基于PyTorch框架的多层全连接神经网络实现MNIST手写数字分类
简单的三层全连接神经网络
导入了PyTorch相关的库,定义了一个名为SimpleNet的类,继承自nn.Module,这个神经网络有三个全连接层,分别是layer1、layer2和layer3。在初始化函数__init__中,指定了输入维度in_dim、两个隐藏层的神经元数量n_hidden_1和n_hidden_2,以及输出维度out_dim。每个全连接层的结构是一个线性变换。在forward函数中,输入x通过每一层全连接层并经过激活函数后得到输出。最终返回神经网络的输出。
import torch
import torch.nn as nn
from torch.autograd.variable import Variable
import numpy as np
# 定义三层全连接神经网络
class SimpleNet(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(SimpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
添加激活函数
# 添加激活函数,增加网络的非线性
class Activation_Net(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Activation_Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim, n_hidden_1), nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2)
)
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
添加批标准化
隐藏层后面添加了批量归一化层(Batch Normalization)。该模型的输入维度为in_dim,第一个隐藏层的神经元数量为n_hidden_1,第二个隐藏层的神经元数量为n_hidden_2,输出层的维度为out_dim。
在forward函数中,输入数据x首先经过第一个隐藏层self.layer1,然后经过批量归一化层和激活函数,接着通过第二个隐藏层self.layer2,再次经过批量归一化层和激活函数,最后经过输出层self.layer3。最终返回神经网络的输出。
class Batch_Net(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Batch_Net, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(n_hidden_2, out_dim)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
批标准化一般放在全连接层的后面,非线性层(激活函数)的前面
训练网络
- 导入需要用的包
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import net
- 定义超参数
# 超参数 Hyper parameters
batch_size = 64
learning_rate = 1e-2
num_epochs = 20
- 数据预处理
# 数据预处理
data_tf = transforms.Compose(
[
# 将图片转换成PyTorch中处理的对象Tensor,在转换的过程中自动将图片标准化,即Tensor的范围是0~1
transforms.ToTensor(),
# 第一个参数是均值,第二个参数是方差,做的处理就是减均值,再除以方差
transforms.Normalize([0.5], [0.5])
]
)
- 导入数据集
# 下载训练集MNIST手写数字训练集
train_dataset = datasets.MNIST(
root='./data',
train=True,
transform=data_tf,
download=True
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=data_tf
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
- 导入网络
# 导入网络
model = net.SimpleNet(28 * 28, 300, 100, 10)
if torch.cuda.is_available():
model = model.cuda()
# 定义损失函数和优化方法
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
- 训练网络
# start train net
model.eval() # 将神经网络模型设置为评估模式,这意味着模型将不会进行梯度计算和参数更新
eval_loss = 0 # 初始化评估损失和评估准确率为0
eval_acc = 0
for data in text_loader: # 历测试集数据加载器中的每个数据
img, label = data # 从数据中获取图像和标签
img = img.view(img.size(0), -1) # 将图像数据展平以便输入到神经网络模型中
if torch.cuda.is_available():
with torch.no_grad():
img = img.cuda()
label = label.cuda()
else:
with torch.no_grad():
img = img
label = label
out = model(img) # 将图像数据输入到神经网络模型中进行前向传播,得到输出
loss = criterion(out, label) # 计算模型输出和标签之间的损失
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print(
'Text Loss:{:.6f},ACC:{:.6f}'.format(
eval_loss / (len(text_dataset)),
eval_acc / (len(text_dataset))
)
)
在较新版本的PyTorch中,num_correct.data[0]已经被弃用,这里使用num_correct.item()来获取Python数值类型的正确预测数量。
在旧版本中,volatile=True用于告诉PyTorch不需要计算梯度,因此在推断阶段可以提高运行效率。然而,由于volatile参数已被移除,这里使用torch.no_grad()上下文管理器来达到相同的效果。
实现
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import mnist
import matplotlib.pyplot as plt
import torchvision
from torchvision.transforms import ToPILImage
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
batch_size =32
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 加载数据集
train_set = mnist.MNIST('./data', train=True,
transform=transform, download=False)
test_set = mnist.MNIST('./data', train=False,
transform=transform, download=False)
train_loader = DataLoader(dataset=train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_set, batch_size=batch_size, shuffle=False)
# 定义模型
model = CNN().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(),
lr=0.01, momentum=0.5)
# 训练函数
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader):
images, labels = data
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (batch_idx + 1) % 300 == 0:
print('[%d,%d],loss is %.2f' %
(epoch, batch_idx, running_loss / 300))
running_loss = 0
# 测试函数
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predict = torch.max(outputs, dim=1)
correct += (labels == predict).sum().item()
total += labels.size(0)
print('correct/total:%d/%d,Accuracy:%.2f%%' % (correct, total, 100 * (correct / total)))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
再实现MINIST手写数字分类
- 准备训练集
- 构建神经网络模型
- 损失函数和优化器
- 训练神经网络
- 测试神经网络
首先创建一个工程来保存我们的数据和代码,data文件夹负责存放数据集, model.py用于保存神经网络模型, test.py用于测试一些代码, recognize_digit.py是工程的主要控制代码

一.准备数据集
batch_size_train = 64
batch_size_test = 1000
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
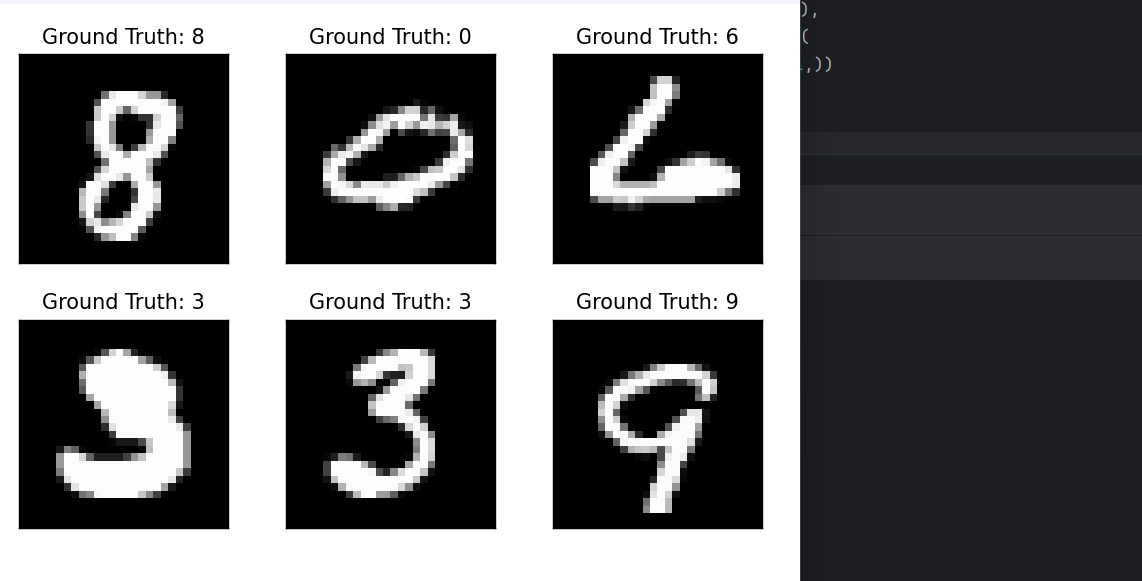
让我们在test.py中看看一批测试数据由什么组成
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape)

example_targets是图片实际对应的数字标签

这意味着我们有1000个例子的28x28像素的灰度
我们可以用matplotlib这个库显示其中一些:
import matplotlib.pyplot as plt
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
二.构建神经网络
下面就正式开始构建我们的网络模型了。
打开model.py文件,在类的初始化函数中构建神经网络模型
# 导入需要的包
import torch
from torch import nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x.to(device)), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
这样我们模型也构建好了。接下来我们回到一开始的recognize_digit.py文件,导入这个模型
from model import Net
实例化模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
network = Net().to(device)
到这里, 神经网络模型也构建完成了。我们可以在test.py文件内板鞋如下代码来简单验证一下神经网络是否构建正确
from model import Net
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
network = Net().to(device)
one = torch.zeros((64, 1, 28, 28)) # 创建一个张量
out = network(i) # 将张量one传递给神经网络, 得到out
print(out.shape) # 打印输出张量的形状以验证网络的输出大小是否符合预期
对应的输出如下:

三.准备损失函数和优化器
损失函数使用交叉熵损失函数
交叉熵是统计学中的一个概念,用于衡量两个概率分布的差异性,而我们神经网络输出的十个数字刚好可以看作一个概率分布。这样,利用交叉熵就可以很容易的衡量出当前的输出与目标输出的差距是多少。
# 交叉熵损失函数
loss_func = torch.nn.CrossEntropyLoss()
接下来是优化器,我们选择SGD优化器
# 优化器
learning_rate = 0.01
momentum = 0.5
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
四.训练与测试神经网络
n_epochs = 3
log_interval = 10
# 模型训练
train_losses = []
train_counter = []
test_losses = []
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
def train(epoch):
network.train() # 将神经网络设置为训练模式
for batch_idx, (data, target) in enumerate(train_loader): # 遍历训练数据集
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 梯度清零
output = network(data) # 向前传播
loss = F.nll_loss(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
if batch_idx % log_interval == 0: # 每隔一定批次打印一次信息
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item()) # 记录训练损失
train_counter.append(
(batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset))) # 记录训练步数
torch.save(network.state_dict(), '../model.pth') # 保存模型
torch.save(optimizer.state_dict(), '../optimizer.pth') # 保存优化器状态
def test():
network.eval() # 将神经网络设置为评估模式
test_loss = 0 # 初始化
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
train(1)
test() # 不加这个,后面画图就会报错:x and y must be the same size
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
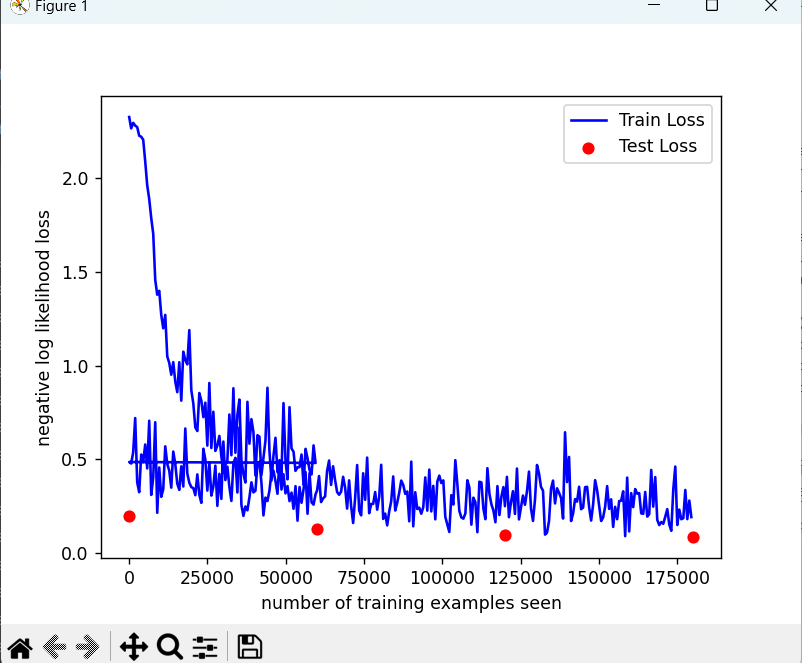
我们来画一下训练曲线。
import matplotlib.pyplot as plt
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()