转自:https://zhuanlan.zhihu.com/p/676061269
1 Chatchat项目结构
整个结构是server 启动API,然后项目内自行调用API。
API详情可见:http://xxx:7861/docs ,整个代码架构还是蛮适合深入学习
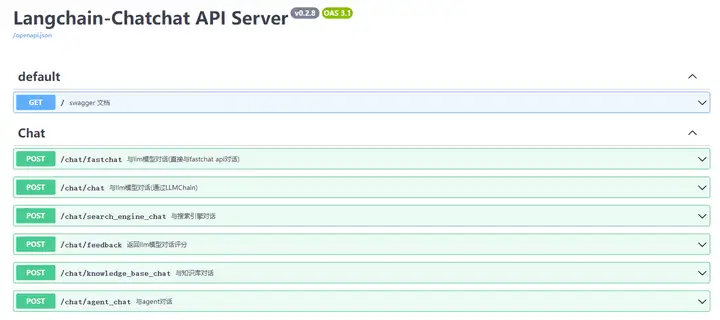
在这里插入图片描述
2 Chatchat一些代码学习
2.1 12个分块函数统一使用
截止 20231231 笔者看到chatchat一共有12个分chunk的函数 这12个函数如何使用、大致点评可以参考笔者的另外文章(RAG 分块Chunk技术优劣、技巧、方法汇总(五)):
CharacterTextSplitter
LatexTextSplitter
MarkdownHeaderTextSplitter
MarkdownTextSplitter
NLTKTextSplitter
PythonCodeTextSplitter
RecursiveCharacterTextSplitter
SentenceTransformersTokenTextSplitter
SpacyTextSplitter
AliTextSplitter
ChineseRecursiveTextSplitter
ChineseTextSplitter借用chatchat项目中的test/custom_splitter/test_different_splitter.py来看看一起调用make_text_splitter函数:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter
# 使用DocumentLoader读取文件
filepath = "knowledge_base/samples/content/test_files/test.txt"
loader = document_loaders.UnstructuredFileLoader(filepath, autodetect_encoding=True)
docs = loader.load()
CHUNK_SIZE = 250
OVERLAP_SIZE = 50
splitter_name = 'AliTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":
docs = text_splitter.split_text(docs[0].page_content)
for doc in docs:
if doc.metadata:
doc.metadata["source"] = os.path.basename(filepath)
else:
docs = text_splitter.split_documents(docs)
for doc in docs:
print(doc)2.2 知识库问答Chat的使用
本节参考chatchat开源项目的tests\api\test_stream_chat_api_thread.py 以及 tests\api\test_stream_chat_api.py 来探索一下知识库问答调用,包括:
- 流式调用
- 单次调用
- 多线程并发调用
2.2.1 流式调用
import requests
import json
import sys
api_base_url = 'http://0.0.0.0:7861'
api="/chat/knowledge_base_chat"
url = f"{api_base_url}{api}"
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
}
data = {
"query": "如何提问以获得高质量答案",
"knowledge_base_name": "ZWY_V2_m3e-large",
"history": [
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,我是 ChatGLM"
}
],
"stream": True
}
# dump_input(data, api)
response = requests.post(url, headers=headers, json=data, stream=True)
print("\n")
print("=" * 30 + api + " output" + "="*30)
for line in response.iter_content(None, decode_unicode=True):
data = json.loads(line)
if "answer" in data:
print(data["answer"], end="", flush=True)
pprint(data)
assert "docs" in data and len(data["docs"]) > 0
assert response.status_code == 200
>>>==============================/chat/knowledge_base_chat output==============================
你好!提问以获得高质量答案,以下是一些建议:
1. 尽可能清晰明确地表达问题:确保你的问题表述清晰、简洁、明确,以便我能够准确理解你的问题并给出恰当的回答。
2. 提供足够的上下文信息:提供相关的背景信息和上下文,以便我能够更好地理解你的问题,并给出更准确的回答。
3. 使用简洁的语言:尽量使用简单、明了的语言,以便我能够快速理解你的问题。
4. 避免使用缩写和俚语:避免使用缩写和俚语,以便我能够准确理解你的问题。
5. 分步提问:如果问题比较复杂,可以分步提问,这样我可以逐步帮助你解决问题。
6. 检查你的问题:在提问之前,请检查你的问题是否完整、清晰且准确。
7. 提供反馈:如果你对我的回答不满意,请提供反馈,以便我改进我的回答。
希望这些建议能帮助你更好地提问,获得高质量的答案。结构也比较简单,call 知识库问答的URL,然后返回,通过response.iter_content来进行流式反馈。
2.2.2 正常调用以及处理并发
import requests
import json
import sys
api_base_url = 'http://0.0.0.0:7861'
api="/chat/knowledge_base_chat"
url = f"{api_base_url}{api}"
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
}
data = {
"query": "如何提问以获得高质量答案",
"knowledge_base_name": "ZWY_V2_m3e-large",
"history": [
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,我是 ChatGLM"
}
],
"stream": True
}
# 正常调用并存储结果
result = []
response = requests.post(url, headers=headers, json=data, stream=True)
for line in response.iter_content(None, decode_unicode=True):
data = json.loads(line)
result.append(data)
answer = ''.join([r['answer'] for r in result[:-1]]) # 正常的结果
>>> ' 你好,很高兴为您提供帮助。以下是一些提问技巧,可以帮助您获得高质量的答案:\n\n1. 尽可能清晰明确地表达问题:确保您的问题准确、简洁、明确,以便我可以更好地理解您的问题并为您提供最佳答案。\n2. 提供足够的上下文信息:提供相关的背景信息和上下文,以便我更好地了解您的问题,并能够更准确地回答您的问题。\n3. 使用简洁的语言:尽量使用简单、明了的语言,以便我能够更好地理解您的问题。\n4. 避免使用缩写和俚语:尽量使用标准语言,以确保我能够正确理解您的问题。\n5. 分步提问:如果您有一个复杂的问题,可以将其拆分成几个简单的子问题,这样我可以更好地回答每个子问题。\n6. 检查您的拼写和语法:拼写错误和语法错误可能会使我难以理解您的问题,因此请检查您的提问,以确保它们是正确的。\n7. 指定问题类型:如果您需要特定类型的答案,请告诉我,例如数字、列表或步骤等。\n\n希望这些技巧能帮助您获得高质量的答案。如果您有其他问题,请随时问我。'
refer_doc = result[-1] # 参考文献
>>> {'docs': ["<span style='color:red'>未找到相关文档,该回答为大模型自身能力解答!</span>"]}然后来看一下并发:
# 并发调用
def knowledge_chat(api="/chat/knowledge_base_chat"):
url = f"{api_base_url}{api}"
data = {
"query": "如何提问以获得高质量答案",
"knowledge_base_name": "samples",
"history": [
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好,我是 ChatGLM"
}
],
"stream": True
}
result = []
response = requests.post(url, headers=headers, json=data, stream=True)
for line in response.iter_content(None, decode_unicode=True):
data = json.loads(line)
result.append(data)
return result
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
threads = []
times = []
pool = ThreadPoolExecutor()
start = time.time()
for i in range(10):
t = pool.submit(knowledge_chat)
threads.append(t)
for r in as_completed(threads):
end = time.time()
times.append(end - start)
print("\nResult:\n")
pprint(r.result())
print("\nTime used:\n")
for x in times:
print(f"{x}")通过concurrent的ThreadPoolExecutor, as_completed进行反馈。
3 知识库相关实践问题
3.1 .md格式的文件 支持非常差
我们在configs/kb_config.py可以看到:
# TextSplitter配置项,如果你不明白其中的含义,就不要修改。
text_splitter_dict = {
"ChineseRecursiveTextSplitter": {
"source": "huggingface", # 选择tiktoken则使用openai的方法
"tokenizer_name_or_path": "",
},
"SpacyTextSplitter": {
"source": "huggingface",
"tokenizer_name_or_path": "gpt2",
},
"RecursiveCharacterTextSplitter": {
"source": "tiktoken",
"tokenizer_name_or_path": "cl100k_base",
},
"MarkdownHeaderTextSplitter": {
"headers_to_split_on":
[
("#", "head1"),
("##", "head2"),
("###", "head3"),
("####", "head4"),
]
},
}
# TEXT_SPLITTER 名称
TEXT_SPLITTER_NAME = "ChineseRecursiveTextSplitter"chatchat看上去创建新知识库的时候,仅支持一个知识库一个TEXT_SPLITTER_NAME 的方法,并不能做到不同的文件,使用不同的切块模型。 所以如果要一个知识库内,不同文件使用不同的切分方式,需要自己改整个结构代码;然后重启项目
同时,chatchat项目对markdown的源文件,支持非常差,我们来看看:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter
# 载入
filepath = "matt/智能XXX.md"
loader = document_loaders.UnstructuredFileLoader(filepath,autodetect_encoding=True)
docs = loader.load()
# 切分
splitter_name = 'ChineseRecursiveTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":
docs = text_splitter.split_text(docs[0].page_content)
for doc in docs:
if doc.metadata:
doc.metadata["source"] = os.path.basename(filepath)
else:
docs = text_splitter.split_documents(docs)
for doc in docs:
print(doc)首先chatchat对.md文件读入使用的是UnstructuredFileLoader,
但是没有加mode="elements"(参考:LangChain:万能的非结构化文档载入详解(一))
所以,你可以认为,读入后,#会出现丢失,于是你即使选择了MarkdownHeaderTextSplitter,也还是无法使用。 目前来看,不建议上传.md格式的文档,比较好的方法是:
- - 文件改成 doc,可以带
#/##/### - - 更改
configs/kb_config.py当中的TEXT_SPLITTER_NAME = "MarkdownHeaderTextSplitter"
3.2 PDF 文件读入 + MarkdownHeaderTextSplitter 分割的可行性
在chatchat项目中,PDF文件的读入是RapidOCRPDFLoader
可能需要下载:
!pip install pyMuPDF -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install rapidocr_onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install unstructured==0.11.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install opencv-python-headless -i https://pypi.tuna.tsinghua.edu.cn/simple其中,没有opencv-python-headless,可能会报错:ImportError: libGL.so.1: cannot open shared object file: No such file or directory
在 document_loaders.mypdfloader
from typing import List
from langchain.document_loaders.unstructured import UnstructuredFileLoader
import tqdm
class RapidOCRPDFLoader(UnstructuredFileLoader):
def _get_elements(self) -> List:
def pdf2text(filepath):
import fitz # pyMuPDF里面的fitz包,不要与pip install fitz混淆
from rapidocr_onnxruntime import RapidOCR
import numpy as np
ocr = RapidOCR()
doc = fitz.open(filepath)
resp = ""
b_unit = tqdm.tqdm(total=doc.page_count, desc="RapidOCRPDFLoader context page index: 0")
for i, page in enumerate(doc):
# 更新描述
b_unit.set_description("RapidOCRPDFLoader context page index: {}".format(i))
# 立即显示进度条更新结果
b_unit.refresh()
# TODO: 依据文本与图片顺序调整处理方式
text = page.get_text("")
resp += text + "\n"
img_list = page.get_images()
for img in img_list:
pix = fitz.Pixmap(doc, img[0])
img_array = np.frombuffer(pix.samples, dtype=np.uint8).reshape(pix.height, pix.width, -1)
result, _ = ocr(img_array)
if result:
ocr_result = [line[1] for line in result]
resp += "\n".join(ocr_result)
# 更新进度
b_unit.update(1)
return resp
text = pdf2text(self.file_path)
from unstructured.partition.text import partition_text
return partition_text(text=text, **self.unstructured_kwargs)
if __name__ == "__main__":
loader = RapidOCRPDFLoader(file_path="tests/samples/ocr_test.pdf")
docs = loader.load()
print(docs)本节笔者测试的是pdf文档中,带#,是否可以使用MarkdownHeaderTextSplitter 进行分割。
测试的代码:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter
import os
CHUNK_SIZE = 250
OVERLAP_SIZE = 50
filepath = "xxx.pdf"
# 文档读入
loader = RapidOCRPDFLoader(file_path=filepath)
docs = loader.load()
import langchain
text_splitter_dict = {
"ChineseRecursiveTextSplitter": {
"source": "huggingface", # 选择tiktoken则使用openai的方法
"tokenizer_name_or_path": "",
},
"SpacyTextSplitter": {
"source": "huggingface",
"tokenizer_name_or_path": "gpt2",
},
"RecursiveCharacterTextSplitter": {
"source": "tiktoken",
"tokenizer_name_or_path": "cl100k_base",
},
"MarkdownHeaderTextSplitter": {
"headers_to_split_on":
[
("#", "标题1"),
("##", "标题2"),
("###", "标题3"),
("####", "标题4"),
]
},
}
splitter_name = 'MarkdownHeaderTextSplitter'
headers_to_split_on = text_splitter_dict[splitter_name]['headers_to_split_on']
text_splitter = langchain.text_splitter.MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on)
docs_2 = text_splitter.split_text(docs[0].page_content)
docs_2首先结论是:
- 读入后,可以按照 # 进行分割,但是会出现某个块字数很多的情况
所以,一般情况下,如果使用MarkdownHeaderTextSplitter,可能后面要再接一个分块器,目前chatchat是不支持多个分块器同时使用的。
markdown_document = "# Intro \n\n ## History \n\n Markdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9] \n\n Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files. \n\n ## Rise and divergence \n\n As Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \n\n additional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks. \n\n #### Standardization \n\n From 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort. \n\n ## Implementations \n\n Implementations of Markdown are available for over a dozen programming languages."
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
]
# MD splits
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on, strip_headers=False
)
md_header_splits = markdown_splitter.split_text(markdown_document)
# Char-level splits
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# Split
splits = text_splitter.split_documents(md_header_splits)
splits
4 webui.py 跨域问题:尝试解决
chatchat整个架构是:langchain框架支持通过基于FastAPI提供的 API 调用服务,或使用基于Streamlit的 WebUI 进行操作。
所以由FastAPI提供所有server的服务,然后webUI这边是独立运行,同时调用FastAPI
如果有跨域问题可能会出现:
- web端一直显示please wait
- 无法建立websocket链接
关于跨域问题,笔者其实不是特别懂,不过听一位前辈形象提过,
不同的服务调用就像两个品牌(比如:东北馆子,麦当劳),你在麦当劳要吃锅包肉,麦当劳员工问了旁边的东北馆子,人家不想卖你锅包肉
所以,如果要想满足客户需求,东北馆子就需要设置允许调货的命令
其中,FastAPI在文件Langchain-Chatchat/startup.py 通过app.add_middleware设置了跨域:
def create_openai_api_app(
controller_address: str,
api_keys: List = [],
log_level: str = "INFO",
) -> FastAPI:
import fastchat.constants
fastchat.constants.LOGDIR = LOG_PATH
from fastchat.serve.openai_api_server import app, CORSMiddleware, app_settings
from fastchat.utils import build_logger
logger = build_logger("openai_api", "openai_api.log")
logger.setLevel(log_level)
app.add_middleware(
CORSMiddleware,
allow_credentials=True,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
sys.modules["fastchat.serve.openai_api_server"].logger = logger
app_settings.controller_address = controller_address
app_settings.api_keys = api_keys
MakeFastAPIOffline(app)
app.title = "FastChat OpeanAI API Server"
return app
那么webui在Langchain-Chatchat/startup.py是通过cmd 直接跑的,所以跟 FastAPI是独立结构。
def run_webui(started_event: mp.Event = None, run_mode: str = None):
from server.utils import set_httpx_config
set_httpx_config()
host = WEBUI_SERVER["host"]
port = WEBUI_SERVER["port"]
cmd = ["streamlit", "run", "webui.py",
"--server.address", host,
"--server.port", str(port),
"--theme.base", "light",
"--theme.primaryColor", "#165dff",
"--theme.secondaryBackgroundColor", "#f5f5f5",
"--theme.textColor", "#000000",
]
if run_mode == "lite":
cmd += [
"--",
"lite",
]
p = subprocess.Popen(cmd)
started_event.set()
p.wait()那么针对Streamlit的跨域,在issue提到了:https://github.com/chatchat-space/Langchain-Chatchat/issues/1397
跨域问题,已解决
在startup.py中进行修改
p = subprocess.Popen(["streamlit", "run", "webui.py",
"--server.enableCORS", "false",
"--server.address", host,
"--server.port", str(port)])但是在云托管docker部署streamlit后无法建立websocket链接? | 微信开放社区 也提到了,设置了也无法使用:
尝试过在streamlit run后面加--server.enableXsrfProtection=false --server.enableCORS=false --server.enableWebsocketCompression=false --browser.serverAddress=公网域名 --server.port=80 中的一个或几个都没用,当然改server.port也会对应修改EXPOSE端口号和流水线的端口号。
尝试把https改成http后访问也没用。
笔者自己尝试的时候,单独设置"--server.enableCORS", "false",会出现提示:
Warning: the config option 'server.enableCORS=false' is not
compatible with 'server.enableXsrfProtection=true'.
As a result, 'server.enableCORS' is being overridden to 'true'.
More information:
In order to protect against CSRF attacks, we send a cookie with each request.
To do so, we must specify allowable origins, which places a restriction on
cross-origin resource sharing.
If cross origin resource sharing is required, please disable server.enableXsrfProtection.
然后参考streamlit官方的configuration信息,Configuration - Streamlit Docs,其中有记录:
# Enables support for Cross-Origin Resource Sharing (CORS) protection, for
# added security.
# Due to conflicts between CORS and XSRF, if `server.enableXsrfProtection` is
# on and `server.enableCORS` is off at the same time, we will prioritize
# `server.enableXsrfProtection`.
# Default: true
enableCORS = true
# Enables support for Cross-Site Request Forgery (XSRF) protection, for added
# security.
# Due to conflicts between CORS and XSRF, if `server.enableXsrfProtection` is
# on and `server.enableCORS` is off at the same time, we will prioritize
# `server.enableXsrfProtection`.
# Default: true
enableXsrfProtection = true所以笔者最终的使用是在Langchain-Chatchat/startup.py 中加了server.enableCORS 和 erver.enableXsrfProtection的false选项:
def run_webui(started_event: mp.Event = None, run_mode: str = None):
from server.utils import set_httpx_config
set_httpx_config()
host = WEBUI_SERVER["host"]
port = WEBUI_SERVER["port"]
cmd = ["streamlit", "run", "webui.py",
"--server.address", host,
"--server.port", str(port),
"--theme.base", "light",
"--server.enableCORS", "false",
"--server.enableXsrfProtection", "false",
"--theme.primaryColor", "#165dff",
"--theme.secondaryBackgroundColor", "#f5f5f5",
"--theme.textColor", "#000000",
]
if run_mode == "lite":
cmd += [
"--",
"lite",
]
p = subprocess.Popen(cmd)
started_event.set()
p.wait()