CSPNet跨阶段局部网络方法
目录论文地址:https://arxiv.org/pdf/1911.11929.pdf
背景和问题
- 随着卷积神经网络结构变得更深更宽,扩展神经网络的体系结构通常会带来更多的计算
- 轻量级网络,
MobileNetv1/v2/v3和ShuffleNetv1/v2采用了深度可分离卷积 技术与工业芯片设计不兼容
网络优化中的「重复梯度信息」。CSPNet 通过整合网络阶段开始和结束的特征图来注重梯度的可变性。
CSPNet不仅仅是一个网络,更是一个处理思想,可以和ResNet、ResNext、DenseNet、EfficientNet等网络结合,使得上诉网络可以部署在 cpu 和移动 gpu 上,而不会牺牲性能。
主要解决问题
- 增强 CNN 的学习能力,能够在轻量化的同时保持准确性。
- 降低计算瓶颈和 DenseNet 的梯度信息重复。
- 降低内存成本。
网络结构
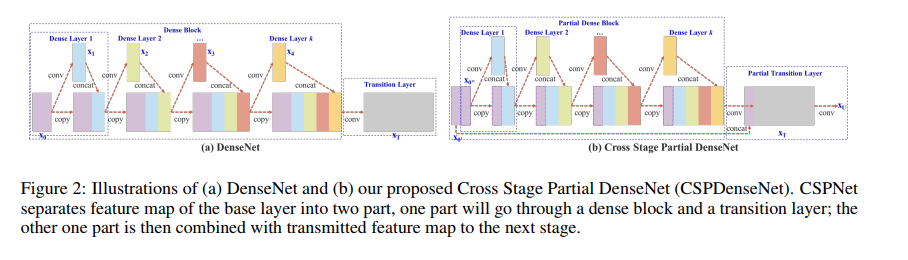
通过将基础层的特征图划分为两个部分 \(x = [x_0^,,x_0^{,,}]\) 其中一个直接连接到网络的最后面,一个通过dense block进行传递。
CSPDenseNet 的一个阶段是由局部密集块和局部过渡层组成a partial dense block and a partial transition layer
主要保留了 DenseNet 重用特征特性,但同时通过截断梯度流防止了过多的重复梯度信息。
采用的是一种分层的特殊融合的策略,并应用于局部过渡层(partial transition layer)。
设计局部密集块(partial dense block)的目的
- 增加梯度路径: 通过分块归并策略,可以使梯度路径的数量增加一倍。由于采用了跨阶段策略,可以减轻使用显式特征图 copy 进行拼接所带来的弊端
- 每一层的平衡计算: 通常,DenseNet 基层的通道数远大于生长速率。由于在局部稠密块中,参与密集层操作的基础层通道仅占原始数据的一半
- 减少内存流量: 假设
DenseNet中一个密集块的基本特征图大小为 \(w × h × c\),增长率为 \(d\) ,共有 \(m\) 个密集块。则该密集块的 CIO为 \((c × m)+(m^2+m)/2\) ,而局部密集块(partial dense block)的CIO为 \([(c × m)+(m^2+m)]/2\)
特征融合策略
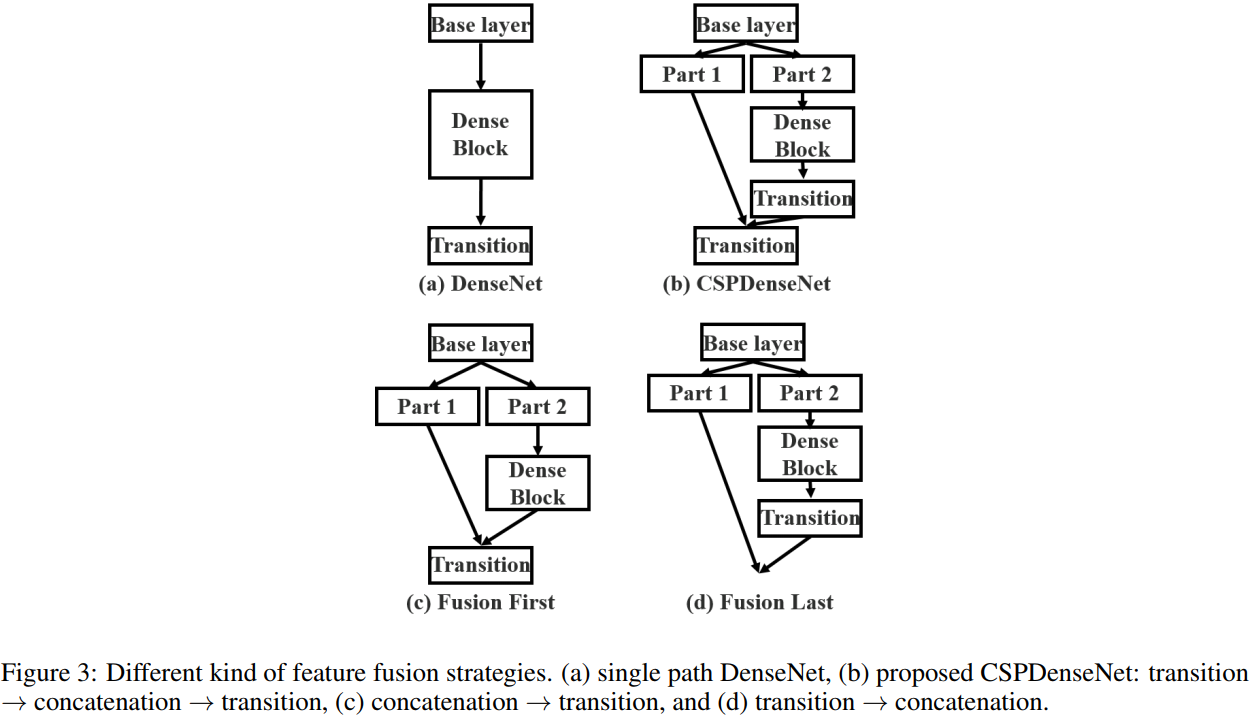
Transition layer,是一个 1x1 的卷积层,过渡层。上图中 transition layer 的位置决定了梯度的结构方式,并且各有优势:
-
(a) 图 为原始的DenseNet的特征融合
-
(c) 图 Fusion First 方式,先将两个部分进行 concatenate,然后再进行输入到 Transion layer 中,采用这种做法会是的大量特梯度信息被重用,有利于网络学习;
-
(d) 图 Fusion Last 的方式,先将部分特征输入 Transition layer,然后再进行concatenate,这样梯度信息将被截断,损失了部分的梯度重用,但是由于 Transition 的输入维度比(c)图少,大大减少了计算复杂度。
-
(b) 图中的结构是论文
CSPNet所采用的,其结合了 (c)、(d) 的特点,提升了学习能力的同时也提高了一些计算复杂度。
CSPnet代码结构
import math
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
#---------------------------------------------------#
# 卷积块 -> 卷积 + 标准化 + 激活函数
# Conv2d + BatchNormalization + Mish
#---------------------------------------------------#
class BasicConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, kernel_size//2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.activation = nn.Mish() # MISH激活函数
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activation(x)
return x
#---------------------------------------------------#
# CSPdarknet的结构块的组成部分
# 内部堆叠的残差块
#---------------------------------------------------#
class Resblock(nn.Module):
def __init__(self, channels, hidden_channels=None):
super(Resblock, self).__init__()
if hidden_channels is None:
hidden_channels = channels
self.block = nn.Sequential(
BasicConv(channels, hidden_channels, 1),
BasicConv(hidden_channels, channels, 3)
)
def forward(self, x):
return x + self.block(x)
#--------------------------------------------------------------------#
# CSPdarknet的结构块
# 首先利用ZeroPadding2D和一个步长为2x2的卷积块进行高和宽的压缩
# 然后建立一个大的残差边shortconv、这个大残差边绕过了很多的残差结构
# 主干部分会对num_blocks进行循环,循环内部是残差结构。
# 对于整个CSPdarknet的结构块,就是一个大残差块+内部多个小残差块
#--------------------------------------------------------------------#
class Resblock_body(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks, first):
super(Resblock_body, self).__init__()
#----------------------------------------------------------------#
# 利用一个步长为2x2的卷积块进行高和宽的压缩
#----------------------------------------------------------------#
self.downsample_conv = BasicConv(in_channels, out_channels, 3, stride=2)
if first:
#--------------------------------------------------------------------------#
# 然后建立一个大的残差边self.split_conv0、这个大残差边绕过了很多的残差结构
#--------------------------------------------------------------------------#
self.split_conv0 = BasicConv(out_channels, out_channels, 1)
#----------------------------------------------------------------#
# 主干部分会对num_blocks进行循环,循环内部是残差结构。
#----------------------------------------------------------------#
self.split_conv1 = BasicConv(out_channels, out_channels, 1)
self.blocks_conv = nn.Sequential(
Resblock(channels=out_channels, hidden_channels=out_channels//2),
BasicConv(out_channels, out_channels, 1)
)
self.concat_conv = BasicConv(out_channels*2, out_channels, 1)
else:
#--------------------------------------------------------------------------#
# 然后建立一个大的残差边self.split_conv0、这个大残差边绕过了很多的残差结构
#--------------------------------------------------------------------------#
self.split_conv0 = BasicConv(out_channels, out_channels//2, 1)
#----------------------------------------------------------------#
# 主干部分会对num_blocks进行循环,循环内部是残差结构。
#----------------------------------------------------------------#
self.split_conv1 = BasicConv(out_channels, out_channels//2, 1)
self.blocks_conv = nn.Sequential(
*[Resblock(out_channels//2) for _ in range(num_blocks)],
BasicConv(out_channels//2, out_channels//2, 1)
)
self.concat_conv = BasicConv(out_channels, out_channels, 1)
def forward(self, x):
x = self.downsample_conv(x)
x0 = self.split_conv0(x)
x1 = self.split_conv1(x)
x1 = self.blocks_conv(x1)
#------------------------------------#
# 将大残差边再堆叠回来
#------------------------------------#
x = torch.cat([x1, x0], dim=1)
#------------------------------------#
# 最后对通道数进行整合
#------------------------------------#
x = self.concat_conv(x)
return x
#---------------------------------------------------#
# CSPdarknet53 的主体部分
# 输入为一张416x416x3的图片
# 输出为三个有效特征层
#---------------------------------------------------#
class CSPDarkNet(nn.Module):
def __init__(self, layers):
super(CSPDarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = BasicConv(3, self.inplanes, kernel_size=3, stride=1)
self.feature_channels = [64, 128, 256, 512, 1024]
self.stages = nn.ModuleList([
# 416,416,32 -> 208,208,64
Resblock_body(self.inplanes, self.feature_channels[0], layers[0], first=True),
# 208,208,64 -> 104,104,128
Resblock_body(self.feature_channels[0], self.feature_channels[1], layers[1], first=False),
# 104,104,128 -> 52,52,256
Resblock_body(self.feature_channels[1], self.feature_channels[2], layers[2], first=False),
# 52,52,256 -> 26,26,512
Resblock_body(self.feature_channels[2], self.feature_channels[3], layers[3], first=False),
# 26,26,512 -> 13,13,1024
Resblock_body(self.feature_channels[3], self.feature_channels[4], layers[4], first=False)
])
self.num_features = 1
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.stages[0](x)
x = self.stages[1](x)
out3 = self.stages[2](x)
out4 = self.stages[3](out3)
out5 = self.stages[4](out4)
return out3,out4,out5
def darknet53():
model = CSPDarkNet([1, 2, 8, 8, 4])
input_data= torch.randn(1,3,416,416)
out3,out4,out5=model(input_data)
print(out3.shape)
print(out4.shape)
print(out5.shape)
darknet53()
参考资料
https://zhuanlan.zhihu.com/p/562927364?utm_id=0
http://pointborn.com/article/2022/2/14/1815.html
https://zhuanlan.zhihu.com/p/263555330
https://zhuanlan.zhihu.com/p/509160824
https://blog.csdn.net/qq_45603919/article/details/117265617 代码
标签:BasicConv,nn,局部,网络,残差,channels,CSPNet,self,out From: https://www.cnblogs.com/tian777/p/17864996.html