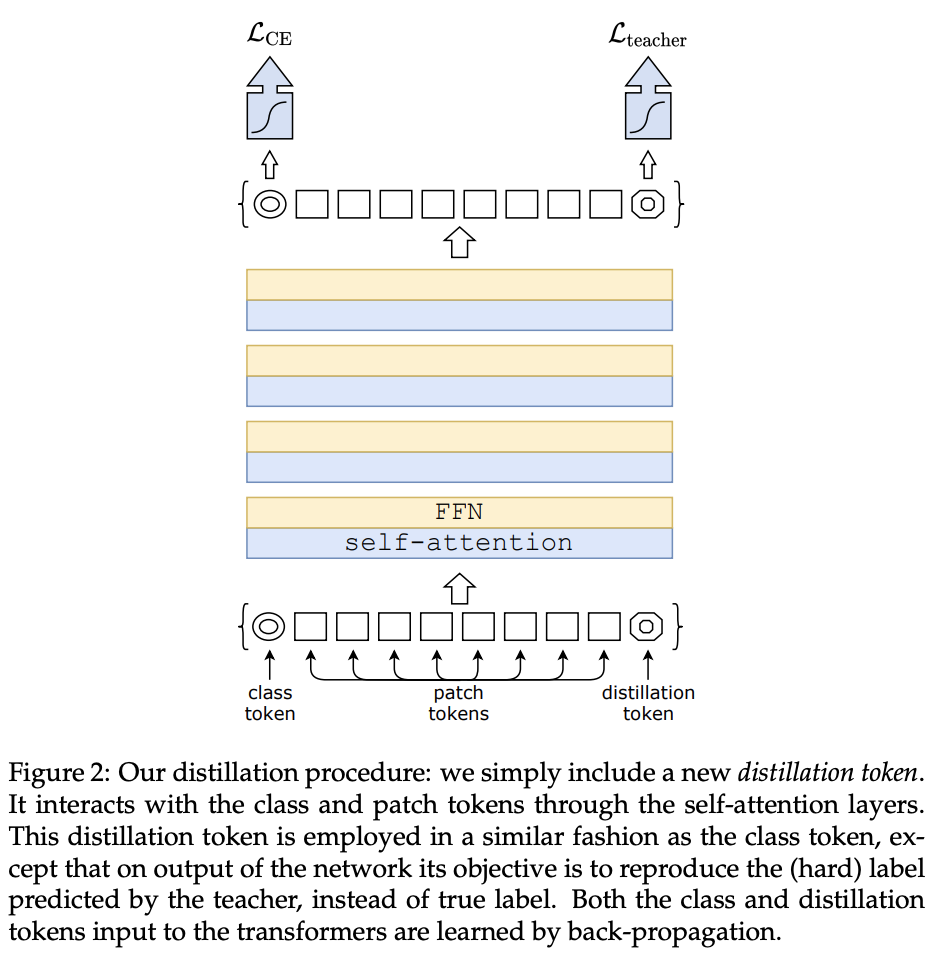
论文提出的蒸馏方案如如图2所示,在输入的token序列中添加一个蒸馏token。蒸馏token与class token类似,通过self-attention与其它token交互并将最后一层中的对应输出作为网络输出,其训练目标为损失函数中的蒸馏损失部分。蒸馏token使得模型可以像常规蒸馏一样从teacher网络的输出中学习,同时与class token保持互补的关系。
论文发现,训练后的输入层class token和蒸馏token收敛到了完全不同的向量,平均余弦相似度仅为0.06。但随着在网络的计算,class和蒸馏token在越深层中的对应输出逐渐变得更加相似,最后一层达到了较高的相似度(cos=0.93),但没有完全相同。这是符合预期的,因为两个token的目标就是产生相似但不相同的目标。
论文也尝试替代实验,用另一个class token代替teacher网络的蒸馏token进行伪蒸馏学习。但无论如何随机且独立地初始化两个class token,训练后都会收敛到相同的向量(cos=0.999),其对应的输出也是准相同的。这表明这个代替的class token不会对分类性能带来任何影响,相比之下蒸馏token则能带来显著的提升。
Fine-tuning with distillation
在分辨率增加的fine-tuning阶段,同样使用真实标签和teacher网络预测标签进行训练。此时需要一个具有相同目标分辨率的teacher网络,可通过FixRes的做法从之前的低分辨率teacher网络中转换。论文也尝试了只用真实标签进行fine-tuning,但这导致了性能的降低。
Classification with our approach:joint classifiers
在测试时,网络输出的class token和蒸馏token都用于标签分类。论文的建议做法是将这两个token独立预测后再融合,即将两个分类器的softmax输出相加再进行预测。
Transformer models
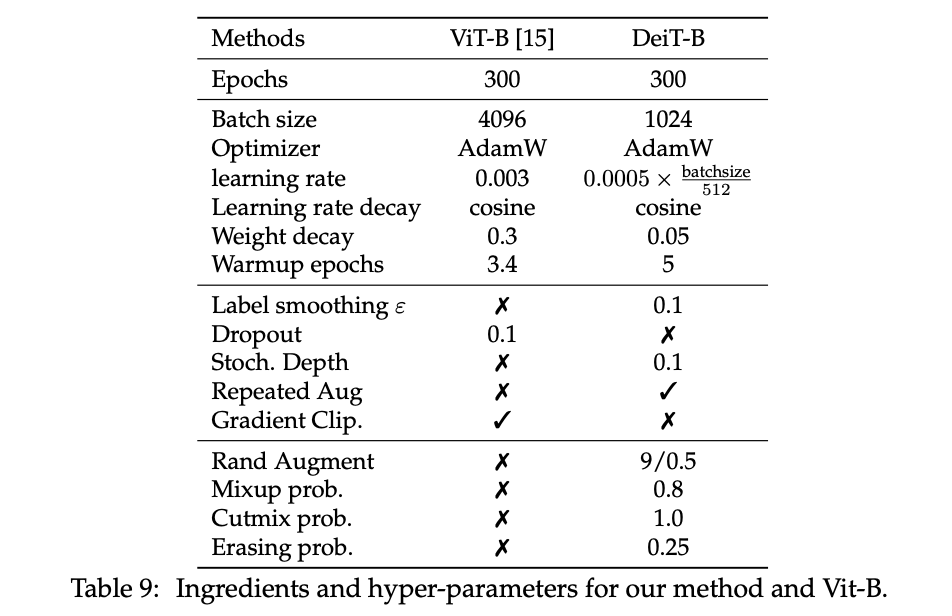
DeiT的架构设计与ViT相同,唯一的区别是训练策略和蒸馏token,训练策略的区别如表9所示。此外,在预训练时不使用MLP,仅使用线性分类器。
为避免混淆,用ViT来指代先前工作中的结果,用DeiT来指代论文的结果。如果未指定,DeiT指的是DeiT-B,与ViT-B具有相同的架构。当以更大的分辨率fine-tune DeiT时,论文会在名字的最后附加分辨率,例如DeiT-B↑384。最后,当使用论文提出的蒸馏方法时,论文会用一个蒸馏符号将其标识为DeiT⚗.。
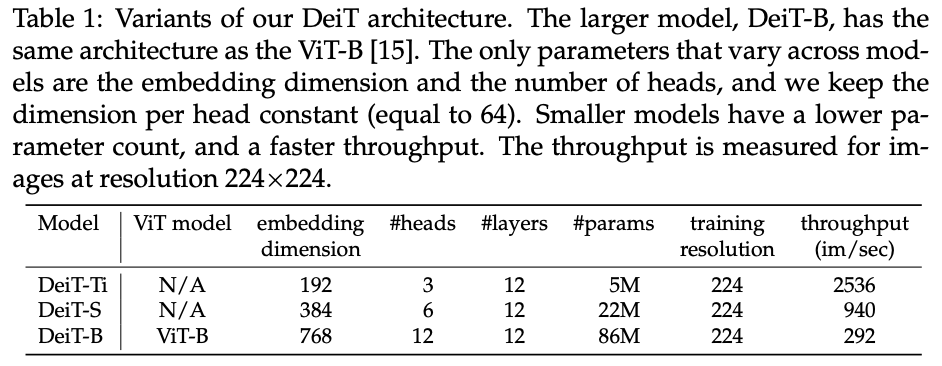
如表1所示,DeiT-B的结构与ViT-B完全一样,参数固定为\(D = 768\),\(h = 12\)和\(d = D/h = 64\)。另外,论文设计了两个较小的模型:DeiT-S和DeiT-Ti,减少了head的数量,\(d\)保持不变。
Experiment
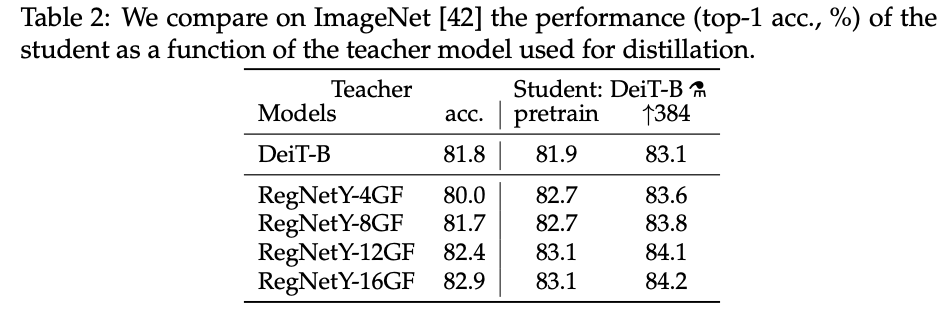
不同类型的teacher网络的蒸馏效果。
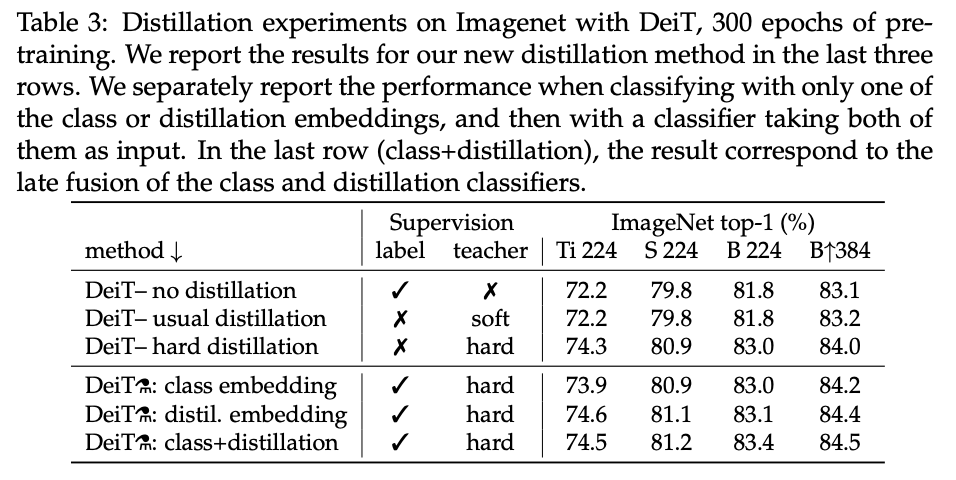
不同蒸馏策略的对比实验。
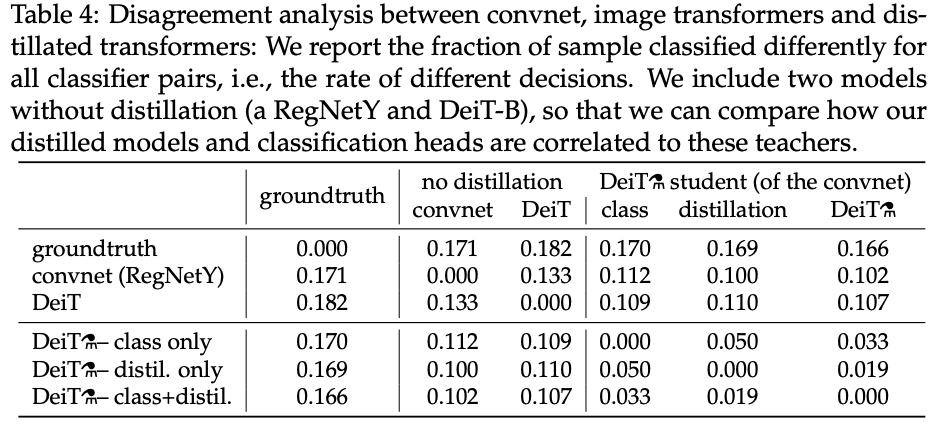
不同网络以及蒸馏策略之间的结果差异,值越小差异越小。
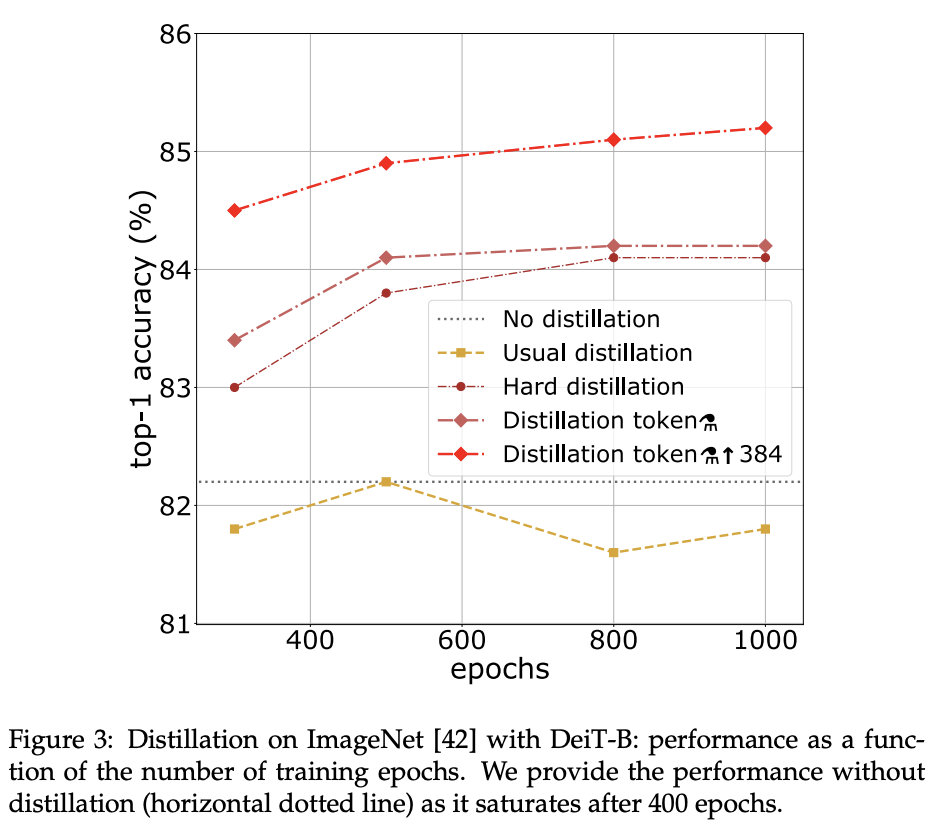
蒸馏策略与训练周期的关系。
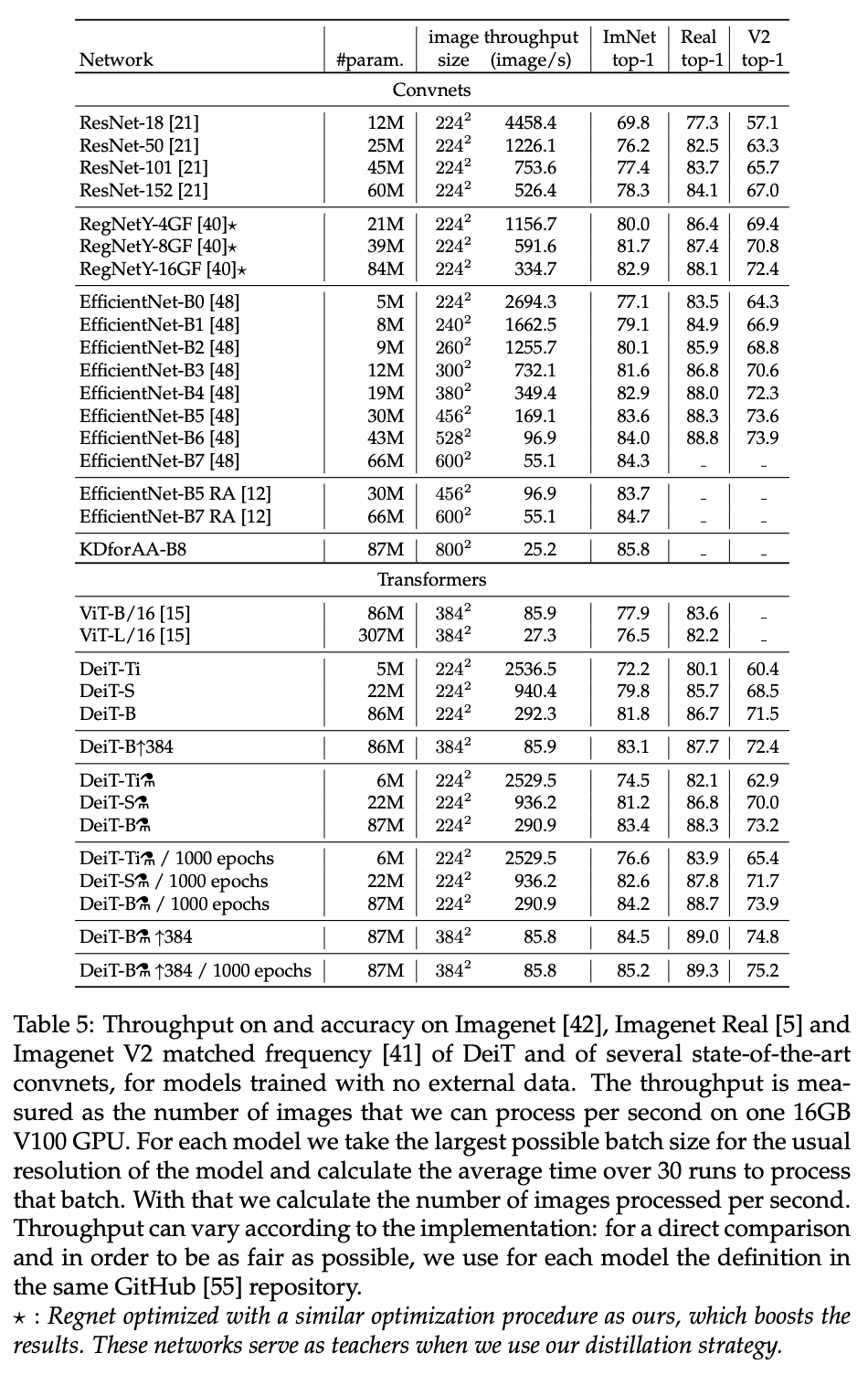
整体性能的对比。
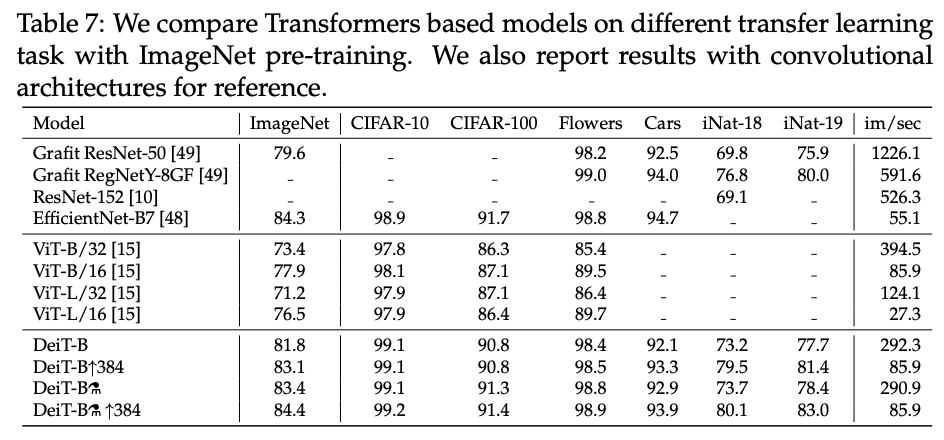
ImageNet上预训练模型的在其它训练集上的迁移效果。

不同优化器、数据增强、正则化的对比,寻找最佳的训练策略和配置。
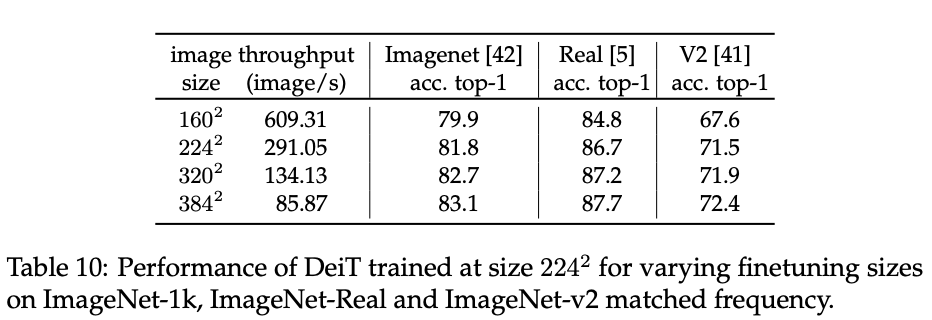
224分辨率预训练的DeiT在不同数据集上用不同分辨率fine-tune的效果。
Conclusion
论文基于改进训练配置以及一种新颖的蒸馏方式,提出了仅用ImageNet就能训练出来的Transformer网络DeiT。在蒸馏学习时,DeiT以卷积网络作为teacher,能够结合当前主流的数据增强和训练策略来进一步提高性能。从实验结果来看,效果很不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
