结构
Transformer 由两个模块构成,分别为编码器模块与解码器模块。如图 I 所示,编码器模块是若干个 encoder 组件堆在一起,同样解码器模块也是若干个 decoder 组件堆在一起(原始文章中都是 6 个,可能比较吉利吧)。
当一个输入 sentence(不妨叫做小 s) 进入到编码器中,小 s 首先会进入到一个自注意力层,这一层的作用是帮助编码器关注与一个需要编码的词相关的其他词汇。自注意力层的输出会传递给一个前馈神经网络。
图 I
![]()
解码器组件也含有编码器中包含的两个层,此外,在这两个层之间还夹了一个注意力层,这个注意力层的作用是让解码器能够注意到输入句子中相关的部分(和seq2seq 中的 attention 一样的作用)。
图 II
自注意力
当模型编码每个位置上的单词的时候,自注意力的作用就是:关注一下输入句子中其他位置的单词,试图寻找一种对当前单词更好的编码方式。
通过 Tensor2Tensor 感受一下可视化过程。
谈到注意力机制,就少不了 QKV 注意力。 这种注意力只是注意力机制的一个变体,常用的还有点集注意力(dot-product attention)、强注意力(hard attention)、软注意力(soft attention)、自注意力(self attention)、交叉注意力(cross attention)、Luong 注意力、Bahdanau 注意力等。
那么,在 Transformer 中自注意力是如何计算的呢?
- 对编码器的每一个输入都计算三个向量,分别为 query, key, value。
计算过程很简单,即把输入向量与三个权重矩阵相乘,即得到相关的向量。 这三个权重矩阵是通过模型训练获取得到。
在文章中,嵌入向量、编码器的输入输出维度是 512 维,但这里的 query, key, value 三个向量维度是64,比嵌入向量的维度小。维度上的减小不是必需的,这样做主要是为了让多头注意力的计算更稳定。
将 $x_1$ 和 $W^Q$ 权重矩阵相乘得到 $q_1$, 就得到与该单词 $x_1$ 相关的查询(query),使用这样的方法,最终我们给输入的每一个单词都计算出一个 query, key 及 value 向量。
- 计算注意力得分。
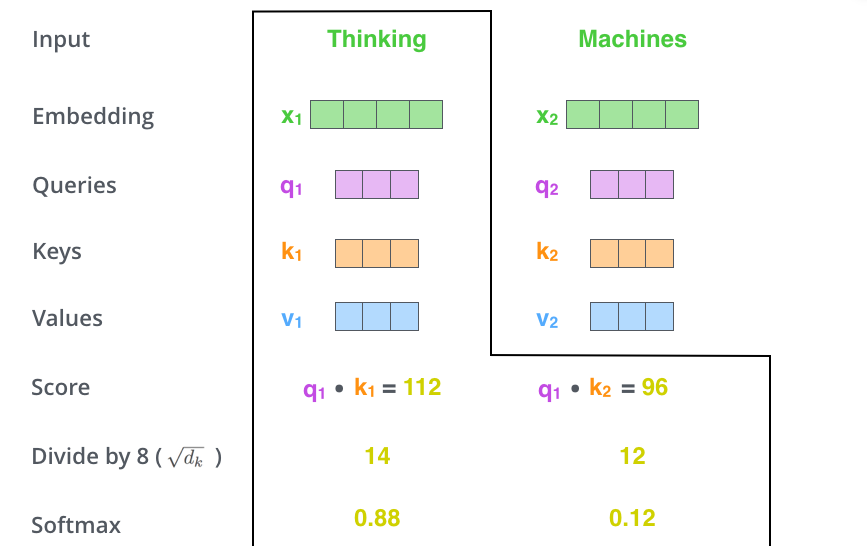
假设我们的输入是 "Happy birthday to this future president.",如何才算计算得到第一个单词 Happy 的自注意力?
我们需要使用自注意力给输入句子中的每个单词打分,这个分数决定当我们编码某个位置的单词的时候,应该对其他位置上的单词给予多少关注度。这个得分是 query 和 key 的点乘积得出来的,其中 query 即 Happy 对应的向量 $q_1$,key 是输入句子中其他位置的单词的 key 向量。点积刻画了二者的相似程度,因此,点积越大,说明 query 和 key 的相似程度越高,得分越高。
举个栗子,计算第一个位置的注意力得分时,就要将第一个单词的 query 和其他的 key 依次相乘,即 $s_1 = q_1 \cdot k_1 + q_1 \cdot k_2 + q_1 \cdot k_3 + ... + q_1 \cdot k_n$。
- 计算注意力权重。
将计算获得的注意力分数除以向量维度的平方根(本例中即为 8),除 8 是为了让梯度计算的时候更稳定。默认是这么设置的,当然也可以用其他值。然后将分数通过 softmax 函数转换为概率,即得到注意力权重。
图 III
- 计算注意力输出。 将每个 value 向量乘以注意力分数,得到一下值 $v_1$。再对这些 value 向量求和,即得到自注意力层的输出 $z_1 = s_1 \cdot v_1 + s_2 \cdot v_2 + s_3 \cdot v_3 + ... + s_n \cdot v_n$,如下图 IV 所示 。
图 IV
多头注意力
论文进一步改进了自注意力层,增加了一个机制,也就是多头注意力机制(Multi Head Attention)。这样做有两个好处:
-
它扩展了模型专注于不同位置的能力。在上面例子里只计算一个自注意力的的例子中,编码 “Thinking” 的时候,虽然最后 $z_1$ 或多或少包含了其他位置单词的信息,但是它实际编码中还是被 “Thinking” 单词本身所主导。
-
它给了注意层多个“表示子空间”。在多头注意力中同时用多个不同的 $W_Q, W_K, W_V$ 权重矩阵( Transformer 使用8个头部,因此我们最终会得到 8 个计算结果),每个权重都是随机初始化的。经过训练每个 $W_Q, W_K, W_V$ 都能将输入的矩阵投影到不同的表示子空间。
图 V
Transformer 中的一个多头注意力(有8个head)的计算,就相当于用自注意力做 8 次不同的计算,并得到 8 个不同的结果 $Z$ (参考上图 V)。
但是这会存在一点问题,多头注意力出来的结果会进入一个前馈神经网络,这个前馈神经网络不能一下接收 8 个注意力矩阵,它的输入需要是单个矩阵(每个行向量对应一个单词),所以我们需要一种方法把这 8 个压缩成一个矩阵。怎么做呢?我们将这些矩阵连接起来,然后将乘以一个附加的权重矩阵 $W_O$,如下图 VI 所示。
图 VI
将以上所有步骤放在一起,我们就得到了多头注意力的计算过程,如下图 VII 所示。
图 VII
参考:
- 图解 Transformer, https://juejin.cn/post/7148332180526071821
- 上文原文链接, http://jalammar.github.io/illustrated-transformer/
- 位置编码详解, https://juejin.cn/post/7104032826357448711