目录
使用平台:AutoDL
实例配置:
使用模型:stable diffusion+lora/ControlNet
阅读文献:
使用网站:
摄影图查找:
提示词查找:
- 艺术家风格:https://lib.kalos.art/
- 针对ai绘图工具的搜索引擎:lexica.art
- ai绘画提示词网站:https://prompthero.com/search
- ai提示词网站(要科技):https://www.prompthunt.com/
controlnetv1.1模型下载:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
-
canny模型(边缘检测):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_canny.pth
-
scribble模型(应用黑白稿):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_scribble.pth
-
inpaint模型(局部重绘):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_inpaint.pth
-
lineart模型(提取线稿重新上色):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_lineart.pth
-
normalbae模型(根据图片生成法线贴图):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_normalbae.pth
-
depth模型(深度检测):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11f1p_sd15_depth.pth
-
softedge模型(边缘检测,适用重新着色以及风格化):https://huggingface.co/lllyasviel/ControlNet-v1-1/resolve/main/control_v11p_sd15_softedge.pth
stable diffusion不同采样方式的区别
https://zhuanlan.zhihu.com/p/612572004
https://zhuanlan.zhihu.com/p/621083328
- 如果只是想得到一些较为简单的结果,选用欧拉(Eular)或者Heun,并可适当减少Heun的步骤数以减少时间
- 对于侧重于速度、融合、新颖且质量不错的结果,建议选择:
-
DPM++ 2M Karras, Step Range:20-30
-
UniPc, Step Range: 20-30
-
期望得到高质量的图像,且不关心图像是否收敛:
-
DPM ++ SDE Karras, Step Range:8-12
-
DDIM, Step Range:10-15
-
如果期望得到稳定、可重现的图像,避免采用任何祖先采样器
Euler
基于Karras论文,在K-diffusion实现,20-30steps就能生成效果不错的图片,采样器设置页面中的 sigma noise,sigma tmin和sigma churn这三个属性会影响到它(后面会提这三个参数的作用);
Euler a
使用了祖先采样(Ancestral sampling)的Euler方法,受采样器设置中的eta参数影响(后面详细介绍eta);
LMS
线性多步调度器(Linear multistep scheduler)源于K-diffusion的项目实现;
heun
基于Karras论文,在K-diffusion实现,受采样器设置页面中的 sigma参数影响;
DPM2
这个是Katherine Crowson在K-diffusion项目中自创的,灵感来源Karras论文中的DPM-Solver-2和算法2,受采样器设置页面中的 sigma参数影响;
DPM2 a
使用了祖先采样(Ancestral sampling)的DPM2方法,受采样器设置中的ETA参数影响;
DPM++ 2S a
基于Cheng Lu等人的论文(改进后,后面又发表了一篇),在K-diffusion实现的2阶单步并使用了祖先采样(Ancestral sampling)的方法,受采样器设置中的eta参数影响;Cheng Lu的github中也提供已经实现的代码,并且可以自定义,1、2、3阶,和单步多步的选择,webui使用的是K-diffusion中已经固定好的版本。对细节感兴趣的小伙伴可以参考Cheng Lu的github和原论文。
DPM++ 2M
基于Cheng Lu等人的论文(改进后的版本),在K-diffusion实现的2阶多步采样方法,在Hagging face中Diffusers中被称作已知最强调度器,在速度和质量的平衡最好。这个代表M的多步比上面的S单步在采样时会参考更多步,而非当前步,所以能提供更好的质量。但也更复杂。
DPM++ SDE
基于Cheng Lu等人的论文的,DPM++的SDE版本,即随机微分方程(stochastic differential equations),而DPM++原本是ODE的求解器即常微分方程(ordinary differential equations),在K-diffusion实现的版本,代码中调用了祖先采样(Ancestral sampling)方法,所以受采样器设置中的ETA参数影响;
DPM fast
基于Cheng Lu等人的论文,在K-diffusion实现的固定步长采样方法,用于steps小于20的情况,受采样器设置中的ETA参数影响;
DPM adaptive
基于Cheng Lu等人的论文,在K-diffusion实现的自适应步长采样方法,DPM-Solver-12 和 23,受采样器设置中的ETA参数影响;
Karras后缀
LMS Karras 基于Karras论文,运用了相关Karras的noise schedule的方法,可以算作是LMS使用Karras noise schedule的版本;
DPM2 Karras,DPM2 a Karras,DPM++ 2S a Karras,DPM++ 2M Karras,DPM++ SDE Karras这些含有Karras名字的采样方法和上面LMS Karras意思相同,都是相当于使用Karras noise schedule的版本;
DDIM
“官方采样器”随latent diffusion的最初repository一起出现, 基于Jiaming Song等人的论文,也是目前最容易被当作对比对象的采样方法,它在采样器设置界面有自己的ETA;
PLMS
同样是元老,随latent diffusion的最初repository一起出现;
UniPC
最新被添加到webui中的采样器,基于Wenliang Zhao等人的论文[7],应该是目前最快最新的采样方法,10步就可以生成高质量结果;在采样器设置界面可以自定义的参数目前也比较多,因为只针对它,所以直接展开聊一下怎么设置,先参考下图
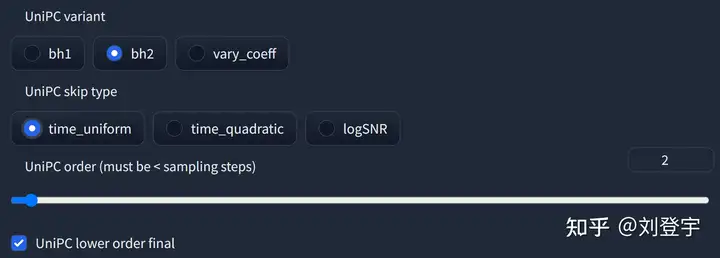
UniPC variant
bh1和bh2和vary_coeff是三种变体
hugging face的团队在diffuser中给出了他们的建议:bh1适合在无条件(没指挥,无引导)且步数小于10情况下使用,其余情况全部使用bh2。
至于vary_coeff这个,作者在论文中实验对比了在“无条件”的和bh1和bh2的区别,即bh1在5,6步表现最好,vary_coeff在7,8或9表现最好,10步以上还是bh2。
由于我们在webui的使用场景使用提示词就是“有条件”了,所以看上去bh2更合适,除非你热衷于10步以内生成图片,但webui的github上有人反应vary_coeff生成的图片背景细节更加丰富[8]。我个人使用下来看,区别不算大,可以自己对比。
一句话总结:懒得对比的话就默认bh2。
UniPC skip type
如果你生成的图片是512 x 512或者更大的话,选uniform。它更适合高分辨率图(512目前相对算高分别率)logSNR适合低分别率
下图为logSNR(注意看某些步数的图片异常情况)

logSNR BH2
logSNR在512 x 512下会出现一些奇怪的细节(模型SD1.5),quadratic稍微好一些(就不放图片了)
下图是uniform,请注意和上面相比细节的合理度。

uniform BH2
结论:512 x 512细节更合理, 推荐uniform
这个order最后两项都有提,作者在原论文也有对比,diffuser也有推荐:有条件(有引导)用2阶,无条件(无引导)用3阶,并且在在推理步数小于15时,打开lower order final,即在最后step使用低阶采样。
请看下图,在不开lower order final的情况下
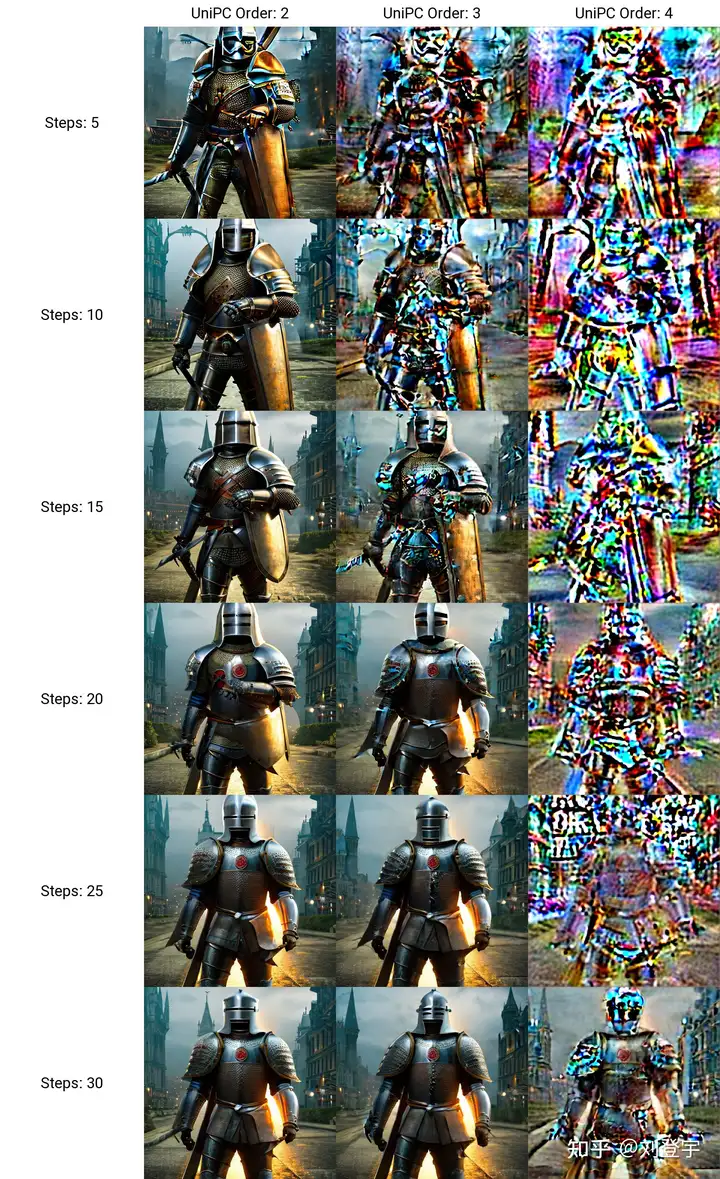
BH2,time_uniform
上面在UniPC skip type的对比环节都是开lower order final的情况下生成的。
结论:开lower order final,别犹豫,order我个人推荐2阶。
eta参数
综合所有采样器,上面提到了eta
eta (noise multiplier) for DDIM只作用DDIM,不为零时,DDIM在推理时图像会一直改变,生成的图像不会最终收敛;
eta (noise multiplier) for ancestral samplers作用于名字后缀带a和SDE的所有采样器,不为零时,生成的图像也不会收敛;
Eta noise seed delta也是seed值,在eta不为零时起到固定初始值,这样你就可以使用相同值还原某些其它人使用了对应eta值的图片。
请看下图(汇集了所有受eta参数影响的采样方法),在所有eta设定为1时的结果,盔甲的细节结构即使在高步数时也会改变

ETA for DDIM和ETA for a都为1

ETA for DDIM和ETA for a都为0
eta为0,除了Euler a和DDIM还会有少量的变化外,其余带a的采样方法,带SDE的,以及DPM fast和DPM adaptive都会收敛稳定(上面的两张图片,除eta值,其余设置完全一样。)
再看下带a(祖先采样)的和原本的采样方式在不同的eta下的对比结果如下图:
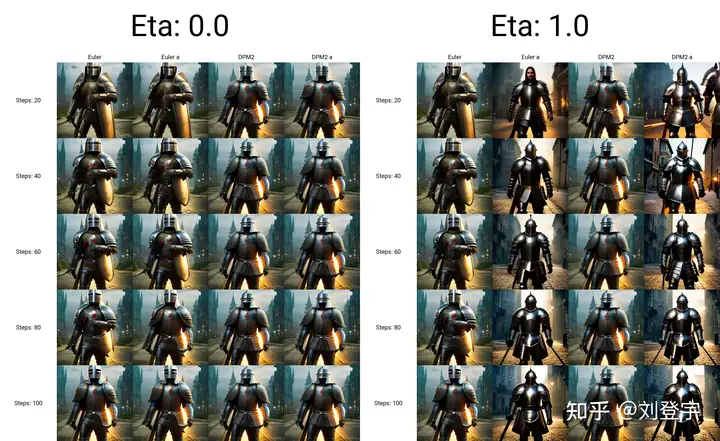
在eta为0时,带a和原始的采样方法生成的图片基本上相同了。
小结:使用上述图中采样方法时记得注意相应的eta,不然会失去所谓的的“多样性”和“想象力”
sigma参数
sigma包含:sigma churn,sigma tmin,sigma noise,仅对euler, heun和dpm2这三个采样器有效
sigma churn:决定sigma noise值如何被使用,如果churn值为0,即使noise值不为0,也没有任何效果。
sigma tmin:决定最小值范围的限制,可以为0
sigma noise:噪声本身的数值大小(注意,churn>0时,噪声值本身才有意义)
图片对比(图片中带a的采样方法不受sigma影响,所以作为对照组一同出现)
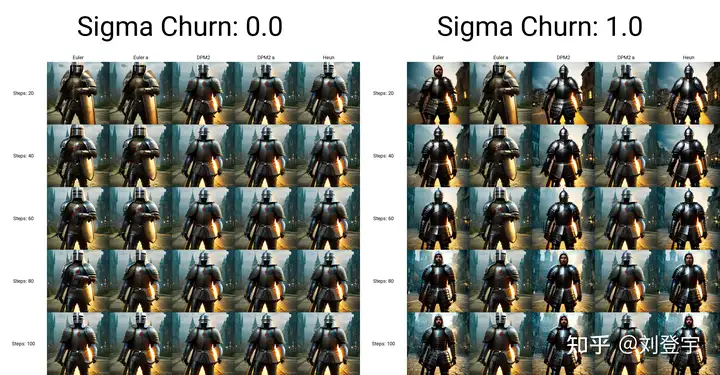
sigma值也是“多样性”或者“想象力”的相关数值。
采样方法小结
1.建议根据自己使用的checkpoint使用脚本跑网格图(用自己关心的参数)然后选择自己想要的结果。
2.懒得对比:请使用DPM++ 2M或DPM++ 2M Karras或UniPC,想要点惊喜和变化,Euler a、DPM++ SDE、DPM++ SDE Karras、DPM2 a Karras(注意调正对应eta值)
3.eta和sigma都是多样性相关的,但是它们的多样性来自步数的变化,追求更大多样性的话应该关注seed的变化,这两项参数应该是在图片框架被选定后,再在此基础上做微调时使用的参数。
超分辨率Hires.fix和Upscaler
或者说图片放大器,在放大分辨率的同时根据AI模型添加相应的细节
在txt2img文生图中位于Hires. fix选项中的Upscaler
Latent系列的放大器工作在潜空间(latent space)上文介绍基础工作原理时提到的那个降维空间。在Denoising强度低于0.5时会出现图片模糊等问题,高于0.5会显著解决问题,但是会改变原图更多的内容,失去之前的面貌。Denoising强度0.5以下请使用其它放大器。
其它非Latent系列的放大不工作在潜空间,所以就比较灵活了,txt2img和img2img都能使用。
Lanczos,Nearest 是比较老的传统算法,不是AI模型,不推荐使用。(接触过计算机图形学的话肯定知道这两个算法,经典算法肯定对后人的工作有启发作用。没有不尊重的意思)参考下图[12]

ESRGAN系列[13]
ESRGAN_4x适用于照片写实类(可能出现细节过于锐利的效果,但有些人喜欢这样的风格),R-ESRGAN 4x+(全能型),R-ESRGAN 4x+ Anime6B(适用于二次元),R-ESRGAN-General-WDN-4xV3(适用于厚涂插画)
SwinIR_4x[14]
SwinIR_4x需要表现光影的厚涂插画表现优于照片和二次元的图片放大,但逊于R-ESRGAN-General-WDN-4xV3
LDSR
LDSR照片写实类图片表现很好,插画和二次元图片不行,而且体积很大,速度很慢(好奇的话,可以尝试)
超分模型小结:
上面的这些超分模型并不是固定用于某一类风格的图片放大,你可以自行尝试。(个别除外,例如Anime6B)
懒得尝试可以按照这个来:照片类ESRGAN_4x,插画风R-ESRGAN-General-WDN-4xV3,二次元R-ESRGAN 4x+ Anime6B
更懒版本:照片类ESRGAN_4x,其余R-ESRGAN 4x+
不想动版本:R-ESRGAN 4x+
seed和CFG Scale
这两个设置使用过stable diffuion Webui应该都知道功能,暂时不展开。
Clip skip参数
这个Clip skip设置被很多人说是玄学,记得上面聊三大组成部分的时候提到的Clip吗?调大Clip skip的数值会让Clip更早结束文本嵌入,让prompt提示的指挥力度被削弱,听上去是不是和CFG Scale唱反调?可能有人会问那都用CFG Scale不就好了吗?确实,平时你可以放着默认的设置不去管他,但是有些模型在训练时会调整这个Clip skip对层的影响深度,所以在使用的时候也需要相应的调整,比如设置为2,大多数我们口中的自己训练SD模型,其实都是对原本模型的微调,而实现微调的原理就是微调三大组件中的Clip或者调整Clip加U-net,说到本地模型训练,今后有时间再写吧。
标签:采样,区别,采样器,Karras,eta,DPM,sigma,SD From: https://www.cnblogs.com/kitorio/p/17898118.html