@
目录一、学习笔记
1.块设备 I/O 缓冲区
在第11章中,我们学习了读写普通文件的算法。这些算法依赖于两个关键操作,即 get_block 和 put_block,这两个操作将磁盘块读写到内存缓冲区中。由于与内存访问相比,磁盘I/O 速度较慢,所以不希望在每次执行读写文件操作时都执行磁盘 I/O。因此,大多数文件系统使用 I/O 缓冲来减少进出存储设备的物理 I/O 数量。合理设计的 I/O 缓冲方案可显著提高文件 I/O 效率并增加系统吞吐量。
I/O 缓冲的基本原理非常简单。文件系统使用一系列 I/O 缓冲区作为块设备的缓存内存。当进程试图读取(dev,blk)标识的磁盘块时,它首先在缓冲区缓存中搜索分配给磁盘块的缓冲区。如果该缓冲区存在并且包含有效数据,那么它只需从缓冲区中读取数据,而无须再次 从磁盘中读取数据块=如果该缓冲区不存在,它会为磁盘块分配一个缓冲区,将数据从磁盘读入缓冲区,然后从缓冲区读取数据,当某个块被读入时,该缓冲区将被保存在缓冲区缓存中,以供任意进程对同一个块的下一次读/写请求使用:同样.当进程写入磁盘块时,它首先会获取一个分配给该块的缓冲区。然后,它将数据写入缓冲区,将缓冲区标记为脏,以延退写入,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效的数据,因此可以使用它来满足对同一块的后续读/写清求,而不会引起实际磁盘 I/O。脏缓冲区只有在被重新分配到不同的块时才会写入磁盘。
在讨论缓冲区管理算法之前.我们先来介绍以下术语。在 read_flle/write_file 中,我们 假设它们从内存中的一个专用缓冲区进行读/写。对于 I/O 缓冲,将从缓冲区缓存中动态分配缓冲区。假设 BUFFER 是缓冲区(见下文定义)的结构类型,而且 getblk(dev, blk) 从缓冲区缓存中分配一个指定给(dev, blk)的缓冲区。定义一个 bread(dev, blk) 函数,它会返回一个包含有效数据的缓冲区(指针)。
从缓冲区读取数据后,进程通过 brelse(bp)将缓冲区释放回缓存。同理,定义一个 write_block(dev,blk,data)函数,如:
BUFFER *break(dev,blk)
{
BUFFER *bp=getblk(dev,blk);
if(bp data valid)
return bp;
bp->opcode=READ;
start_io(bp);
wait for I/O completion;
return bp;
}
其中 bwrite(bp)表示同步写入,dwrite(bp)表示延迟写入,如下文所示。
bwrite(BUFFER *bp){
bp->opcode=WRITE;
start_io(bp);
wait for I/O completion;
brelse(bp); // release bp
}
dwrite(BUFFER *bp){
mark bp dirty for delay_write;
brelse(bp); // release bp
}
同步写入操作等待写操作完成。它用于顺序块或可移动块设备,如USB驱动器。对于随机访问设备,例如硬盘,所有的写操作都是延迟写操作。在延迟写操作中,dwrite(bp) 将缓冲区标记为脏,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效数据,因此可用来满足同一个块的后续读/写请求。这不仅减少了物理磁盘 I/O 的数量,而且提高了缓冲区缓存的效果。脏缓冲区只有在被重新分配到不同的磁盘块时才会被写入磁盘,此时缓冲区将被以下代码写入:
awrite(BUFFER *bp)
{
bp->opcode = ASYNC; //for ASYNC write
start_io(bp);
}
awrite()会调用 start_io() 在缓冲区开始 I/O 操作,但是不会等待操作完成。当异步 (ASYNC) 写操作完成后,磁盘中断处理程序将释放缓冲区。
物理块设备I/O :每个设备都有一个 I/O 队列,其中包含等待 I/O 操作的缓冲区。缓冲区上的start_io() 操作如下:
start_io(BUFFER *bp)
{
enter bp into device I/O queue;
if (bp is first buffer in I/O queue)
issue I/O command for bp to device;
}
当 I/O 操作完成后,设备中断处理程序会完成当前缓冲区上的 I/O 操作,并启动 I/O 队列中的下一个缓冲区的 I/O (如果队列不为空)。设备中断处理程序的算法如下:
IntermiptHandler ()
{
bp = dequeue(device I/O queue); // bp = remove head of I/O queue
(bp->opcode == ASYNC)? brelse(bp) : unblock process on bp;
if (1 empty(device I/O queue))
issue I/O command for first bp in I/O queue;
}
当 I/O 操作完成后,设备中断处理程序会完成当前缓冲区上的 I/O 操作,并启动 I/O 队列中的下一个缓冲区的 I/O (如果队列不为空)。设备中断处理程序的算法如下:
IntermiptHandler ()
{
bp = dequeue(device I/O queue); // bp = remove head of I/O queue
(bp->opcode == ASYNC)? brelse(bp) : unblock process on bp;
if (!empty(device I/O queue))
issue I/O command for first bp in I/O queue;
2.Unix I/O 缓冲区管理算法
Unix 缓冲区管理子系统由以下几部分组成。
(1)I/O 缓冲区:内核中的一系列NBUF缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。
缓冲区结构体由两部分组成:用于缓冲区管理的缓冲头部分和用于数据块的数据部分。 为了保护内核内存,状态字段可以定义为一个位向量,其中每个位表示一个唯一的状态条 件。为了便于讨论,这里将它们定义为int。
(2)设备表:每个块设备用一个设备表结构表示。
每个设备表都有一个 dev_list,包含当前分配给该设备的 I/O 缓冲区,还有一个io_queue,包含设备上等待 I/O 操作的缓冲区。I/O 队列的组织方式应确保最佳 I/O 操作。例如, 它可以实现各种磁盘调度算法,如电梯算法或线性扫描算法等。为了简单起见,Unix 使用 FIFO I/O 队列。
(3)缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和 I/O队列均为空。
(4)缓冲区列表:当缓冲区分配给(dev, blk)时,它会被插入设备表的dev_list中。如果缓冲区当前正在使用,则会将其标记为 BUSY(繁忙)并从空闲列表中删除。
(5)Unix getblk/brelse 算法
下面是关于Unix算法的一些具体说明。
1. 数据一致性:为了确保数据一致性,getblk一定不能给同一个(dev, blk)分配多个缓冲区这可以通过让进程从休眠状态唤醒后再次执行“重试循环”来实现。读者可以验证分配的每个缓冲区都是唯一的一其次,脏缓冲区在重新分配之前被写出来,这保证了数据的一致性。
2. 缓存效果:缓存效果可通过以下方法实现 释放的緩冲区保留在设备列表中,以便可能重用,标记为延迟写入的緩冲区不会立即产生I/O,并且可以重用。缓冲区会被释放到空闲列表的末尾,但分配是从空闲列表的前面开始的,这是基于LRU (最近最少使用)原则,它有助于延长所分配缓冲区的使用期,从而提高它们的缓存效果,
3. 临界区:设备中断处理程序可操作缓冲区列表,例如从设备表的I/O队列中删除 bp,更改其状态并调用brelse(bp)。所以,在getblk和brelse中,设备中断在这些临界区中会被屏蔽。这些都是隐含的,但没有在算法中表现出来
Unix算法的缺点
虽然Unix算法非常简单和简洁.但它也有以下缺点。
(1) 效率低下:该算法依赖于重试循环,例如,释放缓冲区可能会唤醒两组进程:需要 释放的缓冲区的进程,以及只需要空闲缓冲区的进程。由于只有一个进程可以获取释放的缓 冲区,所以,其他所有被唤醒的进程必须重新进入休眠状态。从休眠状态唤醒后,每个被唤醒的进程必须从头开始重新执行算法,因为所需的缓冲区可能已经存在。这会导致过多的进程切换。
(2) 缓存效果不可预知:在Unix算法中,每个释放的缓冲区都可被获取。如果缓冲区由需要空闲缓冲区的进程获取,那么将会重新分配缓冲区,即使有些进程仍然需要当前的缓冲区。
(3) 可能会出现饥饿:Unix算法基于“自由经济”原则,即每个进程都有尝试的机会,但不能保证成功,因此,可能会出现进程饥饿。
(4) 该算法使用只适用于单处理器系统的休眠/唤醒操作。
3.新的 I/O 缓冲区管理算法
在本节中,我们将展示一种用于 I/O 缓冲区管理的新算法。我们将在信号址上使用 p/v 来实现进程同步,而不是使用休眠/唤醒,与休眠/唤醒相比,信号量的主要优点是:
(1) 计数信号量可用来表示可用资源的数量,例如:空闲缓冲区的数量。
(2) 当多个进程等待一个资源时,信号量上的 V 操作只会释放一个等待进程,该进程 不必重试,因为它保证拥有资源。
这些信号量属性可用于设计更有效的缓冲区管理算法我们正式对这个问题做以下详细说明。
使用信号量的缓冲区管理算法
假设有一个单处理器内核(一次运行一个进程)。使用计数信号量上的 P/V 来设计满足 以下要求的新的缓冲区管理算法:
(1) 保证数据一致性。
(2) 良好的缓存效果。
(3) 高效率:没有重试循环,没有不必要的进程“唤醒”。
(4) 无死锁和饥饿。
注意,仅通过信号量上的 P/V 来替换 Unix 算法中的休眠/唤醒并不可取,因为这样会 保留所有的重试循环。我们必须重新设计算法来满足所有上述要求,并证明新算法的确优于 Unix算法。首先,我们定义以下信号量。
BUFFER buf[NBUF]; // NBUF I/O buffers
SEMAPHORE free = NBUF; // counting semaphore for FREE buffers
SEMAPHORE buf[i].sem = 1; // each buffer has a lock sem=l;
为了简化符号,我们将用缓冲区本身来表示每个缓冲区的信号量。与 Unix 算法一样,最开始,所有缓冲区都在空闲列表中,所有设备列表和 I/O 队列均为空。下面展示一个使用信号量的简单缓冲区管理算法。
4.PV 算法
(1) 缓冲区唯一性: 在 getblk()中,如果有空闲缓冲区,则进程不会在(1)处等待,而是会搜索 dev_listc如果所需的缓冲区已经存在,则进程不会重新创建同一个缓冲区。如果所需的缓冲区不存在,则进程会使用一个空闲缓冲区来创建所需的缓冲区。而这个空闲缓冲区保证是存在的,如果没有空闲缓冲区,则需要同一个缓冲区的几个进程可能在(1)处阻塞。当在(10)处释放出一个空闲缓冲区时,它仅释放一个进程来创建所需的缓冲区。一旦创建了缓冲区,它就会存在于 dev_list 中,这将防止其他进程再次创建同一个缓冲区。因此,分配的每个缓冲区都是唯一的。
(2) 无重试循环: 进程重新执行while(1)循环的唯一位置是在(6)处,但这不是重试,因为进程正在不断地执行。
(3) 无不必要唤醒: 在getblk()中,进程可以在(1)处等待空闲缓冲区,也可以在(4)处等待所需的缓冲区,在任意一种情况下,在有缓冲区之前,都不会唤醒进程重新运行。此外,当在(9)处有一个脏缓冲区即将被释放并且在(1)处有多个进程等待空闲缓冲区时,该缓冲区不会被释放而是直接被写入。这样可以避免不必要的进程唤醒。
(4) 缓存效果: 在Unix算法中,每个释放的缓冲区都可被获取。而在新的算法中,始终保留含等待程序的缓冲区以供重用一只有缓冲区不含等待程序时,才会被释放为空闲。这样可以提高缓冲区的缓存效果。
(5) 无死锁和饥饿: 在getblk()中、信号量锁定顺序始终是单向的,即 P(free),然后是 P(bp),但决不会反过来,因此不会发生死锁。如果没有空闲缓冲区,所有清求进程都将在(1)处阻塞,这意味着,虽然有进程在等待空闲缓冲区,但所有正在使用的缓冲区都不能接纳任何新用户。这保证了繁忙缓冲区最终将被释放为空闲缓冲区。因此,不会发生空闲缓冲区饥饿的情况。
5.编程项目
(1)系统组织
Box#1 : 用户界面 这是模拟系统的用户界面部分它会提示输入命令、显示命令执行、显示系统状态和执行结果等在开发过程中,读者可以手动输入命令来执行任务。在最后测试过程中,任务应该有自己的输入命令序列。例如,各任务可以使取包含命令的输入文件。完成任务切换之后,将从另一个文件读取任务输入。
(2)多任务处理系统
Box#2 这是多任务处理系统的 CPU 端,模拟单处理器(单CPU)文件系统的内核模式。实际上,它与第4章中所述的用于用户级线程的多任务系统相同,只是以下修改除外。 当系统启动时,它会创建并运行一个优先级最低的主任务,但它会创建 ntask 工作任务,所有任务的优先级都是1,并将它们输入readyQueue。然后,主任务执行以下代码,该代码将任务切换为从readyQueue 运行工作任务。
由于主任务的优先级最低,所以如果没有可运行的任务或所有任务都已结束,它将再次运行。在后一种情况下,主任务执行 end_task(),在其中收集并显示模拟结果,然后终止,从而结束模拟运行。
所有工作任务都执行同一个 body()函数,其中每个任务从输入文件中读取命令来执行读或写磁盘块操作,直到命令文件结束。
define CMDLEN 10
int cmdfile[NTASK]; // opened command file descriptors
int task = ntask; // number of active tasks
int body()
{
int dev, blk;
char opcode, cmd[CMDLEN];
whiled(1){
if (read(cmdfile[running->pid], cmd, CMDLEN)0){
running->status = DEAD; // task ends
task--; // dec task count by 1
tswtich();
}
sscanf (cmd,"%c%4d%5d", &opcode, &dev, &blk);
if (opcode'r') // read (dev, blk)
readBlk(dev, blk);
if (opcode=='w')
writeBlk(dev, blk); // write (dev, blk)
各任务的命令由rand()函数取模极限值来随机生成。每个命令都是三重形式
[r XXX yyyy] or [w xxx yyyy] , where xxx=dev, yyyy=blkno;
对于[r dev blk]命令,任务调用
BUFFER *bread(dev, blk)
来获取包含有效数据的缓冲区(指针)。从缓冲区读取数据后,它会将缓冲区释放回缓冲区缓存以便重用。在bread()中,任务可以等待getblk()中的缓冲区,或者等待缓冲区数据生效。如果是这样,它会休眠(在Unix算法中)或者被阻塞(在PV算法中),将任务切换到运行readyQueue中的下一个任务。
对于[w dev blk]命令,任务试图获取用于(dev, blk)的缓冲区。如果必须要等待 getblk()中的缓冲区,它将会休眠或被阻塞,并切换任务以运行下一个任务。在将数据写入缓冲区之后,它会将延迟写入的缓冲区标记为脏,并将该缓冲区释放到缓冲区缓存中。然后,它会试图执行下一个命令等。
(3)缓冲区管理器
缓冲区管理器实现各缓冲区管理函数,包括:
BUFFER *bread(dev, blk)
dwrite(BUFFER *bp)
awrite(BUFFER *bp)
BUFFER *getblk(dev, blk)
brelse(BUFFER *bp)
这些函数可能会调用磁盘驱动程序来发出物理磁盘 I/O。
(4)磁盘驱动程序
磁盘驱动程序由两部分组成。
(1) start_io():维护设备I/O队列,并对I/O队列中的缓冲区执行I/O操作。
(2) 中断处理程序:在每次I/O操作结束时,磁盘控制器会中断CPU。当接收到中断后,中断处理程序首先从IntStatus中读取中断状态,IntStatus包含
[dev | R|W I StatusCode]
|< e.g. 10 chars >|
(5)磁盘控制器
(3) Box#3:这是磁盘控制器,它是主进程的一个子进程。因此,它与CPU端独立运行,除了它们之间的通信通道,通信通道是CPU和磁盘控制器之间的接口。通信通道由主进程和子进程之间的管道实现。
命令:从CPU到磁盘控制器的I/O命令。
DataOut:在写操作中从CPU到磁盘控制器的数据输出。
Dataln:在读操作中从磁盘控制器到CPU的数据。
IntStatus:从磁盘控制器到CPU的中断状态。
IntAck:从CPU到磁盘控制器的中断确认。
(6)磁盘中断
从磁盘控制器到CPU的中断由SIGUSR1 (#10)信号实现。在每次I/O操作结束时, 磁盘控制器会发出 kill(ppid, SIGUSR1)系统调用,向父进程发送SIGUSR1信号,充当虚拟 CPU 中断。通常,虚拟 CPU 会在临界区屏蔽出/入磁盘中断(信号)。为防止竞态条件,磁盘控制器必须要从CPU接收一个中断确认,才能再次中断。
(7)虚拟磁盘
(4)Box#4 : 这些是 Linux 文件模拟的虚拟磁盘。使用 Linux 系统调用 lseek()、read()和 write(),我们可以支持虚拟磁盘上的任何块I/O操作。为了简单起见,将磁盘块大小设置 为16字节。由于数据内容无关紧要,所以可以将它们设置为16个字符的固定序列。
二、苏格拉底挑战
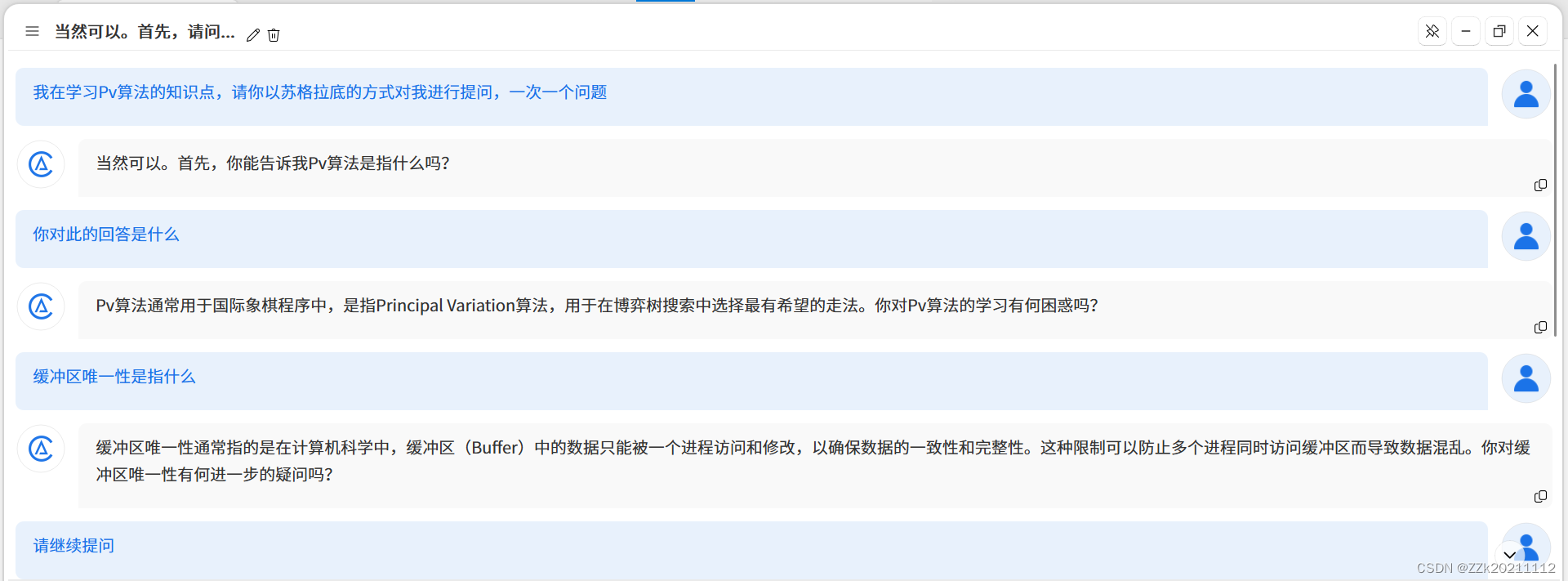
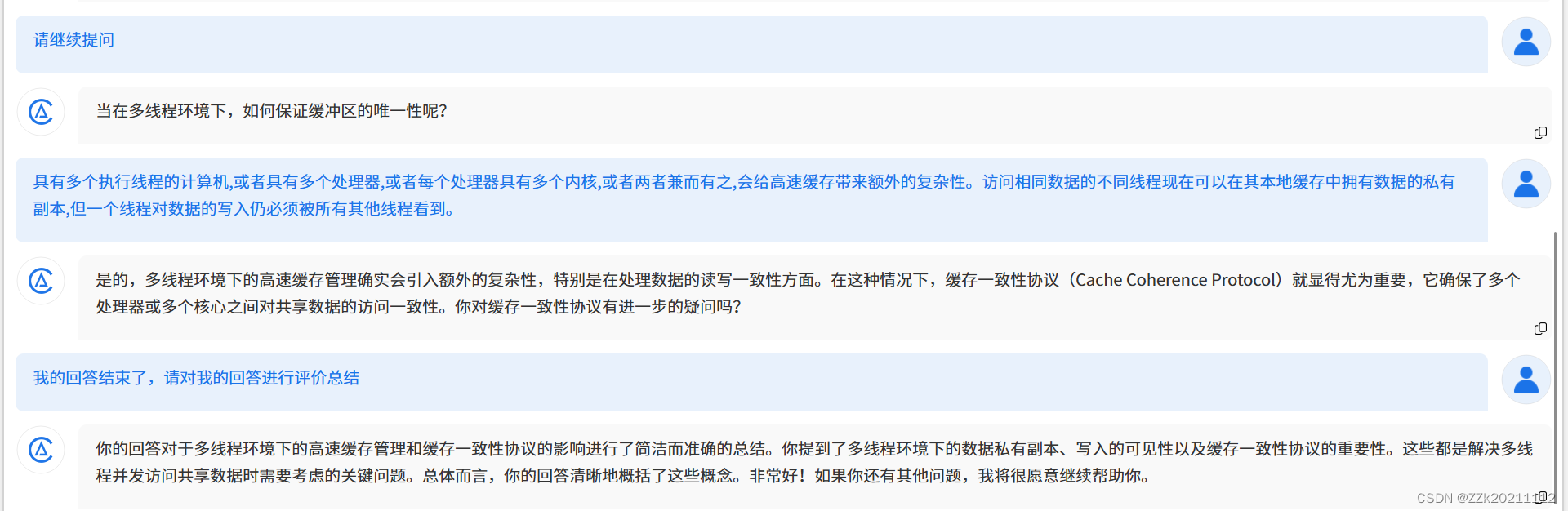
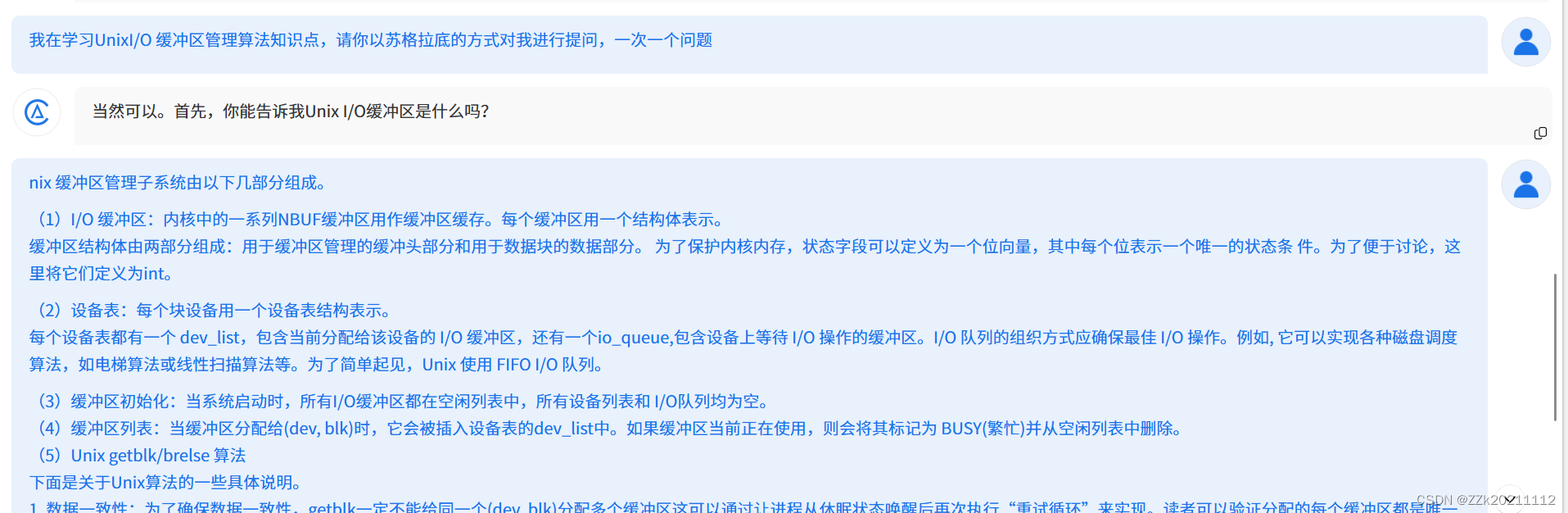

三、实践过程及截图
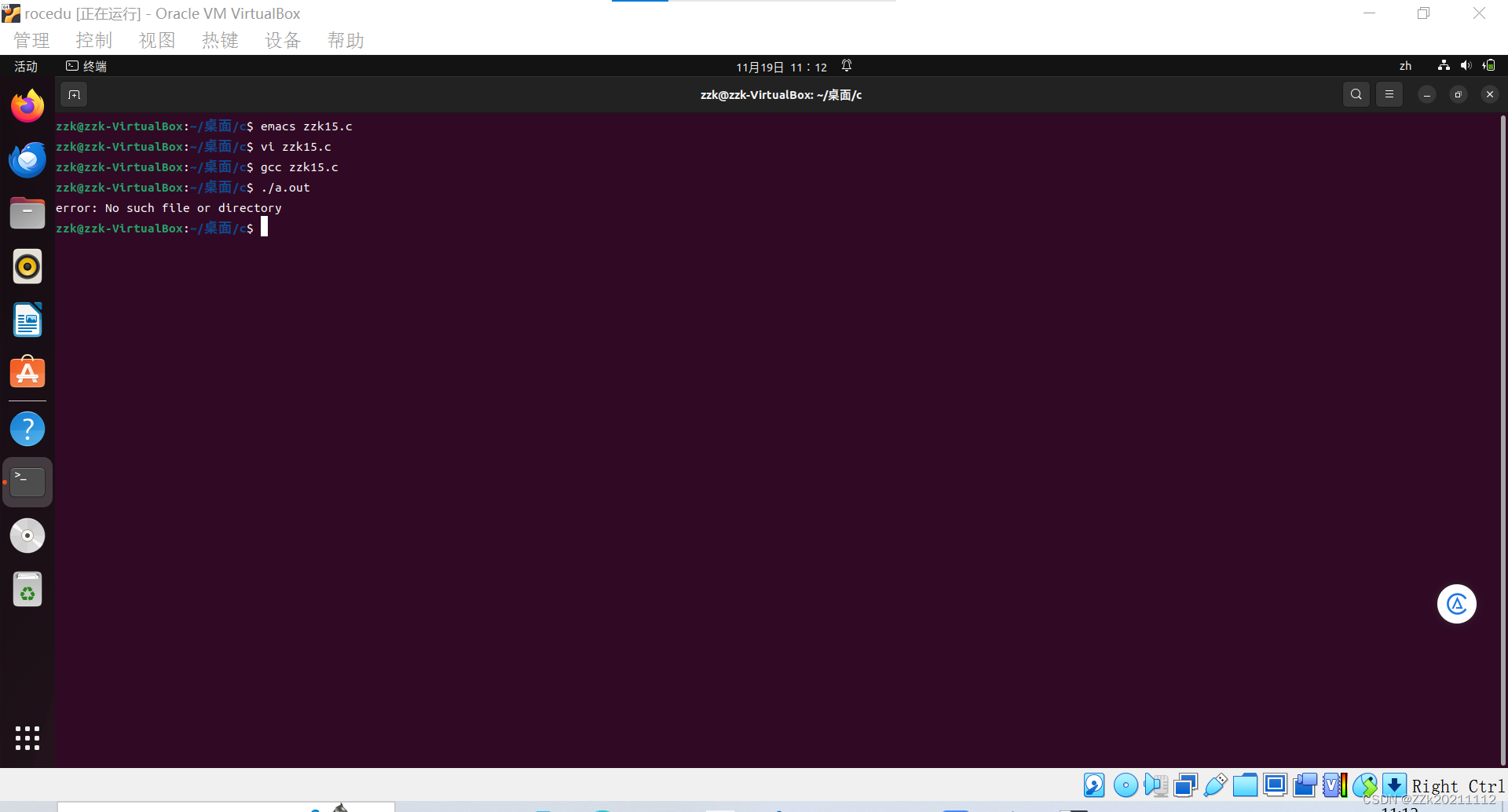
实践代码:
include <stdio.h>
include <errno.h>
include <stdlib.h>
int main()
{
FILE* fd;
fd = fopen("20191322.txt","r");
if(NULL==fd)
{
perror("error");
return -1;
}
return 0;
}