认识Kafaka
最初的定义:消息队列系统
0.10.0版本的定义:分布式流处理平台,发布-订阅消息队列,存储功能、流处理框架
3.x后的定义:分布式流平台,数据管道/集成、流分析
kafka的优势
- 吞吐量高、性能好
- 伸缩性好
- 高容错、高可靠
- 与大数据生态精密结合
kafka的作用
- 高并发环境下的缓冲、消峰
- 解耦:支持不同的数据来源和不同的目的地
- 异步通信:避免同步时的等待时间
两种模式
- 点对点:消费者主动拉取数据,并在消费后删除
- 发布-订阅(常用):同时有多个Topic、多个消费者,独立并行消费,不删除数据
Kafka基础架构
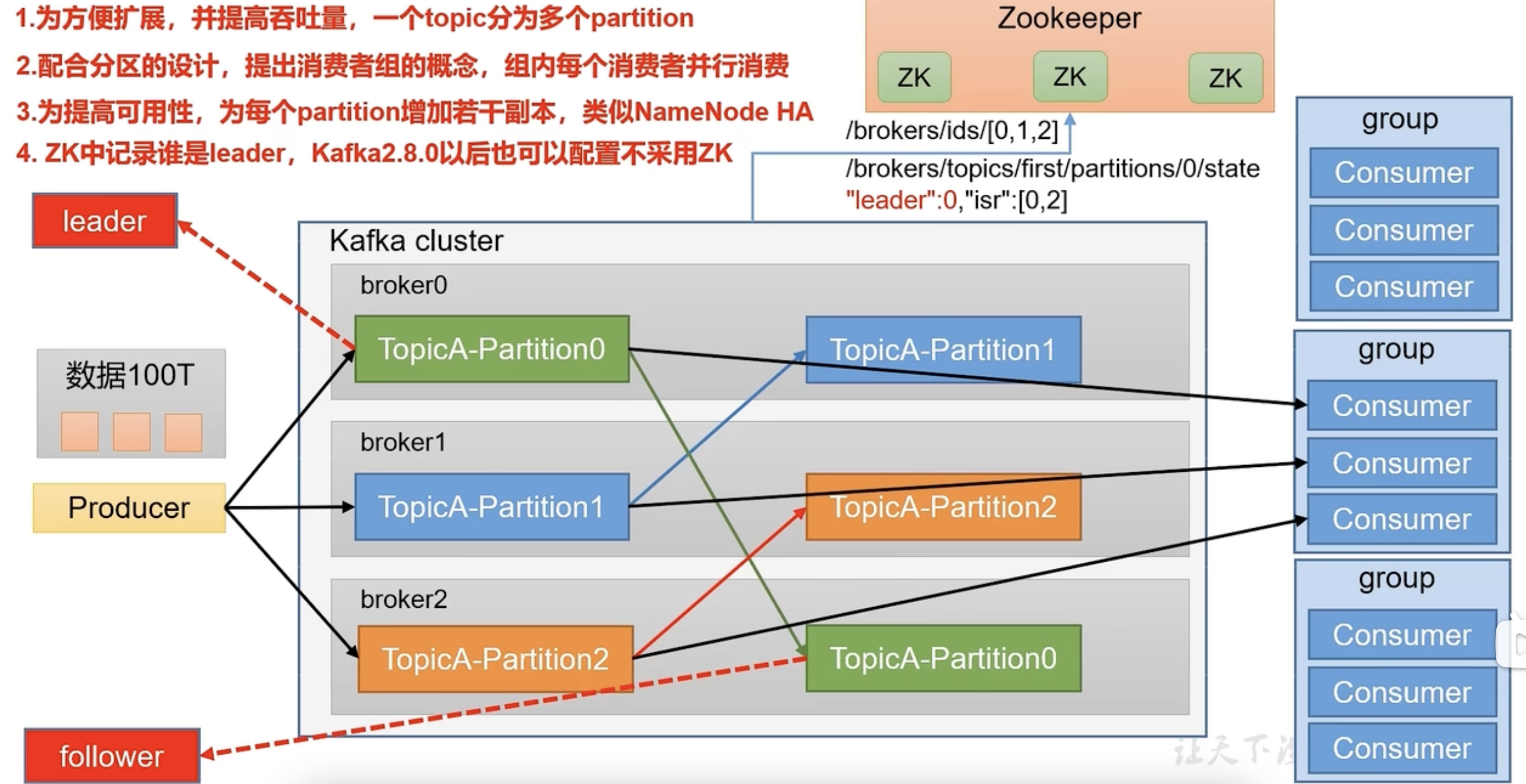
生产者:
Topic:
一个Topic可分为多个Partition分区,便于存储海量数据。为了保证可用性,每个分区又有若干个副本,副本分为leader和follower。生产和消费的处理对象只针对leader,若leader挂掉了,follower有条件成为新的leader
消费者:对应Topic的设计,消费端也有消费者组,组内每个消费者并行消费,每个分区只能由一个消费者消费
Zookeeper:存储kafka中的集群上下线,包括记录每个分区下谁是leader副本(kafka2.8.0后可不用zk)
搭建Kafka
官网下载链接:https://kafka.apache.org/downloads ,这里用的教程一样的3.0.0版本,下载后调整配置
# config/server.properties
broker.id=0 #每个分区的brokerID都需要不同
log.dirs=/home/csop/kafka/logs # 默认的日志保存在临时目录中,有清除的风险
zookeeper.connect=CentOS-001:2181,CentOS-002:2181,CentOS-003:2181/kafka # 在zk里添加一个kafka子目录,便于管理
# ~/.bash_profile环境变量配置
export KAFKA_HOME=/home/csop/kafka
export PATH=$PATH:$KAFKA_HOME/bin
先启动zookeeper,再启动 kafka,但启动kafka时需要添加一些参数:
zk.sh # 自己写的脚本,需要重新查看一下,jps命令也需要查看一下代码
bin/kafka-server-start -demon config/server.properties
06,启动还没有复现
标签:消费者,CentOS,分区,基础,kafka,Topic,leader From: https://www.cnblogs.com/yuan-zhou/p/17710259.html