【NeurIPS 2022】SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
1、研究动机
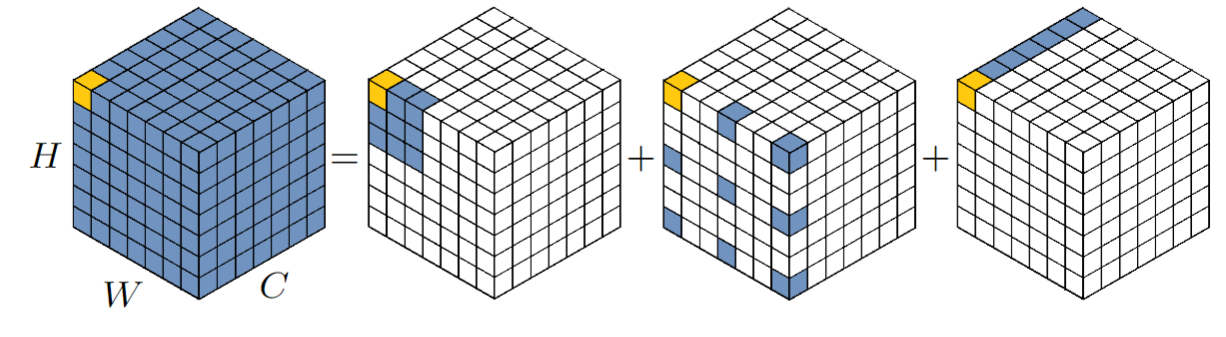
来自清华大学国孟昊博士的论文,可以理解为大核卷积 large kernel attention 的扩展,该方法是在 Visual Attention Network 这篇论文中提出,思想是:用 大核卷积 来替换 Transformer 模型中的 attention。 具体如下图所示,一个标准的卷积可以用 depth-wise conv、depth-wise dilation conv、pointwise conv 来替换。图中展示了一个13x13的大核卷积计算非常复杂,可以用一个 5x5 的 DWConv,空洞为3的 DW-Dilated Conv,以及 1x1x13 的点卷积来取代。
把这个思想用来改进用于语义分割的 SegFormer ,就是本文所提出的 SegNeXt,效果非常好。
2、方法介绍
SegFormer 是NeurIPS 2021 提出的方法,如下图所示,是一个 encoder-decoder 结构,encoder 部分是标准的 Transformer,decoder 把之前输出的特征拼接,然后利用MLP得到最终输出。
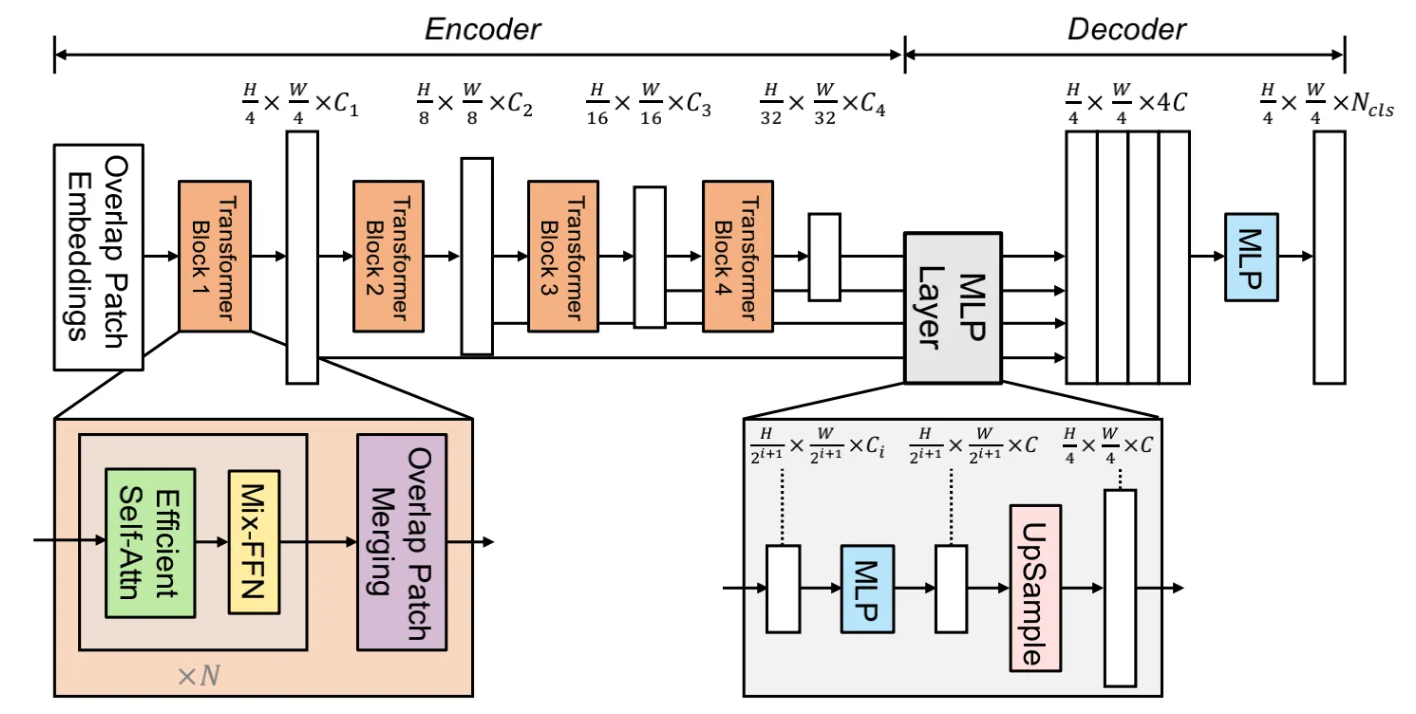
本文提出的 SegNeXt,主要改进了两部分:1)encoder 里 Transformer 结构的 attention 使用多尺度卷积注意力替换;2)改进了 decoder 的结构。
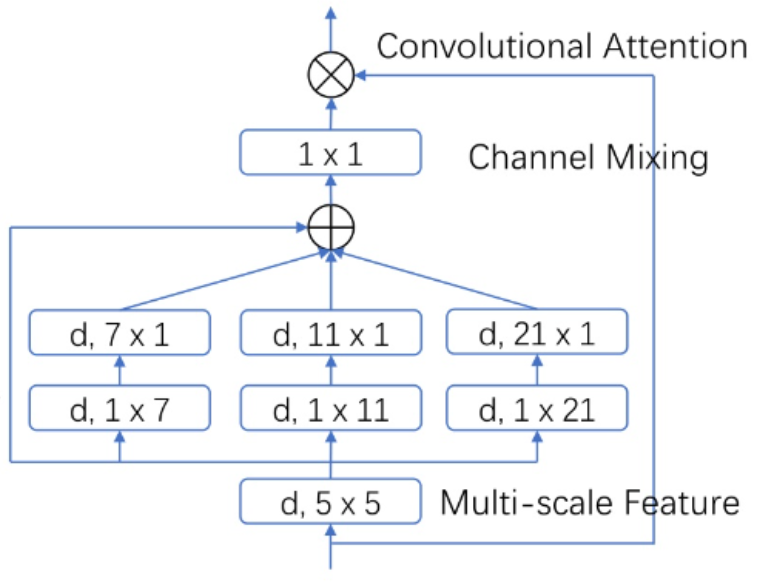
SegNeXt 里面应用的 attention 如下图所示,和 LKA 非常类似,只不过中间的 depth-wise dilated conv 替换为三个并行的多尺度条形卷积,分别为 1x7, 1x11, 1x21 。
代码如下:
class AttentionModule(BaseModule):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * u
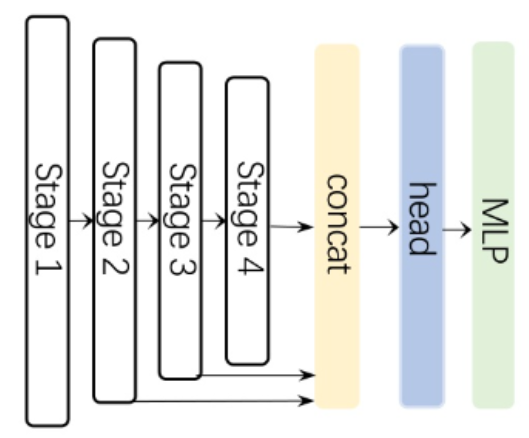
decoder 的改进相对较小,如下图所示,stage 1 的特征没有输入。同时,使用 Hamburger 注意力来处理。
实验部分可以参考作进行论文,这里不过多介绍。
标签:Convolutional,Rethinking,Segmentation,nn,dim,self,attn,SegNeXt,Conv2d From: https://www.cnblogs.com/gaopursuit/p/16756181.html