SimGCL论文阅读笔记
本篇文章主要讲述了图增强虽然有效果,但是起到的作用很小,然后提出了基于添加均匀的噪声来创建对比视图。这样准确性和效率都会优于原来的方法
1.引言部分
尽管现在基于结构扰动的图增强具有着很不错的效果,但是性能提升的原因还是不清楚,并且有研究发现,即使非常稀疏的图增强(dropout rate达到了0.9)也会带来很可观的性能提高,因为巨大的dropout rate会导致原始信息的巨大损失和高度倾斜的图结构
然后该论文做了没有图增强的实验来进行性能比较,实验结果表明,没有图增强时,性能也有着与图增强相似的效果,之后经过研究,该论文发现对推荐性能提高真正重要的是CL的损失,而不是图增强。优化对比损失InfoNCE能够学习更加均匀的用户/项目表示,这对减轻popular bias上起到了重要的作用。但是图增强并不是完全无用的,因为原始图的适当扰动有助于学习对干扰因子不变的表示
于是,该论文提出了一个方法,放弃了图增强,而是在原始表示中添加随机均匀的噪声来进行数据增强,该方法可以平滑的调节均匀性,并且实现起来比较容易
2.推荐中的图对比学习调查
作者使用了四种方法来进行性能的对比,在不使用图增强的的情况下,性能甚至好于使用了ND或RW的图增强的方法,可能的原因是这两个方法可能会丢弃关键的节点或边,极大的扭曲了原始的图,这种情况下图的增强几乎没有什么可学习的不变性,而鼓励他们的一致性可能会产生负面影响
其余研究发现,优化对比损失强化了两个特征,正对特征的对齐以及单位超球面上归一化特征分布的一致性。然后作者使用t-SNE可视化几种方法学习到的embedding,结果发现,LightGCN会显示出高度聚集的特征,而其余的SGL的变体方法学习到的分布会均匀很多
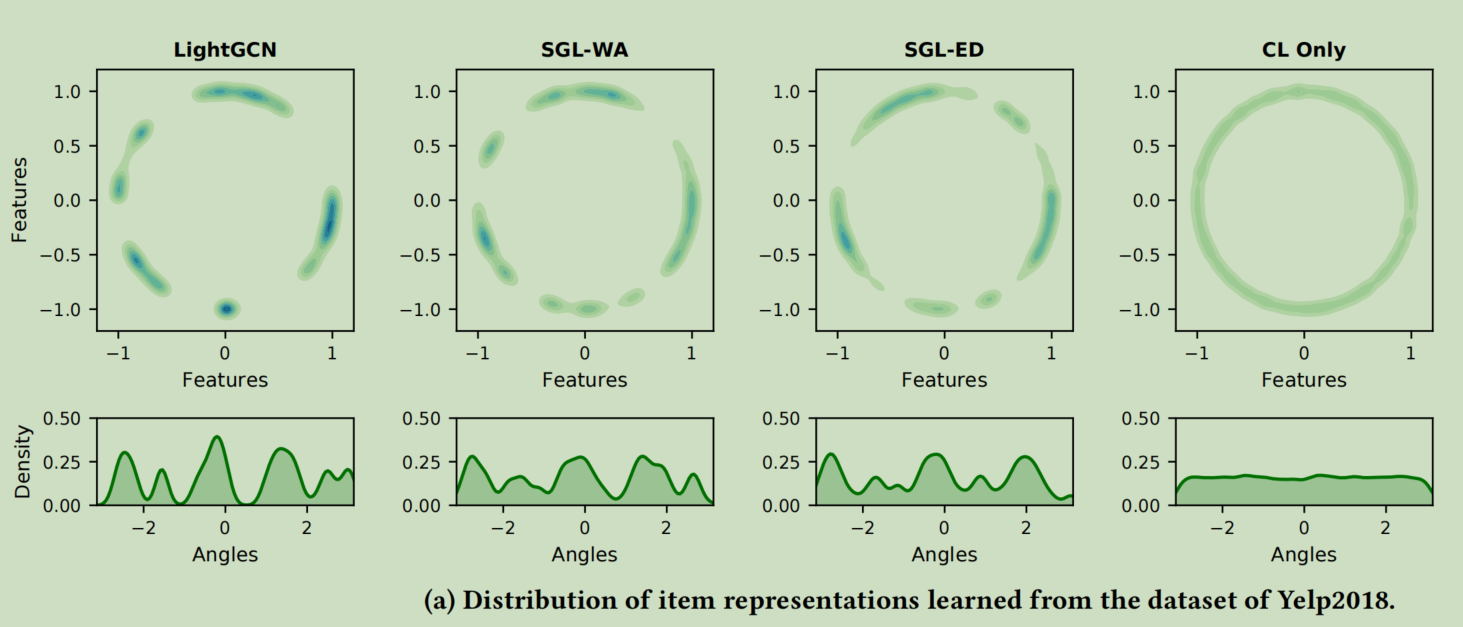
之后作者通过对损失函数的梯度的分析,来解释了为什么会出现这种状况,BPRloss的损失函数的梯度为
\(\bigtriangledown_{e_u} -\eta(1-s)(e_i-e_j)\)
\(s=\sigma(e_u^Te_i-e_u^Te_j)\)
当i是一个很流行的项目时,用户的embedding将不断更新到i的方向。消息传递机制进一步加剧了聚合问题并且会导致表示退化
而CL的损失函数为
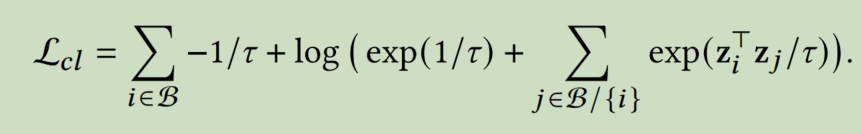
优化CL的损失函数实际上就是最小化不同节点的嵌入之间的余弦相似性,从而导致更加均匀的分布
经过分析,作者得出了一个结论,分布的均匀性是对SGL的推荐性能有决定性影响的关键因素,而不是图增强。因为一个更均匀的表示分布可以保持节点的内在特征,提高泛化能力。
但是还需要注意,仅通过最小化CL损失将会获得较差的性能,这就意味着均匀性和性能之间的正相关只在一定范围内保持,对一致性的过度追求会忽略交互对之间的紧密型和相似的用户/项目之间的紧密型,从而会损害推荐的效果
3. SimGCL结构详解
作者提出的简单的数据增强的方式如下:
\(e'_i=e_i+\bigtriangleup'_i,e''=e_i+\bigtriangleup''_i\)
需要满足的条件为
- $|\bigtriangleup|_2=\epsilon $
- \(\bigtriangleup=\bar{ \bigtriangleup}\odot sign(e_i)\)
其中,$\bar{ \bigtriangleup}\in\mathbb{R}^d\sim U(0,1) $
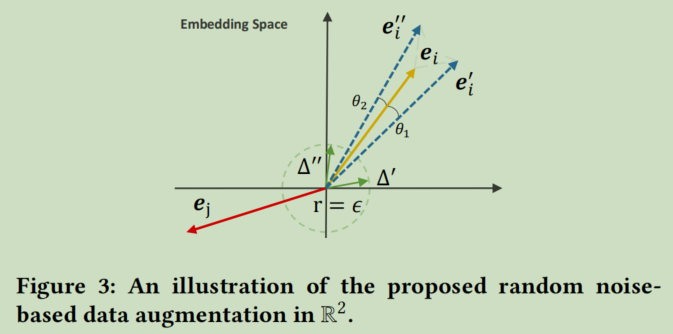
其中第一个约束控制了噪声的粒度,等价于以\(\epsilon\)为半径的超球面上的向量。半径越小,噪声的粒度越小,第二个约束时噪声向量和原始表征位于同一超象限,避免添加噪声造成过大的语义偏离。所以通过添加噪声,可以看作是使得原始的表征向量在空间中旋转了两个小角度,这样既能保留大部分的语义信息,又能带来语义上的不同
标签:增强,噪声,性能,bigtriangleup,笔记,SimGCL,损失,阅读,均匀 From: https://www.cnblogs.com/anewpro-techshare/p/17691761.html