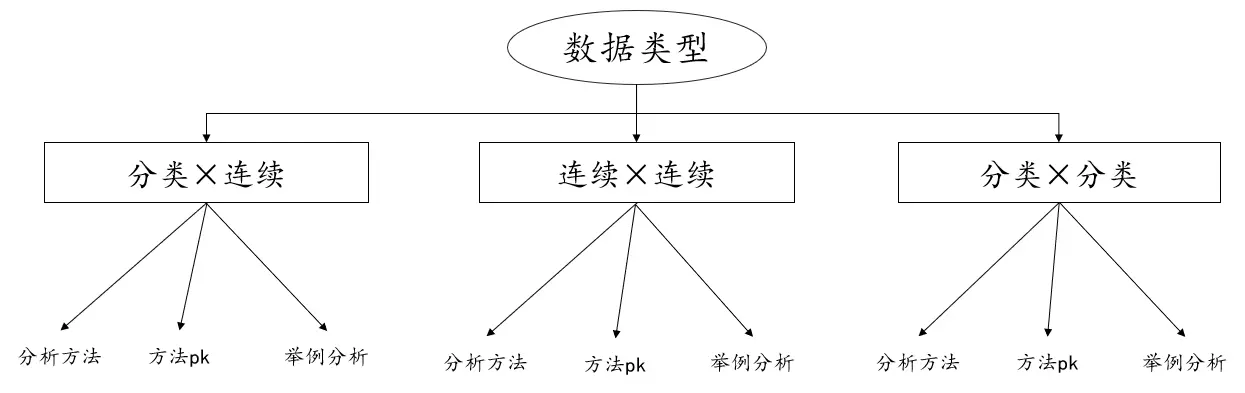
变量说明:
在确定分析方法前,我们需要了解手中的数据类型,这是最基础也是有必要的,在所有的数据类型中,我们将数据类型分为分类变量也为定类变量和连续变量也称为定量变量,那么什么是定类变量?什么是定量变量?
定类变量通俗的讲数字大小不具有比较意义,比如性别中1代表男,2代表女,仅仅代表类别,在比如下图中,1代表底妆2代表唇妆等等,仅是类别关系。

定量变量通俗的讲数字大小具有比较意义,比如调查青少年身高,1.4m比1.3m高,数字本身具有比较意义,在比如如下图片沙发的价格,数字越大说明越贵,数字越小说明越便宜,数字之间是可以比较的。通过数据类型的说明,本次探讨我们以数据类型的不同进行分类说明,分别是分类和连续变量、连续和连续变量、分类和分类变量。
一、分类×连续

如果数据的类型是分类变量和连续变量,那么他的相关性分析或者差异性分析有哪些方法呢?接下来进行说明。
1、分析方法
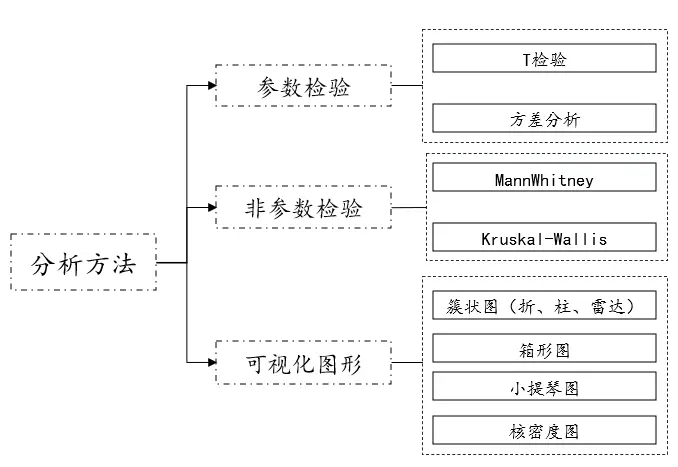
如果数据是分类变量和连续变量,那么进行分析时,分析方法大体可以分为三类,参数检验、非参数检验以及可视化图形,其中参数检验又包括t检验、方差分析,非参数检验包括MannWhitney统计量、Kruskal-Wallis统计量。以及还可以使用可视化图形进行查看。
01、参数检验
- T检验
T检验说明
T检验(独立样本t检验)一般是研究定类变量和定类变量之间的差异性,并且定类变量为二分类变量,比如研究性别和薪资之间是否有显著性差异,性别包括男和女。
T检验数据格式
在进行数据分析之前都需要将数据整理成正确的数据格式然后在进行分析,那么t检验(严格讲为独立样本t检验)的数据格式是什么样的呢?如下说明:
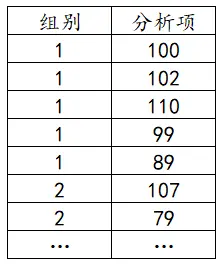
T检验的数据一般有两列,第一列是组别(二分类),第二列是对应的分析项,比如说想要研究不同性别的身高是否有显著性差异,其正确的数据格式如下:

T检验操作
整理成正确的数据格式之后,接下来进行准备利用T检验进行分析,分析操作是怎样的呢?以SPSSAU举例进行说明:
【通用方法:t检验】→【拖拽分析项】→点击开始分析;

T检验结果一般形式

一般结果中会提供均值标准差以及t统计量和p值等。
- 方差分析
方差分析说明
方差分析(单因素方差分析)一般是研究定类变量和定类变量之间的差异性,并且定类变量为多分类变量,比如研究学历和薪资之间是否有显著性差异,学历包括本科以下、本科以及本科以上。
方差分析数据格式
方差分析(严格来讲是单因素方差分析)的数据格式,如下说明:
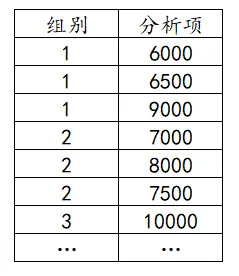
方差分析的数据一般有两列,第一列是组别(多分类),第二列是对应的分析项,比如说上表格中1=本科以下、2=本科、3=本科以上。
方差分析操作
【通用方法:方差分析】→【拖拽分析项】→点击开始分析;

方差分析结果一般形式
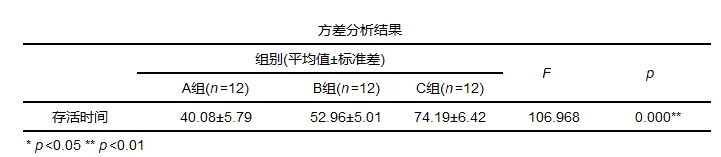
一般结果中会提供均值标准差以及F统计量和p值等。
02、非参数检验
- MannWhitney统计量
MannWhitney说明
MannWhitney非参数检验一般是研究定类变量和定类变量之间的差异性,并且定类变量为二分类变量,比如研究性别和薪资之间是否有显著性差异,性别包括男和女。其数据格式与独立样本t检验类似,组别为一列,对应的定量变量为一列。
MannWhitney操作
【通用方法:非参数检验】→【拖拽分析项】→点击开始分析;
MannWhitney结果一般形式
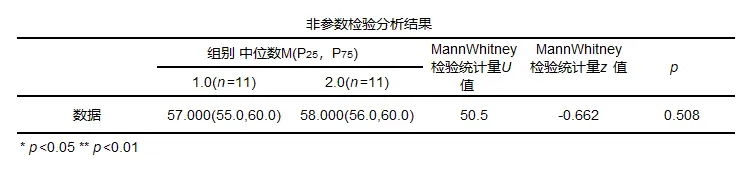
一般结果中会提供中位数以及统计量和p值等。
- Kruskal-Wallis统计量
Kruskal-Wallis说明
Kruskal-Wallis非参数检验一般是研究定类变量和定类变量之间的差异性,并且定类变量为多分类变量,比如研究学历和薪资之间是否有显著性差异,学历包括本科以下、本科以及本科以上。其数据格式与单因素方差类似。操作与MannWhitney一致(SPSSAU会自动判断分类变量的分类数进而判断使用MannWhitney还是Kruskal-Wallis),其一般形式如下:

一般结果中会提供中位数以及统计量和p值等。
03、可视化图形
- 可视化图形
除了可以利用假设检验进行分析外,还可以使用图形进行简单判断分析,由于数据是定类和定量,所以可以使用折线图、条形图、柱形图、雷达图、箱形图、小提琴图、核密度图等。其中折线图、条形图、柱形图、雷达图可以统称为簇状图,簇状图和箱形图、小提琴图、核密度图的数据格式定类为一列,定量为一列,可以在SPSSAU的可视化板块进行选择分析。示例类似如下:
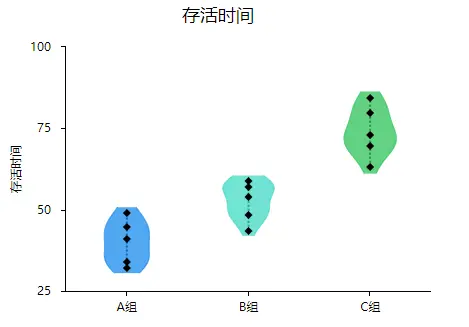
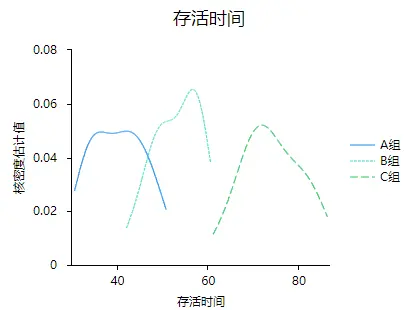
2、方法PK
分类变量和连续变量可以进行参数检验、非参数检验以及可视化图形,那么这些方法应该如何去选择呢?接下来进行说明:
01、参数检验PK非参数检验
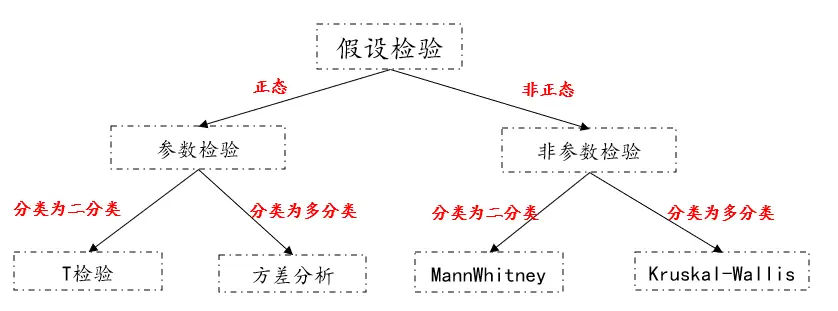
按假设检验类别进行分类,分为参数检验和非参数检验,如果数据为二分类变量,比如分类变量为性别包括男和女,或者为两组分为第一组,第二组。一般考虑使用t检验(参数检验)或者mannwhitney(非参数检验),如果分类变量是多分类变量,比如分类变量是专业包括理学、农学、医学或者分类变量是学历包括专科、本科、硕士、博士。一般考虑使用方差分析(参数检验)或者Kruskal-Wallis(非参数检验),那么参数检验和非参数检验有什么区别呢?
参数检验和非参数检验的区别:参数检验是假定数据服从某分布(一般为正态分布),通过样本参数的估计量(x±s)对总体参数进行检验,比如t检验、u检验、方差分析等。非参数检验则不需要假定总体分布形式,直接对数据的分布进行检验。但是参数检验的效能比非参数检验效能高,以及对于t检验和方差分析,其在实证研究中具有一定的耐性,如果不是严重不满足正态分布都是可以使用t检验或者方差分析进行分析的。
02、可视化图形PK
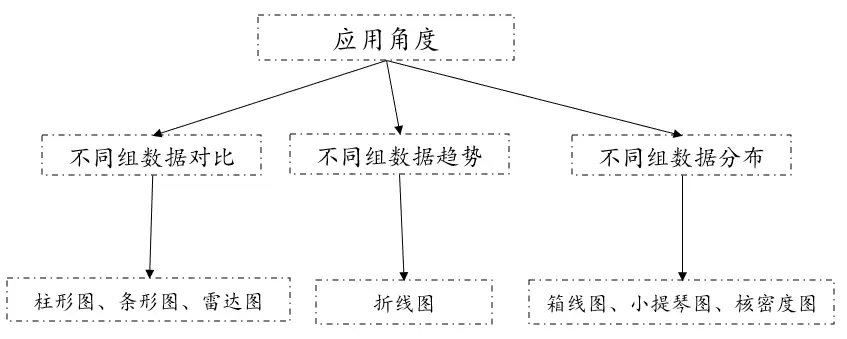
对于分类数据和连续数据之间的可视化图形,从应用角度可以分为三类,第一类是主要用于不同数据的对比,可以考虑使用柱形图、条形图、雷达图比如不同性别的薪资水平对比。第二类主要用于查看不同组数据的变化趋势,一般可以考虑使用折线图,比如不同专业的成绩变化。第三类主要用于不同组别数据的分布,可以考虑使用箱线图、小提琴图或者核密度图,比如南方北方的身高分布。一般在分析时建议可以结合检验和可视化图形进行分析然后得到相应结论。
3、举例分析
比如想要分析如下数据:
第一组:44、55、67、45、46、56、69、34、59、78、99;
第二组:49、59、62、56、68、45、77、89、99、102、45;
分析不同组别之间的相关性(差异性)。
分析:由于是分析不同组别之间的相关性(差异性),由于组别是二分类变量,所以考虑使用t检验或者非参数检验,由于数据基本服从正态分布,所以采用t检验和可视化图形进行结合分析。
直方图(正态检验)的结果如下:

从结果中看到直方图呈现类似“倒扣的钟形”,所以认为数据基本服从正态分布。
01、分析流程

T检验的分析流程,大体可以分为四步:
- 整理成正确的数据格式;
- 验证t检验的前提条件;(前提条件:正态分布、)
- 进行操作;
- T检验的结果分析;
Step1:
整理数据格式,组别为一列,数据为一列,所以整理的结果如下:

Step2:
T检验的前提条件:
- 样本独立
- 正态分布
- 方差齐性
Step3:t检验操作

上传数据后,点击通用方法的t检验,然后将分析项拖拽到对应分析框内,点击开始分析。
Step4:T检验的结果分析;
02、解读分析结果

从t检验分析结果可以看出,第一组的均值为59.27、第二组的均值为68.27,从均值中可以看出来第二组数据平均水平上大于第一组数据,然后t统计量为-1.077,p值为0.294大于显著性水平,说明模型不显著,也即说明第一组数据与第二组数据之间没有差异性。与此同时我们还可以使用柱形图或者条形图进行可视化分析:
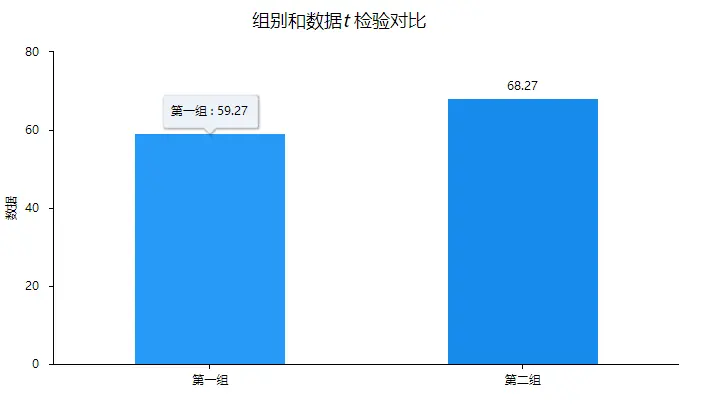
从可视化图形中可以看出第二组数据均值大于第一组数据,但是柱形图中只能看处=出,两组数据的简单对比,对于模型的分析或者显著性的判断,还是需要进行假设检验。
03、指标解读
对于t检验中的t值如何计算得到呢?
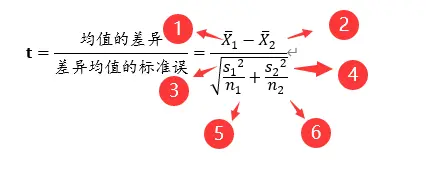
- 样本1的均值,本例子中为59.27;
- 样本2的均值,本例子中为68.27;
- 样本1的方差,本例子中为(18.34)^2=336.3556;
- 样本2的方差, 本例子中为(20.78)^2=431.8084;
- 样本1的样本量, 本例子中为11;
- 样本2的样本量, 本例子中为11,
计算t值为:-1.077;其它指标的计算可以登录SPSSAU官网进行查看。
二、连续×连续
如果数据的类型是连续变量和连续变量,那么他的相关性分析或者差异性分析有哪些方法呢?接下来进行说明。
1、分析方法
如果数据是连续数据和连续变量,那么进行分析时,分析方法大体可以分为四类,相关分析、参数检验、非参数检验以及可视化图形,其中相关分析一般包括皮尔逊(pearson)相关系数以及斯皮尔曼(spearman)相关系数。如果连续变量和连续变量的样本量是相同的,可以考虑使用参数检验中的配对t检验,非参数检验包括配对wilcoxon,可视化图形可以考虑使用散点图。
01、相关分析
相关分析说明
相关分析一般是研究定量数据和定量数据的相关性,以及变量之间存在相关性,相关程度是如何的,比如研究身高和体重之间是否有关联等等。
相关分析数据格式
在进行数据分析之前都需要将数据整理成正确的数据格式然后在进行分析,那么相关分析的数据格式是什么样的呢?如下说明:
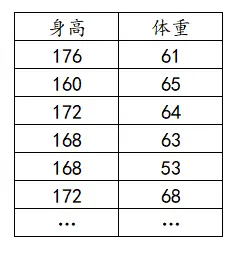
相关分析的数据格式为一个分析项为一列,比如上图中研究身高和体重,则身高为一列、体重为一列。
相关分析操作
整理成正确的数据格式之后,接下来准备进行相关分析,分析操作是怎样的呢?以SPSSAU举例进行说明:
【通用方法:相关分析】→【拖拽分析项】→点击开始分析;
相关分析结果一般形式
分析结果一般包括相关系数以及p值和样本量,一般分析时查看p值就好了。
相关系数判断标准

不同的文献相关系数的判断标准不同,如果在分析中,建议以及所参考的文献等进行参考,比如上面的文献就来自于贾俊平, 何晓群, 金勇进. 统计学.第7版[M]. 中国人民大学出版社, 2018.
02、参数检验
配对t检验说明
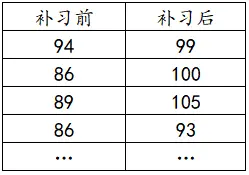
配对t检验一般是研究配对的定量数据和定量数据之间的差异关系,比如研究某班级补习前后两次的语文成绩是否有差异。
配对t检验的数据格式
配对t检验的数据格式比较特殊,因为不仅需要为定量变量,还需要数据为配对数据,也就是两组数据的样本量是需要相同的,一般如下:
配对t检验操作
【通用方法:配对t检验】→【拖拽分析项】→点击开始分析;
配对t检验的一般形式

分析结果一般包括配对的均值和标准差、统计量t值以及p值。
03、非参数检验
- 配对wilcoxon
配对wilcoxon说明
配对wilcoxon一般是研究配对的定量数据和定量数据之间的差异关系,比如研究某班级补习前后两次的语文成绩是否有差异。
配对wilcoxon的数据格式
其数据格式与配对t检验一致。
配对wilcoxon操作
【实验/医学研究:配对样本wilcoxon】→【拖拽分析项】→点击开始分析;
配对wilcoxon的一般形式
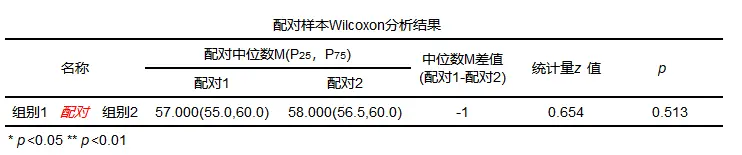
分析结果一般包括配对的中位数、统计量z值以及p值。
04、可视化图形
- 散点图
散点图说明
散点图一般用于绘制定量数据和定量数据关系研究时,比如想要观察身高和体重的关系,就可以使用散点图进行研究。
散点图的数据格式
散点图的数据格式与相关分析一致。
散点图操作
【可视化:散点图】→【拖拽分析项】→点击开始分析;
散点图的一般形式

2、方法PK
连续变量和连续变量可以进行相关分析、参数检验、非参数检验以及可视化图形,那么这些方法应该如何去选择呢?接下来进行说明:
01、相关系数PK
Pearson相关系数也叫皮尔逊积矩相关系数,通常用r表示,使用pearson相关系数,数据需要满足:
- 线性
- 正态分布
- 没有异常值
如果不满足条件可以考虑使用spearman相关系数,以及pearson相关系数的计算如下:

Speaman计算公式如下:

针对pearson相关系数不能识别非线性关系以及并且对一个或者几个异常值比较敏感,此时可以使用spearman相关系数进行替代,spearman相关系数有时也被称为级别相关系数或者秩相关系数,该相关系数是根据两个变量的秩进行相关分析,spearman相关系可以用来衡量两个变量之间是否存在单调相关关系。当值为1时说明一个变量随着一个变量单调递增,当值为-1时,说明一个变量随着另一个变量单调递减。
02、参数检验PK非参数检验
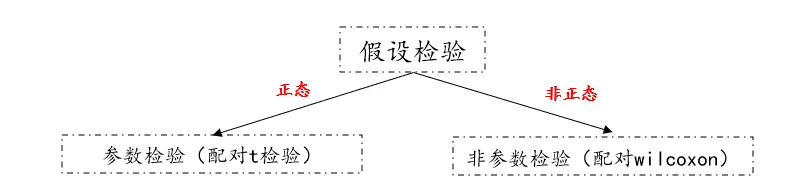
按假设检验类别进行分类,分为参数检验和非参数检验,如果服从正态分布可以使用配对t检验,如果不满足正态分布可以使用配对wilcoxon检验,对于参数检验和非参数检验的区别可以查看上一个模块。对于散点图,一般和相关分析一起联用,在相关分析前,探索数据之间的关系。
3、举例分析
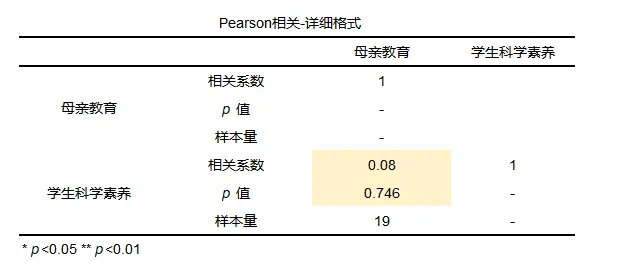
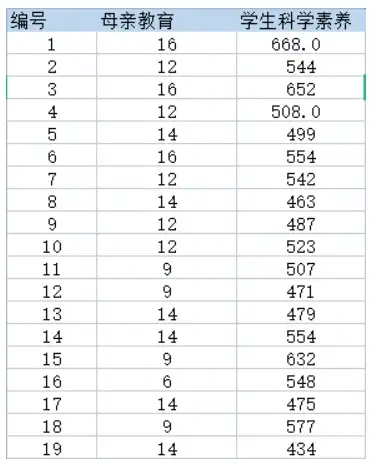
想要了解高中生的母亲受教育年数和学生的科学素养是否有关联,测得19名学生的母亲受教育年数和学生的科学素养数据如下。
分析:由于是分析不同组别之间的相关性(差异性),由于组别是二分类变量,所以考虑使用t检验或者非参数检验,由于数据基本服从正态分布,所以采用t检验和可视化图形进行结合分析。
正态检验的结果如下:

从结果中可以看到,模型不显著,接受原假设说明数据服从正态分布。
01、分析流程

此案例的相关分析分析流程,大体可以分为五步:
- 整理成正确的数据格式;
- 进行散点图查看;
- 验证相关分析的前提条件;(前提条件:正态分布、)
- 进行操作;
- 相关的结果分析;
Step1:
整理数据格式,一个分析项为一列,所以整理的结果如下:
Step2:
pearson相关分析的前提条件:
- 两变量为连续变量
- 两变量存在线性关系
- 两变量呈现正态分布
Step3:进行绘制散点图
简单查看下数据的关系。
Step4:相关分析操作

上传数据后,点击通用方法的相关分析,然后将分析项拖拽到对应分析框内,点击开始分析。
Step5:相关的结果分析;
02、解读分析结果
1)散点图

从散点图可以看出,散点是杂乱无章的,从图中看起来学生科学素养与母亲受教育年限大概没有关系,可以进一步查看相关分析。
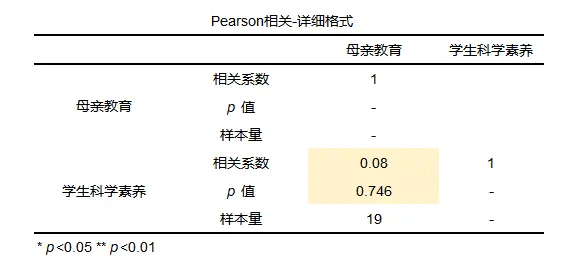
从相关分析的结果中可以看出,相关系数为0.08,说明二者之间的关系极弱,以及p值大于0.1说明整体模型不显著,拒绝原假设,二者没有相关关系。
03、指标解读
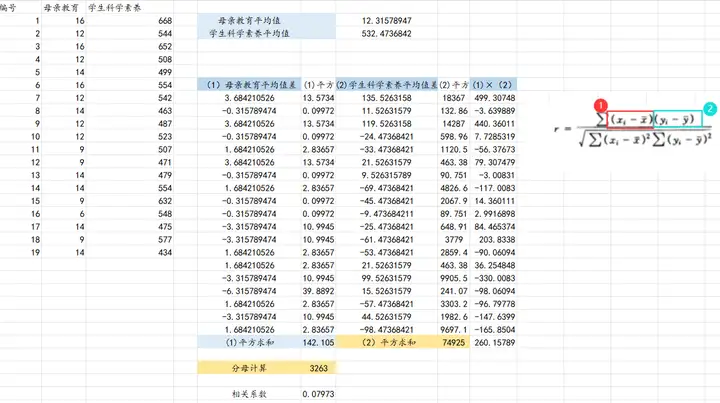
对于pearson相关系数具体如何计算呢?
计算过程如下:
三、分类×分类
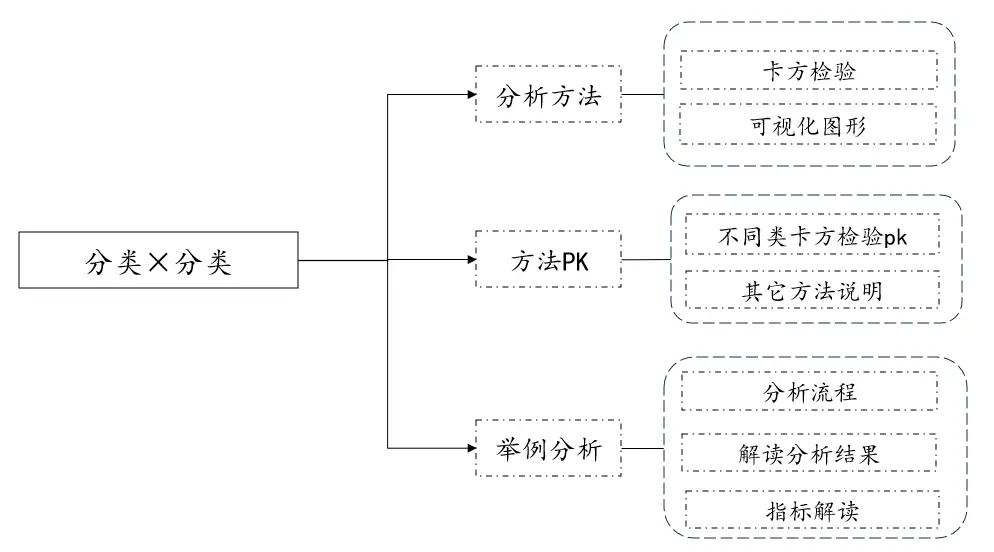
1、分析方法
如果数据是分类变量和分类变量,那么进行分析时,分析方法大体可以分为三类,卡方检验、可视化图形,其中卡方检验又包括pearson卡方、fisher卡方、yates校正卡方、cochran-armitage检验、线性趋势卡方,以及还可以使用可视化图形(堆积柱形图、条形图)进行查看。
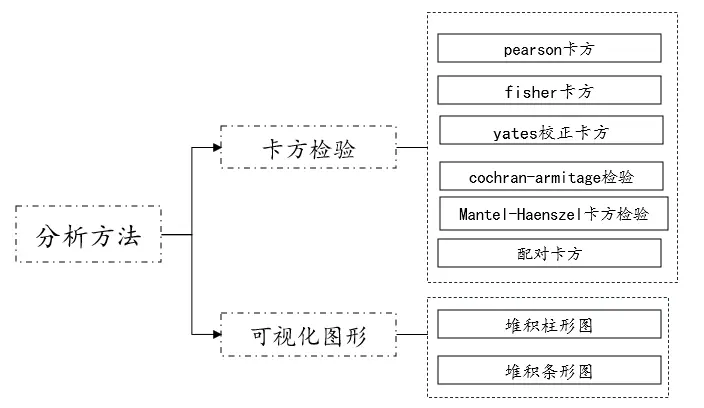
01、卡方检验
- 卡方检验
卡方检验说明
卡方检验一般是研究定类数据和定类数据之间的差异性,比如研究性别和是否吸烟之间的显著性差异。
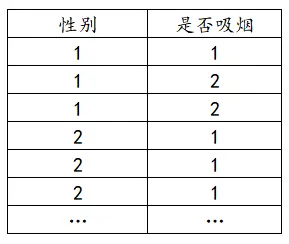
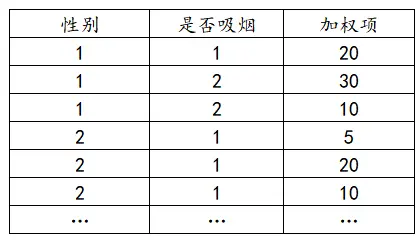
卡方检验数据格式
卡方检验的数据格式为一个分析项为一列,如果有加权格式,则加权格式单独为一列,如下说明:
(1)普通格式
(2)加权格式
卡方检验操作
整理成正确的数据格式之后,接下来进行卡方检验,分析操作是怎样的呢?以SPSSAU举例进行说明:
【实验/医学研究:卡方检验】→【拖拽分析项】→点击开始分析;
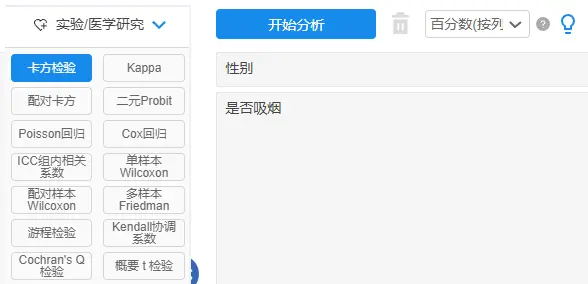
卡方检验结果一般形式
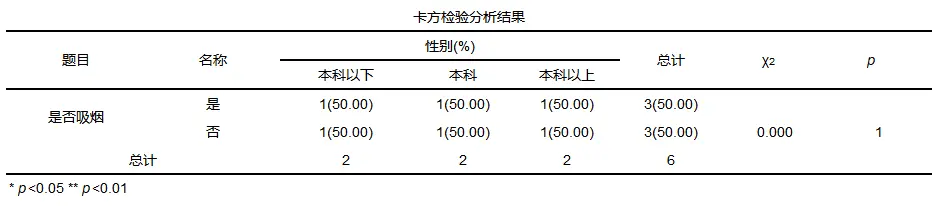
一般结果中会提供均值标准差以及卡方值和p值等。
02、可视化图形
为了更清楚的表示各个类别占比可以使用渡记柱形图或者条形图进行表示。
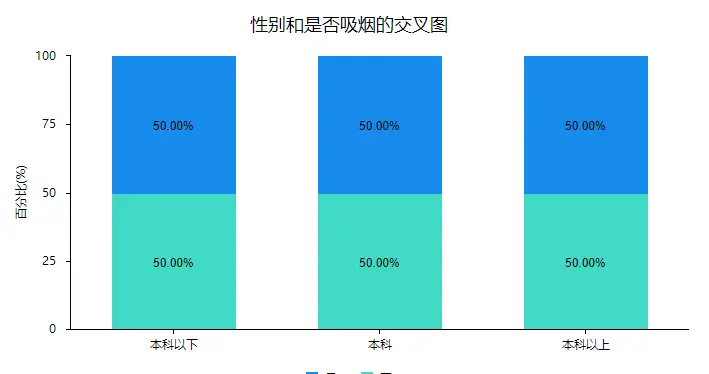
2、方法PK
(1)不同类卡方检验pk
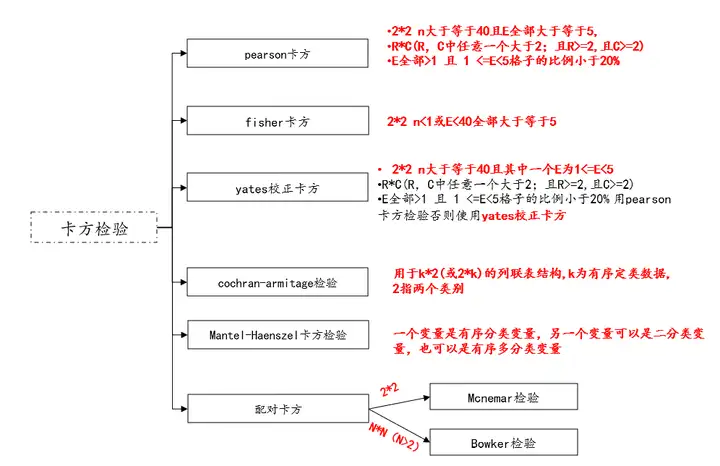
(2)其它方法说明
除了可以使用卡方检验外,还可以使用可视化图形进行描述分类变量和分类变量之间的关系,比如可以使用堆积柱形图和堆积条形图进行描述,更加直观,分析时可以结合自己的分析方法进行绘制研究。
03、举例分析
(1)分析流程
想要调查不用性别(男、女)的饮食习惯(米食、面食),针对卡方检验的分类应该使用pearson卡方检验。
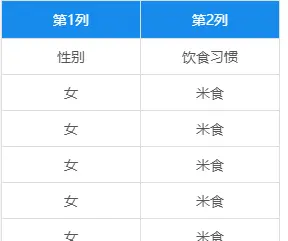
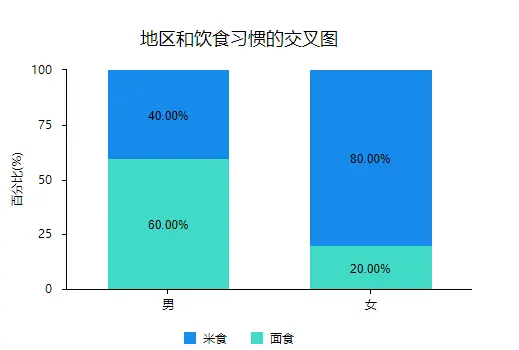
(2)解读分析结果

从分析结果中看出男性更偏爱吃面食占比为60%,女性更偏爱吃米食约占调查中的80%。从数据来看,不同性别的饮食习惯有差异,模型中的卡方值为16.667,其中p值小于0.05,拒绝原假设,说明模型显著,不同性别的饮食习惯有差别。并且从堆积柱形图中也可以直观查看到男性更爱吃面食,女性更爱吃米食。
(3)指标解读
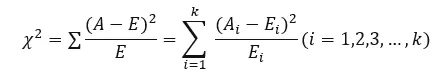
其中Ai为i水平的观察频数,Ei为i水平的期望频数,k为单元格数。
比如:
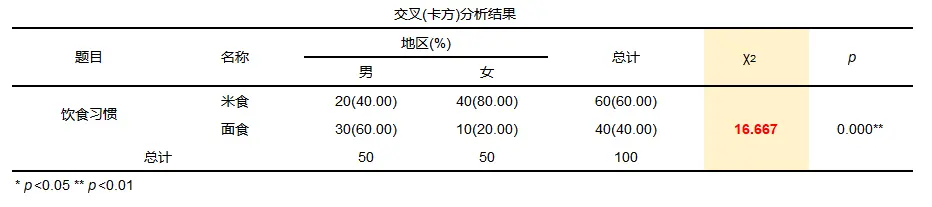
计算如下:
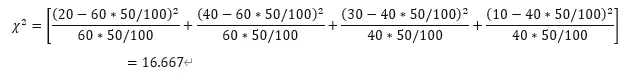
参考文献:
[1]朱玉祥,江剑民,赵亮,等.不同计算形式的相关分析在气象中的应用综述[J].热带气象学报, 2021, 37(1):1-13.
标签:分析,参数检验,变量,数据,检验,统计学,相关性,数据格式,差异性 From: https://www.cnblogs.com/spssau/p/17862448.html