https://zhuanlan.zhihu.com/p/500807675
一张图看懂BERT
1 前言关于 BERT 模型的原理讲解实在太多了,学习路径主要是理解两篇论文:
1)理解 Transformer 模型,BERT 模型的主要结构就是 Transformer 模型的 Encoder 部分。论文传送门:Attention is all you need。
2)理解 BERT 模型,论文传送门:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。
本文主要讲解 BERT 模型的计算过程,并结合代码让读者有一个清晰的认识。
本文使用的 BERT 模型是来自哈工大的中文 ROBERTA 预训练模型,ROBERTA 是 BERT 的改进版本,模型下载地址:chinese_roberta_wwm_ext_L-12_H-768_A-12。尽管 ROBERTA 与 BERT 有一些差异(比如 ROBERTA 取消了 NSP 任务),但本文依然按照 BERT 的计算过程进行讲解。
2 BERT 计算过程
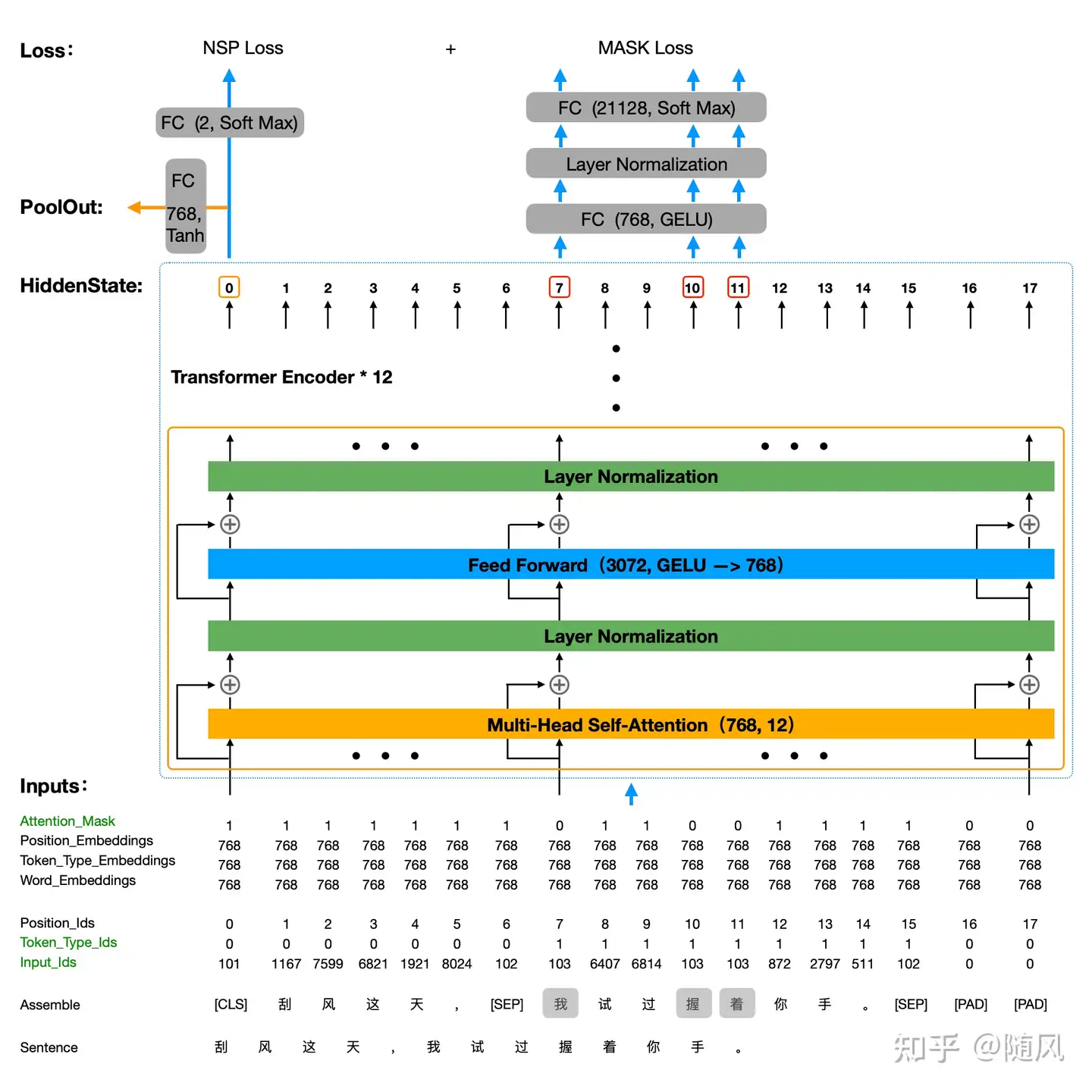
如下图所示,整个计算过程从下往上:
1、第一步输入语句,这里的 Sentence: “刮风这天,我试过握着你手。”
2、第二步数据转换,一般通过 BertTokenizer(分词器)进行转换,这个 BertTokenizer 的主要任务就是对原始语句进行处理,以满足 BertModel 的输入要求。BertTokenizer 主要执行以下处理过程:
1)生成词表,这个词表包含了训练语料库中所有的词,词表存储在 ./chinese_roberta_wwm_ext_L-12_H-768_A-12/vocab.txt 中。打开 vocab.txt,一共有 21128 个词,中文分词其实就是按照汉字进行拆分的。每个词都有对应的索引(索引从 0 开始),比如 [PAD]:0、 [CLS]:101、 [SEP]:102、[MASK]:103,[unused1]~[unused99] 表示未定义的词,是预留给用户自定义的。
2)BertTokenizer 的输入 Sentence:“刮风这天,我试过握着你手。”,定义 BertModel 的输入语句长度为 18,将 Sentence 转换为 BertModel 定义的格式 Assemble:“[CLS]”、 “刮“、 “风”、 “这”、 “天”、 “,”、 “[SEP]”、 “我”、 “试”、 “过”、 “握”、 “着”、 “你”、 “手”、 “。”、 “[SEP]”、 “[PAD]” 、 “[PAD]” 。图中可以看到设定 Mask 的词为 “我”、 “握”、 “着”。
3)BertTokenizer 的输出: Input_ids、Token_Type_ids、Attention_Mask(图中绿色标记)。Input_ids 表示按照词表将每个词映射为索引,比如 “[CLS]” 映射为 101、“刮” 映射为 1167;Token_Type_ids 表示两个语句的上下文关系,第一个语句的每个词都标注 0,第二个语句的每个词都标注 1;Attention_Mask 记录 Mask 的位置信息,在 Mask 位置标注 0,其它位置标注 1。对于 [PAD] 位置统一标注 0。
3、第三步 BertModel 计算,主要执行以下处理过程:
1)生成词表向量库,对应的 size 为 [21128, 768],即一共 21128 个词,每个词向量的维度是 768。将词索引Input_ids 转化为词向量 Word_Embeddings。
2)生成 NSP 向量库,对应的 size 为 [2, 768],即只表示 0、1 两种标注,每个词向量的维度是 768。将上下文关系索引 Token_Type_ids 转化为上下文关系向量 Token_Type_Embeddings。
3)按顺序生成位置索引 Position_ids,索引为 0~17。生成 Position 向量库,对应的 size 为 [18, 768],即长度为 18,每个词向量的维度是 768。将位置索引 Position_ids 转化为位置向量 Position_Embeddings。
4)神经网络的输入就是将 Word_Embeddings、Token_Type_Embeddings、Position_Embeddings 直接相加,即输入 Embeddings = Word_Embeddings + Token_Type_Embeddings + Position_Embeddings。
5)输入 Embeddings 经过 12 层 Encoder 计算模型输出。图中给出了一层 Encoder 结构,其中 Multi-Head Self-Attention 采用 12 个注意力头,输入与输出的词向量维度都是 768;Feed Forward 第一层输出词向量维度 3072(采用 GELU 激活函数),第二层输出词向量维度 768 (作为线性层)。整个 Encoder 的输入到输出词向量的维度都是 768,一直到第 12 层 Encoder 的输出 HiddenState(size = [18, 768]),作为整个模型的输出。
6)通常 BertModel 还有一个输出 PoolOut,它是把 HiddenState 第 0 个位置,即 [CLS] 对应的输出,经过一层全连接层(输出词向量维度 768,采用 Tanh 作为激活函数),得到 PoolOut 的输出结果。通常我们在BertModel 的输出里会看到 HiddenState、PoolOut 两个结果。
7)BertModel 的损失函数分为 NSP Loss 与 MASK Loss。NSP Loss 评价输入的两个句子是否为上下文关系,因此直接把 HiddenState 第 0 个位置的输出接一个二分类器;MASK Loss 预测被 MASK 的词,所以这里需要用到 Attention_Mask 序列来告诉模型哪些位置被 MASK 了,只选取被 MASK 位置的输出参与损失函数计算,这里选取序号 7、10、11 位置的输出,先经过一层全连接层(输出词向量维度 768,采用 GELU 作为激活函数),再经过一层全连接层映射到 21128 维度的向量(词表的大小)。总的损失函数 Loss = NSP Loss + MASK Loss。
注:1)Word_Embeddings 、Token_Type_Embeddings、Position_Embeddings 都参与了训练过程,参数是动态调节的,这一点与 Transformer 有所不同(Transformer 中的 Position_Embeddings 是固定的正余弦函数)。 2)[PAD] 位置是不参与训练的,代码中自动屏蔽了 [PAD] 位置的梯度。
以上就是 BERT 的计算过程,模型训练需要大量的语料,一般都是直接使用训练好的 BERT 模型。加载预训练的 BERT 模型,只需要传入 Input_ids、Token_Type_Ids、Attention_Mask,模型自动完成 Embedding,输出可以取 HiddenState、PoolOut。
3 BERT 计算样例
这里我们做一个简单的例子查看模型的输入、输出。我们不考虑上下文,只输入一句话,所以 token_type_ids 全部为 0;没有 MASK 词,所以 attention_mask 只有在 [PAD] 位置为 0 ,其它全部为 1。
from transformers import BertModel, BertTokenizer
# 加载分词工具
tokenizer = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
# 数据加载
data = tokenizer.encode_plus(text='刮风这天,我试过握着你手。',
truncation=True,
padding='max_length',
max_length=18,
return_tensors='pt',
return_length=True,
return_attention_mask=True
)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
# 加载预训练模型
model = BertModel.from_pretrained("hfl/chinese-roberta-wwm-ext")
# 不训练模型
for param in model.parameters():
param.requires_grad_(False)
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
print('input_ids', input_ids.shape, input_ids)
print('attention_mask', attention_mask.shape, attention_mask)
print('token_type_ids', token_type_ids.shape, token_type_ids)
print('last_hidden_state', out['last_hidden_state'].shape, out['last_hidden_state'])
print('pooler_output', out['pooler_output'].shape, out['pooler_output'])打印结果:
input_ids:1) torch.Size([1, 18])
2)tensor([[ 101, 1167, 7599, 6821, 1921, 8024, 2769, 6407,
6814, 2995, 4708, 872, 2797, 511, 102, 0, 0, 0]])
attention_mask:1) torch.Size([1, 18])
2)tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]])
token_type_ids:1)torch.Size([1, 18])
2)tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
last_hidden_state: 1)torch.Size([1, 18, 768])
2)tensor([[[ 0.0448, 0.2122, 0.3339, ..., -0.7975, -0.3528, -0.2340],
...,
[ 0.3545, -0.1148, 0.0680, ..., -0.2061, -0.3512, -0.6292]]])
pooler_output:1)torch.Size([1, 768])
2)tensor([[ 0.9767, 0.8776, 0.9743, 0.6167, -0.6348, 0.0866, -0.8775, -0.0658,
...,
-0.5344, 0.9941, 0.9434, -0.6481, -0.8505, -0.8339, -0.4736, -0.0645]])
BERT
简介:BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即…
卷积层发表于BERT相...关于BERT中的那些为什么
1、为什么BERT在第一句前会加一个[CLS]标志? BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。 为什么选它呢,因为与文本中已…
sliderSun 标签:BERT,768,Embeddings,模型,一张,ids,图看,向量 From: https://www.cnblogs.com/zhangbojiangfeng/p/18140234