紧接着我们来聊聊可扩展性。 可扩展性是指,软件系统具备面对未来需求变化而进行扩展的能力。系统可根据新的需求做出少量或者不需要修改,无需对整个系统进行重构或重建。 由于软件系统变化多端,新的需求不断提出,因此可扩展性非常重要。为解决可扩展性带来的问题,面向对象思想的提出,设计模式的诞生更是将可扩展性发挥到了极致。几乎所有的技术人员都重视可扩展性。 当涉及到软件系统的可扩展性时,架构师面临一个复杂的挑战:如何预测未来的需求变化并为之提供扩展性,以便系统能够在不需要大幅度修改或重建的情况下支持新的需求。这是因为软件系统在发布后仍然可以不断地修改和演进,导致新的需求不断出现,而系统必须能够应对这些变化。如果系统能够以较小的修改量或甚至无需修改就能实现新需求,那当然是最理想的情况,否则就需要进行大规模修改或重构,这将极大地增加开发成本,也会导致程序员、产品经理和老板的不满。因此,架构师必须尝试预测所有可能的变化并设计出最佳的解决方案,以便在下一次需求到来时,能够高效地满足需求。但是,这个过程并不容易,因为架构师需要在考虑可扩展性和其他设计因素之间进行平衡,并且预测的结果也不总是准确的。同时,如果架构师忽略可扩展性,那么当新需求到来时,可能需要重构系统,这将导致前期投入的工作量白费。因此,架构师需要通过经验和直觉来提高预测结果的准确性,同时也需要明确的标准来帮助评审和决策。 设计具备良好可扩展性的系统有两个基本条件: 但要达成这两个条件,本身也是一件复杂的事情,我来具体分析一下。 软件系统与硬件或者建筑相比,有一个很大的差异:软件系统在发布后,还可以不断地修改和演进。 这就意味着 不断有新的需求需要实现。 如果新需求能够少改代码甚至不改代码就可以实现,那当然是皆大欢喜的,否则来一个需求就要求系统大改一次,成本会非常高,程序员心里也不爽(改来改去),产品经理也不爽(做得那么慢),老板也不爽(那么多人就只能干这么点事)。 要满足这两个条件,本身就是一件复杂的事情。作为架构师,总是试图预测所有的变化,然后设计完美的方案来应对。当新需求真正来临时,可以自豪地说:“这个我当时已经预测到了,架构已经完美地支持,只需要一两天工作量就可以了!” 但是,预测变化的复杂性在于不能每个设计点都考虑可扩展性,也不能完全不考虑。而且所有的预测都存在出错的可能性。架构师必须把握预测的程度和提升预测结果的准确性,这是一件很复杂的事情,没有通用的标准可以简单套用,更多是靠自己的经验和直觉。因此,在架构设计评审时,常常出现两个设计师对某个判断争得面红耳赤的情况,原因在于没有明确标准,不同的人理解和判断有偏差,而最终又只能选择其中一个判断
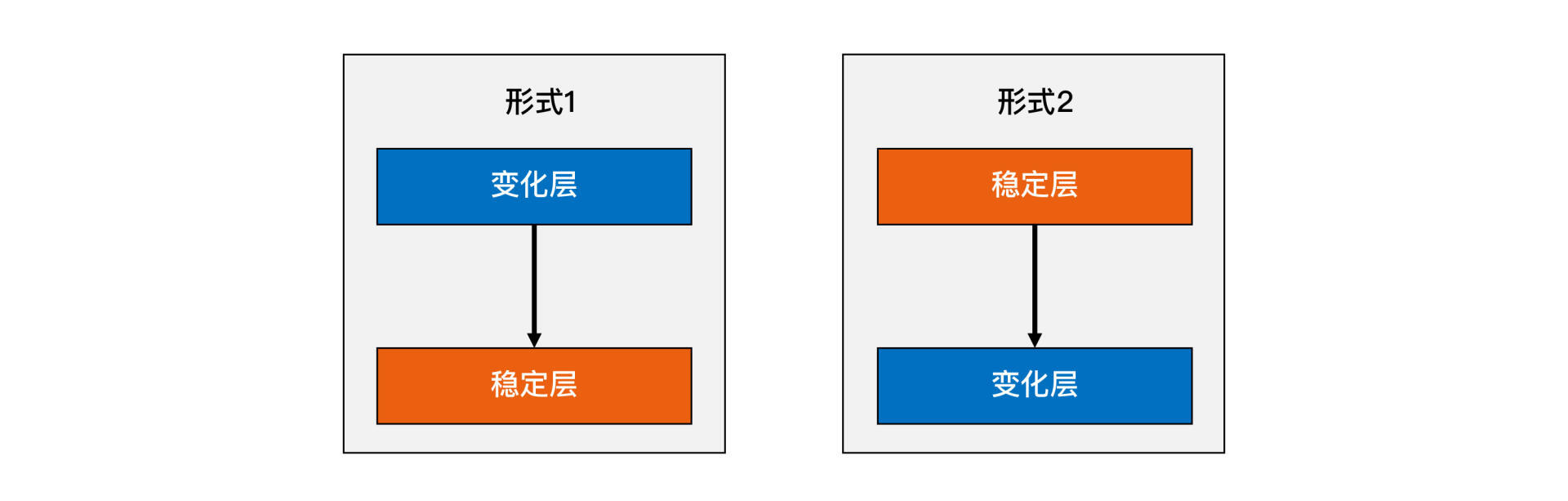
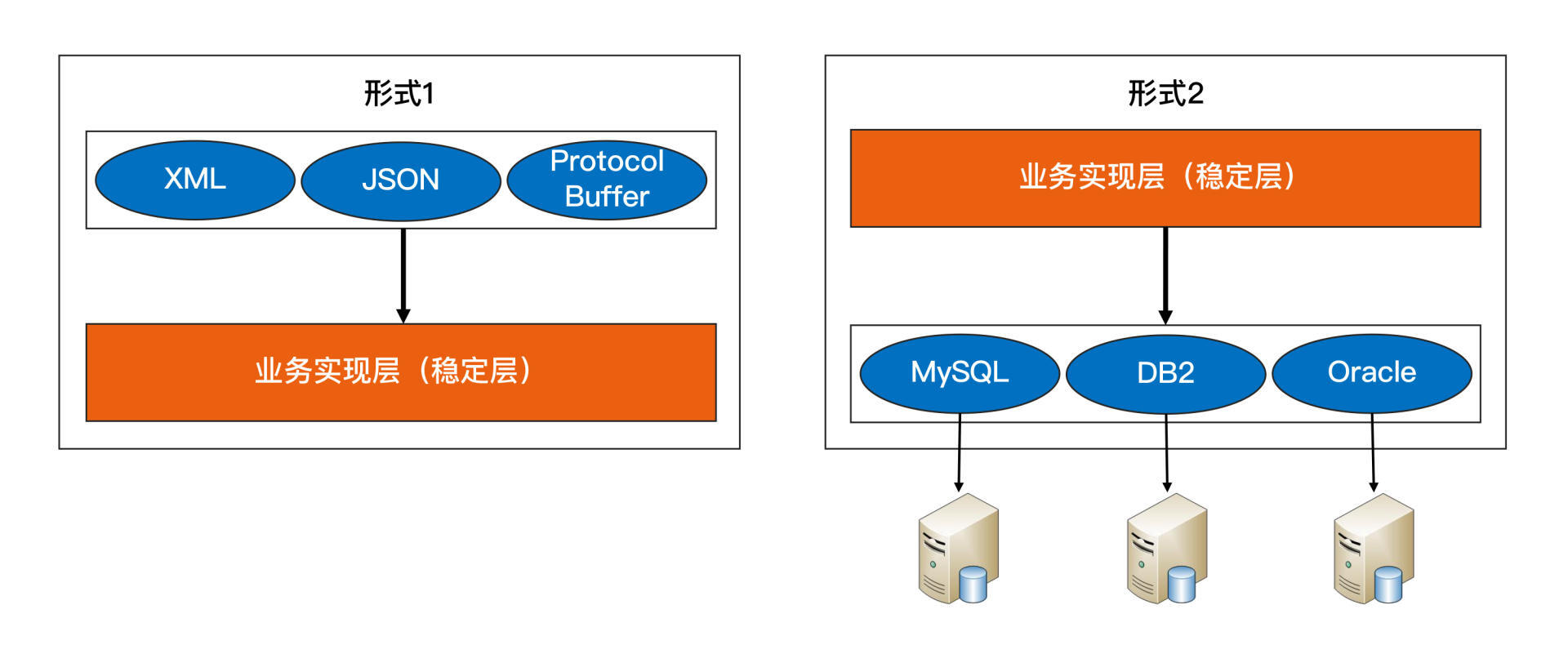
有一句谚语:“唯一不变的是变化。”如果按照这个标准去衡量,架构师每个设计方案都要考虑可扩展性,例如: 如果架构师在设计系统时每个点都考虑可扩展性,那么会让其不堪重负,架构设计也会变得异常庞大,最终可能无法落地。但是如果架构师完全不考虑系统的可扩展性,那么可能会导致系统刚上线就需要重构,这意味着前期的大量投入将会白费。因此,在设计时需要适度考虑可扩展性,以提高系统的灵活性,但也需要合理平衡成本和效益。 同时,“预测”这个词,本身就暗示了不可能每次预测都是准确的。如果预测的事情出错,我们期望中的需求迟迟不来,甚至被明确否定,那么基于预测做的架构设计就没什么作用,投入的工作量也就白费了。 综合分析,预测变化的复杂性在于: 对于架构师来说,如何预测变化的程度和提高预测的准确性是一个非常复杂的问题。目前没有一套通用的标准可以简单地应用,更多是根据架构师的经验和直觉。因此,在架构设计评审时,经常会发生两个设计师就某个判断产生激烈争议的情况。这是因为缺乏明确的标准,不同的人会有不同的理解和判断偏差,最终只能选择其中一个判断。 那么我们设计架构的时候要怎么办呢?根据以往的职业经历和思考,我提炼出一个“2年法则”供你参考: 只预测2年内的可能变化,不要试图预测5年甚至10年后的变化。 当然,你可能会有疑问:为什么一定是2年呢?有的行业变化快,有的行业变化慢,不应该是按照行业特点来选择具体的预测周期吗? 理论上来说确实如此,但实际操作的时候你会发现,如果你要给出一个让大家都信服的行业预测周期,其实是很难的。 我之所以说要预测2年,是因为变化快的行业,你能够预测2年已经足够了;而变化慢的行业,本身就变化慢,预测本身的意义不大,预测5年和预测2年的结果是差不多的。所以“2年法则”在大部分场景下都是适用的。 假设架构师经验非常丰富,目光非常敏锐,看问题非常准,所有的变化都能准确预测,是否意味着可扩展性就很容易实现了呢?也没那么理想!因为预测变化是一回事,采取什么方案来应对变化,又是另外一个复杂的事情。即使预测很准确,如果方案不合适,则系统扩展一样很麻烦。 第一种应对变化的常见方案是: 将不变的部分封装在一个独立的“稳定层”,将“变化”封装在一个“变化层”(也叫“适配层”)。这种方案的核心思想是通过变化层来 隔离变化。 无论是变化层依赖稳定层,还是稳定层依赖变化层都是可以的,需要根据具体业务情况来设计。 如果系统需要支持XML、JSON、ProtocolBuffer三种接入方式,那么最终的架构就是“形式1”架构;如果系统需要支持MySQL、Oracle、DB2数据库存储,那么最终的架构就变成了“形式2”的架构了。 无论采取哪种形式,通过剥离变化层和稳定层的方式应对变化,都会带来两个主要的复杂性相关的问题。 对于哪些属于变化层,哪些属于稳定层,很多时候并不是像前面的示例(不同接口协议或者不同数据库)那样明确,不同的人有不同的理解,导致架构设计评审的时候可能吵翻天。 对于稳定层来说,接口肯定是越稳定越好;但对于变化层来说,在有差异的多个实现方式中找出共同点,并且还要保证当加入新的功能时,原有的接口不需要太大修改,这是一件很复杂的事情,所以接口设计同样至关重要。 例如,MySQL的REPLACE INTO和Oracle的MERGE INTO语法和功能有一些差异,那么存储层如何向稳定层提供数据访问接口呢?是采取MySQL的方式,还是采取Oracle的方式,还是自适应判断?如果再考虑DB2的情况呢? 看到这里,相信你已经能够大致体会到接口设计的复杂性了。 第二种常见的应对变化的方案是: 提炼出一个“抽象层”和一个“实现层”。如果说方案一的核心思想是通过变化层来隔离变化,那么方案二的核心思想就是通过实现层来 封装变化。 因为抽象层的接口是稳定的不变的,我们可以基于抽象层的接口来实现统一的处理规则,而实现层可以根据具体业务需求定制开发不同的实现细节,所以当加入新的功能时,只要遵循处理规则然后修改实现层,增加新的实现细节就可以了,无须修改抽象层。 方案二典型的实践就是设计模式和规则引擎。考虑到绝大部分技术人员对设计模式都非常熟悉,我以设计模式为例来说明这种方案的复杂性。 下面是设计模式的“装饰者”模式的类关系图。 图中的Component和Decorator就是抽象出来的规则,这个规则包括几部分: 这个规则一旦抽象出来后就固定了,不能轻易修改。例如,把规则3去掉,就无法实现装饰者模式的目的了。 装饰者模式相比传统的继承来实现功能,确实灵活很多。例如,《设计模式》中装饰者模式的样例“TextView”类的实现,用了装饰者之后,能够灵活地给TextView增加额外更多功能,包括可以增加边框、滚动条和背景图片等。这些功能上的组合不影响规则,只需要按照规则实现即可。 但装饰者模式相对普通的类实现模式,明显要复杂多了。本来一个函数或者一个类就能搞定的事情,现在要拆分成多个类,而且多个类之间必须按照装饰者模式来设计和调用。 规则引擎和设计模式类似,都是通过灵活的设计来达到可扩展的目的,但“灵活的设计”本身就是一件复杂的事情,不说别的,光是把23种设计模式全部理解和备注,都是一件很困难的事情。 那么,我们在实际工作中具体如何来应对变化呢?Martin Fowler在他的经典书籍《重构》中给出一个“Rule of three”的原则,原文是“Three Strikes And You Refactor”,中文一般翻译为“事不过三,三则重构”。 而我将其翻译为“1写2抄3重构”,也就是说你不要一开始就考虑复杂的可扩展性应对方法,而是等到第三次遇到类似的实现的时候再来重构,重构的时候采取隔离或者封装的方案。 举个最简单的例子,假设你们的创新业务要对接第三方钱包,按照这个原则,就可以这样做: 今天我从预测变化和应对变化这两个设计可扩展性系统的条件,以及它们实现起来本身的复杂性,为你讲了复杂度来源之一的可扩展性,共勉!
预测变化
2年法则
应对变化
方案一:提炼出“变化层”和“稳定层”
方案二:提炼出“抽象层”和“实现层”

1写2抄3重构原则
小结