一、背景
对于算法工程师来说,通常采用python语言来作为工作语言,但是直接用python部署线上服务性能很差。这个问题困扰了我很久,为了缓解深度学习模型工程落地性能问题,探索了Nvidia提供的triton部署框架,并在九数中台上完成线上部署,发现性能提升近337%!!(原服务单次访问模型推理时间175ms左右,同模型框架单次访问推理时间缩减至40ms左右)。本文仅以本次部署服务经验分享给诸多受制于python性能问题的伙伴,希望有所帮助。
二、问题发现
组内原算法服务一直采用python-backend的镜像部署方式,将算法模型包装成接口形式,再通过Flask外露,打入docker中启动服务,但是发现推到线上接口响应时间过长,非常影响用户体验,于是想做出改进。python后端部署一般存在以下问题:
1.性能问题: ◦由于python是一种解释语言,因此对比于其他编译语言(如C,C++或go)要慢很多,这对于要求高性能或者低延迟快速响应的线上服务很不友好,用户体验很差。 ◦GIL全局锁限制,多线程困难,限制了高并发能力,限制程序性能。 ◦python内存占用过多,资源浪费。 2.部署复杂: ◦自训练/自搭建算法模型往往需要一系列的相关依赖和系统库,如果利用python环境直接部署至线上,则必须解决将所有依赖库同步打包至对应容器中,并很可能需要额外解决不同库版本冲突问题,十分麻烦。为了解决上述困扰,我们经过调研行业内其他实践经验,决定摒弃传统镜像部署方式,摆脱python部署环境,换用triton部署算法模型。
三、部署实例
本试验通过fine-tune的Bert模型进行文本分类任务,并通过九数算法中台包装的triton部署框架部署至公网可访问,以下介绍了我们团队部署的全流程和途中踩到的坑,以供大家快速入手(以下均以Bert模型为例):
step 1: 将训练好的模型保存为onnx或torchscript(即.pt)文件格式。据调研行业经验,onnx一般用于cpu环境下推理任务效果较好,.pt文件在gpu环境下推理效果较好,我们最终选择了将模型转化为.pt文件。代码例子如下:
import torch
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('./pretrained-weights/bert-base-chinese')
model = BertForSequenceClassification.from_pretrained('./pretrained-weights/bert-base-chinese', num_labels=10)
# Trace the wrapped model
# input_ids和attention_mask来自tokenizer, 具体可看一下torch.jit.trace用法
traced_model = torch.jit.trace(model, (input_ids, attention_mask))
traced_model.save("./saved_model_torchscript_v3.pt")本段代码借用了torch.jit.trace的存储方式,输入是文本经过tokenizer之后的input_ids和attention_mask,输出是未经softmax处理的线性层。我们尝试将softmax部分包装进模型中一起打包成pt文件,使模型能够直接吐出分类类别,方案是外层再包装一层forward,代码例子如下:
class BertSequenceClassifierWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model.cuda()
def forward(self, input_ids, attention_mask):
outputs = self.model(input_ids=input_ids.cuda(), attention_mask=attention_mask.cuda())
# Apply softmax to the logits
probs = softmax(outputs.logits, dim=-1)
# Get the predicted class
predicted_class = torch.argmax(probs, dim=-1)
return predicted_class
wrapped_model = BertSequenceClassifierWrapper(model)
traced_model = torch.jit.trace(wrapped_model, (input_ids, attention_mask))
traced_model.save("./saved_model_torchscript_v3.pt")然而,参考于行业内实践,我们没有选择将tokenizer部分包装至模型内部,这是因为torchscript仅接受数组类型输入而非文本。最终,我们封装的模型输入为input_ids和attention_mask,输出为分类结果(标量输出)。
【注】:坑点:
◦转onnx需要额外安装transformers-onnx包,需要sudo权限,九数上不能执行,建议本地转换。 ◦对于.pt类型文件,当前九数triton部署仅支持gpu方式推理方式,不支持cpu推理,且torch版本有强要求限制 torch ==1.10.0,cuda11.2(更高版本似乎也可),故我们在保存时必须要在torch ==1.10.0,cuda11.2环境下生成pt文件,不然会部署失败。 ◦转pt文件时建议使用torch.jit.trace而非torch.jit.script,后者经常出现引擎不兼容问题。step 2: 将.pt文件存放在九数磁盘目录下指定位置,注意,目录格式需要严格按照要求,具体可参考九数帮助文档。
目录格式如下(其中model.pt即为我们训练好的模型):
pytorch-backend-online
|-- pytorch-model
| |-- 1
| | |-- model.pt
| `-- config.pbtxtconfig.pbtxt配置如下:
name: "pytorch-model"
platform: "pytorch_libtorch"
input [
{
name: "INPUT__0"
data_type: TYPE_INT64
dims: [1, 512]
},
{
name: "INPUT__1"
data_type: TYPE_INT64
dims: [1, 512]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_INT64
dims: [1, 1]
}
]
instance_group [
{
count: 1
}
]配置中,我们需要指定输入和输出的维度以及数据类型。注意,数据类型指的是每个可迭代对象的类型(比如512维向量每个维度都是int64)。在本实例中,我们定义了两个输入均为1*512维向量,输出为一个标量。
step 3: 模型注册。需要到九数上注册你的模型,然后才能部署,方式如下:
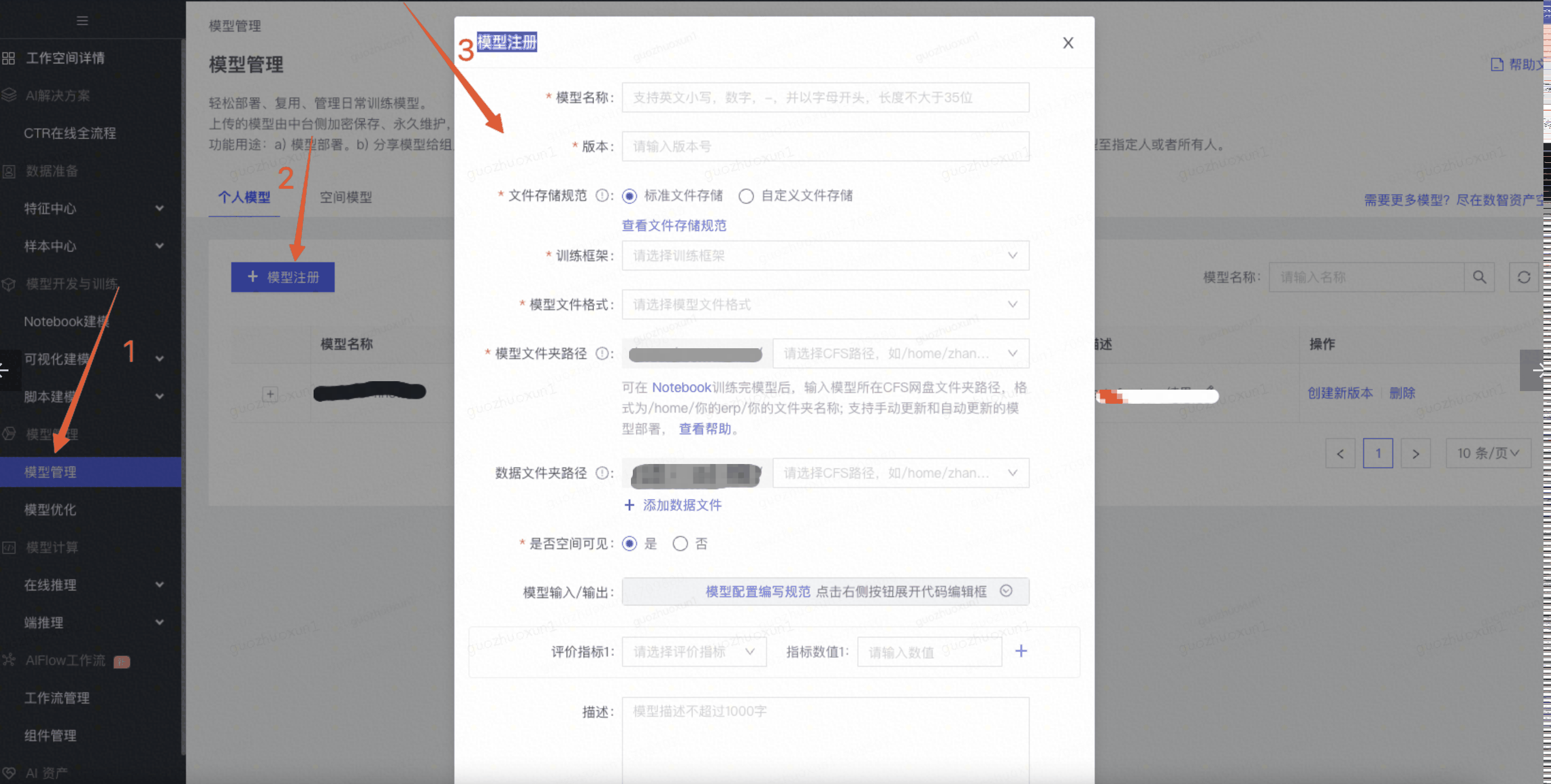
模型注册表填写如下:
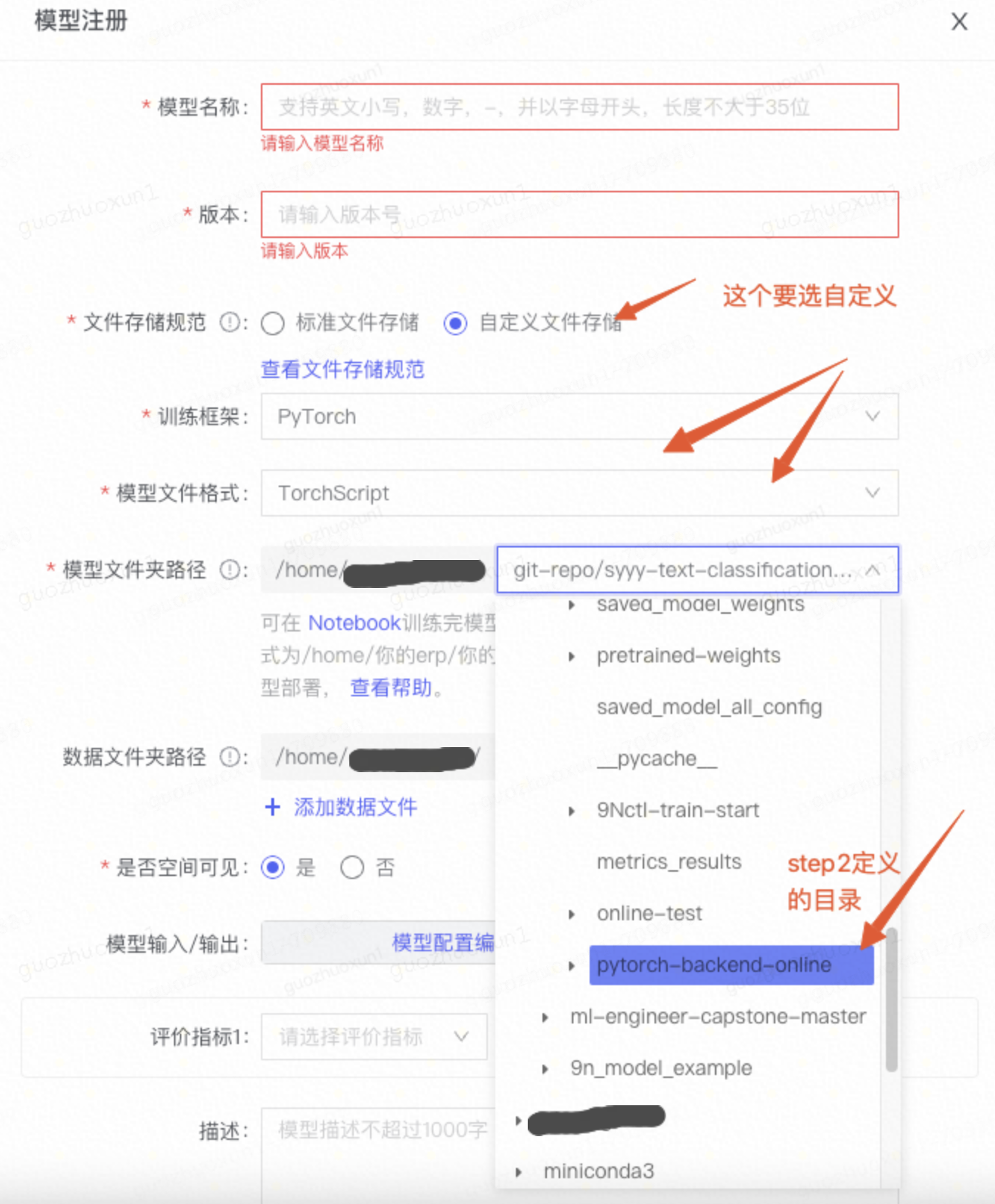
坑点:图中step2定义的一级目录,比如 /home/{erp}/xxx/xxx/xxx。
step 4: 模型注册好之后,就可以在注册好的模型下点击:部署-测试
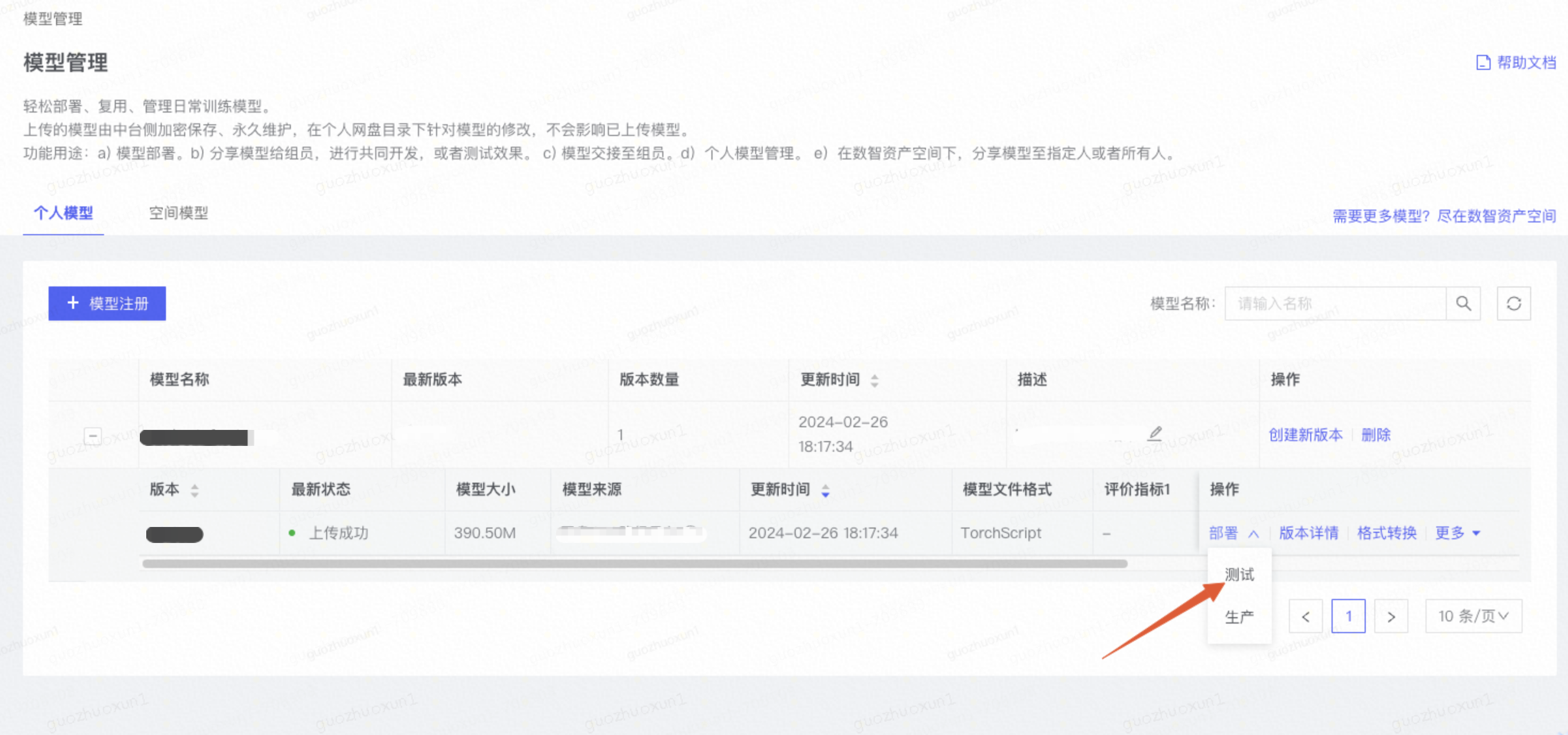
然后需要填写UI界面的信息。
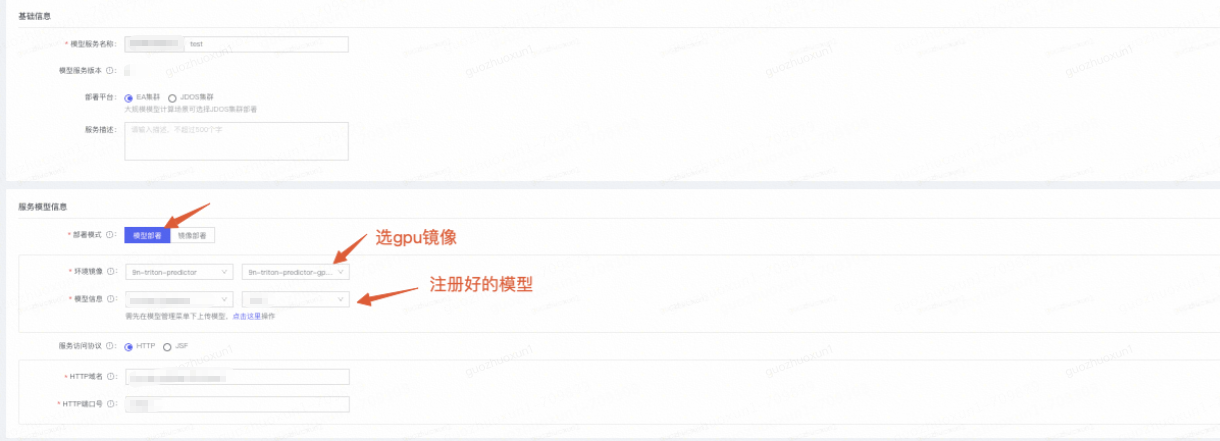
到这里,如果模型没有问题,部署就是成功了~
step 5: 测试端口通不通。如果是测试环境,我们可以通过post接口在notebook中测试接口通不通,测试demo如下:
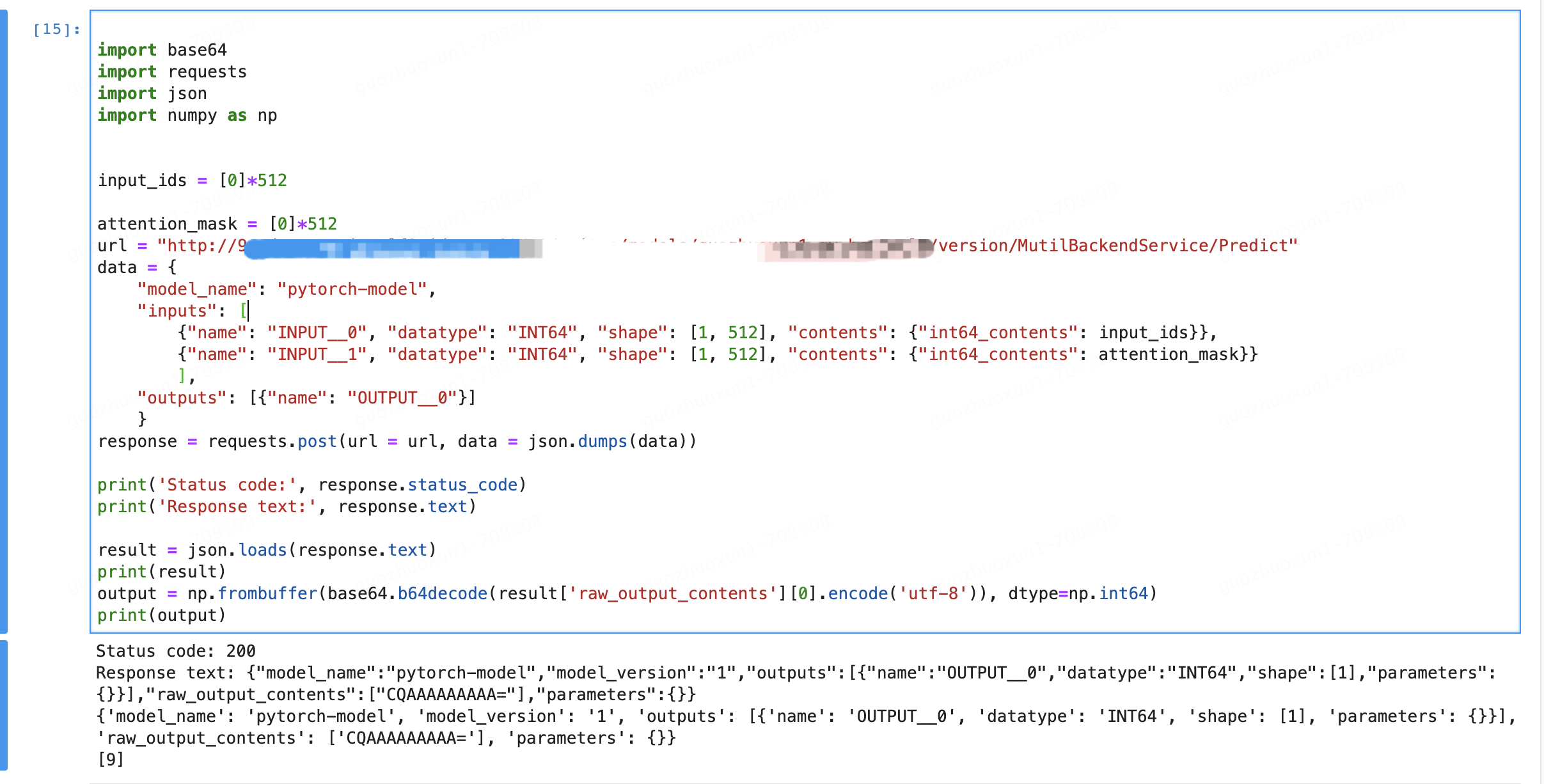
URL来自获取方式如下:

如果测试没有问题,就可以转生产了~配置好域名和端口就可以公网访问了。至此,triton框架部署torchscript方式完结。