transformer补充细节
目录https://juejin.cn/post/7152002993204756487
注意力机制细节
第一步:计算自我注意力的第一步是根据编码器的每个输入向量(每个词的嵌入)创建三个向量。
创建一个Query向量、一个Key向量和一个Value向量。
embedding和编码器输入/输出向量的维数是512, 一般情况下设置多头数为8,所以每个向量的维数是64 (工程上采用创建一个512的整体,切分再合并操作)
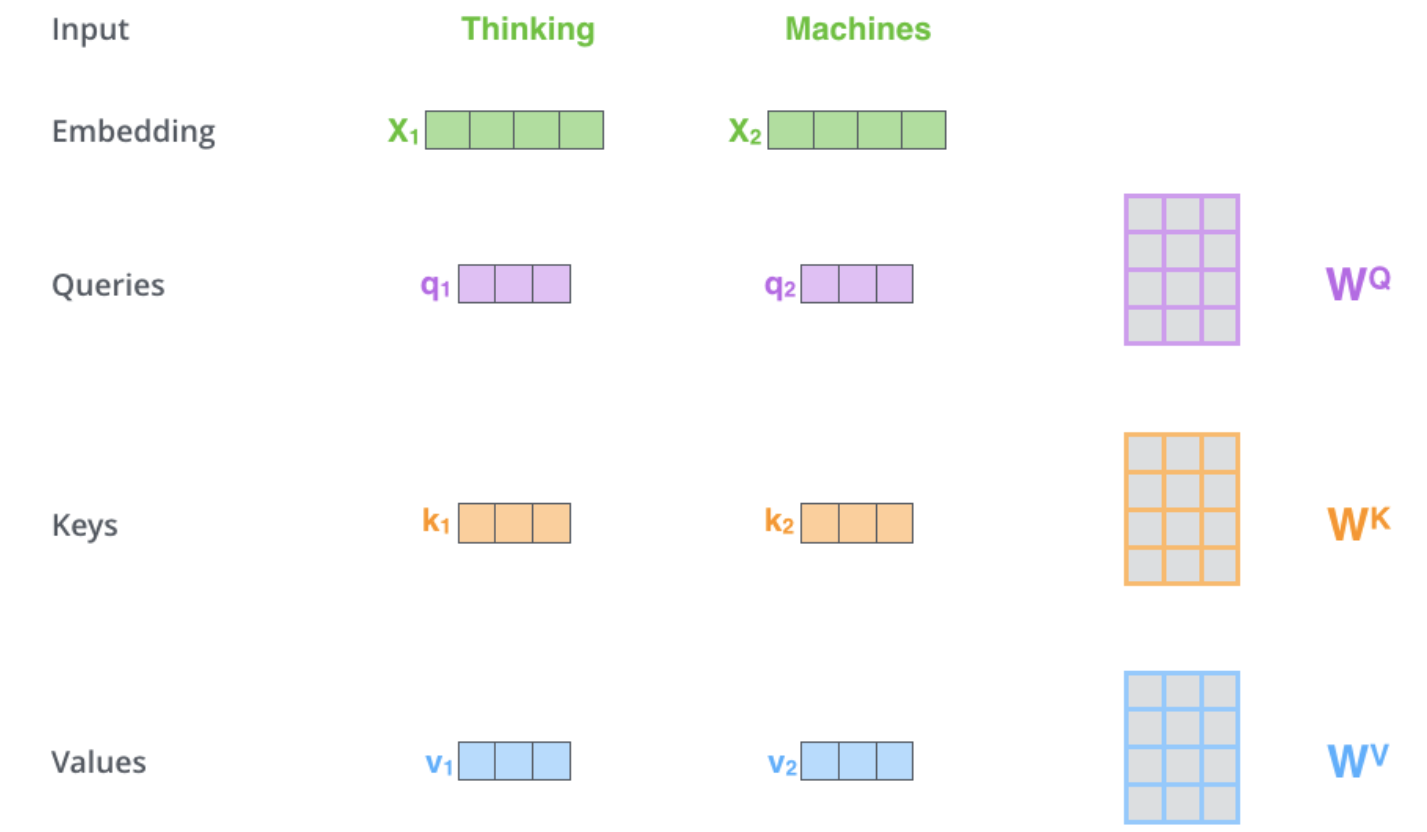
第二步:计算一个分数(score)
比如我们要计算本例中第一个词 “Thinking”的自我注意力。我们需要对输入句子中的每个词与这个词进行评分。分数决定了当我们在某个位置对一个词进行编码时,要对输入句子的其他部分给予多大的关注。
分数的计算方法是将查询向量 Q 与我们要打分的各个单词的关键向量 K 进行点积。因此,如果我们正在处理1号位置的单词的自注意时,第一个分数将是q1和k1的点积。第二个分数将是q1和k2的点积。
第三和第四步是将分数除以8
8的来源是关键向量维度的平方根, 也就是64。这使得拥有更稳定的梯度。
然后将结果通过softmax操作。Softmax将分数归一化,所有分值,加起来是1。这个softmax分数决定了每个词在这个位置的表达量。
第五步 将每个Value向量乘以softmax分数
第六步 是对加权向量进行求和
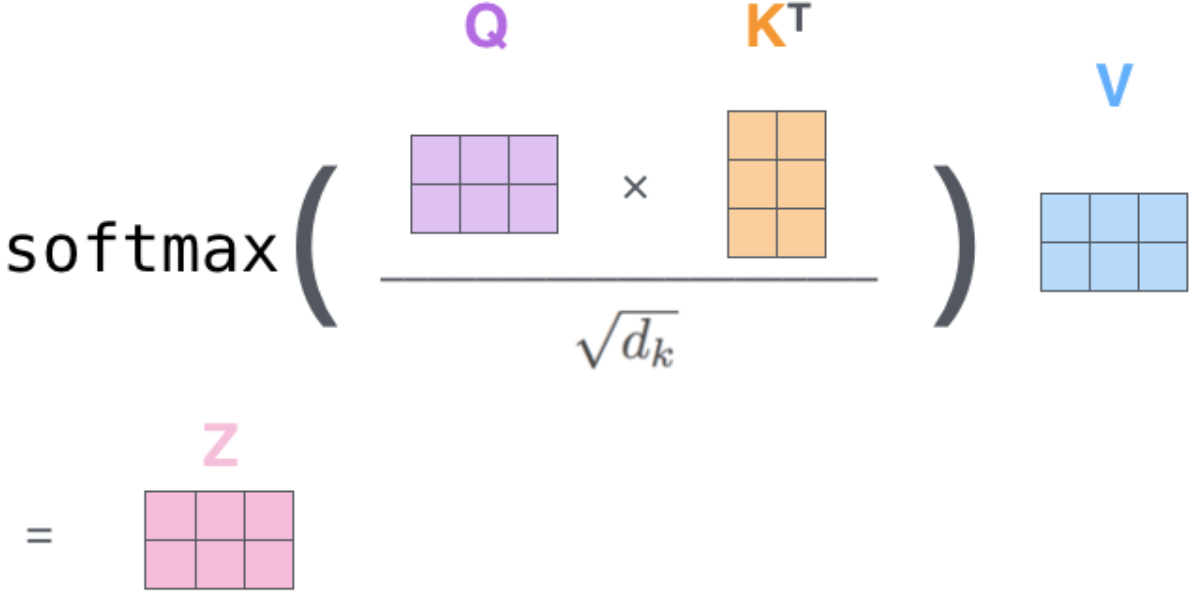
为什么对点积注意力进行缩放
样本维度$d_k $越大,点积增长的幅度越大,会将Softmax函数推入梯度极小的区域,从而使训练难度增大。
构建缩放点积注意力,对$ QK^T $的点积乘以 1/np.sqt(dk) ,进行点积的缩放
多头带来的好处
- 它扩大了模型对不同位置的关注能力
- 给了注意层多个 “表征子空间(representation subspaces)”
数据流
训练时数据流
1、编码器: 输入: 输入文本 包含文本编码和文本位置编码
2、编码器: 输出: 编码器进过6层堆叠处理,输出 K V 编码表示
3、解码器: 输入: 目标序列文本 包含文本编码和文本位置编码
4、解码器: 自注意力输入: 输入来个编码器的 K V 和 本身生成的 Q
5、解码器:输出:输出层将其转换为词的概率,生成最终的输出序列。
Transformer的目标是通过同时使用输入序列和目标序列来学习如何输出目标序列。
推理时数据流
1、 编码器: 输入: 输入文本 包含文本编码和文本位置编码
2、编码器: 输出: 编码器进过6层堆叠处理,输出 K V 编码表示
3、 解码器: 输入:不使用目标序列,使用一个只包含句子起始token的空序列,带文字位置编码
4、解码器: 自注意力输入: 输入来个编码器的 K V 和 本身生成的 Q
5、解码器: 输出: 输出层将其转换为词的概率,生成的输出序列。
6、解码器: 输入:将输出序列的最后一个词作为预测词。这个词现在填充到我们的解码器输入序列的第二个位置,其中包含一个句子起始token和第一个词。
7、重复3,4,5,6 过程。
解码器中注意力的不同
decoder的QKV的Q是自己提供的,K和V都是来自encoder。从流程上encoder就是为了提供K,V
在decoder的输入中,K和V都是从encoder最后一个堆叠模块中输出得到。
Decoder的Q向量是由Decoder自身的前一个时间步的隐藏状态计算得到的。在Decoder中,每个位置的Q向量会与Encoder的所有位置的K向量进行注意力计算,用来捕捉输入序列中不同位置之间的依赖关系。
Decoder的第一个多头注意力机制和普通注意力机制不同
Decoder 的第一个多头注意力机制和普通注意力机制不同,需要确保模型只能依赖于已经生成的前面的单词,而不能直接访问后面的单词。 这个步骤就是通过掩码(隐藏)未来的单词来实现的。
我们需要确保模型只能依赖于已经生成的前面的单词,而不能直接访问后面的单词。 这个步骤就是通过掩码(隐藏)未来的单词来实现的。
还有一个作用:让padding (不够长的补0) 部分不参与attention操作。
带掩码的注意力机制
每个批次输入序列长度是不一样的,因此我们需要对不同长度的序列进行对齐,具体来说,就是给在较短的序列后面填充 0,为了使得decoder看不见未来的信息,对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 时刻之后的输出。因此我们通过增加Mask的方法,把 t 时刻之后的信息给隐藏起来。
实际操作时候:在计算注意力得分时,我们会加上负无穷大,这将使得在下一阶段softmax函数会将这些负数变为0。这种技术确保了模型在没有访问权限的情况下无法访问下一个单词。
具体的做法为:产生一个上三角矩阵,下三角的值全为1,上三角的值权威0,对角线也是1,然后将矩阵作用到每一个序列中。
- 引入类对角矩阵,实现并行解码加速整个训练过程
- 在生成attention时保存信息不泄露- 掩盖到未来的信息
参考:
https://blog.51cto.com/u_15834745/6020640
https://zhuanlan.zhihu.com/p/389705754
位置编码
在transformer的encoder和decoder的输入层中,使用了Positional Encoding
input_embedding是通过常规embedding层,将每一个token的向量维度从vocab_size映射到d_model,由于是相加关系,自然而然地,这里的positional_encoding也是一个d_model维度的向量。
构造位置编码的方法
整型数值标记
给第一个token标记1,给第二个token标记2...,以此类推。
(1)模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化。
(2)模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。
[0,1]范围标记位置
0表示第一个token,1表示最后一个token,比如有3个token,那么位置信息就表示成[0, 0.5, 1]
问题:当序列长度不同时,token间的相对距离是不一样的。例如在序列长度为3时,token间的相对距离为0.5
位置编码要求:
(1)它能用来表示一个token在序列中的绝对位置
(2)在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致
(3)可以用来表示模型在训练过程中从来没有看到过的句子长度。
二进制标记
用一个d_model长度的二进制标识输入input embedding的位置
问题:位置信息不够连续
周期函数标识
需要一个有界又连续的函数,可以考虑把位置向量当中的每一个元素都用一个sin函数来表示,则第t个token的位置向量可以表示为:
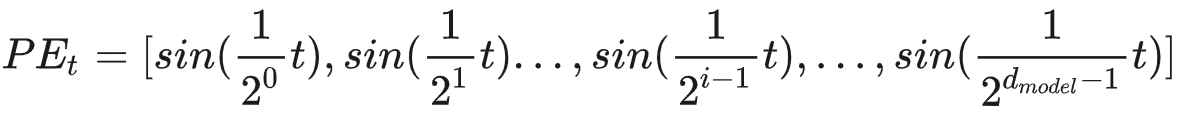
通过控制频率来控制sin函数的波长,频率越小,此时sin函数对t的变动越不敏感
用sin和cos交替来表示位置
- 为了得到 不同的位置向量是可以通过线性转换得到的
详细参考这两篇文章:
https://zhuanlan.zhihu.com/p/454482273
https://juejin.cn/post/7132693792087343117?searchId=202312181553536083277EE760016AA287
训练测试细节
在数据流的操作层面不同
在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而,在预测阶段,其输出序列的词元是逐个生成的。
https://blog.csdn.net/qq_54185421/article/details/125249799?spm=1001.2014.3001.5502
参考资料:
https://juejin.cn/post/7152002993204756487
https://blog.csdn.net/BXD1314/article/details/125759352?spm=1001.2014.3001.5502 详细-和代码绑定
https://juejin.cn/post/7241859817563389989
https://zhuanlan.zhihu.com/p/338817680
标签:transformer,补充,位置,token,细节,输入,序列,注意力,向量 From: https://www.cnblogs.com/tian777/p/17917394.html