@
目录
一 前言
近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。
二 背景
基于分割的方法也分为多分类语义分割、实例分割/二分类语义分割+聚类这两种方式,前者具有一定局限性,必须预定义固定或最大车道线数;后者可以检测可变数量的车道线,但是聚类方法会很大程度上影响检测性能。
语义分割方法目前已经可以达到很好的效果,基于语义分割的车道线检测基本也是沿用一些分割baseline, 而主要改进多是对聚类方法做文章。
Affinity fields一开始是在CVPR2017 "Realtime Multi-Person 2D Human Pose Estimation using Part Affinity Fields" 中用于解决关键点的聚类,由编码location和orientation的单位向量组成。
三 DLA34

更多的非线性操作、更大的网络往往能提高模型性能,bottleneck、residual block、concatenative connection等模块的出现,进一步增强了网络的性能和可实现性,网络架构也从最初的串行连接逐渐演变成包含skip connection的形式。
当前流行的skip connection结构过于单一,因此设计了IDA(Iterative Deep Aggregation)和HDA(Hierarchical Deep Aggregation)两个结构,作为对skip connection的扩展,能够更好地融合语义和空间特征。
3.1 IDA(Iterative Deep Aggregation)
为便于叙述,作者将CNN架构进行模块化拆分,1个CNN由多个stage组成,1个stage由多个block组成,每个block包含多个layer,用下面的图标表示block和stage:

传统的串行连接的CNN如下图所示:

为了融合浅层的底层信息和深层的语义信息,引入从浅层向深层的skip connection,如下图所示:

在此基础上,提出了IDA(Iterative Deep Aggregation)模块,结构如下:
上图中绿色的方块称作“Aggregation Node”,Aggregation Node在特征由浅到深传播的同时聚集特征。

3.2 HDA (Hierarchical Deep Aggregation)
IDA能够有效融合多个stage的特征,但是没有对stage内部多个block的特征进行融合。作者提出了HDA(Hierarchical Deep Aggregation)结构增强stage内部多个block的融合,如下图所示:

3.3 结合
将上述的IDA和HDA结合,形成下图所示的DLA(Deep Layer Aggregation)结构:
上图中每个红色框可以看作1个stage,使用IDA连接多个不同的stage,使用HDA融合stage内部的特征,IDA和HDA共享Aggregation Node。上图中包含4个stage,与ResNet类似,每个stage之间会进行降采样操作。这里使用kernel size为2、步长为2的max pooling进行降采样。
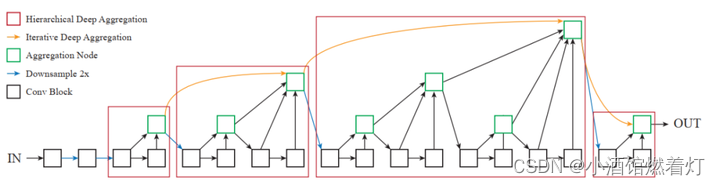
DLA是一个通用的架构,可以很方便地融合到现有的CNN结构中来完成多种计算机视觉任务。
四 BEV视角
BEV的优势:
- 简化的视角: BEV将三维空间简化为二维,这样可以在计算和存储上节省大量资源。
- 视觉效果: BEV提供了一种独特的视觉效果,使得场景中的物体和空间关系更加清晰可见。
- 方便处理: 在BEV中处理物体检测、跟踪和分类等任务相较于直接在原始3D数据中处理要简单得多。
- 便于融合和下游任务处理:与lidar融合更为方便,对下游路径规划控制等任务也更友好。通用坐标系
- 尺度一致:相机检测会出现近大远小的情况,BEV同类目标尺度差异几乎没有,更容易学习特征尺度一致性。
BEV诞生前方案
4.1 逆透视变换(IPM)
在前视摄像头拍摄的图像中,由于透视效应的存在,本来平行的事物,在图像中确实相交的。而IPM变换就是消除这种透视效应,所以也叫逆透视。


4.2 完全分割掩模与脚印分割
这里涉及到图像处理和计算机视觉中的概念,特别是关于Bird's Eye View (BEV) 的透视转换。根据您提供的内容,我为您提供以下中文解释:
- full segmentation mask:完全分割掩模会导致在鸟瞰视图(BEV)中地面以上的像素拉伸。
- 当我们从一般的摄像机透视图转换到鸟瞰视图(俯视图)时,物体的高度与其在BEV中的表示有关。完全分割掩模在转换过程中没有考虑到这一点,从而导致地面以上的像素(例如树、建筑物、行人等)在鸟瞰视图中被拉伸。
- footprint segmentation:脚印分割遵循由单应性(homography)所暗示的平坦世界假设,避免了由于地面以上的像素引起的失真。
- 脚印分割考虑到了只有与地面接触的部分(即物体的“脚印”)应当被纳入BEV,因为这部分遵循单应性转换的平坦世界假设。这样,地面以上的像素(例如物体的上部)就不会被错误地拉伸或扭曲。
这两种方法的主要区别在于它们如何处理与地面非接触部分的像素。完全分割掩模可能会导致这些像素在鸟瞰视图中扭曲,而脚印分割则避免了这种扭曲。
五 LaneAF结构
5.1 三个检测头
首先输入图片经过以DLA-34作为backbone的网络,预测出二值车道线分割masks 以及 per-pixel的horizontal affinity field (HAF) and vertical affinity field (VAF)。而这两个affinity fields用来将前景像素聚类为不同的lanes作为一个post-processing step。二值分割头shape=(b, c, h, w),haf头shape(b, 1, h, w),vaf头(b, 2, h, w)。

手写AI中林哥提到:
- 二值图指定一个合适的阈值,就可以得到如上图的二值图
- 使用HAF、VAF,结合二值分割结果,能够在后处理中对任意数量的车道线进行聚类,得到多个车道线实例
- 一个车道线同一个实例,解码后按照像素级别去预测,看预测那个类别达到要求就预测为哪一类。这一步属于后处理部分。
5.2 Pipeline过程
LaneAF pipeline包括两个阶段: CNN 骨干网的前向过程和使用亲和力场对pipeline实例进行解码:

(i)顶部:用于二值分割掩码的DLA-34主干,以及预测的垂直亲和场和水平亲和场。(ii) Down:亲和域解码器。它从关联字段推断生成车道实例。
六 亲合场(Affinity Fields)
可以看做是一个向量场,或者向量函数,可以将图像平面的任何2D位置映射到2D中的单位向量。使用了两种Affinity Field,分别是Horizontal Affinity Field (HAF)和Vertical Affinity Field (VAF)。HAF中的单位向量指向当前行中车道线的中心,因此可以聚类任意宽度的车道线;而VAF中的单位向量对其上方的下一组车道线像素所在的位置进行编码。
6.1 亲合场生成(计算亲和力场真值)
数据集提供了segmentation label,需要对segmentation label(灰度图0 1 2 3 4 )预生成HAF和VAF label。对于任何给定的图像,HAF 和 VAF 可以被认为是向量场H(·, ·) 和 V (·, ·),它们为图像中的每个 (x, y) 位置分別分配一个单位向量。
Horizontal Affinity Field (HAF)生成:

$$\begin{aligned}
\vec{H}{gt}(x^{l},y)& =\left(\frac{\overline{x}yl-x_il}{|\overline{x}yl-x_il|},\frac{y-y}{|y-y|}\right)^\intercal \
&=\left(\frac{\overline{x}l-x_{i}l}{|\overline{x}l-x_{i}l|},0\right)^\intercal,
\end{aligned}$$
- 上图中绿色框表示属于车道线l的点,蓝色框表示属于车道线l+1的点。箭头表示某个位置处HAF中的向量。
- 对于车道线l第y行上的点$(x_i^y, y)$它的水平单位向量只有三种可能(+1/-1/0,0)。$\overline{x}_y^l$表示车道I第y行的x坐标的均值,可以看做是车道I第y行所有坐标的中心点,那么车道I第y行所有像素点的水平向量为中心点和当前点得向量。
Vertical Affinity Field (VAF)生成:
对于图像第y行中属于车道线l的每个点$\left(x_{i}^{l}, y\right)$,VAF由下式得到:
$$\begin{gathered}
\vec{V}{gt}(x^{l},y) =\left(\frac{\overline{x}{y-1}l-x_il}{|\overline{x}l-x_il|},\frac{y-1-y}{|y-1-y|}\right)^\intercal \
=\left(\frac{\overline{x}{y-1}l-x_il}{|\overline{x}l-x_il|},-1\right)^\intercal
\end{gathered}$$
上式中的$\bar{x}_{y-1}^{l}$表示第y-1行中属于车道线l的所有点的横坐标平均值。求解VAF的过程如下图所示:

代码展示:代码可从手写AI获得。
def generateAFs(label, viz=False):
# 创建透视场数组
num_lanes = np.amax(label) # 获取车道线的数量
VAF = np.zeros((label.shape[0], label.shape[1], 2)) # 垂直透视场
HAF = np.zeros((label.shape[0], label.shape[1], 1)) # 水平透视场
# 对每条车道线进行循环处理
for l in range(1, num_lanes+1):
# 初始化先前的行和列值
...
# 从下到上解析每一行
for row in range(label.shape[0]-1, -1, -1):
# 为每个列值生成水平方向向量
for c in cols:
...
# 检查先前的列和当前的列是否都非空
if prev_cols.size == 0: # 如果没有先前的行/列,更新并继续
...
# 为先前的列生成垂直方向向量
for c in prev_cols:
...
# 使用当前的行和列值更新先前的行和列值
...
6.2 亲合场的解码
网络训练完成后,在推理时利用HAF和VAF、结合二值分割结果进行聚类以得到车道线实例。
Affinity Field 解码过程相较于编码过程要复杂一些。使用网络预测的 HAF和VAF来将二元分割mask中的前景像素聚类为不同的车道线。
流程也是自底向上逐行扫描,在对每一行的前景像素进行处理时,首先利用HAF对像素进行水平方向的聚类得到 clusters,然后利用VAF将clusters与已有的active lanes 进行匹配,匹配上的 clusters 会更新对应的active lanes没有匹配上的 clusters 会作为新的active lanes。
逐行聚类: 令$\vec{H}{\text {pred }}$表示HAF的预测结果,对于第y-1行,上图中$c^{*}$的计算公式如下:
$$c_{h a f}{*}\left(x_{i}, y-1\right)=\left{\begin{array}{rcc} C^{k+1} & \text { if } & \vec{H}{\text {pred }}\left(x^{f g}, y-1\right){0} \leq 0 \ & & \wedge \vec{H}\left(x_{i}^{f g}, y-1\right)_{0}>0 \ C^{k} & \text { otherwise } \end{array}\right. $$
$$上式中的C{k}和C分别表示索引为k和k+1的聚类中心,c_{h a f}{*}\left(x_{i}, y-1\right)表示像素点\left(x_{i}^{f g}, y-1\right)属于哪个聚类中心。$$
上式表示的含义如下图所示:

从底到顶的连接 : 那由HAF聚类的clusters是怎么在行与行之间进行匹配呢?
接下来,使用垂直向量场VAF来将水平簇分配给车道线l,那clusters是怎么与已有的active lanes 进行匹配呢?对每一个active lane 找出其与所有 clusters中误差最小的那个custer,只要两者的误差在设定的闯值范围内就认为匹配成。而未匹配的簇则会初始化为新的车道线。
d{C{k}}(l)用来衡量车道线l与聚类中心C^{k}的距离,公式如下:
$$\begin{aligned} d{C{k}}(l)=& \frac{1}{\left|C^{k}\right|} \sum_{i=0}{\left|C\right|-1} |\left(\bar{x}{C{k}}, y-1\right){\top}-\left(x_{i}, y\right)^{\top} \ &-\vec{V}{p r e d}\left(x^{l}, y\right) \cdot\left|\left(\bar{x}{C{k}}, y-1\right){\top}-\left(x_{i}, y\right)^{\top}\right||| \end{aligned} $$
上式中的$\vec{V}_{\text {pred}}$表示网络预测的VAF,$\left|C^{k}\right|$表示属于该聚类中心的点的数量。
公式$d{Ck}(l)$表示的就是将$C^k$与现有的车道线1相匹配的误差。前面提到过VAF表示指向上一行车道线实例中心像素的单位向量,上一行车道线实例中心可以由两种方式计算得到,第一种方式是直接对cluster 取平均,另外一种方式就是由activelane里的end points(也就是底下一行已经和车道线I匹配成功的簇的像素点)加上垂直向量表示的平移得到,只不过网络预测出来的VAF是单位向量,需要考虑向量的模长。这两种表示的差值即可表示簇$Ck$与车道线的误差。公式$|Ck|$表示第行属于车道线l的所有像素误差也是计算第y行属于车道线l的所有像素相对于y-1 行的族中心的误差的均值。
上式可以用下图表示:

代码展示:代码可从手写AI获得。
def decodeAFs(BW, VAF, HAF, fg_thresh=128, err_thresh=5, viz=False):
# 初始化输出数组为0,其大小与 BW 相同 # BW分割
...
# 用于存储每条车道的末端点的列表
...
# 定义下一个可用的车道ID
...
# 从最后一行开始解码到第一行
# 求解每一行的中心点
for row in range(BW.shape[0]-1, -1, -1):
...
# 如果存在前景像素,则初始化 prev_col 为第一个前景像素列的位置
...
# 水平地解析像素
for col in cols:
...
# 根据水平透视场(HAF)的值,确定像素点是如何与其它像素相关联的
if HAF[row, prev_col] >= 0 and HAF[row, col] >= 0:
...
# vaf与haf中心点差距
# 上一行指向的有一个值和本行估计的值进行就差距,在一定范围内则连成一条线
assigned = [False for _ in clusters]
...
#计算每一个线头坐标点与当前行聚类点之间的dist_error
for r, pts in enumerate(lane_end_pts): # for each end point in an active lane
for c, cluster in enumerate(clusters):
...
# 获取线头点与当前行聚类点在C.shape下的坐标
row_ind, col_ind = np.unravel_index(np.argsort(C, axis=None), C.shape)
for r, c in zip(row_ind, col_ind):
...
for c, cluster in enumerate(clusters):
...
七 损失函数
对于二值分割分支,使用带权重的二值交叉熵损失函数,权重用来解决前景和背景的类别不均衡问题,损失函数表示如下:
$$L_{B C E}=-\frac{1}{N} \sum_{i}\left[w \cdot t_{i} \cdot \log \left(o_{i}\right)+\left(1-t_{i}\right) \cdot \log \left(1-o_{i}\right)\right] $$
上式中的$t_{i}$ 表示真值,$o_{i}$为网络输出的结果,该值通过sigmoid函数进行归一化,w为用于平衡类别的权重。
对于分割分支,还使用了IoU损失,表示如下:
$$L_{I o U}=\frac{1}{N} \sum_{i}\left[1-\frac{t_{i} \cdot o_{i}}{t_{i}+o_{i}-t_{i} \cdot o_{i}}\right] $$
对于affinity field分支,使用L1损失函数进行回归,表示如下:
$$L_{A F}=\frac{1}{N_{f g}} \sum_{i}\left[\left|t_{i}^{h a f}-o_{i}^{h a f}\right|+\left|t_{i}^{v a f}-o_{i}^{v a f}\right|\right] $$
综上,整体的损失函数表示为:
$$L_{\text {total }}=L_{B C E}+L_{I o U}+L_{A F} $$
八 总结
标签:车道,VAF,第八章,像素,right,HAF,LaneAF,感知,left From: https://www.cnblogs.com/heron01/p/17743709.html
- 提出一种通过使用二元分割Mask和Per-pixel Affinity Field来进行车道线检测和实例分割的新方法,并在消融实验和主流数据集验证其有效性。
- 使用Affinity Field聚类方法可以检测到任意宽度可变数量的车道线,无需假设固定或最大数量的车道线。
- 基于Affinity Field的聚类方法显式使用了车道线像素之间的几何约束,具有更强的可解释性