一、简介
Langchain-ChatGLM 相信大家都不陌生,近几周计划出一个源码解读,先解锁langchain的一些基础用法。
文档问答过程大概分为以下5部分,在Langchain中都有体现。
- 上传解析文档
- 文档向量化、存储
- 文档召回
- query向量化
- 文档问答
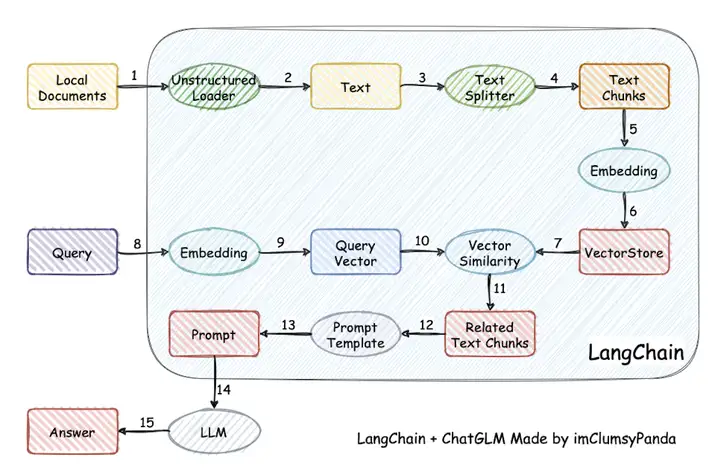
今天主要讲langchain在上传解析文档时是怎么实现的。
二、文档解析逻辑,以txt类型的文件解析为例子
step1:寻找上传逻辑入口:local_doc_qa.py ,关注TextLoader(),ChineseTextSplitter()
def load_file(filepath, sentence_size=SENTENCE_SIZE, using_zh_title_enhance=ZH_TITLE_ENHANCE):
if filepath.lower().endswith(".md"):
loader = UnstructuredFileLoader(filepath, mode="elements")
docs = loader.load()
elif filepath.lower().endswith(".txt"):
loader = TextLoader(filepath, autodetect_encoding=True)
textsplitter = ChineseTextSplitter(pdf=False, sentence_size=sentence_size)
docs = loader.load_and_split(textsplitter)
step2:解析txt/pdf等原始文件,不同类型的文件有不同种类多Loader,比如txt文件有TextLoader,具体load()实现如下:
def load(self) -> List[Document]:
"""Load from file path.""" text = ""
try:
with open(self.file_path, encoding=self.encoding) as f:
text = f.read()
except UnicodeDecodeError as e:
if self.autodetect_encoding:
detected_encodings = detect_file_encodings(self.file_path)
for encoding in detected_encodings:
logger.debug("Trying encoding: ", encoding.encoding)
try:
with open(self.file_path, encoding=encoding.encoding) as f:
text = f.read()
break except UnicodeDecodeError:
continue else:
raise RuntimeError(f"Error loading {self.file_path}") from e
except Exception as e:
raise RuntimeError(f"Error loading {self.file_path}") from e
metadata = {"source": self.file_path}
return [Document(page_content=text, metadata=metadata)]此时输入:file_path,输出:List[Document],其中,Document对象如下:
page_content:原生txt读取的所有内容
metadata:文件地址路径,metadata = {"source": self.file_path}
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
step3:load_and_split()进行文档切割
输入:Optional[TextSplitter],输出:List[Document]
def load_and_split(self, text_splitter: Optional[TextSplitter] = None) -> List[Document]:
"""Load documents and split into chunks."""
if text_splitter is None:
_text_splitter: TextSplitter = RecursiveCharacterTextSplitter()
else:
_text_splitter = text_splitter
docs = self.load()
return _text_splitter.split_documents(docs)然后在split_documents()中分别对documents进行解压缩,最后嵌套调用create_documents()方法,
def split_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents."""
texts = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
return self.create_documents(texts, metadatas=metadatas)create_documents()方法将每一篇文档传入split_text(text)进行解析,其中
输入:texts: List[str],输出:List[Document]
def create_documents(
self, texts: List[str], metadatas: Optional[List[dict]] = None) -> List[Document]:
"""Create documents from a list of texts."""
_metadatas = metadatas or [{}] * len(texts)
documents = []
for i, text in enumerate(texts):
for chunk in self.split_text(text):
new_doc = Document(
page_content=chunk, metadata=copy.deepcopy(_metadatas[i])
)
documents.append(new_doc)
return documents可以看到又进行了一个函数嵌套,最后定位到chinese_text_splitter.py的split_text(),其中具体逻辑就不展示了,这一块也是一个方法重载的过程,溯源起来发现ChineseTextSplitter中的split_text()继承了TextSplitter中的split_text()抽象方法然后进行实例化。实例化后的split_text()干了件啥事?就是把一篇文档按要求切成多个chunk,最后放在一个list里。
输入:text: str,输出:List[str]
def split_text(self, text: str) -> List[str]: ##此处需要进一步优化逻辑
paas
step4:load_and_split()进行文档切割把切好的chunk和对应的metadata重新组合形成一个Document对象,需要注意的是⚠️,此时Document对象放的是文章的某一个chunk,而不是整篇文章。最后返回一个List
def create_documents(
self, texts: List[str], metadatas: Optional[List[dict]] = None) -> List[Document]:
"""Create documents from a list of texts."""
_metadatas = metadatas or [{}] * len(texts)
documents = []
for i, text in enumerate(texts):
for chunk in self.split_text(text):
new_doc = Document(
page_content=chunk, metadata=copy.deepcopy(_metadatas[i])
)
documents.append(new_doc)
return documents三、杂谈
如果想加入自己的文档切割方法该怎么做?可以重写一个类似于ChineseTextSplitter()方法就可以了!
胖友,请不要忘了一键三连点赞哦!
转载请注明出处:QA Weekly
标签:documents,text,self,List,Langchain,源码,split,ChatGLM,Document From: https://www.cnblogs.com/gongzb/p/18073874