【博学谷IT技术支持】
HDFS写流程
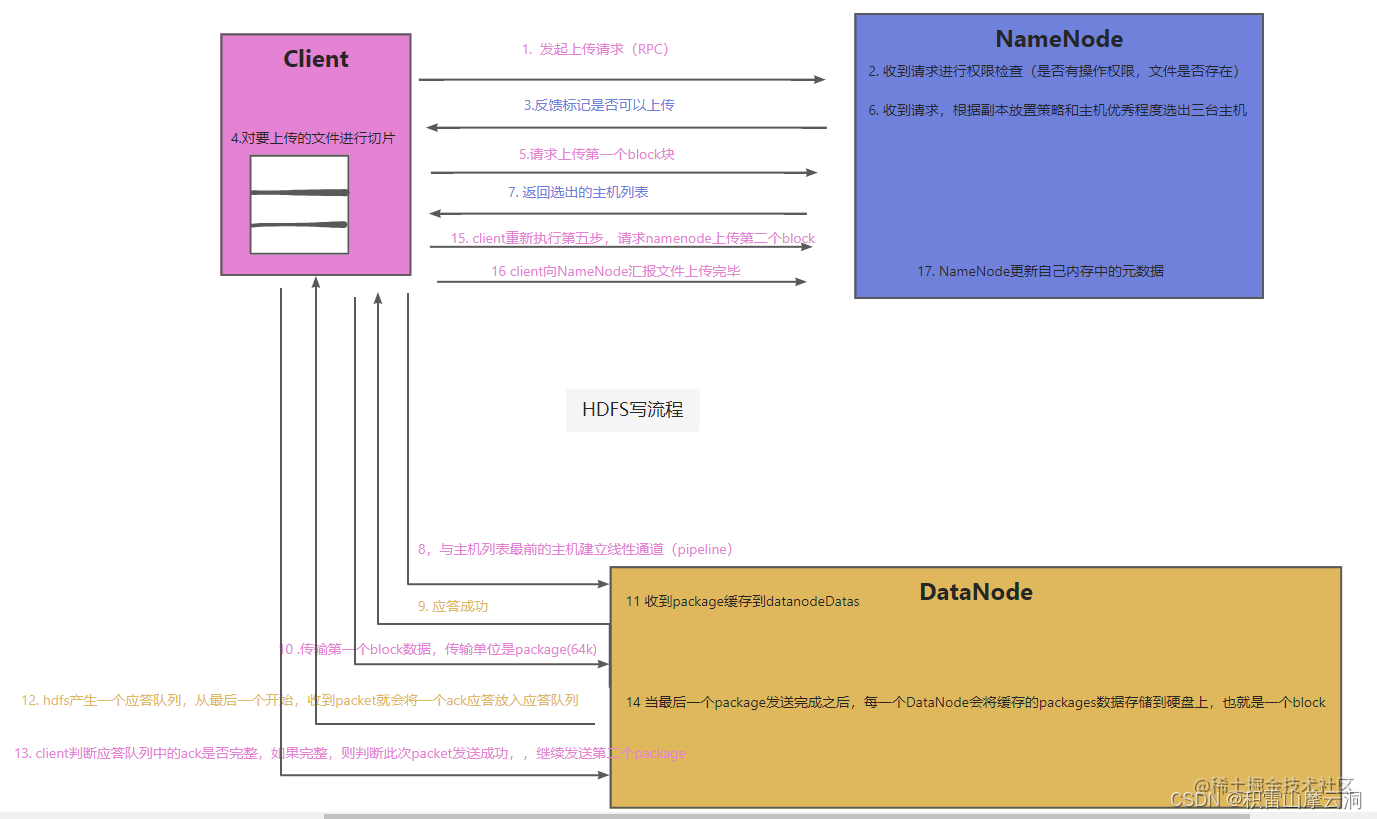
上图是HDFS的写流程图
主要步骤如下
- client向服务器发起上传请求(RPC)
- NameNode接受到请求之后会进行权限检查(目录是否存在权限,目录是否存在)
- NameNode会给client反馈是否可以上传标记
- Client会将要上传的文件安装设置的Block大小进行切片
- Client向NameNode请求上传第一个Block
- 当NameNode收到上传Block请求之后,会根据副本放置策略和主机的优秀程度选出最优主机
- NameNode返回最优的主机列表给Client
- Client和主机列表排在最前的主机建立pipeline
- dataNode告诉应答成功
- Client开始传输第一个Block数据,传输数据的单位是package(64K)
- 收到一个package就会缓存datanodeDatas
- HDFS会产生一个应答队列,从最后一个开始,收到packet,就会将一个ACK应答放入应答队列
- Client判断应答队列的ACK是否完整,如果完整,则判断此次packet发送成功,继续发送第二个package
- 当最后一个package发送完成之后,每一个DataNode会将缓存的Package数据存储到硬盘上,也就是一个Block
- Client重新执行第五步,请求Namenode上传第二个block,
- client向Namenode汇报文件上传完毕
- NameNode更新自己内存中的元数据
写流程简单概况
- client向namenode发起上传请求,namenode判断权限等告诉client是否可以上传,并返回主机列表。
- client与主机建立pipeline,分别上传所有的block。
- 上传完毕汇报client,client告诉namenode更新自己内存中的元数组。
HDFS读流程
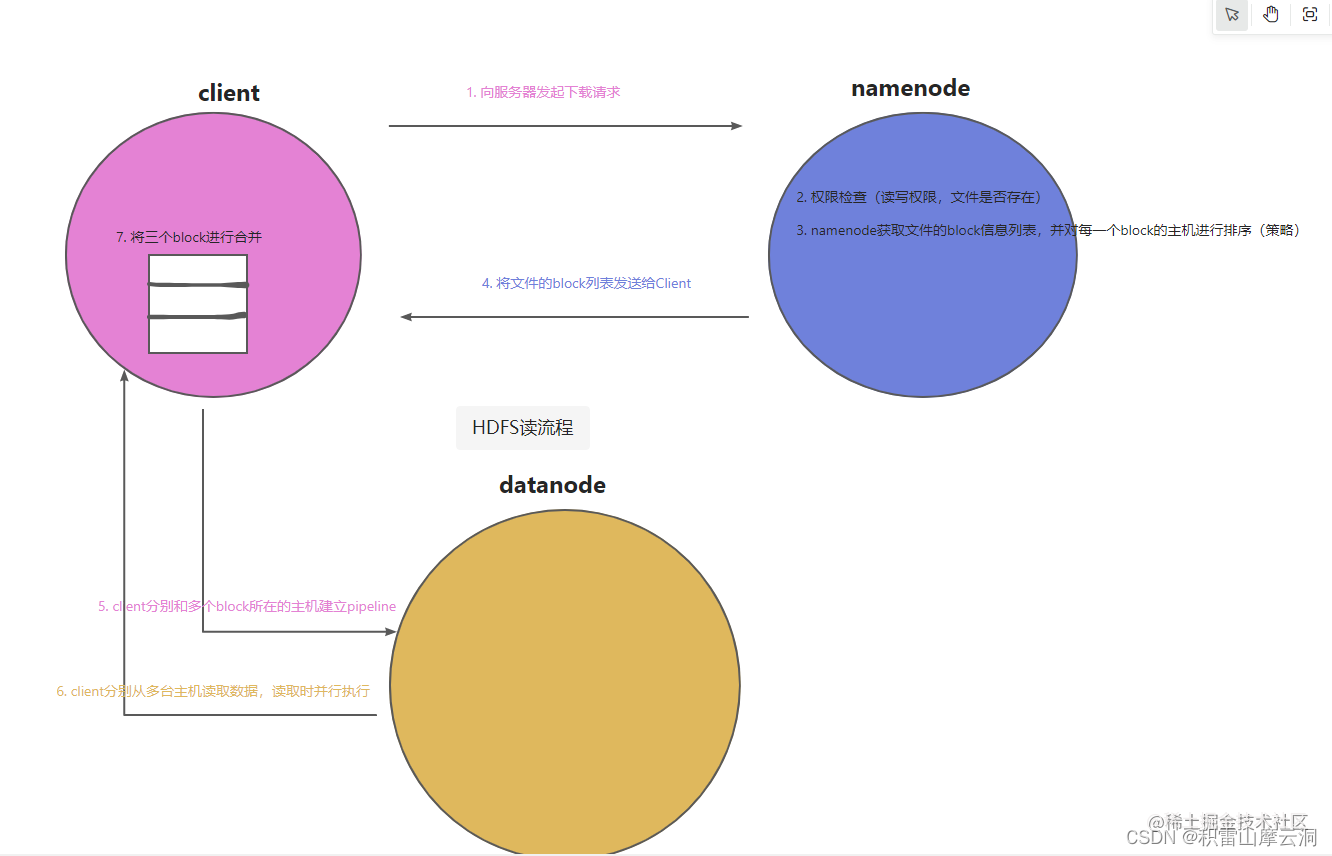
- Client向服务端发起文件下载请求
- 服务器做权限检查,判断文件是否存在以及权限问题
- namenode获取该文件的block信息列表,并且对每一个block的主机进行排序(策略)
block1: node1 node3 node4
block2: node1 node2 node4
block3: node2 node3 node4
- 将文件的block列表发送到client
block1: node1 node3 node4
block2: node1 node2 node4
block3: node2 node3 node4
- client分别和三个block所在的主机建立管道通信
- client分别从三台主机读取数据,读取是并行执行(读取的单位是packet,64k)
- client将这三个block进行合并(字节数组的合并)
读流程简单概况
- 向namenode发起下载请求,namenode判断权限并返回主机列表
- client与主机列表建立pipeline并读取数据
- client对数据进行合并