transformer总体架构
目录论文地址:Attention is All You Need https://arxiv.org/pdf/1706.03762.pdf
循环神经网络
-
长距离衰减问题,距离过长导致梯度消失或爆炸
-
解码阶段,越靠后的内容,翻译效果越差
-
解码阶段缺乏对编码阶段各个词的直接利用
-
无法并行,速度较慢,RNN会依赖前一时刻输出的隐层状态
总体架构

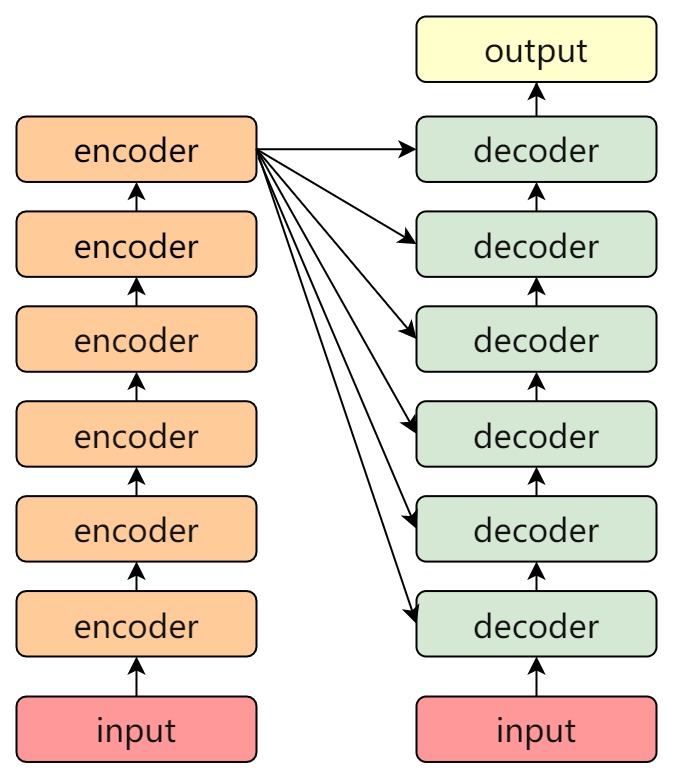
Transformer的基本结构,通过例图可看出transformer是由encoder与decoder构成
左边的部分是编码器Encoder,右边的部分是解码器Decoder,根据不同的任务需要,使用对应的部分,一般编码器部分常用于文本编码分类,解码器部分用于语言模型生成,
Encoder和Decoder都包含6个block层,编码器和解码器并不是简单的串联关系。
Encoder
- 每个编码器由两个子层结构组成
- 第一个子层包括 一个多头自注意力子层, 规范化层、残差连接
- 第二个子层包括 一个前馈全连接层、规范化层、残差连接
Decoder
- 第一个子层包括 一个多头自注意力子层、规范化层、残差连接
- 第二个子层包含 一个多头注意力子层、规范化层、残差连接
- 第三个子层包含 一个前馈全连接层、规范化层、残差连接
编码器Encoder
编码器Encoder 由6个相同层block组成,每一层由相同的两部分组成:一个多头注意力层和一个Feed Forward层。这两个部分后面都进行残差连接和LayerNorm归一化。Feed Forward层其实就是简单的MLP层,由两个线性层组成,中间用LeRU函数进行激活。多头注意力层在后续第3节会讲解。
-
编码器Encoder:每一层都有两个子层。
-
第一层是一个多头注意机制 (Multi-Head Attention)
-
第二层是简单的、位置完全连接的Feed Forward(Feed Forward Neural Network 前馈神经网络),由两个线性变换组成,之间有一个ReLU激活。
-
每个子层会叠加一个Add&Norm, 即采用残差连接,接着进行特征归一化(标准化),每个子层的输出都是LayerNorm(x +Sublayer(x)),其中Sublayer(x) 是由子层本身实现的函数。
解码器Decoder
解码器Decoder 也是由6个相同层组成,每一层由相同的三部分组成:一个带掩码的多头注意力层、一个多头注意力层和一个MLP层。与编码器一样都在各部分后添加残差和LayerNorm归一化,不同的是在多头注意力层中输入的是由编码器输出的key、value和经过带掩码的多头注意力层输出的query
-
第一层是Masked Multi-Head Attention (掩码多头注意力)
-
第二层是Cross) Multi-Head Attention (多头注意力层)
输入输出层
模型输入
获取输入数据的向量 X,X由数据的 Embedding 和 位置的 Position 相加得到。
- 输入数据,将文本信息转化成词向量
inputs embedding - 输入位置信息,由于输入的是序列数据,有着较为严格的前后顺序,因此需要输入序列数据的同时输入位置信息
inputs embedding(词嵌入) 负责将自然语言转化为与其对应的独一无二的词向量表达
词向量模型:https://juejin.cn/post/7297440438235398198
Position Embedding(位置嵌入) 表示单词出现在句子中的位置。理由是Transformer是使用全局信息,无法捕捉到序列顺序信息的,需要使用Position Embeddin表示句子位置。
位置编码
位置编码positional encodings位置编码是直接加在输入的 $a= \left { a_1,a_2,...,a_n \right } $ 中, 即输入的 $pe= \left { pe_1,pe_2,...,pe_n \right } $ 和 $a= \left { a_1,a_2,...,a_n \right } $ 有相同的维度大小。
- 方案1,绝对位置编码
- 方案2,可训练的位置编码
绝对位置编码:
给每个位置的位置信息建模,最简单的实现方式:使用每个词汇的次序 1,2,...,T 作为位置编码信息。例如,BERT使用的是Learned Positional Embedding(可学习的位置嵌入),先初始化位置编码,再放到预训练过程中,训练出每个位置的位置向量。
绝对位置编编码的问题:
-
文本较长位置序列没有边界,超出范围的序列无法处理
-
归一化同样也存在问题,不同长度的位置编码的步长是不同的,较短的文本和较长的文本,相邻两字,编码上量级不同,长文本的相对位置关系被稀释。
引入相对位置编码的需求:
- 能够体现词汇在不同位置的区别,同一个词汇在不同的位置的区别
- 能够体现词汇的先后次序,编码长度不依赖文本长度
- 值域范围限制
文中Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度必须和词向量的维度一致。
关于位置编码transform采用了正弦和余弦函数,公式如下:
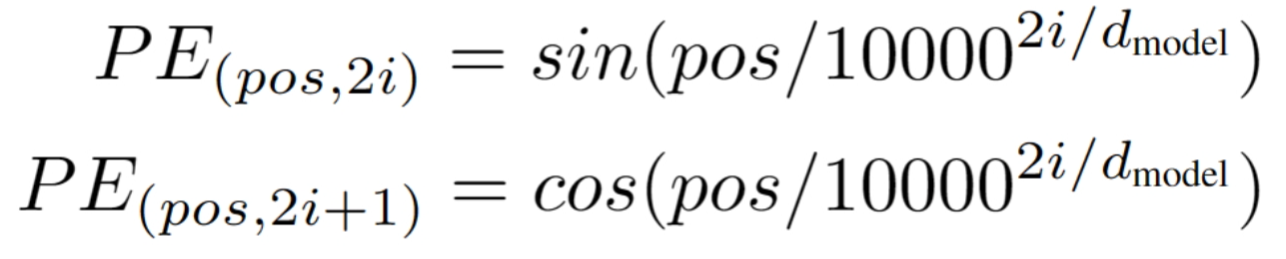
pos表示数据在序列中的绝对位置,pos=0,1,2...., dmodel表示词向量的维度,2i,2i+1表示奇偶性
详细关于位置编码的理解和解释: (https://juejin.cn/post/7241859817563258917)
模型输出
在Decoder之后添加一层 Linear, 一层Softmax构成输出
输出层 在Transformer中输出层由softmax和线性层组成。输出层可以针对不同下游任务进行更换和调整,以适应不同的任务需要。
自注意力机制
参考:https://juejin.cn/post/7241859817563389989
核心公式
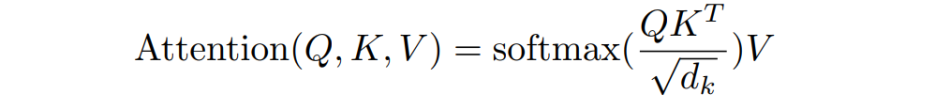
自注意力容许输入的每个输入的信息,给Attention的输入都来自同一个序列
对于每个token,先产生三个向量query,key,value
关于QKV的理解
Query,Key,Value的概念取自于信息检索系统,例如在搜索引擎搜索某个信息,在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key,然后根据Query和Key相似度得到匹配的内容Value
q 代表query,代表要查询的信息,后续会去和每一个k进行匹配
k 代表key, 代表索引,也就是被查询的向量, 后续会被每个q匹配
v 代表value,代码查询到的值,
后续q 和k 匹配的过程可以理解成计算两者的相关性,相关性越大对应v的权重也就越大
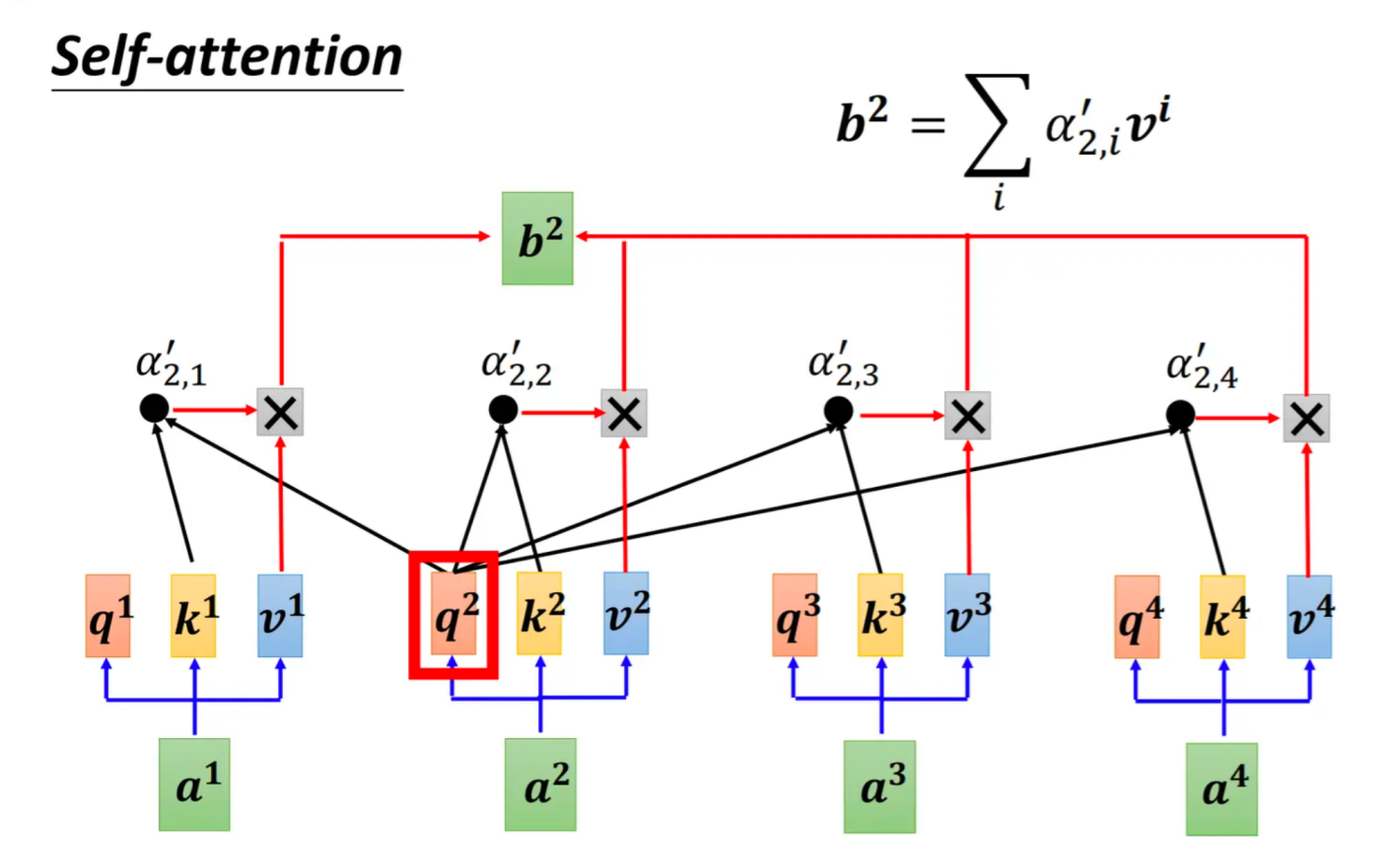
self-attention计算框架(图片来自李宏毅老师课堂ppt)
计算示意图,图的token a2为例
-
它产生一个query,每个query都去和别的token的key做 某种方式 的计算,得到的结果我们称为attention score(即为图中的 α)。则一共得到四个attention score。(attention score又可以被称为attention weight)。
-
将这四个score分别乘上每个token的value,我们会得到四个抽取信息完毕的向量。
-
将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
Q, K, V 及注意力计算
可参考:https://zhuanlan.zhihu.com/p/338817680
1 - 先生成三个向量query,key,value
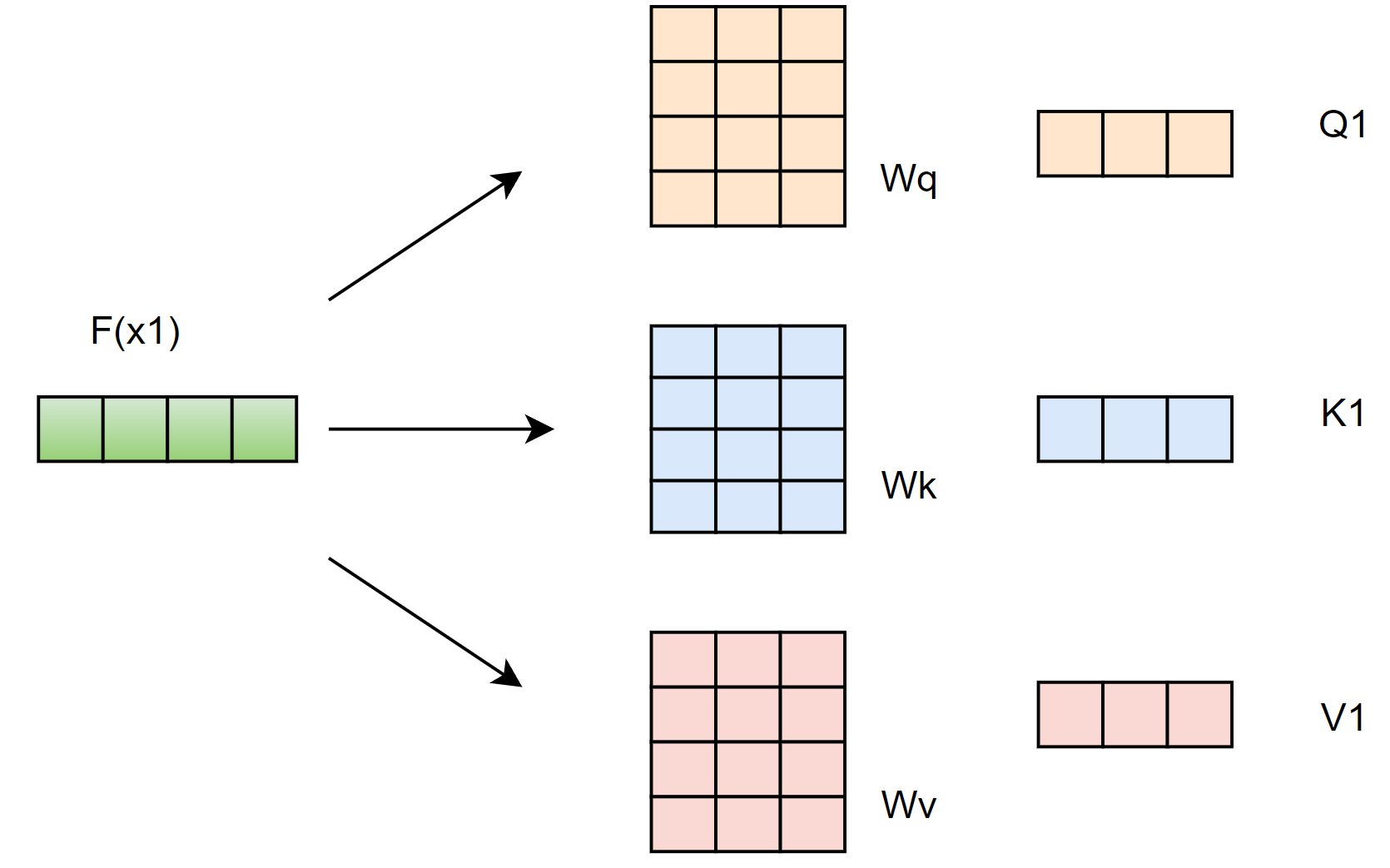
假设输入序列长度为2,\(x_1,x_2\) 然后 通过 input Embedding 映射成 \(a_1,a_2\) ,然后通过三个可学习的变换矩阵 $ W_q,W_k,W_v$ 得到相应的 $q1,k1,v^1, q2,k2,v^2 $
2 - 计算注意力得分, 计算Q与每个单词的K的点积,注意是当前Q与所有的k的运算
3 - 需要除以一个特定的值,让梯度更加稳定
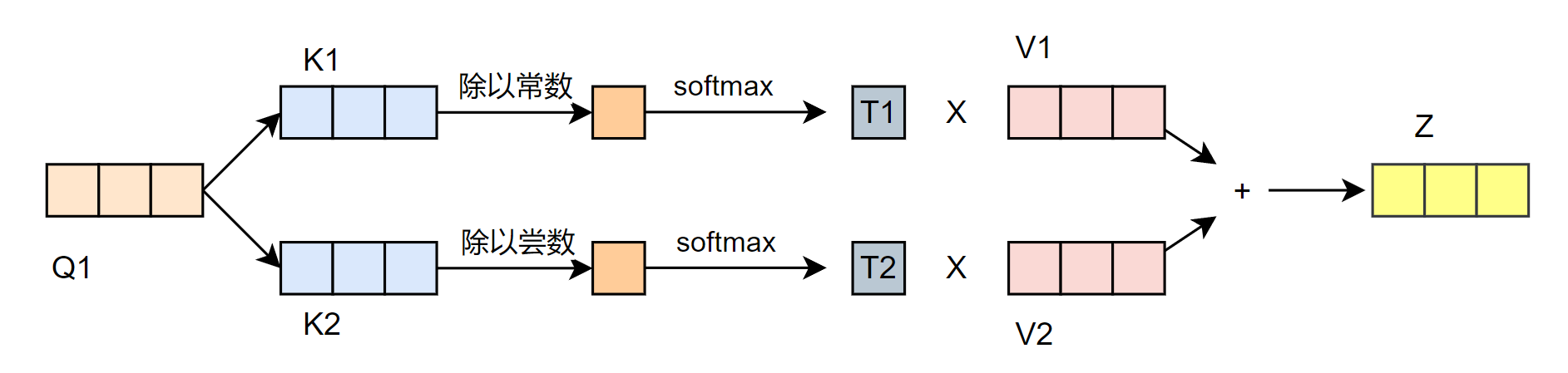
4 - 将结果进行Softmax标准化得到掩盖率(主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词),之后将 V 向量与标准化的结果相乘,得到新的 V
5 - 最后将各个 V 的结果相加
Transformer模型的核心是自注意力机制(Self-Attention Mechanism)
其作用是为每个输入序列中的每个位置分配一个权重,然后将这些加权的位置向量作为输出。
自注意力机制的计算过程包括三个步骤:
- 计算注意力权重:计算每个位置与其他位置之间的注意力权重,即每个位置对其他位置的重要性。
- 计算加权和: 将每个位置向量与注意力权重相乘,然后将它们相加,得到加权和向量。
- 线性变换: 对加权和向量进行线性变换,得到最终的输出向量。
通过不断堆叠多个自注意力层和前馈神经网络层,可以构建出Transformer模型。
多头注意力机制
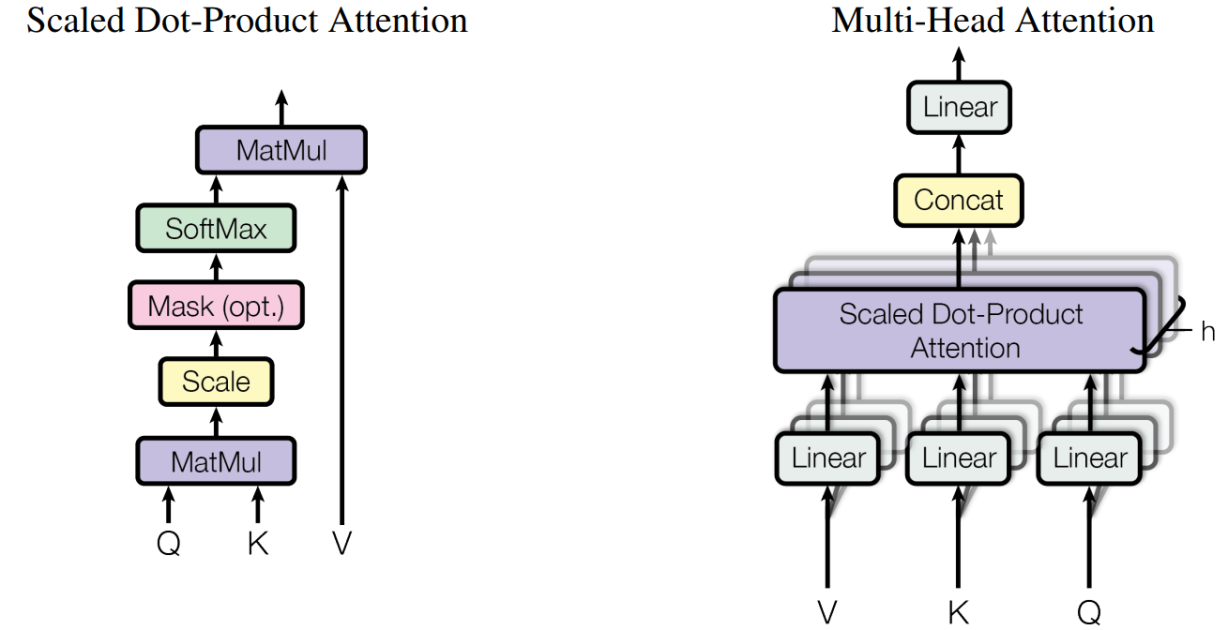
在Transformer中,注意力模块会并行地重复计算多次。其中的每一次计算被称为一个注意力头(Attention Head)。注意力模块将其Query、Key和Value参数分成N份,然后将每一份独立地通过一个单独的Attention Head进行处理。所有这些Attention计算结果最终被融合在一起,形成最终的注意力分数。这被称为多头注意力,使得Transformer能够更好地捕捉每个单词之间的多重关系和细微差别。
Multi-Head Attention相当于 h 个不同的self-attention的集成(ensemble),在这里我们以h=8 举例说明,如下图,
1、数据X分别输入到上述的8个self-attention 中,得到8个加权的特征矩阵$$Z_i,i={1,2,3,..,8}$$
2、将8个Z 按照列拼接Concat成一个大的特征矩阵
3、特征矩阵经过一层全连接层Linear输出得到Z
多头注意力机制作用
自注意力机制的缺陷就是:
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置
多头注意力机制融合了来自于相同的注意力池化产生的不同的知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
基于这种设计,每个头都可能会关注输入的不同部分。可以表示比简单加权平均值更复杂的函数。
多头attention 结构就是 QKV 首先进过一个线性层,然后输入到放缩点积attention, 要做h次,每一次算一个头,每次的参数不共享。
原论文原文中解释了多头的作用:将隐状态向量分成多个头,形成多个子语义空间,可以让模型去关注不同维度语义空间的信息(或者说让模型去关注不同方面的信息)。
总之就是:当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意⼒机制学习到不同的行为
参考链接:https://zhuanlan.zhihu.com/p/360932588
Feed Forward 层
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数。
参考资料
- https://zhuanlan.zhihu.com/p/82312421
- https://blog.csdn.net/qq_37541097/article/details/117691873
- https://blog.csdn.net/qq_52302919/article/details/122207924?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-122207924-blog-86533005.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3
- https://juejin.cn/post/7293151700869021715
- https://zhuanlan.zhihu.com/p/338817680 图解版