使用SQL(Structured Query Language)对数据库/数据仓库进行查询分析操作,几乎成了研发工程师和数据分析师的“家常便饭”,然而要写出高效、清晰、优雅的SQL脚本并非易事。随着大语言模型(LLM)技术的普及,借助大模型微调(Fine Tuning)等技术将自然语言自动翻译为SQL语句(NL2SQL/Text2SQL)便成了非常流行的解决方案,相关的工具框架(Chat2DB、DB-GPT等)也是层出不穷。
同样的,在图数据库领域也存在相似的问题,甚至更为严峻。相比于SQL相对成熟的语法标准(SQL2023),图查询语言尚未形成成熟的统一标准,目前是多种查询语法并存的状态(GQL、PGQ、Cypher、Gremlin、GSQL等),上手门槛高,因此更需要借助大语言模型的自然语言理解能力,降低图数据库查询语言的使用门槛。
1. 图表融合:SQL+GQL
TuGraph计算引擎TuGraph Analytics创新性地设计了SQL+GQL融合语法,以解决图表混合分析场景的业务诉求,将图上的分析计算能力有机地融合到传统的SQL数据处理链路内,实现了图引擎上一体化的图数据建模、图数据集成、图存储、图交互式分析能力。
TuGraph Analytics的SQL+GQL融合语法典型形式为“SELECT-FROM-WITH-MATCH-RETURN”结构,通过GQL语法的“MATCH-RETURN”语法单元,为SQL处理提供数据子视图,方便传统数据分析师对数据的进一步处理。

通过以上的语法设计,可以满足多样化的图表融合处理的诉求。点边数据源提供构图数据,Request数据源提供图计算触发的起点集合。
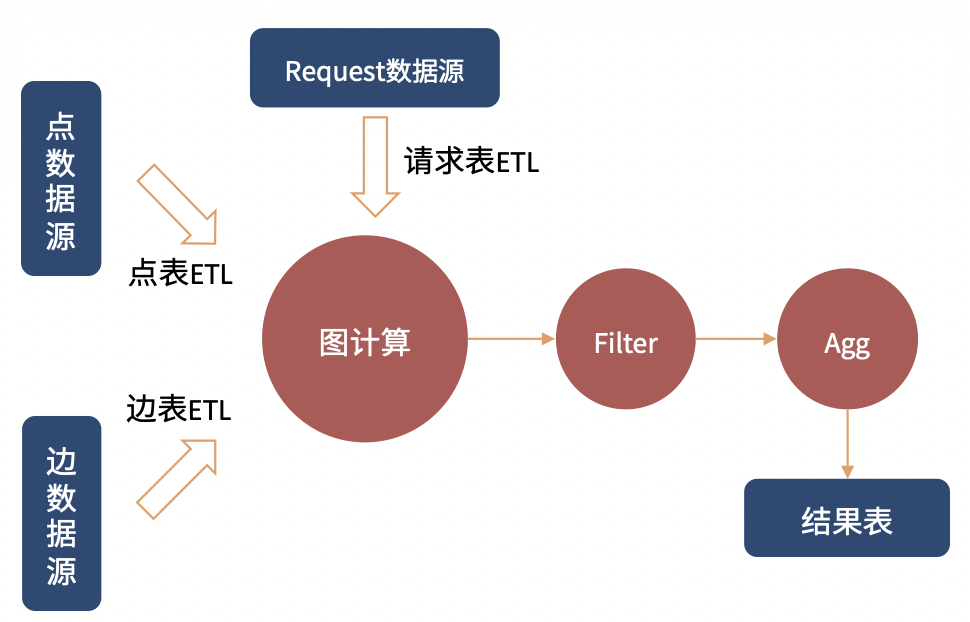
不同的数据源处理模式的组合,形成了多种“流”与“图”的混合计算形态。而SQL+GQL的融合语法设计,可以很好地表达多样化的计算模式。
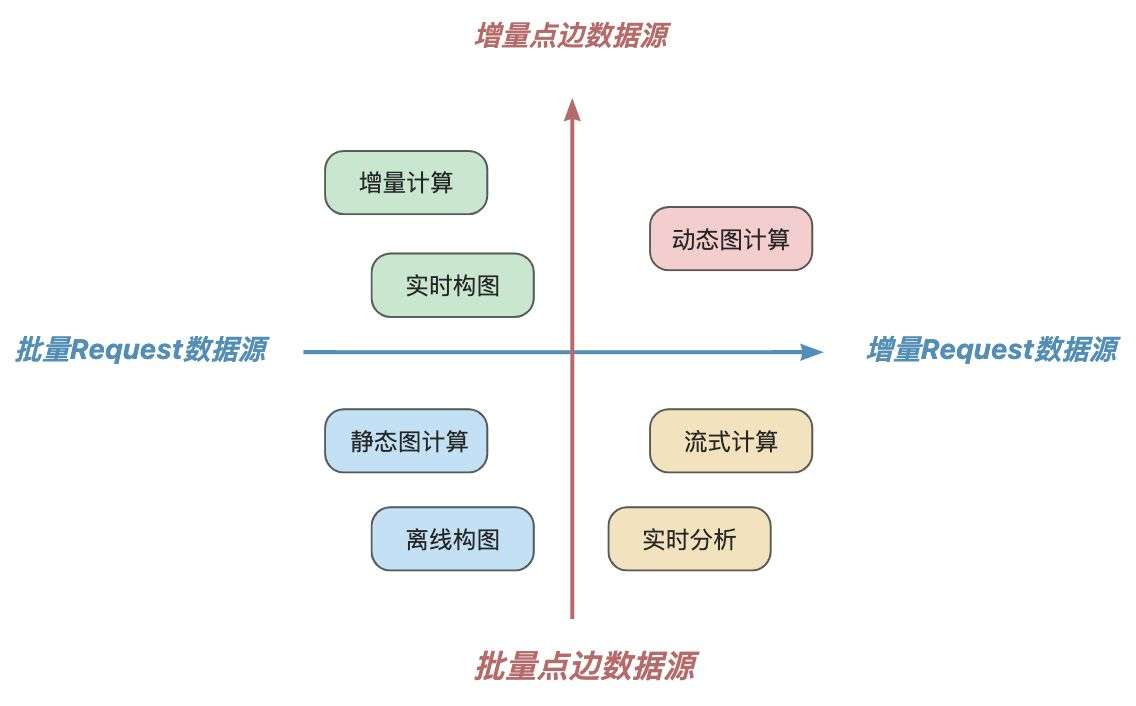
2. 与图对话:ChatTuGraph
我们不否认SQL+GQL融合语法是一个创见性的语言设计,但这并不能解决“新型图查询语言的高上手门槛”这个通病,因此,借助于LLM微调实现专有的图查询语言模型,通过自然语言的方式与图数据交互,实现“与图对话(Chat-to-Graph/Chat-TuGraph)”。
我们初步构想了面向未来的图数据库智能化能力,至少具备以下产品形态:
- 智能交互分析:通过Agent发送图查询指令,同步获取图数据结果。
- 智能数据变更:通过Agent发送图变更指令,修改图数据,获取修改状态(成功与否、影响行数等)。
- 智能任务处理:通过Agent发送图处理任务指令,触发异步图计算任务,获取图任务运行状态。
- 智能运维管控:通过Agent发送管控指令,实时获取图数据库状态(流量、负载、慢查询等),操纵图数据库实例(启停、伸缩、切流等)。
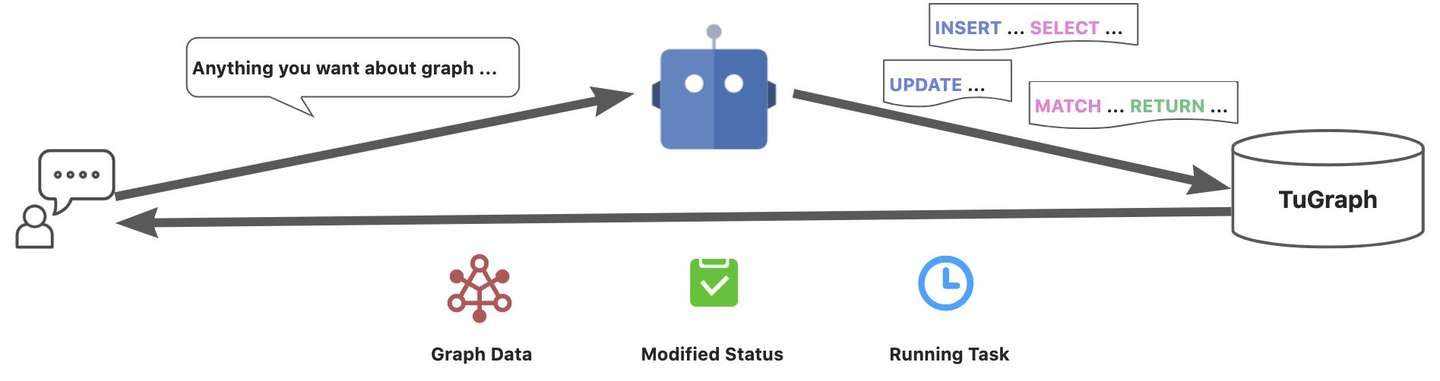
以上设想是一个比较长远的规划,仰望星空后,我们还是要脚踏实地,回归当下,从最基本的“智能交互探索”开始,构建Text2GQL能力。
3. 模型微调:Text2GQL
以下对话场景,便是我们希望第一阶段达成的目标。
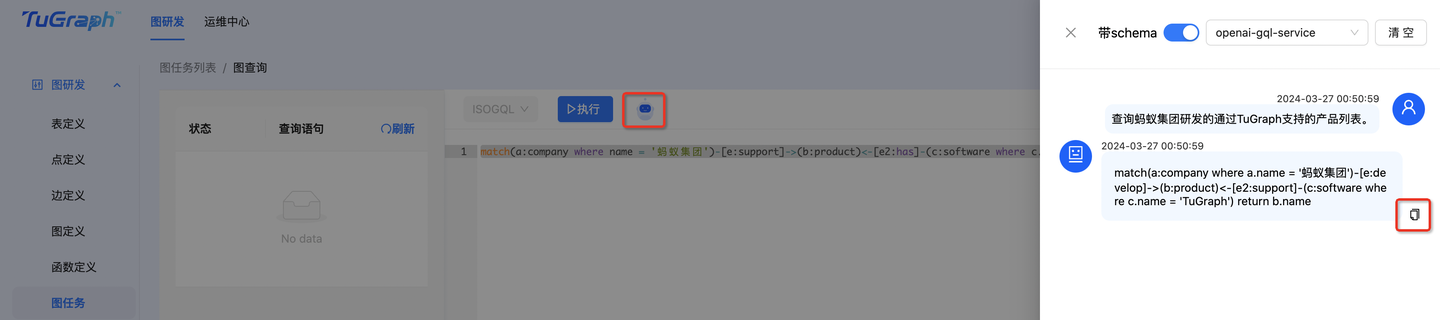
Me: 查询蚂蚁集团研发的通过TuGraph支持的产品列表。
ChatTuGraph: match(a:company where a.name = '蚂蚁集团')-[e:develop]->(b:product)<-[e2:support]-(c:software where c.name = 'TuGraph') return b.name
3.1 语料生成
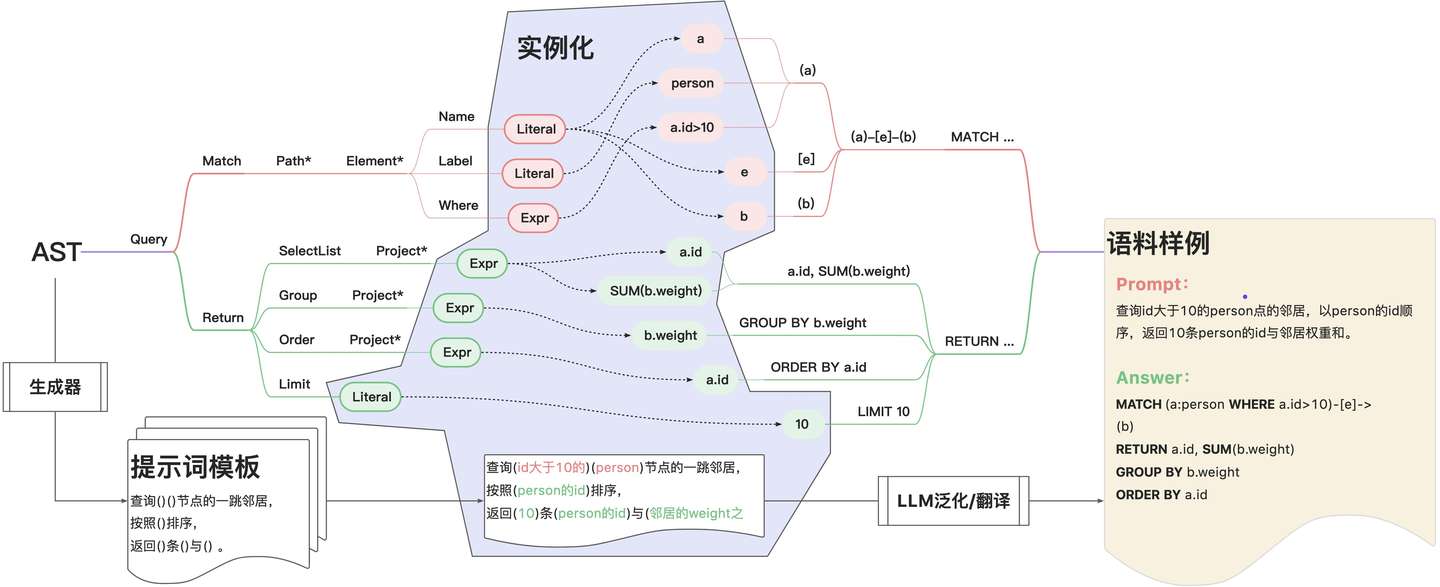
众所周知,要实现模型微调,构建语料是第一步,也是最关键的一步,语料的质量和丰富度会直接决定微调模型的预测效果。但是前面提到,由于图查询语言标准的不够成熟,想要获取现有的GQL语料是一件很困难的事情。另外,SQL+GQL语法更是TuGraph的“独创”,业务语料的丰富度更低。这种情况下,我们只能“自力更生”想办法创造语料,于是就有了“语法制导的语料生成策略”。
该策略的具体思想如下:
- GQL抽象语法树(AST)展开后的基本形式就是表达式(Expr),常量(Literal)也是一种特殊的表达式。
- 通过设计表达式实例生成器,批量生成并组合出大量的AST实例,得到GQL语句样本。
- 特定的AST可以通过通用生成器产生对应的提示词模板,提示词模板随着AST实例化形成提示词文本。
- 特殊的不适合通过生成器生成的提示词模板可以通过人工构造。
- 初步生成的提示词文本可以借助LLM(如GPT-4)进一步泛化和翻译,生成多样的自然语言提示词文本。
3.2 模型训练
构建完语料后,参考OpenAI官方模型微调手册,可以轻松实现模型微调(当然,氪金是必不可少的……)。
这里我们基于模型gpt-3.5-turbo-1106进行微调,首先需要将语料按照如下格式进行处理:
{
"messages": [
{
"role": "system",
"content": "你是TuGraph计算引擎的DSL专家"
},
{
"role": "user",
"content": "查找与person点有关联的公司节点,并按规格分组返回。"
},
{
"role": "assistant",
"content": "match(a:person)-[e:belong]-(b:company) return b.scale group by b.scale"
}
]
}
进入OpenAI模型微调页面,上传格式化后的语料文件(一般以.jsonl结尾),设置模型前缀,创建微调任务。
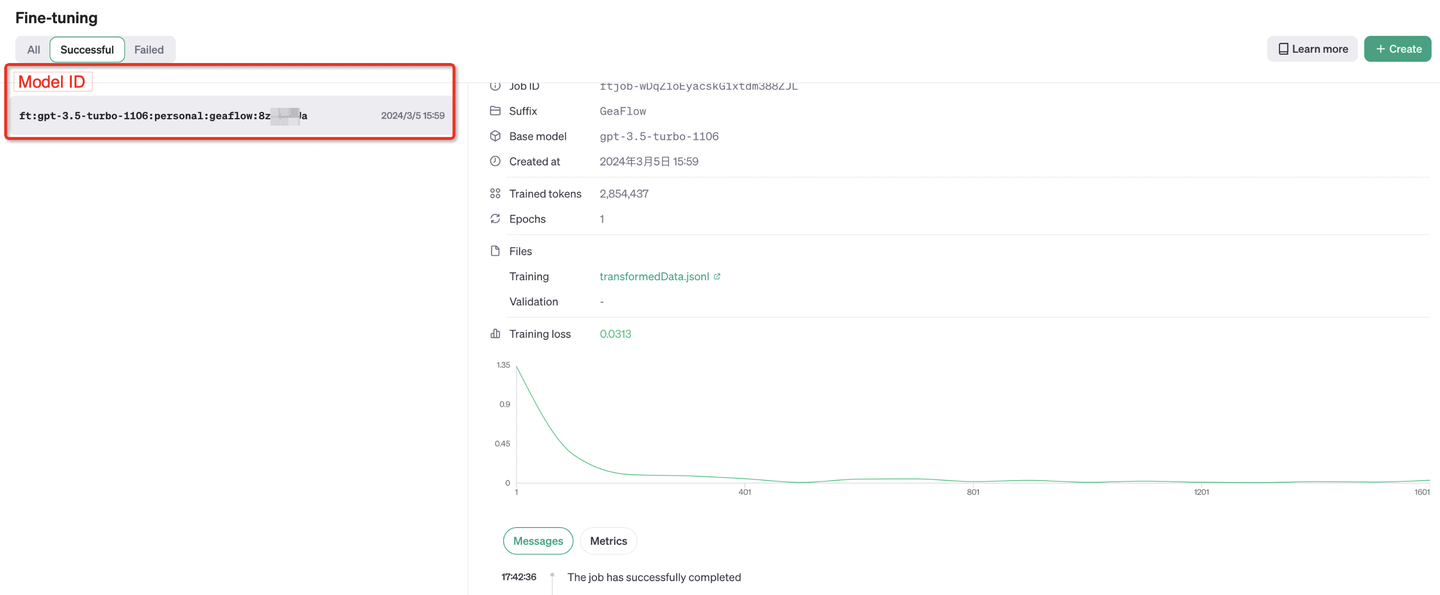
模型微调完成后,可以看到最终的模型ID,形如:ft:gpt-3.5-turbo-1106:personal:<Suffix>:<Id>。
验证微调模型也很简单,调用OpenAI的Chat Completion API时传递微调的模型ID即可。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-1106:personal:geaflow:8z·····a",
temperature=0,
messages=[
{
"role": "user",
"content": "查询蚂蚁集团研发的通过TuGraph支持的产品列表。"
}
]
)
print(completion.choices[0].message.content)
3.3 本地部署
如果不想“斥资”使用OpenAI的微调服务的话,我们也提供了开源的基于CodeLlama-7b-hf微调后的Text2GQL模型CodeLlama-7b-GQL-hf给大家测试使用(模型量化后可以在Mac上本地运行,没有4090的小伙伴也不用怕了v)。
首先,下载HuggingFace上的模型文件到本地(记得先安装git-lfs),如/home/huggingface。同时为了方便大家快速部署本地大模型服务,我们提供了预先安装好CUDA的Docker镜像。
$ git lfs install
$ git clone https://huggingface.co/tugraph/CodeLlama-7b-GQL-hf /home/huggingface
$ docker pull tugraph/llam_infer_service:0.0.1
启动Docker容器,将模型文件目录挂载到容器目录/opt/huggingface,并开放8000模型服务端口。
$ docker run -it --name text2gql-server \
-v /home/huggingface:/opt/huggingface \
-p 8000:8000 \
-d llama_inference_server:0.0.1
进入Docker容器,对模型文件进行转换,最终会看到转换后的模型文件ggml-model-f16.gguf。
$ docker exec -it text2gql-server /bin/bash
> python3 /opt/llama_cpp/convert.py /opt/huggingface
> ...
> Wrote /opt/huggingface/ggml-model-f16.gguf
默认转换后的模型精度为F16,模型大小为13.0GB。正常情况下Mac本地内存无法支撑如此大的模型推理,需要对模型做精度裁剪(当然如果你有4090/在带GPU卡的ECS上运行,可以跳过该步骤……)。
> # q4_0即将原始模型量化为int4,模型大小压缩至3.5GB
> /opt/llama_cpp/quantize /opt/huggingface/ggml-model-f16.gguf /opt/huggingface/ggml-model-q40.gguf q4_0
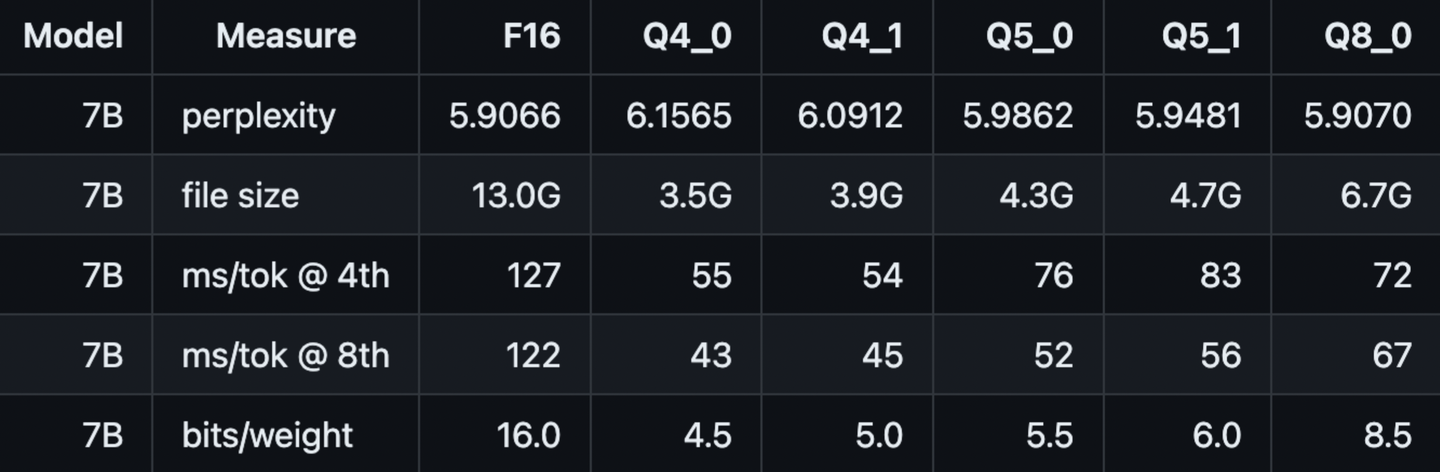
不同规格的量化参数对应的模型规模如下:
最后,启动模型推理服务,绑定0.0.0.0:8000地址,否则容器外无法访问该服务。如果对模型做过量化,记得更新-m参数的值。
> /opt/llama_cpp/server --host 0.0.0.0 --port 8000 -m /opt/huggingface/ggml-model-f16.gguf -c 4096
服务启动完成后,可以对本地模型服务做简单的对话测试。
$ curl http://127.0.0.1:8000/completion \
-H "Content-Type: application/json" \
-d '{"prompt": "查询蚂蚁集团研发的通过TuGraph支持的产品列表。","n_predict": 128}'
4. 平台接入:Console+LLM
TuGraph Analytics的Console平台提供了初步的大模型能力的集成和对话能力,大家可以下载最新的代码部署体验。
登录Console后,切换到“系统模式”,进入“系统管理-模型管理”注册模型服务,模型类型可选择OPEN_AI或LOCAL,分别对应上述的OpenAI微调模型和本地部署模型。注册完成后,可以做简单的可用性测试。
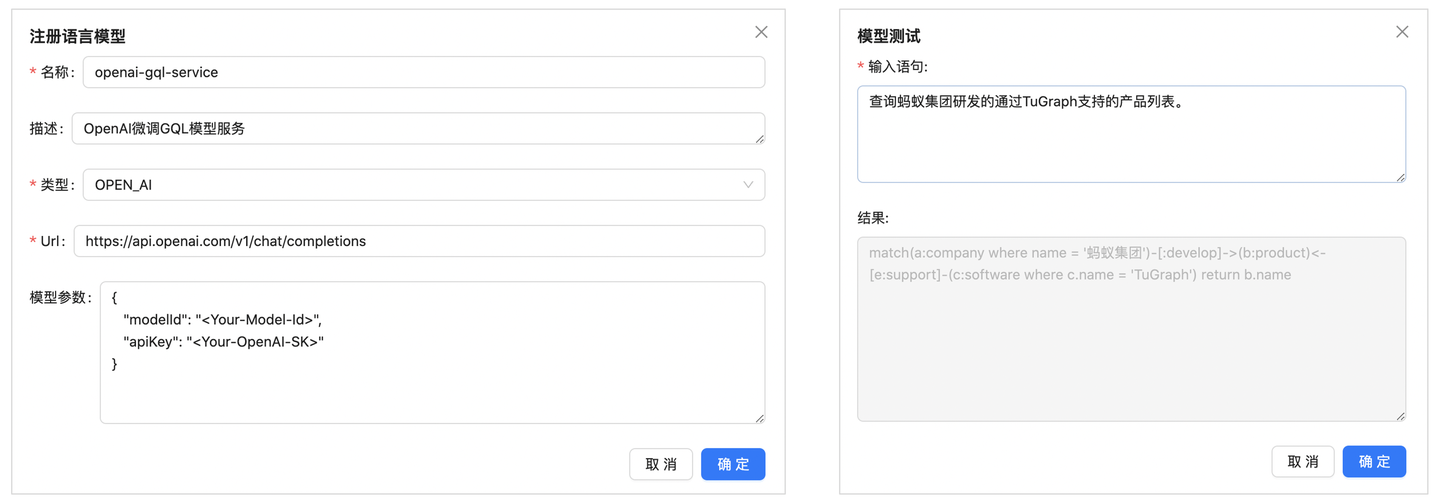
切换到“租户模式”,选择一个图查询任务,进入查询页面。点击“执行”按钮右侧的机器人图标,即可开启对话。对话回答的GQL语句可以点击复制按钮一键执行。
5. 借图发声:Graph+AI
截至此时,借助于大模型微调技术,实现自然语言转图查询,仅仅是一个开端。未来我们相信“图与AI”还有更多的结合场景值得去探索和尝试。
- 首先,当前的模型微调训练语料仍不够完备,真实测试中还是会出现推理幻觉和不准确的问题。进一步丰富训练语料以及在GQL标准不完善的情况下,构建模型的有效性验证方案是亟待解决的问题。
- 其次,面向GQL查询分析场景的微调只解决了图上自然语言交互式分析的问题,对SQL+GQL融合语言中的数据变更、任务提交能力并未覆盖。当然这部分能力也需要TuGraph引擎能力不断迭代改进以获得支持,才能最大化地丰富自然语言操纵图数据库的场景。
- 再次,面向图数据库的智能化运维管控也是一个很值得研究的方向。在以LLM为基础,Agent大行其道的环境下,借助AI能力释放基础软件的运维压力,也符合ESG的战略宗旨。
- 另外,借助于图计算技术,为大模型推理提供更准确的知识库,消除模型幻觉,也是当下AI工程技术RAG研究的热门方向。
- 最后,利用AIGC技术,为图应用场景生成更丰富的解决方案,提供高质量的内容输出,将技术红利带入到行业,对图计算技术的普及也大有裨益。
最后的最后,诚邀大家参与本周六(3.30)TuGraph的社区Meetup,大家喝喝茶、吹吹风,一起聊一聊图计算与AI技术。
活动详情:https://mp.weixin.qq.com/s/LaeGge_oExLce23cxUme3g
标签:GQL,模型,微调,ChatTuGraph,对话,SQL,TuGraph,语料 From: https://www.cnblogs.com/fanzhidongyzby/p/18098628/ChatTuGraph