我们将宝石分类视为一个图像分类任务,主要方法是使用深度神经网络搭建一个分类模型,通过对模型的多轮训练学习图像特征,最终获得用于宝石分类的模型,大致可以分为五步:
1、数据集的加载与预处理;
2、模型的搭建;
3、模型训练;
4、模型评估;
5、使用模型进行预测;
环境:python3.7,使用飞浆2.0版本,操作平台为pycharm
步骤1:我们对宝石图像数据集进行加载与预处理
使用的数据集中包含800多张格式为jpg的宝石图像,包含25个宝石类别。是一个多分类任务,首先我们定义一个方法对宝石的数据集的压缩包进行解压缩,解压缩之后可以观察数据集文件夹结构。
1 def unzip_data(src_path,target_path):
2
3 '''
4 解压原始数据集,将src_path路径下的zip包解压至data/dataset目录下
5 '''
6
7 if(not os.path.isdir(target_path)):
8 z = zipfile.ZipFile(src_path, 'r')
9 z.extractall(path=target_path)
10 z.close()
11 else:
12 print("文件已解压")

解压得到文件夹后,定义一个方法遍历文件夹和图片,按照一定比例将数据划分为训练集和验证集,并生成文本文件train.txt、eval.txt用于记录用于训练和测试的图片路径及其对应的标签,使用制表符进行分割,通过定义一个数据加载器Reader,用于加载训练和评估要使用的数据,并且用于对图像的一些处理、转化操作,需要继承Dataset类:
1 class Reader(Dataset):
2 def __init__(self, data_path, mode='train'):
3 """
4 数据读取器
5 :param data_path: 数据集所在路径
6 :param mode: train or eval
7 """
8 super().__init__()
9 self.data_path = data_path
10 self.img_paths = []
11 self.labels = []
12
13 if mode == 'train':
14 with open(os.path.join(self.data_path, "train.txt"), "r", encoding="utf-8") as f:
15 self.info = f.readlines()
16 for img_info in self.info:
17 img_path, label = img_info.strip().split('\t')
18 self.img_paths.append(img_path)
19 self.labels.append(int(label))
20
21 else:
22 with open(os.path.join(self.data_path, "eval.txt"), "r", encoding="utf-8") as f:
23 self.info = f.readlines()
24 for img_info in self.info:
25 img_path, label = img_info.strip().split('\t')
26 self.img_paths.append(img_path)
27 self.labels.append(int(label))
28
29
30 def __getitem__(self, index):
31 """
32 获取一组数据
33 :param index: 文件索引号
34 :return:
35 """
36 # 第一步打开图像文件并获取label值
37 img_path = self.img_paths[index]
38 img = Image.open(img_path)
39 if img.mode != 'RGB':
40 img = img.convert('RGB')
41 img = img.resize((224, 224), Image.BILINEAR)
42 img = np.array(img).astype('float32')
43 img = img.transpose((2, 0, 1)) / 255
44 label = self.labels[index]
45 label = np.array([label], dtype="int64")
46 return img, label
47
48 def print_sample(self, index: int = 0):
49 print("文件名", self.img_paths[index], "\t标签值", self.labels[index])
50
51 def __len__(self):
52 return len(self.img_paths)
53
54
55 # In[8]:
56
57
58 train_dataset = Reader('./',mode='train')
59
60 eval_dataset = Reader('./',mode='eval')
61
62 #训练数据加载
63 train_loader = paddle.io.DataLoader(train_dataset, batch_size=16, shuffle=True)
64 #测试数据加载
65 eval_loader = paddle.io.DataLoader(eval_dataset, batch_size = 8, shuffle=False)

步骤2:搭建神经网络模型
使用全连接神经元搭建神经网络模型:
1 #定义DNN网络
2 class MyDNN(paddle.nn.Layer):
3 def __init__(self):
4 super(MyDNN,self).__init__()
5 self.linear1 = paddle.nn.Linear(in_features=3*224*224, out_features=1024)
6 self.relu1 = paddle.nn.ReLU()
7
8 self.linear2 = paddle.nn.Linear(in_features=1024, out_features=512)
9 self.relu2 = paddle.nn.ReLU()
10
11 self.linear3 = paddle.nn.Linear(in_features=512, out_features=128)
12 self.relu3 = paddle.nn.ReLU()
13
14 self.linear4 = paddle.nn.Linear(in_features=128, out_features=25)
15
16 def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑
17 # input.shape (16, 3, 224, 224)
18 x = paddle.reshape(input, shape=[-1,3*224*224]) #-1 表示这个维度的值是从x的元素总数和剩余维度推断出来的,有且只能有一个维度设置为-1
19 # print(x.shape)
20 x = self.linear1(x)
21 x = self.relu1(x)
22 # print('1', x.shape)
23 x = self.linear2(x)
24 x = self.relu2(x)
25 # print('2',x.shape)
26 x = self.linear3(x)
27 x = self.relu3(x)
28 # print('3',x.shape)
29 y = self.linear4(x)
30 # print('4',y.shape)
31 return y
步骤3:训练神经网络模型
1 # # 3、训练模型
2
3 # In[12]:
4
5
6 model=MyDNN() #模型实例化
7 model.train() #训练模式
8 cross_entropy = paddle.nn.CrossEntropyLoss()
9 opt=paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
10
11 epochs_num=train_parameters['num_epochs'] #迭代次数
12 for pass_num in range(train_parameters['num_epochs']):
13 for batch_id,data in enumerate(train_loader()):
14 image = data[0]
15 label = data[1]
16
17 predict=model(image) #数据传入model
18
19 loss=cross_entropy(predict,label)
20 acc=paddle.metric.accuracy(predict,label)#计算精度
21
22 if batch_id!=0 and batch_id%5==0:
23 Batch = Batch+5
24 Batchs.append(Batch)
25 all_train_loss.append(loss.numpy()[0])
26 all_train_accs.append(acc.numpy()[0])
27
28 print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,loss.numpy(),acc.numpy()))
29
30 loss.backward()
31 opt.step()
32 opt.clear_grad() #opt.clear_grad()来重置梯度
33
34 paddle.save(model.state_dict(),'MyDNN')#保存模型
35
36 draw_train_acc(Batchs,all_train_accs)
37 draw_train_loss(Batchs,all_train_loss)
这里调用了两个方法画出训练准确率和损失率的图像,其画图方法定义为:
1 #定义了准确率和损失率的画法
2 Batch=0
3 Batchs=[]
4 all_train_accs=[]
5 def draw_train_acc(Batchs, train_accs):
6 title="training accs"
7 plt.title(title, fontsize=24)
8 plt.xlabel("batch", fontsize=14)
9 plt.ylabel("acc", fontsize=14)
10 plt.plot(Batchs, train_accs, color='green', label='training accs')
11 plt.legend()
12 plt.grid()
13 plt.show()
14
15 all_train_loss=[]
16 def draw_train_loss(Batchs, train_loss):
17 title="training loss"
18 plt.title(title, fontsize=24)
19 plt.xlabel("batch", fontsize=14)
20 plt.ylabel("loss", fontsize=14)
21 plt.plot(Batchs, train_loss, color='red', label='training loss')
22 plt.legend()
23 plt.grid()
24 plt.show()

步骤4:对模型进行评估
#模型评估
para_state_dict = paddle.load("MyDNN")
model = MyDNN()
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #验证模式
accs = []
for batch_id,data in enumerate(eval_loader()):#测试集
image=data[0]
label=data[1]
predict=model(image)
acc=paddle.metric.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print("当前模型在验证集上的准确率为:",avg_acc)

步骤5:预测新的宝石图像
1 '''
2 模型预测
3 '''
4 para_state_dict = paddle.load("MyDNN")
5 model = MyDNN()
6 model.set_state_dict(para_state_dict) #加载模型参数
7 model.eval() #训练模式
8
9 #展示预测图片
10 infer_path='/home/aistudio/data/archive_test/alexandrite_3.jpg'
11 img = Image.open(infer_path)
12 plt.imshow(img) #根据数组绘制图像
13 plt.show() #显示图像
14
15 #对预测图片进行预处理
16 infer_imgs = []
17 infer_imgs.append(load_image(infer_path))
18 infer_imgs = np.array(infer_imgs)
19
20 label_dic = train_parameters['label_dict']
21
22 for i in range(len(infer_imgs)):
23 data = infer_imgs[i]
24 dy_x_data = np.array(data).astype('float32')
25 dy_x_data=dy_x_data[np.newaxis,:, : ,:]
26 img = paddle.to_tensor (dy_x_data)
27 out = model(img)
28 lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
29
30 print("第{}个样本,被预测为:{},真实标签为:{}".format(i+1,label_dic[str(lab)],infer_path.split('/')[-1].split("_")[0]))
31
32 print("结束")

完整的代码如下所示:
1 #!/usr/bin/env python
2 # coding: utf-8
3
4 # # **任务描述:**
5 #
6 # ### 本次实践是一个多分类任务,需要将照片中的宝石分别进行识别,完成**宝石的识别**
7 #
8 # ### **实践平台:百度AI实训平台-AI Studio、PaddlePaddle2.0.0 动态图**
9 #
10 #
11 # 
12 #
13
14 # # 深度神经网络(DNN)
15 #
16 # ### **深度神经网络(Deep Neural Networks,简称DNN)是深度学习的基础,其结构为input、hidden(可有多层)、output,每层均为全连接。**
17 # 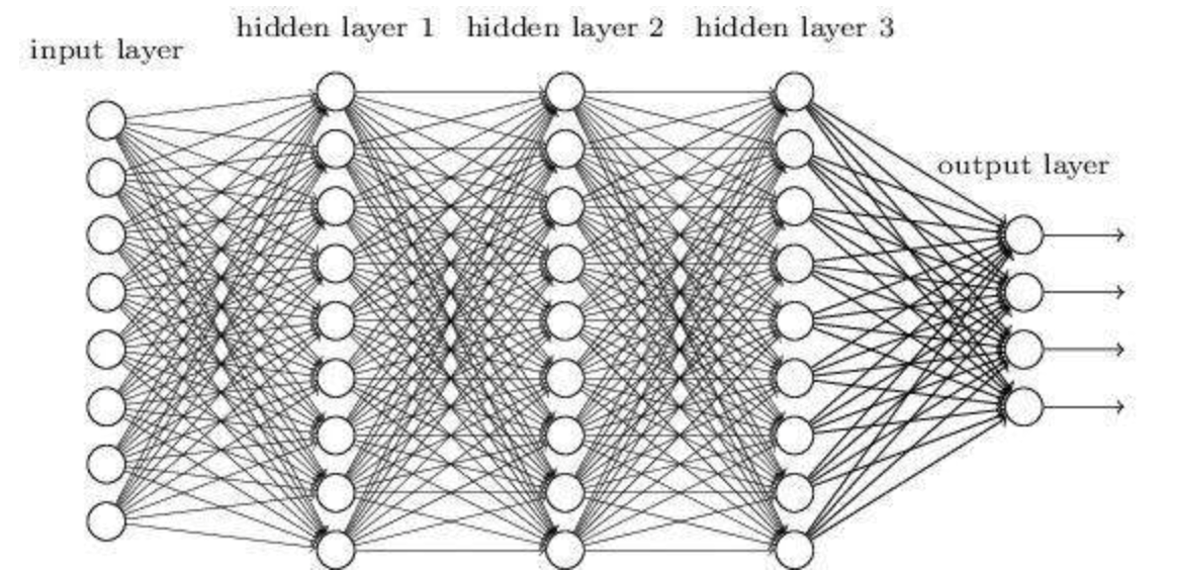
18 #
19 #
20
21 # # 数据集介绍
22 #
23 # * **数据集文件名为archive_train.zip,archive_test.zip。**
24 #
25 # * **该数据集包含25个类别不同宝石的图像。**
26 #
27 # * **这些类别已经分为训练和测试数据。**
28 #
29 # * **图像大小不一,格式为.jpeg。**
30 #
31 #
32 # 
33 #
34
35 # In[1]:
36
37
38 # 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
39 # View dataset directory. This directory will be recovered automatically after resetting environment.
40 # get_ipython().system('ls /home/aistudio/data')
41
42
43 # In[2]:
44
45
46 #导入需要的包
47 import os
48 import zipfile
49 import random
50 import json
51 import cv2
52 import numpy as np
53 from PIL import Image
54 import paddle
55 import matplotlib.pyplot as plt
56 from paddle.io import Dataset
57
58
59 # # 1、数据准备
60
61 # In[3]:
62
63
64 '''
65 参数配置
66 '''
67 train_parameters = {
68 "input_size": [3, 224, 224], #输入图片的shape
69 "class_dim": -1, #分类数
70 "src_path":"data/data55032/archive_train.zip", #原始数据集路径
71 "target_path":"/home/aistudio/data/dataset", #要解压的路径
72 "train_list_path": "./train.txt", #train_data.txt路径
73 "eval_list_path": "./eval.txt", #eval_data.txt路径
74 "label_dict":{}, #标签字典
75 "readme_path": "/home/aistudio/data/readme.json", #readme.json路径
76 "num_epochs": 1, #训练轮数
77 "train_batch_size": 16, #批次的大小
78 "learning_strategy": { #优化函数相关的配置
79 "lr": 0.001 #超参数学习率
80 }
81 }
82
83
84
85 # In[4]:
86
87
88 def unzip_data(src_path,target_path):
89
90 '''
91 解压原始数据集,将src_path路径下的zip包解压至data/dataset目录下
92 '''
93
94 if(not os.path.isdir(target_path)):
95 z = zipfile.ZipFile(src_path, 'r')
96 z.extractall(path=target_path)
97 z.close()
98 else:
99 print("文件已解压")
100
101
102 # In[5]:
103
104
105 def get_data_list(target_path,train_list_path,eval_list_path):
106 '''
107 生成数据列表
108 '''
109 #存放所有类别的信息
110 class_detail = []
111 #获取所有类别保存的文件夹名称
112 data_list_path=target_path
113 class_dirs = os.listdir(data_list_path)
114 if '__MACOSX' in class_dirs:
115 class_dirs.remove('__MACOSX')
116 # #总的图像数量
117 all_class_images = 0
118 # #存放类别标签
119 class_label=0
120 # #存放类别数目
121 class_dim = 0
122 # #存储要写进eval.txt和train.txt中的内容
123 trainer_list=[]
124 eval_list=[]
125 #读取每个类别
126 for class_dir in class_dirs:
127 if class_dir != ".DS_Store":
128 class_dim += 1
129 #每个类别的信息
130 class_detail_list = {}
131 eval_sum = 0
132 trainer_sum = 0
133 #统计每个类别有多少张图片
134 class_sum = 0
135 #获取类别路径
136 path = os.path.join(data_list_path,class_dir)
137 # 获取所有图片
138 img_paths = os.listdir(path)
139 for img_path in img_paths: # 遍历文件夹下的每个图片
140 if img_path =='.DS_Store':
141 continue
142 name_path = os.path.join(path,img_path) # 每张图片的路径
143 if class_sum % 15 == 0: # 每10张图片取一个做验证数据
144 eval_sum += 1 # eval_sum为测试数据的数目
145 eval_list.append(name_path + "\t%d" % class_label + "\n")
146 else:
147 trainer_sum += 1
148 trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
149 class_sum += 1 #每类图片的数目
150 all_class_images += 1 #所有类图片的数目
151
152 # 说明的json文件的class_detail数据
153 class_detail_list['class_name'] = class_dir #类别名称
154 class_detail_list['class_label'] = class_label #类别标签
155 class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
156 class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
157 class_detail.append(class_detail_list)
158 #初始化标签列表
159 train_parameters['label_dict'][str(class_label)] = class_dir
160 class_label += 1
161
162 #初始化分类数
163 train_parameters['class_dim'] = class_dim
164 print(train_parameters)
165 #乱序
166 random.shuffle(eval_list)
167 with open(eval_list_path, 'a') as f:
168 for eval_image in eval_list:
169 f.write(eval_image)
170 #乱序
171 random.shuffle(trainer_list)
172 with open(train_list_path, 'a') as f2:
173 for train_image in trainer_list:
174 f2.write(train_image)
175
176 # 说明的json文件信息
177 readjson = {}
178 readjson['all_class_name'] = data_list_path #文件父目录
179 readjson['all_class_images'] = all_class_images
180 readjson['class_detail'] = class_detail
181 jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
182 with open(train_parameters['readme_path'],'w') as f:
183 f.write(jsons)
184 print ('生成数据列表完成!')
185
186
187 # In[6]:
188
189
190 '''
191 参数初始化
192 '''
193 src_path=train_parameters['src_path']
194 target_path=train_parameters['target_path']
195 train_list_path=train_parameters['train_list_path']
196 eval_list_path=train_parameters['eval_list_path']
197 batch_size=train_parameters['train_batch_size']
198 '''
199 解压原始数据到指定路径
200 '''
201 unzip_data(src_path,target_path)
202
203 '''
204 划分训练集与验证集,乱序,生成数据列表
205 '''
206 #每次生成数据列表前,首先清空train.txt和eval.txt
207 with open(train_list_path, 'w') as f:
208 f.seek(0)
209 f.truncate()
210 with open(eval_list_path, 'w') as f:
211 f.seek(0)
212 f.truncate()
213
214 #生成数据列表
215 get_data_list(target_path,train_list_path,eval_list_path)
216
217
218 # In[7]:
219
220
221 class Reader(Dataset):
222 def __init__(self, data_path, mode='train'):
223 """
224 数据读取器
225 :param data_path: 数据集所在路径
226 :param mode: train or eval
227 """
228 super().__init__()
229 self.data_path = data_path
230 self.img_paths = []
231 self.labels = []
232
233 if mode == 'train':
234 with open(os.path.join(self.data_path, "train.txt"), "r", encoding="utf-8") as f:
235 self.info = f.readlines()
236 for img_info in self.info:
237 img_path, label = img_info.strip().split('\t')
238 self.img_paths.append(img_path)
239 self.labels.append(int(label))
240
241 else:
242 with open(os.path.join(self.data_path, "eval.txt"), "r", encoding="utf-8") as f:
243 self.info = f.readlines()
244 for img_info in self.info:
245 img_path, label = img_info.strip().split('\t')
246 self.img_paths.append(img_path)
247 self.labels.append(int(label))
248
249
250 def __getitem__(self, index):
251 """
252 获取一组数据
253 :param index: 文件索引号
254 :return:
255 """
256 # 第一步打开图像文件并获取label值
257 img_path = self.img_paths[index]
258 img = Image.open(img_path)
259 if img.mode != 'RGB':
260 img = img.convert('RGB')
261 img = img.resize((224, 224), Image.BILINEAR)
262 img = np.array(img).astype('float32')
263 img = img.transpose((2, 0, 1)) / 255
264 label = self.labels[index]
265 label = np.array([label], dtype="int64")
266 return img, label
267
268 def print_sample(self, index: int = 0):
269 print("文件名", self.img_paths[index], "\t标签值", self.labels[index])
270
271 def __len__(self):
272 return len(self.img_paths)
273
274
275 # In[8]:
276
277
278 train_dataset = Reader('./',mode='train')
279
280 eval_dataset = Reader('./',mode='eval')
281
282 #训练数据加载
283 train_loader = paddle.io.DataLoader(train_dataset, batch_size=16, shuffle=True)
284 #测试数据加载
285 eval_loader = paddle.io.DataLoader(eval_dataset, batch_size = 8, shuffle=False)
286
287
288 # In[9]:
289
290
291 train_dataset.print_sample(200)
292 print(train_dataset.__len__())
293 eval_dataset.print_sample(0)
294 print(eval_dataset.__len__())
295 print(eval_dataset.__getitem__(10)[0].shape)
296 print(eval_dataset.__getitem__(10)[1].shape)
297
298
299 # In[10]:
300
301 #定义了准确率和损失率的画法
302 Batch=0
303 Batchs=[]
304 all_train_accs=[]
305 def draw_train_acc(Batchs, train_accs):
306 title="training accs"
307 plt.title(title, fontsize=24)
308 plt.xlabel("batch", fontsize=14)
309 plt.ylabel("acc", fontsize=14)
310 plt.plot(Batchs, train_accs, color='green', label='training accs')
311 plt.legend()
312 plt.grid()
313 plt.show()
314
315 all_train_loss=[]
316 def draw_train_loss(Batchs, train_loss):
317 title="training loss"
318 plt.title(title, fontsize=24)
319 plt.xlabel("batch", fontsize=14)
320 plt.ylabel("loss", fontsize=14)
321 plt.plot(Batchs, train_loss, color='red', label='training loss')
322 plt.legend()
323 plt.grid()
324 plt.show()
325
326
327 # # 2、定义模型
328
329 # In[11]:
330
331
332 #定义DNN网络
333 class MyDNN(paddle.nn.Layer):
334 def __init__(self):
335 super(MyDNN,self).__init__()
336 self.linear1 = paddle.nn.Linear(in_features=3*224*224, out_features=1024)
337 self.relu1 = paddle.nn.ReLU()
338
339 self.linear2 = paddle.nn.Linear(in_features=1024, out_features=512)
340 self.relu2 = paddle.nn.ReLU()
341
342 self.linear3 = paddle.nn.Linear(in_features=512, out_features=128)
343 self.relu3 = paddle.nn.ReLU()
344
345 self.linear4 = paddle.nn.Linear(in_features=128, out_features=25)
346
347 def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑
348 # input.shape (16, 3, 224, 224)
349 x = paddle.reshape(input, shape=[-1,3*224*224]) #-1 表示这个维度的值是从x的元素总数和剩余维度推断出来的,有且只能有一个维度设置为-1
350 # print(x.shape)
351 x = self.linear1(x)
352 x = self.relu1(x)
353 # print('1', x.shape)
354 x = self.linear2(x)
355 x = self.relu2(x)
356 # print('2',x.shape)
357 x = self.linear3(x)
358 x = self.relu3(x)
359 # print('3',x.shape)
360 y = self.linear4(x)
361 # print('4',y.shape)
362 return y
363
364
365 # # 3、训练模型
366
367 # In[12]:
368
369
370 model=MyDNN() #模型实例化
371 model.train() #训练模式
372 cross_entropy = paddle.nn.CrossEntropyLoss()
373 opt=paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
374
375 epochs_num=train_parameters['num_epochs'] #迭代次数
376 for pass_num in range(train_parameters['num_epochs']):
377 for batch_id,data in enumerate(train_loader()):
378 image = data[0]
379 label = data[1]
380
381 predict=model(image) #数据传入model
382
383 loss=cross_entropy(predict,label)
384 acc=paddle.metric.accuracy(predict,label)#计算精度
385
386 if batch_id!=0 and batch_id%5==0:
387 Batch = Batch+5
388 Batchs.append(Batch)
389 all_train_loss.append(loss.numpy()[0])
390 all_train_accs.append(acc.numpy()[0])
391
392 print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,loss.numpy(),acc.numpy()))
393
394 loss.backward()
395 opt.step()
396 opt.clear_grad() #opt.clear_grad()来重置梯度
397
398 paddle.save(model.state_dict(),'MyDNN')#保存模型
399
400 draw_train_acc(Batchs,all_train_accs)
401 draw_train_loss(Batchs,all_train_loss)
402
403
404 # # 4、模型评估
405
406 # In[13]:
407
408
409 #模型评估
410 para_state_dict = paddle.load("MyDNN")
411 model = MyDNN()
412 model.set_state_dict(para_state_dict) #加载模型参数
413 model.eval() #验证模式
414
415 accs = []
416
417 for batch_id,data in enumerate(eval_loader()):#测试集
418 image=data[0]
419 label=data[1]
420 predict=model(image)
421 acc=paddle.metric.accuracy(predict,label)
422 accs.append(acc.numpy()[0])
423 avg_acc = np.mean(accs)
424 print("当前模型在验证集上的准确率为:",avg_acc)
425
426
427 # # 5、模型预测
428
429 # In[14]:
430
431
432 import os
433 import zipfile
434
435 def unzip_infer_data(src_path,target_path):
436 '''
437 解压预测数据集
438 '''
439 if(not os.path.isdir(target_path)):
440 z = zipfile.ZipFile(src_path, 'r')
441 z.extractall(path=target_path)
442 z.close()
443
444
445 def load_image(img_path):
446 '''
447 预测图片预处理
448 '''
449 img = Image.open(img_path)
450 if img.mode != 'RGB':
451 img = img.convert('RGB')
452 img = img.resize((224, 224), Image.BILINEAR)
453 img = np.array(img).astype('float32')
454 img = img.transpose((2, 0, 1)) # HWC to CHW
455 img = img/255 # 像素值归一化
456 return img
457
458
459 infer_src_path = '/home/aistudio/data/data55032/archive_test.zip'
460 infer_dst_path = '/home/aistudio/data/archive_test'
461 unzip_infer_data(infer_src_path,infer_dst_path)
462
463
464 # In[15]:
465
466
467 '''
468 模型预测
469 '''
470 para_state_dict = paddle.load("MyDNN")
471 model = MyDNN()
472 model.set_state_dict(para_state_dict) #加载模型参数
473 model.eval() #训练模式
474
475 #展示预测图片
476 infer_path='/home/aistudio/data/archive_test/alexandrite_3.jpg'
477 img = Image.open(infer_path)
478 plt.imshow(img) #根据数组绘制图像
479 plt.show() #显示图像
480
481 #对预测图片进行预处理
482 infer_imgs = []
483 infer_imgs.append(load_image(infer_path))
484 infer_imgs = np.array(infer_imgs)
485
486 label_dic = train_parameters['label_dict']
487
488 for i in range(len(infer_imgs)):
489 data = infer_imgs[i]
490 dy_x_data = np.array(data).astype('float32')
491 dy_x_data=dy_x_data[np.newaxis,:, : ,:]
492 img = paddle.to_tensor (dy_x_data)
493 out = model(img)
494 lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
495
496 print("第{}个样本,被预测为:{},真实标签为:{}".format(i+1,label_dic[str(lab)],infer_path.split('/')[-1].split("_")[0]))
497
498 print("结束")
数据集的话关注,私聊我!!!!!!
标签:宝石,img,self,神经网络,train,深度,path,data,class From: https://www.cnblogs.com/caizhou520/p/17810369.html