TL;DR
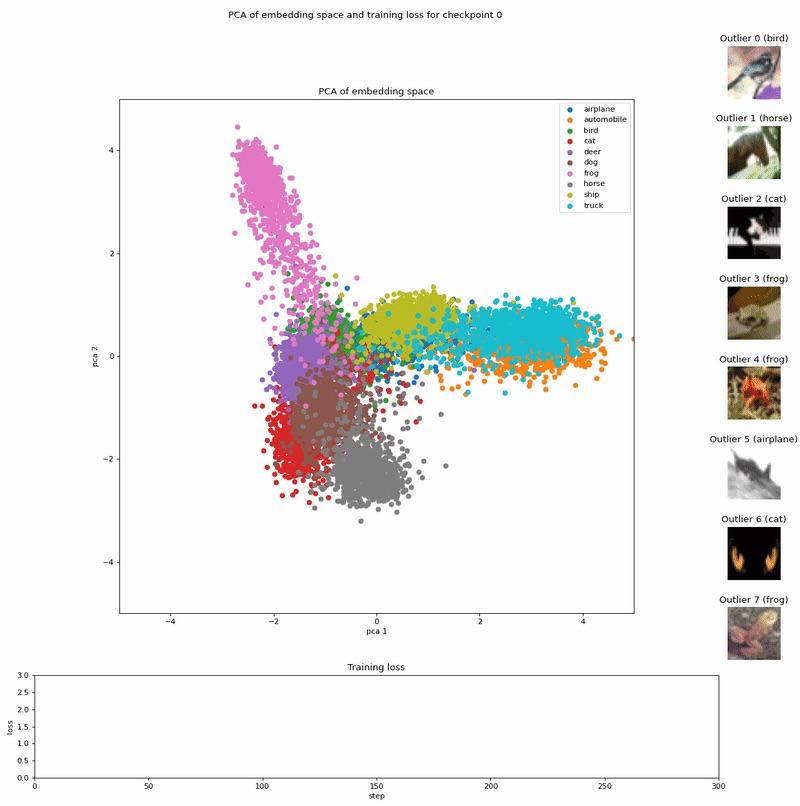
微调在图像分类中显著影响嵌入向量。微调前的嵌入向量提供通用性表征,而微调后的嵌入向量捕获任务特定的特征。这种区别可能导致在异常检测和其他任务中的不同结果。微调前和微调后的嵌入向量各有其独特优势,应结合使用以实现图像分类和分析任务中的全面分析。
请查看本文的 CIFAR-10 数据集【3】在线演示之一。
点击跳转
1 引言
在图像分类中,先使用如 ImageNet 这样的大型数据集上预训练模型,随后对特定目标数据集进行微调,已成为默认方法。然而,在处理现实世界的目标数据集时,考虑其固有噪声非常重要,包括异常值、标签错误和其他异常。数据集的交互式探索在全面理解数据中发挥着关键作用,通过数据丰富化,能够识别和解决关键数据段。
在分析非结构化图像数据时,嵌入向量扮演着关键角色。它们提供高层次的语义信息,支持数据分析、洞察生成和异常检测等各种任务。通过在低维空间中表示图像,嵌入向量使得探索数据内的相似性和差异性变得更加容易,并允许使用 t-SNE 或 UMAP 等技术创建相似性映射。我们将使用 Spotlight 来交互式探索我们创建的丰富数据集:
免责声明:本文作者也是 Spotlight 的开发者之一。本文中的部分代码片段也可在 Spotlight 仓库中找到。
在本文中,我们将深入探讨微调前后嵌入向量的差异,并特别关注异常检测。虽然重要的是要注意,使用经过微调的模型的嵌入向量并不总是为异常检测带来最佳结果(我们也可以使用概率),但这仍然是一种引人入胜的方法。嵌入向量的可视化为分析过程增添了一种视觉上的吸引力。
为了评估嵌入向量在异常检测任务中的性能和有效性,我们将检查在图像分类中广泛使用的典型数据集。此外,我们将使用两种常见的基础模型。通过这种探索,我们旨在深入了解模型微调对嵌入向量的影响,更好地理解它们的能力和局限。
2.环境准备
安装所需要的python包
!pip install renumics-spotlight datasets torch pandas cleanlab annoy
2.1 提取嵌入向量
我们将使用基于 google/vit-base-patch16-224-in21k [1] 和 [microsoft/swin-base-patch4-window7-224(https://huggingface.co/microsoft/swin-base-patch4-window7-224) [2] 的模型,这些模型可在 Hugging Faces 上获得,用以提取微调前的嵌入向量以及每个数据集最受欢迎的微调模型:araki/vit-base-patch16-224-in21k-finetuned-cifar10、MazenAmria/swin-tiny-finetuned-cifar100、nateraw/vit-base-beans、farleyknight/mnist-digit-classification-2022-09-04。
case = {
"cifar10": {
"base_model_name": "google/vit-base-patch16-224-in21k",
"ft_model_name": "aaraki/vit-base-patch16-224-in21k-finetuned-cifar10",
},
"beans": {
"base_model_name": "google/vit-base-patch16-224-in21k",
"ft_model_name": "nateraw/vit-base-beans",
},
"mnist": {
"base_model_name": "google/vit-base-patch16-224-in21k",
"ft_model_name": "farleyknight/mnist-digit-classification-2022-09-04",
},
"cifar100": {
"base_model_name": "microsoft/swin-base-patch4-window7-224",
"ft_model_name": "MazenAmria/swin-tiny-finetuned-cifar100",
},
}
为了加载数据集,我们使用 datasets 模块中的 load_dataset 函数,并为图像分类任务做好准备。你可以从本文测试并报告的数据集中选择 CIFAR-10 [3]、CIFAR-100 [3]、MNIST [4] 和 Beans [5],或尝试使用与之对应的模型,从 Hugging Face 获取不同的图像分类数据集。
import datasets
# 可选 cifar10, cifar100, mnist 或 beans。
# 对应模型将自动选择
DATASET = "cifar10"
ds = datasets.load_dataset(DATASET, split="train").prepare_for_task(
"image-classification"
)
df = ds.to_pandas()
# df = df.iloc[:1000] # 取消注释以限制数据集大小进行测试
我们定义了 huggingface_embedding 函数,用于从微调模型和基础/基本模型中提取嵌入向量。这些嵌入向量被存储在原始数据框(df)的不同列中(“embedding_ft” 和 “embedding_foundation”)。
import datasets
from transformers import AutoFeatureExtractor, AutoModel
import torch
import pandas as pd
ft_model_name = case[DATASET]["ft_model_name"]
base_model_name = case[DATASET]["base_model_name"]
def extract_embeddings(model, feature_extractor, image_name="image"):
"""
计算嵌入向量的工具函数。
参数:
model: huggingface 模型
feature_extractor: huggingface 特征提取器
image_name: 数据集中图像列的名称
返回:
计算嵌入向量的函数
"""
device = model.device
def pp(batch):
images = batch[image_name]
inputs = feature_extractor(
images=[x.convert("RGB") for x in images], return_tensors="pt"
).to(device)
embeddings = model(**inputs).last_hidden_state[:, 0].cpu()
return {"embedding": embeddings}
return pp
def huggingface_embedding(
df,
image_name="image",
modelname="google/vit-base-patch16-224",
batched=True,
batch_size=24,
):
"""
使用 huggingface 模型计算嵌入向量。
参数:
df: 含有图像的数据框
image_name: 数据集中图像列的名称
modelname: huggingface 模型名称
batched: 是否批量计算嵌入向量
batch_size: 批量大小
返回:
包含嵌入向量的新数据框
"""
# 初始化 huggingface 模型
feature_extractor = AutoFeatureExtractor.from_pretrained(modelname)
model = AutoModel.from_pretrained(modelname, output_hidden_states=True)
# 从 df 创建 huggingface 数据集
dataset = datasets.Dataset.from_pandas(df).cast_column(image_name, datasets.Image())
# 计算嵌入向量
device = "cuda" if torch.cuda.is_available() else "cpu"
extract_fn = extract_embeddings(model.to(device), feature_extractor, image_name)
updated_dataset = dataset.map(extract_fn, batched=batched, batch_size=batch_size)
df_temp = updated_dataset.to_pandas()
df_emb = pd.DataFrame()
df_emb["embedding"] = df_temp["embedding"]
return df_emb
embeddings_df = huggingface_embedding(
df,
modelname=ft_model_name,
batched=True,
batch_size=24,
)
embeddings_df_found = huggingface_embedding(
df, modelname=base_model_name, batched=True, batch_size=24
)
df["embedding_ft"] = embeddings_df["embedding"]
df["embedding_foundation"] = embeddings_df_found["embedding"]
2.2 计算异常值得分
接下来,我们使用 Cleanlab 来计算基于嵌入向量的微调模型和基础/基本模型的异常值得分。我们利用 OutOfDistribution 类来计算异常值得分。生成的异常值得分将存储在原始数据框(df)中:
from cleanlab.outlier import OutOfDistribution
import numpy as np
import pandas as pd
def outlier_score_by_embeddings_cleanlab(df, embedding_name="embedding"):
"""
使用 cleanlab 通过嵌入向量计算异常值得分
参数:
df: 含有嵌入向量的数据框
embedding_name: 嵌入向量所在列的名称
返回:
新的 df_out: 含有异常值得分的数据框
"""
embs = np.stack(df[embedding_name].to_numpy())
ood = OutOfDistribution()
ood_train_feature_scores = ood.fit_score(features=np.stack(embs))
df_out = pd.DataFrame()
df_out["outlier_score_embedding"] = ood_train_feature_scores
return df_out
df["outlier_score_ft"] = outlier_score_by_embeddings_cleanlab(
df, embedding_name="embedding_ft"
)["outlier_score_embedding"]
df["outlier_score_found"] = outlier_score_by_embeddings_cleanlab(
df, embedding_name="embedding_foundation"
)["outlier_score_embedding"]
2.3 寻找最近邻居图像
为了评估异常值,我们使用仅经过微调模型的 Annoy 库计算最近邻居图像。生成的图像将存储在原始数据框(df)中:
from annoy import AnnoyIndex
import pandas as pd
def nearest_neighbor_annoy(
df, embedding_name="embedding", threshold=0.3, tree_size=100
):
"""
使用 annoy 查找最近邻居。
参数:
df: 含有嵌入向量的数据框
embedding_name: 嵌入向量列的名称
threshold: 异常检测的阈值
tree_size: annoy 的树大小
返回:
新的数据框,包含最近邻居信息
"""
embs = df[embedding_name]
t = AnnoyIndex(len(embs[0]), "angular")
for idx, x in enumerate(embs):
t.add_item(idx, x)
t.build(tree_size)
images = df["image"]
df_nn = pd.DataFrame()
nn_id = [t.get_nns_by_item(i, 2)[1] for i in range(len(embs))]
df_nn["nn_id"] = nn_id
df_nn["nn_image"] = [images[i] for i in nn_id]
df_nn["nn_distance"] = [t.get_distance(i, nn_id[i]) for i in range(len(embs))]
df_nn["nn_flag"] = df_nn.nn_distance < threshold
return df_nn
df_nn = nearest_neighbor_annoy(
df, embedding_name="embedding_ft", threshold=0.3, tree_size=100
)
df["nn_image"] = df_nn["nn_image"]
2.4 可视化
为了使用 Spotlight 进行可视化,通过使用 lambda 函数将整数标签映射到它们的字符串表示形式,我们在数据框中创建了一个新的“label_str”列。使用 dtypes 字典来指定每列的数据类型,以获得正确的可视化效果,同时布局确定了可视化中的排列和显示的列:
from renumics import spotlight
df["label_str"] = df["labels"].apply(lambda x: ds.features["labels"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources//layout_pre_post_ft.json",
)
之后会打开一个浏览器的新窗口
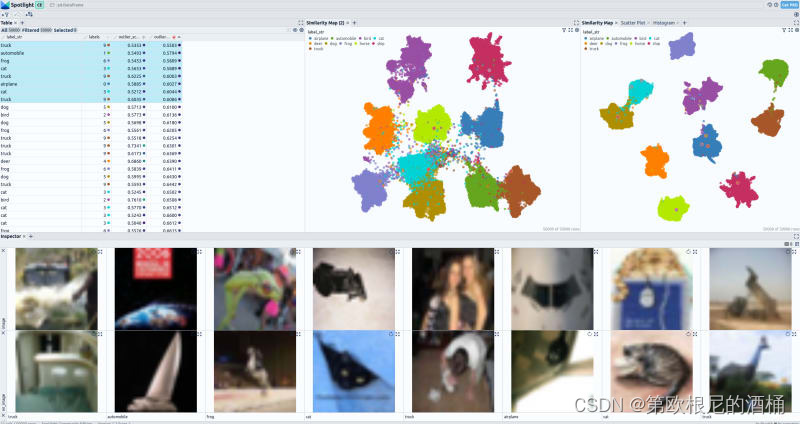
在可视化部分,左上角显示了一个全面的表格,展示了数据集中存在的所有字段。选择了基础模型的嵌入向量识别为异常值的图像。在右上角,你可以观察到两个 UMAP 表示:第一个表示来自基础模型的嵌入向量,而第二个表示来自微调模型的嵌入向量。在底部,选定的图像与数据集中它们的最近邻居一起展示。
3 结果
现在让我们检查所有数据集的结果。你可以通过使用不同的输入数据集重复第2节的所有步骤来复制结果,或者可以使用下面的代码片段加载预处理的数据集。或者你可以查看链接的在线演示。
3. 1 CIFAR-10
加载 CIFAR-10数据集
from renumics import spotlight
import datasets
ds = datasets.load_dataset("renumics/cifar10-outlier", split="train")
df = ds.rename_columns({"img": "image", "label": "labels"}).to_pandas()
df["label_str"] = df["labels"].apply(lambda x: ds.features["label"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_pre_post_ft.json",
)
或查看在线演示 https://huggingface.co/spaces/renumics/cifar10-outlier 来检查异常值:

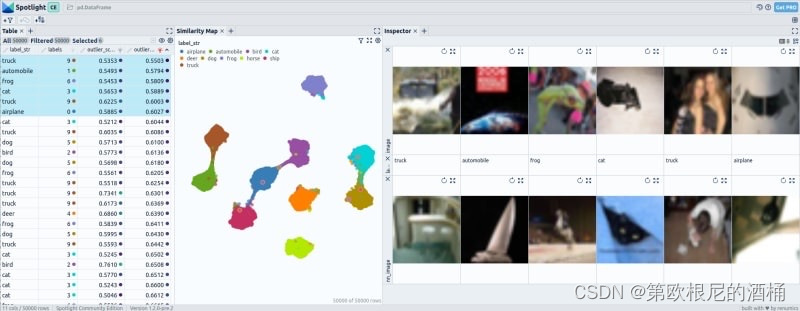
微调后嵌入向量的 UMAP 可视化显示了独特的模式,其中某些类别完全与其他所有类别分离,而有些可能只与一两个其他类别相连。
在 CIFAR-10 中,使用微调前嵌入向量检测到的异常值似乎并不特别少见,因为它们与相邻图像相对相似。相比之下,使用微调后嵌入向量识别出的异常值则非常独特且在数据集中极为少见。
3.2 CIFAR-100
加载CIFAR-100数据集
from renumics import spotlight
import datasets
ds = datasets.load_dataset("renumics/cifar100-outlier", split="train")
df = ds.rename_columns({"img": "image", "fine_label": "labels"}).to_pandas()
df["label_str"] = df["labels"].apply(lambda x: ds.features["fine_label"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_pre_post_ft.json",
)
或查看在线演示 https://huggingface.co/spaces/renumics/cifar100-outlier 来检查异常值:
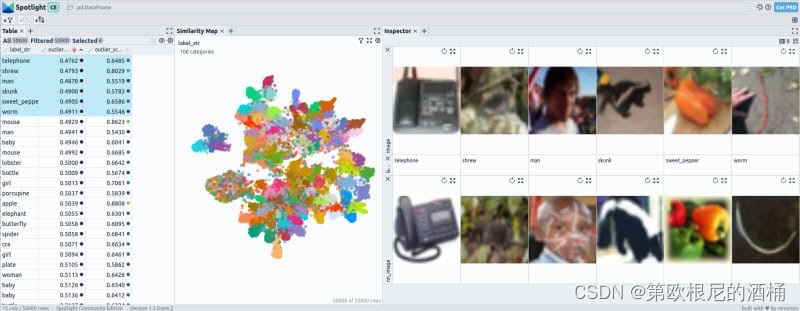

当检查包含 100 个类别的 CIFAR-100 的嵌入向量时,我们观察到即使在微调之后,与微调前的嵌入向量相比,仍有更多的类别相连。然而,嵌入空间内的结构变得更加明显和有序。
微调前的嵌入向量并未显示出明显突出于其邻近图像的异常值,表明在异常检测方面的效果有限。然而,当使用微调后的嵌入向量时,性能得到提升。在识别出的六个异常值中,前三个被有效地检测为数据集内不常见的异常。
3.3 MNIST
加载MINIST数据集
from renumics import spotlight
import datasets
ds = datasets.load_dataset("renumics/mnist-outlier", split="train")
df = ds.rename_columns({"label": "labels"}).to_pandas()
df["label_str"] = df["labels"].apply(lambda x: ds.features["label"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_pre_post_ft.json",
)
或查看在线演示 huggingface.co/spaces/renumics/mnist-outlier 来检查异常值:
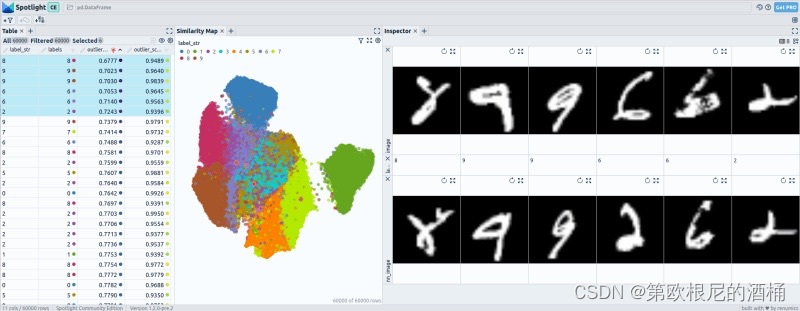

在 MNIST 的微调过程中,嵌入向量经历了显著变化。微调前,不同数字类别之间可能存在重叠区域,仅凭嵌入向量的邻近性难以区分它们。然而,微调后,嵌入向量展现出数字类别之间更清晰的分离。
微调前的嵌入向量只揭示出一个与邻近图像明显不同的异常值,表明其在异常检测方面的性能中等。然而,当使用微调后的嵌入向量时,异常值的检测性能提高。大约能够识别出 3 到 4 个在数据集中非常罕见的异常值。
3.4 Beans
加载Beans数据集
from renumics import spotlight
import datasets
ds = datasets.load_dataset("renumics/beans-outlier", split="train")
df = ds.to_pandas()
df["label_str"] = df["labels"].apply(lambda x: ds.features["labels"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_pre_post_ft.json",
)
或查看在线演示 huggingface.co/spaces/renumics/beans-outlier 来检查异常值:
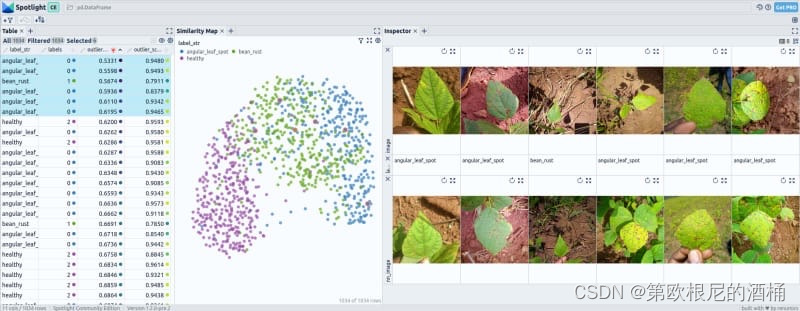
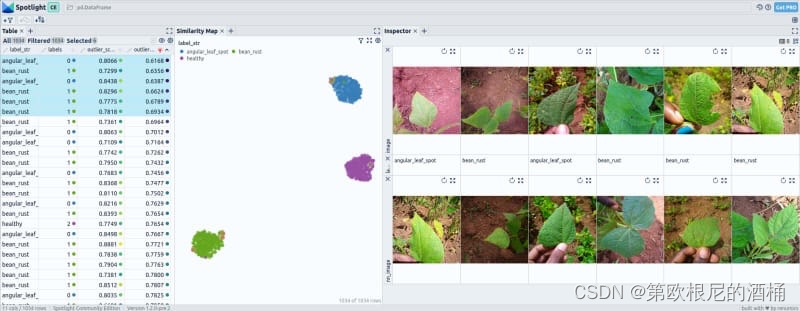
在 Beans 数据集中,经过微调后,大多数嵌入向量展现出三个类别之间的完全分离。然而,仍有一些案例显示出轻微的重叠,可能是由于某些类型的豆类之间的相似性或误分类所致。
使用微调前和微调后的嵌入向量进行的异常检测并未产生显著偏离常态的异常值。识别出的异常值在数据集中并不突出或罕见。
4 结论
总之,微调对图像分类中的嵌入向量有显著影响。微调前,嵌入向量提供通用性表征,而微调后,它们捕获了特定于当前任务的特征。
这种区别在 UMAP 可视化中清晰反映出来,其中微调后的嵌入向量展示出更加结构化的模式,某些类别完全与其他类别分离。
对于异常检测而言,使用微调后的嵌入向量可能更有效。然而,值得注意的是,基于微调所获得的概率计算异常值可能比仅依赖嵌入向量带来更好的结果。
微调前和微调后的嵌入向量各有其独特优势,应结合使用以在图像分类和分析任务中实现全面分析。
参考文献
[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020), arXiv
[2] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (2021), arXiv
[3] Alex Krizhevsky, Learning Multiple Layers of Features from Tiny Images (2009), University Toronto
[4] Yann LeCun, Corinna Cortes, Christopher J.C. Burges, MNIST handwritten digit database (2010), ATT Labs [Online]
[5] Makerere AI Lab, Bean disease dataset (2020), AIR Lab Makerere University
标签:Transformer,嵌入,name,df,embedding,spotlight,向量 From: https://blog.csdn.net/Iconicdusk/article/details/136668361