前言 本文介绍了深度学习中精简模型的技术:量化和蒸馏。
本文转载自DeepHub IMBA
作者:Aaditya ura
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
深度学习模型,特别是那些具有大量参数的模型,在资源受限环境中的部署几乎是不可能的。所以就出现了两种流行的技术,量化和蒸馏,它们都是可以使模型更加轻量级,而不会对性能造成太大影响。但是它们需要什么,它们又如何比较呢?

一、量化:牺牲精度换取效率
量化是关于数字精度的。通过减少模型中权重和激活的位宽度,缩小模型大小,从而潜在地提高推理速度。
神经网络有相互连接的神经元,每个神经元都有在训练过程中调整的权重和偏差。这些参数值一般存储在32位浮点数中,这样虽然保证了精度,但占用了大量内存。例如,一个50层的ResNet需要168MB来存储2600万32位权重值和1600万32位激活值。
量化旨在通过使用较低的位数(如8位整数)来表示权重和激活,来减少内存占用。但这引入了量化误差,所以量化的目标是在精度和内存使用之间取得平衡。像每通道量化、随机舍入和再训练这样的先进技术可以最大限度地减少对模型精度的影响。
最常见的两种量化情况是:float32 -> float16和float32 -> int8。
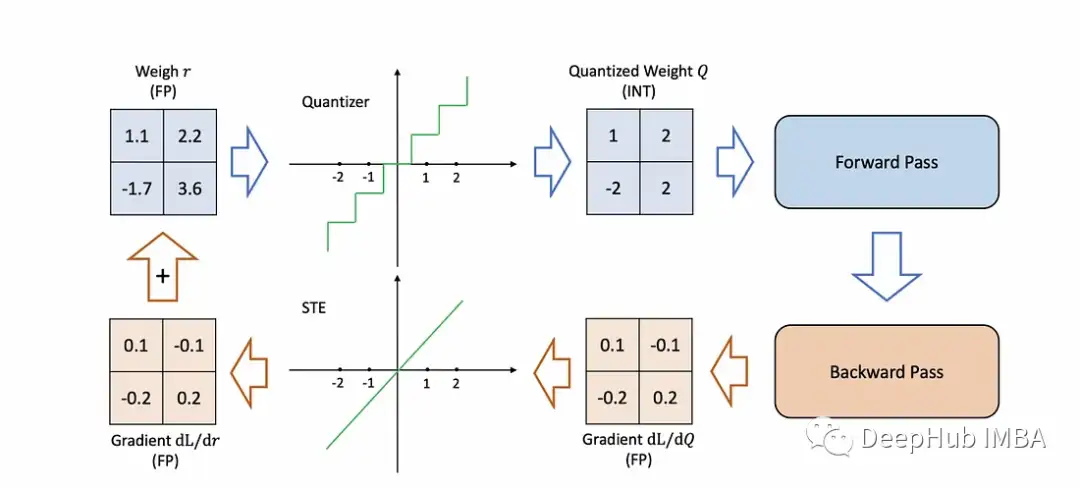
量化背后的数学理论:

上面公式提供了一种将实数转换为量化整数的简单且计算效率高的方法,使其成为许多量化方案中的流行选择。
如何量化机器学习模型?
训练后量化:这就像用一支普通的笔写整本书,在你写完之后,用一支更好的更细笔重写它,使它更小。你不需要改变故事的任何内容;只要把字改小一点就行了。这是非常容易的,但有时较小的文字可能更难阅读(这意味着神经网络的准确性可能会下降)。
量化感知训练:这就像从一开始就用一支好笔写书。当你写的时候,你会意识到字母应该有多小,所以你会在写的时候调整你的写作风格。这样最终小版本从一开始就更容易阅读,因为你一直在为小版本的书进行考虑(这意味着神经网络从一开始就被训练成可以很好地与更小的量化版本一起工作)。
在这两种情况下,目标都是使书(或神经网络)更小、更高效,同时又不失去故事的本质(或网络的准确性)。
优点:
- 减小模型大小:例如,从32位浮点数转换为8位整数可以将模型大小减小四倍。
- 速度和硬件兼容性:在特定的硬件加速器上,低精度的算法可以更快。
- 内存效率:更少的数据意味着更少的内存带宽需求。
缺点
- 准确性权衡:较低的精度有时会影响模型性能。
- 实现挑战:量化,特别是量化感知训练,可能会很棘手。
二、蒸馏:老师到学生传递知识
蒸馏包括训练一个较小的神经网络(称为学生)来模仿一个更大的预训练网络(即教师)。
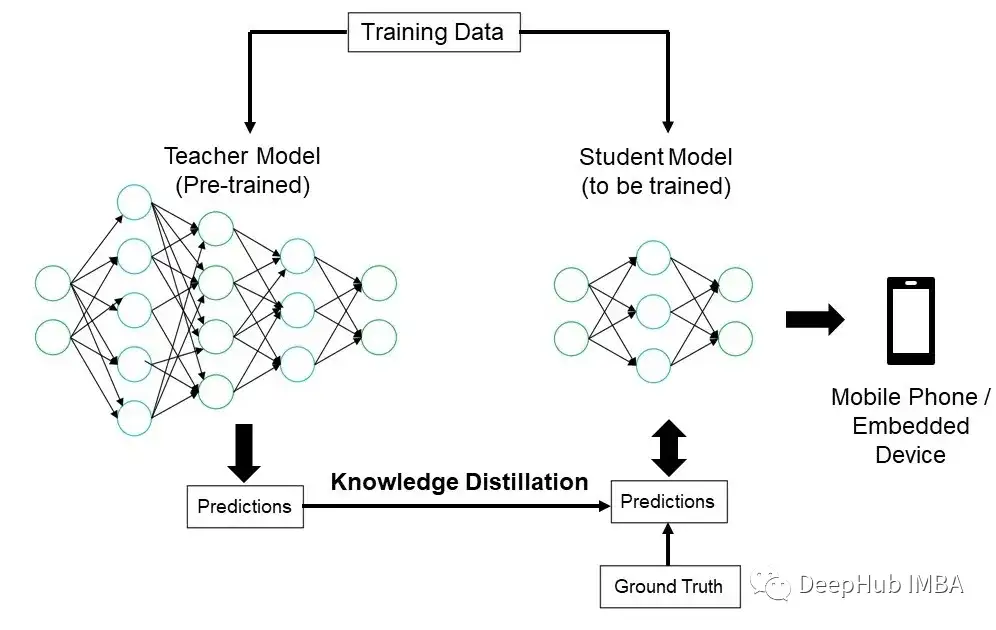
下面的举例我们都以书籍写作为例,这样可以更加清晰
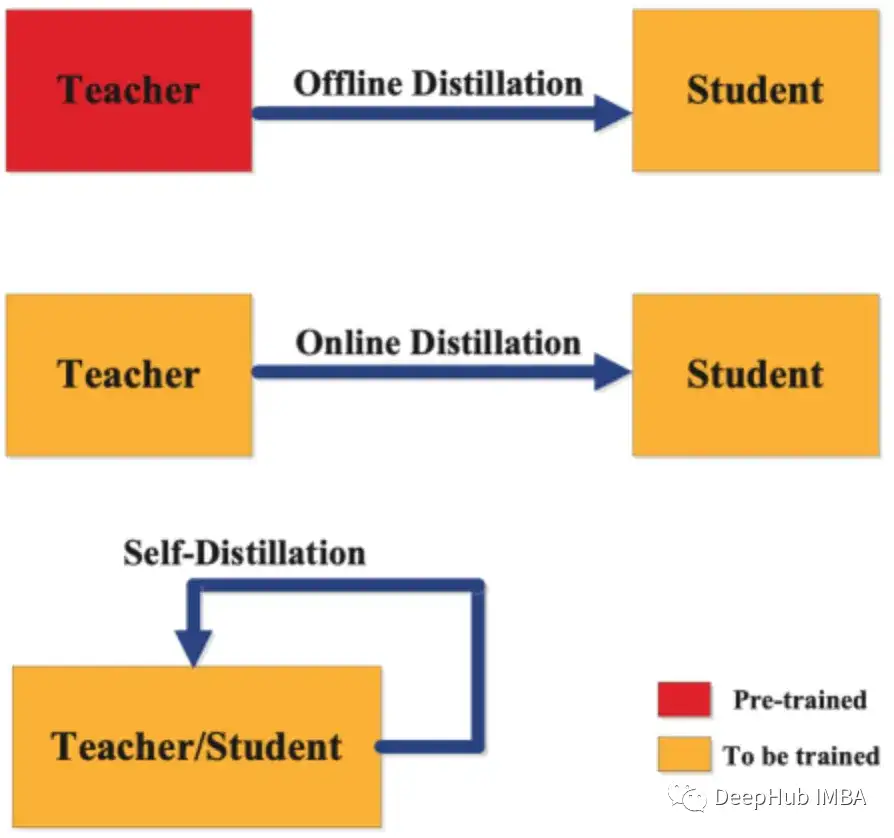
从广义上讲,蒸馏有三种类型的分类:
离线蒸馏:一个作家正在从一本已经出版的成功的书中学习。出版的书(教师模型)是完整和固定的。新作者(学生模式)从这本书中学习,试图根据所获得的见解写出自己的作品。在神经网络的背景下,这就像使用一个经过充分训练的、复杂的神经网络来训练一个更简单、更有效的网络。学生网络从教师的既定知识中学习,而不修改它。
在线蒸馏:想象一个有作家和一个经验丰富的作家同时写他们的书。当经验丰富的作者开发新的章节(更新教师模型)时,新作者也会编写他们的章节(更新学生模型),并在此过程中向经验丰富的作者学习。这两本书同时写作,两个作者的作品相互启发。在神经网络中,这意味着同时训练教师和学生模型,让他们一起学习和适应,增强学生模型的学习过程。
自蒸馏:一本书作者既是老师又是学生。他以目前的技能水平开始写书。当他获得新的见解并提高写作水平时,会修改前面的章节。这是一种自学习的模式,作者根据自己不断发展的理解不断完善自己的作品。在神经网络中,这种方法涉及单个网络学习和自我改进,使用其更高级的层或后期的训练来增强其较早的层或初始阶段,有效地教会自己变得更高效和准确。
蒸馏背后的数学理论:
精馏的目的是尽量减少教师预测和学生预测之间的差异。这种散度最常用的度量是Kullback-Leibler散度:

优点
- 大小灵活性:学生模型的架构或大小可以定制,从而在大小和性能之间提供平衡。
- 精度更好:一个训练有素的学生模型可以达到接近老师的成绩,并且更小。
缺点
- 再训练是必须的:与量化不同,蒸馏要求对学生模型进行再训练
- 训练开销:训练学生模型需要时间和计算资源。
三、总结
量化通常在特定于硬件的部署中找到它的位置,而精馏则是在需要性能接近大型对应模型的轻量级模型时需要的方法。在许多情况下,两者可以结合——提炼一个模型,然后量化它——可以带来两个方法的好处。将选择与部署需求、可用资源以及在准确性和效率方面的可接受权衡相结合是至关重要的。
如果你对这两个技术感兴趣,请看这两篇综述
- A Survey of Quantization Methods for Efficient Neural Network Inference [ https://arxiv.org/pdf/2103.13630.pdf]
- Knowledge Distillation: A Survey [https://arxiv.org/pdf/2006.05525.pdf]
引用
[1] Wang, Xiaohui, et al. "LightSeq2: Accelerated training for transformer-based models on gpus." arXiv preprint arXiv:2110.05722 (2021).
[2] Micikevicius, Paulius, et al. "Mixed precision training." arXiv preprint arXiv:1710.03740 (2017).
[3] Pisarchyk, Yury, and Juhyun Lee. "Efficient memory management for deep neural net inference." arXiv preprint arXiv:2001.03288 (2020).
[4] Jacob, Benoit, et al. "Quantization and training of neural networks for efficient integer-arithmetic-only inference." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[5] Alistarh, Dan, et al. "QSGD: Communication-efficient SGD via gradient quantization and encoding." Advances in neural information processing systems 30 (2017).
[6] Choi, Jungwook, et al. "Pact: Parameterized clipping activation for quantized neural networks." arXiv preprint arXiv:1805.06085 (2018).
[7] Wang, Xiaohui, et al. "LightSeq: A high performance inference library for transformers." arXiv preprint arXiv:2010.13887 (2020).
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:蒸馏,模型,arXiv,神经网络,量化,CV From: https://www.cnblogs.com/wxkang/p/17836013.html