Abstract
联合训练和测特征会影响目标域的预测,因为学习的嵌入被包含偏差信息的源域所主导。于是我们提出了异构跨域推荐的预训练和微调图。我们设计了一个新的跨域推荐的预训练图神经网络(PCRec),它采用了一个图编码器的对比自监督预训练,然后我们转移预先训练好的图编码器来初始化目标域上的节点嵌入,这有利于对单域推荐系统在目标域上的微调
Introduction
由于冷启动和数据稀疏性问题,从单个领域学习的模型无法达到令人满意的性能。因为人们提出了跨域推荐。它将信息从源域传输到目标域,这样就可以提高目标域上的推荐性能。
CDR的基本思想是利用这两个领域上的共同用户来传输相关信息,这可以从两个角度来实现:
- 将源域中的用户信息建模为目标域中的辅助信息
- 联合训练两个域上的可共享参数
现有的工作假设来自源域的信息与目标域中的预测目标相关,但是这并不一定是正确的。如果一个源域包含对目标域中的显性偏差,则目标域的预测就会被误导,从而破坏推荐性能
所以我们应该设计一种新的CDR范式,它不仅可以传递信息,还可以保护目标域的预测不受来自源域的偏差的支配。我们为CDR设计一个新的预训练框架,优点有两个,首先在源域上的预训练模型将辅助信息传递到了目标域。其次对目标域中的微调步骤确保了预测受目标域信息的主导,从而克服了来自源域的偏差
之后介绍存在的问题:首先CDR中唯一可用的数据是用户-项目交互,这是非常稀疏的,然后还不清楚如何发挥预训练好的模型,同时避免偏差阻碍对目标域的预测
因此我们提出通过将图的结构信息从源域转移到目标域,来训练一个跨域推荐的图神经网络。在预训练阶段,我们采用自监督学习方案来训练一个图编码器。然后我们将预训练好的图编码器转移到目标域。然而由于编码器也被源域中的结构偏差所主导,因此我们利用预训练的编码器来初始化另一个单一域模型的节点嵌入。
并且我们发现在微调阶段中在目标域中采用简单的矩阵分解模型明显由于其他复杂模型。我们假设是一个简单的MF在源域和目标域信息之间保持平衡,而其他的复杂模型过度强调目标域上的数据,从而减少了源域信息,本文的主要贡献是设计了一个新的框架来处理CDR问题,它在源域上预先训练一个图编码器来初始化目标域中的用户/项目嵌入
Model
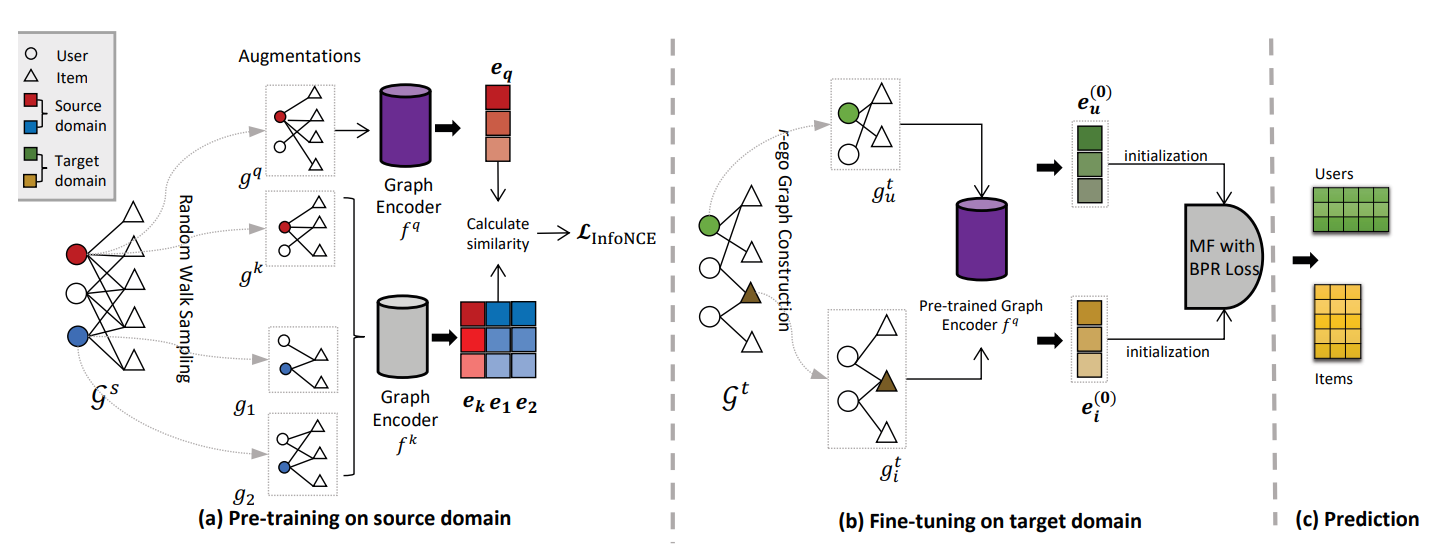
模型的总体结构如下:
对于每个节点,我们从r-ego网络中提取其上下文信息,其定义为:
节点u的r跳邻居被定义为\(\mathcal{S}_u=\{i:d(u,i)\leq r\}\)其中\(d(u,i)\)是图中u和i之间的最短路径的距离
顶点u的r-ego网络记为\(\mathcal{G}_u\),是由Su和Su对应的边组成的子图。接下来我们提出了如何采用自监督学习在源域图上训练一个图编码器
Pre-training on Source Domain
我们在预训练阶段采用SSL方案,采用对比学习方法对图编码器进行优化,SSL有三个组成部分,1.数据增强,构造一个节点的正、负子图对 2.图编码器来嵌入子图 3.对比损失来优化编码器
1)数据增强
我们将正对构造为一个节点的两个子图,子图应该共享相似的结构信息,以保证两个子图是正对。因此我们从一个节点的r-ego网络中对它们进行采样。首先对节点u的r-ego网络进行两次随机扰动,生成两个子图,将它们视为正对,然后架构不同的r-ego网络生成的子图视为负样本
2)GNN Encoder
在生成子图后,我们将它们输入到两个图编码器\(f_q\)和\(f_k\)中,我们用fq来编码正对的子图,用fk来编码其它子图。我们分布为正对\(g_q\)和\(g_k\)生成地位代表向量\(e_q\)和\(e_k\) 在这项工作中,我们选择了图同构网络(GIN)作为图编码器,因为GIN在区分广泛的图方面表现出强大的能力
3)对比损失函数
采用InfoNCE函数,在实践中,我们将这些实例视为一个查询嵌入\(e_q\)和一组关键嵌入\(\{\mathbf{e}_i\}|_{i=1}^n\)。对比损失查找一个\(e_q\)在键集中匹配的单个键\(e_k\)
在对比学习中,保持K大小的查找键集是必不可少的。直观的说,更大的key大小会导致对底层数据空间进行更好的采样。由于计算约束,我们采用Moco训练方案,MoCo能够增加键集的大小,而无需增加额外的反向传播成本。
4)对目标域进行微调
在从源域获得预训练的GIN模型后,我们应该将模型转移到目标域,然而由于预训练的编码器受到源域图的结构偏差的影响,直接微调目标域的编码器不能避免源域偏差的干扰。相反,我们使用预训练的GIN模型来初始化目标域中的节点嵌入。然后我们对一个具有初始化嵌入的简单矩阵分解模型进行微调,以推断出节点的最终嵌入。