PyTorch学习教程
1-安装PyTorch
PyTorch 安装官网选择对应的版本进行下载链接的复制(注意CUDA版本和Driver Version版本的一致性)
注意conda需要换源
换源后直接使用下面的指令。
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
以下是注意事项:
原先的conda源地址
show_channel_urls: true
ssl_verify: true
envs_dirs:
- X:\SetupPackage\Anaconda\envs
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
新配置文件内容:
show_channel_urls: true
ssl_verify: true
envs_dirs:
- X:\SetupPackage\Anaconda\envs
channels:
- http://mirrors.aliyun.com/anaconda/pkgs/msys2
- http://mirrors.aliyun.com/anaconda/pkgs/r
- http://mirrors.aliyun.com/anaconda/pkgs/main
- defaults
其它注意事项:
conda需要更新版本(需要管理员运行终端)
conda update -n base -c defaults conda 更新conda相关版本,以适应安装需求。
conda clean --all 清理缓存文件,以释放磁盘空间(不会对已经安装好的包产生任何影响)。
conda update --all 更新所有包
2-两大函数
dir()函数,help()函数。
可以使用这两个函数来学习不同包中含有的语法函数以及作用是什么。
3-不同工具解释
python文件中是以一整块为整体的,从头到尾运行。(通用,传播方便)
python控制台中是以每一行为快,运行的。(用于调试,可以显示每个变量属性,但不利于代码的任意修改)
Jupyter中是任意行为快运行的,方便随时更改,其后任然是块(学习方便,方便修改,环境需要配置)
4-加载数据
Dataset:提供一种方式取获取数据及label。(如何获取每个数据及其label、告诉我们总共有多少的数据)
# -*- coding: utf-8 -*-
# @Time : 2024/1/31 14:58
# @Author: tao
# @FileName: read_data.py
# @Software: PyCharm
from torch.utils.data import Dataset
from PIL import Image
import os
class MyDataset(Dataset):
#初始化路径 和 标签
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir) #将路径和类名拼接在一起
self.img_path = os.listdir(self.path) #获取路径下的所有图片地址
#获取其中的每一个图片(图片、标签)
def __getitem__(self, idx):
img_name = self.img_path[idx] #名称
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) #每一个图像的地址
img = Image.open(img_item_path)
label = self.label_dir
return img,label
#获取列表的长度
def __len__(self):
return len(self.img_path)
root_dir = "Base_Learn/视频学习/dataset/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyDataset(root_dir,ants_label_dir)
bees_dataset = MyDataset(root_dir,bees_label_dir)
train_dataset = ants_dataset + bees_dataset #蚂蚁在前面,蜜蜂在后面,拼接
Dataloader: 为后面的网络提供不同 的数据形式。
5-图片转换
总结:使用pyTorch库,需要注意输入输出,多看官方文档,关注方法需要什么参数。
5.1-tensorboard的使用
TensorBoard 是一组用于数据可视化的工具。
TensorBoard 的主要功能包括:
- 可视化模型的网络架构
- 跟踪模型指标,如损失和准确性等
- 检查机器学习工作流程中权重、偏差和其他组件的直方图
- 显示非表格数据,包括图像、文本和音频
- 将高维嵌入投影到低维空间
tensorboard --logdir=logs --port=6007 #新加端口的设置
代码:
# -*- coding: utf-8 -*-
# @Time : 2024/1/31 15:49
# @Author: tao
# @FileName: Tensorboard.py
# @Software: PyCharm
#tensorboard
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
img_path = "X:\\NewCode\\Pycharm_Code\\Pytorch_GPU\\Base_Learn\\视频学习\\dataset\\hymenoptera_data\\train\\ants\\5650366_e22b7e1065.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
# print(type(img_PIL))
# print(type(img_array))
writer.add_image("test",img_array,2,dataformats='HWC')
# y = 2x
for i in range(100):
#标题,y轴,x轴
writer.add_scalar("y=2x",2*i,i)
writer.close()
5.2-transform的使用(转换图片的工具)
torchvision模块
torchvision.transforms:常用的图像预处理方法
torchvision.datasets:常用数据集的dataset实现,MNIST,CIFAR-10,ImageNet等。
tochvision.model:常用的模型与训练,AlexNet,VGG,ResNet,GoogLeNet等。
torchvision.transforms:常用的数据预处理方法,提升泛化能力。
包括:数据中心化、数据标准化、缩放、裁剪、旋转、翻转、填充、噪声添加、灰度变换、线性变换、仿射变换、亮度、饱和度及对比度变换等。
代码:
# -*- coding: utf-8 -*-
# @Time : 2024/2/1 10:48
# @Author: tao
# @FileName: UsefulTransforms.py
# @Software: PyCharm
import numpy as np
from torchvision.transforms import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
img = Image.open('images/7759525_1363d24e88.jpg')
# img_array = np.array(img)
# print(img_array)
print(img)
#1-ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor",img_tensor)#前面是将其装换成ToTensor类型,方便此步骤的直接使用
# print(img_tensor)
#2-Normalize
# print(img_tensor[0][0][0]) #第一个,第一行,第一列
trans_norm = transforms.Normalize([6,3,2],[9,3,5]) #均值,方差
img_norm = trans_norm(img_tensor) #进行规划后
# print(img_norm[0][0][0])
writer.add_image("Normalize3",img_norm)
# print(img_norm)
#3-Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
#img PIL -> resize ->img_resize PIL
img_resize = trans_resize(img)
#img_resize PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("resize",img_resize,0)
# print(img_resize)
#4-Compos - resize - 2 放大
trans_resize_2 = transforms.Resize(512)
#PIL -> PIL -> tensor 注意下面Compose数据类型需要相应的匹配,确保一致性
trans_compos = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compos(img)
writer.add_image("resize",img_resize_2,1)
#5-RandomCrop 随机裁剪
trans_random = transforms.RandomCrop((200,300))
trans_compos_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compos_2(img)
writer.add_image("RandomCropHW",img_crop,i)
writer.close()
5.2.1-transforms.ToTensor()
将图片 处理后,输出为我们所用的图片格式。

5.2.2-transforms.Normalize()
为什么要使用Normalize: Totensor将数据归一到[0,1]之后,再通过Normalize计算过后,将数据归一化到[-1,1]。
[0,1]只是范围改变了,并没有改变分布,mean和std处理后,可以让数据正态分布。
功能:逐channel的对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛。output = (input - mean) / std
mean:各通道的均值
std:各通道的标准差
inplace:是否原地操作
input[channel] = (input输入[channel] - mean均值[channel] ) / std方差[channel]
思考:
(1)据我所知,归一化就是要把图片3个通道中的数据整理到[-1, 1]区间。
x = (x - mean(x))/std(x)
只要输入数据集x确定了,mean(x)和std(x)也就是确定的数值了,为什么Normalize()函数还需要输入mean和std的数值呢????
解答:mean 和 std 肯定要在normalize()之前自己先算好再传进去的,不然每次normalize()就得把所有的图片都读取一遍算这两个
(2)RGB单个通道的值是[0, 255],所以一个通道的均值应该在127附近才对。
如果Normalize()函数去计算 x = (x - mean)/std ,因为RGB是[0, 255],算出来的x就不可能落在[-1, 1]区间了。
解答:针对第二个问题,有两种情况
(a )如果是imagenet数据集,那么ImageNet的数据在加载的时候就已经转换成了[0, 1].
(b) 应用了torchvision.transforms.ToTensor,其作用是将数据归一化到[0,1](是将数据除以255),transforms.ToTensor()会把HWC会变成C *H *W(拓展:格式为(h,w,c),像素顺序为RGB)
(3)在我看的了论文代码里面是这样的:
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
为什么就确定了这一组数值,这一组数值是怎么来的? 为什么这三个通道的均值都是小于1的值呢?
解答:针对第三个问题:[0.485, 0.456, 0.406]这一组平均值是从imagenet训练集中抽样算出来的。
6-三通道彩色图像的存储
opencv里面的图像存储为BGR,与流行的RGB正好相反
# img.shape H*W*3 = 高度 * 宽度 * 3通道
(1080, 1920, 3)
# img.size
6220800
# img.dtype
uint8
# img
[[[255 255 255]
[255 255 255]
[255 255 255]
...
图像的 shape 为 (1080, 1920, 3),第一维 1080 表示有 1080 行,所以有 1080 个小的二维矩阵,每个二维矩阵是三通道图像中的一行。

在每一个小矩阵中,有 1920 行,每一行有 3 列,每一行的三个像素值就对应当前位置的 B G R 三个通道。这列能够看出,虽然按照行来分块,但实际上列方向才是位置上相邻的像素点。

再从通道的角度看,BGR 是三通道,第一整列对应的就是一幅图所有的 B 通道灰度值(更准确一些应该叫亮度值),第二、第三就分别是 G 和 R 通道对应的灰度值。下图只截取了一部分。

import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib qt5
img = cv2.imread('Touka.jpg')
channels = ["B", "G", "R"] # 注意通道顺序
for i in range(3):
print("channel: " + channels[i])
print(img[:,:,i])
plt.subplot(1, 3, i+1)
plt.imshow(img[:,:,i], cmap=plt.cm.gray)
plt.title(channels[i])
print(img[:,:,0].shape)
plt.show()
7-数据集
7-1 dataset
对数据集进行封装,对数据进行预处理,清洗数据,记录 sample 与 label 的对应关系;
# -*- coding: utf-8 -*-
# @Time : 2024/2/1 12:58
# @Author: tao
# @FileName: dataset_transform.py
# @Software: PyCharm
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
#应用到每一张图片中,进行转换ToTensor,Tensor格式的转换
train_set = torchvision.datasets.CIFAR10(root="../../dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=dataset_transform,download=True)
print(test_set[0])
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
7-2 dataloader
一般来说PyTorch中深度学习训练的流程是这样的: 1. 创建Dateset 2. Dataset传递给DataLoader 3. DataLoader迭代产生训练数据提供给模型
对应的一般都会有这三部分代码
# 创建Dateset(可以自定义)
dataset = face_dataset # Dataset部分自定义过的face_dataset
# Dataset传递给DataLoader
dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=False,num_workers=8)
# DataLoader迭代产生训练数据提供给模型
for i in range(epoch):
for index,(img,label) in enumerate(dataloader):
pass
到这里应该就PyTorch的数据集和数据传递机制应该就比较清晰明了了。Dataset负责建立索引到样本的映射,DataLoader负责以特定的方式从数据集中迭代的产生 一个个batch的样本集合。在enumerate过程中实际上是dataloader按照其参数sampler规定的策略调用了其dataset的getitem方法。
先看一下实例化一个DataLoader所需的参数,我们只关注几个重点即可。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
参数介绍:
dataset (Dataset) – 定义好的Map式或者Iterable式数据集。
batch_size (python:int, optional) – 一个batch含有多少样本 (default: 1)。
shuffle (bool, optional) – 每一个epoch的batch样本是相同还是随机 (default: False)。
sampler (Sampler, optional) – 决定数据集中采样的方法. 如果有,则shuffle参数必须为False。
batch_sampler (Sampler, optional) – 和 sampler 类似,但是一次返回的是一个batch内所有样本的index。和 batch_size, shuffle, sampler, and drop_last 三个参数互斥。
num_workers (python:int, optional) – 多少个子程序同时工作来获取数据,多线程。 (default: 0) windows如果大于0可能会出错。
collate_fn (callable, optional) – 合并样本列表以形成小批量。
pin_memory (bool, optional) – 如果为True,数据加载器在返回前将张量复制到CUDA固定内存中。
drop_last (bool, optional) – 如果数据集大小不能被batch_size整除,设置为True可删除最后一个不完整的批处理。如果设为False并且数据集的大小不能被batch_size整除,则最后一个batch将更小。(default: False)
timeout (numeric, optional) – 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。 (default: 0)
worker_init_fn (callable, optional) – 每个worker初始化函数 (default: None)
# -*- coding: utf-8 -*-
# @Time : 2024/2/1 14:26
# @Author: tao
# @FileName: dataloader.py
# @Software: PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
#准备的测试集
test_set = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=dataset_transform,download=True)
test_loader = DataLoader(dataset=test_set,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#drop_last 是否舍弃不足batch_size大小的
#shuffle 在对数据进行读取时,如果是多轮读取,设置shuffle为False,在不同epoch中,他们的值会随机打乱的。
#shuffle如果是True,则不会打乱。
#测试数据集中第一张图片及target
img, target = test_set[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data",imgs,step)
step = step + 1
writer.close()
8-神经网络-基本骨架
nn.Module的使用

nn_module使用
# -*- coding: utf-8 -*-
# @Time : 2024/2/1 15:44
# @Author: tao
# @FileName: nn_module.py
# @Software: PyCharm
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
卷积层使用:
# -*- coding: utf-8 -*-
# @Time : 2024/2/1 16:25
# @Author: tao
# @FileName: nn_conv.py
# @Software: PyCharm
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5)) #数量,通道, 宽, 高
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# print(input)
# print(kernel)
output = F.conv2d(input, kernel, stride=1) #输入图像, 卷积核, 移动的大小
print(output)
output = F.conv2d(input, kernel, stride=2)
print(output)
output = F.conv2d(input, kernel, stride=1, padding=1) #输入图像, 卷积核, 移动的大小, 补充边缘
print(output)
开始整理笔记
9-神经网络-卷积层
卷积层解释:卷积层的作用是提取输入图片中的信息,这些信息被称为图像特征,这些特征是由图像中的每个像素通过组合或者独立的方式所体现,比如图片的纹理特征,颜色特征。
卷积操作是通过卷积核对每个通道的矩阵从左到右(卷积核一般是3x3的矩阵)从上至下进行互相关运算(先是从左到右,再是从上至下,所以卷积操作也会保留位置信息),就像一个小的窗口一样,从左上角一步步滑动到右下角,滑动的步长是个超参数,互相关运算的意思就是对应位置相乘再相加,最后把三个通道的值也对应加起来得到一个值。
图像卷积运算如下图所示:

卷积层有很多卷积核,通过做越来越多的卷积,提取到的图像特征会越来越抽象。
代码描述:
# -*- coding: utf-8 -*-
# @Time : 2024/2/1 16:25
# @Author: tao
# @FileName: nn_conv.py
# @Software: PyCharm
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5)) #数量,通道, 宽, 高
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# print(input)
# print(kernel)
output = F.conv2d(input, kernel, stride=1) #输入图像, 卷积核, 移动的大小
print(output)
output = F.conv2d(input, kernel, stride=2)
print(output)
output = F.conv2d(input, kernel, stride=1, padding=1) #输入图像, 卷积核, 移动的大小, 补充边缘
print(output)
真实代码描述:
# -*- coding: utf-8 -*-
# @Time : 2024/2/2 11:40
# @Author: tao
# @FileName: nn_conv2d.py
# @Software: PyCharm
import torch
from torch import nn
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)#获取64个数据(图片)
#定义模型的地方
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
#输出的通道数,要输出的通道数,核心曾,步长,填充量
def forward(self, x):
x = self.conv1(x) #将x放入卷积层中
return x
tudui = Tudui()
step = 0
writer = SummaryWriter("./logs") #日志存放地点
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(output.shape)
#torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs,step)
#torch.Size([64, 6, 30, 30]) 需要更改图形大小 ,变成上面的通道数量 torch.Size([64*2, 3, 30, 30])
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
print(output.shape)
step = step + 1
writer.close()
效果类似如下(进行图像特征的提取):



10-神经网络-最大池化
池化层的作用是对卷积层中提取的特征进行挑选
常见的池化操作有最大池化和平均池化,池化层是由n×n大小的矩阵窗口滑动来进行计算的,类似于卷积层,只不过不是做互相关运算,而是求n×n大小的矩阵中的最大值、平均值等。
如图,对特征图进行最大池化和平均池化操作:
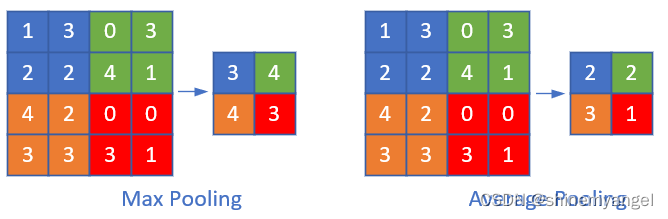
池化层主要有以下几个作用:
-
挑选不受位置干扰的图像信息。
-
对特征进行降维,提高后续特征的感受野,也就是让池化后的一个像素对应前面图片中的一个区域。
-
因为池化层是不进行反向传播的,而且池化层减少了特征图的变量个数,所以池化层可以减少计算量。
代码实例:
# -*- coding: utf-8 -*-
# @Time : 2024/2/2 12:27
# @Author: tao
# @FileName: nn_maxpool.py
# @Software: PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)#获取64个数据(图片)
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]],dtype=torch.float32) #进行数据类型的转换
# input = torch.reshape(input,(-1,1,5,5))
# print(input.shape)
class Lt(nn.Module):
def __init__(self):
super(Lt,self).__init__()
self.maxpool1 = MaxPool2d(3,ceil_mode=True)
def forward(self,x):
output = self.maxpool1(x)
return output
# lt = Lt()
# output = lt(input)
# print(output)
lt = Lt()
step = 0
writer = SummaryWriter("./logs")
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs,step)
output = lt(imgs)
writer.add_images("output",output,step)
step = step + 1
writer.close()
11-神经网络-非线性激活
非线性变换,引入非线性特征
如果神经元的输出是输入的线性函数,而线性函数之间的嵌套任然会得到线性函数。如果不加非线性函数处理,那么最终得到的仍然是线性函数。所以需要在神经网络中引入非线性激活函数。
常见的非线性激活函数主要包括Sigmoid函数、tanh函数、ReLU函数、Leaky ReLU函数。
11.1-ReLU函数
Rectified Linear Unit,是一种人工神经网络中常用的激活函数,通常意义下,其指代数学中的斜坡函数,即
f ( x ) = max ( 0 , x )
f(x)=max(0,x)
对应的函数图像如下所示:
 ****
****
而在神经网络中,ReLU函数作为神经元的激活函数,为神经元在线性变换 w T x + b之后的非线性输出结果。换言之,对于进入神经元的来自上一层神经网络的输入向量 x xx,使用ReLU函数的神经元会输出
max ( 0 , w T x + b )
至下一层神经元或作为整个神经网络的输出(取决现神经元在网络结构中所处位置)。
优势
相比于传统的神经网络激活函数,诸如逻辑函数(Logistic sigmoid)和tanh等双曲函数,ReLU函数有着以下几方面的优势:
-
仿生物学原理:相关大脑方面的研究表明生物神经元的讯息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。使用线性修正以及正规化;(regularization)可以对机器神经网络中神经元的活跃度(即输出为正值)进行调试;相比之下,逻辑函数在输入为0时达到 0.5,即已经是半饱和的稳定状态,不够符合实际生物学对模拟神经网络的期望。不过需要指出的是,一般情况下,在一个使用ReLU的神经网络中大概有50%的神经元处于激活态。
-
更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题;
-
简化计算过程:没有了其他复杂激活函数中诸如指数函数的影响;同时活跃度的分散性使得神经网络整体计算成本下降.
代码示例:
# -*- coding: utf-8 -*-
# @Time : 2024/2/2 13:04
# @Author: tao
# @FileName: nn_relu.py
# @Software: PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# input = torch.tensor([[1,-0.5],
# [-1,3]])
#
# input = torch.reshape(input,(-1,1,2,2))
#
# print(input)
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)#获取64个数据(图片)
class Lt(nn.Module):
def __init__(self):
super(Lt,self).__init__()
self.relu1 = ReLU(False)
self.sigmoid1 = Sigmoid()
def forward(self,input):
# output = self.relu1(input)
output = self.sigmoid1(input)
return output
lt = Lt()
# output = lt(input)
# print(output)
step = 0
writer = SummaryWriter("./logs")
for data in dataloader:
imgs, targets = data
writer.add_images("in_Sigmoid",imgs,step)
output = lt(imgs)
writer.add_images("out_Sigmoid",output,step)
step = step + 1
writer.close()
12-神经网络-线形层
及其它层介绍
线性网络介绍
线性层参数 in_features 就是输入x,out_features 是线性层的输出是上图的g。x到g的关系式为:,其中的
是权重,
是偏置(参数bias为True时,才存在)。
in_features:x1 ...
out_features: g1 ...
每一条线段:K1 * X1 + B1(偏执)

# -*- coding: utf-8 -*-
# @Time : 2024/2/2 15:39
# @Author: tao
# @FileName: nn_linear.py
# @Software: PyCharm
import torch
import torchvision
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch import nn
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)#获取64个数据(图片)
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
lt = Lt()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
# output = torch.reshape(imgs,(1,1,1,-1))
output = torch.flatten(imgs)
print(output.shape)
output = lt(output)
print(output.shape)
13-神经网络-Sequential 与 实战
通过搭建一个简单的网络模型来练习sequential。
下面是搭建模型的框架图(模型结构,下面有代码实现)

# -*- coding: utf-8 -*-
# @Time : 2024/2/2 16:14
# @Author: tao
# @FileName: nn_seq.py
# @Software: PyCharm
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)#获取64个数据(图片)
class Lt(nn.Module):
def __init__(self):
super().__init__()
# self.conv1 = Conv2d(3,32,5,1,2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,5,1,2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,5,1,2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
self.model1 = Sequential(
Conv2d(3,32,5,1,2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
lt = Lt()
print(lt)
#以下代码用来检测 网络的正确性检测(还可以用来计算图片的shape)
input = torch.ones(64,3,32,32)
output = lt(input)
print(output.shape)
writer = SummaryWriter("./logs_sequential")
writer.add_graph(lt,input)
writer.close()
14-神经网络-衡量误差
损失函数与反向传播
# -*- coding: utf-8 -*-
# @Time : 2024/2/2 16:49
# @Author: tao
# @FileName: nn_loss.py
# @Software: PyCharm
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
output = torch.reshape(targets,(1,1,1,3))
loss = L1Loss() #构建Loss函数
result = loss(inputs,output)#将输入和输出 填入以计算loss值
loss_mse = MSELoss()
result_mse = loss_mse(inputs,output)
#交叉熵Loss(另一种Loss对象)
x = torch.tensor([0.001,0.98,0.001])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
实际情况代码
# -*- coding: utf-8 -*-
# @Time : 2024/2/3 12:12
# @Author: tao
# @FileName: nn_loss_network.py
# @Software: PyCharm
import torchvision
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch import nn
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)#获取64个数据(图片)
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3,32,5,1,2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
lt = Lt()
for data in dataloader:
imgs, targets = data
output = lt(imgs)
result_loss = loss(output,targets)
# print(result)
#梯度下降-反向传播
result_loss.backward() #添加方向传播grad,自己计算grad值,为后续优化提供依据
print("ok")
15-神经网络-优化器
构建优化器,以提升模型的训练效果。
关键代码optim = torch.optim.SGD(lt.parameters(),lr=0.01) #设置parameters、设置速率
# -*- coding: utf-8 -*-
# @Time : 2024/2/3 12:30
# @Author: tao
# @FileName: nn_optim.py
# @Software: PyCharm
import torch.optim
import torchvision
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch import nn
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)#获取64个数据(图片)
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3,32,5,1,2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1, 2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1, 2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
lt = Lt()
optim = torch.optim.SGD(lt.parameters(),lr=0.01) #设置parameters、设置速率
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
output = lt(imgs)
result_loss = loss(output,targets)
#梯度下降-反向传播
optim.zero_grad()#梯度清零
result_loss.backward() # 添加方向传播grad,自己计算grad值,为后续优化提供依据
optim.step()#对梯度调优
running_loss = running_loss + result_loss
print(running_loss)
优化效果:

16-神经网络-模型使用与修改
需要提前安装好scipy包
# -*- coding: utf-8 -*-
# @Time : 2024/2/3 13:36
# @Author: tao
# @FileName: model_pretrained.py
# @Software: PyCharm
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# train_data = torchvision.datasets.ImageNet("../../dataset",split='train',download=True,
# transform=torchvision.transforms.ToTensor)
vgg16_false = torchvision.models.vgg16(pretrained = False)
vgg16_true = torchvision.models.vgg16(pretrained = True)
# print(vgg16_true) #输出模型结构
dataset = torchvision.datasets.CIFAR10(root="../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)#获取64个数据(图片)
#添加模型层
# vgg16_true.add_module('add_linear', nn.Linear(1000,10))
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000,10))
print(vgg16_true) #输出vgg16_true 添加后的结构
#修改模型层
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false) #输出vgg16_false 修改后的结构
17-模型保存-加载
保存模型
# -*- coding: utf-8 -*-
# @Time : 2024/2/4 14:32
# @Author: tao
# @FileName: model_save.py
# @Software: PyCharm
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16()
#保存1
torch.save(vgg16,"vgg16_method1.pth") #保存的是模型的结构+参数
#保存2 —— 官方推荐
torch.save(vgg16.state_dict(),"vgg16_method2.pth")#将vgg16模型中的 参数 保存 成字典形式
#陷阱
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x = self.conv1(x)
return x
lt = Lt()
torch.save(lt,"lt_method1.oth")
加载
# -*- coding: utf-8 -*-
# @Time : 2024/2/4 14:34
# @Author: tao
# @FileName: model_load.py
# @Software: PyCharm
import torch
import torchvision.models
from torch import nn
#方式1(对应保存方式一)——加载模型
# model = torch.load('vgg16_method1.pth')
# print(model)
#方式2 —— 字典形式加载
vgg16 = torchvision.models.vgg16()
vgg16.load_state_dict(torch.load('vgg16_method2.pth')) #通过字典形式加载模型
# model = torch.load('vgg16_method2.pth')
# print(vgg16)
#陷阱1
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x = self.conv1(x)
return x
model = torch.load('lt_method1.oth')
print(model)
18-完整的模型训练套路
(1-2-3)
train.py文件
# -*- coding: utf-8 -*-
# @Time : 2024/2/4 14:50
# @Author: tao
# @FileName: train.py
# @Software: PyCharm
import torch
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
#准备数据集
train_data = torchvision.datasets.CIFAR10("../../dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#leng 长度
train_data_size = len(train_data) #训练数据集的大小
test_data_size = len(test_data) #训练数据集的大小
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#搭建神经网络
lt = Lt()
#创建损失函数
loss_fn = nn.CrossEntropyLoss()
#优化器
learning_rate = 0.01 # 1e-2
optimizer = torch.optim.SGD(lt.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("----------第 {} 轮训练开始----------".format(i+1))
#训练步骤开始
# lt.train() #对特定的层有作用
for data in train_dataloader:
imgs, targets = data
outputs = lt(imgs)
loss = loss_fn(outputs,targets)
#梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step() #开始进行 优化
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
# dropout关掉
# lt.eval() #对特定的层有作用
total_test_loss = 0
#正确率的计算
total_accuracy = 0
with torch.no_grad(): #清除梯度,不需要梯度进行优化
for data in test_dataloader:
imgs, targets = data
outputs = lt(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
#保存每一轮的结果
torch.save(lt,"lt_{}.pth".format(i))
#官方推荐的保存方式
#orch.save(lt.state_dict(),"lt_{}.pth".format(i))
print("模型已保存")
writer.close()
模型单独存放文件 model.py
# -*- coding: utf-8 -*-
# @Time : 2024/2/4 15:00
# @Author: tao
# @FileName: model.py
# @Software: PyCharm
import torch
from torch import nn
#搭建神经网络
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
lt = Lt()
input = torch.ones((64,3,32,32))
output = lt(input)
print(output.shape)
19-利用GPU训练
19.1-方式1(貌似不常用)
lt = Lt()
if torch.cuda.is_available():
lt = lt.cuda() #GPU训练
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = lt(imgs)
with torch.no_grad(): #清除梯度,不需要梯度进行优化
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
实用代码:
# -*- coding: utf-8 -*-
# @Time : 2024/2/4 16:26
# @Author: tao
# @FileName: train_gpu_1.py
# @Software: PyCharm
import torch
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
#准备数据集
train_data = torchvision.datasets.CIFAR10("../../dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#leng 长度
train_data_size = len(train_data) #训练数据集的大小
test_data_size = len(test_data) #训练数据集的大小
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#搭建神经网络
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
lt = Lt()
if torch.cuda.is_available():
lt = lt.cuda() #GPU训练
#创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda() #GPU设置
#优化器
learning_rate = 0.01 # 1e-2
optimizer = torch.optim.SGD(lt.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("./logs_train")
start_time = time.time()
for i in range(epoch):
print("----------第 {} 轮训练开始----------".format(i+1))
#训练步骤开始
lt.train() #对特定的层有作用
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = lt(imgs)
loss = loss_fn(outputs,targets)
#梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step() #开始进行 优化
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time-start_time)
print("训练次数:{}, Loss:{}".format(total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
lt.eval() #对特定的层有作用
total_test_loss = 0
#正确率的计算
total_accuracy = 0
with torch.no_grad(): #清除梯度,不需要梯度进行优化
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = lt(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
#保存每一轮的结果
torch.save(lt,"lt_{}.pth".format(i))
#官方推荐的保存方式
#orch.save(lt.state_dict(),"lt_{}.pth".format(i))
print("模型已保存")
writer.close()
19.2-方式2
使用时:.to(device)
定义device时:Device = torch.device("cpu")
Torch.device("cuda:0")
常见写法(如下行代码):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
使用代码:
# -*- coding: utf-8 -*-
# @Time : 2024/2/5 13:44
# @Author: tao
# @FileName: train_gpu_2.py
# @Software: PyCharm
import torch
import torch.optim
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
#定义训练的设备
device = torch.device("cuda:0")
#准备数据集
train_data = torchvision.datasets.CIFAR10("../../dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../../dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
#leng 长度
train_data_size = len(train_data) #训练数据集的大小
test_data_size = len(test_data) #训练数据集的大小
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#搭建神经网络
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
lt = Lt()
lt.to(device) #方式二调用CUDA
#创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) #调用CUDA
#优化器
learning_rate = 0.01 # 1e-2
optimizer = torch.optim.SGD(lt.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 10
#添加tensorboard
writer = SummaryWriter("./logs_train")
start_time = time.time()
for i in range(epoch):
print("----------第 {} 轮训练开始----------".format(i+1))
#训练步骤开始
lt.train() #对特定的层有作用
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = lt(imgs)
loss = loss_fn(outputs,targets)
#梯度清零
optimizer.zero_grad()
loss.backward()
optimizer.step() #开始进行 优化
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time-start_time)
print("训练次数:{}, Loss:{}".format(total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
lt.eval() #对特定的层有作用
total_test_loss = 0
#正确率的计算
total_accuracy = 0
with torch.no_grad(): #清除梯度,不需要梯度进行优化
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = lt(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
#保存每一轮的结果
torch.save(lt,"lt_{}.pth".format(i))
#官方推荐的保存方式
#orch.save(lt.state_dict(),"lt_{}.pth".format(i))
print("模型已保存")
writer.close()
20-完整的模型验证套路
测试 or Demo (利用已经训练好的模型,然后给它提供服务)
通过直接调用以训练好的模型lt_9.pth来实现对../images/img_1.png图片的预测功能。
# -*- coding: utf-8 -*-
# @Time : 2024/2/5 13:57
# @Author: tao
# @FileName: test.py
# @Software: PyCharm
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
#验证模型
image_pth = "../images/img_1.png"
image = Image.open(image_pth)
# print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
# print(image)
#开始加载网络模型
#搭建神经网络
class Lt(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
model = torch.load("./lt_9.pth")
# model = torch.load("./lt_7.pth",map_location=torch.device("cpu")) #指定、映射到cpu中
# print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
21-Github源码阅读
github搜索pytorch寻找star最多的项目进行代码的阅读和场景的复刻。