问题建模
异构多智能体战场决策
所有智能体之间在无直接通讯的情况下完全独立决策,分别由不同的程序控制并可以运行在不同的主机上
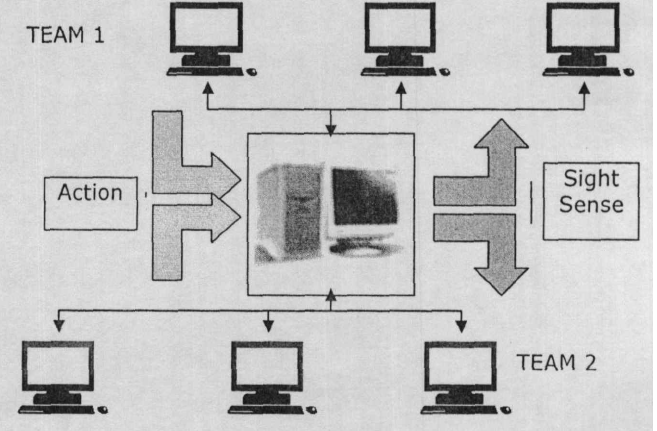
POSG模型给了我们一个更好的理解不确定环境下多智能体规划问题的途径,但在这里问题的规模是最大的挑战。最基本的做法是采用分层设计的思想(Stone P, 1998),将整个规划框架分为三层处理。
战场感知问题
对于初步环境,采取完全信息,即敌我信息完全可观测,这时状态空间为双方所有agent的编号、方位、武器。
对于进阶环境,采取不完全信息,即可观测信息为雷达照射区域,雷达照射区域下方可获取对方agent的编号、方位、武器信息。对于敌方三维信息可采取降维模糊化的手段,方便训练。
感知算法设计1
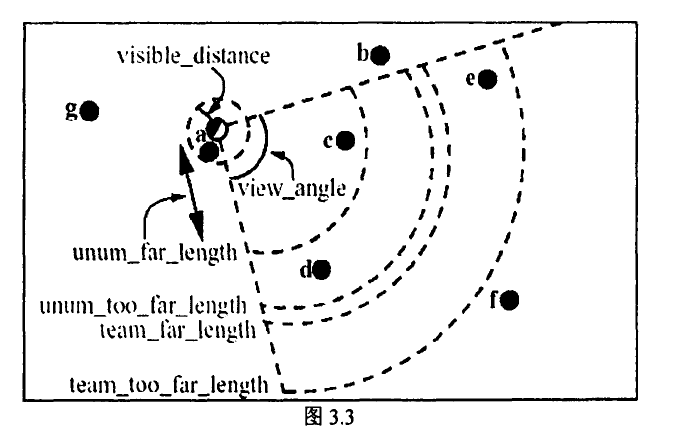
如图所示,当视野中player 距离在team_ far_length内,其身份可识别;
距离在team_ far_ length与team_too_far_ length之间时,身份呈概率可见,概率随着距离的增加而降低
另外,智能体还存在一个对物体的感知距离,见图中的visible distance 内的圆形区域。
对于不在视角内但在这个感知距离内的物体,智能体可以获得其位置信息及物体类型信息
上述部分可观察的机制为世界模型的维护与更新带来了两点问题:
第一,场上可视范围之外的球员无法观察到,这样的情况下无法对其位置速度等信息进行直接同步;
第二,即使处于可视范围内被观察到的球员,智能体仍有可能无法获知其装备类型,为了做同步更新还需要先进行身份确认。
针对第-一个问题的处理方法是给每个物体的状态参量都加入了一个置信度(conf),参量被更新时置信度重置为1.0。 任何周期,当参量没有得到更新时,将对置信度做指数衰减,乘以一个conf_ decay。比如球的conf decay设为0.96,球员的conf_ decay设为0.99.
而针对第二个问题,由于实时决策过程能够分配给底层更新的计算时间非常有限。
雷达感知建模
行为设计问题
切依靠智能体自主决策,从模型给出的原子动作开始,直接去规划出进攻或者防守的策略是不切实际的。
在决策算法的设计中,很自然的引入了中间层的设计。在我们的实现框架中间层又叫做战略层和战术层,是抽象意义的战略行为,典型的比如有结合人类经验抽象出来的迂回、包夹等。
决策行为描述
将指挥决策分解为战役决策和战术决策,按照其层级关系对状态空间和动作空间进行分割。
战役决策针对全局作战态势信息(敌我作战资源伤亡情况、主要打击目标等)下达宏观作战指令,例如,导弹打击、逃避机动、追逐机动、迂回机动、指定未知空域侦察机动等。
战术决策对执行宏观作战指令的作战编组下达微观作战动作,例如,当战役决策层下达“导弹打击”的动作到战术决策层时,战役决策层以歼灭敌方飞机为目标,根据交战双方作战单位数量、阵型等局部作战态势信息,对下属作战单元下达攻击、机动规避等微观作战动作,其他战术决策与此类似。
分层结构
定义 \(BP\) 为战役决策、 \(bp\)为战术决策, 为战役策略,定义 的状态空间、动作空间、反馈奖励为 、 、 ,用 代表在战术决策池内的 个战术策略,定义 的状态空间、动作空间、反馈奖励为 、 、 。
在 时刻, 获取全局战场态势信息 ,基于此时的态势选取 :
假设在 时刻, 根据局部态势信息 选取战术动作 。当其选取的战术指令执行完成后,获得反馈奖励为 和其下一个态势信息 ,同时获得信息序列 存储到回放缓存 中为训练做准备。
战役策略 根据选取的战术策略 :反馈信息计算所选取作战指令 所获取的反馈奖励:
同样,战役策略 得到它的下一个状态 和信息序列 ,存储到回放缓存 中。此时刻为 , 将会根据此时的状态信息进行下一次的战术策略选取。