转载自https://zhuanlan.zhihu.com/p/58916233
在上节,我们学习了词向量的两种训练方式:Skip-Gram和CBOW,都是通过句子中的某个单词去预测另一个单词。而本节,我们将学习第三种词向量的训练模型:GLOVE[1]。
GLOVE模型是由斯坦福教授Manning、Socher等人于2014年提出的一种词向量训练模型,该模型的提出正是在Skip-Gram和CBOW模型出来一年之后。
Manning教授是斯坦福自然语言处理热门课程CS224n的主讲导师,同时其在2018年末接替李飞飞教授成为了斯坦福人工智能实验室的主任。
区别于Skip-Gram和CBOW,GLOVE模型的训练并没有使用神经网络,而是计算共线矩阵通过统计的方法获得。
GLOVE模型获得词向量的步骤可以简单分为两步:
- 构造共现矩阵。
- 构造损失函数并训练模型。
1. 构造共现矩阵
GLOVE模型训练词向量的第一步骤是根据语料库构建共现矩阵X。假设语料库的大小为N(即有N个单词),则共现矩阵是一个形状为(N, N)的二维向量,其中每个元素 ��� 当窗口滑动遍历完整个语料库之后,即可更新得到共线矩阵X,比如代表单词i和单词j共同出现在一个窗口(window)中的频数。
我们假设语料库中有如下句子,共包含8个单词:
I would like a glass of orange juice.设置window_size=2,即中心词左右2个单词记为上下文词,其包括中心词构成窗口里面的词。如果我们从左到右滑动窗口,每滑动一次记录一个新的窗口,则会生成以下窗口内容:
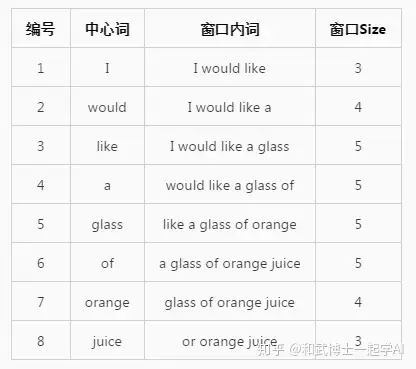
当窗口滑动到编号3时,中心词为like,窗口内的词为I、would、like、a、glass,因此对共现矩阵内的元素进行更新:
�����,�=�����,�+1�����,�����=�����,�����+1�����,�=�����,�+1�����,�����=�����,�����+1
当窗口滑动遍历完整个语料库之后,即可更新得到共线矩阵X,比如:
I would like a glass of orange juice.
I like orange juice.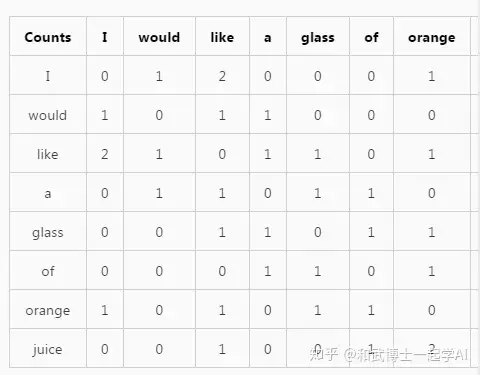
理解了Glove中的共现矩阵之后,我们将依此构造Glove模型的目标损失函数。
2 构造损失函数
在写Glove的损失函数前,我们先看看最简单的线性回归的损失函数,即平方误差损失函数。
平方误差损失函数: �=∑��[(���+�)−�(�)]2
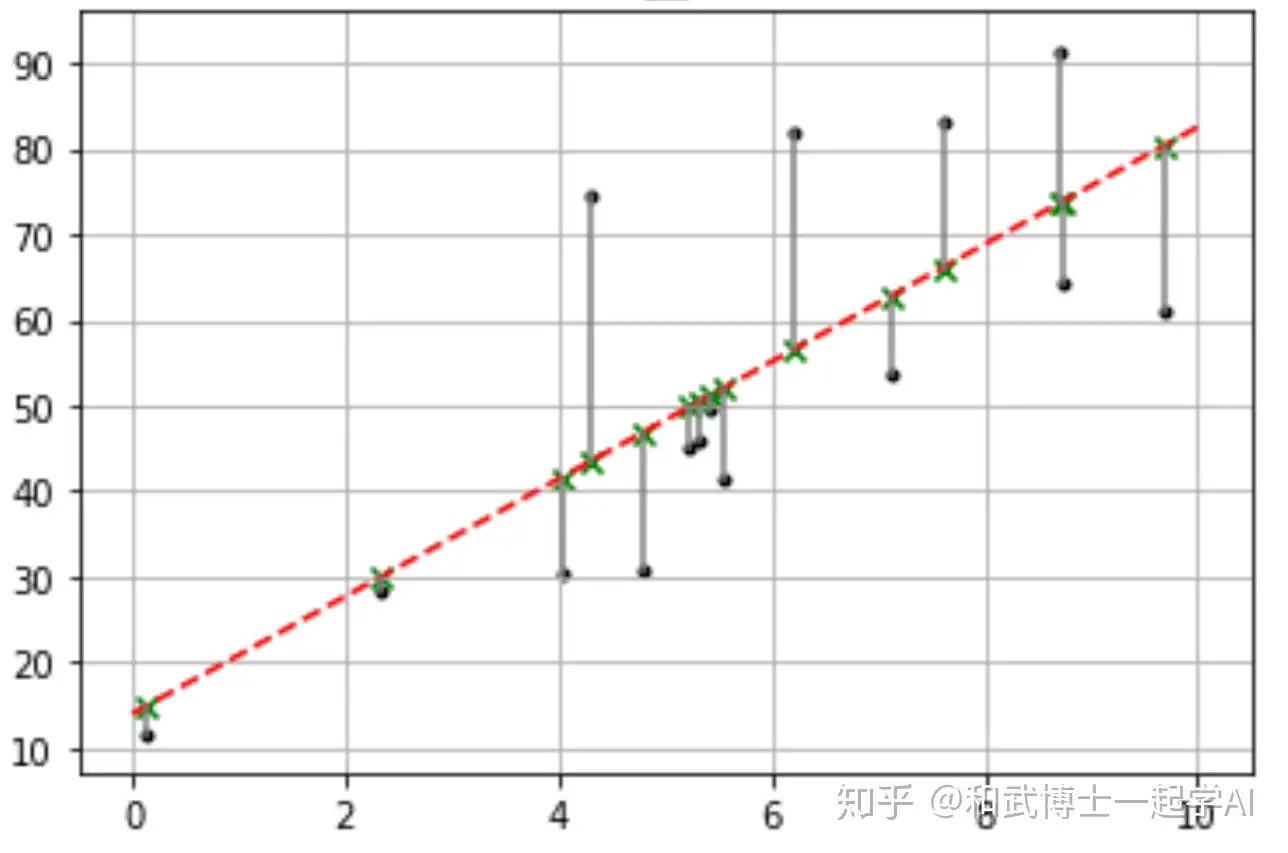
我们希望预测值 ���+� 和实际值 �� 的差距越小越好,反应在函数中即损失函数J的值越小越好(上图中各灰色线段越短越好), 加上平方则是避免值为负数且方便求导。可见,在平方误差损失函数的训练过程中,预测值和实际值的差距将越来越小。
从平方误差损失函数出发,我们只需要找到两个值,其中一个代表词向量,另外一个代表它的真实标签,我们就可以借助平方误差损失函数让它们越来越接近,最后得到词向量。
然而我们并不能找到一个真实标签来直接代表词向量,所以在论文中采用了一种迂回的方法,即以单词i和单词j共同出现在一个窗口(window)中的频数作为真实标签,以词向量的点乘作为预测值。
由此我们先写下一个Glove模型的简化版损失函数。
�=∑�,��(�����−���(��,�))2
其中, �� 和 �� 是在初始阶段单词i和单词j的词向量(在后续的训练中会逼近真实的词向量), ��,� 为根据共现矩阵得到的单词i和单词j共同出现在一个窗口(window)中的频数。
有线性代数基础的同学应该知道向量的点乘结果类似余弦相似度可以在一定程度上反映两个向量的相近程度,此处就是使用两个词向量的点乘来反映预测相似度,以两个单词共同出现的频数来反映实际相似度。通过对平方误差损失函数的不断训练,可以让预测相似度不断地逼近实际相似度,当预测相似度和实际相似度非常的接近时,我们也就得到了我们想要的词向量。
理解了简化版Glove损失函数之后对Glove的理解就差不多了,剩下的细枝末节只是为了让模型更鲁棒。
由于 ��,� 有可能为0,即两个单词从来都没有一起出现过。则 ���(���) 变为 ���0 是未定义的,所以我们需要加上一个加权项 �(���) ,即:
�=∑�,���(���)(�����−���(��,�))2
使得当 ��� 为0时, �(���) ,即跳过这一项。同时 �(���) 还有一个作用是使得常出现的词如(this, is, he I)等不会有太大的权重值,而一些很少出现的词比如(incessant、retention)等不会有太小的权重。通俗来说,就是告诫模型不要一直盯着那些一直出现的词,也要照顾一下那些很少出现的词。
最后,为了增强模型的鲁棒性,作者像在线性回归中加入偏置项一样在Glove模型中也加入了偏置项,得到了最终的损失函数模型:
�=∑�,���(���)[(�����+��+��)−���(��,�)]2
通过训练这个损失函数使得J最小,我们也就得到了训练好的词向量。
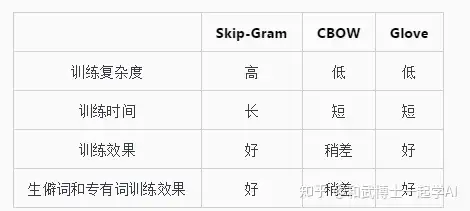
3. Glove和Skip-Gram、CBOW的区别
Glove相对于Skip-Gram和CBOW利用了词共现的信息,即不仅仅关注word2vector窗口大小的上下文,而是利用共现矩阵用到了全局的信息。
同时,Glove的优点是训练快,可以拓展到大规模语料,也适用于小规模语料和小向量,且最终效果通常更好。
4. 词向量测评
到目前为止,我们已经学习了词向量及其应用,以及训练获得词向量的三种模型。基于不同的语料库和不同的模型训练出来的词向量都有差别,所以摆在眼前的问题是:如何评价词向量的好坏?
目前常用的评价方法主要有两种:
- 内部对比分析
内部对比分析即借助我们在以前提到的余弦相似度。该任务是给定三个词,比如"king"、"queen"、"man",然后遍历语料计算余弦相似度进行查找,即"queen"对于"king"相当于什么词对于"man"?若是通过词向量能准确定位到"woman"这个词,代表这个样本定位成功。在实际中是借助人工标记,进行多个类比对比,比如"Chinese"对于"China"和"Japanese"对于"Japan"等。
- 外部任务测评
外部任务评价则更好理解,即借助不同的词向量进行同样的文本处理任务,比如情感分类等,通过情感分类任务的预测准确度来评价不同词向量的好坏。
你需要带走的知识点:)
1. 什么是共线矩阵?其维度是多少?每个元素代表什么含义?
2. 如何理解Glove的损失函数?
3. Glove和Skip-Gram、CBOW的区别?
4. 如何评价词向量的好坏?
[1]: Pennington J, Socher R, Manning C. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
标签:NLP,函数,GLOVE,模型,矩阵,Glove,单词,四十六,向量 From: https://www.cnblogs.com/zhangxianrong/p/17558235.html