https://zhuanlan.zhihu.com/p/681321783
又开新坑,继续掰扯基础软件开发。这里已经更新到第二季了,欲先睹为快的可以到这里:
基础软件开发新坑 -- 神秘的MESI和坑爹的LockFree(一)
基础软件开发新坑 -- 神秘的MESI和坑爹的LockFree(二)
正文开始:
在《HPC(高性能计算第一篇) :一文彻底搞懂并发编程与内存屏障》中,我简述了CPU的架构:
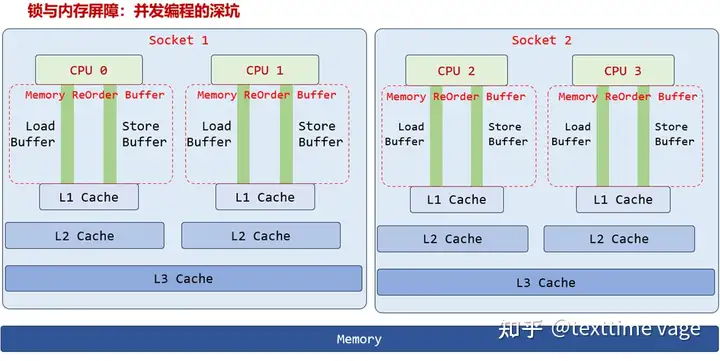 图1
图1
图1是一个双Socket(基本上可以认为就是双路),每个Socket中是一个大CPU,每个大CPU中有两个Core的架构图。
当然,真实的一个大CPU,Core数往往多于2个。这里画不下了,大家凑合着看。
图1中的CPU 0、CPU 1……,准确叫法应该是Core 0、Core 1……。
不过,习惯上称它们为CPU 0/2/3/4也可以。(后文中时常混用CPU、核,标准写法应该是Core、核)
内存屏障那篇文章中,我们简单提了一嘴,CPU之间是需要通信的,还有一个MESI协议。本文就是针对这两项的,MESI协议,和CPU间的通信。
关于MESI协议,好多资料都是再讲它的实现,是在教你如何搞出一个MESI协议,至于它对程序现实意义上的影响,鲜有涉及。
本文就抛开这些文绉绉的理论,和严谨的用词,从实践上了解下MESI协议、核间通信,对程序现实上的影响。
有好多朋友没有深入的了解过MESI,所以开头先简单的普及下基本理论。
MESI协议,其本质意义是:CPU核间通信延迟情况下的产物,目的是为了减少核间通信的次数。
多核时代,内存是共享的。有可能一个Core要读、写的任何内存数据(内存变量),同时有另一个Core也要读、写。
就好像一条公路,不是你家庭院自己的路,可能你每走一步,都会撞到别人。怎么办?
你要每时每刻都用眼去观察对方,没人和你抢道时,你向前走。有人抢了你的道时,为了不撞车,你也只能等。
CPU也是这样,理论上,每一次内存读、写,都要确认没有其他Core和你抢。怎么确认呢?和其他Core通个信,“我要修改这个内存,谁赞成,谁反对!“

但这样会不会很麻烦?
每一次内存读、写,都要互相通信,这通信次数、通信量也太大了。如何减少通信次数?
减少通信次数很简单啊,如果你已经取得了某一处内存(通常是64字节的一小块内存)的读、写权限,就可以不通信的情况下进行读写。
就好像,你把整条公路都买下来,公路就是你家庭院,你在自家庭院撒欢儿,就不需要看别人脸色了。
这是MESI协议的本质啊:
MESI协议的本质,在取得权限后、原先权限并无改变的情况下,再次进行权限对应的操作,无需核间通信。
先理解这个本质,接下来我们再来细节。
我们先说权限。
CPU对内存的访问,并不是以字节为单位,而是64字节为单位(有些CPU是128字节,国产的爱整这些小细节上的调整,以证明自己的技术实力)。
为什么不以字节为单位,因为CPU和内存间的延迟比较大吗。
就像送快递,大老远跑一趟,一次带上64件,万一除了目标这一件外,还有另一件也是要送的呢!
这个就是局部性原理,CSAPP那本书中有讲。(CSAPP:行业黑话,指《深入理解计算机系统》)
整个计算机从硬到软的体系中,到处都是这样的思想啊。数据库中你读写一行数据,数据库会将整个块(通常是8KB、16KB)读入内存,再进行读写。可以说数据库是以块(8K、16K)为单位读写的。这也是局部性原理。
CPU访问内存时的块大小,就是64字节。数据库的块大小是8K、16K……。
延迟越小时,块大小通常越小。延迟越大,块大小通常也越大。
稍具体的说一说,比如CPU要读、写char型(宽度为一字节)内存变量_x,
1.CPU先把_x所在64字节读入自己L1 Cache。每个64字节,在L1 Cache中,叫做一个Cache Line。
叫什么不重要,数据库中有叫块的,有叫页的。CPU这个块太小了,叫Line,仅此而已。不要在名字上纠结。
2.然后CPU再在刚才的L1 Cache Line中,读、写_x。
关于CPU和L1的关系,这里不展开了。咱们IT知识刺客后续文章,逐个讲解它们。
如果CUP要实现一个权限管理,自然不可能以字节为单位,每个字节都来个权限。这个64字节的Line,就是权限管理的目标。而权限管理的实现,就在L1中。
L1一共也就32KB(目前也有48KB或其他大小的,每提一个名词都要说一下特殊情况,也挺累的,而且一定有超出我了解的意外情况,后文我简化下,不这么搞了。我不是写技术清单,而是讲技术原理,各别地方没提到的很正常。我所讲的原理有问题的话,欢迎大家指正啊)。
一个Line 64字节,L1中一共也就512个Line。每个Line,多设置几个字节,做为状态标志。到底几个字节,我也不清楚。应该不会大,CPU里面可是不养闲人的,每个二进制位都要用到刀刃上。
我们先从最基本的开始,假设我在Line的状态标志中设置了读、写两个权限。并且制定如下规则:
1、CPU读、写L1 Cache Line前,先要得到对应的权限。
2、得到对应的权限时,要和其他Core通信,确认没有权限冲突时,才可以得到权限。
什么叫权限冲突?比如你要得到写权限,另一个Core已经在内存对应L1 Cache Line的状态标志上,拥有了写权限,而且还没有完成“写“操作。这就是权限冲突,这个时候,你要等。等对方发消息说:我好了,你可以继续了。
3、如果你的权限没有被改变时,进行同等、或低于此权限的操作,可以不进行通知。
第3点,是重点。前面讲了吗,MESI的本意,就是“减少核间通信的次数“,对应就是第3点。
我们稍详细解说下,先从权限改变开始。
你取得了写权限,在目标Cache Line对应的状态中,设置了“写权限“位。然后,你的写操作完成了。Cache Line状态中的写权限,会一直保留。
直到另一个Core说:“哥,我也想修改你的这个Line对应的内存“。这是另一个Core在请求写权限。
然后,你会把写权限降级为无权限。他会得到内存对应Line的写权限。
这个过程,你的权限被降级了。这就是权限改变。当然,写可以变为读、无权限。读也可以升级为写,或者无权限升级为写。等等。
明白意思就好,我们不是要设计CPU,是为了进行基础软件开发,没有必要把各个权限搞的非常细。
题外话,一直有人和我讨论基础软件开发,我常说,要有“基础软件思想“。为了有”基础软件思想“,当然要深究一些原理。要深究到哪一步呢?难到要从晶体管的PN结开始吗?
晶体管PN结还不是最基础的,是不是什么量子霍尔效应、量子隧穿(CPU有涉及量子隧穿)也要研究,都到这一步了,相对论铁定是绕不开了,这样一来,我一搞软件开发的,整成理论物理学家了。
关于原理层研究的“度“问题,你只能自己把握了。不排除你研究了好久,后来发现,自己的研究过了头。这也没关系,人生在世,谁能不走点弯路啊。不要纠结这个”度“的问题,关键是要尽早的开始你的研究,学过的东西,总会有用得着的时候。
说回第3点,如果你得到了写权限,别人也请求同一内存位置的写权限,你的写权限就改变了。
如果你得到了写权限后,其他Core没有请求同一内存位置的写权限,你的写权限就一直保留,一直是写权限。这个时候,你又对Cache Line发起一次写操作,或权限等级低于写的读操作,你不需要再和其他CPU通个信,可以直接向L1的Line写。这不就是减少了通信的次数吗。这就是MESI的本质意义。
就好像,你知道这是你自家的庭院,你可以随便走,不用担心撞到别人。
什么情况下我不用看人、随便走,什么情况下我要和别人通个信儿、打个着呼再走,把所有情况整理为一套规则,就是MESI。
具体而言,它把权限规定为4种:
M:Modify,修改权限。
E:Exclusive,独占权限。
S:Shared,共享权限。
I:Invalidate,无效权限。
其实这里的“权限”,换成状态,会更合适。修改、独占、共享、无效,四大状态。
四个单词首字母合起来,即MESI,也就是协议名称的由来。
对内存的操作,有Load、Store两种,也就是读、写了。
Store前,要把Line的权限状态先设置为E,独占。Store时,再转为M,修改权限。(这里有可能是是先M,再E,不影响我所描述的MESI思想,一些细节我记不太清了)
Load,当然对应S权限。但如果只有一个CPU Load,也会对应E独占权限。当其他CPU 也Load 同一内存处数据时,再由E降为S。
如果当前Core L1中某Line状态是M、E,这是高于S权限, Core可以直接Load。
如果你Store了,得到了M、E权限。别的Core Load了,你的M、E权限降级为S权限。你不再独占这块64字节的内存了,别的Core也读了这一块内存。
如果你Store了,得到了M、E权限。别的Core也Store,你的M、E权限降为I,无效权限。
如果你Load了,得到了E或S权限。别的Core Store,你的权限降为I。
也就是Store会将其他Core的无论什么权限,都降级为I。
I,无效权限,代表L1 Cache Line无效了,虽然它还在L1中,但CPU不能读它里面的数据了。因为它已经无效了吗。要读只能重新发起内存读、或从L2、L3读。
好,科普结束。
虽然说是科普,但学是说到了一些本质的,比如MESI的本质是“减少核间通信的次数”。为什么要减少核间通信的次数?因为核间通信延迟很高。
核间通信延迟,还有核间数据同步延迟有多高?
下面亲手来测量下吧。
“自己动手测量”可以把各种基础知识调动起来,把点连成线、把线连成面。然后,在某一天,你就会突然悟道,产生“基础软件思想”。
当然,这是我的方法,可能不一定适用于其他人。我写出来,仅供大家参考一下。
先考虑一个问题,如果CPU_a写一个内存,CPU_b多久能看到新值?(这是核间同步,它包括核间通信)
首先,我们得有一块共享内存。进程1、进程2各自在两个CPU上执行,进程1修改了一块内存,进程2读取同一内存,这不就会触发CPU的内部通信与同步吗!
所以我们要分配共享内存。
另外,还要控制进程在哪个CPU之上,因此我们还需要绑核,
分配内存,我用如下程序:
void * smem()
{
void *ptr;
ptr = mmap(0, (arr_size_X * arr_size_Y + 4 ) * sizeof(TYPE), PROT_READ | PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS|0x40000, -1, 0); // 大页
if (ptr == MAP_FAILED)
printf("Failed to allocate shared memory\n");
return ptr;
}MAP_SHARED标志声明这是一块共享内存。
0x40000标志是大页。
我的绑核函数:
void setcpu(int cpu)
{
int i, nrcpus, cur_cpu;
cpu_set_t mask;
unsigned long bitmask = 0;
CPU_ZERO(&mask);
CPU_SET(cpu, &mask);
if (sched_setaffinity(0, sizeof(cpu_set_t), &mask) == -1)
{
perror("sched_setaffinity fail!");
exit(EXIT_FAILURE);
}
} 你看,试验还没开始呢,又是绑核、又是分配大页内存,是不是各种知识开始串起来了。
如果程序将来执行时,大页内存分配失败,可能是没有配置大页,可以如下配置:
cat /proc/sys/vm/nr_hugepages
echo 10 > /proc/sys/vm/nr_hugepages我分配了10个大页,足够我们这个测量程序用了。
大页、绑核这些还能简单,关键是时间的测量。我们的测量目标是只有几十、几百周期的指令,如此精度的计时器,就只有TSC了。在《高性能计算(HPC)系列之二:深入基础软件开发》系列中,有使用过rdtscp,就是TSC。
TSC是核内一小块独立集成电路构成的计时器,它是独立的。它以基础频率为单位,它跟随频率高、低电平的变化而变化,每次高、低电平的转换,TSC加1。
也就是说,TSC就是以CPU基础频率为单位的时钟周期。
除了基础频率,CPU还有最小、最大频率。lscpu就能看到最小、最大频率:
[root@localhost ~]# lscpu
Architecture: x86_64
……
Model name: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
Stepping: 3
CPU MHz: 3200.000
CPU max MHz: 3200.0000
CPU min MHz: 800.0000
……最小频率是800,最大频率是3200。
由于睿频的存在,CPU的其他部件,在最小频率和最大频率间摆动。而我们的TSC是基础频率,这不同步啊。
不同步,一定会影响我们测量结果的精度。有时可能会得到远超预想值的测量结果。怎么办?
这好办,修改/sys/devices/system/cpu/intel_pstate/min_perf_pct,改为100:
echo 100 > /sys/devices/system/cpu/intel_pstate/min_perf_pct这个意思就是让CPU一直跑在3.2GHz的最大频率下。
你可以用《高性能计算(HPC)系列之二:深入基础软件开发》中的频率测量方法,验证一下修改结果。
只要CPU的其他部件频率不再摆动,我们就可以用TSC进行测量了。
这里还有一个问题,多核间TSC的同步问题。
TSC是核内一块独立的模块不假,但每个核都有TSC,核间的TSC会不会不同步?
是有这个可能的。不过,Linux内核会定期同步所有核的TSC。所以,这个顾虑不用担心。而且如果你的CPU TSC就是不同步,像Intel,还提供了一个校准用的MSR寄存器。这一块我们后面单开一章来讲,其实用这个TSC还是能做很多事情的,比如生成分式数据库的ID什么的。
共享内存有了,绑核也搞定了,测量单位就是TSC:基准时钟周期。万事具备,开始设计程序吧。
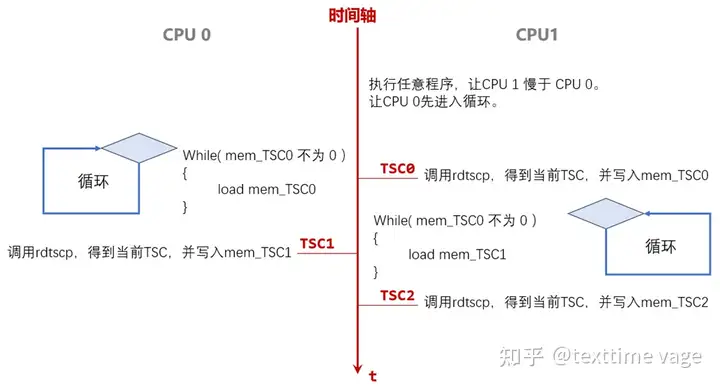
我的程序思路如上图,两个进程,绑在两个核上,假设如图的CPU 0和CPU 1吧。
CPU 0的程序,一上来就是一个循环。直到读到mem_TSC0不为0,才退出循环。
mem_TSC0,从变量名上能看出来,它是一个内存变量(不能被编译器转为寄存器),它的内存就来自于共享内存。
它什么时候会不为0呢。要看CPU 1上的程序。
CPU 1上的程序一上来要先执行一个没什么意义的循环。目的,就是让CPU 0这边,先进入循环。
其实就是让CPU 1暂停一下,让CPU 0先走到循环里。
暂停,用sleep()可以吗?
不行。
因为sleep()会导致后续少量指令频率下降。如果两个CPU工作频率不一样,测量数据会不准确。
这里的暂停程序如下:
if (cur_cpu == fg[2])
for (i=0; i<=fg[3]; i++)
k+=i;对指定CPU循环执行k+i。
在CPU 0进入循环之后。
CPU 1使用rdtscp指令,得到当前TSC计数值。然后,写入共享内存变量mem_TSC0。
在写入之后,CPU 0还会在很长一段时间内,不断循环load mem_TSC0,并比较它的值是否不为0。
若干周期后,CPU 0读到的mem_TSC0终于不为0了,CPU 0上的循环退出。
CPU 0循环退出后马上再次调用rdtscp,得到TSC计数,写入mem_TSC1。
那么,mem_TSC1 – mem_TSC0,就是CPU 1写 共享内存mem_TSC0后,CPU 0多久时间才看到新值。
后面CPU 1的循环也一样,mem_TSC2 – mem_TSC1,是CPU 0写入新值,CPU 1多久后才能看到新值。
对应的代码如下:
// 将 TSC0, TSC1, TSC2 加载到两个Core的L1,最终Line状态为S
__asm__ __volatile__
(
"lea %0, %%r8\n\t"
"mov (%%r8), %%rax\n\t" // TSC0
"mov 128(%%r8), %%rax\n\t" // TSC1
"mov 256(%%r8), %%rax\n\t" // TSC2
:
:"m"( *mem )
:"rax","r8"
);
// 暂停:第二个CPU上的进程暂停一下
if (cur_cpu == fg[2])
for (i=0; i<=fg[3]; i++)
k+=i;
// 开始测量
if ( cur_cpu == fg[1] )
{ // 第一个CPU中运行的测量程序
__asm__ __volatile__
(
"lea %0, %%r8\n\t" // &mem
"SYNC_TSC0:\n\t"
"mov (%%r8), %%r9\n\t" // while load
"cmp $0, %%r9\n\t"
"je SYNC_ TSC0\n\t"
"rdtscp \n\t" // TSC 2
"movq %%rax, 128(%%r8)\n\t"
"movq %%rdx, 136(%%r8)\n\t"
:
:"m"( *mem )
:"rax","rdx","r8","r9"
);
}
else
{ // 第二个CPU中运行的测量程序
__asm__ __volatile__
(
"lea %0, %%r8\n\t" // &mem
"rdtscp \n\t" // TSC 0
"mov %%rax, (%%r8)\n\t"
"mov %%rdx, 8(%%r8)\n\t"
"SYNC_TSC1:\n\t"
"mov 128(%%r8), %%r9\n\t" // while load
"cmp $0, %%r9\n\t"
"je SYNC_TSC1\n\t"
"rdtscp \n\t" // TSC 3
"movq %%rax, 256(%%r8)\n\t"
"movq %%rdx, 264(%%r8)\n\t"
:
:"m"( *mem )
:"rax","rdx","r8","r9"
);
}(完整程序我放在后面。这里只列出最重要的部分)
程序的运行结果:
[root@localhost ff]# gcc -g mesi2.c -o mesi2
[root@localhost ff]#
[root@localhost ff]# ./mesi2 0 1 3 10000000
1-----------SUB Process at CPU: 1----------
PID is 23906
TSC 0:416665567 0
TSC 1:416665785 218
TSC 2:416665998 213
2-----------SUB Process at CPU: 3----------
PID is 23907
TSC 0:416665567 0
TSC 1:416665785 218
TSC 2:416665998 213先说参数,./mesi2 0 1 3 10000000,0是在0号CPU上做初始化,分配共享内存、清0等等操作。1 3,两个进程分别在1号、3号两个CPU上运行。最后的10000000,是CPU 3上的程序,先执行10000000次循环,暂停一段时间。让CPU 1先进入循环。
好,看结果,TSC 1后面的218,就是CPU 3写mem_TSC0后,CPU 1在218个周期后才看到新值。
我们前面不是提过吗,CPU完成一个整数加、减法、位移、cmp等等,不涉及浮点数和乘、除,大部分指令都是一个周期。
一次L1 Cache访问,4、5个周期。
CPU 间的同步,218周期。
如果一次L1 Cache做为1天的话,那么:
加、减法 6个小时
L1 Cache访问 1天
CPU 间同步 1个半月
好了,先到这里吧。大家先消化消化,马上,《基础软件开发 -- 神秘的MESI和坑爹的LockFree》第二季就要发布了
标签:Core,--,TSC,LockFree,转帖,内存,Line,权限,CPU From: https://www.cnblogs.com/jinanxiaolaohu/p/18010978