本文将深入研究深度学习中精简模型的技术:量化和蒸馏
深度学习模型,特别是那些具有大量参数的模型,在资源受限环境中的部署几乎是不可能的。所以就出现了两种流行的技术,量化和蒸馏,它们都是可以使模型更加轻量级,而不会对性能造成太大影响。但是它们需要什么,它们又如何比较呢?

量化:牺牲精度换取效率
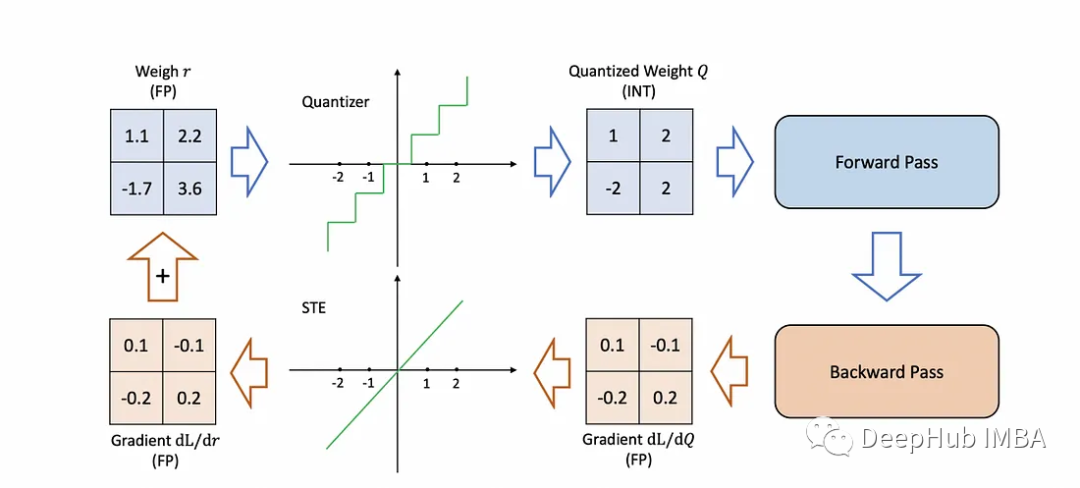
量化是关于数字精度的。通过减少模型中权重和激活的位宽度,缩小模型大小,从而潜在地提高推理速度。
神经网络有相互连接的神经元,每个神经元都有在训练过程中调整的权重和偏差。这些参数值一般存储在32位浮点数中,这样虽然保证了精度,但占用了大量内存。例如,一个50层的ResNet需要168MB来存储2600万32位权重值和1600万32位激活值。
量化旨在通过使用较低的位数(如8位整数)来表示权重和激活,来减少内存占用。但这引入了量化误差,所以量化的目标是在精度和内存使用之间取得平衡。像每通道量化、随机舍入和再训练这样的先进技术可以最大限度地减少对模型精度的影响。
最常见的两种量化情况是:float32 -> float16和float32 -> int8。
https://avoid.overfit.cn/post/f2c1456d33094a439903409792f75729
标签:蒸馏,32,模型,神经网络,量化,精度 From: https://www.cnblogs.com/deephub/p/17831022.html