Rust基础学习
Rust是一种适合于系统开发、网络层等开发的编程语言,具有高效、安全的特性。
Cargo
常用命令
Cargo是Rust用来管理代码的工具。常用指令有:
- 创建新项目:
cargo new hello_cargo
- 构建项目
cargo build
- 构建+运行项目
cargo run
- 检查是否编译可以通过
cargo check
- 发布代码
cargo build --release
优化编译项目,在target/release下生成可执行文件。
辅助技能
- 查看当前项目所有依赖项的说明文档
cargo doc --open
debug
使用dbg!宏。接收一个表达式的所有权,不过如果不想让它接收可以传引用。
#[derive(Debug)] // 允许结构体以debug形式输出
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);//输出结构体的各字段值
}
基础语法
变量
变量由let声明。变量默认是不可改变的,但可以加mut变为可变变量:let mut x = 5;。
常量由const而不是let限定,且需指明类型。
Rust支持多次let覆盖之前的变量,这叫做变量遮蔽,以前那个变量其实还在,直到离开该作用域,但是永远也无法访问到了,除非之前加了引用。
数据类型
Rust是静态类型语言,声明变量必须表明类型,但Rust通常可以推段出类型故不用标。
标量类型:整数(i和u)、浮点数(f32和f64)、字符、布尔
注意,如果发生数值溢出,则会panic
复合类型:
- 元组:不能改变,用
.寻址。元组内元素类型可不同。用(...)表示
let tup: (i32, f64, u8) = (500, 6.4, 1);
tup.0来获取第0个元素
- 数组:元素类型必须相同,用[]表示。用
a[0]寻址。不能越界访问
函数
参数需指定类型。
例如:fn another_function(x: i32) {
let y = {
let x = 3;
x + 1
};
大括号括起来的是一个表达式,x+1不带分号表示是返回值。
具有返回值的函数,要用->声明它的类型。
控制流
- if分支
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
循环
-
loop循环:只有加break才会退出,相当于c语言的while(1)。break后可加一个返回值(加分号)。也可为loop指定标签:
'xxx':loop{...},break时采用break 'xxx';来跳出指定的循环 -
while 循环
-
for循环:
let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } ---- for number in (1..4).rev() { println!("{number}!"); }
结构体
结构体的定义:
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
创建结构体实例,就和创建对象类似:
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("[email protected]"),
sign_in_count: 1,
};
如果要创建可修改成员的结构体,需要使用let mut。必须要将结构体实例声明为可变的,才能修改其中的字段,Rust 不支持将某个结构体某个字段标记为可变
- 字段初始化简写语法
字段名和参数名相同时,可简写:
fn build_user(email: String, username: String) -> User {
User {
active: true,
username,
email,
sign_in_count: 1,
}
}
- 结构体更新语法
当一个实例创建时的部分字段值等于另一个实例时,可以简写:
fn main() {
// --snip--
let user2 = User {
email: String::from("[email protected]"),
..user1
};
}
注意,由于user1中含有String类型的带所有权的变量,因此这样操作后不能再使用user1了
- 元组结构体
可以定义一个不带字段名的元组结构体:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}
除了Color和Point的类型不同外,他们都可以当成普通元组使用。
成员方法
定义类方法时,要通过impl class_name来定义。
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
pub fn new(width: u32, height: u32) -> Self {
Rectangle { width, height }
}
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
之后调用area时就可以像成员方法一样调用了,比如rec.area()。self指代此类型的实例,依然具有所有权的概念:
self表示Rectangle的所有权转移到该方法中,这种形式用的较少&self表示该方法对Rectangle的不可变借用&mut self表示可变借用
而首字母大写的Self指impl后面的类型,self指Self对应的变量。
关联函数
定义在 impl 中且没有 self 的函数被称之为关联函数。例如:
impl Rectangle {
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
}
使用结构体名和::来调用构造函数。如let sq = Rectangle::square(3);
rust允许对同一个结构体进行多个impl定义。
也可以为枚举实现方法,类似于结构体。
执行方法使用.即可,编译器会自动解引用。
所有权
栈上的数据不需要我们来管理,因为它的寻址等操作是快速的,而且只有出栈、入栈操作是比较安全的。但堆则不同,分配空间、来回移动内存指针来定位等等是慢速的,而且堆上数据处理不当会导致不安全。因此,Rust使用所有权来管理堆上的数据。
所有权规则:
- 每个值都有一个owner,这个owner就是变量,值就是堆上的一串空间
- 同一个时间里只能有一个owner,每个值只能同时对应一个owner
- owner离开作用域后,值被抛弃,对应的堆空间自动被释放
一句话概括:值 (Value)在同一时间只能被绑定到一个 变量 (Variable)上
例如:
let s1 = String::from("hello");
let s2 = s1;
s1是一个存放在堆上数据的owner,当被赋值给s2时,所有权发生转移,s1这个变量失效了,由s2接管s1之前管理的堆上的数据。之后再使用s1会报错。
注意,所有权的转移,类似于浅拷贝,不过是增加一个使原变量失效的操作,因此又称为移动。
不过这只限于堆上的数据,如果是栈上的数据,则没有所有权这一说:
let x = 5;
let y = x;
之后还可以使用x,因为x具有copy属性,不受所有权机制的管束。
另外,函数传递没有copy属性的参数时,也会发生所有权转移,就和前面的变量赋值一样。如果不希望发生所有权转移,则使用引用。
如果函数返回值是一个owner,则会发生所有权转移,也就是说,函数返回时不会将对应的返回值数据清空。
浅拷贝和深拷贝
Rust 永远也不会自动创建数据的 “深拷贝”。深拷贝是指把堆上的数据一同拷贝,浅拷贝是指只复制栈上的数据。
实现了Copy特征的类型,在赋值时不会发生所有权的转移。可以实现Copy特征的类型有:任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的,例如:
- 不可变引用
&T,但注意,可变引用&mut T是不可以Copy的
引用
注意,引用没有所有权,因此主动引用的变量不能出卖其成员的所有权,被引用的变量也不能出卖其成员的所有权。你把房子租出去了还想卖呀?
引用不会发生所有权转移,它的作用就是指向被引用的owne。例如:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.push_str(", world"); //Error,不可变引用
s.len()
}
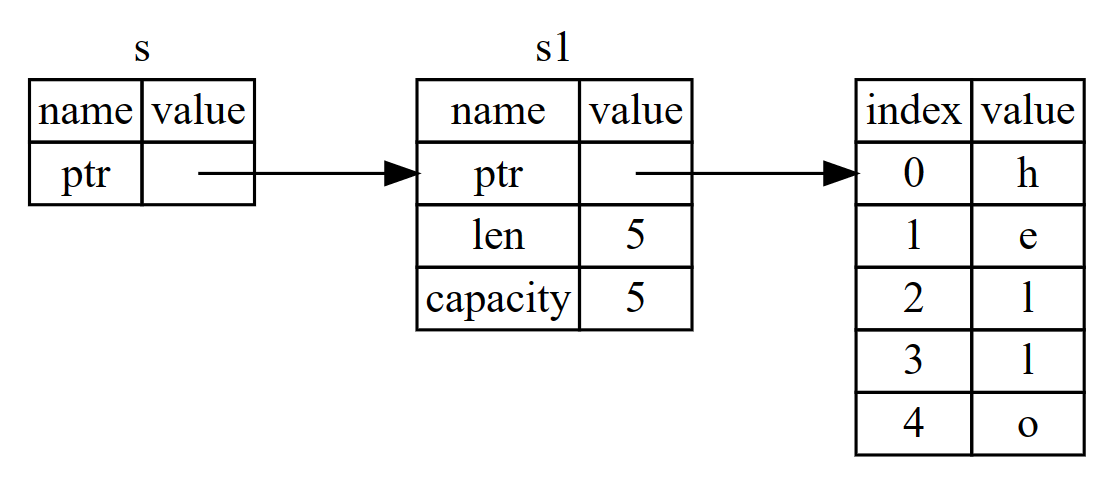
需要注意的是,上面的引用是不可变引用。即不能对所引用的数据进行操作,也就是只能读。
可变引用则要在owner声明时加mut,且引用&符号后也要加mut,表示允许该引用修改数据:
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
为了保证数据访问的正确性,防止两个对同一owner的引用同时修改数据,要么只能有一个可变引用,要么有任意数量的不可变引用。同时读不会造成安全问题。
另外,引用的作用域和变量不太一样。引用的作用域是引用创建到最后一次使用该引用的地方。也就是说,下面代码是合法的:
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{} and {}", r1, r2);
// variables r1 and r2 will not be used after this point
let r3 = &mut s; // no problem
println!("{}", r3);
最后一次使用完r1和r2,这两个引用就失效了。这给代码书写造成了极大的便利。
注意,引用前不需要加mut了,直接let定义即可。
悬空引用
就和悬空指针类似,数据已经失效了,但引用还在。rust不允许出现这种现象,如果出现则会报错。也就是说,引用必须永远是有效的,编译器确保数据不会在其引用之前离开作用域。
例如:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
} // s离开作用域,其own的数据失效
// &s对s进行悬空引用,非法!!!
- 部分move
可以对集合中的部分元素转移所有权,部分元素进行引用。
let t = (String::from("hello"), String::from("world"));
// ref表示s2是个引用
let (s1, ref s2) = t;
println!("{:?}, {:?}, {:?}", s1, s2, t.1);
生命周期
注意,生命周期是说引用
如果引用的生命周期以一些不同方式相关联的时候,编译器无法判断引用的生命周期,这时就需要加入生命周期注解。
- 生命周期注解
首先需要注意的是,生命周期注解不会改变生命周期的长短,只是告诉编译器一些信息。它以'开头,例如:
&i32 // 引用
&'a i32 // 带有显式生命周期的引用
&'a mut i32 // 带有显式生命周期的可变引用
如果两个引用的生命周期注解相同,那么说明它们至少活的和'a一样久。
- 函数中的生命周期注解
请注意,生命周期也是泛型,因此也在尖括号中声明。在函数名和参数列表间的尖括号里声明生命周期:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
返回值标上'a则说明,返回值的存活周期是x和y中的最小者。
- 结构体中的生命周期
结构体中也可以有引用类型的成员,不过必须加入生命周期注解。例如:
struct ImportantExcerpt<'a> {
part: &'a str,
}
这表示ImportantExcerpt 的实例不能比其 part 字段中的引用存在的更久
- 生命周期注解省略规则
函数或方法的参数的生命周期被称为 输入生命周期,而返回值的生命周期被称为 输出生命周期。编译器依次使用3条规则,如果没有计算出所有引用的生命周期,就会报错;否则就不会。3条规则为:
- 每个引用参数都分配一个生命周期参数。如果有多个则生命周期注解不同。(针对输入生命周期)
- 如果只有一个输入生命周期参数,那么会赋予给所有输出生命周期参数。
- 如果方法中有输入参数为
&self或&mut self,即是对象的方法,则所有输出生命周期参数都被赋予self的生命周期。
- 方法定义中的生命周期注解
为具有生命周期的结构体实现方法时,需要在impl和结构体后加入注解(类似于泛型):
impl<'a> ImportantExcerpt<'a> {
如果方法中出现了2个生命周期注解,编译器需要知道那个生命周期更大,则可以使用以下两种语法:
impl<'a: 'b, 'b> ImportantExcerpt<'a> {
//or
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'b str
where
'a: 'b,
'a: 'b是生命周期约束语法,与泛型约束类似,表明'a必须活的比'b久。
- 静态生命周期
'static代表的生命周期能够存活在整个程序期间,所有字符串literal都拥有static生命周期。
slice
切片本身是一种动态大小类型,表示集合中部分连续的元素序列。我们一般无法直接使用切片,例如str、[u8],因为它在编译期无法确定大小,一般使用的都是切片的引用,例如&str、&[u8],我们也把这叫成切片,下面指的"切片slice"都是指“切片的引用”。
slice类似于python中的概念,但是在rust中是一种引用,表示对集合一部分值的引用。如:
let s = String::from("hello world");
let hello = &s[0..5];//不包括5
let world = &s[6..11];//不包括11
其中hello和world分别是s的两个不可变引用,其记录了slice的长度和开始位置。
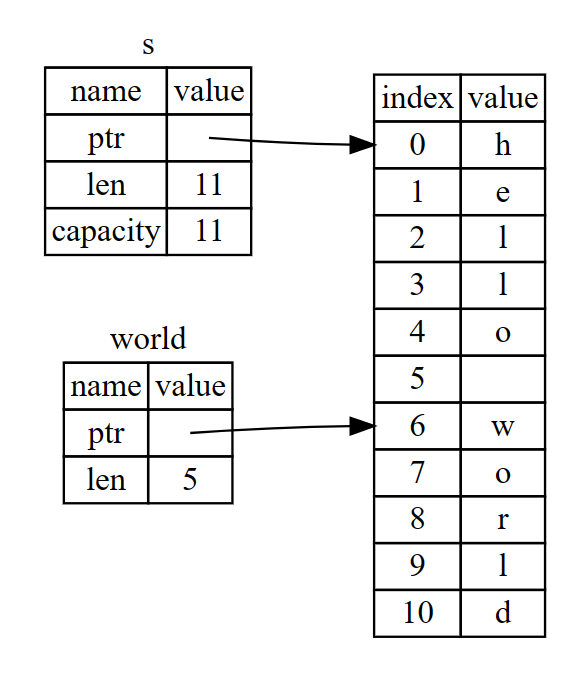
slice的好处在于,如果原字符串改变,那么子引用将失效,保证安全:
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // 错误!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
s.clear()会尝试获取一个可变引用,如果之后还会使用word这个不可变引用,那么word的作用域仍然会贯穿s.clear()这个使用可变引用的过程,这样rust编译是不允许的。
另外,字符串字面值就是slice,
let s = "Hello, world!";
s的类型就是&str,是一个指向二进制程序特定位置的slice。
要让String类型转换为&str类型,直接在其前面加&即可,这是一种deref性质。
枚举和模式匹配
枚举定义和创建:
enum IpAddrKind {
V4,
V6,
}
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
枚举也可以为成员关联数据:
enum Message {
Quit,
Move { x: i32, y: i32 }, //类似结构体
Write(String), //包含一个String,类似元组结构体
ChangeColor(i32, i32, i32),
}
也可以通过impl为枚举定义成员方法
Option枚举
为了解决其他程序语言中空值导致的系统问题,rust没有提供Null值。如果一个变量可能为空,那么必须定义为Option类型。Option是标准库中定义的一个枚举类型:
enum Option<T> {
None,
Some(T),
}
定义变量示例:
let some_number = Some(5);
let some_char = Some('e');
let absent_number: Option<i32> = None;
- 使用Option
如果要对Option进行操作,那么可以使用match。如下:
//有值则加1,否则返回空
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
- Option的常用方法
-
将Option<&T>拷贝得到Option<T>:
x.copied() -
获取Some中的值,如果是None得到一个默认值:
unwarp_or(default)。 -
如果Option内的元素未实现Copy特征,match的时候,这样写会导致所有权转移,可以在前面加一个
refmatch y { Some(ref p) => ... }// 不加ref导致所有权转移
match
功能类似于switch。本身是一个表达式,其匹配也需要是一个表达式
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin { //要匹配的表达式
Coin::Penny => {
println!("Lucky penny!");
1
}
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
=>前者是匹配模式的值,后者是要执行的代码。
- 绑定值的模式
如果模式绑定了值,则可以这样:
#[derive(Debug)] // 这样可以立刻看到州的名称
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {:?}!", state);
25
}
}
}
这样就可以从枚举成员中提取值了。
- match的通配模式
注意,match内必须涵盖所有情况,如果想使用default,则可以使用other或_。
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),//other代表了dice_roll的值
}
如果不想使用other获取的值,则使用_,它匹配任意值但不绑定到该值:
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (), //空元组表示无事发生
}
if let简洁控制流
如果match中的一些模式我们不需要去管,那么就可以用if let来简化match:
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("The maximum is configured to be {}", max);
}
if let后加一个等号分隔的表达式,前者为模式,后者为表达式,次序不能颠倒
也可以在if后加else:
if let ...{
} else {
...
}
- 变量遮蔽
match和if let都是一个新的代码块,如果绑定新变量的名字和以前的一样,则会发生变量遮蔽。
fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
if let Some(age) = age {// 这里age会遮蔽右边的age,直到出了if let语句块
println!("匹配出来的age是{}",age);
}
println!("在匹配后,age是{:?}",age);
}
因此最好不要使用同名。
-
什么是模式
-
字面值
-
解构的数组、枚举、结构体或者元组
-
变量
-
通配符
-
占位符
-
-
_是一个通配符,并不会发生所有权的转移
-
匹配守卫
match分支模式后面可以加一个额外的if语句,来实现进一步的匹配条件。
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {}", n),
_ => println!("Default case, x = {:?}", x),
}
println!("at the end: x = {:?}, y = {}", x, y);
}
常见集合
接口文档:std::collections - Rust (rust-lang.org)
固定数组
固定数组:
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
可见,数组类型是[T; len],而数组切片类型是[T].
vector
- 创建空的vector:
let v: Vec<i32> = Vec::new();
- 通过宏创建包含初值的vector,类型会自动推断出来:
let v = vec![1, 2, 3];
- 更新vector:
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
-
Vector与其元素共存亡
-
读取vector:
有两种方式,索引和get
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("The third element is {third}"),
None => println!("There is no third element."),
}
索引&x[y]的方式当出现越界访问时会panic,而get则会返回一个None值。
另外,当获取vector中某个元素的引用时,相当于对整体进行了引用,不能再向vector中插入元素了。(vector实现机制类似C++的,其内存位置可能会随着元素个数变化而改变,因此对某个元素的引用可能会造成空值)
- 遍历vector
只读:
let v = vec![100, 32, 57];
for i in &v { //获取vector中每个元素的不可变引用
println!("{i}");
}
修改:
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
类似java,这样的for循环中不支持对vector的插入和删除。
- 在vector中存放不同的数据类型
通过元组实现:
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
通过特征对象实现(常用):
trait IpAddr {
fn display(&self);
}
struct V4(String);
impl IpAddr for V4 {
fn display(&self) {
println!("ipv4: {:?}",self.0)
}
}
...
let v: Vec<Box<dyn IpAddr>> = vec![
Box::new(V4("127.0.0.1".to_string())),
Box::new(V6("::1".to_string())),
];
排序
rust中实现了2种排序算法:
- 稳定的排序
sort和sort_by:速度慢, 额外分配空间 - 非稳定排序
sort_unstable和sort_unstable_by:速度快
其中带有by后缀的可以实现自定义排序。
例如升序排序:
let mut vec = vec![1, 5, 10, 2, 15];
vec.sort_unstable();
- 实现自定义排序
sort_unstable()只能对实现全数值可比较Ord特征的类型进行排序。
如果sort_unstable不能满足排序情况,例如对f32类型排序(实现了部分排序),则可以:
let mut vec = vec![1.0, 5.6, 10.3, 2.0, 15f32];
vec.sort_unstable_by(|a, b| a.partial_cmp(b).unwrap());
如果要对结构体数组进行排序,可以有2种方式,根据某个元素大小进行排序:
let mut people = vec![
Person::new("Zoe".to_string(), 25),
Person::new("Al".to_string(), 60),
Person::new("John".to_string(), 1),
];
// 定义一个按照年龄倒序排序的对比函数
people.sort_unstable_by(|a, b| b.age.cmp(&a.age));
也可以通过实现Ord特征进行排序。但实现Ord需要先实现Eq、PartialEq、PartialOrd,可以通过derive来实现:
#[derive(Debug, Ord, Eq, PartialEq, PartialOrd)]
struct Person {
name: String,
age: u32,
}
这样在排序时,会依据属性的顺序依次进行比较排序。
- 容量
容量 capacity 是已经分配好的内存空间
长度 len 则是当前 Vec 中已经存储的元素数量。
let mut vec = Vec::with_capacity(10);
assert_eq!(vec.len(), 0);
assert_eq!(vec.capacity(), 10);
字符串
字符串实际上就是字符串字面值的引用。Sring是一个带有一些功能的字节vector的封装。
- 新建字符串
//创建空String
let mut s = String::new();
//根据已有的字符串创建
let s = "initial contents".to_string();
let s = String::from("initial contents");
- 更新字符串
let mut s = String::from("foo");
s.push_str("bar"); //附加字符串,注意,该函数使用的参数是引用
let s2 = "bar"; //s2类型为&str
s1.push_str(s2);
//之后s2还可以被使用
- 拼接字符串
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // 注意 s1 被移动了,不能继续使用
s3的产生实际上调用了add函数,该函数定义为:
fn add(self, s: &str) -> String {
第一个参数为self本身,不是引用,因此会发生所有权的转移,s1之后不能再使用了。第二个形式参数虽然是&str,接收的实参是&String,但会发生类型强转,不会报错。之后s2还可以继续使用。
另一种拼接方法是使用format!,它的用法和println!类似,但是会返回拼接后的字符串:
let s = format!("{s1}-{s2}-{s3}"); //参数使用引用,不会获取任何参数所有权
- 索引字符串
请注意,Rust 的字符串不支持索引,即s[0]是非法的。如果真的想,那么应该使用[x..y]来获取字符串slice,如:
let hello = "Здравствуйте";
let s = &hello[0..4];
获取前4个字节。
HashMap
- 新建HashMap与访问
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name).copied().unwrap_or(0);
}
get方法返回Option<&V>。如果键不存在,则返回None。
copied方法使得获取的是拷贝后的Option<V>而不是Option<&V>
unwrap_or在返回None的情况下设置为返回0.
遍历map的每个键值对:
for (key, value) in &scores {
println!("{key}: {value}");
}
- 插入键值对
默认情况下,insert插入时是覆盖旧值的。
如果想只在没有该键值对时插入,则:
scores.entry(String::from("Yellow")).or_insert(50);
entry方法返回该键值对Entry<K,V>
entry的or_insert方法在键对应的值存在时,返回该值V的可变引用&mut V,否则将参数作为新值插入并返回新值的可变引用。
如果想根据旧值得到新值,则可以这样做:
let text = "hello world wonderful world";
let mut map = HashMap::new(); //HashMap<&str, i32>
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1; //count类型为&i32,为了修改必须先解引用
}
- 通过[(K, V)]集合创建HashMap
let teams_list = vec![
("中国队".to_string(), 100),
("美国队".to_string(), 10),
("日本队".to_string(), 50),
];
let teams_map: HashMap<_,_> = teams_list.into_iter().collect();
错误处理
不可恢复的错误
对于出现错误需要结束程序运行的错误,可以使用panic!宏。
panic!("crash and burn");
如果要定位是具体是哪些函数在调用时出现Panic,就像java报错一样,则可以在运行时开启backtrace环境变量:
RUST_BACKTRACE=1 cargo run
可恢复的错误
例如打开一个文件时,如果打开失败我们不需要退出程序,则这就是个可恢复的错误。可恢复的错误一般要求函数返回Result类型,它的定义是这样的:
enum Result<T, E> {
Ok(T),
Err(E),
}
看下面这个例子:
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem opening the file: {:?}", error),
};
}
File::open函数返回值就是Result<T,E>,T在这里指文件句柄,E的类型是std::io::Error。当open函数成功时,返回一个Ok实例,失败时返回Err实例。
下面是将Result作为函数返回值的例子:
fn read_username_from_file() -> Result<String, io::Error> {
- 简写形式:
可以使用unwrap来简化错误处理:
let greeting_file = File::open("hello.txt").unwrap();
Result成员为Ok时,返回Ok中的值;如果为Err,则panic
使用expect简化:
expect比unwrap更强大,可以自己提供报错信息,其他与unwrap相同
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
- 错误传播
就像java中的throw 异常一样,不过是rust只能返回Result值。
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
?相当于一个match表达式,如果是Ok则返回Ok的值;如果是Err则将Err作为整个函数的返回值。。而且?可以自动进行类型转换,调用from方法
另外,?也可以作用于Option对象,当为Some时返回Some中的值,为None时整个函数返回None。
注意,不太能在闭包中使用?,因为闭包函数必须返回Result或者Option才可以
- try!
尽量不要使用了
- 带返回值的main函数
fn main() -> Result<(), Box<dyn Error>> {
let f = File::open("hello.txt")?;
Ok(())
}
泛型
泛型可以代表多种类型。
函数中的泛型
函数参数和返回值可以使用泛型,使得函数可以接收或返回不同类型的数据。例如
fn largest<T>(list: &[T]) -> T {
函数largest有泛型参数T,函数参数list的元素类型是T,类型是数组切片,返回值也是T。调用时按正常函数调用即可。
结构体中的泛型
struct Point<T> {
x: T,
y: T,
}
方法中的泛型
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}
impl后面的泛型<X1, Y1>是指impl后面结构体中是泛型而不是具体类型。方法中的泛型是指该方法的。
泛型类型T有时候需要增加一个类型限制,来满足一些运算符,这个类型限制就是Trait。
Trait
trait类似于java语言中interface接口的功能,定义共同的行为。
为类型定义trait
例如两个结构体:News和Tweet,它们都需要一个成员方法,显示消息的摘要,那么可以这样定义:
pub trait Summary {
fn summarize(&self) -> String;
}
trait后面是该trait的名字,要实现这个方法则这么做:
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
另外,使用时需要将trait和类型一起引入作用域,以便使用额外的trait方法:
use aggregator::{Summary, Tweet};
当然,也可以在定义trait时就指定一个默认的方法:
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
如果想让News使用这个默认方法,只需要让News成为这个trait即可,不需要做额外操作:impl Summary for NewsArticle {}
将trait作为函数参数
如果想让特定的泛型作为函数参数,也就是一个接口作为参数,则可以像下面这样做:
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
这样,item参数就是实现了Summary特征的类型。
还有一种写法,比如:
pub fn notify<T: Summary>(item1: &T, item2: &T) {
这样,item1和item2都必须是同一类型T。T必须实现了Summary。这种impl trait的语法被称为trait bound。
- 指定多个trait
如果参数要有多个约束条件,即多个trait,那么可以用+号实现:
pub fn notify<T: Summary + Display>(item: &T) {
//或
pub fn notify(item: &(impl Summary + Display)) {
另外,也可以用where从句简化trait bound的长度:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
在返回值中使用trait
函数如果要返回一个实现了某个特征的类型,则可以这么写:
fn returns_summarizable() -> impl Summary {
不过这只适用于返回单一类型。如果返回News或Tweet都可能则无法通过编译。如果要实现返回不同的类型,则需要使用特征对象。
特征对象
类似于用一个接口来同时代表许多个类型,只使用泛型时一个接口同时只能表示一个类型。
特征对象指向实现了某个特征X(下面是Draw)的实例,可以通过 & 引用或者 Box<T> 智能指针的方式来创建特征对象。
例如:
fn draw1(x: Box<dyn Draw>) {
// 由于实现了 Deref 特征,Box 智能指针会自动解引用为它所包裹的值,然后调用该值对应的类型上定义的 `draw` 方法
x.draw();
}
fn draw2(x: &dyn Draw) {
x.draw();
}
draw1(Box::new(x));
draw2(&x);
dyn 关键字只用在特征对象的类型声明上,在创建时无需使用 dyn。也就是说,draw1和draw2的参数x就是特征对象。
注意,特征对象在使用时,只能使用该特征的方法,而不能再使用其具体类型的方法
- 特征对象的限制
只有满足下面2个条件的特征才能拥有特征对象:
- 方法的返回类型不能是
Self - 方法没有任何泛型参数
如果返回Self,则特征对象返回一个具体的类型,则和上面的注意相违背。
如果包含泛型参数,则还是与具体类型有关。
- 一些使用示例:
- 返回值中使用特征对象
fn hatch_a_bird(t:i32) -> Box<dyn Bird>{
match t {
2 => {
let duck = Duck{};
Box::new(duck)
},
_ => {
let swan = Swan{};
Box::new(swan)
},
}
}
- 数组中使用特征对象
let birds: [Box<dyn Bird>; 2] = [Box::new(Duck{}), Box::new(Swan{})];
特征约束
特征约束用来限定泛型类型必须实现哪些特征。看下面一段代码:
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
这表明,T类型必须要实现DIsplay+PartialOrd两个特征。
另外,也可以为任何实现了某个trait的类型再实现一个trait:
impl<T: Display> ToString for T {
// --snip--
}
这位所有实现了Display的类型又实现了ToString。这种操作又称为blanket implementations.
特征定义中的特征约束
如果定义一个特征A时,特征A需要使用另一个特征B的功能,则需要限定实现特征A的类型也实现特征B。
trait OutlinePrint: Display {
fn outline_print(&self) {
let output = self.to_string(); //使用了Display
}
}
通过derive派生特征
通过derive来派生特征,可以让某类型自动实现对应的特征代码,简化写法。
例如:
#[derive(Debug)]
struct xxx {}
这样,xxx就实现了Debug特征,并可以使用该特征下实现的默认代码
关联类型
关联类型是在特征定义的语句块中,申明一个自定义类型,这样就可以在特征的方法签名中使用该类型:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
}
}
Self用来指代当前调用者的具体类型。因此对于实现迭代器特征的Counter来说,next函数返回的就是Option<u32>
默认泛型类型参数
使用泛型类型参数时,可以指定一个默认的具体类型,使用时可以不再声明。
trait Add<RHS=Self> {
type Output;
fn add(self, rhs: RHS) -> Self::Output;
}
如果相加的两个类型相同时,只需要impl Add即可,而不需要impl Add<SOME_Type>。
调用同名的方法
如果特征上有同名的方法,而且本类型上也有,则优先调用本类型上定义的方法。
如果要调用特征上的方法,则使用完全限定语法即可。
<Type as Trait>::function(receiver_if_method, next_arg, ...);
Type为具体类型,Trait为要调用方法的特征。第一个参数为方法接收器(3种self的具体形式),之后为参数。
包和模块
- 项目(Packages):一个
Cargo提供的feature,可以用来构建、测试和分享包 - 包(Crate):一个由多个模块组成的树形结构,编译后会生成一个可执行文件或者一个库
- 模块(Module):可以一个文件多个模块,也可以一个文件一个模块,模块可以被认为是真实项目中的代码组织单元
项目Package
Package是一个工程项目,含有独立的 Cargo.toml 文件,以及因为功能性被组织在一起的一个或多个包。一个Package只能包含一个库(library)类型的包,但是可以包含多个二进制可执行类型的包。
典型的Package结构:
- 唯一库包:
src/lib.rs - 默认二进制包:
src/main.rs,编译后生成的可执行文件与Package同名 - 其余二进制包:
src/bin/main1.rs和src/bin/main2.rs,它们会分别生成一个文件同名的二进制可执行文件 - 集成测试文件:
tests目录下 - 基准性能测试
benchmark文件:benches目录下 - 项目示例:
examples目录下
包crate
crate 是一个编译单元。二进制包的包根为src/main.rs,库包的包根为src/lib.rs。包根是编译器开始处理源代码文件的地方
模块
模块是Rust的代码构成单元。
- 创建新模块
mod aname
Rust所有类型默认情况下都是私有化的,父模块完全无法访问子模块中的私有项,但子模块可以访问父模块及其父...模块的私有项。
同层模块之间可以相互访问(不管pub)
- 将模块与文件分离
在lib.rs中加入mod front_of_house; ,告诉 Rust 从另一个和模块 front_of_house 同名的文件中加载该模块的内容。(如果要该模块可见,则需要加pub)
如果要把一个文件夹作为一个模块,那么该文件夹要包含一个rs文件,该文件中定义子模块(声明),来确定子模块的可见性,例如:
pub mod hosting;
pub mod serving;
而在hosting.rs和serving.rs中,则直接写函数即可。
- main.rs要引用lib.rs时
要引用的加包名::。。。
模块允许控制可见性和作用域。编译器编译时,会依次执行以下步骤:
-
从 crate 根节点开始: 在
src/lib.rs和src/main.rs下寻找被编译的代码 -
声明模块:crate根文件中,可以用
mod garden;声明一个叫做garden新模块,编译器会在下列位置寻找模块代码:- 当
mod garden后方不是一个分号而是一个大括号 - 在文件 src/garden.rs
- 在文件 src/garden/mod.rs
- 当
-
声明子模块: 在除了 crate 根节点以外的其他文件中,可以定义子模块。例如,可以在src/garden.rs中定义
mod vegetables;,其父模块为garden,故编译器会在garden下寻找子模块代码:- 当
mod vegetables后方不是一个分号而是一个大括号 - 在文件 src/garden/vegetables.rs
- 在文件 src/garden/vegetables/mod.rs
- 当
-
模块中的代码路径:一个 garden vegetables 模块下的
Asparagus类型可以在crate::garden::vegetables::Asparagus被找到 -
私有 vs 公用: 子模块的代码默认对其父模块私有。可以使用
pub mod声明来使模块公用。公用模块内部成员如果要公用还需要在其前加pub -
use关键字: 在一个作用域内,use关键字创建了一个成员的快捷方式。类比java就行
可见性
同一个模块中的代码互相都可见。
模块的可见性仅仅是允许其它模块去引用它
crate&module
Crate是一个独立的编译单元,例如main.rs和lib.rs都是一个Crate(crate root),它的名字和它所在的project名称相同,都是文件夹的名字。
module则是通过mod来创建的。用于对crate按照功能性进行充足。module可以嵌套,其中父module不能访问子module的私有项,而子module可以完全访问父module、父父module的所有私有项。
使用模块或模块中的函数用use即可。
- re-export
当外部module A被引入到当前module中,它的可见性自动被设为私有。如果希望允许其他外部代码引用module A,则可以对它进行再导出:
pub use crate::front_of_house::hosting;
问题
其实函数参数理解成一个变量的定义即可,加mut就是说这个变量可以改变。
标签:String,self,基础,学习,let,Rust,类型,fn,引用 From: https://www.cnblogs.com/fyqs/p/17683375.html