2024.3.14 Transformer框架+编码器+解码器
预训练----->NNLM----->word2vec------>ElMo--->Attention
NLP(自然语言处理)中预训练的目的,其实就是为了生成词向量
transformer其实就是attention的一个堆叠
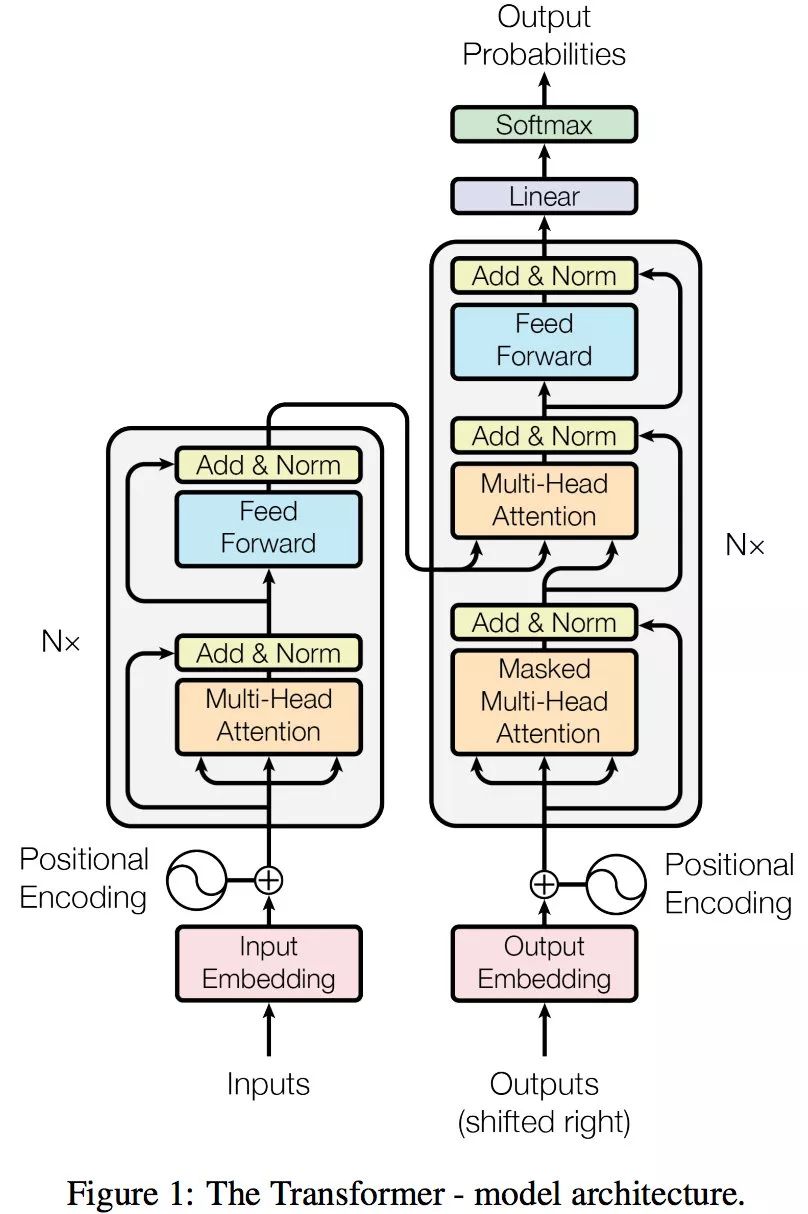
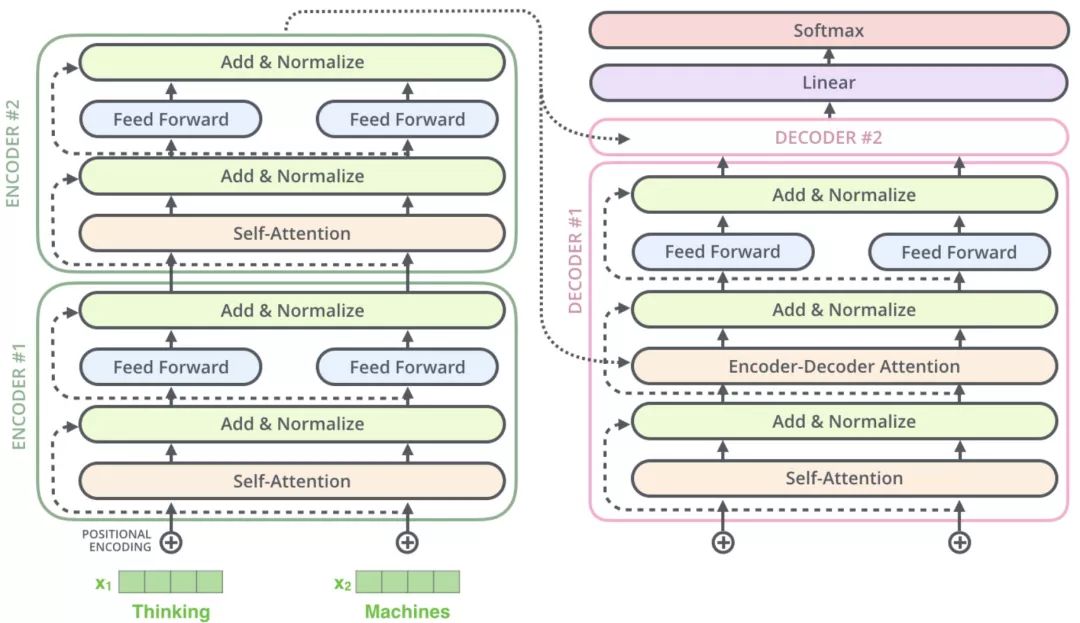
Transformer 的整体框架
[Transformer框架]:对Transformer模型中各个结构的理解(一遍必懂)-CSDN博客

机器翻译流程(Transformer)
上图所示的整体框架乍一眼一看非常复杂,由于 Transformer 起初是作为翻译模型,因此我们以翻译举例,简化一下上述的整体框架:
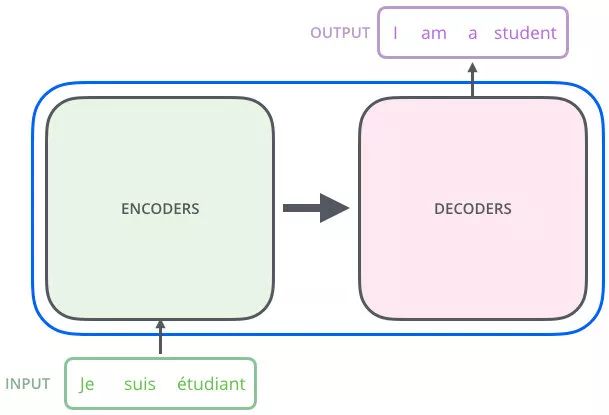
机器翻译流程:给一个输入,给出一个输出(输出是输入的翻译的结果)
例子:我是一个学生-----通过transformer------> I am a student

从上图可以看出 Transformer 相当于一个黑箱,左边输入 “Je suis etudiant”,右边会得到一个翻译结果 “I am a student”。
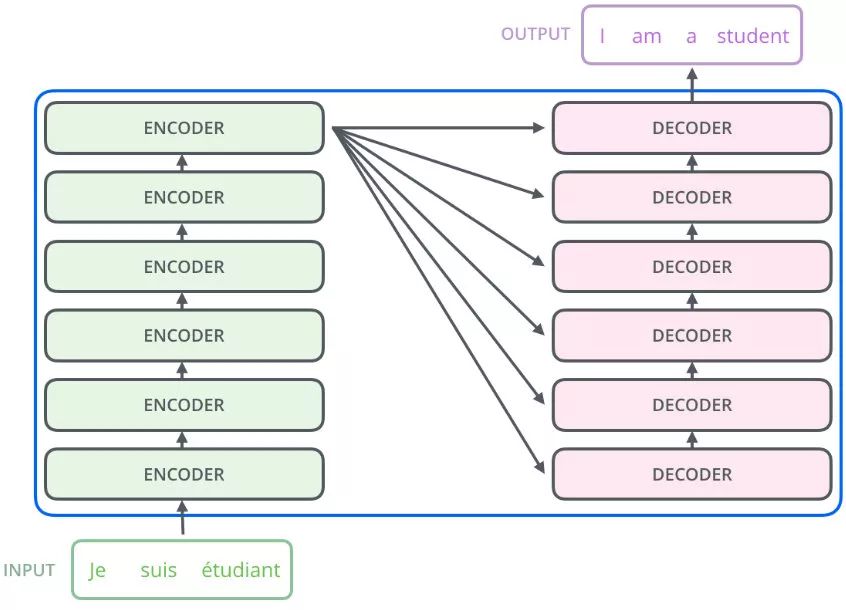
再往细里讲,Transformer 也是一个 Seq2Seq 模型(Encoder-Decoder 框架的模型),左边一个 Encoders 把输入读进去,右边一个 Decoders 得到输出,如下所示:
编码器和解码器
编码器:把输入变成一个词向量------>(Self-Attention)
解码器:获取编码器输出的词向量后,生成翻译的结果
Transformer框架中输入的Nx表示编码器里又有N个小编码器(默认N=6)
通过6个编码器,对此词向量一步一步的强化
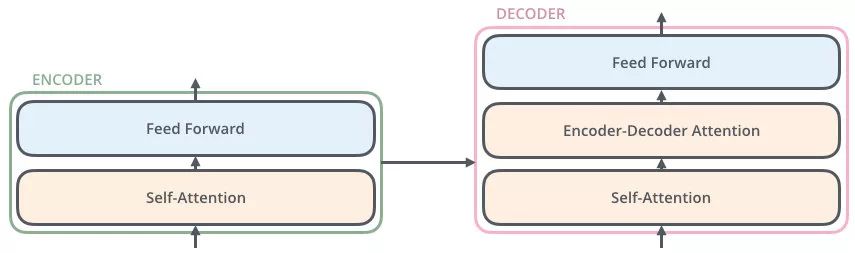
了解Transformer就是了解里面小的编码器和小的解码器
概略图
FFN(Feed Forward):就是一种线性变换;如$w_1x+b_1$---->$w_2((w_1x+b_1))+b_2$
编码器包括两个子层:Self-Attention、Feed Foreward
每个子层的传输过程中都会有一个(残差网络+归一化)
编码器详细图

以机器翻译的例子为例:
Thinking
-->得到绿色的$x_1$(词向量,可以通过one-hot、word2vec获取)+叠加位置编码(给$x_1$赋予位置属性)----->得到黄色的$x_1$
--->输入到Self-attention子层中,做注意力机制($x_1、x_2$拼接起来的一句话一起做Self-attention)------>得到$z_1$($x_1$与$x_1,x_2$拼接起来的句子做了自注意力机制的词向量,表征任然是thinking),也就是说$z_1$拥有了位置特征、句法特征、语义特征的词向量
----->残差网络(避免梯度消失---》$w_2((w_1*x+b_1))+b_2$,如果$w_1,w_2$特别小,乘完之后数字太小),归一化(LayerNorm),做标准化(避免梯度爆炸-----》防止数字之间相差过大),得到粉色的$z_1$
x1作为残差结构的直连向量,直接和z1相加,之后进行 Layer Norm 操作,得到粉色向量z1
- 残差结构的作用:避免出现梯度消失的情况
- Layer Norm 的作用:为了保证数据特征分布的稳定性,并且可以加速模型的收敛
----->Feed Forward,(有激活函数Relu----》Relu($w_2((w_1*x+b_1))+b_2$)),(前面每一步都在做线性变换,$wx+b$,线性变化的叠加永远都是线性变化(线性变化就是空间中平移和伸缩),通过Feed Forward中的Relu做多次非线性变换,这样 的空间变换可以无限拟合任何一种状态了),--->得到$r_1$(是thinking新的表征)
z1经过前馈神经网络(Feed Forward)层,经过残差结构与自身相加,之后经过 LN (归一化)层,得到一个输出向量 r1
- 该前馈神经网络包括两个线性变换和一个ReLU激活函数:FFN(x)=max(0,xW1+b1)W2+b2
x、z、r 都具有相同的维数
Transformer解码器
解码器会接收编码器生成的词向量,然后通过这个词向量去生成翻译结果。
解码器的Self-Attention在编码已经生成的单词
例如:目标词“我是一名学生”-------->masked Self-Attention
训练阶段:
目标词“我是一名学生”是已知的,然后Self-Attention是对目标词做计算
如果不做masked,每次训练阶段都会获得全部消息
如果做masked,Self-Attention第一次对“我”做计算
Self-Attention第二次对“我是”做计算
.........
测试阶段:
-
目标词未知,假设目标词是“我是一个学生”(未知),Self-Attention第一次对“我”做计算
-
Self-Attention第二次对“我是”做计算
-
........
而测试阶段,每生成一点,就获得一点
生成词
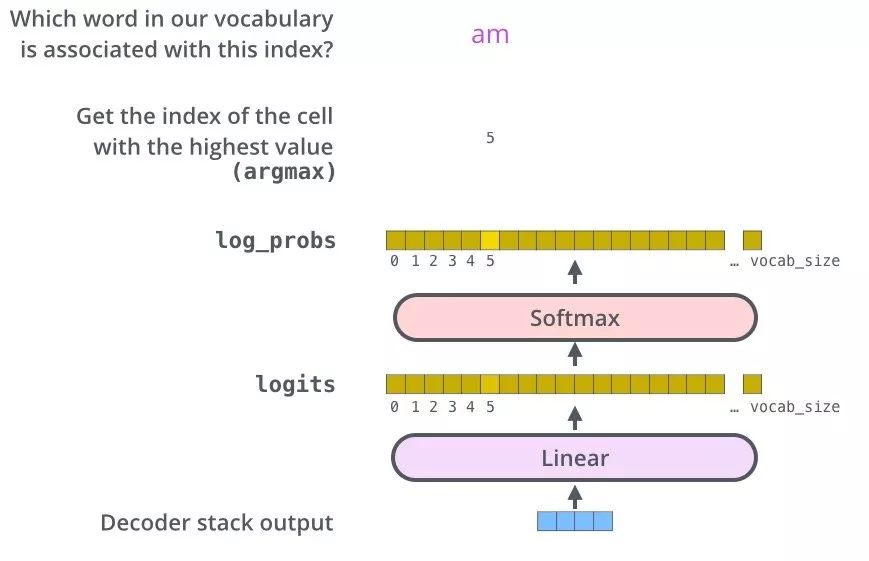
从上图可以看出,Transformer 最后的工作是让解码器的输出通过线性层 Linear 后接上一个 softmax
- 其中线性层是一个简单的全连接神经网络,它将解码器产生的向量 A 投影到一个更高维度的向量 B 上,假设我们模型的词汇表是10000个词,那么向量 B 就有10000个维度,每个维度对应一个惟一的词的得分。
- 之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!
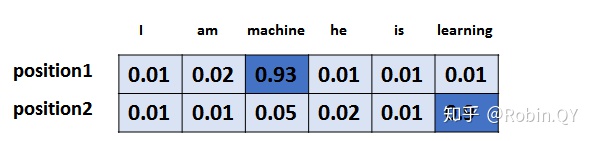
假设词汇表维度是 6,那么输出最大概率词汇的过程如下:
 标签:Transformer,Self,Attention,编码器,解码器,向量
From: https://www.cnblogs.com/adam-yyds/p/18074037
标签:Transformer,Self,Attention,编码器,解码器,向量
From: https://www.cnblogs.com/adam-yyds/p/18074037