一. 区间最值操作
本文对吉如一老师在 \(2016\) 年国家集训队论文中的线段树处理历史区间最值的问题的一些杂谈。
区间最值笼统地指求区间的最值以及区间所有数对 \(x\) 取最值(即令 \(a_i=\max/\min (a_i,x)\))这一类的查询与修改操作。
支持对区间取min,维护区间最大值,查询区间和。
如果没有第一个操作即为普通线段树。
我们考虑对于线段树上的每个节点维护权值和 \(sum\),区间最大值 \(mx\),严格次大值 \(se\),最大值出现个数 \(cnt\)。
假设当前我们在区间 \([l,r]\) 对 \(x\) 取 \(\min\),那么对于线段树上的每个节点我们有一下三种分类来确定是否往下递归:
-
\(mx\le x\)。显然当前操作对区间不会产生影响,那么退出递归。
-
\(se<x<mx\)。此时操作只会影响到区间中的所有最大值,那么我们对 \(sum\) 加上 \(cnt\times (x-mx)\) 并将 \(mx\) 更新为 \(x\),打上标记后直接退出。
-
\(x\le se\)。此时无法直接更新节点信息,故向下左右子树递归。
这个看似暴力的算法可以证明复杂度是 \(O(m\log n)\) 的。具体参见吉老师在论文中势能分析复杂度部分。
模糊地理解,如果将线段树上每个节点打上标记表示所代表的区间的最值,若一个节点的标记等于其父亲节点,那么删除该节点的标记。不难发现全树最终只有至多 \(n\) 个标记,并且每一个位置实际的值为从叶子节点出发往上遇到的一个标记。
那么我们维护的次大值可以转化为子树中(显然不包括自己本身)的标记最大值。我们重新回顾区间取 \(\min\) 对于标记的影响:由于标记显然随着深度增加而递减,那么暴力 dfs 的过程即在子树中回收大于它的所有标记。
所以复杂度可以转化为标记回收的复杂度。
实现上,我们将一个区间 \([l,r]\) 与 \(x\) 取 \(\min\),这会将一些节点的权值更新为 \(x\),我们把这次操作所产生的标记称为同一类。那么标记回收时少会有一类标记(即大于 \(x\) 的标记)被清除。
每次操作都会新增一类标记,每类标记的个数最多只有 \(\log n\) 个。所以均摊下来总时间复杂度为 \(O(m\log n)\)。对于更加严谨的证明还是去看论文。
回归代码实现是容易的。
#include<bits/stdc++.h>
using namespace std;
#define ls p<<1
#define rs p<<1|1
#define ll long long
const int N=1e6+7;
int T,n,m,a[N],mx[N<<2],se[N<<2],cnt[N<<2],tag[N<<2];
ll sum[N<<2];
inline void pushup(int p){
sum[p]=sum[ls]+sum[rs];
if(mx[ls]==mx[rs]){
mx[p]=mx[ls],se[p]=max(se[ls],se[rs]);
cnt[p]=cnt[ls]+cnt[rs];
}
else if(mx[ls]>mx[rs]){
mx[p]=mx[ls],se[p]=max(se[ls],mx[rs]);
cnt[p]=cnt[ls];
}
else{
mx[p]=mx[rs],se[p]=max(se[rs],mx[ls]);
cnt[p]=cnt[rs];
}
return;
}
inline void build(int p,int l,int r){
tag[p]=-1;
if(l==r){
sum[p]=mx[p]=a[l];
cnt[p]=1,se[p]=-1;
return;
}
int mid=(l+r)>>1;
build(ls,l,mid),build(rs,mid+1,r);
pushup(p);
return;
}
inline void pushtag(int p,int tg){
if(mx[p]<=tg)return;
sum[p]+=(ll)(tg-mx[p])*cnt[p];
mx[p]=tag[p]=tg;
return;
}
inline void pushdown(int p){
if(tag[p]==-1)return;
pushtag(ls,tag[p]),pushtag(rs,tag[p]);
tag[p]=-1;
return;
}
inline void update(int p,int l,int r,int s,int t,int val){
if(mx[p]<=val)return;
if(s<=l&&r<=t&&se[p]<val){
pushtag(p,val);
return;
}
int mid=(l+r)>>1;
pushdown(p);
if(s<=mid)update(ls,l,mid,s,t,val);
if(t>mid)update(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline int querymax(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return mx[p];
int mid=(l+r)>>1,res=-1;
pushdown(p);
if(s<=mid)res=max(res,querymax(ls,l,mid,s,t));
if(t>mid)res=max(res,querymax(rs,mid+1,r,s,t));
return res;
}
inline ll querysum(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return sum[p];
int mid=(l+r)>>1;ll res=0;
pushdown(p);
if(s<=mid)res+=querysum(ls,l,mid,s,t);
if(t>mid)res+=querysum(rs,mid+1,r,s,t);
return res;
}
inline void solve(){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
build(1,1,n);
for(int i=1;i<=m;i++){
int op,l,r,val;
scanf("%d%d%d",&op,&l,&r);
if(!op){
scanf("%d",&val);
update(1,1,n,l,r,val);
}
else if(op==1)printf("%d\n",querymax(1,1,n,l,r));
else printf("%lld\n",querysum(1,1,n,l,r));
}
return;
}
int main(){
scanf("%d",&T);
while(T--)solve();
return 0;
}
支持区间加,区间取 \(\min/\max\),求区间和,区间 \(\min/\max\)。
由于增加了区间加的操作,我们在上一题维护了最大值、次大值、最大值个数、区间和等标记的同时,要新增 lazytag 的引入。对于区间和与区间最值的标记下传问题我们不能直接地套用上一题时间复杂度证明的过程,但是形式是十分类似的,参加吉老师的论文,理论复杂度为 \(O(m\log^2n)\),但实际运行接近于 \(O(m\log n)\)。
对于标记下传的部分,我们最优先处理区间加的标记,两个区间最值的标记优先度相等。处理时注意对于只有一两个数的区间可能发生数集在不同的标记中重合,比如一个数既是最大值又是次小值。
#include<bits/stdc++.h>
using namespace std;
#define ls p<<1
#define rs p<<1|1
#define ll long long
#define int ll
const int N=5e5+6;
const int inf=2e9;
int n,Q,a[N];
struct node{
int mx,mx2,mn,mn2,cmx,cmn,tmx,tmn,tad;
//mx secmx mn secmn cntmx cntmn tagmx tagmn tagadd
ll sum;
}tr[N<<2];
inline void pushup(int p){
tr[p].sum=tr[ls].sum+tr[rs].sum;
if(tr[ls].mx==tr[rs].mx){
tr[p].mx=tr[ls].mx,tr[p].mx2=max(tr[ls].mx2,tr[rs].mx2);
tr[p].cmx=tr[ls].cmx+tr[rs].cmx;
}
else if(tr[ls].mx>tr[rs].mx){
tr[p].mx=tr[ls].mx,tr[p].mx2=max(tr[ls].mx2,tr[rs].mx);
tr[p].cmx=tr[ls].cmx;
}
else{
tr[p].mx=tr[rs].mx,tr[p].mx2=max(tr[ls].mx,tr[rs].mx2);
tr[p].cmx=tr[rs].cmx;
}
if(tr[ls].mn==tr[rs].mn){
tr[p].mn=tr[ls].mn,tr[p].mn2=min(tr[ls].mn2,tr[rs].mn2);
tr[p].cmn=tr[ls].cmn+tr[rs].cmn;
}
else if(tr[ls].mn<tr[rs].mn){
tr[p].mn=tr[ls].mn,tr[p].mn2=min(tr[ls].mn2,tr[rs].mn);
tr[p].cmn=tr[ls].cmn;
}
else{
tr[p].mn=tr[rs].mn,tr[p].mn2=min(tr[ls].mn,tr[rs].mn2);
tr[p].cmn=tr[rs].cmn;
}
return;
}
inline void pushadd(int p,int l,int r,int val){
tr[p].sum+=(ll)(r-l+1)*val;
tr[p].mx+=val,tr[p].mn+=val;
if(tr[p].mx2!=-inf)tr[p].mx2+=val;
if(tr[p].mn2!=inf)tr[p].mn2+=val;
if(tr[p].tmx!=-inf)tr[p].tmx+=val;
if(tr[p].tmn!=inf)tr[p].tmn+=val;
tr[p].tad+=val;
return;
}
inline void pushmax(int p,int val){
if(tr[p].mn>val)return;
tr[p].sum+=(ll)(val-tr[p].mn)*tr[p].cmn;
if(tr[p].mx2==tr[p].mn)tr[p].mx2=val;
if(tr[p].mx==tr[p].mn)tr[p].mx=val;
if(tr[p].tmn<val)tr[p].tmn=val;
tr[p].mn=val,tr[p].tmx=val;
return;
}
inline void pushmin(int p,int val){
if(tr[p].mx<=val)return;
tr[p].sum+=(ll)(val-tr[p].mx)*tr[p].cmx;
if(tr[p].mn2==tr[p].mx)tr[p].mn2=val;
if(tr[p].mn==tr[p].mx)tr[p].mn=val;
if(tr[p].tmx>val)tr[p].tmx=val;
tr[p].mx=val,tr[p].tmn=val;
return;
}
inline void pushdown(int p,int l,int r){
if(tr[p].tad){
int mid=(l+r)>>1;
pushadd(ls,l,mid,tr[p].tad);
pushadd(rs,mid+1,r,tr[p].tad);
tr[p].tad=0;
}
if(tr[p].tmx!=-inf){
pushmax(ls,tr[p].tmx);
pushmax(rs,tr[p].tmx);
tr[p].tmx=-inf;
}
if(tr[p].tmx!=inf){
pushmin(ls,tr[p].tmn);
pushmin(rs,tr[p].tmn);
tr[p].tmn=inf;
}
return;
}
inline void build(int p,int l,int r){
tr[p].tmn=inf,tr[p].tmx=-inf;
if(l==r){
tr[p].sum=tr[p].mx=tr[p].mn=a[l];
tr[p].mx2=-inf,tr[p].mn2=inf;
tr[p].cmx=tr[p].cmn=1;
return;
}
int mid=(l+r)>>1;
build(ls,l,mid),build(rs,mid+1,r);
pushup(p);
return;
}
inline void updadd(int p,int l,int r,int s,int t,int val){
if(s<=l&&r<=t){
pushadd(p,l,r,val);
return;
}
int mid=(l+r)>>1;
pushdown(p,l,r);
if(s<=mid)updadd(ls,l,mid,s,t,val);
if(t>mid)updadd(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline void updmax(int p,int l,int r,int s,int t,int val){
if(tr[p].mn>=val)return;
if(s<=l&&r<=t&&tr[p].mn2>val){
pushmax(p,val);
return;
}
int mid=(l+r)>>1;
pushdown(p,l,r);
if(s<=mid)updmax(ls,l,mid,s,t,val);
if(t>mid)updmax(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline void updmin(int p,int l,int r,int s,int t,int val){
if(tr[p].mx<=val)return;
if(s<=l&&r<=t&&tr[p].mx2<val){
pushmin(p,val);
return;
}
int mid=(l+r)>>1;
pushdown(p,l,r);
if(s<=mid)updmin(ls,l,mid,s,t,val);
if(t>mid)updmin(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline ll querysum(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return tr[p].sum;
int mid=(l+r)>>1;ll res=0;
pushdown(p,l,r);
if(s<=mid)res+=querysum(ls,l,mid,s,t);
if(t>mid)res+=querysum(rs,mid+1,r,s,t);
return res;
}
inline ll querymax(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return tr[p].mx;
int mid=(l+r)>>1;ll res=-inf;
pushdown(p,l,r);
if(s<=mid)res=max(res,querymax(ls,l,mid,s,t));
if(t>mid)res=max(res,querymax(rs,mid+1,r,s,t));
return res;
}
inline ll querymin(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return tr[p].mn;
int mid=(l+r)>>1;ll res=inf;
pushdown(p,l,r);
if(s<=mid)res=min(res,querymin(ls,l,mid,s,t));
if(t>mid)res=min(res,querymin(rs,mid+1,r,s,t));
return res;
}
signed main(){
scanf("%lld",&n);
for(int i=1;i<=n;i++)scanf("%lld",&a[i]);
build(1,1,n);
scanf("%lld",&Q);
while(Q--){
int op,l,r,val;
scanf("%lld%lld%lld",&op,&l,&r);
if(op==1){
scanf("%lld",&val);
updadd(1,1,n,l,r,val);
}
else if(op==2){
scanf("%lld",&val);
updmax(1,1,n,l,r,val);
}
else if(op==3){
scanf("%lld",&val);
updmin(1,1,n,l,r,val);
}
else if(op==4)printf("%lld\n",querysum(1,1,n,l,r));
else if(op==5)printf("%lld\n",querymax(1,1,n,l,r));
else printf("%lld\n",querymin(1,1,n,l,r));
}
return 0;
}
-
Mzl loves segment tree
有两个序列 \(A,B\)。对 \(A\) 支持区间加,区间取最值,询问对于 \(B\) 的区间求和。对于每次操作后若 \(A_i\) 发生变化则 \(B_i\) 加一。
如果没有区间取最值那么每次区间加减的修改都会对 \(A\) 发生变化,那么就转化为对于 \(B\) 的区间加了。现在新增了区间最值,我们回顾上一题中对于区间最值标记下传时的影响:比如我们是取 \(\min\),当前线段树节点上的区间只有最大值发生变化。修改后区间内的相对大小依旧不变。
这启发我们将区间最值操作转化为一种针对区间的最值进行加减修改的操作。
将线段树节点上的区间中的数划分为三个集合:最大值、最小值、其他(非最值)。那么,我们对于这三个集合分别维护,对于区间取最值时相当于在最值集合上进行加减操作,区间加减时则相当于在非最值集合上进行加减操作。至此,本题得解。
-
ChiTuShaoNian loves segment tree
两个序列 \(A,B\),对 \(A,B\) 分别区间加、区间取 \(\min\)。查询 \(\max\{ A_i+B_i\}\)。
与上一题相同:将区间划分为 \(4\) 个集合:同时在 \(A,B\) 中都为最大值的、仅在 \(A\) 中为最大值的、仅在 \(B\) 中为最大值的、在 \(A,B\) 中都不是最大值的。然后由于区间修改操作互相独立,所以标记之间不会存在影响。那么这个题便可以拓展到 \(k\) 个序列的情况,此时将区间分为了 \(2^k\) 类,时间复杂度 \(O(2^km\log n)\)。
-
Dzy loves segment tree
支持区间取 \(\min\),区间加,查询区间 \(\gcd\)。
如果只有区间加的修改,相信大家都经典地会使用差分转而使用线段树维护。
增加了区间取 \(\min\) 的操作,我们猜想是否能够使用之前题目中的将区间取最值转化为区间加减的思想?容易发现直接将原序列差分后操作是不行的,因为询问与下标顺序是有关的。
那么我们考虑对于区间非最大值进行差分,而对于区间最大值单独拿出来维护。具体地从实现上来说,对于每个线段树节点额外维护 \(s,t\) 表示非最大值序列的开头结尾与 \(g\) 表示区间 \(\gcd\)。合并两个儿子的答案时,对于最大值与次大值的维护是 trival 的,这里不做赘述。假设 \(mx_l>mx_r\),那么非最大值序列的 \(s,t\) 更新为 \(s_l,mx_r\),即得 \(g=\gcd(g_l,g_r,t_l-s_r,t_r-mx_r)\)。至此本题解决,复杂度为 \(O(m\log^3n)\)(算上了 \(\gcd\) 的复杂度)。
这题也启发了我们对于将区间取最值转化为区间加减这个思想的局限性:因为将区间划分时没有考虑下标顺序,所以对于涉及到下标顺序的题目时会难以处理;诸如求子区间权值和最大值便显得笨拙。
二. 历史最值问题
历史区间最值分为三类:历史区间最大值、历史区间最小值、历史区间版本和。更具体地,历史最值问题可按照难度分为四类:我们将在下述的题目中进行介绍。
1. 可以使用懒标记处理的问题
支持区间加,区间覆盖,查询区间最大值与区间历史最大值。
此题有一个很强的性质:对于被赋值操作后区间,之后的所有区间加可以视为区间赋值。
定义一个新的懒标记:\(tagmx_p\) 表示从上一次将这个节点 \(p\) 的懒标记下传的时刻知道当前时刻的这段时间中,这个节点 \(p\) 的 \(tag\) 标记所达到过的最大值。
而对于 \(tagmx\) 向儿子的传递是容易的。我们以 \(tag\) 维护的是区间加和为例子:\(tagmx_{son_p}=\max(tagmx_{son_p},tagmx_p+tag_{son_p})\)
。对于维护区间最值同理。至此,我们通过传统的 lazytag 懒标记解决此题。
#include<bits/stdc++.h>
using namespace std;
#define ls p<<1
#define rs p<<1|1
const int N=1e5+6;
const int inf=1e9;
int n,Q,a[N],vis[N<<2],mx[N<<2],hmx[N<<2],sum[N<<2],summx[N<<2],asg[N<<2],asgmx[N<<2];
//mx:区间最大值 hmx:区间历史最大值 vis:是否进行过赋值操作
//sum:当前节点上次pushdown之后的加和 asg: 当前节点上次pushdown之后的赋值操作 (赋值之后的区间加操作算入赋值)
//summx:上次pushdown之后达到的最大加和 asgmx:上次pushdown之后赋的最大值
inline void pushup(int p){
mx[p]=max(mx[ls],mx[rs]);
hmx[p]=max(hmx[ls],hmx[rs]);
return;
}
inline void pushsum(int p,int val,int mxval){
if(vis[p]){
asgmx[p]=max(asgmx[p],asg[p]+mxval);
hmx[p]=max(hmx[p],mx[p]+mxval);
mx[p]+=val,asg[p]+=val;
}
else{
summx[p]=max(summx[p],sum[p]+mxval);
hmx[p]=max(hmx[p],mx[p]+mxval);
mx[p]+=val,sum[p]+=val;
}
return;
}
inline void pushasg(int p,int val,int mxval){
if(vis[p]){
hmx[p]=max(hmx[p],mxval);
asgmx[p]=max(asgmx[p],mxval);
}
else{
vis[p]=1;
asgmx[p]=mxval;
hmx[p]=max(hmx[p],mxval);
}
mx[p]=asg[p]=val;
return;
}
inline void pushdown(int p){
pushsum(ls,sum[p],summx[p]),pushsum(rs,sum[p],summx[p]);
sum[p]=summx[p]=0;
if(!vis[p])return;
pushasg(ls,asg[p],asgmx[p]),pushasg(rs,asg[p],asgmx[p]);
vis[p]=asg[p]=asgmx[p]=0;
return;
}
inline void build(int p,int l,int r){
if(l==r){
mx[p]=hmx[p]=a[l];
return;
}
int mid=(l+r)>>1;
build(ls,l,mid),build(rs,mid+1,r);
pushup(p);
return;
}
inline void update(int p,int l,int r,int s,int t,int val){
if(s<=l&&r<=t){
pushsum(p,val,val);
return;
}
int mid=(l+r)>>1;
pushdown(p);
if(s<=mid)update(ls,l,mid,s,t,val);
if(t>mid)update(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline void assign(int p,int l,int r,int s,int t,int val){
if(s<=l&&r<=t){
pushasg(p,val,val);
return;
}
int mid=(l+r)>>1;
pushdown(p);
if(s<=mid)assign(ls,l,mid,s,t,val);
if(t>mid)assign(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline int querymax(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return mx[p];
int mid=(l+r)>>1,res=-inf;
pushdown(p);
if(s<=mid)res=max(res,querymax(ls,l,mid,s,t));
if(t>mid)res=max(res,querymax(rs,mid+1,r,s,t));
return res;
}
inline int queryhis(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return hmx[p];
int mid=(l+r)>>1,res=-inf;
pushdown(p);
if(s<=mid)res=max(res,queryhis(ls,l,mid,s,t));
if(t>mid)res=max(res,queryhis(rs,mid+1,r,s,t));
return res;
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
build(1,1,n);
scanf("%d",&Q);
while(Q--){
char op;int l,r,val;
cin>>op;scanf("%d%d",&l,&r);
if(op=='Q')printf("%d\n",querymax(1,1,n,l,r));
else if(op=='A')printf("%d\n",queryhis(1,1,n,l,r));
else if(op=='P'){
scanf("%d",&val);
update(1,1,n,l,r,val);
}
else{
scanf("%d",&val);
assign(1,1,n,l,r,val);
}
}
return 0;
}
给出一个数列 \(A\) 与辅助数列 \(B\),\(B\) 初始与 \(A\) 完全相同。每次操作有以下几种类型:
- \(\forall i\in[l,r],a_i\leftarrow \max(a_i-x,0)\)
- 区间加
?3. 区间赋值- 单点查询 \(A_i\) 或 \(B_i\)
每次操作后 \(B_i\leftarrow\max(A_i,B_i)\)。
首先第一个操作等价于区间加后对 \(0\) 取 \(\max\)。
我们定义一种标记 \(f(x,y)\) 表示给区间中所有数先加上 \(x\) 后对 \(y\) 取 \(\max\)。那么我们可以表示出前三种操作:\(f(-x,0),f(x,-\inf),f(-\inf,x)\)。
显然 \(f\) 是满足结合律的。\(f(a,b)\) 与 \(f(c,d)\) 合并后得到 \(f(a+c,\max(b+c,d))\)。那么对于查询 \(A_i\) 的情况只需要将从根到叶子的所有标记下传。
对于历史最大值的询问,在吉如一的论文中,将标记 \(f\) 看作函数,并将两个函数的图像以及它们合并后的函数图像画出来,即如下图所示,得出更新标记后形式同原来相同的结论进而发现历史最值标记亦可以如查询 \(A_i\) 一样下传。
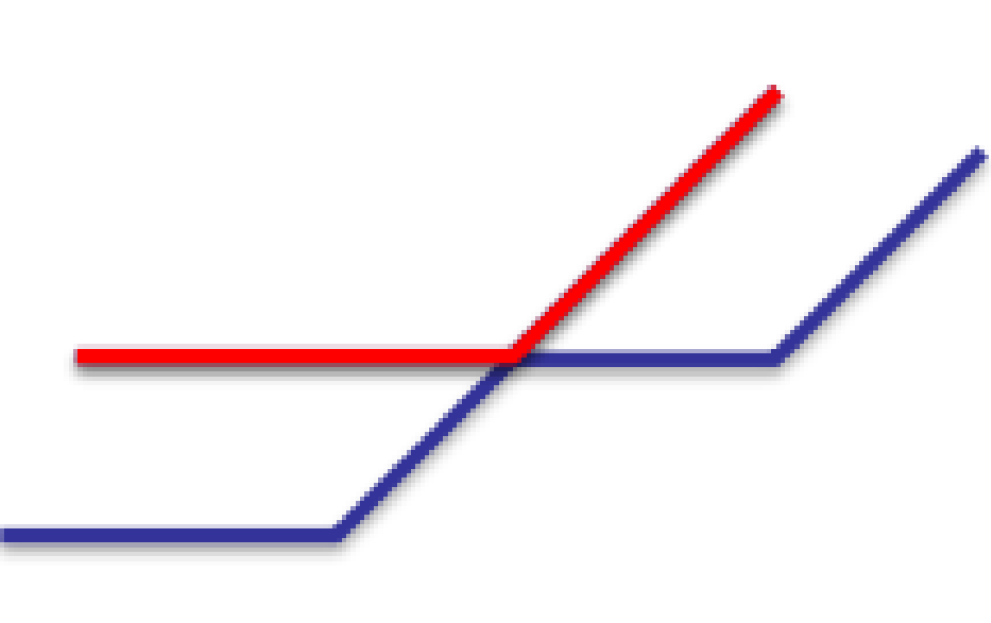
事实上,考虑从另一角度出发:我们发现 \(f\) 是封闭的。将 \(f(x)=\max(x+a,b)\) 表示,有:
\[\begin{aligned}f_1(f_2(x)) & = \max(\max(x+f_2(a),f_2(b))+f_1(a),f_1(b))\\ & = \max\{x+f_2(a)+f_1(a),f_2(b)+f_1(a),f_1(b)\}\end{aligned} \]这里将 \(f_2\) 视为儿子节点,\(f_1\) 视为父亲节点。因为合并有相对先后顺序。历史最大值同理:\(f_1(f_2(x))=\max(x+\max(f_1(a)+f_2(a)),\max(f_1(b),f_2(b)))\)。
#include<bits/stdc++.h>
using namespace std;
#define ls p<<1
#define rs p<<1|1
#define int long long
const int N=5e5+6;
const int inf=1e18;
int n,Q,a[N];
struct tag{
int x,y,X,Y;
tag(int x=0,int y=0,int X=0,int Y=0):x(x),y(y),X(X),Y(Y){}
}tr[N<<2];
inline tag merge(tag a,tag b){
return tag(max(a.x+b.x,-inf),max(a.y+b.x,b.y),max(a.X,a.x+b.X),max(a.Y,max(a.y+b.X,b.Y)));
}
inline void pushdown(int p){
tr[ls]=merge(tr[ls],tr[p]),tr[rs]=merge(tr[rs],tr[p]);
tr[p]=tag(0,0,0,0);
return;
}
inline void build(int p,int l,int r){
tr[p]=tag(0,0,0,0);
if(l==r)return;
int mid=(l+r)>>1;
build(ls,l,mid),build(rs,mid+1,r);
return;
}
inline void update(int p,int l,int r,int s,int t,tag val){
if(s<=l&&r<=t){
tr[p]=merge(tr[p],val);
return;
}
int mid=(l+r)>>1;
pushdown(p);
if(s<=mid)update(ls,l,mid,s,t,val);
if(t>mid)update(rs,mid+1,r,s,t,val);
return;
}
inline tag query(int p,int l,int r,int ps){
if(l==r)return tr[p];
int mid=(l+r)>>1;
pushdown(p);
if(ps<=mid)return query(ls,l,mid,ps);
else return query(rs,mid+1,r,ps);
}
signed main(){
scanf("%lld%lld",&n,&Q);
for(int i=1;i<=n;i++)scanf("%lld",&a[i]);
build(1,1,n);
while(Q--){
int op,l,r,x;
scanf("%lld",&op);
if(op==1){
scanf("%lld%lld%lld",&l,&r,&x);
update(1,1,n,l,r,tag(x,-inf,x,-inf));
}
else if(op==2){
scanf("%lld%lld%lld",&l,&r,&x);
update(1,1,n,l,r,tag(-x,0,-x,0));
}
else if(op==3){
scanf("%lld%lld%lld",&l,&r,&x);
update(1,1,n,l,r,tag(-inf,x,-inf,x));
}
else if(op==4){
scanf("%lld",&x);tag t=query(1,1,n,x);
printf("%lld\n",max(a[x]+t.x,t.y));
}
else{
scanf("%lld",&x);tag t=query(1,1,n,x);
printf("%lld\n",max(a[x]+t.X,t.Y));
}
}
return 0;
}
-
Rikka with Sequences
不会kdt,先咕着。
2. 无法用懒标记处理的单点问题
此处的单点问题包括区间询问历史最值,因为做法与查询单点历史最值相同。
最开始有两个长度为 \(n\) 的完全相同的数列 \(A\) 和 \(B\),接下来有 \(m\) 次操作,每一次操作都是以下的四种之一:
- 对于所有的 \(i∈[l,r]\),将 \(A_i\) 变成 \(A_i+c\)。
- 对于所有的 \(i∈[l,r]\),将 \(A_i\) 变成 \(\max(A_i,d)\)。
- 对于所有的 \(i∈[l,r]\),询问 \(A_i\) 的最小值。
- 对于所有的 \(i∈[l,r]\),询问 \(B_i\) 的最小值。
在每一次操作结束后都会进行一次更新,将所有的 \(B_i\leftarrow \min(B_i,A_i)\)。
我们发现这题的区间取最值操作是取最大值,而查询是取最小值,故由于方向相反我们无法沿用先前的直接合并标记的做法。
但是我们可以回忆在第一章节所得到的 trick:区间取最值转化为区间加减。我们还是将线段树节点上的区间分为两类:最小值与非最小值。此时只有了区间加减操作,历史最值便是容易处理的。
更具体的,我们维护四个 lazytag:表示区间最小值的标记 \(tag_1\)、区间非最小值的标记 \(tag_2\)、区间最小值的标记的历史最小值 \(htag_1\)、区间非最小值的标记的历史最小值 \(htag_2\)。注意其中的历史最小值皆指从上一次 pushdown 至此这段时间内的最小值。
#include<bits/stdc++.h>
using namespace std;
#define ls p<<1
#define rs p<<1|1
const int N=5e5+6;
const int inf=2e9;
int n,Q,a[N];
struct node{
int mn,se,hmn,tag1,tag2,htag1,htag2;
}tr[N<<2];
inline void pushup(int p){
tr[p].mn=min(tr[ls].mn,tr[rs].mn);
tr[p].hmn=min(tr[ls].hmn,tr[rs].hmn);
if(tr[ls].mn==tr[rs].mn)tr[p].se=min(tr[ls].se,tr[rs].se);
else if(tr[ls].mn<tr[rs].mn)tr[p].se=min(tr[ls].se,tr[rs].mn);
else tr[p].se=min(tr[ls].mn,tr[rs].se);
return;
}
inline void build(int p,int l,int r){
if(l==r){
tr[p].mn=tr[p].hmn=a[l];
tr[p].se=inf;
return;
}
int mid=(l+r)>>1;
build(ls,l,mid),build(rs,mid+1,r);
pushup(p);
return;
}
inline void pushtag(int p,int val1,int val2,int hval1,int hval2){
tr[p].hmn=min(tr[p].hmn,tr[p].mn+hval1);
tr[p].mn+=val1;
tr[p].htag1=min(tr[p].htag1,tr[p].tag1+hval1);
tr[p].tag1+=val1;
tr[p].htag2=min(tr[p].htag2,tr[p].tag2+hval2);
if(tr[p].se!=inf)tr[p].se+=val2;
tr[p].tag2+=val2;
return;
}
inline void pushdown(int p){
if(!tr[p].tag1&&!tr[p].tag2&&!tr[p].htag1&&!tr[p].htag2)return;
int mn=min(tr[ls].mn,tr[rs].mn);
if(tr[ls].mn==mn)pushtag(ls,tr[p].tag1,tr[p].tag2,tr[p].htag1,tr[p].htag2);
else pushtag(ls,tr[p].tag2,tr[p].tag2,tr[p].htag2,tr[p].htag2);
if(tr[rs].mn==mn)pushtag(rs,tr[p].tag1,tr[p].tag2,tr[p].htag1,tr[p].htag2);
else pushtag(rs,tr[p].tag2,tr[p].tag2,tr[p].htag2,tr[p].htag2);
tr[p].tag1=tr[p].tag2=tr[p].htag1=tr[p].htag2=0;
}
inline void updateadd(int p,int l,int r,int s,int t,int val){
if(s<=l&&r<=t){
pushtag(p,val,val,val,val);
return;
}
int mid=(l+r)>>1;
pushdown(p);
if(s<=mid)updateadd(ls,l,mid,s,t,val);
if(t>mid)updateadd(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline void updatemax(int p,int l,int r,int s,int t,int val){
if(val<=tr[p].mn)return;
if(s<=l&&r<=t&&tr[p].se>val){
pushtag(p,val-tr[p].mn,0,val-tr[p].mn,0);
return;
}
int mid=(l+r)>>1;
pushdown(p);
if(s<=mid)updatemax(ls,l,mid,s,t,val);
if(t>mid)updatemax(rs,mid+1,r,s,t,val);
pushup(p);
return;
}
inline int query(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return tr[p].mn;
int mid=(l+r)>>1,res=inf;
pushdown(p);
if(s<=mid)res=min(res,query(ls,l,mid,s,t));
if(t>mid)res=min(res,query(rs,mid+1,r,s,t));
return res;
}
inline int queryhis(int p,int l,int r,int s,int t){
if(s<=l&&r<=t)return tr[p].hmn;
int mid=(l+r)>>1,res=inf;
pushdown(p);
if(s<=mid)res=min(res,queryhis(ls,l,mid,s,t));
if(t>mid)res=min(res,queryhis(rs,mid+1,r,s,t));
return res;
}
int main(){
scanf("%d%d",&n,&Q);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
build(1,1,n);
while(Q--){
int op,l,r,val;
scanf("%d%d%d",&op,&l,&r);
if(op==1){
scanf("%d",&val);
updateadd(1,1,n,l,r,val);
}
else if(op==2){
scanf("%d",&val);
updatemax(1,1,n,l,r,val);
}
else if(op==3)printf("%d\n",query(1,1,n,l,r));
else printf("%d\n",queryhis(1,1,n,l,r));
}
return 0;
}
对于线段树3的区间加维护参见之前的讨论。维护起来也是容易的。
3. 无区间最值操作的区间问题
这一类型的题目修改操作大都为区间加减,而询问为区间历史最大/小值之和、历史版本和之和。由于没有区间取最值的操作,我们无法使用懒标记来直接维护。下文将针对这询问的不同类型做出转化方法。
- 询问历史最小/大值之和
以最小值为例。最大值显然同理。
设 \(a_i,b_i\) 分别是当前数组、历史最小值。我们定义一个辅助数组 \(c_i=a_i-b_i\)。那么,当 \(a_i+x\) 时,若 \(b_i\) 无变化则 \(c_i\) 亦相当于 \(+x\) 否则变为 \(0\)。
那么,对于 \(c_i\) 的变化我们可以发现:对于 \(A\) 的区间加减在 \(C\) 上相当于 \(\max(c_i+x,0)\)——那么这是个取最值的问题——便是我们所熟知的了。
将 \(A-C\),得到即为答案。前者使用朴素的线段树,后者即为我们在第三章讨论的 trival 做法。
- 询问历史版本和之和
设 \(a_i,b_i\) 分别为当前数组、历史版本和。令 \(t\) 表示此时结束的操作数(不包括当前操作),同样地定义辅助数组 \(c_i=b_i-ta_i\)。
与上一种情况类似的,对于不影响到 \(b_i\) 时,对 \(A\) 的加法在 \(C\) 上体现为减去 \(tx\)。于是,这种情况甚至未涉及到区间取最值——直接使用最朴素的线段树维护区间加减即可。
4. 有区间最值操作的区间问题
我们通过一道例题来引入并结束此章节的讨论。
-
赛格蒙特彼茨
给出数组 \(A,B\),初始时 \(B\) 与 \(A\) 完全相同。
支持维护 \(A\) 的区间加减、区间取 \(\max\),查询 \(B\) 的区间和。\(B\) 为 \(A\) 的历史最小值。
三. 习题
四. 参考文献&鸣谢
- 吉如一,2016年国家集训队论文-区间最值操作与历史最值问题。对本文提供了本文大部分的结构以及思路指导。
https://yutong.site/wp-content/uploads/2018/09/国家集训队2016论文集.pdf
- Joyemang233的博客:「清华集训2015」V。对于此题提供了另一种值得思考的做法。
- command_block的博客:关于线段树上的一些进阶操作。对习题进行了一些补充。
https://www.luogu.com.cn/blog/command-block/guan-yu-xian-duan-shu-shang-di-yi-suo-jin-jie-cao-zuo
- 洛谷Luogu上关于吉老师线段树第一部分时间复杂度的讨论。对第一部分的复杂度做出了进一步的探讨。
标签:return,rs,int,tr,Tree,Beats,区间,Segment,最值 From: https://www.cnblogs.com/trsins/p/17970751