标签:Convolutional 教师 Own 蒸馏 训练 Neural 模型 损失 分类器
摘要
本文中,提出了一种名为自蒸馏的通用训练框架,该框架通过缩小网络的规模而不是扩大网络的规模,而提高卷积神经网络的性能。
传统的知识蒸馏是一种网络之间的知识转换方法,它迫使学生神经网络接近预先训练的教师神经网络的softmax层输出,与此不同,所提出的自蒸馏框架提取网络本身的知识。网络首先分为几个部分。然后,网络中较深部分的知识被挤压到浅层部分。
自蒸馏首先在不同深度的神经网络中间层之后附加几个基于注意力的浅分类器。然后,在训练期间,
将更深层
次的分类器视为教师模型
,并利用它们通过输出上的
KL
散度损失和特征图上的
L2
损失来指导学生模型的训练。在推理期间,可以删除所有额外的浅分类器,这样它们就不会带来额外的参数和计算。
1、介绍
与尽力而为的网络相比,由于预定义的性能损失,已经提出了各种技术来减少计算和存储量,以匹配硬件实现带来的限制。此类技术包括轻量级网络设计、修剪和量化。知识蒸馏(KD
)是实现模型压缩的可用方法之一。
作为一种流行的压缩方法,知识蒸馏受到教师向学生转移知识的启发。它的关键是将紧凑的学生模型定位为近似于参数化程度过高的教师模型。因此,学生模型可以获得显著的绩效提升,有时甚至比教师模型更好。通过用紧凑的学生模型代替过度参数化的教师模型,可以实现高压缩和快速加速。然而,荣耀随着而来的是遗留问题。第一个挫折是知识转移效率低,这意味着学生模型几乎没有使用教师模型中的所有知识。一个杰出的学生模型胜过其教师模型仍然罕见。另一个障碍是如何设计和培训合适的教师模型。现有的蒸馏框架需要大量的努力和实验来找到最佳的教师模型架构,这需要相对较长的时间。为了训练紧凑的模型以实现尽可能高的精度,并克服传统蒸馏的缺点,提出了一种新的自蒸馏框架。我们没有在传统的提炼中实现两个步骤,即第一:训练一个大型教师模型,第二:将知识从中提炼到学生模型,而是
提出了一个一步自蒸馏框架,其训练直接针对学生模型。
2、相关工作
一般来说,教师模型和学生模型分别以各自的方式工作,知识在不同的模型之间流动。相反,我们提出的自蒸馏方法中的学生和教师模型来自相同的卷积神经网络。
自适应计算
:一些研究人员倾向于选择性地跳过几个计算过程来消除冗余。他们的工作可以从三个不同的角度来见证:层次、通道和图像。
跳过神经网络中的某些层。
跳过神经网络中的某些通道。
跳过当前输入图像中不太重要的像素。
深度监督。深度监督是基于这样的观察,即根据高度辨别特征训练的分类器可以提高推理性能。为了解决梯度消失问题,增加了额外的监督来直接训练隐藏层。自蒸馏框架类似于深度监督网络。自蒸馏的主要区别在于,浅分类器是通过蒸馏而不是通过标签来训练的,这导致了实验结果支持的明显更高的准确性。
3、自蒸馏
如图
2
所示。

我们
通过以下思维方式构建自蒸馏框架
:
首先,根据目标卷积神经网络的深度和原始结构,将其分为几
个浅层部分
。例如,
ResNet50
根据
ResBlock
分为
4
个部分。
其次,在每个浅部分之后设置一个分类器,
该分类器与瓶颈层和完全连接层相结合,这些层仅用于训练,可以在推理中去除
。
添加
bottleneck
层的
主要考虑是减轻每个浅分类器之间的影响,并增加
hint
的
L2
损失
。
在训练期间,所有具有相应分类器的
浅部分都是通过从最深部分中蒸馏出来,训练成学生模型,这在概念上可以被视为教师模型。为了提高学生模型的性能,在训练过程中引入了三种损失:
损失来源
1
:从标签到最深分类器,以及所有浅层分类器的交叉熵损失。它是用来自
训练数据集的标签和
每个分类器的
softmax
层的输出来计算的
。通过这种方式,
隐藏在数据集中的知识直接从标签引入到所
有分类器。
损失来源
2
:
KL
是在教师的指导下
1
的散度损失
,
KL
散度是使用学生和教师之间的
softmax
输出来计算
的,并被引入到每个浅分类器的
softmax
层
。通过引入
KL
散度,自蒸馏框架影响教师的网络,即最深的 网络,到每个浅分类器。
损失来源
3
:
hint
的
L2
损失。它
可以通过计算最深分类器和每个浅分类器的特征图之间的
L2
损失来获
得
。
通过
L2
损失,将特征图中的不精确知识引入到每个浅分类器的瓶颈层,从而使其瓶颈层中的所有分
类器的特征图都结合最深分类器的特征映射
。
3.1构想
给定
M
类中的N个样本

,我们将其相应的标签集表示

神经
网络中的分类器(所提出的
自蒸馏在整个网络中具有多个分类器)表示为

,其中
C
表示卷积神经网
络中分类器的数量。在每个分类器之后设置
softmax
层。

这里,
z是全连接层之后的输出。

是分类器,

的第i个可能类别。
。
T
通常设置为
1
,表示蒸馏温度。
T
越大,概率分布越柔和。
3.2训练方法
在自蒸馏中,除最深层分类器

外,每个分类器的监督来自三个来源。使用两个超参数

和
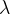
来平衡他们。

第一个来源是用
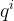
和标签y计算的交叉熵损失。
注意,
表示分类器,
是softmax层的输出。

第二个来源是
和

之间的
KL
,我们的目标是使浅分类器接近最深分类器,这表明来自蒸
馏的监督。注意,
表示最深分类器的softmax层的输出。

最后一个监督是来自最深层分类器的提示。提示被定义为教师模型隐藏层的输出,其目的是引导学生模型学习。它的工作原理是减少浅层分类器与最深分类器中特征图之间的距离。然而,由于不同深度的特征图具有不同的大小,因此应该添加额外的层来对齐它们。我们使用的不是卷积层,而是对模型性能产生积极影响的bottleneck
结构。
综上:整个神经网络的损失函数由每个分类器的损失函数组成

请注意,最深分类器的为0,
这意味着最深分类器对所有标签的监督只来自标签。
4
、实验
自蒸馏框架的一个显著优点是他不需要额外的教师。相比之间,传统的蒸馏方法首先需要设计和训练一个过渡参数化的教师模型。涉及一个高质量的教师模型需要大量的实验来找到最佳的深度和架构。这些问题可以在自蒸馏中直接避免,教师和学生模型都是其自身的子部分。
比深度监督的好处:在自蒸馏中,(i)
添加额外的
bottleneck
层来检测分类器特定的特性,避免了浅分类和深分类器之间的冲突。
(ii)
蒸馏方法已被用于训练分类器而不是标签以提高性能
(
iii)
更好的浅层分类器可以获得更多的判别特性,这反过来提高了更深层次分类器的性能。
标签:Convolutional,
教师,
Own,
蒸馏,
训练,
Neural,
模型,
损失,
分类器
From: https://blog.csdn.net/weixin_43238909/article/details/136676987