Abstract
跨域推荐(cross-domain recommend CDR)旨在利用源域在目标域中提供更好的推荐结果,这在推荐系统中得到了广泛的应用和探索,然而匹配模块的CDR在表示学习和知识转移中都存在这数据稀疏性和流行偏差问题。在这项工作中我们提出了一个新的对比跨域推荐(CCDR)框架的CDR匹配,具体来说我们构建了一个巨大的多样化偏好网络来捕获反映用户不同兴趣的多个信息,并设计了一个域内对比学习和三个域间对比学习任务,以更好的进行表示学习和知识转移。域间对比学习通过图增强在目标域内实现更有效和更平衡的训练,而域内对象学习从用户、分类和邻居方面构建不同类型的跨域交互。
Introduction
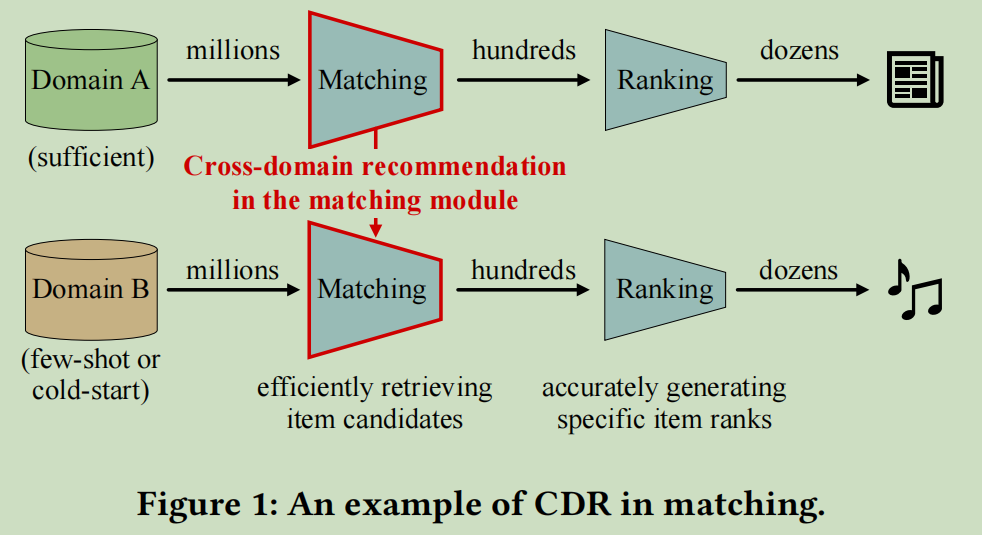
目前的推荐通常采用经典的包含排名和匹配的两级架构。匹配模块更关注效率和多样性,它首先从百万级大语料库中检索候选项的一个小子集。接下来排名模块给出了最终显示的项目的特定等级。
因为这是第一次接触CDR,所以就展示一下图,详细介绍一下:
随着推荐规模的增加和推荐场景的扩大,现实世界的推荐通常需要引入更多的数据源作为补充,以提高其内容覆盖率和多样性。这些新数据源的冷启动项目在热身阶段只有很少的用户行为。因此很难适当地推荐这些冷启动项目。提出跨域推荐旨在充分利用来自源领域的信息知识来帮助目标域的推荐,以解决这一问题。
但是现有的CDR方法通常严重依赖于对齐的用户表示来构建用户映射函数,而忽略了推荐中的其他丰富信息,如分类法。它将损害不同领域之间的知识转移,特别是在冷启动场景中。
此外许多CDR方法都考虑了复杂的跨域用户-项目交互,由于在线效率的问题,不能直接用于匹配。匹配模块中的CDR不仅要考虑推荐的准确性,还要考虑多样性和效率
在这项工作中,我们的目标是通过CDR的方式来提高匹配模块在新的(few-shot或严格的冷启动)域上的性能。图1显示了这个任务的说明。准确的说,CDR的匹配主要存在以下三个挑战:
- 如何解决CDR在匹配中的数据稀疏性和流行度偏差的问题
- 如何在用户行为很少的情况下对目标领域(冷启动)进行更有效的知识转移,传统的CDR方法强烈地依赖于用户对齐的用户及其行为。如果大多数用户和项目的交互作用很少,并且模型不能在冷启动领域中学习可靠的表示,那么CDR在匹配中的性能将会大大降低。此外在CDR中还应该充分考虑其他异构信息,以连接不同的域。我们应该建立更有效和更健壮的跨域知识转移路径,以更好的学习流行对象和长尾对象。
- 如何平衡CDR匹配的准确性、多样性和效率的实际要求?需要严格遵守在线效率的要求。此外匹配比排序更能影响多样性,因为它决定了排序的输入。一个好的CDR匹配模型应该通过多条路径将用户不同的偏好全面转移到目标域
为了解决这些问题,我们提出了一种新的对比交叉域推荐(CCDR)来在匹配中转移用户偏好。具体来说,我们为两个领域构建了两个全局多样化的偏好网络,包含六种类型的对象,以增强多样性和跨域连接。我们对异构交互进行了一个基于邻居相似性损失的GNN聚合器,以捕获用户不同的兴趣。为了加强跨领域的知识转移,我们在CCDR中设计了域内对比学习和域间对比学习。对比学习内部使用基于子图的数据增强进行额外的自监督学习,以学习更可靠的目标域匹配表示。
相比之下,CL内设计了三种对比性的学习任务,它们侧重于对齐用户、分类和它们异构邻居之间的跨域映射。具有不同类型对象的互信息最大化增加了跨领域知识转移的有效性,最后在多任务学习(MTL)框架下,将所有额外的CL损失与原始的CDR损失相结合。我们进行了跨域多通道匹配,以进一步提高在线匹配的多样性
CCDR具有以下三个优点:
- cl内部为长尾用户和项目带来了自监督学习,从而缓解了匹配中的数据稀疏性和流行偏差问题
- cl间引入了新的基于cl的跨域交互作用使得CDR在匹配中更有效,更健壮
- 多样化的偏好网络,多CL任务和跨域多通道匹配很好地捕获了用户的多样性偏好,满足了在线系统中多样性和效率的要求
本篇文章的贡献如下:
- 提出了一种新的对比跨域推荐的CDR匹配
- 提出了一种基于子图的数据增强的CL内任务,以学习单域内更好的节点表示,从而缓解匹配CDR中的数据稀疏性问题
- 我们还通过多样化偏好网络中的对齐用户、分类和它们的邻居创造性的设计了三个cl间任务,这使得在不同领域之间更有效和多样化的知识转移路径
Methodology
Problem Definition
CDR匹配:经典的两阶段推荐系统,匹配是排名前的第一步,从百万候选项目中检索数百个项目,更关心的是是否检索到好的项目,通常由hit rate来衡量。匹配任务中的CDR尝试借助源域改进目标域中的匹配模块
整体框架,CCDR采用三种类型的损失来进行训练,包括原始源/目标单域损失,域内CL损失和域间CL损失
- 首先为每个领域构建异构巨大的多元化偏好网络,作为用户偏好的来源。这个多样化的偏好网络包含了各种对象,比如用户、项目等和它们的交互,从不同的方面带来用户的不同的偏好。
- 通过一个GNN聚合器和基于邻居相似度的损失来训练单域匹配模型
- 由于冷启动域缺乏足够的用户行为,我们在目标域内引入了域内CL,通过基于子图的数据增强来训练更可靠的节点表示
- 为了增强跨域知识转移,我们设计了三个域间CL任务,通过两个域之间的对齐用户、分类和相似域,与多样化偏好网络很好地配合,这三种损失是在多任务学习框架下结合的
Diversified Preference Network
传统的匹配和CDR模型通常严重依赖用户-项交互来学习CTR目标和跨域映射。然而由于流行度偏差的问题,它会减少匹配的多样性。此外除了不同领域之间的用户外,它还没有充分利用其他连接(比如标签、单词、媒体)等,这在跨领域的知识转移中的信息特别丰富
我们为每个域构建了一个全局多样化偏好网络,将推荐中的六种重要对象作为节点,它们的异构交互作为边。具体来说,我们使用物品、用户、标签、类别、媒体和词作为节点。标签和类别是表示用户的细粒度和粗粒度兴趣的项目分类法。媒体表示该项目的生产者。单词反映了从项目的标题或内容中提取的项目的语义信息。为了减轻数据的稀疏性并加速我们的离线训练,我们还根据用户的基本配置文件将用户聚集到用户组中(所有具有相同性别-年龄-位置熟悉的用户都聚集在同一个用户组中)这些用户组在CCDR中被视为用户节点
至于边,我们考虑以下六个与项目相关的交互:
- 用户-项目边:如果用户组至少交互三次,则会生成此边,我们共同考虑多个用户行为来构建具有不同权重的这条边
- 项目-项目边:引入了会话中用户行为的顺序信息。如果有两个项在一个会话中出现在相邻的位置上,则会构建它
- 标签-项目边:标签项目边连接着项目和它们的标签。它捕获项目的细粒度分类法信息
- 类别-项目边:记录了项目的粗粒度分类法信息
- 媒体-项目边:将物品与它们的生产者/资料来源联系起来
- 文字/项目边:突出了项目标题中的语义信息。每条边都是无向的,但是根据边缘类型和强度进行经验加权。
与传统的U-I图相比,我们的多样化偏好网络尽量通过这些异构交互来描述来自不同方面的项目。这种多样化的偏好网络的优点是: - 带来了额外的信息,作为用户-项目交互的补充,共同提高了准确性和多样性
- 通过用户、标签、类别和词汇,在不同领域间建立更多潜在的桥梁,与CDR中的CL间任务和在线多通道匹配协同良好
Single-domain GNN Aggregator
使用GAT作为多样化偏好网络的聚合器
基于邻居相似度的优化:
在实际场景中,用户在目标域中的项目上通常有较少的历史行为。为了从行为、会话、分类、语义和数据源等方面获取额外的信息,我们在多样化的偏好网络上进行了基于邻居相似性的损失。这种损失将所有节点投射到相同的潜在空间中,使所有节点与其邻居节点相似。除了用户-项目交互外,它还将所有类型的边视为无监督的信息来指导训练。形式上基于邻居相似度的损失LN的定义如下:
\(L_N=-\sum_{e_i}\sum_{e_k\in N_{e_i}}\sum_{e_j\notin N_{e_i}}\left(-\log(\sigma(e_i^\top e_j))+\log(\sigma(e_i^\top e_k))\right)\)
然后开始介绍这个损失函数的好处:
- 在匹配中充分利用异构对象之间的所有类型的交互,包括来说用户行为、会话、项目分类、数据和语义的重要信息。它有助于捕获用户不同的偏好,以平衡匹配的准确性和多样性
- 匹配中的CDR应处理长尾项目。这个损失函数为长尾项目提供了有利于冷启动域的额外信息
- 我们采用了跨域多通道匹配策略。这种基于嵌入的减少策略还依赖于由损失函数优化的异构节点嵌入,以检索目标域的类似项
- 损失函数与在线多通道匹配完全吻合,也与多元化偏好网络和CL间损失由很好的配合。我们不能在等式中进行复杂的用户-项目交互计算,因为我们依赖于基于快速嵌入的匹配检索来提高效率
Intra-domain Contrastive Learning
在CCDR中,我们执行两种类型的CL任务。在目标域内进行域内对比学习来学习更好的节点表示,而在源域和目标域之间采用域间对比学习来指导更好的知识转移
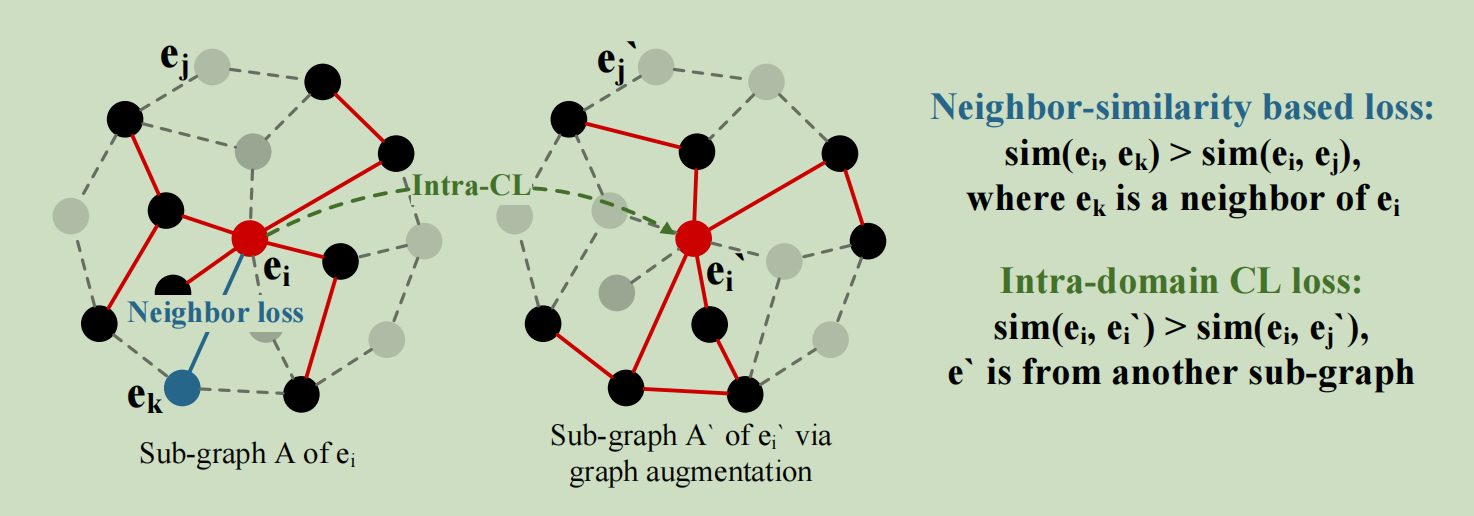
在CL内部,我们对每个节点聚合进行基于子图的数据增强,可以视为经典图增强中的动态节点/边退出。准确地说,对于一个节点\(e_i\),我们采样两个邻居集\(N_{e_i},N_{e_i}^{'}\) 来进行GNN聚合,并接受两个节点表示\(e_i,e_i^{'}\) \(e_i^{'}\)被认为是cl内\(e_i\)的阳性实例,不同的子图采样聚焦于\(e_i\)的不同邻居。类似地,我们在\(e_i\)的同一批的其他样本\(e_j^{'}\)中随机取样得到阴性样本\(e_j\) 为了提高效率,我们并没有使用B中的所有样本作为负样本。在这种情况下,流行偏差部分解决了。我们使用InfoNCE来定义域内损失
邻居相似损失和域内损失的示意图如下:
Inter-domain Contrastive Learning
三个不同域的域间对比学习的示意图如下:
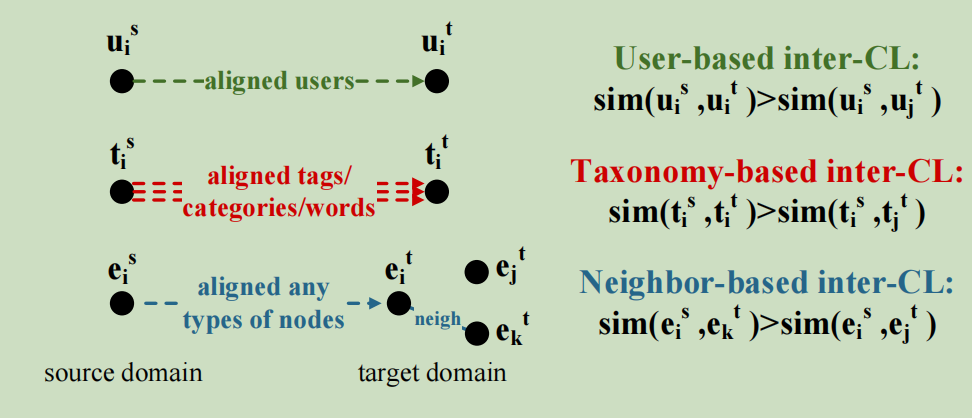
域间CL的目的是通过多样化偏好网络中不同类型的节点和边缘来改善不同领域之间的知识转移,通过对齐用户、分类和邻居来设计三个域间的CL任务
基于用户的域间CL
我们让源域与目标域之间相同的用户更相似,不同的用户更不相似
基于分类的域间CL
在不同的域中,相同的标签/类别/单词应该具有相同的含义,同样地,我们使得域中相同分类法的聚合节点之间更加相似
这个可以作为对原始的基于用户的映射的补充
基于邻居的域间CL
我们假设不同域中的相似节点应该有相似的邻居,也就是使源域中的节点和目标域中的对应节点的邻居更相似。并且可以扩展到多跳邻居,这样能够更好的实现CDR的泛化和多样性
这种基于邻居的域间CL能够极大地增加两个域之间不同的知识转移路径。
此外,不同类型的源域节点表示与目标域项表示之间的相似性可以直接用于在线多通道匹配
跨多通道匹配的可行性和优点如下:
- 多匹配通道依赖于目标域项目和异构节点之间的相似性,这与基于邻居相似性的损失和CL间的损失相一致
- 多通道匹配充分利用所有异构信息,生成多样化的候选项