Swin Transformer
目录简介
论文地址: https://arxiv.org/pdf/2103.14030.pdf
论文代码: https://github.com/microsoft/Swin-Transformer
VIT的缺陷
vit detr 等基于transformer模型已经成功应用到CV领域,现阶段还存在这不少的问题
1、同一实体的尺寸变化问题。视觉实体的尺度区别很大,例如车辆和人,detr 在小目标上的识别较差
2、高分辨率图像引起的计算复杂度上升问题, 图像像素的分辨率太大,导致计算量过大,vit 计算量为平方级的增长
3、tranformer结构训练,需要巨大的数据集作为支持
Swin Transformer 是在 ViT的基础上将层次性、局部性和平移不变性等先验引入网络结构,使用层级式的,滑动窗口,能适用于多种CV任务,且其复杂度相对图片大小为线性相关,计算效率得到了提升
提出了一种包含滑窗操作,具有层级设计的Swin Transformer。一种通用的backbone结构,可以应用下的classification, detection, segmentation 等任务
核心创新
滑动窗口(shifted window)
-
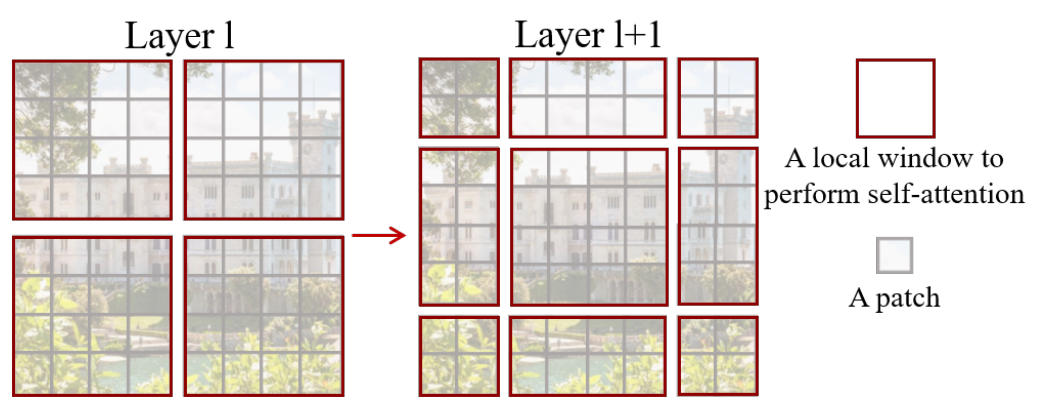
在窗口内计算attention 在每一层中,将图片切分成若干个窗口,自注意的计算在局部的非重叠窗口内进行
- 好处一、减少计算的复杂度,复杂度从此前的和图像大小的平方关系变成了线性关系,也使得层次化的整体结构设计、局部先验的引入成为可能,好处二、是因为采用非重叠窗口,自注意计算时不同query会共享同样的key集合,从而对硬件友好,更实用
-
层间做patch合并以获得多尺度特征,patch merging 通过某种方法,改变原始图片大小,然后继续按相同的方式划分窗口
滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量
VIT的架构特点
- 在不同层中,保持patch数量和patch大小(16*16)不变。
- 一整张图就是一个窗口,即VIT是在整张图的维度上计算attention的。
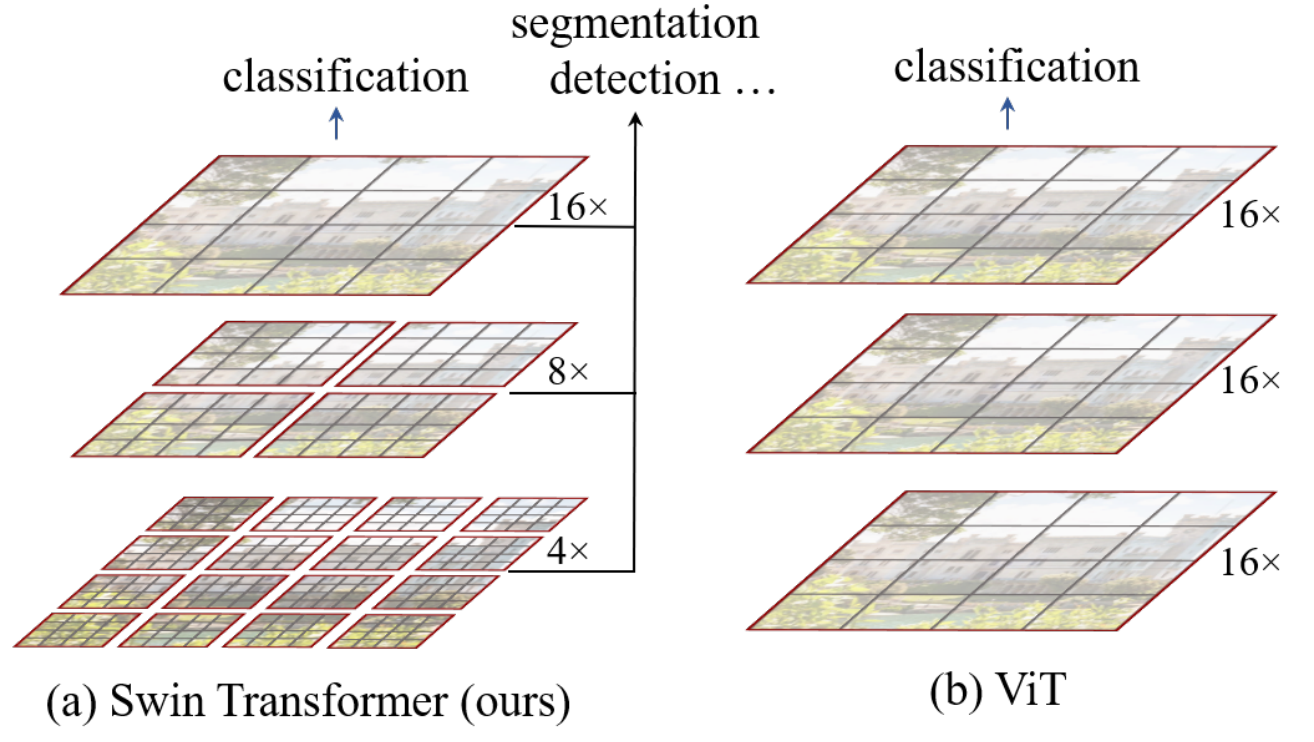
总体结构和运作
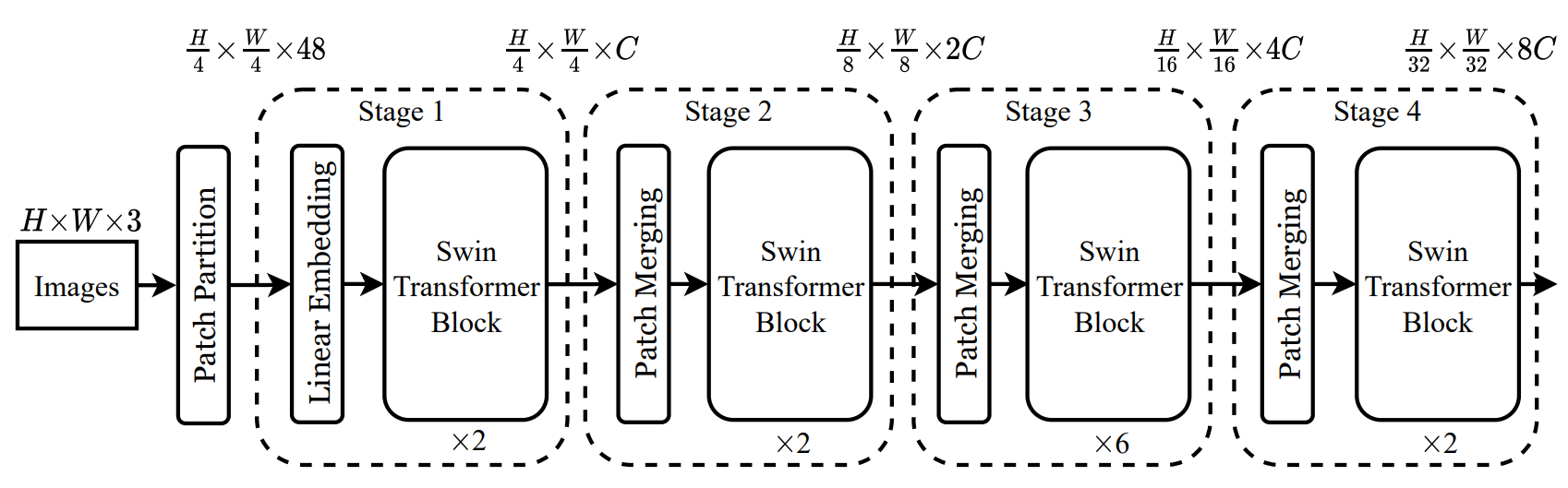
swin transformer借鉴了很多卷积神经网络的设计理念以及其先验知识。层级结构,分辨率每层变成一半,而通道数变成两倍。
整个模型一共主要设计了4个Stage,每个 Stage 都会缩小输入特征的分辨率
假设输入图片的维度是224x224x3,即这里H=224, W=224
1、在输入时,先做一个 Patch Embedding,patch大小为4×4, 每4个像素一个Patch 将图片切成一个个图块,相当于4倍下采样,最后维度变成了56x56 个大小为4*4*3的小方块, 然后把这些小方块拉平,就得到56*56*48 相当于VIT中等分成小块的操作
2、通过Linera Embedding层,这就是一个全连接层,会将刚刚56x56x48的特征图映射为 56x56x96。 这里和ViT模型是一样的
3、现在得到56x56x96的特征图,通过Swin Transformer Block结构,输出结果仍然是56x56x96
4、通过第一个Swin Transformer Block后,尺寸为56x56x96将其送入Patch Merging,这层实现了将特征图分辨率减半,通道数翻倍的操作,输出图像为28x28x192
5、接下来都是一些重复的结构了
其中 Patch Merging 类似一个池化的操作操作来降低特征的分辨率,swin transformer Black结构,和transformer block基本类似,用来提取特征。
网络细节
Patch partition
这里采用了和VIT相同的操作,将输入图像裁剪模成不重叠的小块。
假设一个图像 H × W × C 现在将其切分成P x P x C 全部的patches的维度为 N×P×P×C, 然后将每个patch进行展平,相应的数据维度就可以写为 $(N,P^2,C) $
N 输入到Transformer的序列长度, C 为输入图像的通道数, P 为图像patch的大小
将图像分成4×4的patch(小方块),每个patch块可以看做是一个token(词向量),每个块的特征维度4x4x3=48
Linear Embedding
在原始值特征上应用一个线性变换的嵌入层,将其投影到任意维度C。
Patch Merging
特征图分辨率减半,通道数翻倍
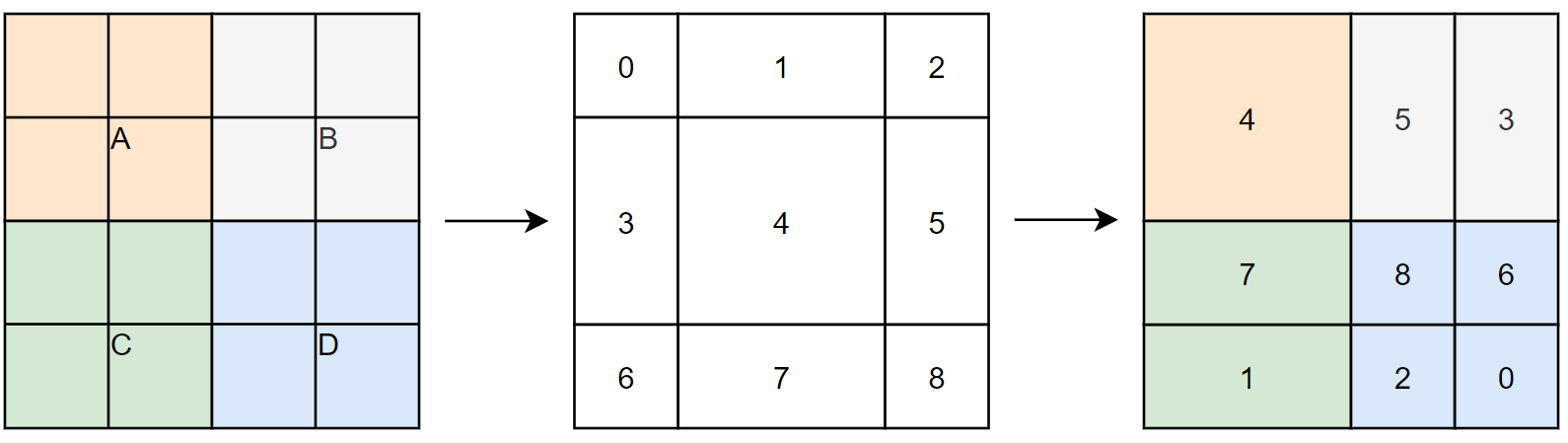
Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层,将feature map的深度由C变成C/2,实现非卷积的的下采样操作。如图表示 特征图concat 过程
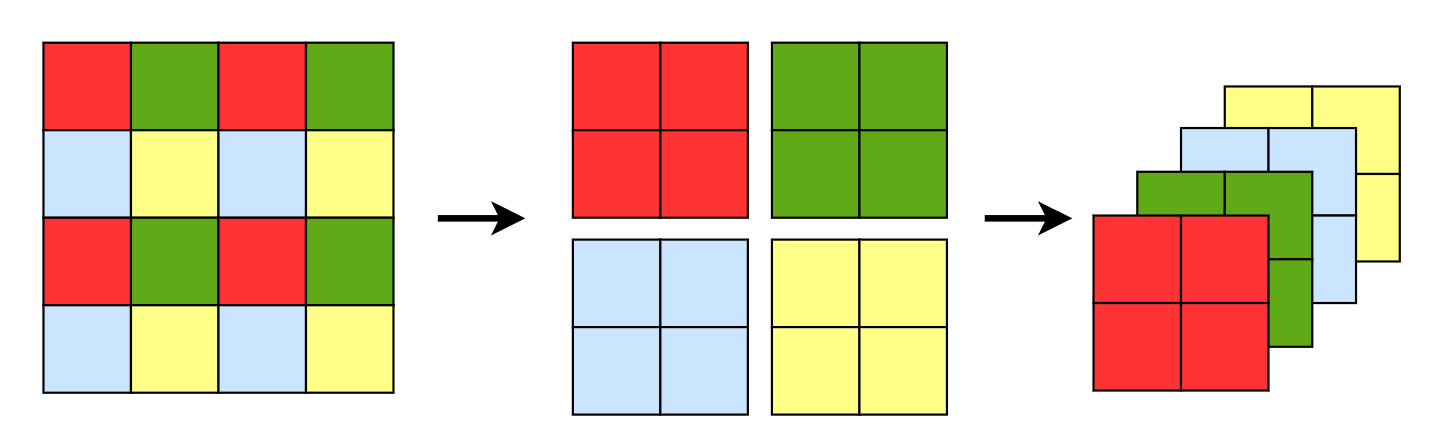
假设输入是4×4大小单通道的特征图,首先我们会隔一个取一个小Patch组合在一起,最后4×4的特征图会行成4个2×2的特征图. 接下来将4个Patch进行拼接,现在得到的特征图尺寸为2×2×4.
然后会经过一个LN层,LN层后特征图尺寸不会改变,仍为2×2×4。最后会经过一个全连接层,将特征图尺寸由2×2×4变为2×2×2。
Swin Block模块
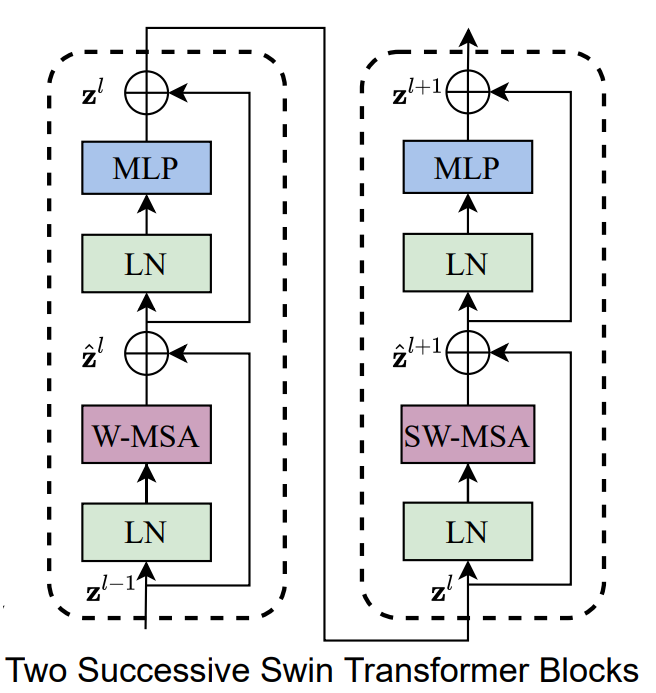
Swin Block整体上和 tansformer 的结构一样,不同的有 W-MSA **SW-MSA ** 两个模块。
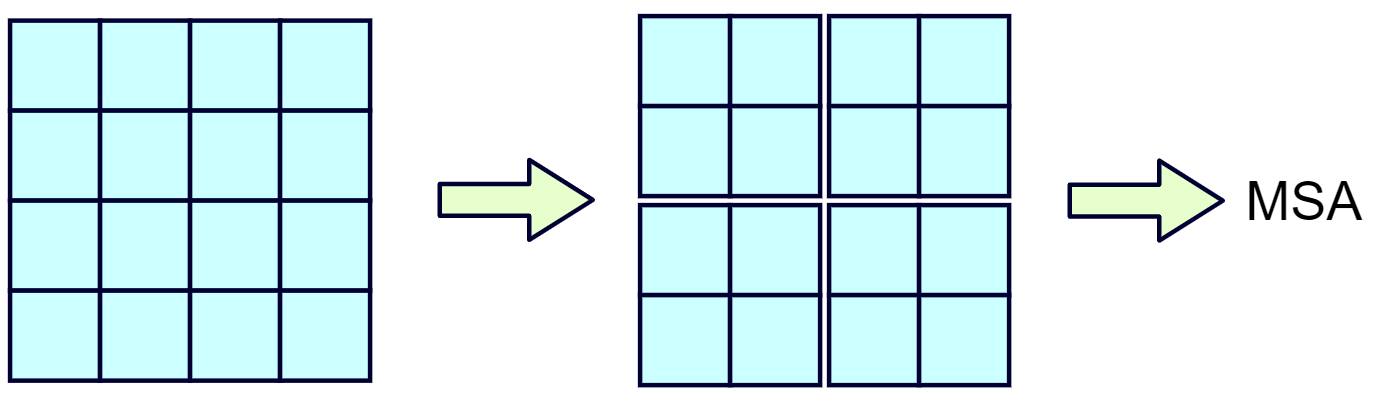
W-MSA(Windows Multi-Head Attention)和传统多头注意力机制不同的就是按照一定的尺寸将图像划分为不同的window,每次transformer的attention只在window内部进行计算
SW-MSA 是为了解决每个窗口之间的交互,引入了对特征图的偏移,采用的是mark方法
W-MSA
W-MSA,即Windows Multi-Head Attention,它也是一个多头的自注意机制。它和传统的 Multi-Head Attention的区别就在于W-MSA会先将特征图分成一个个Windows,然后对每个Windows执行Multi-Head Attention操作
将56x56xC特征图划分为标准的大小规则的窗口,论文中使用的7x7,然后在7x7的特征图上做注意力操作,输入维度为49x96
SW-MSA
由于W-MSA将原始特征图分成一个个小窗口,然后分别送入MSA中,这会导致各个窗口之前没有任何的联系,都是独立的
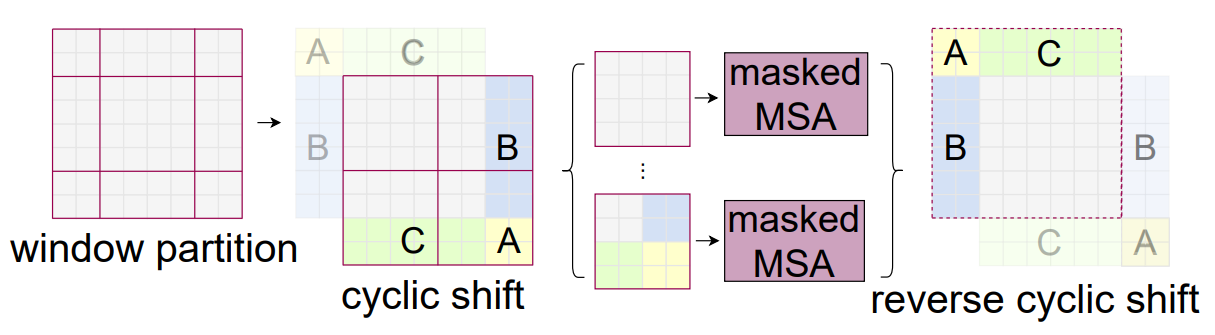
为实现窗口交互,提出了一种向右下方位偏移的配置方法(偏移了1/2个窗口像素),但是经过移动之后窗口的大小会产生不同,如图由原先的4个变成了9个,这样后续进行MSA就很麻烦,导致W-MSA的窗口尺寸发生了变换。
提出了一种比较高效的计算方式 Efficient batch computation for shifted configuration
SW-MSA会重新划分窗口,即由图像左上角变成图像右下角
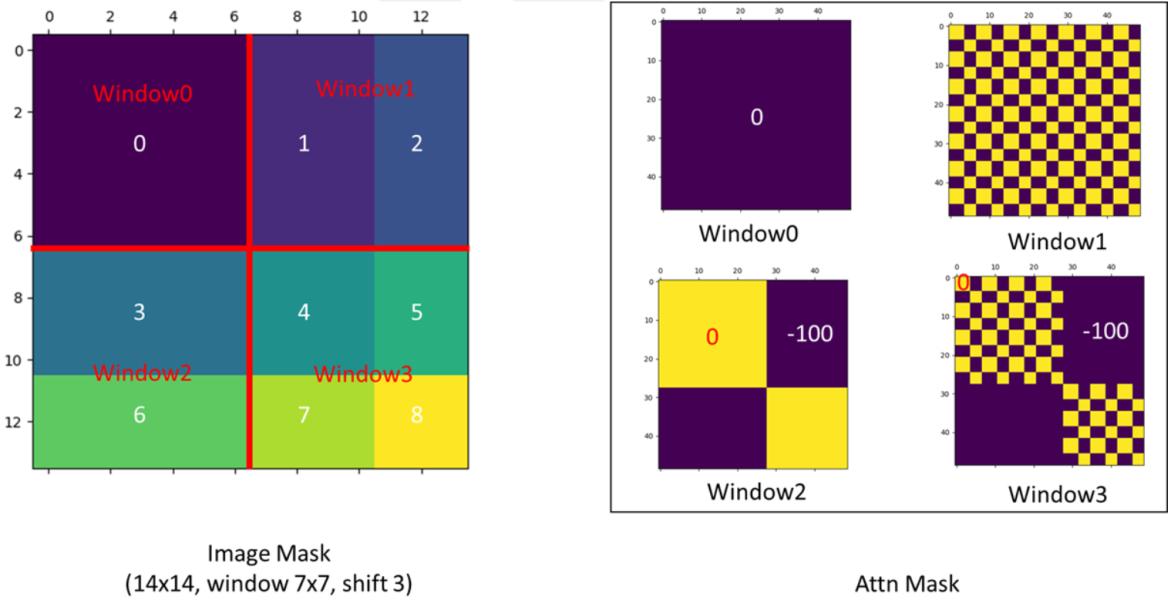
简单理解W-MSA 是图像分为比较规整的 A,B,C,D 四个窗口,SW-MSA 是进行了图像偏移之后的拼接图像,原先的左上角A移动到了右下角的A,原先左侧的B移动了右侧B,原先上面C移动了下面C, 参考图像中数字。
此时一共可以分成4个窗口,和没划分窗口前一样,但是现在的4个窗口就解决了原先窗口无法进行信息传递的问题,例如现在5 3构成的窗口融合了原始四个窗口的信息,即使原始的四个窗口之前有了联系。
可以理解成将原始的窗口向右下角移动2个patch
这样移动的好处是,对一些patch来说,两次计算attention时,它们分属不同的窗口,这样可以让它们和不同的patch交互,扩大感受野。
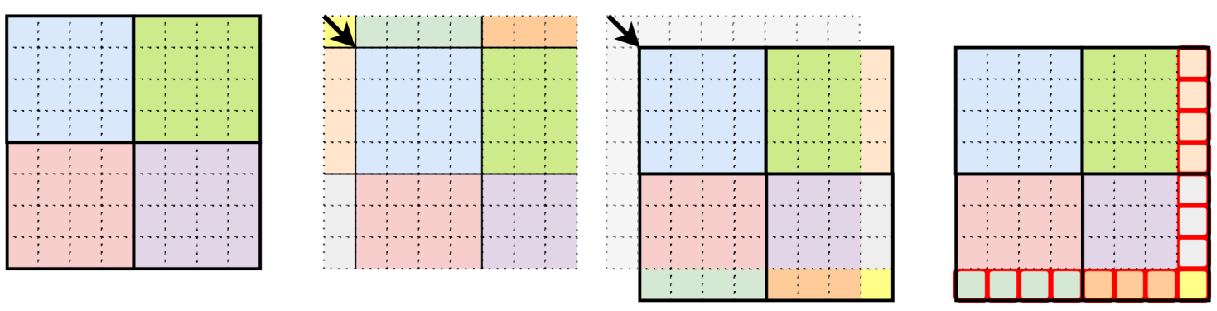
如图,4是一个独立的窗口,将5和3合并成一个窗口,将7和1合并一个窗口,将8,6,2,0合并为一个新的窗口,这样还是4x4保证计算相同。
Attention Mask
为了防止 5 3 区域在原图上是不相邻的两个区域,不应该做自注意力。不符合常理。提出掩码操作即maskedMSA。
最后将循环位移回去,变回原来位置,以保持相对位置不变,整个图片的语义信息也是不变的。不做相当于将图片一直往右下角移动,语义信息就可能被破坏。
假设是 3 5 区域计算注意力,属于区域3 的特征,只能和区域3 的特征进行匹配,而不能和区域5的进行匹配, 那么我们可以将不属于区域3中的所有匹配结果都减去100,将其中一些数减去100后在通过SoftMax得到对应的权重都等于0了,所有实际上还是只和区域3内的特征进行了MSA
参考资料:https://github.com/microsoft/Swin-Transformer/issues/38
参考资料:https://blog.csdn.net/qq_16227333/article/details/125116344
整个Swin Block的设计目的有两个目标
1、window的数量不能多,也不能变
2、window的之间存在信息交流
计算成本分析
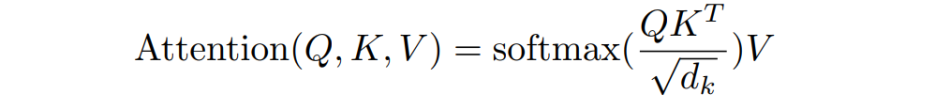
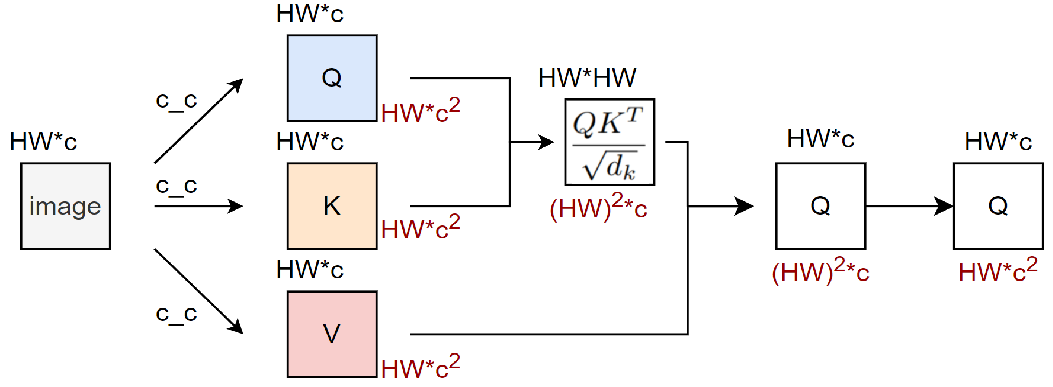
忽略batch维度(认为b = 1),则此时输入数据的维度为(hw, C),其中hw(即h * w)表示patch数量,也就等同于token序列的长度
- 计算Attention的第一步,我们需要让输入数据和 $W_Q W_k W_v $ 这三个矩阵相乘,得到Q、K、V三个结果矩阵。三个矩阵的维度都是
(C, C)借助上面的公式(hw, C) * (C, C) = (hw, C),此时的运算量为 \(3hwC^2\) - 需要将Q和K相乘,得到attention score,
(hw, C) * (C, hw) = (hw, hw), 此时的运算为\((hw)^2C\) - 要将attention score和V相乘,
(hw, hw) * (hw, C) = (hw, C)此时的运算为\((hw)^2C\) - 最后将结果过一层线性映射层 ,
(hw, C) * (C, C) = (hw, C)此时的运算量为 \((hw)C^2\)
以上四步的运算相加为
\[(MSA)=4hwC^2+2(hw)^2C \]设窗口的H和W的值为:H=M,W=M,默认操作中M=7 代入
\[nums=\frac{H}{M}*\frac{W}{M} \]\[(SMSA)=\frac{H}{M}*\frac{W}{M}*( 4M^2C^2+2(M^2)^2C) \]\[(SMSA)=4hwC^2+2M^2hwC \]\[(CMSA)=4hwC^2+s*hw^2C+sh^2wC \]主要优势
W-MSA相比于传统的MSA,兼顾 全局特性和局部特性、同时提升计算速度
1、将图像划分为不同的window
2、仅仅对窗口进行注意力机制
3、设计移动窗口、实现窗口信息交流,保持全局特性
Swin Transformer V2
Swin Transformer V2的核心是将模型扩展到更大的容量和分辨率
-
后归一化技术和缩放余弦注意方法,以提高大视觉模型的稳定性;
-
对数间隔连续位置偏置技术,有效地将在低分辨率图像和Windows下训练的模型传递给高分辨率的对应模型。
-
分析了关键实现细节,这将导致显著节省GPU内存消耗,从而使使用常规GPU训练大型视觉模型成为可能。
参考
https://blog.csdn.net/qq_36758270/article/details/130833560
https://www.jianshu.com/p/0635969f478b
https://zhuanlan.zhihu.com/p/663747861
标签:Transformer,Swin,窗口,hw,patch,MSA From: https://www.cnblogs.com/tian777/p/17935080.html