前言
为什么用Decoder only
LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
众所周知,Attention矩阵一般是由一个低秩分解的矩阵加softmax而来,具体来说是一个 n × d 的矩阵与 d × n 的矩阵相乘后再加softmax(n ≫ d ),这种形式的Attention的矩阵因为低秩问题而带来表达能力的下降,具体分析可以参考《Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth》。而Decoder-only架构的Attention矩阵是一个下三角阵,注意三角阵的行列式等于它对角线元素之积,由于softmax的存在,对角线必然都是正数,所以它的行列式必然是正数,即Decoder-only架构的Attention矩阵一定是满秩的!满秩意味着理论上有更强的表达能力,也就是说,Decoder-only架构的Attention矩阵在理论上具有更强的表达能力,改为双向注意力反而会变得不足。
prefix LM和causal LM的区别?
attention mask不同,前者的prefix部分的token互相能看到,后者严格遵守只有后面的token才能看到前面的token的规则。
ChatGLM-6B[1] prefix LM
LLaMA-7B[2] causal LM
GPT系列就是Causal LM,目前除了T5和GLM,其他大模型基本上都是Causal LM。
说一下LLM常见的问题?
出现复读机问题。
比如:ABCABCABC不断循环输出到max length。
对于这种现象我有一个直观的解释(猜想):prompt部分通常很长,在生成文本时可以近似看作不变,那么条件概率 P(B|A)也不变,一直是最大的。
生成重复内容,是语言模型本身的一个弱点,无论是否微调,都有可能出现。并且,理论上良好的指令微调能够缓解大语言模型生成重复内容的问题。[3]但是因为指令微调策略的问题,在实践中经常出现指令微调后复读机问题加重的情况。
另外,可能出现重复用户问题的情况,原因未知。
如何缓解复读机问题?
解码方式里增加不确定性,既然容易复读那我们就增加随机性,开启do_sample选项,调高temperature。
如果学的太烂,do_sample也不顶用呢?加重复惩罚,设置repetition_penalty,注意别设置太大了。不然你会发现连标点符号都不会输出了。
llama 输入句子长度理论上可以无限长吗?
这里引用苏神(RoPE作者)在群里的回复。
限制在训练数据。理论上rope的llama可以处理无限长度,但问题是太长了效果不好啊,没训练过的长度效果通常不好。而想办法让没训练过的长度效果好,这个问题就叫做“长度外推性”问题。
所以接受2k的长度限制吧。
为什么大模型推理时显存涨的那么多还一直占着?
首先,序列太长了,有很多Q/K/V。
其次,因为是逐个预测next token,每次要缓存K/V加速解码。
大模型大概有多大,模型文件有多大?
一般放出来的模型文件都是fp16的,假设是一个 n B的模型,那么模型文件占 2n G,fp16加载到显存里做推理也是占 2n G,对外的pr都是 10n 亿参数的模型。
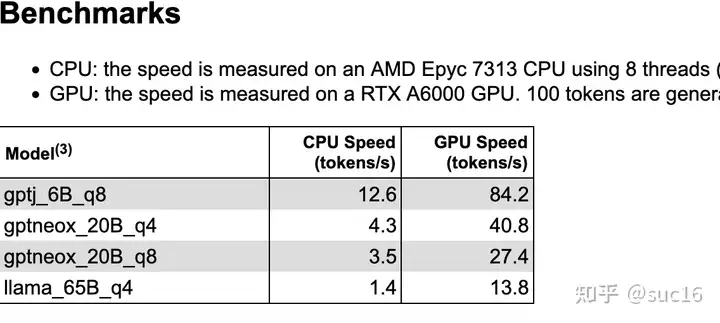
大模型在gpu和cpu上推理速度如何?
7B量级下,cpu推理速度约10token/s,单卡A6000和8核AMD的推理速度通常为 10:1。[5]
能否用4 * v100 32G训练vicuna 65b?
不能。
首先,llama 65b的权重需要5* v100 32G才能完整加载到GPU。
其次,vicuna使用flash-attention加速训练,暂不支持v100,需要turing架构之后的显卡。
(刚发现fastchat上可以通过调用train脚本训练vicuna而非train_mem,其实也是可以训练的)
V100下不要进行 8bit 模式的训练,alpaca_lora的复现上很多人遇到了loss突变为0的bug。
如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
一般 n B的模型,最低需要 16-20 n G的显存。(cpu offload基本不开的情况下)
vicuna-7B为例,官方样例配置为 4*A100 40G,测试了一下确实能占满显存。(global batch size 128,max length 2048)当然训练时用了FSDP、梯度累积、梯度检查点等方式降显存。
推理速度上,int8和fp16比起来怎么样?
根据实践经验,int8模式一般推理会明显变慢(huggingface的实现)
如果就是想要试试65b模型,但是显存不多怎么办?
最少大概50g显存,可以在llama-65b-int4(gptq)模型基础上LoRA[6],当然各种库要安装定制版本的。
LoRA权重是否可以合入原模型?
可以,将训练好的低秩矩阵(B*A)+原模型权重合并(相加),计算出新的权重。
ChatGLM-6B LoRA后的权重多大?
rank 8 target_module query_key_value条件下,大约15M。
SFT(有监督微调)的数据集格式?
一问一答
RM(奖励模型)的数据格式?
一个问题 + 一条好回答样例 + 一条差回答样例
PPO(强化学习)的数据格式?
理论上来说,不需要新增数据。需要提供一些prompt,可以直接用sft阶段的问。另外,需要限制模型不要偏离原模型太远(ptx loss),也可以直接用sft的数据。
奖励模型需要和基础模型一致吗?
不同实现方式似乎限制不同。(待实践确认)colossal-ai的coati中需要模型有相同的tokenizer,所以选模型只能从同系列中找。在ppo算法实现方式上据说trlx是最符合论文的。
如何给LLM注入领域知识?
第一种办法,检索+LLM,先用问题在领域数据库里检索到候选答案,再用LLM对答案进行加工。
第二种方法,把领域知识构建成问答数据集,用SFT让LLM学习这部分知识。[7]
为什么SFT之后感觉LLM傻了?
-
SFT的重点在于激发大模型的能力,SFT的数据量一般也就是万恶之源alpaca数据集的52k量级,相比于预训练的数据还是太少了。如果抱着灌注领域知识而不是激发能力的想法,去做SFT的话,可能确实容易把LLM弄傻。
-
指令微调是为了增强(或解锁)大语言模型的能力。
其真正作用:
指令微调后,大语言模型展现出泛化到未见过任务的卓越能力,即使在多语言场景下也能有不错表现 。
微调数据集:
应该选择多个有代表性的任务,每个任务实例数量不应太多(比如:数百个)否则可能会潜在地导致过拟合问题并影响模型性能 。
同时,应该平衡不同任务的比例,并且限制整个数据集的容量(通常几千或几万),防止较大的数据集压倒整个分布。
如果想要快速体验各种模型,该怎么办?
推荐fastchat[4],集成了各路开源模型,从自己的vicuna到stable AI的stableLM。
找数据集哪里找?
推荐Alpaca-COT[8],数据集整理的非常全,眼花缭乱。
标签:显存,模型,Attention,矩阵,QA,LLM,Decoder From: https://www.cnblogs.com/heyjjjjj/p/17488425.html