kafka的partiton在实际的消息生产消费过程中是如何使用的。
安装
zookeeper安装
jdk安装~
#zookeeper 默认端口2181
数据缓存位置:zoo.cfg => dataDir=xxx
1.启动方式
./zkServer.sh stop
./zkServer.sh start
./zkServer.sh status
2.连接方式
bin/zkCli.sh
#指定端口
bin/zkCli.sh -server ip:port
3.集群角色
领导者leader 负责进行投票的发起和决议,更新系统状态
学习者Learner (跟随者Follower、观察者Observer)
跟随者Follower 用于接受客户请求,并返回客户端结果,在选主过程中参与投票
观察者Observer 接受客户请求,转发leader节点,不参与投票,之同步Leader状态
客户端Client
java连接
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.List;
/**
* 操作ZooKeeper的Znode
*/
public class ZnodeDemo implements Watcher {
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
//创建连接zookeeper对象
ZooKeeper zooKeeper = new ZooKeeper("192.168.3.130:2181,192.168.3.130:2182,192.168.3.130:2183",150000,new ZnodeDemo());
//
// String path=zooKeeper.create("/bjsxt/test","oldlu".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT_SEQUENTIAL);
// System.out.println(path);
// byte[] result=zooKeeper.getData("/bjsxt/test0000000000",new ZnodeDemo(),new Stat());
// System.out.println(new String(result));
//遍历所有的znode节点
// List<String> list=zooKeeper.getChildren("/bjsxt",new ZnodeDemo());
// for (String path:list){
// byte[] data=zooKeeper.getData("/bjsxt/"+path,new ZnodeDemo(),null);
// System.out.println(new String(data));
// }
//设置Znode的值
// Stat stat=zooKeeper.setData("/bjsxt/test0000000000","modifyvalue1".getBytes(),-1);
// System.out.println(stat);
zooKeeper.delete("/bjsxt/test0000000000",-1);
}
/**
* 事件通知回调方法
* @param event
*/
@Override
public void process(WatchedEvent event) {
if(event.getState() == Event.KeeperState.SyncConnected){
System.out.println("连接成功");
}
}
}
kafka安装
#config/server.properties
broker.id 节点唯一标识
#配置Listeners配置的ip为内网ip advertised.listeners公网ip
listeners(ٖ内网Ip)
advertised.listeners(公网ip)
#修改zookeeper地址,默认地址
zookeeper.connection=localhost:2181
#消息存储的目录
log.dirs=
#启动命令
./kafka-server-start.sh ../config/server.properties &
./kafka-server-start.sh -daemon ../config/server.properties &
./kafka-server-stop.sh
./kafka-topics.sh --create --zookeeper 192.168.3.128:2181 --replication-factor 1 --partitions 1 --topic xdclass-topic
#查看topic
./kafka-topics.sh --list --zookeeper 192.168.3.128:2181
#生产者
./kafka-console-producer.sh --broker-list 192.168.3.128:9092 --topic xdclass-topic
#消费者 --from-beginning 会将主题中以往的数据读出来
./kafka-console-consumer.sh --bootstrap-server 192.168.3.128:9092 --from-beginning --topic xdclass-topic
#删除topic
./kafka-topics.sh --zookeeper 192.168.3.128:2181 --delete --topic t1
#查看broker状态
./kafka-topics.sh --describe --zookeeper 192.168.3.128:2181 --topic xdclass-topic
基本概念
-
LEO(LogEndOffset)
- 表示每个partition的log最后一条Message的位置
-
HW (HighWatermark)
- 各个replicas数据同步且一致的offset位置
-
Broker
- Kafka服务端程序,一个mq节点
- broker存储topic数据
-
Producer生产者
-
Consumer消费者
-
ConsumerGroup消费者组
一个组只有一个消费者可以消费同一个topic中的一个消息
-
ReplicationLeader、ReplicationFollower
- Partition有多个副本,但只有一个RelicationLeader负责该Partition和生产者消费
- ReplicationFollower只是作为一个备份,从RelicationLeader进行同步
-
LEO(LogEndOffset)
- 表示每个partition的log最后一条Message的位置
-
HW(HighWaterMark)
- 表示partition各个replicas数据间同步且一致的offset位置,即表示all replicas已经commit的位置
- HW之前的数据才是commit后的,对消费者才可见
- ISR集合里面最小leo
-
offset
- 每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中
- partition中的每个消息都有一个联系的序列号叫做offset,用于partition唯一表示一条消息
- 可以认为offset是partition中message的id
-
Segment:每个partition又由多个segment file组成
- segment file 由两个部分组成,分别是index file 和data file (log file)
- 两个文件一一对应,后缀.index和.log分别表示索引文件和数据文件
- 命名规则:partition的第一个segment从0开始i,后续每个segment文件名为上一个segment文件最后一条消息的offset+1
-
Kafka高效文件存储设计特点:
- topic中一个partition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
- 通过索引信息可以快速定位message
- producer生产数据,要写入到log文件中,写的过程中一直追加到文件末尾,为顺序写,官网数据表明。同样的磁盘,顺序写能到600m/s,而随机写只有100k/s
-
kafka的producer生产着发送到broker流程
- 如果指定Partition ID,则PR被发送到指定partition(ProducerRecord)
- 如果未指定Partition ID,但指定了key,PR会按照hash(key)发送至指定Partition
- 如果未指定Partition ID 也没有指定Key,PR会按照round-Robin轮训模式发送到每个Partition
- 消费者消费partition分区默认是range模式
- 如果同时指定了Partition ID和Key,PR只会发送到指定的Partition(Key不起作用,代码逻辑决定)
- Partition由多个副本,只有一个replicationLeader负责改Partition和生产者消费者交互
点对点和订阅发布模型
点对点
#创建topic
./kafka-topics.sh --create --zookeeper 192.168.3.128:2181 --replication-factor 1 --partitions 2 --topic t1
./kafka-console-producer.sh --broker-list 192.168.3.128:9092 --topic t1
#指定配置文件启动两个消费者
./kafka-console-consumer.sh --bootstrap-server 192.168.3.128:9092 --from-beginning --topic t1 --consumer.config ../config/consumer.properties
发布订阅
修改config/comsumer.properties中的group.id确保不一样
整合springboot
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>
KafkaAdmin
import org.apache.kafka.clients.admin.*;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.*;
import java.util.concurrent.ExecutionException;
@SpringBootTest
public class KafkaAdminTest {
private static final String TOPIC_NAME = "my-topic";
/**
* 设置admin客户端
* @return
*/
public static AdminClient initAdminClient(){
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.128:9092");
AdminClient adminClient =
AdminClient.create(properties);
return adminClient;
}
@Test
public void createTopic() {
AdminClient adminClient = initAdminClient();
NewTopic newTopic = new NewTopic(TOPIC_NAME, 2 , (short) 1);
CreateTopicsResult createTopicsResult = adminClient.createTopics(Arrays.asList(newTopic));
try {
createTopicsResult.all().get();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("创建新的topic");
}
//获取topic集合
@Test
public void listTopic() throws ExecutionException, InterruptedException {
AdminClient adminClient = initAdminClient();
ListTopicsOptions options = new ListTopicsOptions();
options.listInternal(true);
ListTopicsResult listTopics = adminClient.listTopics(options);
Set<String> topics = listTopics.names().get();
for (String topic : topics) {
System.err.println(topic);
}
}
//删除
@Test
public void delTopicTest() {
AdminClient adminClient = initAdminClient();
DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList("xdclasssp11-topic"));
try {
deleteTopicsResult.all().get();
} catch (Exception e) {
e.printStackTrace();
}
}
//查看topic详细信息
@Test
public void getTopicInfo() throws Exception {
AdminClient adminClient = initAdminClient();
DescribeTopicsResult describeTopicsResult =
adminClient.describeTopics(Arrays.asList(TOPIC_NAME)
);
Map<String, TopicDescription> stringTopicDescriptionMap = describeTopicsResult.all().get();
Set<Map.Entry<String, TopicDescription>> entries = stringTopicDescriptionMap.entrySet();
entries.stream().forEach((entry)-> System.out.println("name:"+entry.getKey()+" , desc:"+ entry.getValue()));
}
@Test
public void incrPartitionsTest() throws Exception{
Map<String, NewPartitions> infoMap = new HashMap<>();
NewPartitions newPartitions = NewPartitions.increaseTo(5);
AdminClient adminClient = initAdminClient();
infoMap.put(TOPIC_NAME, newPartitions);
CreatePartitionsResult createPartitionsResult = adminClient.createPartitions(infoMap);
createPartitionsResult.all().get();
}
}
生产者
基础配置
生产者常见配置:https://kafka.apache.org/documentation/#producerconfigs
#kafka地址,即broker地址
bootstrap.servers
#当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
acks
#请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
retries
#每个分区未发送消息总字节大小,单位:字节,超过设置的值就会提交数据到服务端,默认值是16KB
batch.size
# 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满,如果想减少请求的数量,可以设置 linger.ms 大于#0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端
# 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求
#如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
linger.ms
# buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
# 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器
# 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
# buffer.memory要大于batch.size,否则会报申请内存不足的错误,不要超过物理内存,根据实际情况调整
buffer.memory
# key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被设置,即使
#消息中没有指定key,序列化器必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将#key序列化成字节数组。
key.serializer
value.serializer
注意!!!!
key默认是null,大多数应用程序会用到key
如果key为空,kafka使用默认的partitioner,使用RoundRobin算法将消息均衡的分布在各个partition上
如果key不为空,kafka使用自己实现的hash方法对key进行散列,决定消息被写到Topic的哪个partition,拥有相同key消息会被写到同一个partition,实现顺序消息
样例
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.junit.jupiter.api.Test;
import java.time.LocalDateTime;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class KafkaProducerTest {
private static final String TOPIC_NAME = "xdclasssp-topic";
public static Properties getProperties(){
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.3.128:9092");
//props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "112.74.55.160:9092");
// 当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
props.put("acks", "all");
//props.put(ProducerConfig.ACKS_CONFIG, "all");
// 请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
props.put("retries", 0);
//props.put(ProducerConfig.RETRIES_CONFIG, 0);
// 生产者缓存每个分区未发送的消息,缓存的大小是通过 batch.size 配置指定的,默认值是16KB
props.put("batch.size", 16384);
/**
* 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满
* 如果想减少请求的数量,可以设置 linger.ms 大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到 服务端
* 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求
* 如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
*/
props.put("linger.ms", 1);
/**
* buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
* 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到 Kafka服务器
* 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
* buffer.memory要大于batch.size,否则会报申请内存不#足的错误,不要超过物理内存,根据实际情况调整
* 需要结合实际业务情况压测进行配置
*/
props.put("buffer.memory", 33554432);
/**
* key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被 设置,
* 即使消息中没有指定key,序列化器必须是一个实
org.apache.kafka.common.serialization.Serializer接口的类,
* 将key序列化成字节数组。
*/
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
return props;
}
/**
* send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
* 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
*
* 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
* 发送消息后返回的一个 Future 对象,调用get即可
*
* 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
* 1)main线程发送消息到RecordAccumulator即返回
* 2)sender线程从RecordAccumulator拉取信息发送到broker
* 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
*
*
*/
@Test
public void testSend(){
Properties props = getProperties();
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 1; i < 3; i++){
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("my-topic", "xdclass-key"+i, "xdclass-value"+i));
try {
RecordMetadata recordMetadata = future.get();//不关心是否发送成功,则不需要这行
System.out.println("发送状态:"+recordMetadata.toString());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(i+"发送:"+ LocalDateTime.now().toString());
}
producer.close();
}
}
自定义partition分区规则
- 默认分区器
org.apache.kafka.clients.producer.internals.DefaultPartitioner
-
自定义分区规则
- 创建类,实现Partitioner接口,重写方法
- 配置partitioner.class指定类
public class XdclassPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if("xdclass".equals(key)) { return 0; } //使用hash值取模,确定分区(默认的也是这个方式) return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }@Test public void testSend(){ Properties props = getProperties(); props.put("partitioner.class", "net.xdclass.xdclassredis.XdclassPartitioner"); Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 3; i++){ Future<RecordMetadata> future = producer.send(new ProducerRecord<>(TOPIC_NAME, "xdclass", "xdclass-value"+i)); try { RecordMetadata recordMetadata = future.get(); System.out.println("发送状态:"+recordMetadata.toString()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } System.out.println(i+"发送:"+LocalDateTime.now().toString()); } producer.close(); }
消费者
- 消费者根据什么模式从broker获取数据的?
- 为什么是pull模式,而不是broker主动push?
- 消费者采用 pull 拉取方式,从broker的partition获取数据
- pull 模式则可以根据 consumer 的消费能力进行自己调整,不同的消费者性能不一样
- 如果broker没有数据,consumer可以配置 timeout 时间,阻塞等待一段时间之后再返回
- 如果是broker主动push,优点是可以快速处理消息,但是容易造成消费者处理不过来,消息堆积和延迟。
- 为什么是pull模式,而不是broker主动push?
消费者从哪个分区进行消费?
- 一个 topic 有多个 partition,一个消费者组里面有多个消费者,那是怎么分配过
- 一个主题topic可以有多个消费者,因为里面有多个partition分区 ( leader分区)
- 一个partition leader可以由一个消费者组中的一个消费者进行消费
- 一个 topic 有多个 partition,所以有多个partition leader,给多个消费者消费,那分配策略如何?
顶层接口
org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
- round-robin (RoundRobinAssignor非默认策略)轮训
- 【按照消费者组】进行轮训分配,同个消费者组监听不同主题也一样,是把所有的 partition 和所有的 consumer 都列出来, 所以消费者组里面订阅的主题是一样的才行,主题不一样则会出现分配不均问题,例如7个分区,同组内2个消费者
- topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5/topic-p6
- c-1: topic-p0/topic-p2/topic-p4/topic-p6
- c-2:topic-p1/topic-p3/topic-p5
- 弊端
- 如果同一消费者组内,所订阅的消息是不相同的,在执行分区分配的时候不是轮询分配,可能会导致分区分配的不均匀
- 有3个消费者C0、C1和C2,他们共订阅了 3 个主题:t0、t1 和 t2
- t0有1个分区(p0),t1有2个分区(p0、p1),t2有3个分区(p0、p1、p2))
- 消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2
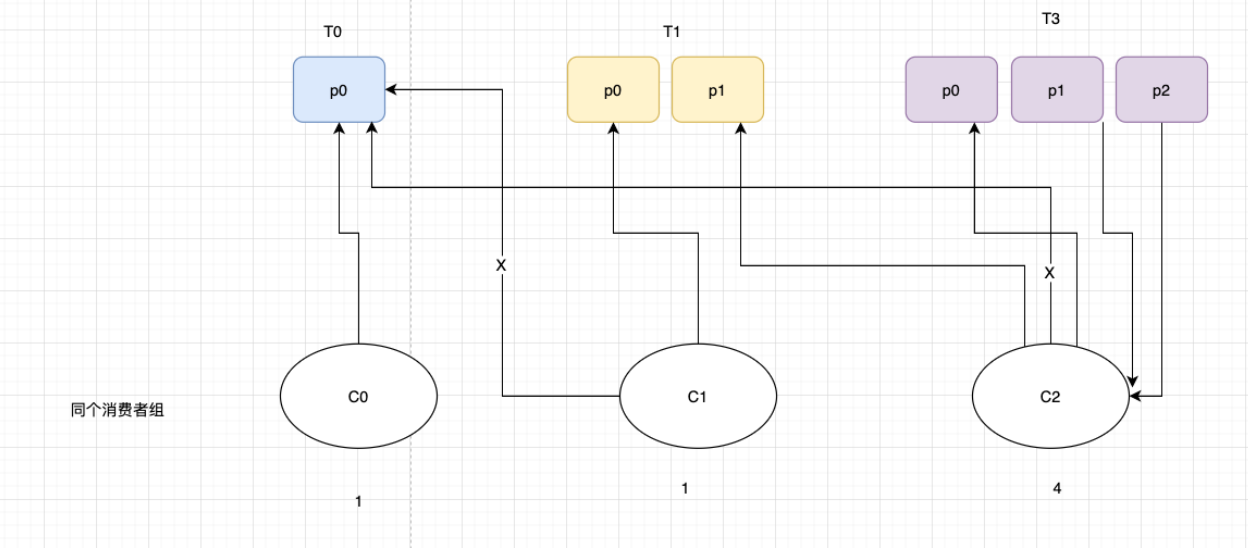
- range (RangeAssignor默认策略)范围
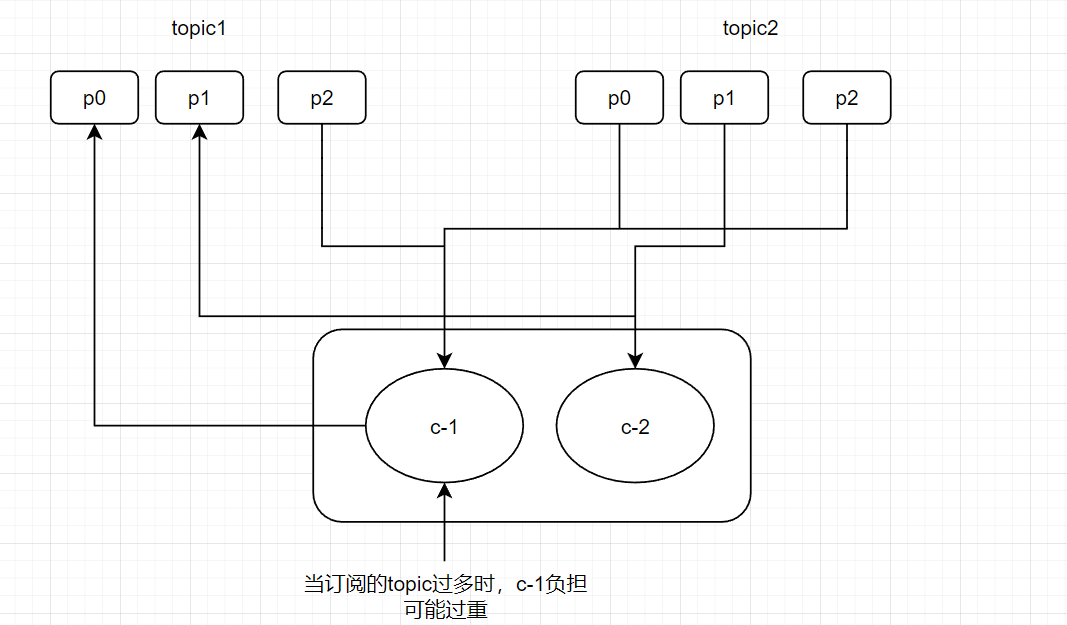
- 【按照主题】进行分配,如果不平均分配,则第一个消费者会分配比较多分区, 一个消费者监听不同主题也不影响,例如7个分区,同组内2个消费者
- topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5//topic-p6
- c-1: topic-p0/topic-p1/topic-p2/topic-p3
- c-2:topic-p4/topic-p5/topic-p6
- 弊端
- 只是针对 1 个 topic 而言,c-1多消费一个分区影响不大
- 如果有 N 多个 topic,那么针对每个 topic,消费者 C-1 都将多消费 1 个分区,topic越多则消费的分区也越多,则性能有所下降
面试
-
什么是Rebalance操作
-
kafka 怎么均匀地分配某个 topic 下的所有 partition 到各个消费者,从而使得消息的消费速度达到最快,这就是平衡(balance),前面讲了 Range 范围分区 和 RoundRobin 轮询分区,也支持自定义分区策略。
-
而 rebalance(重平衡)其实就是重新进行 partition 的分配,从而使得 partition 的分配重新达到平衡状态
-
-
面试
- 例如70个分区,10个消费者,但是先启动一个消费者,后续再启动一个消费者,这个会怎么分配?
- Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
- 当消费者组内的消费者数量发生变化(增加或者减少),就会产生重新分配patition
- 分区数量发生变化时(即 topic 的分区数量发生变化时)
- Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
- 例如70个分区,10个消费者,但是先启动一个消费者,后续再启动一个消费者,这个会怎么分配?
-
面试:当消费者在消费过程突然宕机了,重新恢复后是从哪里消费,会有什么问题?
- 消费者会记录offset,故障恢复后从这里继续消费,这个offset记录在哪里?
- 记录在zk里面和本地,新版默认将offset保证在kafka的内置topic中,名称是 __consumer_offsets
- 该Topic默认有50个Partition,每个Partition有3个副本,分区数量由参数offset.topic.num.partition配置
- 通过groupId的哈希值和该参数取模的方式来确定某个消费者组已消费的offset保存到__consumer_offsets主题的哪个分区中
- 由 消费者组名+主题+分区,确定唯一的offset的key,从而获取对应的值
- 三元组:group.id+topic+分区号,而 value 就是 offset 的值
消费者配置
#消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
group.id
#为true则自动提交偏移量
enable.auto.commit
#自动提交offset周期
auto.commit.interval.ms
#重置消费偏移量策略,消费者在读取一个没有偏移量的分区或者偏移量无效情况下(因消费者长时间失效、包含偏移量的记录已经过时并被删除)该如何处理,
#默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更 才可以
auto.offset.reset
#序列化器
key.deserializer
消费者机制和分区策略
消费者从哪个分区进行消费?两个策略
- 顶层接口
org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
-
round-robin (RoundRobinAssignor非默认策略)轮训
- 【按照消费者组】进行轮训分配,同个消费者组监听不同主题也一样,是把所有的 partition 和所有的 consumer 都列出来, 所以消费者组里面订阅的主题是一样的才行,主题不一样则会出现分配不均问题,例如7个分区,同组内2个消费者
- topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5/topic-p6
- c-1: topic-p0/topic-p2/topic-p4/topic-p6
- c-2:topic-p1/topic-p3/topic-p5
- 弊端
- 如果同一消费者组内,所订阅的消息是不相同的,在执行分区分配的时候不是轮询分配,可能会导致分区分配的不均匀
- 有3个消费者C0、C1和C2,他们共订阅了 3 个主题:t0、t1 和 t2
- t0有1个分区(p0),t1有2个分区(p0、p1),t2有3个分区(p0、p1、p2))
- 消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2
-
range (RangeAssignor默认策略)范围
- 【按照主题】进行分配,如果不平均分配,则第一个消费者会分配比较多分区, 一个消费者监听不同主题也不影响,例如7个分区,同组内2个消费者
- topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5//topic-p6
- c-1: topic-p0/topic-p1/topic-p2/topic-p3
- c-2:topic-p4/topic-p5/topic-p6
- 弊端
- 只是针对 1 个 topic 而言,c-1多消费一个分区影响不大
- 如果有 N 多个 topic,那么针对每个 topic,消费者 C-1 都将多消费 1 个分区,topic越多则消费的分区也越多,则性能有所下降
reblance操作
-
什么是Rebalance操作
- kafka 怎么均匀地分配某个 topic 下的所有 partition 到各个消费者,从而使得消息的消费速度达到最快,这就是平衡(balance),前面讲了 Range 范围分区 和 RoundRobin 轮询分区,也支持自定义分区策略。
- 而 rebalance(重平衡)其实就是重新进行 partition 的分配,从而使得 partition 的分配重新达到平衡状态
-
面试
- 例如70个分区,10个消费者,但是先启动一个消费者,后续再启动一个消费者,这个会怎么分配?
- Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
- 当消费者组内的消费者数量发生变化(增加或者减少),就会产生重新分配patition
- 分区数量发生变化时(即 topic 的分区数量发生变化时)
- Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
- 例如70个分区,10个消费者,但是先启动一个消费者,后续再启动一个消费者,这个会怎么分配?
-
面试:当消费者在消费过程突然宕机了,重新恢复后是从哪里消费,会有什么问题?
- 消费者会记录offset,故障恢复后从这里继续消费,这个offset记录在哪里?
- 记录在zk里面和本地,新版默认将offset保证在kafka的内置topic中,名称是 __consumer_offsets
- 该Topic默认有50个Partition,每个Partition有3个副本,分区数量由参数offset.topic.num.partition配置
- 通过groupId的哈希值和该参数取模的方式来确定某个消费者组已消费的offset保存到__consumer_offsets主题的哪个分区中
- 由 消费者组名+主题+分区,确定唯一的offset的key,从而获取对应的值
- 三元组:group.id+topic+分区号,而 value 就是 offset 的值
Consumer配置讲解和Kafka调试日志配置
- springboot关闭kafka调试日志
#yml配置文件修改
logging:
config: classpath:logback.xml
#logback.xml内容
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!-- 格式化输出: %d表示日期, %thread表示线程名, %-5level: 级别从左显示5个字符宽度 %msg:日志消息, %n是换行符 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS}[%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</configuration>
- 消费者配置
#消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
group.id
#为true则自动提交偏移量
enable.auto.commit
#自动提交offset周期
auto.commit.interval.ms
#重置消费偏移量策略,消费者在读取一个没有偏移量的分区或者偏移量无效情况下(因消费者长时间失效、包含偏移量的记录已经过时并被删除)该如何处理,
#默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更 才可以
auto.offset.reset
#序列化器
key.deserializer
Kafka消费者Consumer消费消息配置实战
- 配置
public static Properties getProperties() {
Properties props = new Properties();
//broker地址
props.put("bootstrap.servers", "112.74.55.160:9092");
//消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
props.put("group.id", "xdclass-g1");
//开启自动提交offset
props.put("enable.auto.commit", "true");
//自动提交offset延迟时间
props.put("auto.commit.interval.ms", "1000");
//反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
- 消费订阅
@Test
public void simpleConsumerTest(){
Properties props = getProperties();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic主题
consumer.subscribe(Arrays.asList(KafkaProducerTest.TOPIC_NAME));
while (true) {
//拉取时间控制,阻塞超时时间
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
System.err.printf("topic = %s, offset = %d, key = %s, value = %s%n",record.topic(), record.offset(), record.key(), record.value());
}
}
}
Consumer手工提交offset配置和从头消费配置
-
如果需要从头消费partition消息,怎操作?
- auto.offset.reset 配置策略即可
- 默认是latest,需要改为 earliest 且消费者组名变更 ,即可实现从头消费
//默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效 props.put("auto.offset.reset","earliest"); -
自动提交offset问题
- 没法控制消息是否正常被消费
- 适合非严谨的场景,比如日志收集发送
-
手工提交offset配置和测试
- 初次启动消费者会请求broker获取当前消费的offset值
-
手工提交offset
- 同步 commitSync 阻塞当前线程 (自动失败重试)
- 异步 commitAsync 不会阻塞当前线程 (没有失败重试,回调callback函数获取提交信息,记录日志)